

Если у вас в компании десятки тысяч сотрудников и тысячи внутренних систем, управление доступами превращается в одну из самых главных задач. Стоит лишь немного ошибиться с ролями — и это может привести к компрометации, утечке или остановке бизнес-процессов. Но и слишком строгим делать этот процесс тоже нельзя, иначе команда будет буксовать на этапе выдачи доступов. Поэтому приходится постоянно искать баланс между безопасностью и скоростью, когда вокруг не прекращающиеся наймы, ротации, увольнения и сложные ролевые модели.
Мы — Андрей Аникин и Влад Альчиков, команда информационной безопасности в Техплатформе Городских сервисов Яндекса. Наша зона ответственности — доступы ко всем системам и продуктам: Яндекс Go, Маркет, Еда, Лавка, Доставка и другие. Только внутри нашей IDM-системы сейчас крутится больше 27 миллионов ролей. Согласования, подтверждения, отказы, отозванные роли, групповые и персональные доступы — всё это живёт в едином конвейере, который должен быть надёжным, быстрым и безопасным.

В этой статье мы расскажем, как управляем доступами в условиях большого масштаба и высокого темпа. С какими проблемами сталкиваемся, как автоматизируем процессы и добиваемся того, чтобы принцип минимально необходимых привилегий работал не на бумаге, а в реальности — каждый день и для каждого сотрудника.
Как всё было устроено и почему этого было недостаточно
Начнём с базовой картины. Внутри Городских сервисов Яндекса почти всё связано с доступами. CRM, колл-центры, админки, склады, хранилища, отчётность — каждое действие в системе требует чётко выданной роли. Эти роли отвечают не только за то, что может делать сотрудник, но и за то, как быстро он вообще начнёт работать.
Чтобы держать это под контролем, у нас есть вышеупомянутая IDM или Identity Manager — собственная централизованная система управления доступами. В неё интегрированы более 1800 систем, как внутренних, так и внешних. Через IDM сотрудники запрашивают доступы, ответственные лица их согласовывают и выдают роли. В любой момент можно посмотреть, кто, когда и на какой срок получил роль, кто её согласовал, какие параметры у доступа и когда он будет отозван.

С технической точки зрения всё выглядит вполне прозрачно: сотрудник заходит в веб-интерфейс IDM, выбирает нужную роль, указывает срок — и запускает процесс согласования. Дальше запрос уходит по цепочке: сначала руководителю, потом — владельцу системы, а при необходимости — и в службу ИБ. Модель гибкая: для некритичных доступов может быть один согласующий, для критичных — три. Это помогает не перегружать процесс и быстрее выдавать рутинные доступы.
Сами роли бывают трёх типов:
- Персональные — выдаются конкретному сотруднику (таких ролей у нас 17 миллионов).
- Групповые — назначаются на команды, проектные группы или v-teams (их 10 миллионов).
- Технические — выдаются на роботов и автоматизированные процессы.
Системы, к которым запрашивают доступ, условно делятся на четыре блока:
- Веб-интерфейсы: админки, CRM, поддержка, WMS.
- Хранилища данных: Postgres, Mongo, YTsaurus, ClickHouse.
- Аналитика и отчётность: DataLens, OLAP, Atlas, 1С.
- Инфраструктура: Runtime, балансеры, логи, секреты.

В этой статье мы не будем касаться доступа к инфраструктуре — сосредоточимся на первых трёх пунктах. Это те системы, в которых сотрудники работают каждый день, где доступы напрямую влияют на скорость бизнеса и уровень риска.
И вот тут начинается самое интересное. Формально — система есть, роли выдаются, процессы прозрачны. Но на практике всё не так гладко. IDM не знает, как используются выданные роли, потому что системы не передают туда логи использования ролей. А поток заявок на доступы настолько большой, что сотрудникам часто приходилось ждать не часы, а сутки, прежде чем начать работу.
Мы начали разбираться, почему так происходит — и быстро поняли, что проблема состоит из двух частей. Первая — это риски безопасности, связанные с избыточными или устаревшими ролями. Вторая — это длительное ожидание доступа, которое мешает сотрудникам быстро включаться в работу.
В обоих случаях мы стремились прийти к тому, чтобы построить такую систему управления доступами, которая умеет масштабироваться, работает точно и по возможности максимально автономно и ничего при этом не ломает.
Избыточные доступы — главный риск безопасности
Чем больше компания, тем сложнее понять, кто и зачем имеет доступ к тем или иным системам. А в какой-то момент это перестаёт быть просто вопросом учёта и превращается в реальный риск безопасности.
Как уже упоминалось выше, у нас в Городских сервисах Яндекса выдано больше 27 миллионов ролей. Из них 17 миллионов — персональные, остальные — групповые и технические. И в этом объёме невозможно вручную уследить за тем, кто из сотрудников действительно пользуется своими доступами, а кто давно о них забыл — но формально всё ещё может делать в системе что-то, что позволяют эти доступы.
Почему это проблема
В идеале у каждого сотрудника должны быть только те доступы, которые нужны ему прямо сейчас. Не шире. Не «на всякий случай», а только по факту рабочих задач.
Это не бюрократия и не академический принцип. Это просто вопрос безопасности. Потому что избыточные роли могут влиять сразу на два серьёзных риска:
- Компрометация аккаунта. Если у сотрудника есть лишние роли, то в теории злоумышленник, завладевший его аккаунтом, может получить гораздо больше прав при взломе.
- Нелегитимное использование. Люди меняют команды, задачи, приоритеты — но доступы часто остаются. И кто-то может продолжать использовать их даже спустя долгое время.
Гипотетический пример: разработчик стажировался в компании и получил доступ к системе выдачи промокодов. Стажировка закончилась, его перевели в другую команду — но доступ остался. Через время разработчик попадается на несанкционированной выдаче этих промокодов. И это далеко не уникальный случай — на большом масштабе такие ситуации возникают регулярно.
Как мы подошли к решению
Начали с главного вопроса: как находить избыточные роли автоматически?
Оказалось, что 90% избыточных ролей — это просто неиспользуемые роли. Люди могут не пользоваться ими месяцами. Это и стало нашей основной гипотезой: если роль долго не используется — значит, она больше не нужна.
Чтобы подтвердить это, мы объединили два источника данных:
- Слепок текущих ролей из IDM — кто, где и когда получил доступ.
- Access-логи систем — какие действия совершались, когда и с какой ролью.
Дальше — никакой магии, а только аналитика. Мы начали сопоставлять роли и активность по ним. Если за определённый интервал времени сотрудник не использовал роль — мы помечали её как неактуальную.
Проблема в том, что у нас нет единой схемы ролевых моделей. Системы сильно различаются по структуре и логике доступов. Мы выделили три основных типа:
- Плоская модель — одна роль = фиксированный набор действий (простой кейс).
- Ролевая модель на основе атрибутов (ABAC) — роль собирается из атрибутов, которые динамически мапятся на действия.
- Иерархическая модель — доступ заказывается на сущность (например, директорию), и распространяется на все вложенные элементы. Особенно характерно для хранилищ данных.
Первое усложнение: нужно было создать универсальный процесс, который умеет работать со всеми этими моделями.
Второе — объём данных. Мы обрабатываем примерно 1 петабайт логов в день. Чтобы не грепать каждый раз весь объём, мы агрегируем данные в рамках дня или недели и храним только актуальный стейт за последние полгода. Каждый день он пересчитывается на основе свежих данных.
Как определить, что роль действительно не используется
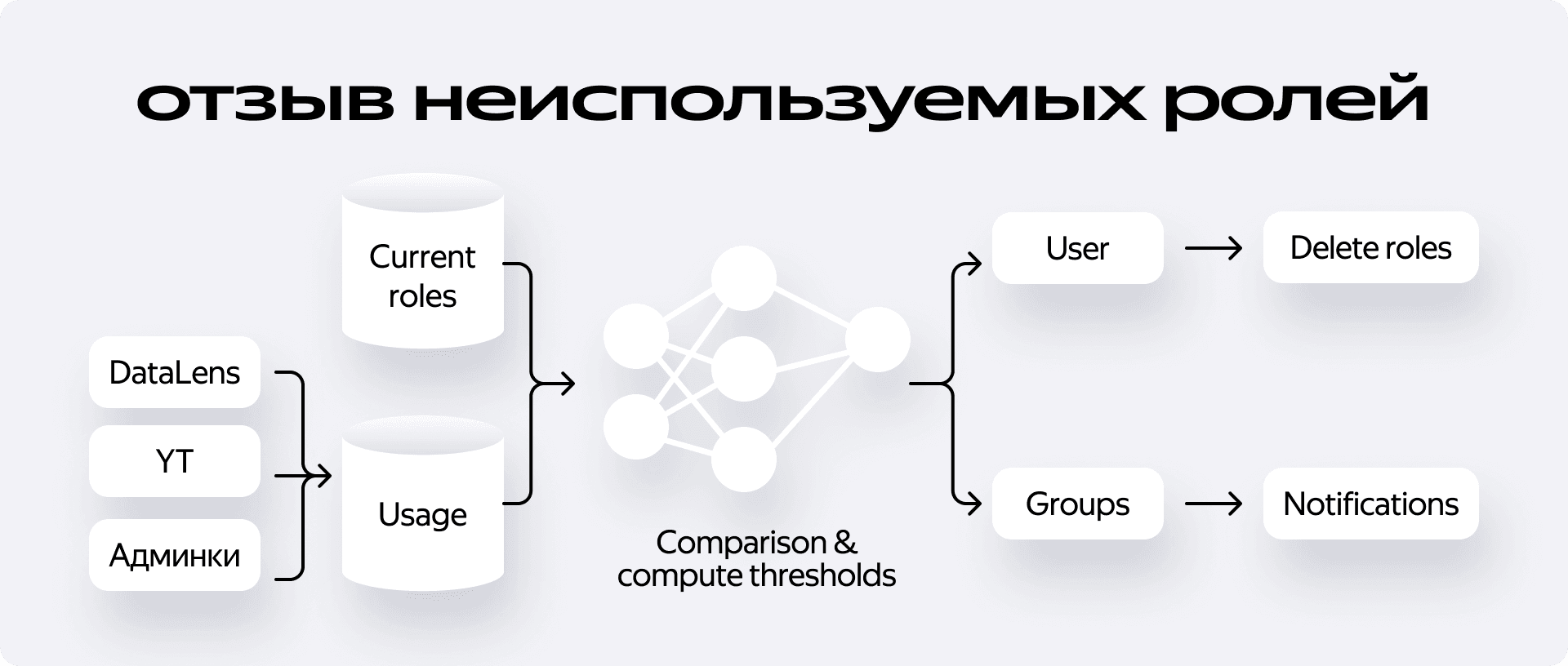
Сначала мы задали простой порог: 60 дней неактивности. Если сотрудник не использует роль дольше двух месяцев её вполне можно считать избыточной. Казалось бы, всё логично…
Но дальше начинаются нюансы:
- Сезонность. Например, сервис Самокатов в некоторых холодных регионах не работает зимой. И хотя они всё равно продолжают always on подготовку, роли могут не использоваться по объективным причинам.
- Редкие кейсы. Руководитель может заходить в дашборд раз в квартал, и мы не хотим отозвать ему этот доступ.
- Групповые роли. Если роль назначена на 200 человек, а пользуются ей только двое — это не значит, что её можно просто взять и забрать. Мы должны перезаказать её на более узкий скоуп.
Поэтому мы ушли от фиксированного срока и перешли к персонализированным порогам — для каждой роли и каждого сотрудника. Это дало гораздо больше гибкости и точности.
Что делаем с неиспользуемыми ролями
У нас есть два сценария:
- Автоматический отзыв — для персональных ролей, если уверены, что они не используются.
- Мягкое оповещение — для критичных и групповых ролей: уведомляем владельца, рекомендуем пересмотреть доступ.
К примеру, если роль используется всего двумя людьми из двухсот — логичнее выдать её только тем, кто реально работает, а не держать по дефолту у всех.
А чтобы этот процесс внятно контролировать и не наделать ошибок, мы:
- Проверяем полноту логов — если система перестала логировать, можно ошибочно подумать, что роль не используется.
- Настраиваем алерты — если вдруг хотим отозвать сотни ролей в системе, где обычно это десятки, система отправит предупреждение.
- Смотрим на перезапросы ролей — если роль отозвали, а сотрудник сразу пошёл и запрашивает её заново, это сигнал. К счастью, таких случаев — единицы.
Кроме того, мы отдельно настроили усиленные сценарии для специальных категорий. Например, если сотрудник уходит в декрет — мы сразу отзываем расширенные доступы, не дожидаясь 60 дней. Для этого интегрировали IDM с HR-системами.
Заработало ли всё это у нас?
Конечно заработало! После запуска этой автоматизации мы сразу отозвали четверть всех активных ролей в нашей бизнес-группе. И теперь каждый день система продолжает автоматически удалять десятки, а то и сотни неиспользуемых ролей. Причём без единого сломанного бизнес-процесса.
Такой подход дал нам главное — живой и непрерывный механизм реализации принципа минимальных привилегий. Не «раз в год по чек-листу», а каждый день, автоматически и точно.
От ручного онбординга к умному управлению
Решить проблему с избыточными доступами — это только половина дела. Вторая половина — это выдать нужные роли тем, кто только приходит в компанию. Или тем, кто переходит из одной команды в другую. Или тем, кто просто начинает новую задачу. Тут уже всё гораздо сложнее, потому что приходится управлять доступами в динамике.
В Городских сервисах Яндекса ротация достаточно высокая. Каждый день в компании появляются десятки новых сотрудников. Операционные команды растут, меняются, разбиваются на временные проектные группы. И каждому новичку нужно выдать роли — быстро, точно, а главное безопасно. Причём так, чтобы не перегрузить ни самих сотрудников безопасности, ни владельцев систем.
Сначала, как и у всех, наверное, у нас всё происходило вручную:
запрос роли → согласование → ожидание → выдача
Но при большом объёме людей и систем в какой-то момент это перестаёт работать. В итоге получалось, что кто-то ждал доступы сутками, а кто-то получал больше, чем нужно, просто чтобы не тормозить процессы.
Поэтому мы автоматизировали онбординг — и сделали его гранулярным.
Когда сотрудник выходит в Яндекс, он автоматически попадает в нужную группу — с заранее заданным минимальным набором доступов. Эти роли покрывают всё, что нужно на старте: инструменты для организации работы, обучающие материалы, тестовые окружения. Всё то, что не слишком критично, но точно нужно, чтобы войти в курс дела.
Дальше — по мере прохождения этапов онбординга — права расширяются:
- Сотрудник подтверждает, что ознакомился с политиками безопасности.
- Проходит нужные курсы, например, по информационной гигиене или NDA.
- Осваивает базовые процессы.
После этого мы автоматически добавляем ему новые роли. Без ручных заявок, без ожиданий, без участия менеджера или владельца системы.

Когда человек набирается опыта — происходит ещё одно расширение. Всё это мы тоже делаем автоматически и поэтапно, чтобы избежать резкого скачка привилегий. Такой подход позволяет максимально точно выдавать права в нужный момент, не раньше и не позже.
Почему такой подход работает
- Во-первых, экономим ресурсы. Раньше на выдачу ролей новичкам уходили часы работы специалистов по безопасности. Сейчас процесс идёт сам — по заранее заданным сценариям.
- Во-вторых, ускоряем запуск сотрудников. Новичок не ждёт согласований, а получает доступы в нужный момент — и сразу может включаться в работу.
- В-третьих, исключаем человеческий фактор. Ничего не забудут, ничего не перепутают, доступ не выдадут случайно «с запасом».
А ещё это позволяет проще соблюдать политики безопасности по умолчанию. Мы точно знаем, что сотрудник прошёл нужные курсы и подписал нужные документы, прежде чем получил более широкий доступ. И если он, например, не прошёл базовое обучение по ИБ — система автоматически ограничит ему доступ к критичным данным.
Мы уже масштабируем этот подход на другие кейсы. А в будущем — пойдём ещё дальше: добавим автоматическое принятие решений на основе ML-моделей, рекомендации по ролям, умный скоринг критичности и временные блокировки.
Подытожим
Управление доступами — это не только про банальный учёт ролей. Это в первую очередь про безопасность, стабильность и скорость работы всей компании. Особенно когда у тебя тысячи систем, десятки тысяч сотрудников и постоянное движение людей внутри команд.
Мы попробовали и выяснили, что можно выстроить систему, в которой принцип минимальных привилегий работает по-настоящему — непрерывно, точно и масштабируемо. Где избыточные роли отзываются не потому, что так написано в политике, а потому что система видит, что они реально не используются. Где онбординг автоматизированный и умный, и не отнимает целые дни работы у новичков и их менеджеров.
И главное — всё это не мешает обычным рабочим задачам сотрудников.
Совсем скоро Техплатформа Городских сервисов Яндекса проведёт митап о разработке. Присоединяйтесь!






