
Знаете, как обычно стартуют масштабные AI-проекты в больших компаниях? Защита роадмапа, сбор v-тима, выделение дополнительных ставок, долгие согласования. Но иногда бывает так, что по-настоящему полезный проект может начаться с обычного дружеского обсуждения.
Меня зовут Анна Кожевина, я продукт-лид в Яндекс Доставке. Моя команда отвечает за опыт пользователей при общении с поддержкой, мы развиваем админки и автоматизируем бэк-офис. Ещё у нас есть сильная техническая команда багхантеров – третья линия на стыке поддержки и разработки. И казалось бы — причём здесь вообще автоматизация для юристов?
Всё получилось случайно, практически как в кино. Я дружу с руководителем legal-команды Доставки и Такси. Как-то между делом мы разговорились о работе, и она рассказала, что их идеи по автоматизации рутины пока продолжают бороться за приоритет в бэклоге внутреннего AI-бюро и просто ждут свободного ресурса. Своей разработки, чтобы как-то ускорить этот процесс, у юристов не было.
Я слушала её и понимала — то, о чём она говорит, подозрительно похоже на наши недавние задачи. Чуть раньше багхантеры из нашей продуктовой команды собрали классные автоматизации в трекере с помощью AI-ассистента и внутреннего конструктора пайплайнов. Ребята очень вдохновились тем, какие возможности открылись с помощью новой технологии, и были очень заинтересованы сделать еще какие-то автоматизации. Получилось идеальное совпадение: у нас были инструменты и мотивация, а у юристов — большой запрос.
В этой статье я расскажу, как мы без долгих согласований и дополнительных расходов смогли освободить серьёзных профи от монотонной работы.
Кто вообще обращается к юристам Городских сервисов Яндекса и зачем?
Юридическая команда ежедневно обрабатывает огромный поток запросов от самых разных направлений бизнеса. Часть из них требует глубокой экспертизы, долгих встреч и детального анализа — в таких творческих и сложных процессах автоматизация попросту не нужна. Зато другая часть задач — это механическая работа и ответы на типовые вопросы. Именно на них мы и решили сфокусироваться. Мы разобрали типичную очередь юридических задач и выделили два массовых сценария, которые съедали больше всего ресурсов просто из-за своих объёмов.
Типовые запросы на выгрузку данных
Юристам регулярно поступают внешние запросы. Суть всегда примерно одинаковая — нужно предоставить историческую информацию по заказам с определёнными параметрами за конкретный период. Список полей для выгрузки обычно стандартизирован.
Как это работало раньше:
- Юрист брал задачу, шёл в админку и руками искал нужные заказы.
- В каждом заказе он проверял даты, время и соответствие условиям.
- Затем копировал данные, переносил их в таблицу и только после этого собирал итоговый ответ.
Сформулировать грамотный ответ — это действительно юридическая задача. А вот монотонно кликать по полям админки — точно нет.
Поскольку счёт таким задачам идёт на тысячи в год, суммарно на ручной сбор информации уходили сотни человеко-часов. Если заказов было немного, юрист искал их сам. Но когда требовалось выгрузить большой пакет данных, приходилось ставить отдельную задачу на техническую команду. Это не только замедляло процесс подготовки ответа, но и ложилось непрофильной рутинной нагрузкой на коллег из информационной безопасности.
Внутренние вопросы
Второй сценарий — ответы на вопросы в тикетах от команд внутри компании.
У ребят в Такси собрана отличная legal-база знаний. Там описано то, как работает наш сервис с точки зрения юридических схем. И чаще всего ответ на типовой вопрос уже лежит в этой документации.
Но юристу всё равно нужно взять тикет в работу, внимательно прочитать запрос, найти нужный абзац в базе знаний и направить ответ коллегам. Задача простая, но она разрывает контекст и требует времени на погружение.
Мы посмотрели на оба процесса и сделали важный вывод — большая часть решения этих задач не требует юридической экспертизы.
В Яндексе есть отдельный экспертный продукт, который помогает команде юристов — Нейроюрист. Мы начали свой проект параллельно, потому что понимали, что не конкурируем с его возможностями. Мы решали совершенно другую задачу — автоматизировать неюридическую рутину. Нам нужен был быстрый и исполнительный ассистент, который просто заберёт скучную механическую работу на себя. А у юристов освободится время на то, чтобы заниматься действительно сложными вещами, требующими их экспертизы.
Когда мы разложили проблемы по полочкам, стало понятно, что одно универсальное техническое решение тут не нужно. Для каждого из сценариев мы выбрали свой подход и свою архитектуру.
Техническая реализация AI-помощника без написания сложного кода
В нашей бизнес-группе есть Процессиум — платформа для управления бизнес-процессами. По сути, это low-code среда, где пайплайны собираются из кубиков, как в конструкторе. Техническую реализацию взяли на себя наши багхантеры — подкованные ребята из продукта. Мы договорились об одном жёстком условии: эксперименты не должны портить основные метрики работы — SLA, скорость и качество. Если всё стабильно и не вредит основным обязанностям, то можно пилить сайд-проект.
Классический пайплайн вместо нейросети
Для выгрузки заказов мы сознательно отказались от идеи «умного» агента. Когда нужно собирать чёткие параметры по конкретным поездкам, LLM-модели избыточны.
Мы разбили процесс на понятные шаги:
- Распознавание. На входе работает небольшая AI-модель с узким промптом. Юрист описывает задачу естественным языком, а микроаишка парсит текст и достаёт параметры для поиска. Её цель — перевести человекочитаемый запрос в машиночитаемый формат.
def run(features: dict):
information = features['information']
# Разбиваем текст на строки
lines = information.strip().split('\n')
# Инициализируем переменные
car_number_v2 = ""
created_from_v2 = ""
created_to_v2 = ""
driver_license_for_serch_v2 = ""
phone_v2 = ""
# Парсим каждую строку
i = 0
while i < len(lines):
line = lines[i].strip()
if line.startswith("Номер авто:"):
if ":" in line and len(line) > len("Номер авто:"):
value = line.split(":", 1)[1].strip()
elif i + 1 < len(lines):
value = lines[i + 1].strip()
else:
value = ""
# Проверяем, что значение не "Нет"
if value != "Нет":
car_number_v2 = value
elif line.startswith("Созданы от:"):
if ":" in line and len(line) > len("Созданы от:"):
date_str = line.split(":", 1)[1].strip()
elif i + 1 < len(lines):
date_str = lines[i + 1].strip()
else:
date_str = ""
# Проверяем, что значение не "Нет"
if date_str != "Нет":
created_from_v2 = date_str
elif line.startswith("Созданы до:"):
if ":" in line and len(line) > len("Созданы до:"):
date_str = line.split(":", 1)[1].strip()
elif i + 1 < len(lines):
date_str = lines[i + 1].strip()
else:
date_str = ""
# Проверяем, что значение не "Нет"
if date_str != "Нет":
created_to_v2 = date_str
elif line.startswith("Номер ВУ:"):
if ":" in line and len(line) > len("Номер ВУ:"):
value = line.split(":", 1)[1].strip()
elif i + 1 < len(lines):
value = lines[i + 1].strip()
else:
value = ""
# Проверяем, что значение не "Нет"
if value != "Нет":
driver_license_for_serch_v2 = value
elif line.startswith("Номер телефона инициатора:"):
if ":" in line and len(line) > len("Номер телефона инициатора:"):
value = line.split(":", 1)[1].strip()
elif i + 1 < len(lines):
value = lines[i + 1].strip()
else:
value = ""
# Проверяем, что значение не "Нет"
if value != "Нет":
phone_v2 = value
i += 1
return {
'car_number_v2': car_number_v2,
'created_from_v2': created_from_v2,
'created_to_v2': created_to_v2,
'driver_license_for_serch_v2': driver_license_for_serch_v2,
'phone_v2': phone_v2
}
- Сбор данных. Дальше запускается классическая автоматизация. Скрипт берёт готовые параметры, идёт в API админки, дёргает нужные ручки, находит заказы и собирает требуемые поля. ИИ на этом этапе уже не участвует — система просто идёт по жёсткому алгоритму.
- Формирование результата. Собранные данные перекладываются в итоговую табличку.
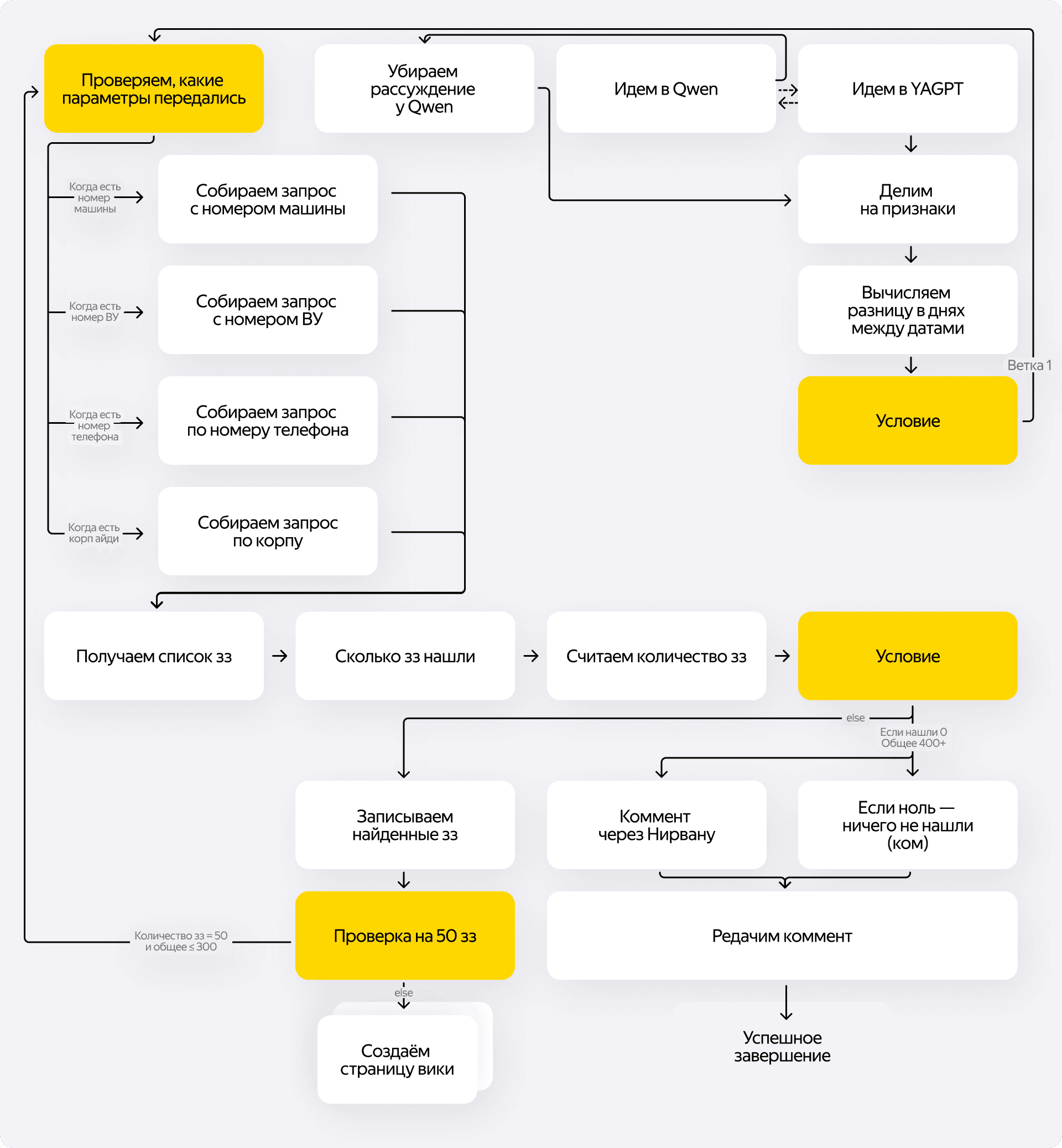
В итоге юристу достаточно вызвать робота через специальный макрос в трекере и вписать свои вводные. Дальше скрипт всё делает сам.
Безопасная генерация ответов LLM в чувствительной правовой среде
А вот для ответов по базе знаний LLM подходит отлично. Вопрос часто формулируется текстом, ответ тоже лежит в текстовой документации — системе нужно найти релевантный фрагмент и аккуратно его пересказать.
Мы построили решение на базе всё той же технологии Нейроэксперта. Обучением самой модели мы не занимались, это базовая разработка Яндекса. Нашей задачей было загрузить хорошую базу знаний и настроить триггеры в трекере.
Как работает процесс сейчас:
- Пользователь создаёт тикет в очереди юристов Такси.
- Трекер реагирует на событие и отправляет текст задачи Нейроэксперту.
- Робот приходит в комментарии к тикету и даёт рекомендацию, как можно ответить на вопрос.

Поскольку правовое направление крайне чувствительно к ошибкам, ассистент функционирует строго как ко-пилот. Он никогда не отвечает пользователям напрямую. Более того, к комментарию робота прикреплено предупреждение большими красными буквами — это текст исключительно для юриста, его нельзя использовать как готовый ответ для заказчика.
Если первоначальной рекомендации недостаточно, юрист может продолжить диалог с агентом прямо в тикете. Робот сохраняет весь контекст беседы и помогает быстро вытащить нужную информацию из документов.
Организация процесса непрерывного дообучения модели
Запустить LLM в прод — это только половина дела. Базовая модель всё равно будет иногда ошибаться или давать неполные ответы, поэтому её нужно постоянно дообучать на свежих кейсах. Сделать это без качественной разметки от самих юристов невозможно.
Поэтому мы решили собирать фидбек прямо в трекере, чтобы не заставлять людей ходить в сторонние интерфейсы. В конце каждого комментария от AI-ассистента мы встроили форму опроса. Вместо обычной бальной шкалы мы предложили юристам две простые оценки — «норм» и «стрём». Ребятам настолько зашёл этот нейминг, что с тех пор это так и прижилось в системе.

Превращение ошибок ИИ в качественный датасет для обучения
Процесс дообучения мы выстроили вокруг прозрачного и регулярного флоу.
- Сбор ошибок. Если робот даёт точную рекомендацию, юрист жмёт «норм». Если ИИ промахнулся или не учёл контекст — сотрудник выбирает «стрём».
- Еженедельное ревью. Плохие ответы не просто улетают в пустоту, они собираются в отдельный микродашборд. Раз в неделю команда юристов просматривает этот список и пишет, каким должен был быть идеальный ответ на конкретный запрос.
- Корректировка модели. Мы берём этот эталонный текст и скармливаем его системе в связке с изначальным вопросом. Модель запоминает правильный ответ и больше не ошибается в подобных сценариях.
Мониторинг активности через дашборды
Чтобы ассистент становился лучше, люди должны стабильно тратить время на разметку. Естественно, всегда найдутся те, кто попытается проигнорировать дополнительные клики.
Мы подготовились к этому заранее и собрали ещё один дашборд. Он показывает активность команды — кто регулярно размечает подсказки, а кто не участвует в обучении.
Так как лигал-команда сама очень хотела автоматизировать рутину, у них было достаточно мотивации помогать разметке. Тут всё логично: если хочешь поскорее избавиться от скучной работы, помоги роботу быстрее научиться её делать.
Главные технические сложности при внедрении AI в готовую инфраструктуру
Казалось бы, собрать пайплайн из готовых кубиков и подключить API — дело техники. Но когда работаешь на стыке ИИ, старых систем и юридических данных, неизбежно всплывают нюансы, о которых на старте даже не задумываешься.
Информационная безопасность
Официальные реквесты всегда содержат персональные данные. Поэтому первым делом мы пошли к команде безопасности. Договориться оказалось легко, потому что наши сервисы позволяют выстроить работу с персональными данными безопасно для всех участников.
Мы согласовали прозрачную архитектуру: запускать процесс может только юрист, все действия логируются, а самих данных в тикетах нет.
Тут возникла интересная проблема — как именно передать юристу собранную таблицу? Изначально мы хотели выводить результат табличкой прямо в комментарии к тикету. Но из-за особенностей трекера, даже если удалить комментарий, его текст навсегда остаётся в истории изменений. Для персональных данных такое совершенно недопустимо.
Пришлось искать обходные пути. Сначала научили скрипт создавать внутренний документ, интегрироваться с ним и удалять файл после скачивания. Но потом пришли к самому безопасному варианту — робот создаёт закрытую вики-страницу в кластере юристов. Доступ к ней есть только у legal-команды.
На этой странице лежит кнопка для скачивания файла в CSV или Excel. Как только юрист закрывает задачу, система безвозвратно удаляет вики-страницу. После этого дозапросить данные уже не получится. Такое решение мы приняли исходя из соображений безопасности. Так мы минимизируем риск доступа к чувствительной информации даже для самого юриста после завершения работы над запросом.
Пропускная способность и лимиты
Ещё уже в процессе работы выяснилось, что API нашей админки имеет лимит по таймингам. В целом не удивительно, всё таки админка создавалась для ручного использования, а не для массового парсинга.
Но вот когда мы попытались собрать информацию сразу по сотням заказов, мы упёрлись в эти лимиты. Если запросов было слишком много, скрипт просто не успевал отработать и падал. Мы буквально бинарным поиском вычисляли границу, после которой система отказывала.
На первых этапах мы предложили юристам простой воркэраунд — если вы запросили данные за неделю и робот ответил, что не успел, разбейте запрос на части и попробуйте выгрузить заказы за три дня. Но плотность поездок у разных автомобилей и водителей сильно отличается, поэтому сейчас мы учим нашу автоматизацию самостоятельно дробить один большой запрос на множество мелких и запускать их параллельно.
Борьба с галлюцинациями
Опыт создания прошлых ИИ-продуктов научил нас одной важной вещи — если скормить модели слишком большую базу знаний, она неизбежно начнёт галлюцинировать. Мы уже сталкивались с этим в нашей команде багхантеров. Например, для техподдержки, которая работает с партнёрами, пользователь — это водитель, а для тех, кто работает с потребителями пользователь — это пассажир. И если в тикете прямо не указано о ком именно идёт речь, а просто написано «пользователь приложения», модель вполне может запутаться.
Пока наш legal-помощник работает только с документацией сервиса Такси, поэтому мы обходимся одной обученной моделью. Но мы сразу заложили архитектуру под будущее масштабирование на другие сервисы.
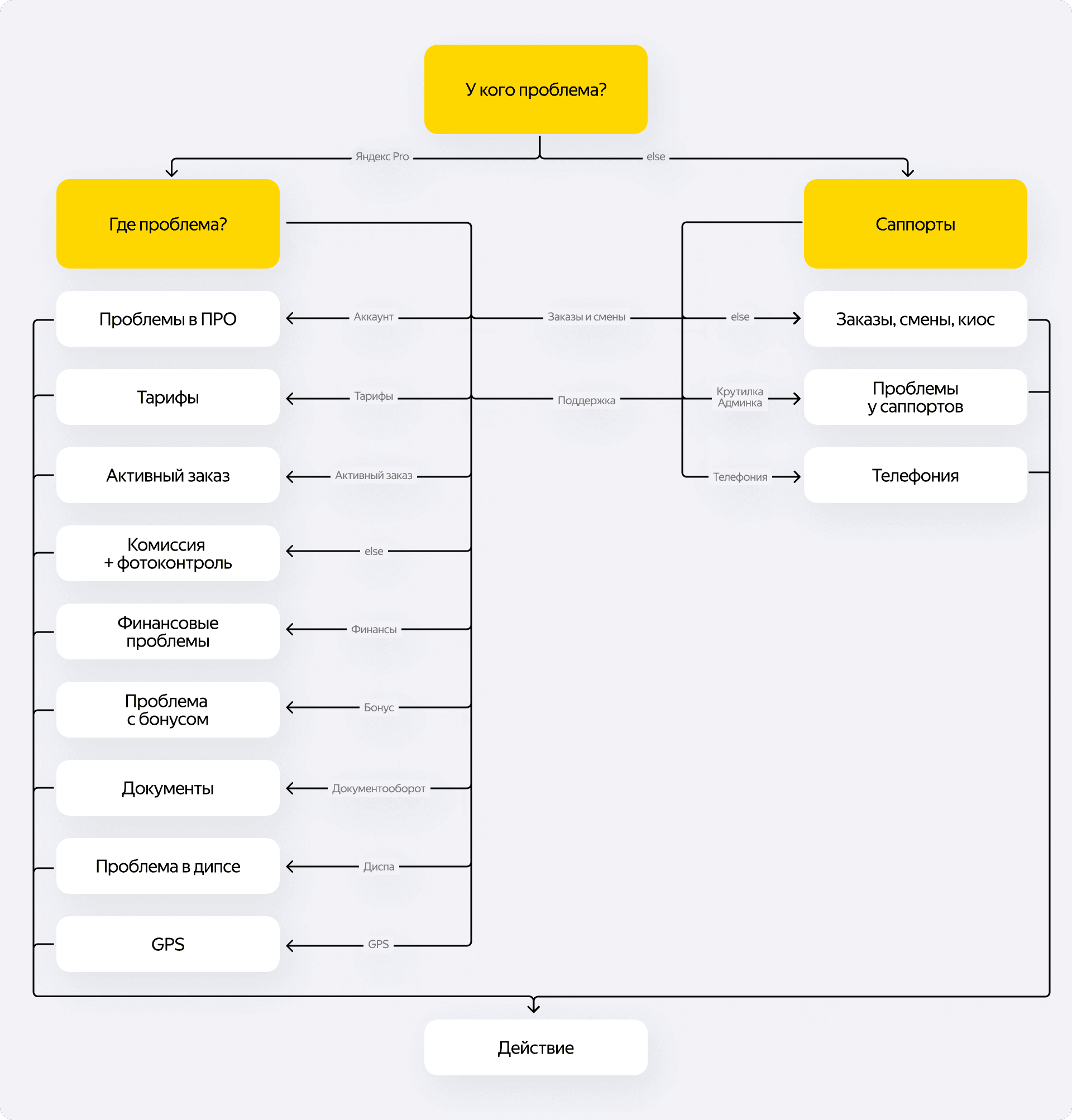
Чтобы не допустить путаницы в терминах, мы планируем разделить систему. На входе будет стоять агент-оркестратор — его задача заключается только в том, чтобы понять контекст вопроса по специальной разметке. И дальше он уже будет маршрутизировать запрос к нужному узкому эксперту — отдельной микромодели, обученной на локальной документации конкретного сервиса.
Работа с документами и обход платформенных ограничений
До определённого момента наш ассистент умел читать только текст самого тикета в трекере. Но вокруг правового отдела постоянно крутятся тонны официальной корреспонденции. В тикеты приходят отсканированные документы, судебные запросы и повестки. И если ИИ не может заглянуть в прикреплённый PDF, юристу всё равно приходится открывать файл, вручную выписывать из него номера заказов или ФИО и только потом скармливать их нашему роботу для выгрузок и автоматизаций.
Мы хотели, чтобы система сама вычитывала параметры из сканов и подставляла их в шаблон ответа. Но мы встретили платформенные ограничения — в Процессиуме еще не было модуля работы с файлами.
Мы дождались, когда команда платформы выкатит нужный модуль. Но в его первой версии была одна особенность — лимит на размер файла для чтения в 3 мегабайта. Для большинства отсканированных PDF документов такого объёма было просто недостаточно. Поэтому нам пришлось искать обходной путь.
Тогда наши ребята сели разбираться в вопросе сами и в итоге нашли обходной путь. Они придумали схему, при которой скрипт скачивает файл, распознаёт текст прямо на лету и нигде его не сохраняет. Сейчас мы пошли ещё дальше: ассистент не только читает входящие документы, но и помогает формировать готовые заполненные шаблоны ответов. Юристу остаётся только проверить и отправить документ.
Автоматическое связывание тикетов
Возможность читать файлы моментально расширила пул задач, до которых мы могли дотянуться. Одной из частых задач для ассистентов правового отдела была работа с документами по судебным делам.
Яндекс участвует в десятках судов ежемесячно. По каждому делу постоянно приходят новые бумажки. Раньше процесс выглядел так:
- Ассистент видел новый документ по суду.
- Он копировал номер дела и шёл в отдельную очередь судов в трекере.
- Искал, есть ли уже заведённый тикет по этому разбирательству.
- Если тикет был — ассистент закрывал новую задачу, скачивал вложения и руками перекладывал их в оригинальный тикет. Если старого тикета не было — оставлял всё как есть.
Сейчас мы переложили эту монотонную работу на алгоритмы. Сотруднику достаточно скопировать номер дела и название суда, вставить их в готовый макрос и вызвать робота. Дальше скрипт сам идёт по всем очередям, ищет совпадения, закрывает дубли, скачивает аттачи и аккуратно перекладывает их в нужную задачу.
Ну а теперь, раз уж мы наконец-то научились распознавать файлы, наши ребята уже учат модель самостоятельно заглядывать в PDF, находить там номер дела и название суда и без участия человека запускать всю цепочку по связыванию тикетов. Юристу останется только посмотреть на результат и кивнуть.
Реальная продуктовая польза автоматизации в цифрах и метриках
Следующий резонный вопрос, который у нас возник: а как измерить пользу от всего того, что мы сделали? Провести классическое A/B-тестирование мы не могли. Поскольку я и моя команда занимаемся основным продуктом поддержки, мы отлично знаем это по своему опыту: тесты на людях в операционке не работают точно. Ты не можешь заставить человека в одном тикете призывать робота, а в другом принципиально искать всё руками. Кроме того, SLA в трекере тоже не показатель. Сотрудник может открыть задачу, начать собирать инфу и только потом назначить тикет на себя.
Но, поскольку мы точно знаем объём инбокса по каждому типу задач, мы решили пойти по пути расчётных оценок.
- Официальные запросы. Раньше на сбор данных для одного реквеста уходило 15 минут ручной работы. Важно заметить, что это примерное допущение, а не строго высчитанное среднее значение, но порядок цифр именно такой. Сейчас юрист тратит около 3 минут — в основном на то, чтобы вписать параметры в макрос, подождать пару минут и забрать результат. Кроме того, теперь для подготовки больших выгрузок заказов не требуется запуск отдельного сложного процесса и привлечение коллег из СИБ. С учётом того, что в год приходит больше 1000 таких запросов, автоматизация экономит нам порядка 80 рабочих дней юриста. Это треть годовой ставки специалиста.
- Работа с судебными тикетами. Для ассистентов время обработки одного документа сократилось с нескольких минут буквально до одной. В пересчёте на поток задач это экономит около 50 часов в месяц.
- Чтение файлов. Здесь оценка сильно плавает в зависимости от типа задачи. Какие-то скрипты экономят 30 часов в год, а какие-то — 30 часов в месяц.
Означает ли это, что после всех оптимизаций лигал-команда уменьшится? Совсем не обязательно. Бизнес постоянно масштабируется, количество задач растёт, и мы просто позволяем командам повысить их производительность.
Нас не уволят, мы просто возглавим автоматизацию
Наши юристы — очень диджитал-ориентированные ребята, развёрнутые к бизнесу. Когда мы пришли на общую встречу legal-команды и показали, как в один клик собирается реквест, они были в восторге. Ребята, работающие с реквестами и другими рутинными задачами, сами тестировали макросы и писали ТЗ на доработки. Ассистенты, увидев робота в действии, сами начали приходить с идеями: «Слушайте, у нас тоже есть много шаблонных задач с четкими инструкциями, давайте обсудим, можно ли это автоматизировать?».
Они говорили нам: «Мы просто не знали, что всё это можно настолько улучшить, и просто делали свои задачи». Они искренне рады избавиться от рутины, потому что у них всегда есть сложные, творческие задачи.
Главный продуктовый инсайт
Всё, что мы собрали и протестировали, пока работает на базе Такси и Доставки. Но схожие задачи и процессы есть и у других сервисов. Поэтому следующий шаг — масштабировать наши пайплайны на другие legal-команды.
Мы изначально проектировали архитектуру с таким заделом. Если у соседнего направления есть подробная база знаний и понятная документация по API админки, запустить автоматизацию можно довольно быстро — вплоть до копирования готовых триггеров в их очереди. У нас уже запланированы встречи, чтобы показать коллегам, как это работает, и перенести наш опыт на их процессы.
Конечно, всё это было бы невозможно без лоу-код платформы, которую вовремя выкатили наши коллеги из Техплатформы Городских сервисов Яндекса. Самое большое спасибо – Мише Нечаеву, Кириллу Хилажеву и Саше Александрову из моей команды и его команде багхантеров. Ребята проделали невероятную работу, очень многое раскопали и не меньше вещей реализовали впервые, мне крайне приятно работать с такой заряженной на результат командой!
Но главная продуктовая мысль, которую я вынесла из этого кейса, лежит за пределами технологий.
Иногда самый полезный проект может находиться за пределами вашей формальной зоны ответственности. Он живёт в соседней команде и выглядит просто как чужая операционная проблема. И если вы руководите продуктом, разработкой или аналитикой, вам полезно не только рассказывать о своих результатах, но и внимательно слушать коллег. Часто они даже не подозревают, что ваш опыт можно переиспользовать и применить у себя.



