
В мобильной разработке Яндекс Go мы давно используем DivKit — он позволяет доставлять экраны по сети, без апдейта приложения. Это удобно. Но у этого подхода есть оборотная сторона: экраны приходилось постоянно верстать. Много. Рутинно. Вручную.
На один экран вполне могло уйти от пары часов до нескольких дней. Даже если у тебя уже есть дизайн в Figma. Даже если у тебя есть Kotlin DSL, на котором можно писать в духе Jetpack Compose. Даже если у тебя есть мощная дизайн-система. Всё равно ты сидишь и руками переносишь нарисованное из макета в код.

В какой-то момент стало очевидно: так дальше продолжать нельзя. Нужно ускоряться. И у нас появилась гипотеза — а что если начать использовать LLM для того, чтобы автоматизировать этот процесс? Причём не просто в стиле «сгенерируй мне что-то похожее», а чтобы сразу получить код, близкий к продакшену, который компилируется и соответствует нашей дизайн-системе.
Всем привет, меня зовут Ярослав Атрошенко, я разработчик в Яндекс Go. В этой статье я расскажу, как мы прошли путь от наивной генерации по Figma JSON до полноценного template-based воркфлоу. Почему отказались от популярных решений вроде agent IDE и RAG и как придумали свою YAML-нотацию.
Почему нельзя просто скормить LLM макет из Figma
Наш первый подход был предельно простым и, как оказалось, очень наивным. Мы решили действовать в лоб: взяли JSON-файл, который отдаёт Figma API, и просто скормили его модели с запросом «сверстай нам этот экран на DivKit».
Как вы понимаете, ничего хорошего из этой затеи не получилось и вот почему.
-
Во-первых, LLM понятия не имела, что такое наш внутренний фреймворк DivKit и уж тем более — наша собственная дизайн-система, которую мы между собой для удобства называем UiKit. Для модели это был неизвестный язык, на котором она разговаривать не умела.
-
Во-вторых, даже если бы мы захотели её научить, мы бы столкнулись с жёстким техническим ограничением. Figma JSON — это монструозная структура, которая даже для не самых сложных экранов может занимать десятки тысяч строк. К этому нужно было бы добавить документацию по DivKit и UiKit. По нашим подсчётам, суммарный объем такого промпта легко переваливал за 400 тысяч токенов, в то время как контекстное окно доступных нам моделей было ограничено примерно 200 тысячами. Мы просто физически не могли поместить всю необходимую информацию в один запрос.

Справедливости ради, саму проблему гигантского размера Figma JSON мы в итоге решили. Вдохновившись существующими алгоритмами, мы внедрили собственный процесс сжатия: он парсит ответ от API, выносит все повторяющиеся компоненты в глобальные переменные и удаляет пустые поля. Но здесь нас ждал важный инсайт: просто отдать модели сжатый JSON нельзя. Без объяснения правил, по которым мы изменили структуру, LLM воспринимала оптимизированный файл даже хуже, чем громоздкий оригинал. Это ещё раз подтвердило, что контекст и правила игры для модели важнее чистоты входных данных.
Немного подумав, мы решили, что логичнее будет не скармливать модели всю документацию целиком, а просто дать к ней доступ. В то время мы, как и многие, активно экспериментировали с Agent IDE вроде Cursor. Это и стало нашим вторым шагом. Мы взяли всю документацию по DivKit и нашей дизайн-системе, разбили её на множество небольших файлов в формате Markdown и назвали эту базу знаний Memory Bank.
Процесс выглядел уже интереснее. Разработчик писал в IDE промпт, в котором обращался к этому Memory Bank и давал ссылку на макет в Figma. Что-то вроде: «Используя @/memory_bank, реализуй вот этот экран: [ссылка]».
И вы не поверите, но это начало работать! Мы впервые стали получать на выходе код, который был приблизительно похож на то, что нам нужно. Но вместе с первым успехом пришла новая, куда более хитрая проблема. Agent IDE — это настоящий чёрный ящик. Мы давали ему на вход базу знаний, но понятия не имели, какие именно её фрагменты он решит прочитать и использовать для генерации ответа.
Первый успех с Agent IDE принёс и первую фундаментальную проблему: нельзя построить надёжный инструмент, если сам не понимаешь, почему он ошибается.
Из-за этого улучшать качество было практически невозможно. Что делать, если код компилируется с ошибкой? Как понять из-за чего именно это произошло: потому что модель не нашла нужный фрагмент документации, нашла не тот или просто неверно его интерпретировала? Однозначно ответить на эти вопросы было невозможно, а без этих ответов мы не могли двигаться дальше. В итоге у нас получился сносно работающий прототип, но совершенно бесконтрольный. Нам нужен был собственный, полностью управляемый воркфлоу.
Собираем конвейер с компилятором и циклом обратной связи
Чтобы двигаться дальше, мы для начала сформулировали чёткие требования к собственному решению: это должен быть программный воркфлоу, который на входе получает Figma JSON, самостоятельно извлекает релевантный контекст из документации по DivKit и нашему UiKit, а затем на основе этих данных генерирует готовый код.
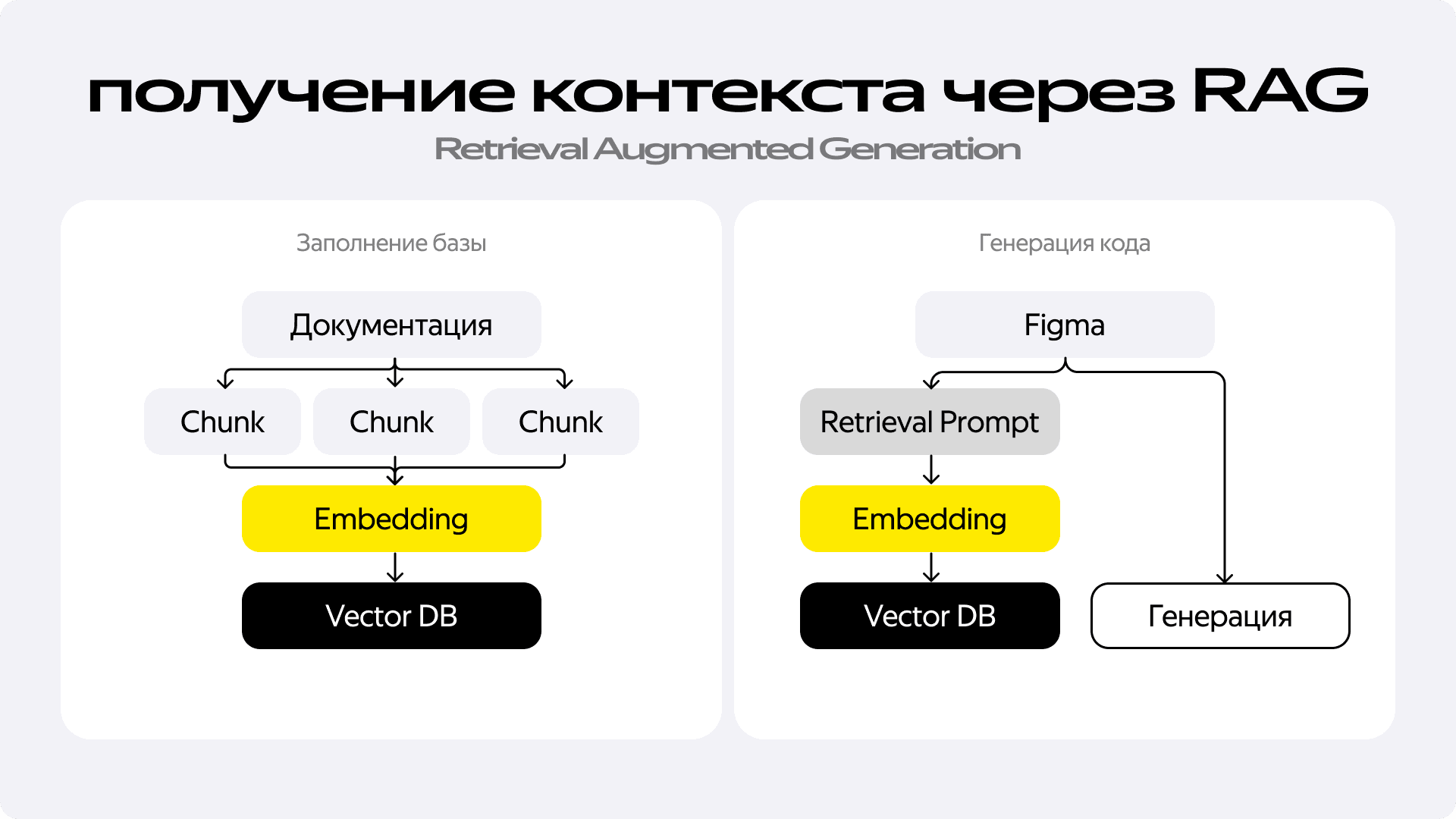
На новом этапе ключевой технологией для решения такой задачи стал RAG — Retrieval-Augmented Generation. Если не вдаваться в детали, его суть проста и элегантна. Сначала мы готовим нашу базу знаний: берём всю документацию и нарезаем её на небольшие логические фрагменты — чанки. Каждый чанк мы пропускаем через специальную embedding-модель, которая превращает текст в вектор — набор чисел, отражающий его семантический смысл. Все эти векторы мы складываем в векторную базу данных. Теперь, когда нам нужно получить контекст для генерации, мы формируем поисковый запрос, тоже превращаем его в вектор и ищем в базе наиболее близкие по смыслу векторы. Так мы находим именно те фрагменты документации, которые нужны для решения конкретной задачи, а не пытаемся запихнуть в модель всё подряд.
Вооружившись этим подходом и инструментами вроде LangChain, мы начали собирать наш воркфлоу шаг за шагом.
-
Шаг 1: чистый RAG. Первая версия была прямолинейной: берём Figma JSON, используем его для поиска релевантной информации в двух RAG-базах — одна для DivKit, вторая для UiKit, и отправляем всё это модели для генерации кода. И это сработало — мы больше не зависели от Agent IDE и получали код, который был очень близок к цели. Но у него всё ещё оставались серьёзные недостатки: он был плохо структурирован, а главное — почти никогда не компилировался с первого раза.
-
Шаг 2: автоматизация проверки. Мы добавили в воркфлоу этап, на котором сгенерированный код отправлялся на проверку Kotlin-компилятору. Если компиляция была неудачной, мы отправляли текст ошибки обратно LLM с просьбой всё исправить. Качество заметно выросло: модель неплохо исправляла собственные ошибки. Но это породило две новые проблемы. Во-первых, процесс стал значительно медленнее из-за дополнительных циклов генерации. Во-вторых, даже для LLM ошибки компилятора не всегда очевидны. Представьте, что модель неправильно использовала один из десятков параметров в сложной функции — ответ компилятора может быть настолько громоздким, что модели сложно понять, где именно она ошиблась.
-
Шаг 3: учим модель рассуждать. Впрочем, проблема была не только в синтаксисе, но и в логике. Чтобы улучшить структуру кода и позиционирование элементов, мы добавили предварительный этап рассуждения. Перед генерацией кода мы просили модель проанализировать макет и составить план в виде bullet-point’ов: из каких компонентов состоит экран, как они расположены друг относительно друга, какие параметры могут понадобиться. Этот план затем передавался на этап генерации. Код действительно стал лучше структурирован, а модель начала точнее понимать взаимное расположение элементов. Но за это пришлось заплатить скоростью — воркфлоу стал ещё медленнее.
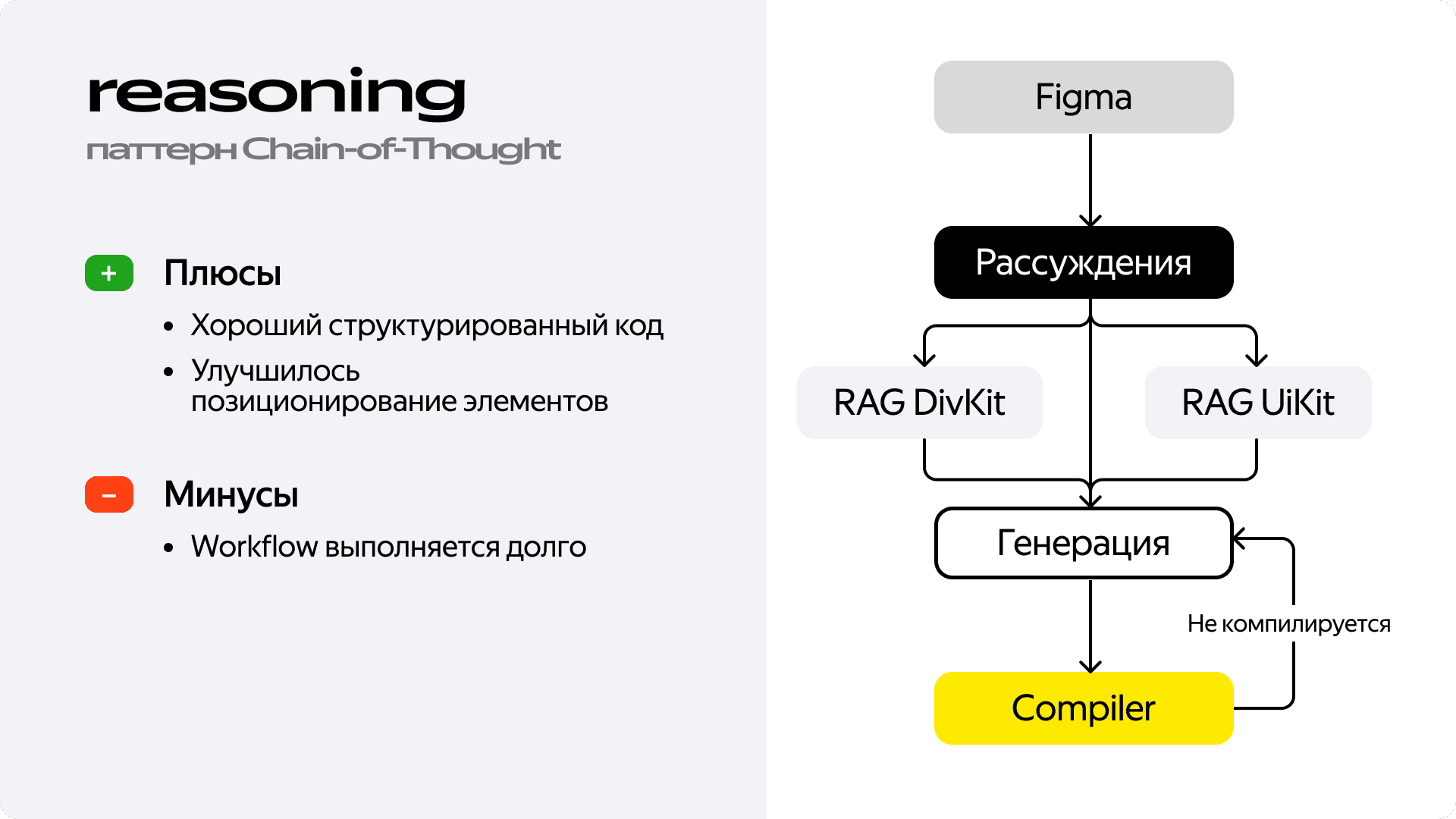
В итоге мы пришли к довольно сложной, многошаговой системе. Она работала и работала достаточно неплохо, но мы упёрлись в потолок. Качество было близко к тому, что нам нужно, но всё равно требовало ручной доработки. А 100% компилируемости мы так и не добились. Но главное — скорость генерации была слишком низкой из-за большого количества запросов к модели. И тут мы поняли, что оказались в тупике: дальнейшее усложнение воркфлоу давало все меньше значимого результата. Стало ясно, что нужно не улучшать старый подход, а искать принципиально новый.
Каждое улучшение качества в нашем RAG-воркфлоу мы оплачивали скоростью. И закономерно оказались в точке, где дальнейшее усложнение системы уже не давало соразмерного результата в качестве.
Переосмыслить всё
Интересно, что пока мы бились над усовершенствованием нашего RAG-воркфлоу, индустрия технологий не стояла на месте. Как раз в то время Google показала демонстрацию, где Gemini на лету генерировал интерфейс в ответ на действия пользователя. И глядя на это, мы поймали себя на мысли: вряд ли модель в реальном времени пишет и компилирует конечный программный код. Скорее всего, она оперирует более высокоуровневыми, заранее описанными блоками.
Именно эта мысль стала нашим ключевым инсайтом, который заставил нас полностью изменить подход к решению задачи. Зачем заставлять LLM генерировать сложный программный код, если для сборки интерфейса это совсем не обязательно? Генерировать Kotlin DSL со всеми его нюансами — строгой типизацией, импортами, сложными сигнатурами функций — невероятно трудная задача для модели. Она постоянно натыкалась на эти синтаксические ловушки, и мы тратили ресурсы на то, чтобы помочь ей их обойти.
Мы поняли, что заставляем LLM быть идеальным компилятором, тогда как её истинная сила — быть креативным архитектором. Мы просто дали ей эту возможность.
Новое решение, которое мы назвали Template-based Generation, состояло из двух ключевых частей.
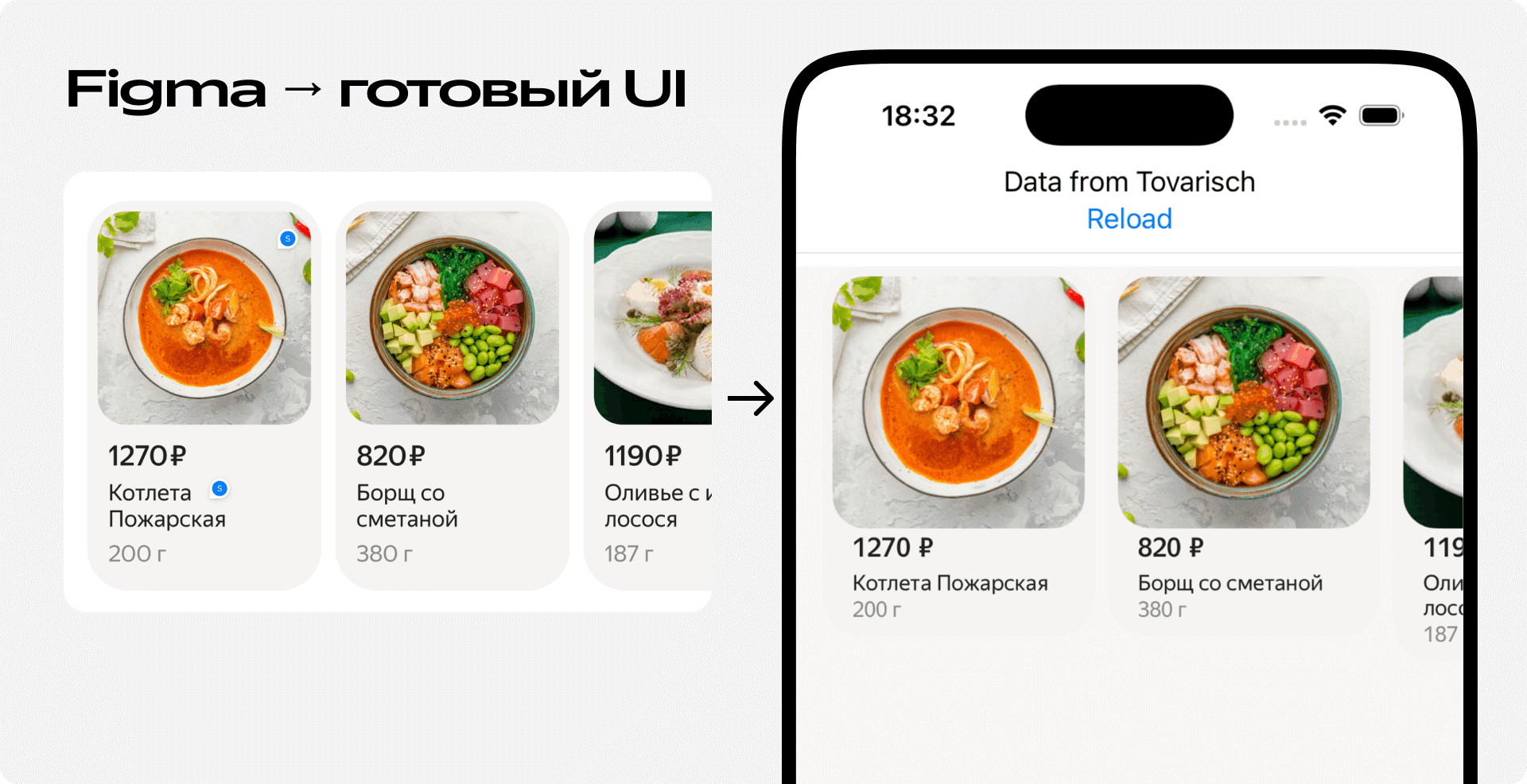
- Промежуточный язык описания. Вместо того чтобы генерировать Kotlin, мы попросили модель генерировать описание интерфейса на простом, но выразительном языке, который мы сами для себя разработали на основе YAML. Эта нотация описывала только суть: какие компоненты использовать, в какой иерархии они находятся и какими параметрами обладают. Вся сложность реального синтаксиса, типов и импортов была скрыта от модели. Её задача сводилась только лишь к генерации простой и понятной структуры данных.
- Детерминированный транслятор. Вторую часть работы мы взяли на себя. Мы написали транслятор — программу, которая берёт на вход этот YAML-шаблон и гарантированно, без ошибок, преобразует его в валидный, компилируемый Kotlin-код на DivKit. Этот компонент — полностью детерминированный, в нём нет никакой магии LLM и никаких чёрных ящиков.

Вишенкой на торте стали красивые ошибки. Если LLM все-таки ошибалась в YAML-структуре — например, использовала некорректное значение для поля orientation или передавала строку вместо числа, — наш транслятор генерировал чёткое и понятное сообщение об ошибке, которое мы отправляли обратно модели. Вместо простыни логов от компилятора она получала прямое указание: «Ты вот тут ошиблась, значение VERTICAL невалидно. Используй одно из этих: vertical, horizontal, overlap».
Этот подход одним махом решил все наши ключевые проблемы. Сложный и медленный RAG-воркфлоу с несколькими обращениями к модели оказался попросту не нужен. Вся генерация теперь умещалась в один промт. Мы получили 100% надёжность, ведь транслятор всегда выдавал компилируемый код, а любые ошибки в шаблоне исправлялись за один дополнительный запрос. И, конечно, скорость всего процесса выросла в разы. В результате мы смогли себе позволить перестать бороться с синтаксисом и сосредоточились на сути — описании интерфейса.

Чему нас научил этот путь и куда он ведёт теперь
В итоге задача, которая раньше отнимала у разработчика дни, а порой и недели, превратилась в процесс, занимающий от силы несколько часов: пара минут на генерацию основы и несколько часов на доработку деталей до merge-ready состояния. Но главный вывод, который мы для себя сделали, заключается не в выборе конкретной модели или фреймворка. Он в самом подходе к решению задачи.
Весь наш долгий и тернистый путь к конечному результату наглядно показывает эволюцию мысли. Мы начали с простых, но неконтролируемых решений вроде Agent IDE. Затем построили сложный, но все ещё неидеальный RAG-воркфлоу, пытаясь научить модель быть идеальным программистом. И только в конце пришли к самому эффективному, хоть и более сложному в реализации, подходу — перестали заставлять LLM делать то, что ей несвойственно. Мы разделили задачи: творческую и высокоуровневую отдали модели, а рутинную, требующую абсолютной точности, — детерминированному коду.
Теперь, когда у нас есть надёжный фундамент, мы видим три ключевых направления для развития:
- Генерировать не только вёрстку, но и поведение. Наш подход позволяет легко добавлять в экраны логику и получение данных из внешних источников, двигаясь в сторону полностью автономных экранов.
- Двигаться в обратную сторону: от текста к Figma. Раз у нас есть простой язык описания интерфейсов, ничто не мешает использовать его для генерации не кода, а самих макетов в Figma. Это дало бы дизайнерам возможность вайбкодить интерфейсы, описывая их текстом.
- Создать единый язык описания интерфейсов. Это самая глобальная цель — прийти к общей нотации, понятной и дизайнеру, и разработчику, и LLM. Такой язык мог бы стать эдаким мостом, который окончательно устранит разрыв между дизайном и кодом.
Эксперимент, о котором я рассказал — не какая-то законченная история, а лишь один из шагов в нужном направлении. Но уже сейчас он явно показывает, что LLM — это мощный партнёр разработчика, способный взять на себя целый пласт творческой, но рутинной работы, если правильно определить для неё задачу.



