
Всем привет! Меня зовут Михаил, я бэкенд-разработчик в команде курьерского продукта Яндекс Еды.
Люди — социальные существа, и нам всегда хочется общаться и чувствовать принадлежность к группе. Классическая занятость часто предоставляет такие условия. Например, в офисе вы с коллегами сидите в одном кабинете, вместе ходите на обед, а после смены можете собраться в CS на пару каток. Постоянное общение укрепляет связи, растит производительность и круто снижает стресс.
И даже когда многие форматы работы перешли на удалёнку, потребность в команде никуда не исчезла — мы просто перенесли наши офисные кухни в мессенджеры и видеозвонки, чтобы обсуждать наболевшее. Главное, что мы всё равно находимся в постоянной коммуникации и можем помогать друг другу.
А теперь представьте формат занятости, где постоянного коллектива у вас просто нет. Как у курьеров, например. Вы выбираете удобный слот, выходите на улицу, и дальше есть только вы, верный байк, термосумка и наше приложение ПРО с очередным заказом.
Хотя тут нужно сделать оговорку — не все исполнители работают в таком вакууме. Если доставлять заказы из даркстора — например, в Яндекс Лавке — то слот привязан к конкретной точке. Ребята катаются от склада до клиента и обратно, пересекаются на базе, образуют своё локальное сообщество. В промежутках между заказами они могут делиться советами и обсуждать, кто сколько доставил и заработал. А вот у курьеров Еды всё иначе — они доставляют заказы по всему городу и редко привязываются к одной точке.
Мы уже предпринимали попытки решить проблему одиночества, создавая городские общалки в мессенджерах. Отчасти это помогало, но когда в чате собирается тысяча и больше человек — он уже не чувствуется уютным и ламповым. Кроме того, мы регулярно проводим опросы среди исполнителей Еды и Лавки, чтобы понять их боли и критерии выбора сервиса. И там периодически всплывала тема комьюнити. Люди примерно так и писали — вот в Лавке есть мои братишки, а в Еде я сам по себе. Кроме того, новичкам часто не хватает прозрачных ориентиров. Им сложно понять, сколько вообще можно доставить заказов за день, какой тип передвижения самый выгодный и где лучше выходить на слоты.
Так весной 2025 года мы решили сделать большую социальную фичу — Публичный профиль курьера. Раздел внутри приложения, где можно добавлять других курьеров в друзья, следить за их прогрессом на сервисе, смотреть на достижения лидеров рейтинга — тех самых курьеров, которые доставляют больше всего заказов в городе, — и перенимать их фишки.
Сегодня я расскажу, как мы превращали эту продуктовую задумку в работающий сервис. Вы узнаете, почему для объединения профилей мы не смогли использовать исторические ID курьеров — ведь в одном приложении работают исполнители из разных сервисов, каждый со своими форматами данных, и нам пришлось их связывать. Я покажу, как мы собирали статистику заказов и достижений из множества смежных внутренних микросервисов Яндекса, балансируя между моментальной загрузкой экрана и возможными таймаутами, чтобы избежать любых падений. И, конечно, поговорим про обновление гигантских лидербордов — как пересчитывать рейтинг десятков тысяч человек и заливать его в базу частями, чтобы избежать одной огромной транзакции, которая теоретически могла бы намертво заблокировать работу всей системы.
Архитектура с прицелом на переиспользование
Как только менеджеры принесли идею публичного профиля, начались долгие раунды встреч и обсуждений. Сразу стало понятно, что разработка намечается масштабная, поэтому мы решили пилить проект на части и запускать его итеративно.
Разумеется, мы не могли просто взять и сделать статистику всех исполнителей открытой по умолчанию — безопасность личных данных стоит на первом месте. Ведь комьюнити — дело добровольное: кто-то хочет соревноваться со всем городом, кто-то готов делиться успехами только с близкими друзьями, а кому-то уютнее вообще ни с кем не общаться.
В итоге, исходя из строгой модели приватности, мы выделили три состояния видимости профиля:
- Анонимный профиль — стартовое состояние. Никакая информация о человеке никому не показывается, а во всех топах он абсолютно обезличен.
- Открытый профиль — полностью открытый профиль, где все могут просматривать доступную статистику курьера.
- Закрытый профиль — ведёт себя аналогично открытому, но показывает данные только подтверждённым друзьям.
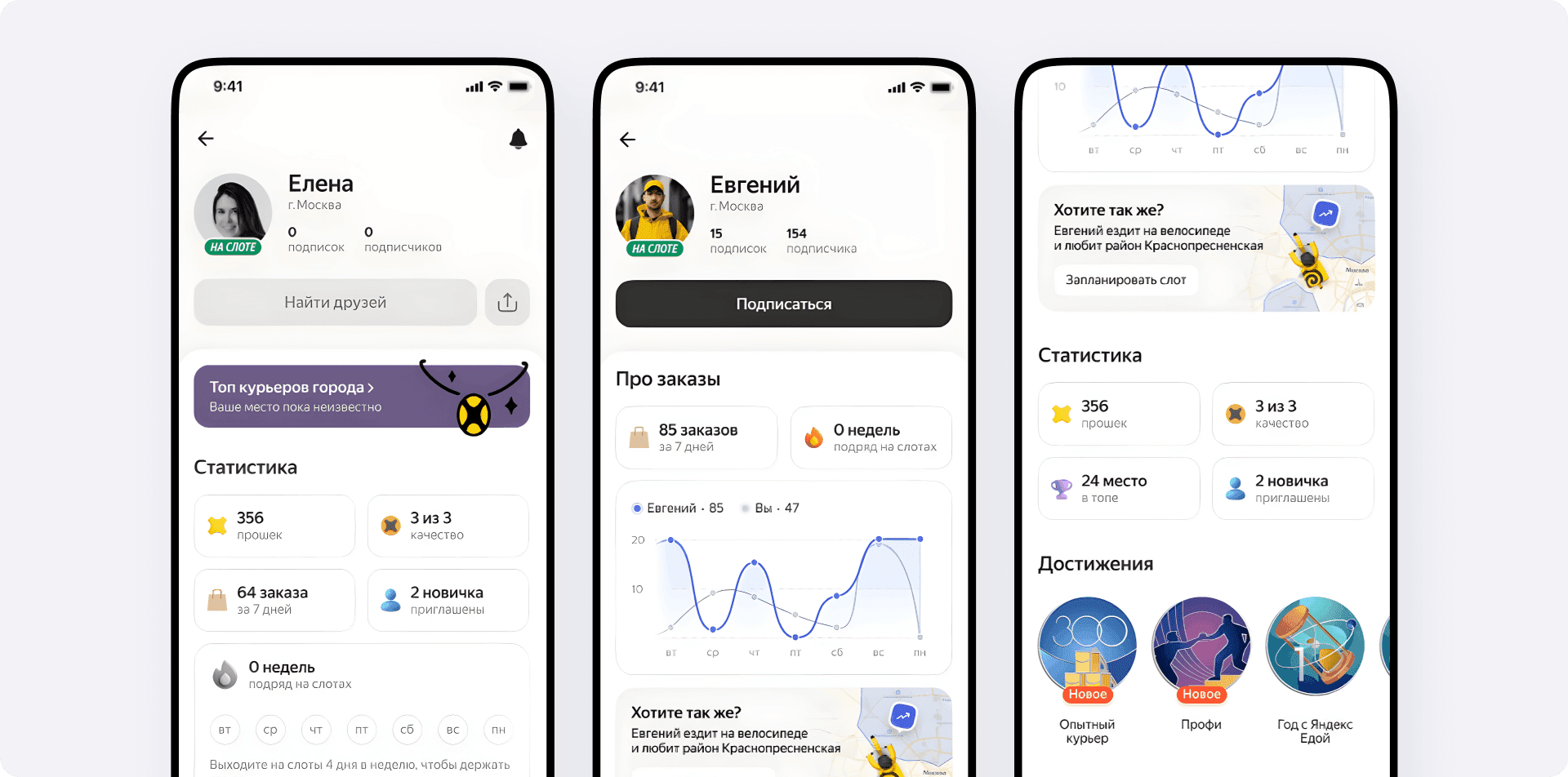
Сама механика дружбы строится на взаимной подписке. Исполнители могут шарить ссылку на свой профиль или искать друзей по нику в Телеграме. Само собой поиск работает строго с учётом выбранного уровня приватности. Если человек перевёл свой профиль в закрытый или анонимный режим, найти его через поисковую строку уже не получится.
Казалось бы, довольно простая и понятная схема, но чтобы всё это заработало на бэкенде, нам пришлось решить сразу несколько серьёзных архитектурных задач.
Проблема разных идентификаторов
Ещё перед стартом разработки мы пошли к соседним бизнес-юнитам Городских сервисов Яндекса и спросили, насколько им была бы интересна такая фича. Сразу заезжать в неё тогда никто не решился, но определённый интерес был. Коллеги сказали, что посмотрят на метрики после запуска и, возможно, после этого захотят добавить профили и к себе. Поэтому мы сразу решили, что ядро сервиса нужно проектировать так, чтобы логику можно было легко переиспользовать.
Вся архитектура для исполнителей из разных бизнес-юнитов у нас функционируют внутри одного приложения Яндекс Про. И по идее у них должны быть единые идентификаторы пользователей.
Так исторически сложилось, что разные сервисы у нас имеют под капотом совершенно разную технологическую базу и логику работы с профилями. Еда и Лавка развивались и масштабировались по-своему, поэтому у каждого бизнеса со временем сформировались свои уникальные форматы внешних айдишников.
Внутренний маппинг профилей и подписок
Завязывать архитектуру социальной сети на конкретный формат ID было нельзя. А когда в системе уже исторически сложился целый зоопарк разных идентификаторов, какое решение напрашивается первым? Правильно — добавить ещё один.
Поэтому мы пошли по пути внутреннего маппинга. Мы создали таблицу, которая связывает внешний идентификатор исполнителя из конкретного бизнес-юнита с нашим собственным, внутренним ID публичного профиля. Именно к этому новому идентификатору мы сразу привязали настройки приватности, которые курьер меняет в приложении. Дальше все операции внутри нашего сервиса производятся только по этой внутренней сущности.

Связи между пользователями реализовали достаточно просто — через таблицу подписок. В ней лежат айдишники:
- того, кто подписывается;
- на кого подписываются;
- специальный флаг подтверждения принятия запроса.
Обратная такая же запись с принятым запросом образует полноценную связь друзей.
Такая схема отлично подходит для нашего случая. Счёт записей идёт на тысячи, и база данных по нужным индексам вытаскивает информацию за вполне адекватное время без лишней нагрузки. Ручки простановки и получения этих связей получились максимально простыми, поэтому детально на них останавливаться нет смысла.
Собираем тяжёлые данные
После того как ядро публичного профиля было готово — можно было выводить статистику и показывать её курьерам. Но тут возникла новая проблема — откуда брать эти данные так, чтобы главная страница не грузилась вечность.
Обычно статистика курьера в рантайме никому не нужна. Все исторические данные выгружаются в медленное аналитическое хранилище YT. Для аналитики это работает отлично, но для главной страницы профиля такие задержки недопустимы, потому что экран должен открываться моментально.
На этот раз мы пошли к соседним командам узнавать, есть ли у них нужная информация в горячем доступе. Оказалось — есть. Соседние микросервисы смогли отдавать нам количество доставленных заказов и показатели исполнителя во внутренней системе мотивации.
А вот с рефералами возникла сложность. Данные по приглашённым курьерам всё-таки пришлось выгружать из медленного YT, но мы переложили их в базу данных специального сервиса статистики. Уже оттуда мы забираем информацию на лету.
Асинхронность и отказоустойчивость
Главная страница собирает много данных из разных систем. У нас было два пути. Первый — загружать базовую информацию одним быстрым запросом, чтобы клиент хоть что-то отрисовал, а остальное подтягивать частями. Второй — отдавать всю страницу целиком, дождавшись загрузки всех данных.
Нам очень не хотелось плодить лоадеры и лишние моргания интерфейса на главном экране. Мы выбрали второй вариант, но чтобы минимизировать время простоя, запускаем асинхронные запросы ко всем источникам данных одновременно.

При такой схеме очень важно помнить про отказоустойчивость. Мы разделили все источники на критичные и некритичные:
- критичный источник упал (например, базовый профиль исполнителя) — сервис честно возвращает ошибку;
- некритичный источник отвалился по таймауту — мы просто опускаем проблемный блок в ответе, и пользователь продолжает пользоваться разделом.
Подход с параллельными запросами может легко сломаться о несогласованные таймауты разных клиентов. Если мы ждём первый сервис 500 миллисекунд, а второй — 300 миллисекунд, то при проблемах на бэкендах соседей время ответа нашей ручки деградирует до худшего значения из всех. За этим моментом нужно строго следить, иначе весь выигрыш от асинхронности сойдёт на нет. Сейчас мы выжали отличный результат — в 99-м перцентиле время ответа главной страницы составляет меньше 100 мс.
Продуктовые требования и их оптимизация
Ещё одна интересная деталь — как продуктовые ограничения помогли сэкономить железо. По требованиям, если профиль исполнителя закрыт, другие не должны видеть его статистику. Эта логика идеально легла в нашу асинхронную схему. Перед тем как запускать пачку тяжёлых сетевых вызовов, мы проверяем уровень приватности. Если проверки не проходят — запросы просто не выполняются. Так мы одновременно закрываем продуктовые требования и оптимизируем утилизацию ресурсов бэкенда.
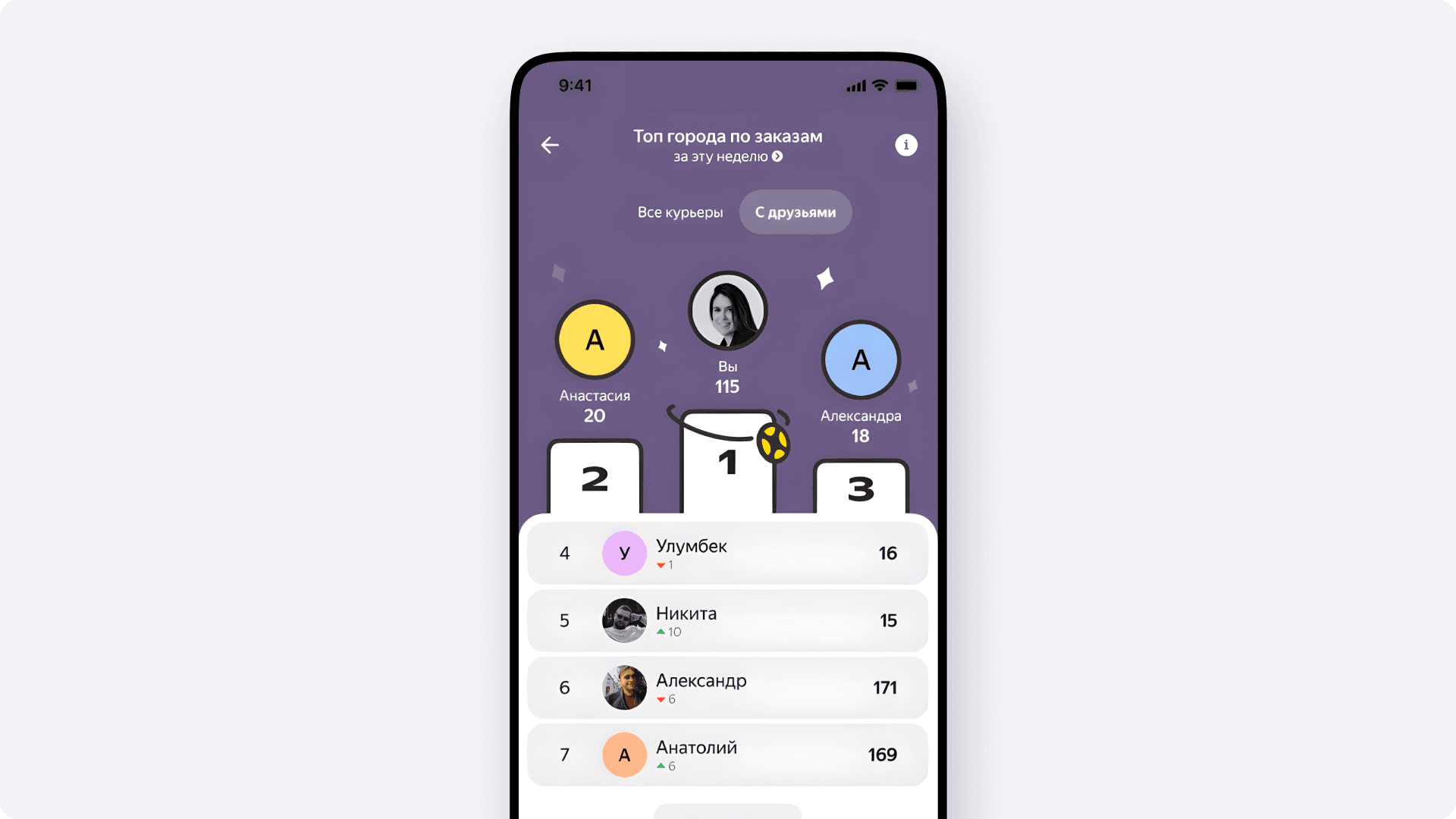
С главной страницей и ядром разобрались. База готова. Но сам по себе профиль — это всё ещё просто красивая визитка. Он есть, и он хорошо выглядит, но чтобы курьерам было интересно туда заходить регулярно, мы решили добавить некий соревновательный элемент — региональные и дружеские лидерборды.
Как обновлять огромные массивы данных и не положить базу
Лидерборды — это, по сути, та же статистика заказов, которую мы запрашиваем на главном экране профиля, но с другим периодом расчёта. Они обновляются раз в день, считаются с понедельника по воскресенье и не требуют синхронных походов в кучу соседних сервисов. Данные об исполнителях подтягиваются из медленных хранилищ в фоне и складываются в базу сервиса статистик.
Но тут возникает серьёзная техническая проблема. Если мы не зальём огромный массив данных за одну атомарную операцию, курьеры увидят расползающийся стейт: часть расчётов будет новой, а часть старой. Так быть не должно.
Транзакции против версионности
Важное условие — обновление должно запускаться только на одном инстансе нашего микросервиса. В экосистеме userver — это C++ фреймворк, который мы используем. У него есть готовые инструменты: компонента DistLock и класс Periodic, на базе которых построена библиотека для периодических задач с распределённой блокировкой через БД.
Мы стали выбирать алгоритм заливки данных. Первой мыслью было обернуть всё в транзакцию. Но это тупиковый путь. Транзакции на сотни тысяч записей имеют неконтролируемую длительность. Общая производительность БД неизбежно просядет, а в пике мы получим отказ всего кластера.

Тогда мы пошли по пути версионирования.
Создали таблицу версий лидерборда и связали её с таблицей самих данных лидерборда по внешнему ключу. Алгоритм работает так:
- Фоновый процесс (воркер) смотрит на актуальную версию, из которой ручки профиля сейчас отдают информацию.
- Воркер инкрементирует эту версию (N+1) и начинает заливать свежие данные именно под этим новым номером. Запись идёт отдельными батчами без длинных блокирующих транзакций.
- Если процесс прервётся, ничего страшного. При следующем запуске он проверит, сколько строк уже успел залить под новой версией, и продолжит с нужного места.
- Как только все данные легли в БД, мы атомарно обновляем основную версию. Ручки бэкенда мгновенно переключаются и начинают отдавать пользователям свежий топ.
BDUI и соседи по рейтингу
Конечно же, показывать курьеру весь список из десятков тысяч исполнителей региона бессмысленно — это больно и для базы, и для клиента. Нам нужно отдать только топов рейтинга и показать, где конкретно находится наш пользователь относительно лидеров.
Мы делаем выборку по позиции в регионе — берём N лучших курьеров. Дальше по идентификатору запрашивающего находим его текущее место и забираем ещё несколько исполнителей, находящихся рядом с ним. У нас на руках оказывается два набора данных, которые могут как угодно пересекаться между собой — от полного вхождения до пересечения на краях.
Далее мы обрабатываем все эти кейсы на бэкенде. На основе полученных наборов строится интерфейс с помощью BDUI. Обязательно применяем продуктовые фильтры приватности. Если человек решил остаться анонимным — мы не можем светить его имя или статистику, но и не показывать его в топе неправильно. Поэтому вместо имени и фото в рейтинге гордо красуется «Аноним». Готовая JSON-спецификация отправляется на мобильный клиент, где и рендерится.
Дружеский лидерборд и курьеры из разных городов
Региональный рейтинг — это круто. Он показывает, что в твоём городе можно доставлять больше заказов. А если из него провалиться в профиль топового курьера, то можно посмотреть его уровень и статистику.
Но главная задача публичного профиля — укреплять социальные связи между друзьями. А региональный топ с тысячами незнакомцев для этого не очень подходит. Поэтому мы сделали второй лидерборд — дружеский.
Он строится по тем же принципам, что и региональный, но с одним важным нюансом. Список друзей динамический, и курьеры могут дружить, находясь в разных регионах. В таблицах у нас лежат поля position_in_region и change_position_in_region. Если показывать их как есть, рейтинг начнёт нещадно врать: курьер из Москвы на 1000-м месте не может сравниваться с курьером из небольшого города, где всего 500 человек. Да и непонятно, от какого момента считать изменение позиции, если ты только что добавил нового друга.
Решили мы эту задачу следующим образом: в дружеском лидерборде мы отказались от дельты изменений и оставили только абсолютное значение — количество заказов orders_count.
Дальше всё просто: передаём в сервис статистики текущего курьера и список его друзей, делаем выборку всех значений и сортируем относительно orders_count. Ограничения на показ топа и «соседей» работают точно так же, как в региональном рейтинге. Наборы данных формируются с учётом приватности, прогоняются через те же билдеры и улетают BDUI-конструктором на клиент.
Строим асинхронную фабрику уведомлений
К этому моменту у нас уже была готова отличная функциональность: статистика, друзья, прогресс в системе мотивации и лидерборды. Но всё это имело достаточно мало смысла, если курьер просто забывал заходить в раздел. Не было никакого триггера, который бы напомнил: «Эй, у твоего друга что-то поменялось, зайди посмотри».
Чтобы увеличить количество заходов, мы решили добавить ленту новостей и пуши к ним. Вопрос модерации пользовательского контента — это всегда отдельная боль, поэтому пока мы не дали исполнителям возможность писать произвольные посты. Им прилетают только системные события из строго заданного набора: выход друга на слот, доставка N заказов за день, приглашение новых коллег, увеличение уровня мотивации или появление N друзей в профиле.
Архитектура пайплайна на базе STQ
Разработку фидов разделили на две части. Сначала написали ядро, которое решает: кому отправлять, в каком формате, можно ли вообще сейчас тревожить человека, и делает саму отправку пуша. Вторая часть — это сбор событий из разных систем и постановка их в очередь нашего ядра.
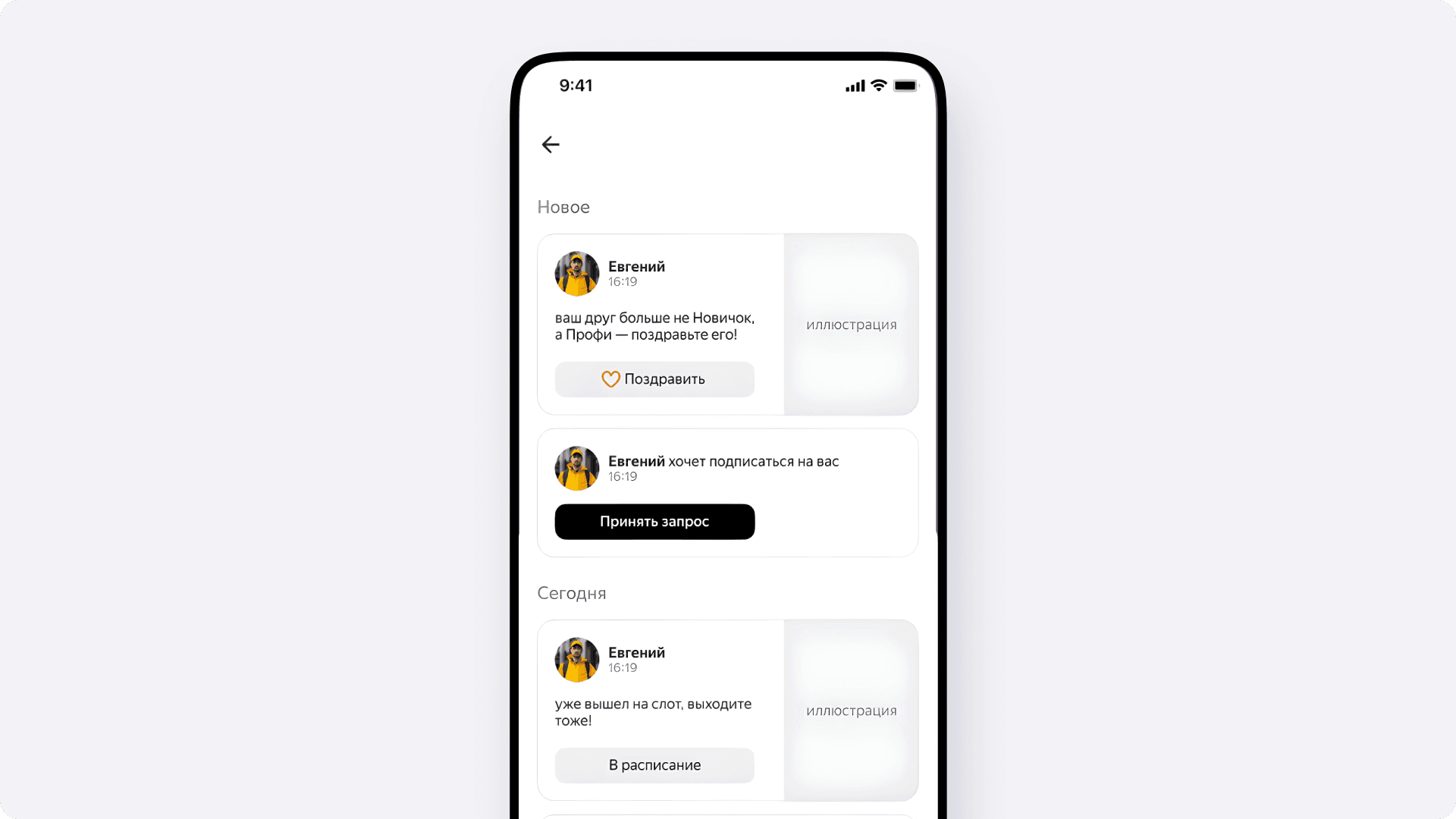
Для асинхронной обработки событий мы используем STQ. Чтобы построить один фид, нужно пройти строгий пайплайн:
- Понять, кому его отправлять.
- Получить данные о получателях.
- Проверить, можно ли им отправлять фид и нотификацию прямо сейчас.
- Сформировать payload для фронтенда.
- Записать данные в базу.
Каждый этап пайплайна мы вынесли в отдельный строгий интерфейс. Классы, реализующие эти интерфейсы, инкапсулируют логику конкретного типа фида. А потом всё это собирается через фабрику.

Давайте посмотрим на код обработчика события. Он выглядит примерно так:
void Performer::Perform(TaskDataParsed&& task, handlers::Dependencies&& dependencies) {
const auto& event_type{feeds::contract::common::Transform(task.args.event_type)};
const auto& event_processor = dependencies.event_processor_manager.Get(event_type);
const auto related_profile = public_profiles::contract::models::RelatedProfile{
.type = stq_common::ConvertType(task.args.performer_id.type),
.id = task.args.performer_id.id,
};
const auto relations = event_processor.GetRelationsSolver().Solve(task.args.extra_data, related_profile);
if (relations.source.has_value() &&
relations.source.value().public_profile.privacy_mode ==
public_profiles::contract::models::PrivacyMode::kAnonymous)
{
LOG_INFO() << "Skipping feed creation from anonymous source";
return;
}
const auto checked_profiles = event_processor.GetCommunicationsChecker().Check(task.args.extra_data, relations);
auto feeds = event_processor.GetFeedBuilder().Build(relations.source, checked_profiles, task.args.extra_data);
dependencies.feeds_database_storage
.InsertFeeds(task.args.idempotency_token, std::move(feeds), ToString(event_type));
}
Пройдёмся по основным моментам:
- RelationSolver — определяет адресатов. Например, если курьер вышел на слот, уведомление должно улететь всем его друзьям. Но если кто-то подписался на тебя — пуш нужен только тебе.
- CommunicationsAvailabilityChecker — защита от спама и здравый смысл. Если друг уже выходил на слот сегодня, мы не хотим закидывать курьера дублями сообщений. Чекер проверяет историю и отсекает лишнее. Плюс он смотрит на время — если у получателя сейчас два часа ночи, пуш точно отправлять не стоит.
- FeedsBuilder — собирает финальный контент: тексты, картинки и метаданные фида.
Внимательный читатель мог заметить в архитектуре абстракцию MobileFormatConverterInterface. Она не участвует в построении фида для БД, а задействуется, когда мобильное приложение приходит за списком новостей. Этот конвертер на лету преобразует сырой JSON в формат, который понимает клиент.
Двойная запись и гарантия идемпотентности
После того как фид собран, нам нужно его где-то сохранить и отправить адресату. Внутри инфраструктуры Яндекса существует специальный микросервис feeds, который закрывает базовые сценарии работы с лентами новостей. Логично было бы просто формировать данные в нашей таске STQ и сразу пулять их в этот платформенный сервис.
Но дело в том, что у популярного курьера может быть много друзей. Это значит, что на одно событие — например, выход на слот — нужно сгенерировать огромное количество фидов. Отправлять весь этот объём одним тяжеловесным запросом во внешний сервис нельзя, это не масштабируется. Данные нужно бить на батчи.
И так как таски в STQ могут ретраиться, то если между первым падением и новым запуском данные успеют измениться — например, кто-то добавится в друзья или удалится — то алгоритм соберёт уже другие пачки. А если состав пачек между запусками меняется, мы физически не можем сформировать для них стабильный и консистентный токен идемпотентности для похода во внешний сервис.
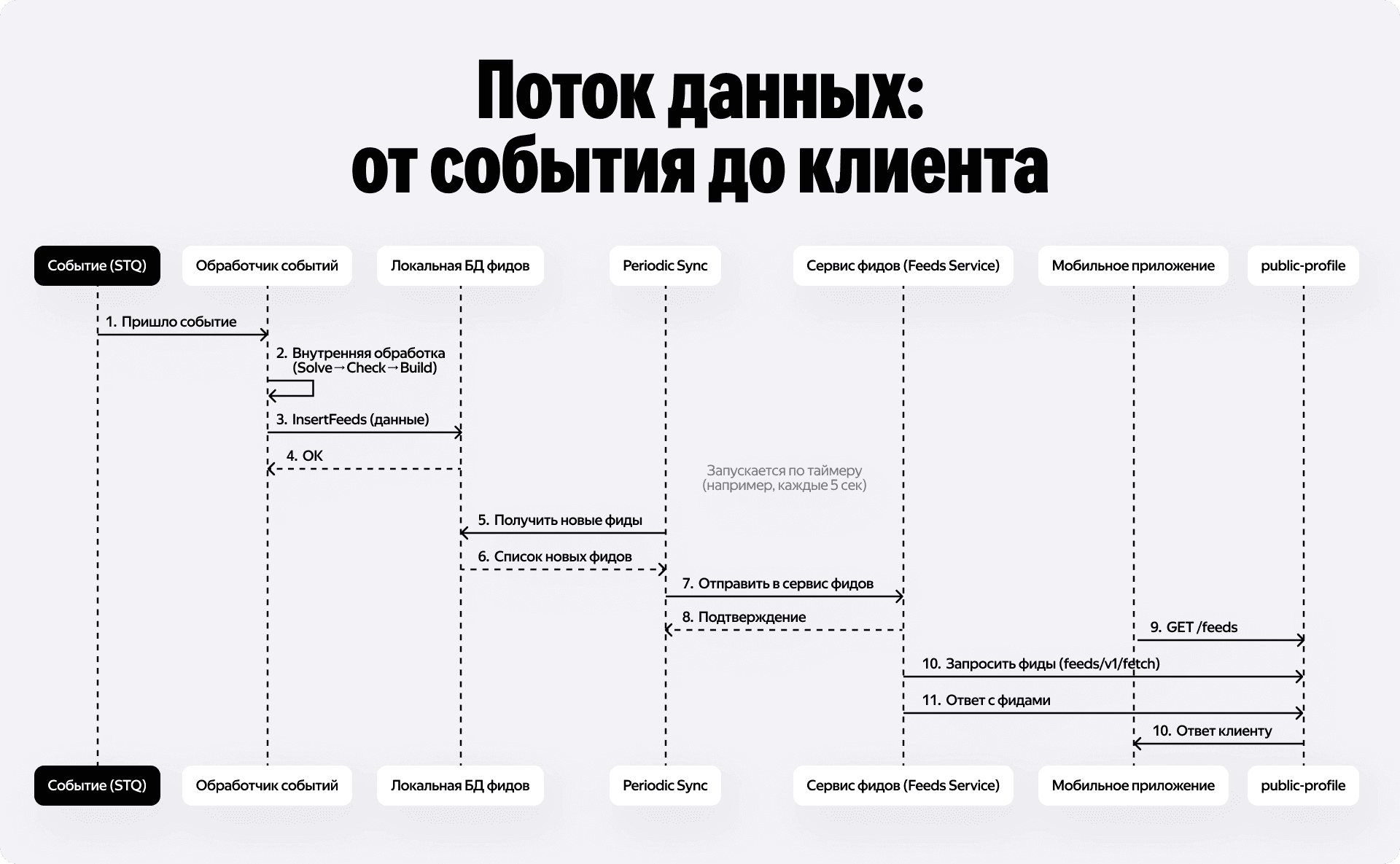
Именно поэтому мы ввели архитектурный буфер в виде локальной базы данных. Сначала мы сохраняем все сгенерированные фиды к себе. На уровне нашей БД мы жёстко гарантируем уникальность записей для каждого адресата по составному ключу: внешний idempotency_token пришедшего события + social_profile_id пользователя, которого нужно уведомить.
А уже после этого в работу включается отдельный периодический процесс, который вычитывает из нашей базы зафиксированные, статичные данные, спокойно бьёт их на одинаковые пачки и с помощью курсоров гарантирует железобетонную идемпотентность при походах в платформенный сервис feeds. В итоге система легко масштабируется, а у курьеров не дублируются уведомления.
В самих фидах зашито ещё несколько классных продуктовых механик — например, возможность поздравить друга прямо из ленты или в один тап перейти в нужный раздел приложения ПРО. Но техническое ядро, позволяющее всё это крутить, работает именно так, как описано выше.
Финал
Что же мы получили после того, как выкатили публичный профиль в продакшен и собрали первые данные экспериментов? С одной стороны — сухие цифры: мы увидели заметное улучшение бизнесовых метрик. С другой — живые люди: метрики опросов показали, что исполнителям действительно стала нравиться их рабочая среда.
Аналитика тоже подтверждает, что профиль не стал мёртвым грузом и не остался фичей ради фичи. По графикам видно, что курьерам интересно: они открывают разные вкладки, проверяют свои параметры, скроллят ленту фидов и следят за лидербордами. Более того, нам уже начали приходить репорты с обратной связью от самих пользователей — ребята просят новые фишки и предлагают, что ещё можно добавить или улучшить.
Для команды разработки это классный показатель того, что фича оказалась востребованной, и мы точно продолжим развивать публичный профиль, чтобы исполнителям было ещё комфортнее.
Вся эта большая работа с микросервисами, асинхронными вызовами, хитрыми алгоритмами версионирования баз данных и пайплайнами STQ затевалась ради одной простой человеческой вещи. Пишете ли вы сложный код в шумном опенспейсе или везёте очередной заказ на велосипеде через весь город — каждому из нас необходимо комьюнити и чувство связи со своими людьми. И кажется, мы смогли его сделать.



