
В рамках микросервисной архитектуры достаточно легко делать «реактивные» сервисы: к вам приходит событие или вызов HTTP-метода, и в ответ на это происходит какое-то действие. Однако бывают более сложные сценарии, когда надо собрать некоторое количество информации или событий прежде, чем что-то делать. В таком случае нужен пайплайн — механизм организации сложных правил обработки событий.
Привет, меня зовут Павел Сухов, я ведущий разработчик Яндекс Доставки, и в последнее время занимаюсь финансовыми сервисами. Недавно нам пришлось организовать пайплайн с использованием интересных трюков С++. О них я и расскажу в статье.
Итак, вы узнаете:
- Как хранить в одном контейнере разные типы и использовать тип в качестве ключа контейнера
- Как средствами метапрограммирования удобно сериализовать и десериализовать разнотипные объекты
- Как сделать универсальный запускатель функций, который будет запускать любую функцию и сам искать, откуда «добыть» эти аргументы
- И главное, как сделать интерфейс для написания пайплайна обработки события — удобный и полностью изолированный от инфраструктуры
Инфраструктура доставки
Для начала расскажу, как устроена внутри разработка, сервисная архитектура и исходя из каких предпосылок мы пишем код.
Микросервисная инфраструктура. В Доставке мы используем сотни инстансов микросервисов, которые общаются друг с другом через кодогенерированные клиенты — фактически HTTP-запросы, где отправляешь параметры и получаешь ответ.
Ещё есть шина событий — вариация асинхронного взаимодействия, когда мы отправляем уведомление о том, что что-то произошло, в другой сервис, и оно гарантированно дойдёт. Наша шина немного специфичная — между разными заказами обрабатывает события параллельно, но в рамках одного заказа доставки все события гарантированно исполняются последовательно. И это важно.
Кодогенерация API. Все структуры мы делаем в схеме OpenAPI. Вот по этому описанию оно генерирует код на C++, обработчик API, клиент, структуры данных и всякие возможные вспомогательные функции для них.

Это важно: мы считаем, что у нас любую структуру можно сериализовать в JSON. Кодогенерация сделает функции для сериализации структуры в JSON, в строку, FlatBuffer и прочие поддерживаемые форматы. И есть кодогенерация HTTP-интерфейсов. Она генерирует часть кода для сервера и клиенты на C++ для других сервисов. Чтобы обращаться к другому сервису, нам достаточно в настройках указать имя этого сервиса, чтобы в зависимостях у нас появился клиент к нему. Это тоже важно, потому что мы никогда не делаем напрямую HTTP-запросы, — у нас всегда клиенты C++.
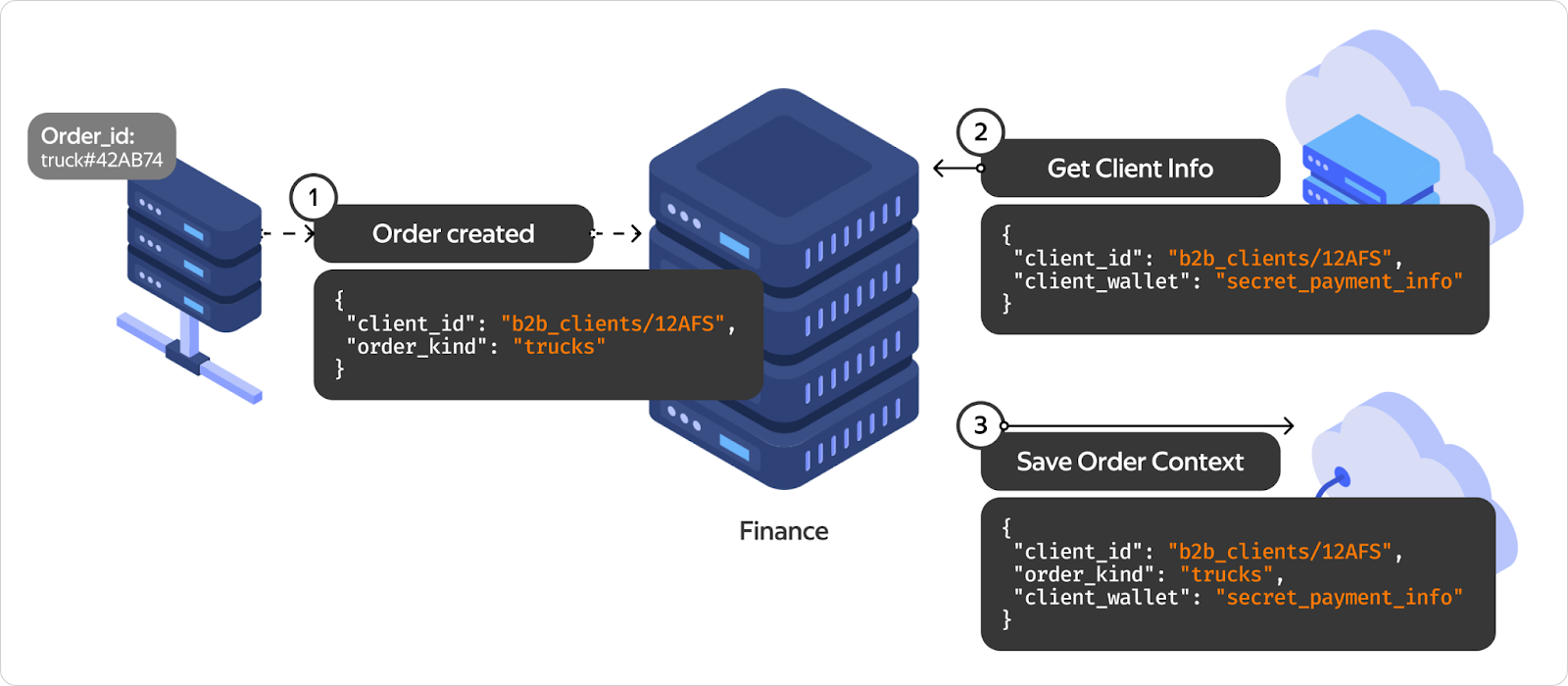
Сервис финансов. В рамках этой инфраструктуры есть сервис финансов, который сопровождает цикл заказа. Из большого цикла заказа доставки приходят события: например, о том, что заказ был создан. Но тот, кто отправляет эти события, не владеет, а зачастую и не должен владеть некоторой информацией. К примеру, сервис, который отвечает за создание заказа, не должен знать платёжную информацию клиента. Но зато он знает ID клиента, а значит, мы можем сходить в соседний сервис и обогатить данные, которые получаем из ивента: дописать туда ID кошелька клиента.
Мы получаем дополнительную информацию и из-за особенностей сервиса ничего не можем с этими данными сделать. Чтобы совершить платёж, у нас недостаточно информации: мы не знаем ни юридической схемы, ни кому платить. Поэтому сохраняем весь массив полученных данных в некую промежуточную структуру, которую называем контекстом.
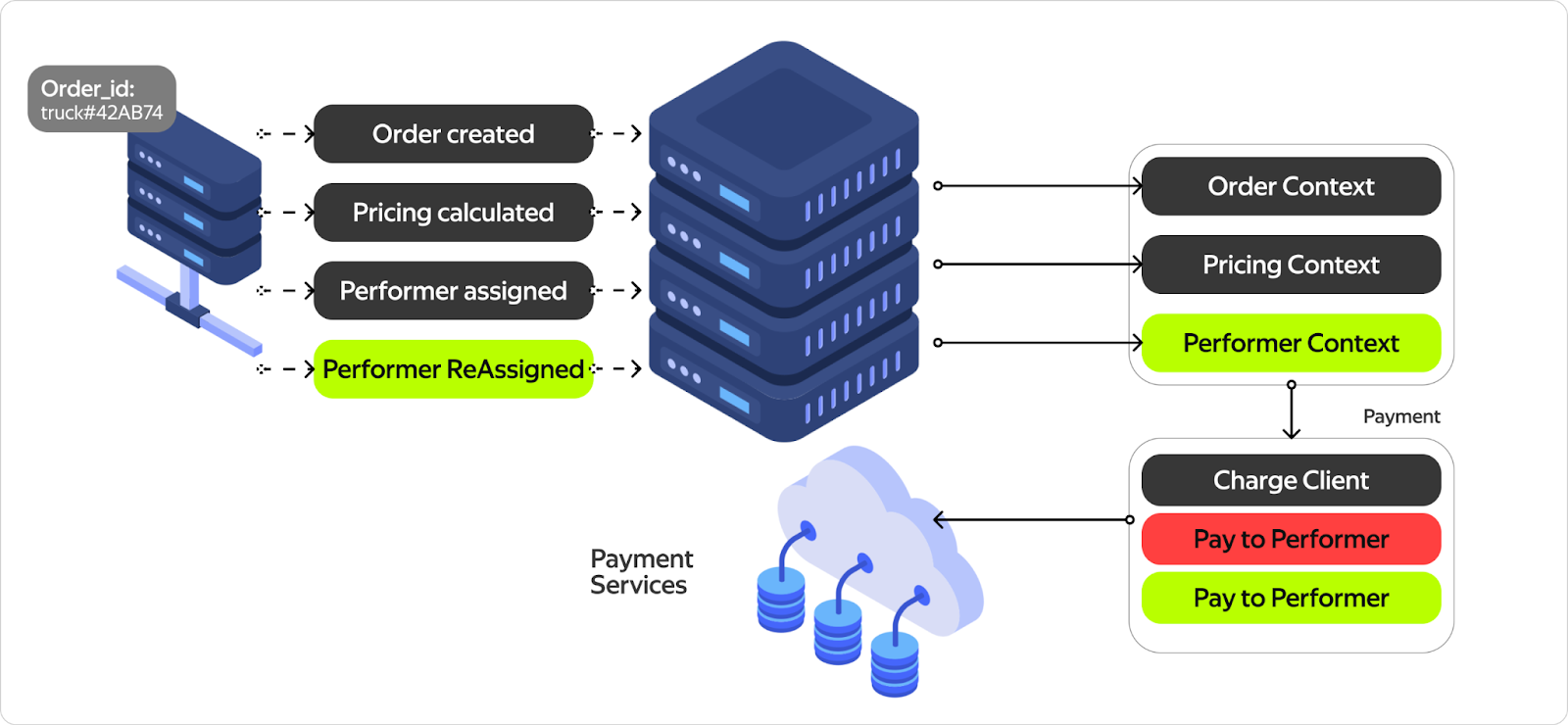
Итак, мы преобразуем события о создании заказа в контекст заказа. События о подсчёте финальной стоимости или юридической схеме, — в pricing-контекст. События о назначении курьера, — в контекст курьера. И только на этом этапе, когда мы знаем, от кого платить, как и кому, у нас достаточно данных, чтобы провести платёж. Отправляем платёжное распоряжение в платёжные сервисы. При этом не обязательно происходит движение денег — возможно, они замораживаются на карте клиента, проводится не денежная транзакция или происходит любое другое действие в рамках платёжного распоряжения.
Потом какое-то время спустя приходят новые события: например, переназначен курьер. Тогда мы пересчитываем контекст и платёжные распоряжения. В итоге приходит событие -доставка закончена, и мы финализируем все платежи. После этого всё равно может прийти несколько событий, которые что-то поменяют.
На практике на каждый сценарий доставки, продукт и тариф у нас своё подмножество событий. И для каждого подмножества может быть своя логика для разных курьеров, типов оплаты и клиентов. И варианты логики умножаются, умножаются, умножаются. Есть внутренняя логика, с которой средний программист не знаком и знакомиться едва ли захочет. Например, вот в этой стране нет контракта с эквайером, так что, если курьер на машине, деньги мы получаем как юрлицо доставки, а платим как юрлицо такси, а значит, нужны дополнительные транзакции для перепродажи заказа самим себе.
И людей, которые это всё знают и ещё и умеют писать код, очень мало — их можно записать не то что в Красную книгу, а на небольшой красный листочек.
Изоляция бизнес-логики от инфраструктуры
Мы стараемся максимально изолировать бизнес-логику. В идеале хотим, чтобы специалисты, которые пишут бизнес-логику, не видели остальной инфраструктуры, потому что у них и так сложная доменная область. Идеальный интерфейс для них — это функция. Она принимает на вход события и возвращает контекст. Это они и должны написать, всё остальное вокруг — мы.
Если спецам по бизнес-логике нужен какой-то клиент, настройки хоста, библиотеки — это всё должно быть отдельными аргументами функции, а всё, что они производят, — возвращаемое значение без сайд-эффектов. И ещё какая-нибудь функция, которая принимает на вход сгенерированные контексты. Она вызывается тогда и только тогда, когда все контексты сгенерированы, и выдаёт платеж. Ну и разные более хитрые комбинации, например обработка события только в случае, если у нас был сгенерирован какой-то контекст.
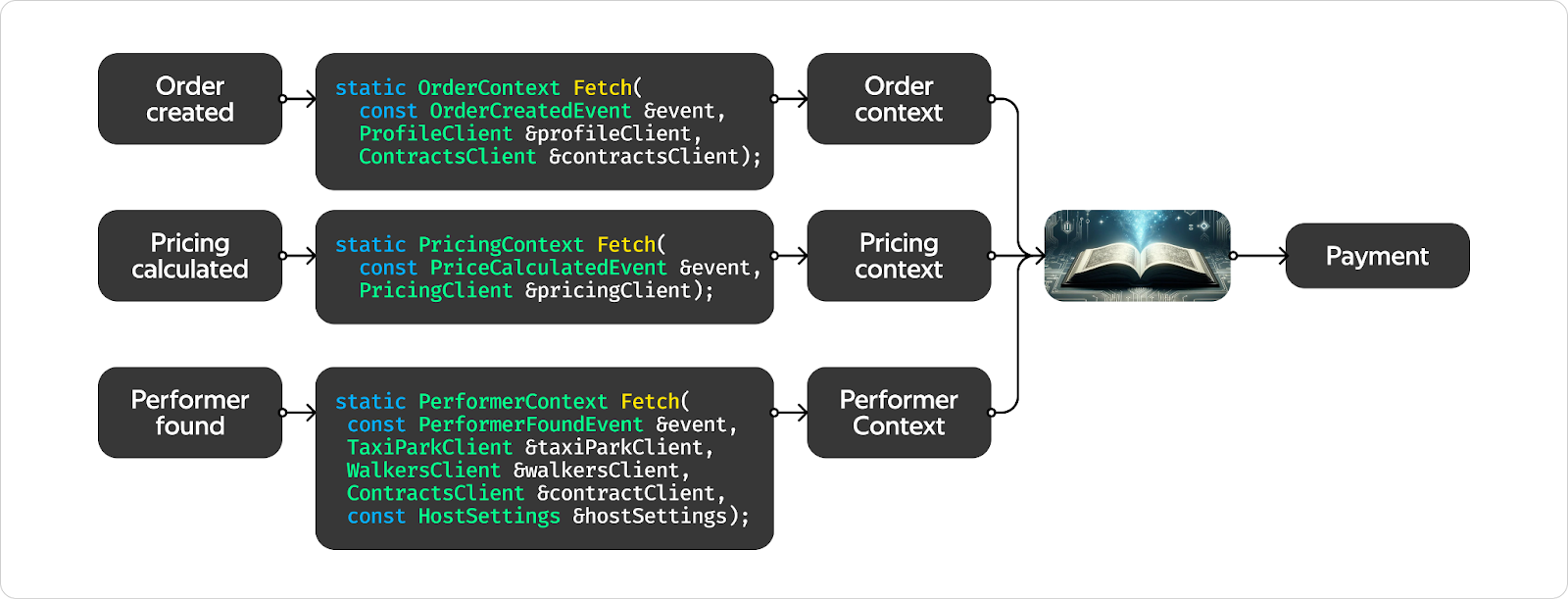
Вот так это должно выглядеть в коде.
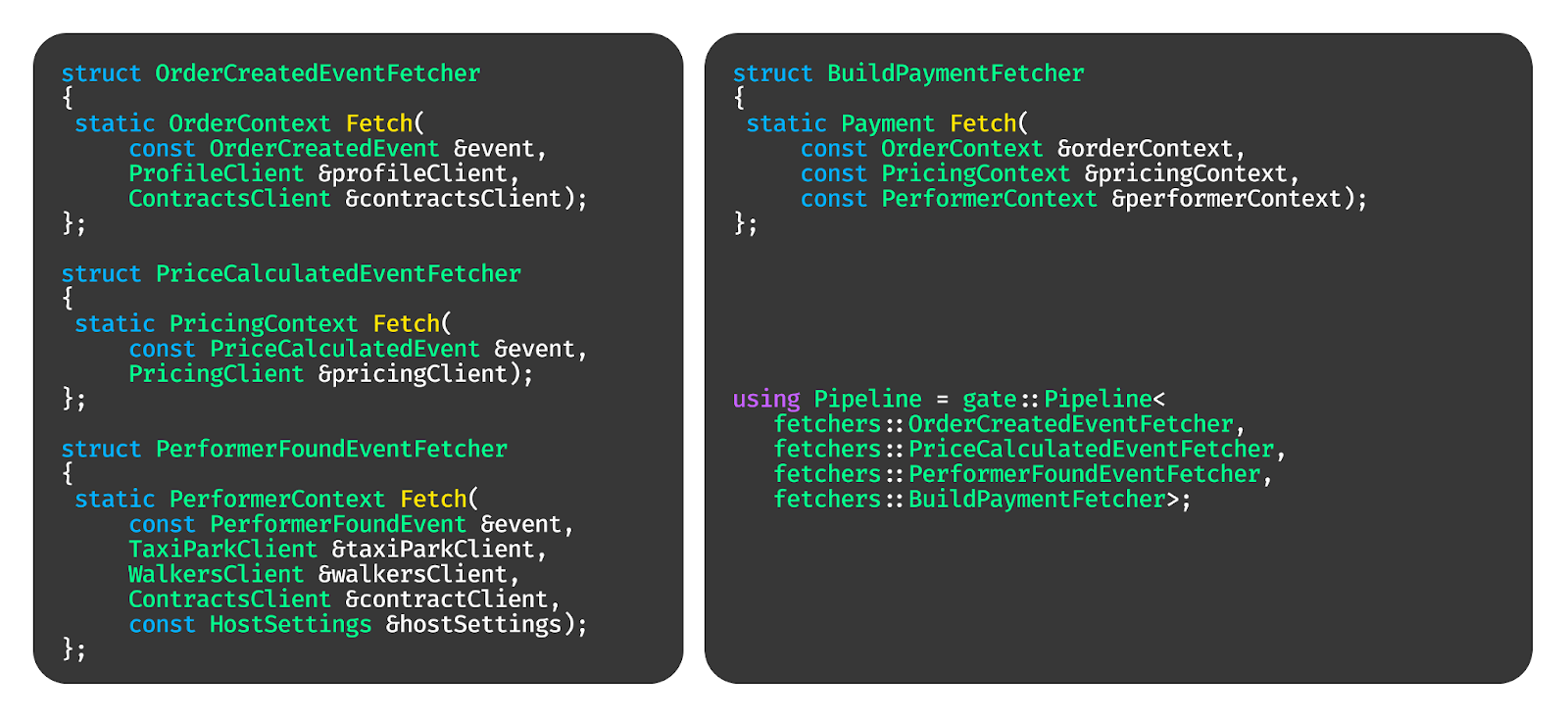
После этого разработчики бизнес-логики все эти функции добавляют в некоторый список и не должны делать больше ничего. Их ответственность — бизнес-логика, как и где эта логика будет запущена и выполнена — уже наша зона ответственности.
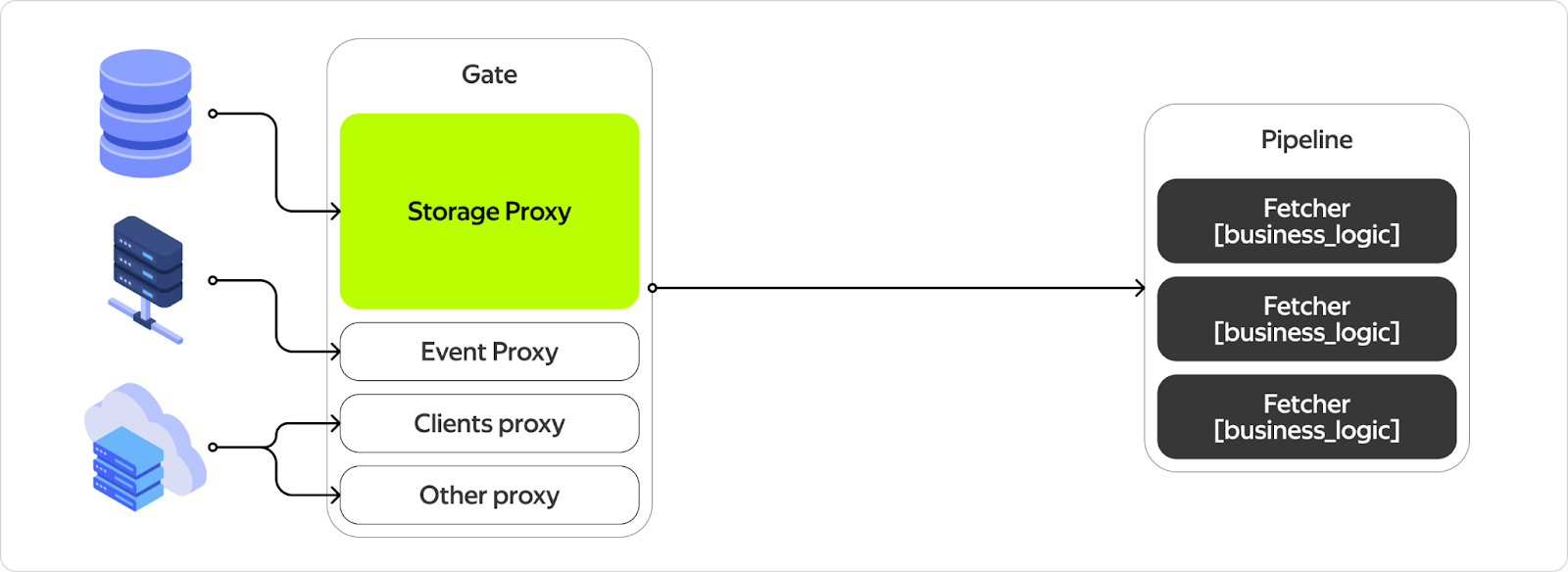
Собственно, это должно выглядеть как-то так. Большой прокси до всей инфраструктуры. Некая штука, которую мы называем пайплайн, которая понимает, какие обработчики запускать в каком порядке и как в них прокидывать данные. То, что чёрное, будут писать аксакалы от бизнес-логики. То, что белое, должны сделать мы.
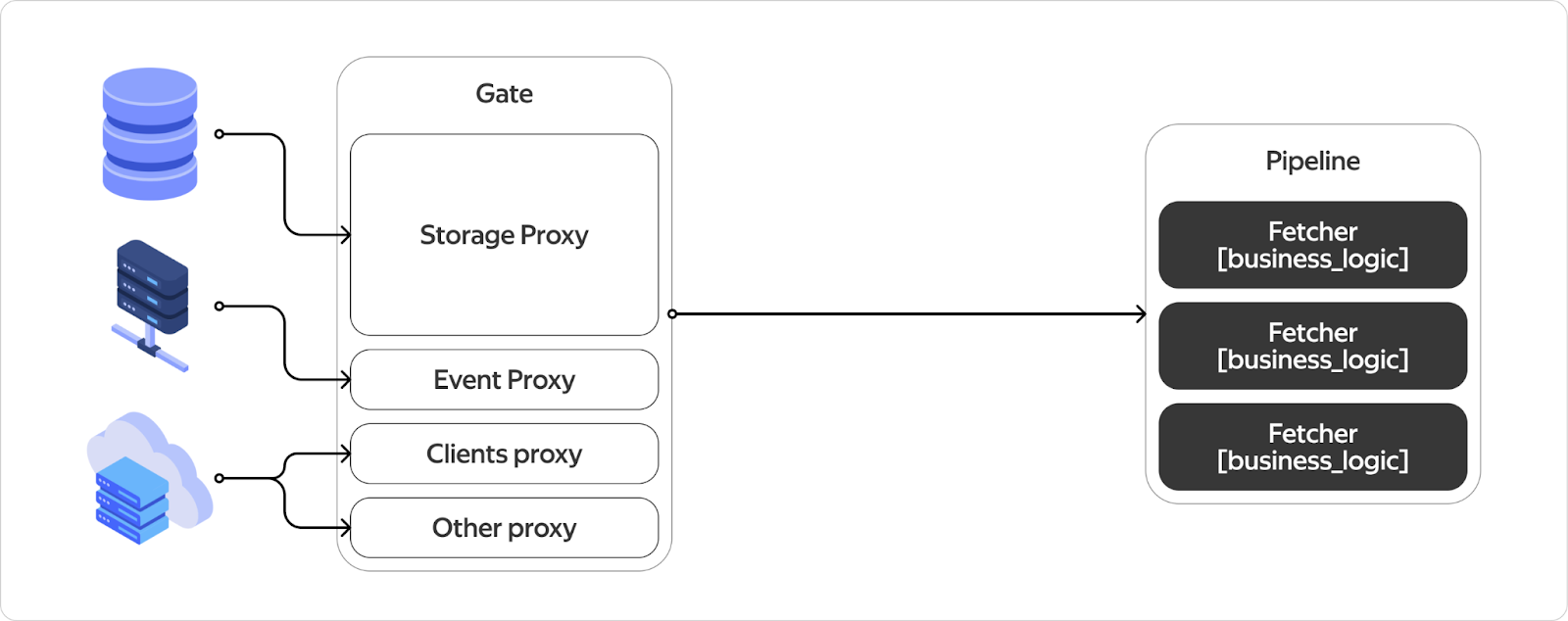
Storage Proxy
И теперь перейдём к коду. Разберём, что делает вот эта функция.

Это статическая функция, в которой есть статическая переменная типа atomic. Поскольку она статическая, она будет проинициализирована один раз для всех вызовов функции. И дальше каждый вызов функции эту переменную инкрементирует и возвращает значение. Функция next — это просто последовательность чисел: 0, 1, 2, 3, …

Теперь давайте пойдём на следующий уровень.

Эта функция опять статическая, и в ней есть статическая константа. Она будет проинициализирована один раз для всех вызовов функции. И потом всегда будет возвращать константу, то есть одно и то же значение.
Но есть нюанс — шаблонный тип Type. А значит, для каждого типа будет сформирована своя собственная константа и проинициализирована функцией next, то есть из нашей бесконечной последовательности.

Фактически мы создали индексацию типов. Для типа T мы поставили в соответствии число 0, для типа B — 1, для типа string — 2, для типа int — 3. Из приятного: эта штука ещё устойчива к alias — это юзинги, тайпдефы и прочее.

Мы сумели сделать преобразование из типа в число, причём в число от 0 до n. Это очень маленький трюк, который на самом деле даёт нам невероятно красивую возможность общаться с типами как с данными.
Универсальный registry
Давайте на основе трюка, описанного выше, сделаем некий универсальный registry, который представляет из себя структуру данных для хранения любого типа. Туда можно поместить тип B, туда можно поместить тип A. Можно проверить, all of вернёт true, только если мы в registry сохраняли и тип A, и тип B, и тип C, и тип D.

Функция last вернёт последнее сохранённое значение, a и b соответственно. А функция all вернёт весь список, всю историю изменений типа C.
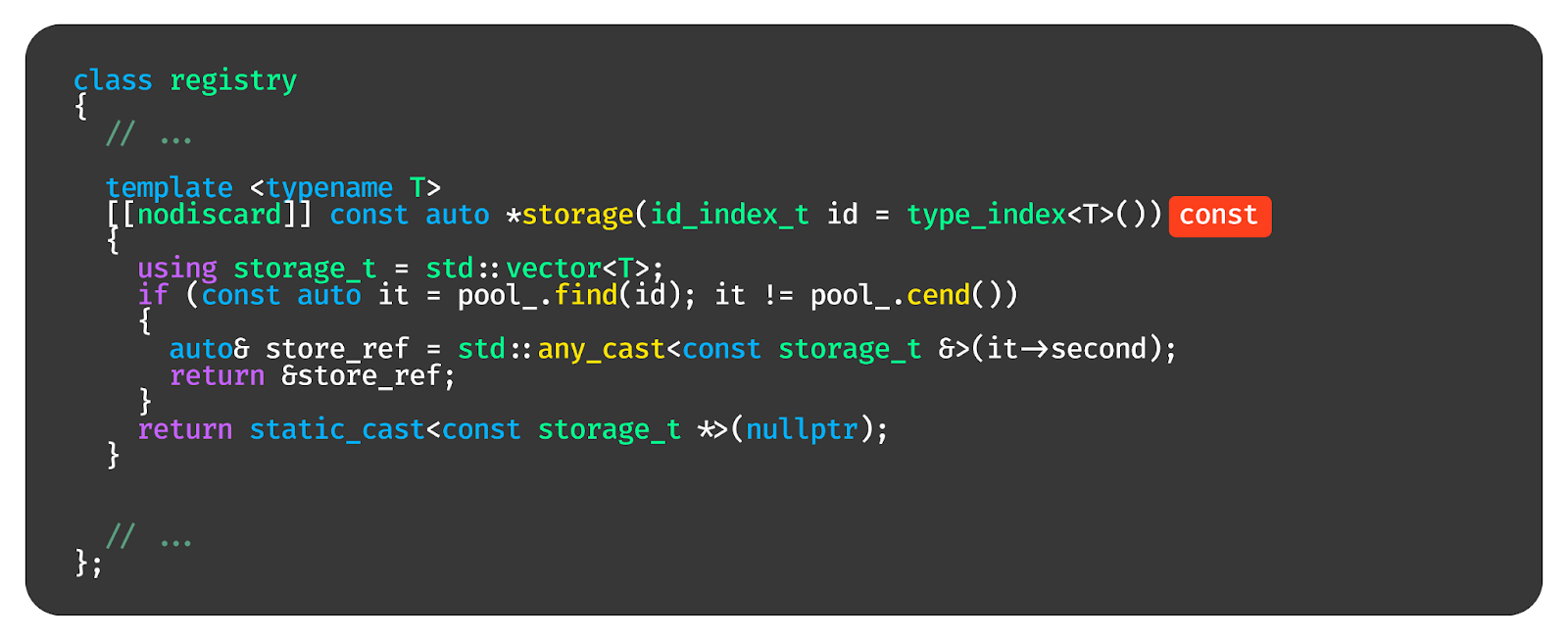
На самом деле теперь, когда мы уже умеем делать ID-шники для типов, такое универсальное хранилище создаётся достаточно просто. Давайте используем тип unordered map для создания ассоциативного контейнера из индекса в any.
Дальше мы сделаем функцию storage, которая принимает на вход тип T, и при этом аргументом id принимает индекс этого T. Таким образом, в этой функции мы одновременно знаем и тип, и соответствующий ему индекс.
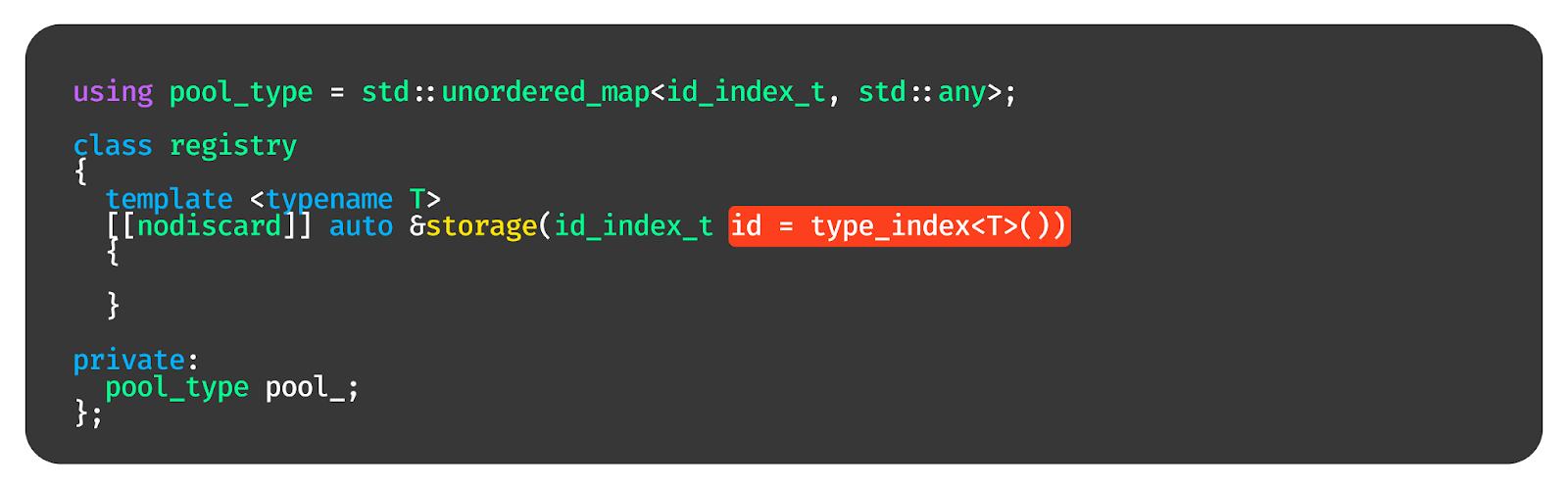
По этому индексу мы можем получить any, который соответствует типу T. Если any пустой, мы его заполним и скастим этот any к вектору типов T. И вот у нас получается, что в registry хранится мапа, из которой мы можем получить вектор для типа T, просто передав функцию тип T в качестве шаблонного параметра.
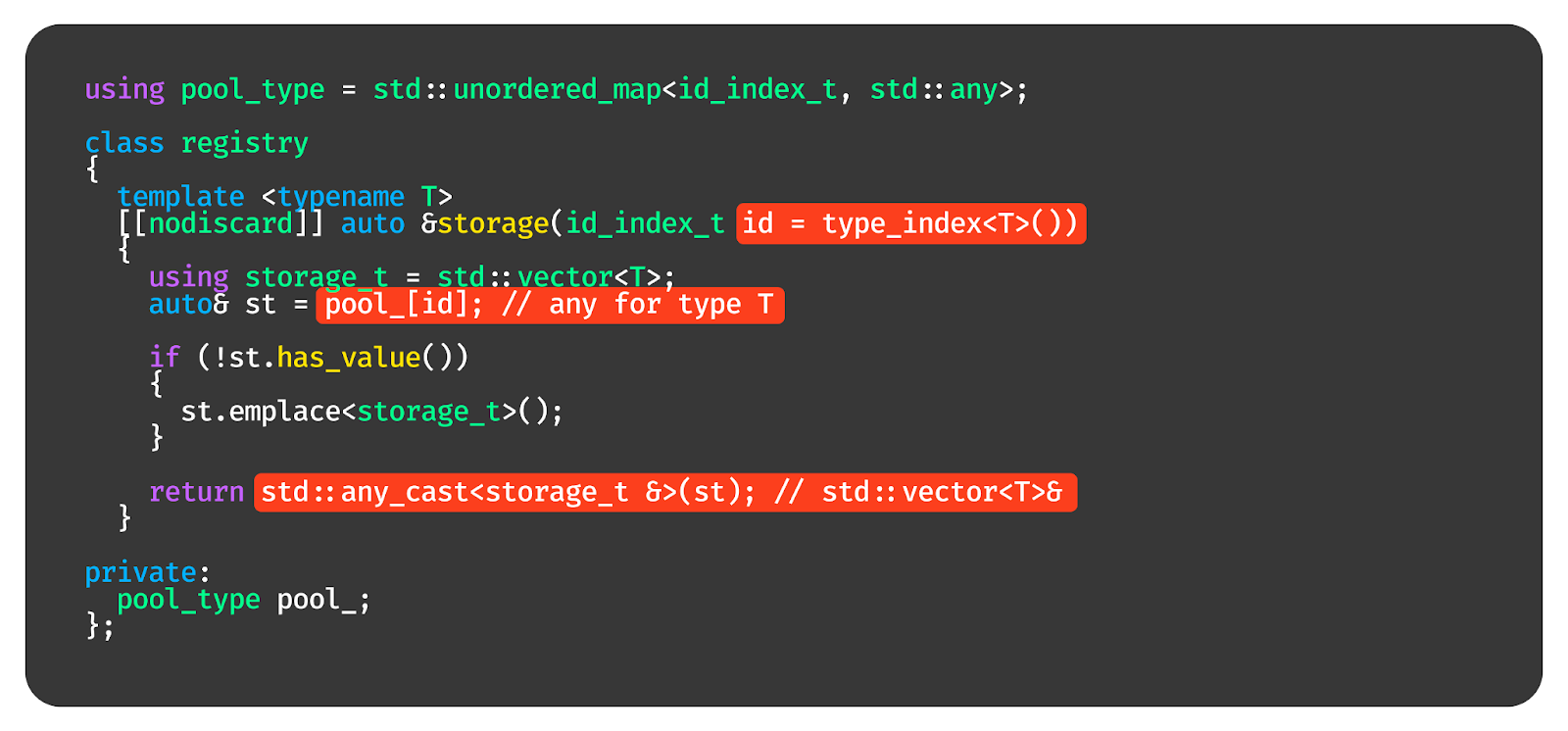
А дальше всё делается просто — если мы хотим поместить в registry какой-то объект. Давайте вытащим вектор типа T и положим туда объект этого типа. Работает вот так.

Дальше надо научиться читать из registry наши значения. Тут сложность заключается в том, что нужен const. У нас всегда должны быть const-функции, когда мы читаем данные, поэтому вместо ссылок здесь будут указатели. Если у нас ничего не сохранялось по определённому типу, то мы вернём nullptr.
Мы можем определить, например, функцию has, которая проверяет, сохранялся ли когда-нибудь тип T в наш registry. Там всё элементарно. Давайте попробуем получить указатель на вектор от этого типа T. И у нас что-то сохранялось, если это не пустой указатель на не пустой вектор.
А если нам надо проверить несколько типов, мы просто агрегируем это через fold expression. У нас сохранились все типы T, если сохранился каждый, и any, если хотя бы один. Поскольку мы используем тот же самый трюк с индексацией типов — alias работают нормально. А также для fold expression определено поведение для пустого списка, что видно в последних двух строчках теста.

Мы делали этот registry для конкретной задачи, поэтому везде поставили ограничение, что мы работаем только с decay-типами, чтобы не мучиться со ссылками, указателями и всем прочим. Но в теории можно продумать и эту функциональность.
Чтение данных из registry
С историей всё просто. У нас хранится вектор, в функции emplace мы добавляли новый объект всегда в его конец. Поэтому история изменений — это просто возврат разыменованного указателя на вектор.

А с последним сохранённым значением всё чуть хитрее. Когда мы берём значение одного типа, мы хотим получить константную ссылку на этот тип. А когда мы хотим получить несколько типов, мы хотим получить tuple константных ссылок.

Задача со звёздочкой (напишите ответ в комментариях): как объяснить, почему в функции last тип возвращаемого значения decltype(auto), а не auto?

Итак, теперь у нас есть нужный registry. Не обязательно делать registry так, чтобы он хранил именно типы. Можно делать специальные структуры данных с какой-то метаинформацией. Например, поставить булевский флажок: для этого типа — «да», для другого типа — «нет». Это иногда бывает полезно в рантайме.

Вариацию на тему такого registry с немного другой функциональностью и другими трюками можно найти в библиотеке ENTT. Кроме того, там можно подглядеть интересные реализации итераторов, ассоциативных контейнеров и много других полезных трюков.
Зачем мы всё это делали? Потому что у нас есть схема решения, которую мы хотим реализовать. И самое сложное во всей этой схеме — это прокси до базы данных. Мы хотим применить следующую концепцию: когда стартует пайплайн, он стартует для некоторого заказа, у которого есть ID, и мы хотим вытащить изо всех баз данных, кешей — отовсюду всё, что соответствует ID этого заказа, и поместить в большой список JSON.
Дальше — распарсить JSON в структуры данных, а структуры данных сохранить в in-memory-хранилище, чтобы раскидывать по функциям. И мы только что сделали этот in-memory storage, который может хранить и отдавать любые типы.
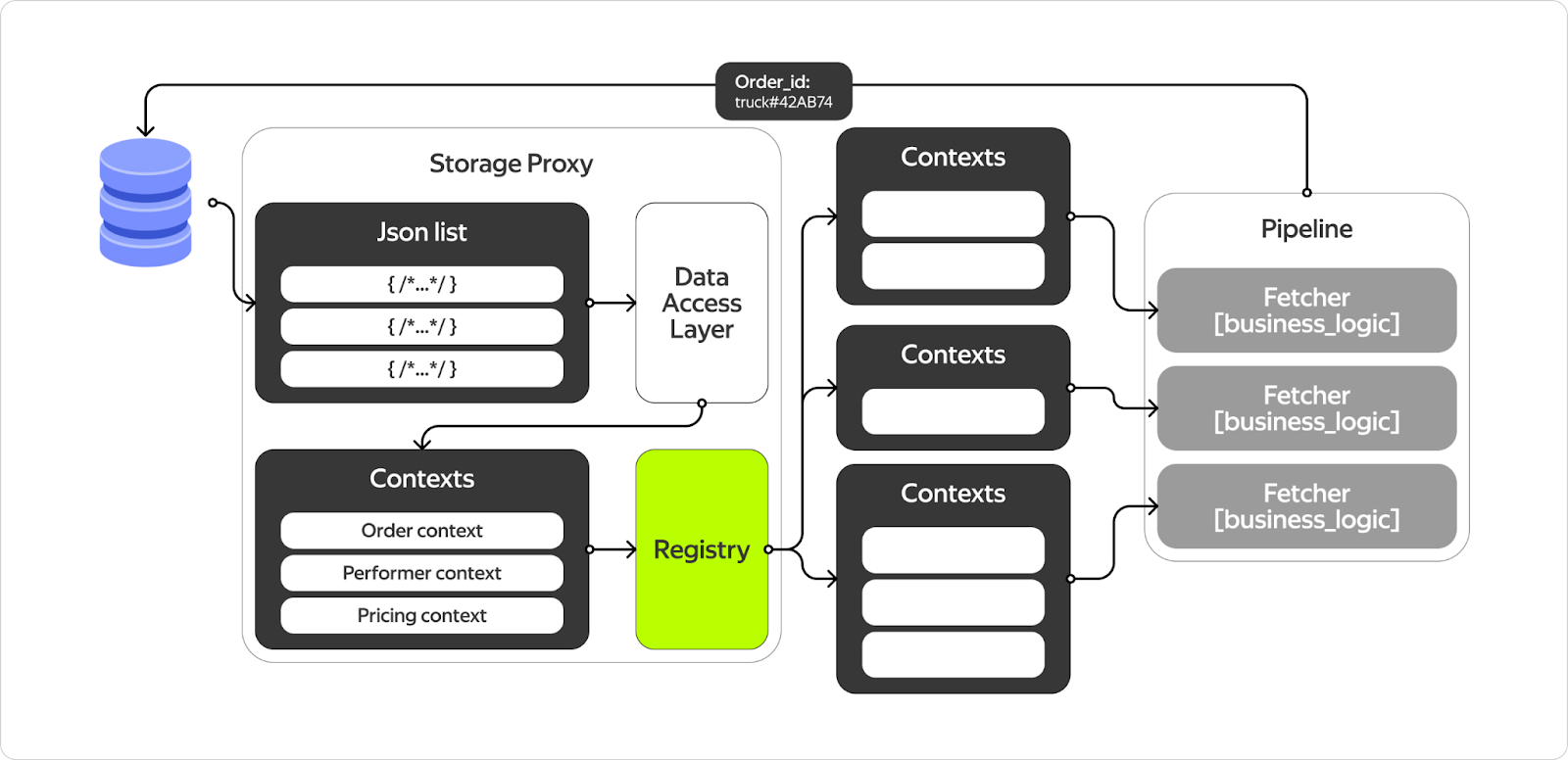
Осталось научиться парсить эти JSON и складывать их в in-memory-хранилище.
Парсинг
С парсингом есть загвоздка: когда мы сохраняем контекст, мы просто конвертируем структуру в JSON (а у нас по предпосылкам любая структура может быть конвертирована в него). Но в обратную сторону это немного сложнее: мы не знаем, в какой тип мы хотим этот JSON распарсить.
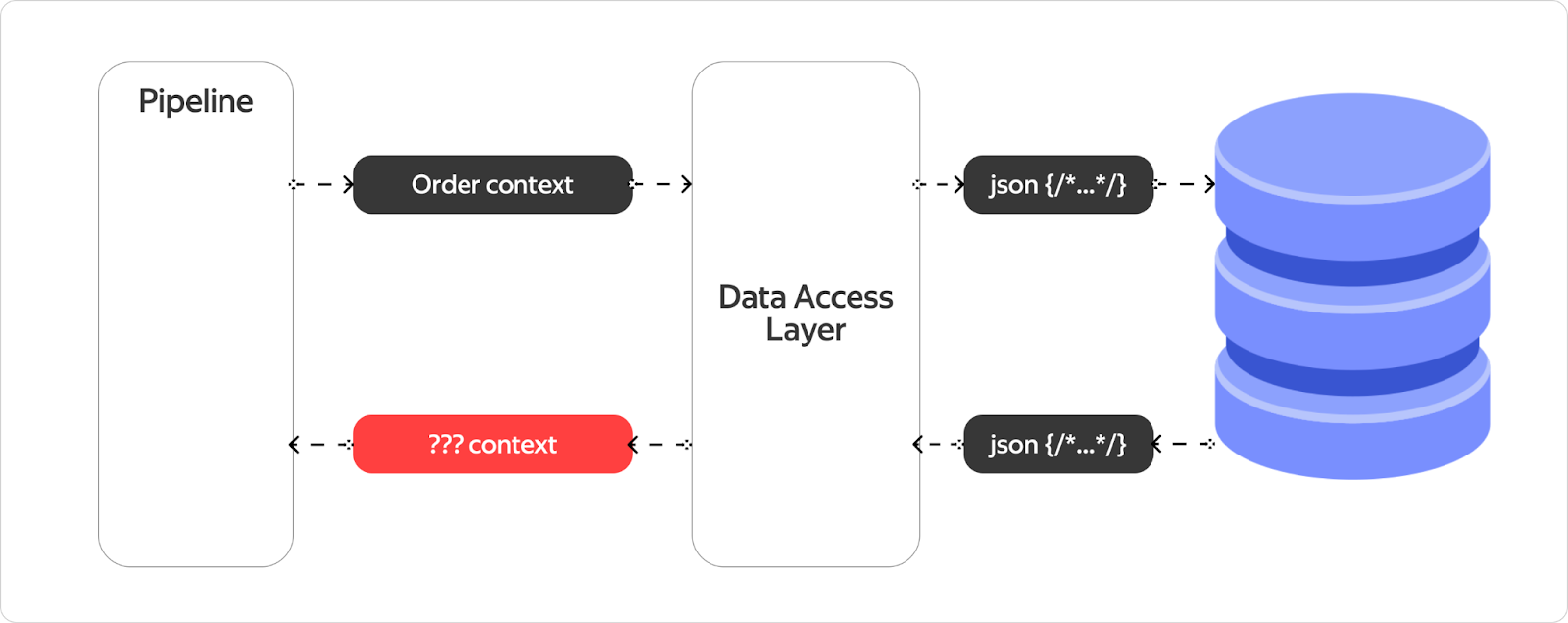
И чтобы решить проблему с десериализацией, мы поставили дополнительные ограничения на контекст. Контекстом называется структура данных, в которой есть поле — enum из одного единственного элемента. Для такого open-api-описания генерируется структура данных из C++, но самое главное, мы знаем, что при сериализации этой структуры в JSON всегда будет одно и то же значение поля — context_kind.
Вообще, надо делать статическую константу класса, но в OpenAPI нет такой функциональности, а это — наиболее близкий лайфхак.

Воспользуемся этой предпосылкой, чтобы по значению JSON понять, к какой структуре надо его парсить.
У функции парсинга Parse есть тип C (это контекст, к которому мы пытаемся парсить), есть входящий JSON и есть входящая ссылка на registry. Что мы делаем? Мы попытаемся распарсить JSON в тип C. Если контекст поля context_kind в JSON совпадает с полем context_kind в типе C, значит, мы сохраняли в JSON этот тип. И мы можем сделать парсинг из JSON и положить его в registry. А registry принимает любые типы.
Теперь функцию, которая умеет парсить в конкретный контекст, нам надо размножить на все возможные контексты в системе через fold expression.
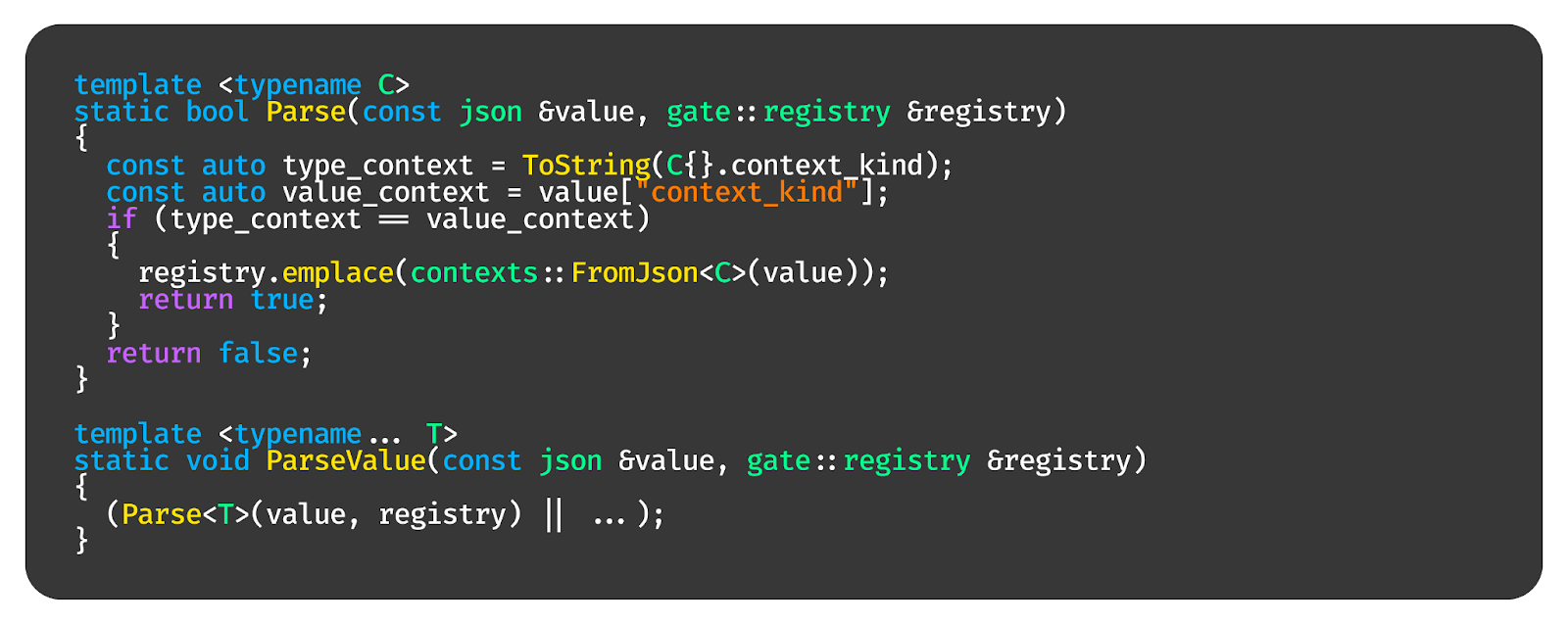
Потом нужно повторить этот набор действий для всего вектора JSON, который у нас получается на вход из базы данных. Выглядит это так.

Мы создаём парсер из огромнейшего списка контекстов. Делаем fill registry. На входе у нас вектор из JSON, который мы хотим распарсить, на выходе — registry с уже заполненными классами — можно брать и пользоваться.

Выявление типов
Проблема в том, что мы не хотим держать контексты явным списком. Вспоминаем, что те, кто пишет бизнес-логику, делают только функции. Вопрос: можем ли мы получить все контексты, которые используют эти функции? Ответ, конечно же, «да».

Мы можем объявить некий тип от одного шаблонного аргумента и сделать его специализацию. Она принимает на вход функцию, которая возвращает R, и вызывается от некоторого списка аргументов Args.

И дальше внутри этой специализации мы можем работать как с типом возвращаемого значения, так и с типами аргументов. Мы знаем, что все обработчики — это статическая функция Fetch из нашего класса.
Передаём в эту специализацию decltype функции Fetch.

Кстати, тут можно покопаться в коде Джейсона Тернера. Он сделал на основе таких специализаций настоящую магию по детальному анализу типов функций в compile-time.
Ну а дальше дело техники: собрать все типы, указанные в нашем пайплайне, и сделать парсер, который принимает шаблонным аргументом все типы, используемые в конкретном пайплайне.
Итого у нас полностью реализован блок, отвечающий за взаимодействие с базой данных, а также за сохранение и получение контекстов (помечен зелёным). Чтобы реализовать оставшиеся блоки, нам нужно выучить ещё пару вспомогательных трюков.
Получение имени типа
Один из трюков — получение имени типа (typename). Понятно, что мы можем сделать это через typeid, но те, кто пользовался таким методом, всегда страдают. Как тогда понять, что i — это тип int, а вот эта страшная магия — это строка?

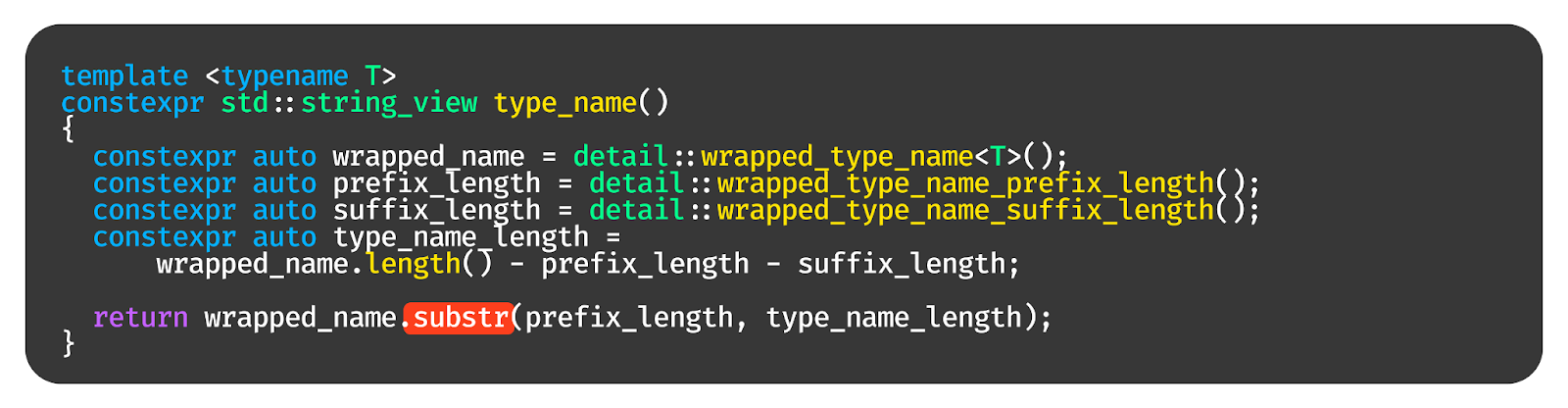
Давайте попробуем воспользоваться определением имени типа, которое нам даёт компилятор. Реализуем функцию wrapped_type_name, которая возвращает макрос PRETTY_FUNCTION, то есть человекочитаемое имя типа.

Значение этого макроса будет implementation-defined, а следовательно, отличаться от компилятора к компилятору. Например, в gcc это будет [with T = <my_type>, в clang — [T = <my_type>. Но и там и там это будет имя типа, которое создатели компиляторов намеренно делали «удобным» для чтения.
А самое главное — это constexpr std::string_view. Это значит, что мы можем с этой штукой спокойно баловаться в compile-time. Например, мы можем вызвать функцию для типа void и поискать в этой большой строке подстроку void. Разные компиляторы выдадут нам разные строки, но для каждой из них мы таким образом посчитаем длины префикса. Потом мы можем посчитать длину суффикса.

Дальше мы можем для произвольного типа составить функцию, которая генерирует «волшебную строку», содержащую имя типа, а также длину префикса и суффикса (которые одинаковы для всех таких «волшебных строк»).
А затем нам просто надо вернуть подстроку между префиксом и суффиксом: она и будет человекочитаемым именем типа.
Запускаем. Вуаля, оцените, что у нас сверху и что у нас снизу!
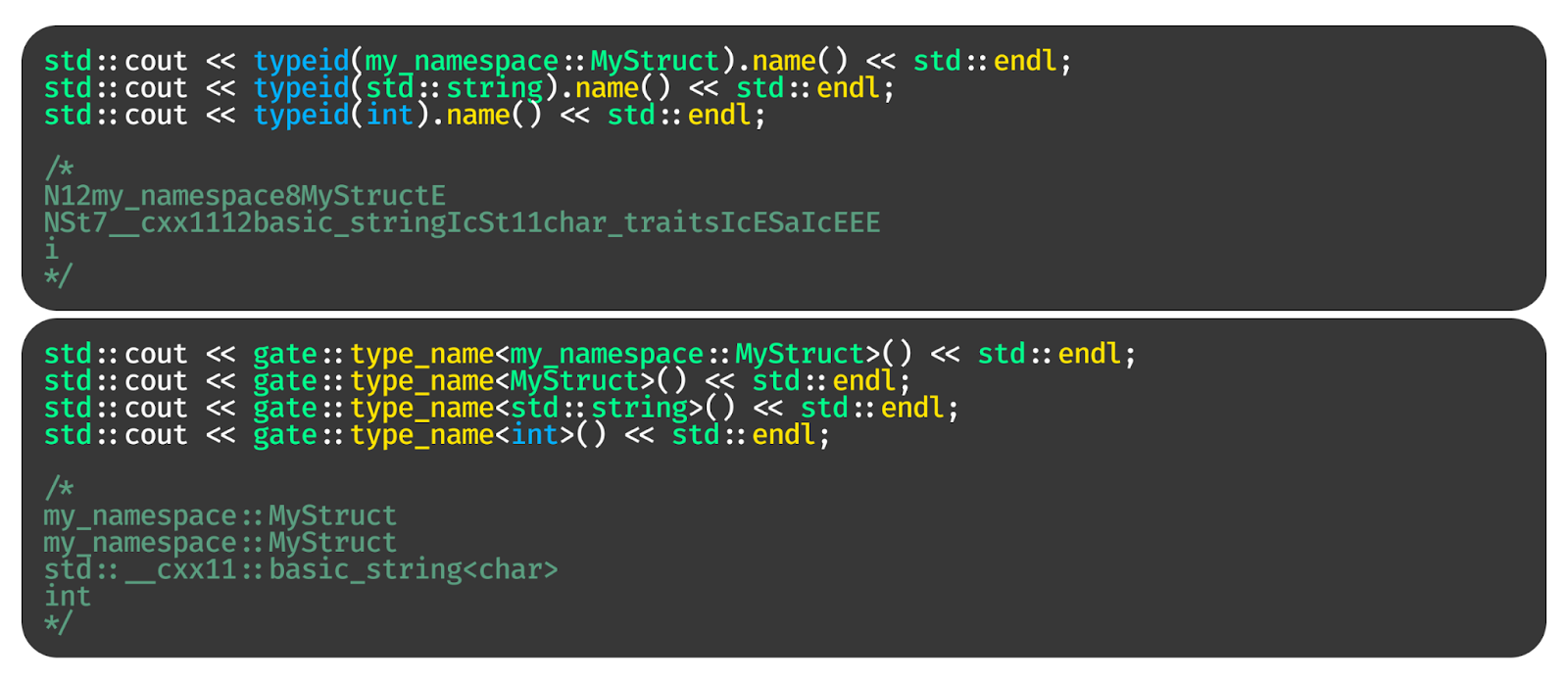
Такой же результат можно получить деманглом, например через буст: boost::core::demangle(typeid(T).name()). Но демангл работает в рантайме с нетривиальным парсингом, выделением памяти под итоговый результат и т. п. Очень не хочется сначала генерировать нечитаемую строку, а потом героически с этим сражаться.
Более того, функция нормально работает со стандартной библиотекой и стандартными типами. К тому же она устойчива к alias, а ещё полностью раскрывает неймспейсы. Когда мы работаем с шаблонными аргументами, этот трюк очень удобно использовать для логов, мониторингов и в других подобных вещах.
У нас даже была идея сохранять имя типа в базу и делать десериализацию для произвольного типа по сохранённому типу, но мы от неё отказались. И если «жизнь и рассудок дороги вам» ©, избегайте этого.
Дело в том, что парсинг будет ломаться при переименовании, в том числе при смене имён неймспейсов. Программисты редко ожидают, что переименование может привести к проблемам в проде.
Концепты
И наконец, самая полезная и крутая фича, которая есть в современном C++, по моему мнению, — концепты.

Вот концепт, который определяет, что тип T — это optional. Я могу объявить две функции с одинаковым заголовком, но так, что у первой будет ограничен шаблон. Он будет принимать только optional), а второй — любой другой тип.
И соответственно, при вызове функции f, если аргумент является optional, будет вызвана первая функция. Для аргумента любых других типов будет вызвана вторая функция. Казалось бы, для optional мы можем сделать это другими средствами языка, но концепты — мощный инструмент сам по себе.
Например, мы можем определить концепт Context, который говорит, что тип T является контекстом, только если в нём есть поле context_kind, конвертируемое к строке. А это практически один в один наше определение контекста.
То же самое с event. Event — это класс с полем event_kind, которое конвертируется к строке.

Как мы можем воспользоваться такими концептами? Например, если мы вспомним функцию parse, то можем закинуть в список типов (которые парсят вообще все типы, включая мусор) не только контексты, но и какие-нибудь event, произвольные классы, int. И сделать специализацию: если тип — контекст, то пытаемся его парсить, а если нет, то игнорируем.

Вызов функции
Самое классное применение концептов — для вызова функции Fetch с разнообразными аргументами.
Предположим, что у нас есть класс, в котором есть статическая функция Fetch. Она принимает на вход произвольное количество аргументов (мы заранее не знаем какое). Но мы знаем, что у всех аргументов, необходимых для вызова этой функции, разные типы.

А ещё у нас есть «универсальное хранилище» — registry, которое мы создали в самом начале статьи. Задача: если все аргументы, необходимые для вызова функции, хранятся в registry — нужно вызвать функцию Fetch, а если нет — не вызывать.
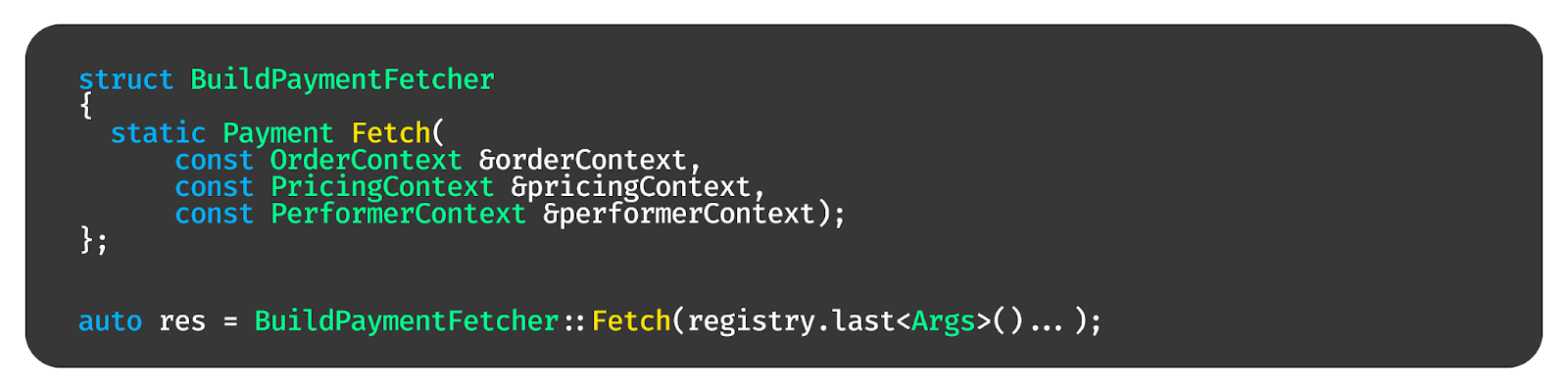
Создаём Helper, который принимает на вход тип func. Делаем его специализацию, в которой раскрываем типы аргументов и возвращаемого значения.
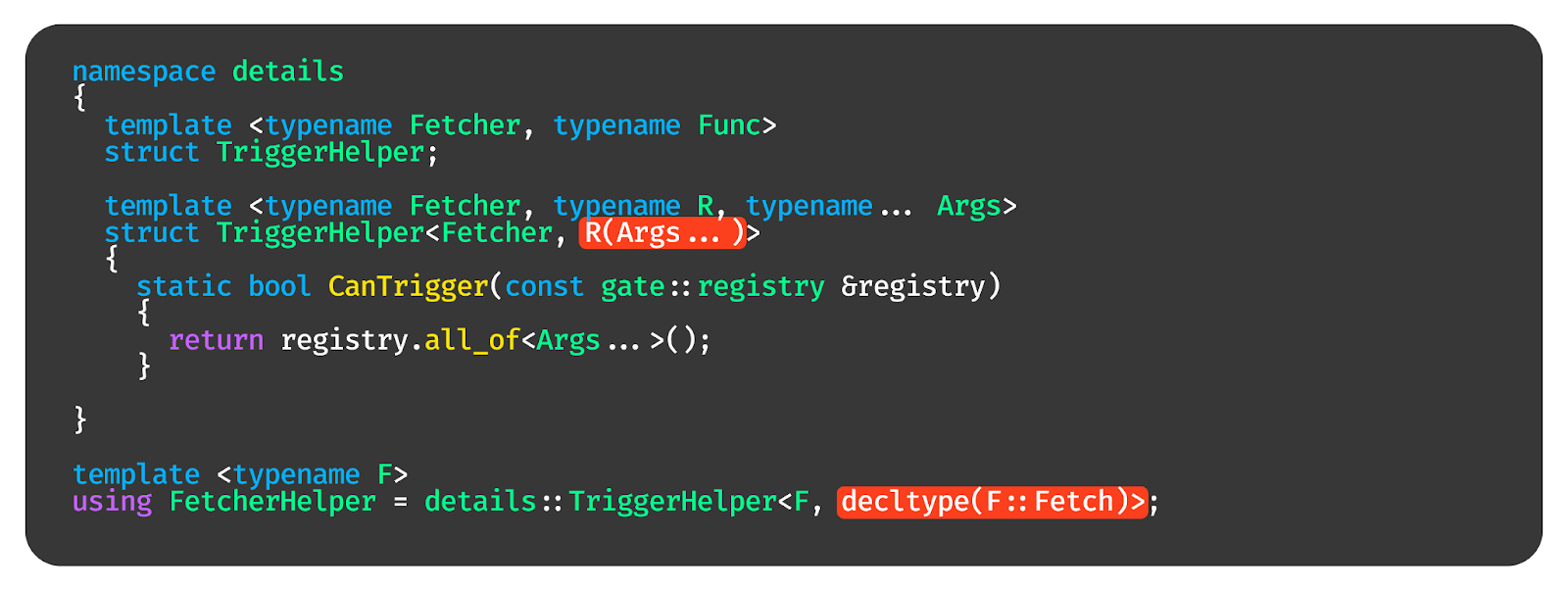
Делаем функцию CanTrigger, которая по типам аргументов скажет, есть ли все они в registry, и функцию Trigger, которая вызовет эту функцию.
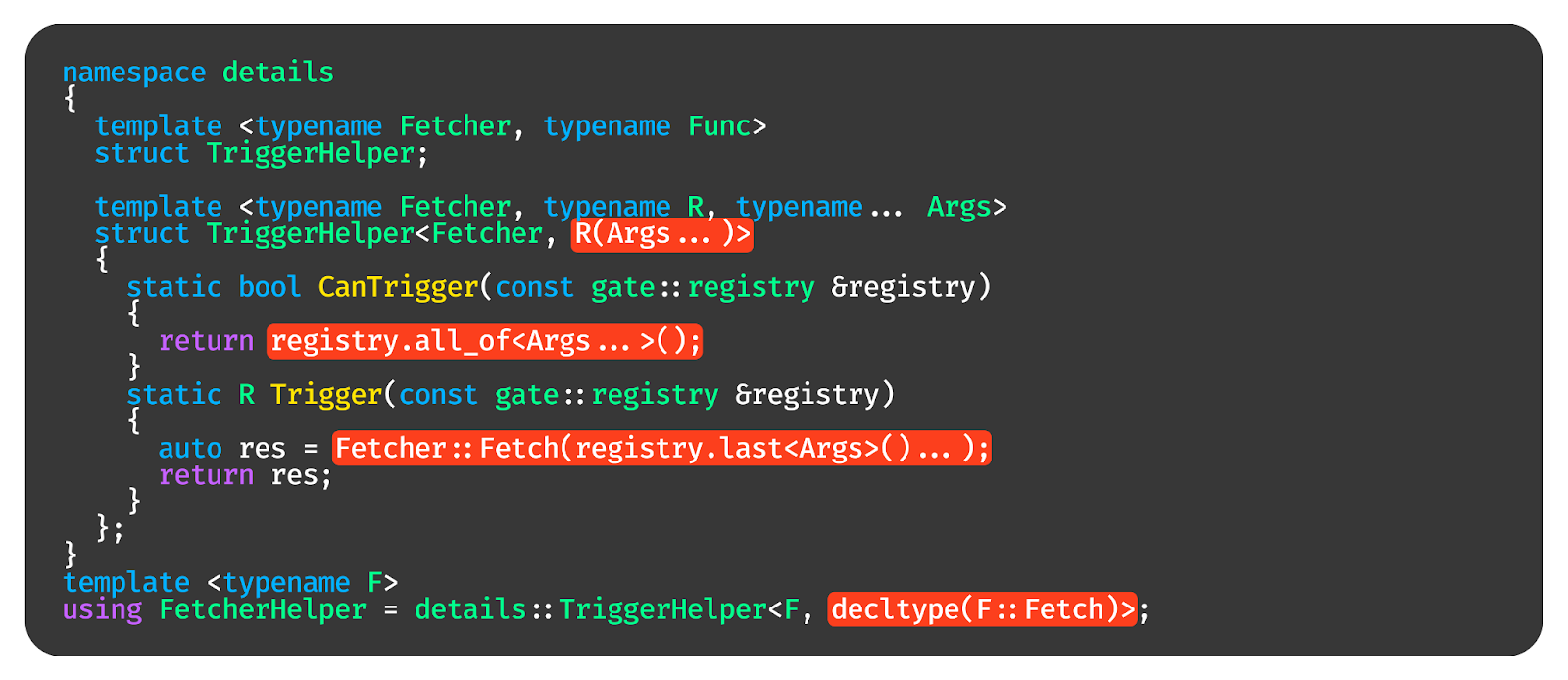
После чего мы можем сделать хелпер от любого типа, который будет в нём вызывать функцию, подставляя аргументы из registry.

Тут оно работает, потому что функция принимает только контексты. Но что делать, если у нас функция принимает event, клиент, настройки, библиотеку и что-нибудь ещё? Мы не можем всё положить в registry. Это может быть какой-нибудь singleton или штука, которую мы вообще не хотим хранить in-memory.
Gate (шлюз)
Для этого нам нужна обёртка поверх in-memory storage!
И здесь нам помогут концепты: пусть у нас будет некая обёртка, где есть dependency (в них хранятся кодогенерированные клиенты других сервисов), registry с in-memory сохранёнными данными, JSON с event, который мы в данный момент обрабатываем, и любые другие необходимые источники данных. Назовём эту обёртку «шлюз», или gate.
Создадим класс, в котором хранятся все нужные нам источники данных.

Есть ли у нас в этом шлюзе event типа T? Есть, если в JSON event kind совпадает с event_kind в типе T.

А контекст T у нас есть, если он находится в registry. А точнее, если в какой-то момент при создании шлюза мы загрузили из базы данных все JSON с контекстами, распарсили их, сложили в registry и у одного из этих сохранённых контекстов был тип T.

А DependencyType у нас есть всегда. DependencyType — это клиенты, кеши и прочие кодогенерированные структуры. Потому что если у нас есть этот тип, то кодогенерация положила его в общий список всех клиентов, доступных в нашем сервисе, — dependency.
Optional у нас тоже есть всегда. Если у нас его нет, то мы создадим пустой.

А теперь вспомним наш helper. Будем передавать в него не registry, а обёртку вокруг registry — шлюз, который будет проверять, можно ли запустить функцию. При этом функции могут быть аргументами любых типов, поддерживаемых внутри шлюза.
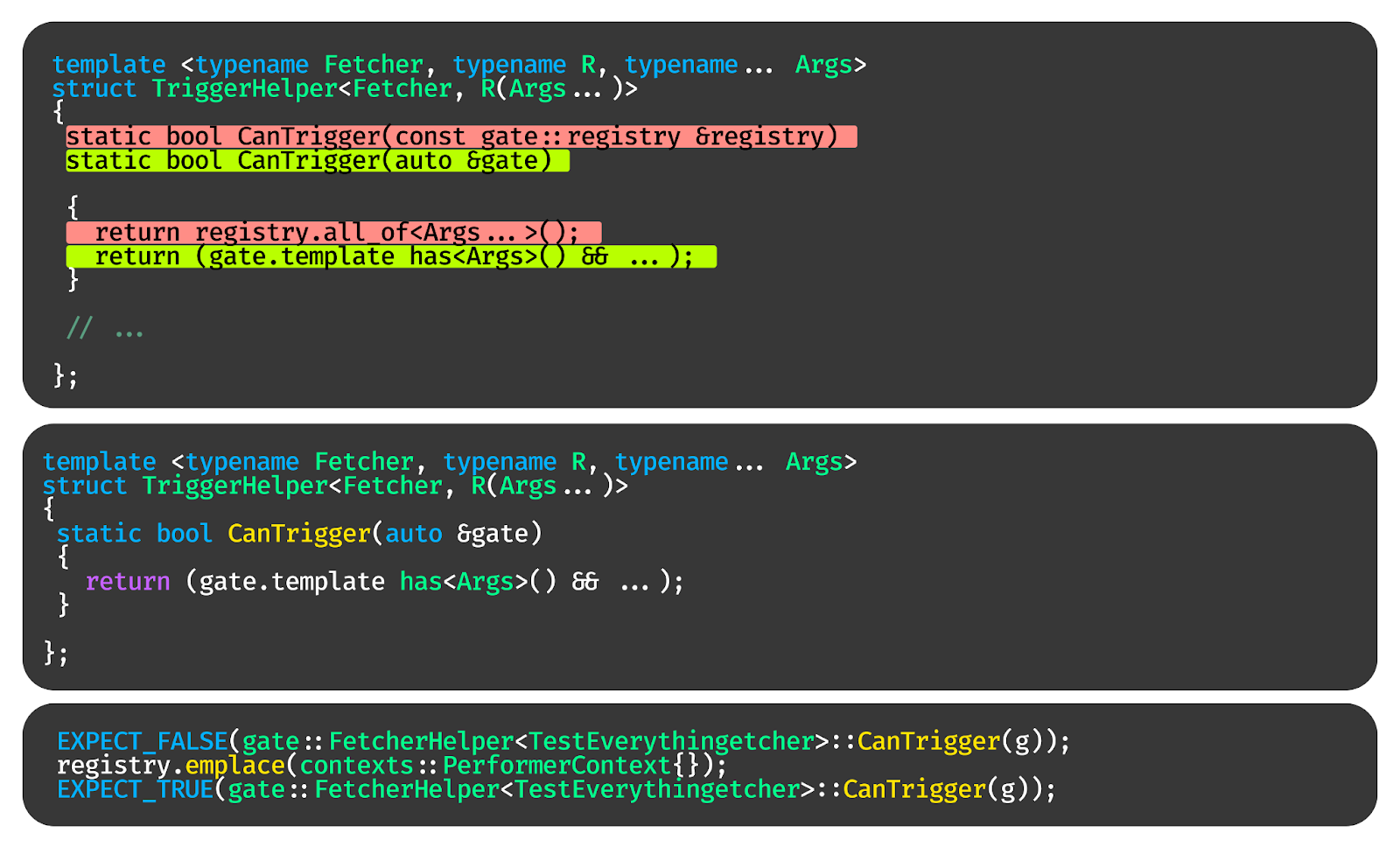
Как мы получаем объекты из шлюза? Тоже через специализации и контексты. Event парсим из JSON, контекст читаем из registry. Клиенты мы получаем из dependency.

С optional сложнее. Если у нас внутри шлюза есть тип optional<T>::value_type, то мы получаем этот объект из шлюза и помещаем в наш optional. Если нет, то возвращаем пустой optional. То есть рекурсивно используем сами себя.

И вот у нас есть функция, которая принимает на вход константную ссылку на event, опциональный контекст, константную ссылку на контекст и ссылку на клиент. И она нормально запускается через уже известную нам функцию Trigger в нашем хелпере.
Поздравляю — мы переизобрели фикстуры из Python!
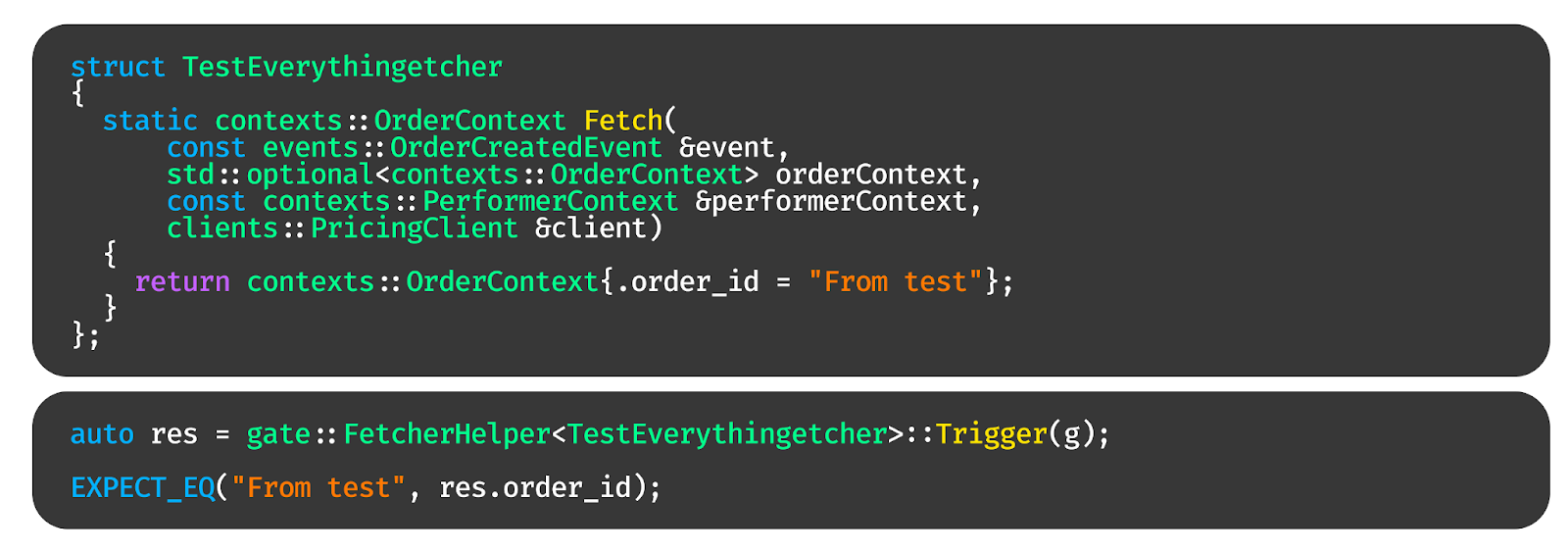
В какой-то момент понадобится расширить шлюз. Например, мы можем придумать какой-нибудь сложный концепт, который говорит, что тип T — это константная ссылка на вектор из контекстов.

Что нам нужно сделать, чтобы расширить шлюз? Добавляем две новые функции: первую, которая проверяет, что мы можем вернуть этот вектор, и вторую, которая возвращает вектор для этого концепта.

Заметьте, что для добавления функциональности мы ничего не удалили. Мы только добавляем код. Суетологи от мира паттернов разработки скажут вам, какая это буква из SOLID.
Итого шлюз нормально расширяется. Мы можем с его помощью запускать произвольные функции с произвольным количеством аргументов.
Но как мы знаем, дела, пущенные на самотёк, имеют тенденцию развиваться от плохого к худшему. Рано или поздно у нас появятся обработчики, принимающие на вход 50+ зависимостей, и станут абсолютно нечитаемыми.
Чтобы этого не случилось, нам надо оставить разработчикам возможность группировать аргументы и выделять общие куски обработки в библиотеки. Например, у нас в зависимости от некоторых внутренних параметров контракт может лежать в шести разных микросервисах. И мы хотим вынести логику получения контракта в некоторую стороннюю библиотеку. Мы называем её toolkit.

Toolkit
Toolkit — структура, в которой есть полезные функции. Например, получить кошелёк у курьера либо получить контракт — что-то подобное. В отличие от обычной библиотечной функции, здесь есть статическая функция MakeToolkit, которая и создаёт toolkit. То есть статическая функция, которая генерирует нам полноценную библиотеку из кучи клиентов.

А дальше по методу чайника задача решается через предыдущую. Мы можем на основе этой информации о классе определить концепт. Toolkit — это класс с функцией MakeToolkit, которая возвращает этот самый toolkit. И добавить в шлюз возможность его генерации toolkit «на лету».
А раз это статическая функция, значит, для неё мы можем определить хелпер, который проверяет, можем ли мы сконструировать toolkit из тех аргументов, которые у нас есть в шлюзе. Если можем, то создаём его.

Затем в самом обработчике или фетчере мы удаляем четыре клиента и заменяем их на библиотеку.

Особенно здорово, что аргументом для создания toolkit может быть другой toolkit. Он точно так же будет пытаться конструироваться через наш шлюз, а у него могут быть свои toolkit в виде аргументов и так далее.
Таким образом, мы строим иерархию наших библиотек, которые при этом мы явно не поддерживаем. Мы просто подставляем функцию и говорим компилятору: «А собери-ка нам всё, что нужно для создания такой библиотеки».
Пайплайн
Получается, что здесь мы только что добавили в прокси до инфраструктуры буквально всё, что угодно. Хотим библиотеки — будут библиотеки, хотим события — будут события, хотим данные, которые мы сохраняем, — будут данные.
И всё, что нам осталось, — это сделать движок, который сумеет запустить бизнес-логику в правильном порядке.
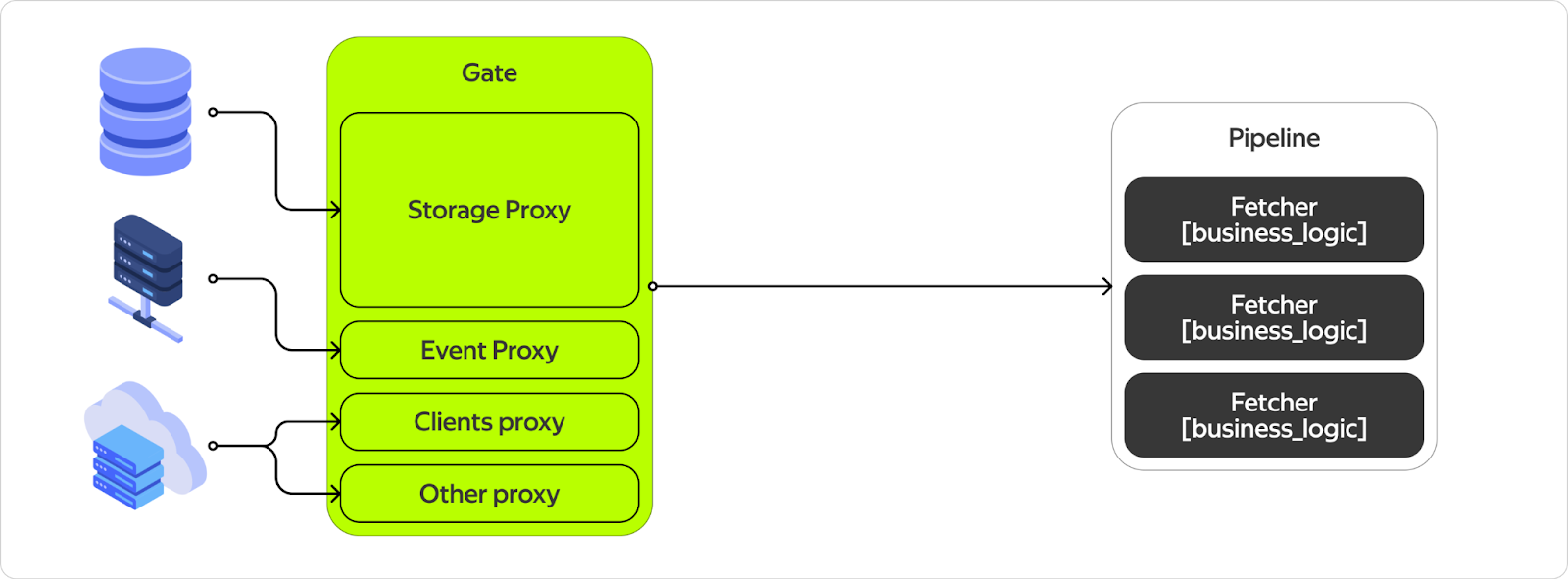
Нам нужна прослойка, которая по входящему событию найдёт, какие функции должны быть запущены. По контекстам, которые они генерируют, — какие функции надо попытаться запустить, чтобы пересчитать зависимые контексты. А платежи, которые функции генерируют, — отправить в сервисы оплаты.
И казалось бы, это сложно, но на самом деле, когда у нас есть список этих функций, это очень просто. Вот у нас есть пайплайн.
Это класс от структур обработчиков. Давайте рассмотрим один обработчик (Fetcher) и обработаем его в функции ProcessOne. Должны ли мы запустить функцию Fetch из этого обработчика? Проверяется это легко. Если мы можем запустить, мы запускаем — всё.

Логика следующая. Если функция не обрабатывает событие, которое только что пришло, то CanTrigger вернёт false, потому что шлюз скажет: «У меня нет сейчас этого события, которое мы обрабатываем». Если функция обрабатывает несколько контекстов, то она сможет запуститься только тогда, когда все контексты будут сформированы, а значит, до генерации контекста CanTrigger тоже вернёт false. Ровно то, что нам и надо.
Дальше — fold expression и запуск функции ProcessOne для всех фетчеров, которые объявлены в этом пайплайне.

Логика запуска пайплайна будет готова буквально за несколько строчек.
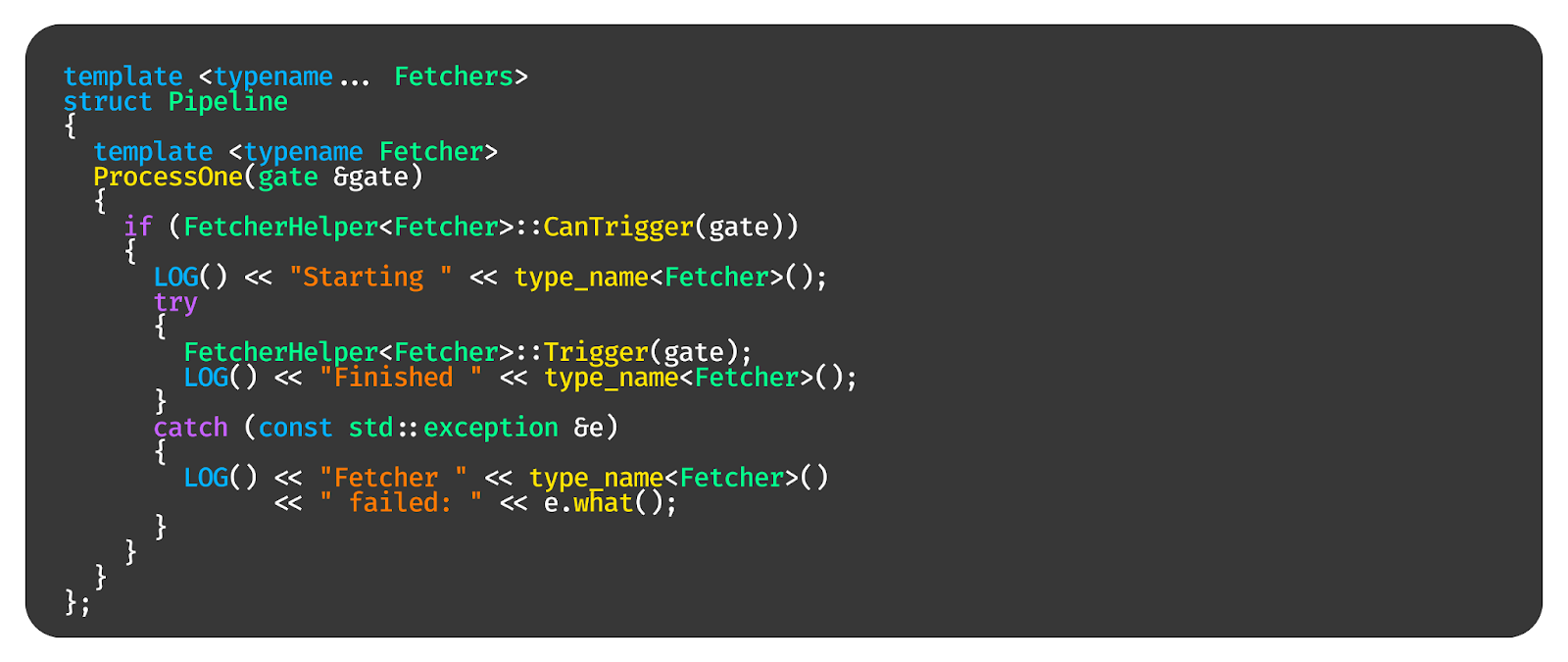
И вот как выглядит наш интерфейс в коде. Для тех, кто делает бизнес-логику, — это просто функции. То, что им надо, они указывают в аргументах, и это им автоматически придёт. То, что им надо сохранить или отправить, указывают в возвращаемом значении — оно сохранится или отправится. Собирают эти функции в пайплайн, и он сам по себе запустится.
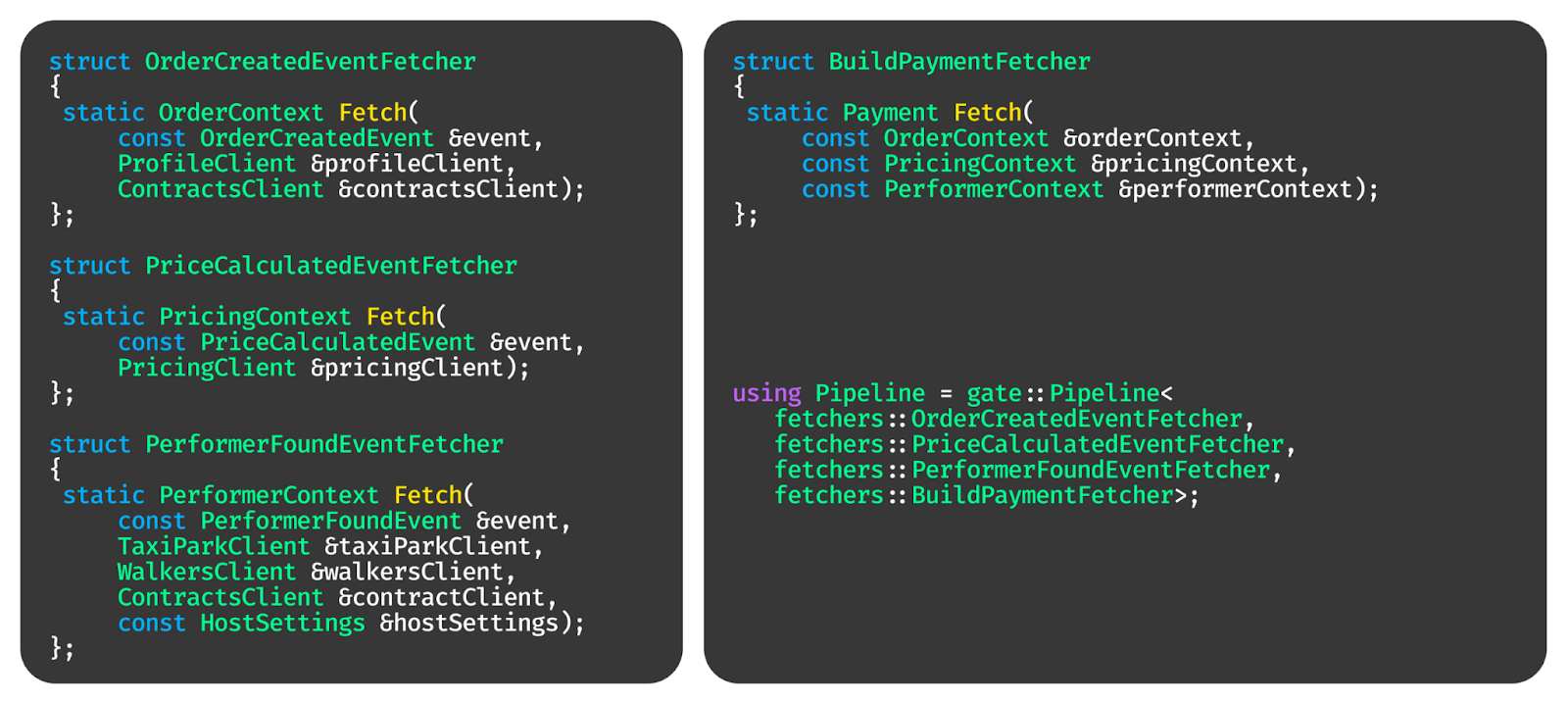
А ещё поверх этой штуки можно натащить разных интересных статических проверок, которые за счёт концептов покажут, что не так в коде.
Или сделать какие-нибудь сложные штуки. Например, у нас есть статическая проверка, что фетчеры правильно топологически отсортированы. То есть если функция-обработчик принимает контекст, то этот контекст был сгенерирован фетчером, который был до него, а не после. И если это не так, код сразу не скомпилируется.
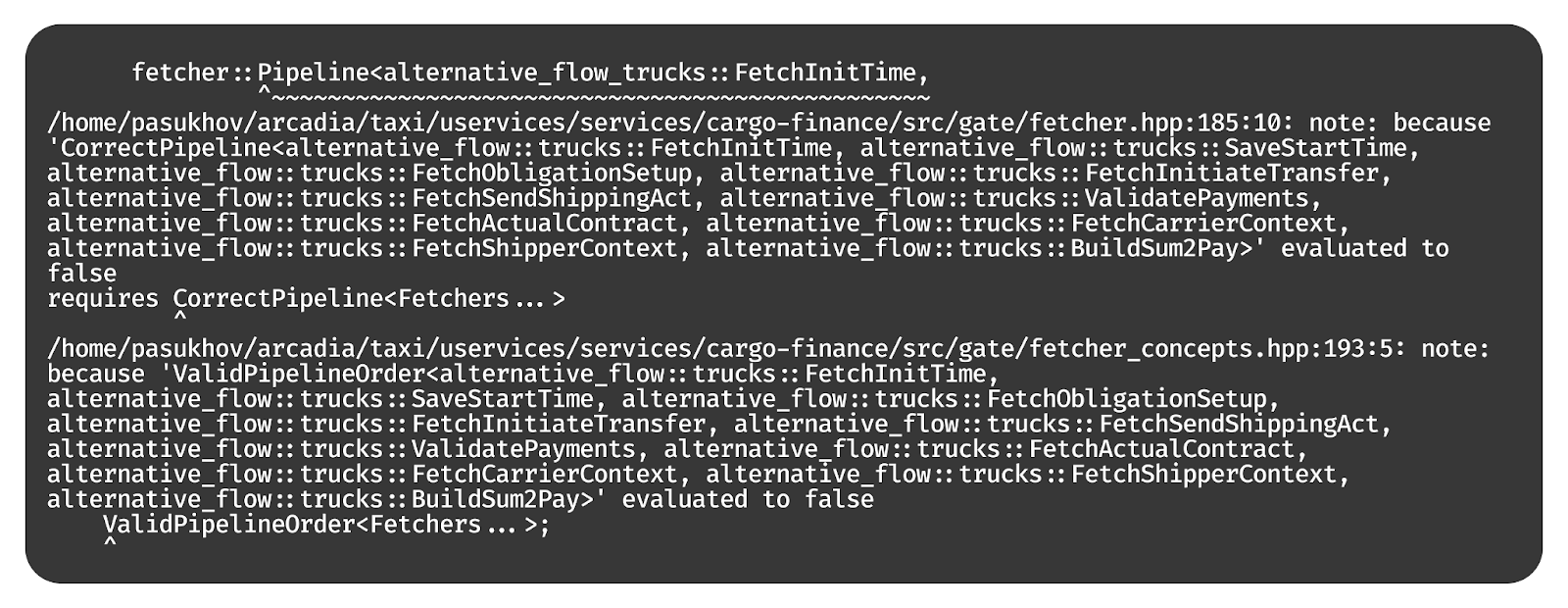
Ещё можно запускать только нужные обработчики. Мы можем поставить отдельное условие, которое говорит, что мы запускаем обработчик, принимающий на вход контексты только в том случае, если хотя бы один из них поменялся.
Мы можем также реализовать ProcessingDisabled — отдельные настройки пайплайна. То есть выключить вручную отдельные обработчики и в рантайме манипулировать всеми обработчиками без участия тех, кто пишет бизнес-логику.

Кроме того, мы можем сделать необязательные статические переменные внутри наших классов-фетчеров, которые будут менять логику запуска этого фетчера внутри нашего пайплайна. Например, AlwaysRebuild, которое обходит то, что мы сделали в прошлом примере с кодом.

Или мы можем сделать несколько абсолютно разных шлюзов в абсолютно разных местах, а потом склеить их в один (но придётся помучиться с CRTP). И есть свои тонкости насчёт конструкторов. Но у нас это работает: мы уже переписали код, и теперь наши шлюзы склеиваются из разных маленьких подшлюзов.

Концептуальная идея этой статьи в том, что настоящая инженерия — это не про то, как сделать преобразование одного JSON в другой, а про то, как создать инструмент для удобного преобразования. Он должен упрощать какие-то частые, типовые изменения. Но чтобы сделать где-то просто, где-то ещё придётся сделать сложно.
И вот для этого «сложно» (для создания инструментов, а не финальной программы) вам потребуются продвинутые языковые инструменты. И возможно — разной степени «грязности» трюки и тонкости языка.
И надеюсь, некоторые из показанных в статье трюков вам однажды пригодятся.



