
Привет! Меня зовут Василий Дмитриев. За последние пять лет я успел поработать над водительским приложением, приложением для медиков во времена пандемии — «Помощь рядом», запустил проект по биконам для команды Еды: курьеры, которые участвовали в эксперименте, стали в среднем в два раза быстрее получать заказы в ресторанах. При этом время с момента, когда заведение начинает готовить блюда, до их выдачи доставщику уменьшилось в среднем на 25%. В общем, успел уже много чего сделать. Много писал на Swift и Dart, а сейчас в свободное время активно продвигаю Flutter. Ещё я успел окончить курсы ML в ШАДе, и эти знания сейчас здорово помогают мне в работе.
Но сегодня я хочу рассказать не о Flutter, а о проекте DutyGPT, который родился в нашей команде в марте 2024 года. Представьте ситуацию: в трекер падает новый тикет. Чтобы понять, какая команда должна им заниматься, разработчику нужно перелопатить кучу документации, вспомнить все зоны ответственности смежников, а иногда и поучаствовать в дискуссии на 20+ комментариев в стиле «кто крайний?». Знакомо? Мы столкнулись с тем, что даже при ручной маршрутизации людьми, точность таких тикетов составляла всего 67%. Люди тратили ценное время на рутинные задачи, которые к тому же выполнялись не идеально.
Мы задались вопросом: а можно ли сделать так, чтобы разработчики вообще не тратили время на разметку тикетов, и при этом ещё и повысить точность обработки? Так и появился DutyGPT — наш внутренний сервис, цель которого — автоматически определять нужную команду для каждого нового тикета. Давайте расскажу, как мы к этому пришли и чего добились.
Первые шаги и поиск лучшей модели
Итак, мы поняли, что ручная разметка тикетов — это долго, не всегда точно и отнимает много времени у разработчиков. Естественным шагом было попробовать автоматизировать этот процесс с помощью машинного обучения.
На старте мы решили не изобретать велосипед и обратились к коллегам из команды Support GPT. У них уже была готовая инфраструктура и ML-инструменты, заточенные под похожие задачи. Мы договорились о сотрудничестве и запустили первую версию DutyGPT на их основе. Внутри там крутилась модель на базе BERT, обученная на наших данных.
Мы запустились, но первые результаты, честно говоря, очень расстроили. Точность автоматической разметки оказалась заметно ниже изначальных 67%, которые показывали люди. Конечно, было неприятно, но мы не из тех, кто сдаётся после первой неудачи. Мы верили, что потенциал у ML-подхода есть. Нужно было только накопить побольше данных для обучения и поработать над развитием самих моделей.
Пока система работала на решении от Support GPT, я параллельно начал проводить локальные эксперименты. Благо, на Hugging Face огромное количество предобученных моделей — те же BERT и другие архитектуры. Я пробовал разные варианты, обучал их на наших данных и сравнивал результаты. И довольно скоро стало понятно, что некоторые из этих open-source моделей локально показывают качество лучше, чем то, что мы получали от первоначальной модели.
Примерно в это же время в Яндексе стали активно появляться и обсуждаться внутренние инструменты для дообучения классификаторов на базе YandexGPT. Я провёл тесты, сравнив результаты дообученного YandexGPT с тем, что давала модель Support GPT и мои локальные эксперименты. И YandexGPT показал гораздо лучшее качество на наших задачах.
Как работает DutyGPT сегодня: архитектура и процесс обучения
В основе DutyGPT лежит классификатор YandexGPT. Мы взаимодействуем с ним через API облачной платформы Яндекса. Для управления самим процессом обучения мы используем библиотеку MLSDK. Благодаря этому мы можем самостоятельно настраивать гиперпараметры модели, запускать эксперименты с разными конфигурациями и после обучения выбирать лучшую модель на основе объективных метрик.

Теперь о данных, на которых мы обучаем наши модели. Всё начинается с трекера — нашей системы управления задачами и тикетами. У каждой команды, подключённой к DutyGPT, есть свой фильтр в трекере, который позволяет выгрузить исторические тикеты, относящиеся именно к этой команде, за определенный период. Мы проходимся по этим фильтрам и собираем данные.
Ключевой момент: из всего многообразия информации в тикете нас интересуют только два поля — заголовок (title) и описание (description). Мы сознательно решили не использовать комментарии или другие кастомные поля, чтобы модель фокусировалась на сути проблемы, изложенной автором тикета. Именно эти два текстовых поля и становятся входом для нашей модели.
Сам процесс обучения довольно классический для таких задач. Мы собираем данные для команды и формируем два датасета: один для обучения модели, другой — для её последующей проверки. Затем запускаем сам процесс обучения. Обычно мы экспериментируем и для одной команды запускаем примерно 5–7 моделей с разными параметрами. Когда обучение заканчивается мы анализируем их результаты по различным метрикам и выбираем ту модель, которая показала лучшие данные именно по нужным нам метрикам. Она и отправляется в продакшн.
Благодаря нашей внутренней инфраструктуре, подключение новой команды к DutyGPT — процесс довольно быстрый. Нам достаточно добавить в конфигурацию сервиса идентификатор команды и ID обученной для неё модели. После этого DutyGPT начинает автоматически обрабатывать новые тикеты, поступающие в указанную очередь. Наш сервис умеет реагировать на создание новых тикетов практически в любой очереди трекера — у нас есть триггеры и автоматика, которые можно настроить под нужды конкретной команды.
Что умеет DutyGPT и каких результатов мы достигли
Итак, мы полностью перешли на YandexGPT, наладили процесс обучения и выкатки моделей. Что же конкретно умеет делать DutyGPT для команд, которые к нему подключены?
Наш сервис решает несколько ключевых задач:
- Автоматическая маршрутизация. Основная функция — реагировать на новые тикеты в заданной очереди и проставлять в них нужный компонент или тег. Какую именно метку использовать, зависит от потребностей конкретной команды.
- Призыв дежурного. Если команде нужно, чтобы при назначении компонента или тега автоматически призывался дежурный инженер, DutyGPT умеет это делать, используя нашу внутреннюю систему дежурств «ABC».
- Запись дополнительной информации. Недавно мы добавили возможность записывать в локальные поля тикета кастомную информацию — это могут быть логи работы сервиса или какие-то специфические пометки, нужные команде. Для этого потребуется небольшая настройка полей в самой очереди трекера.
Как видите, мы стараемся максимально автоматизировать рутинные действия вокруг обработки нового тикета. Но тут встаёт другой вопрос: как понять, что наш сервис действительно справился хорошо?
Мы очень внимательно следим за точностью работы DutyGPT. У нас есть чёткое правило: мы считаем, что тикет размечен правильно, только если выполняются два условия:
- Тикет закрыт.
- В тикете стоит единственная метка — компонент, тег или другая, которую модель обучалась ставить, и эта метка верна.
Почему так строго? Иногда бывает, что на тикет ставят метки сразу нескольких команд. У нас для этого даже есть отдельный статус «multiple teams». В таких случаях мы не можем однозначно сказать, угадал наш сервис или нет. Мы отслеживаем такие ситуации на внутренних дашбордах и просим команды помочь с доразметкой. Это помогает нам не только чистить данные для будущих обучений модели, но и лучше понимать сложные кейсы.
А теперь самое интересное — результаты. Помните, я упоминал, что изначальная точность ручной разметки разработчиками была всего 67%? Так вот сегодня DutyGPT размечает тикеты лучше, чем это делали люди.
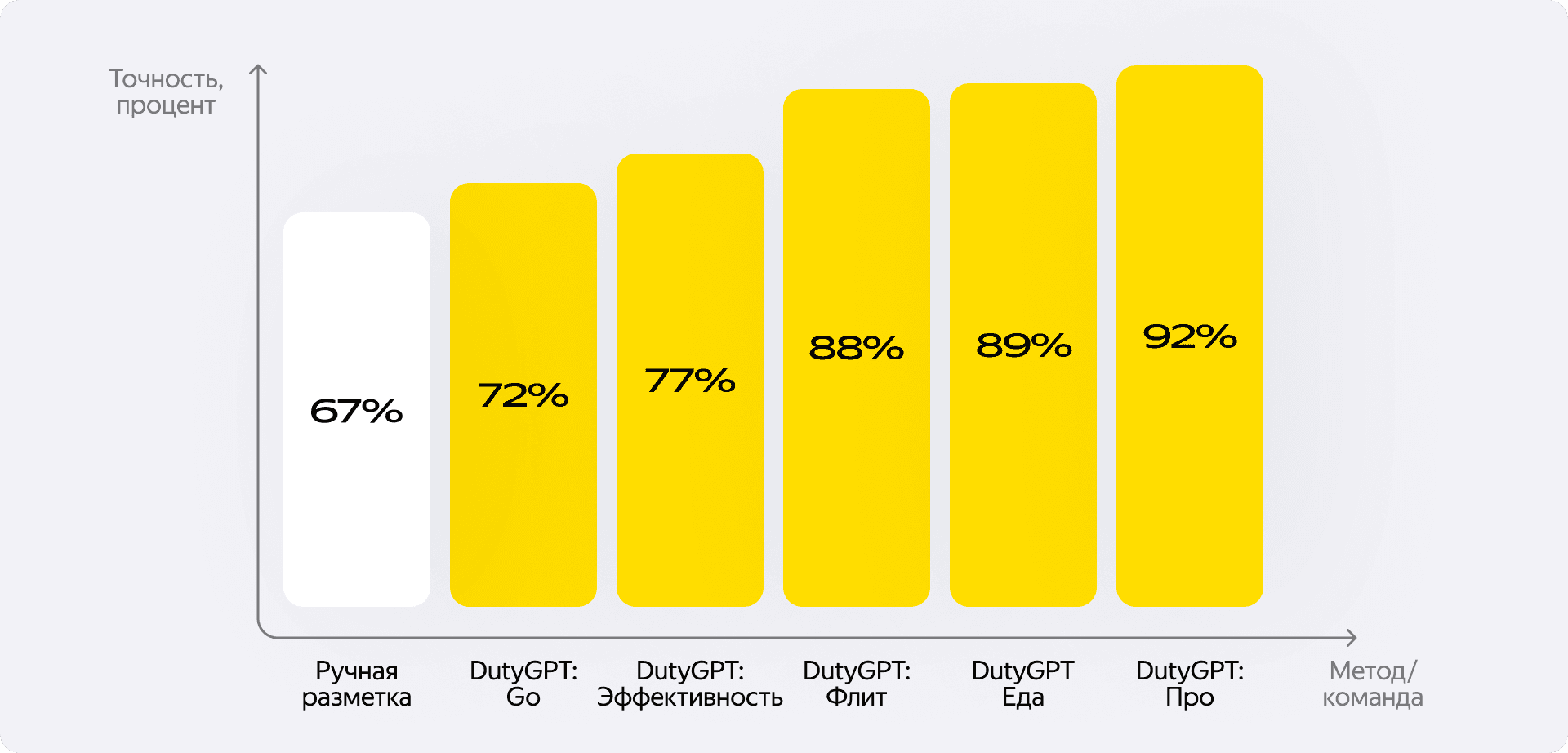
Мы начинали с одной команды — Яндекс Про. Сейчас к сервису подключены уже несколько команд. И вот какие показатели точности мы видим в наших дашбордах за последний месяц:
- Про: 92%
- Go: 72%
- Эффективность: 77%
- Еда: 89%
- Флит: 88%
Ещё подключили команду Доставки, но по ней пока не собрали достаточного количества метрик. Впрочем, когда делали прогон на тикетах за день, которые модель до этого не видела, то правильно разметили 13 из 14 тикетов — это 92%
Понятно, что точность — не статичный показатель: она продолжает расти по мере того, как мы дообучаем модели на новых данных и улучшаем процессы. Но уже сейчас с уверенностью можно сказать, что мы смогли избавить разработчиков от рутинной задачи и добились лучших результатов с помощью ML.
Поиск похожих тикетов с помощью RAG
Автоматическая маршрутизация тикетов была нашей первой и основной задачей. Но по мере подключения новых команд к DutyGPT стали появляться и новые запросы на функциональность. Один из самых частых — «А давайте научимся автоматически находить похожие тикеты к только что созданному?».
Дело в том, что сейчас поиск дубликатов или похожих проблем часто выполняется вручную. Этим занимаются не только разработчики, но и другие сотрудники, тратя время на изучение истории тикетов. Мы решили, что это тоже отличный кандидат на автоматизацию, и здесь нам на помощь приходит технология RAG — Retrieval-Augmented Generation.
Если коротко, RAG-платформа позволяет создать индекс из ваших документов, в нашем случае — старых тикетов, и затем быстро находить в этом индексе документы, семантически близкие к вашему запросу. У RAG есть и более продвинутые возможности, например, генерация текста на основе найденных документов как это делает другой внутренний проект, используя YandexGPT. Но для нашей задачи достаточно первой части — эффективного поиска и извлечения похожих тикетов.
Как мы планируем это реализовать в DutyGPT
- Индексация. Для каждой команды, которая захочет использовать эту фичу, мы предварительно загрузим и проиндексируем её старые тикеты в RAG-платформе.
- Запрос. Когда в трекере появляется новый тикет, DutyGPT берёт его заголовок и описание.
- Поиск. DutyGPT отправляет эту информацию в RAG-платформу в качестве поискового запроса к индексу тикетов этой команды.
- Извлечение. RAG-платформа находит и возвращает список наиболее похожих тикетов из индекса. Мы можем настроить, сколько тикетов возвращать и какой порог схожести использовать.
- Линковка. Получив этот список, DutyGPT просто использует API трекера, чтобы прилинковать найденные похожие тикеты к новому, свежесозданному.
В итоге мы получаем двойную пользу: DutyGPT не только определяет правильную команду для тикета, но и сразу же предоставляет разработчикам ссылки на похожие проблемы, которые могли возникать и решаться ранее. Это должно значительно упростить диагностику и ускорить поиск решения.
Мы уверены, что, как и в случае с маршрутизацией, через некоторое количество итераций и дообучений автоматический поиск похожих тикетов с помощью RAG станет эффективнее и точнее, чем ручной поиск, который используется сейчас. Это наш следующий шаг к тому, чтобы избавить инженеров от рутины и позволить им сфокусироваться на разработке.
Заключение
Вот так, начав с понятной и довольно ощутимой проблемы — неэффективной ручной маршрутизации тикетов с точностью всего 67% — мы пришли к созданию DutyGPT. Путь был не совсем прямым: мы стартовали с одних ML-решений, экспериментировали с другими, пока не нашли оптимальный для нас вариант в виде дообученного классификатора YandexGPT.
Сегодня DutyGPT успешно справляется с автоматической разметкой тикетов для нескольких команд, проставляет нужные компоненты или теги и даже призывает дежурных. И самое главное — он делает это точнее, чем делали люди вручную, достигая показателей в 77%, 89% и даже 92% для разных команд, и эти цифры продолжают расти.
Конечно, такой сервис — это не работа одного человека. Хочу сказать спасибо коллегам, которые помогали и помогают проекту. Например, большую помощь с настройкой всей необходимой инфраструктуры, интеграцией с ботами и системой алертов оказал Алексей Шведчиков, пока я мог сфокусироваться на экспериментах с моделями и ML-части DutyGPT. А разработкой именно механизма поиска и линковки похожих тикетов, в том числе с использованием RAG, сейчас занимается Даниил Чашков.
Наш опыт с DutyGPT наглядно показывает: современные ML-подходы, будь то классификация текста или семантический поиск с помощью RAG, — это мощные инструменты, которые действительно способны взять на себя рутинные, но важные задачи.



