

Про микросервисную архитектуру и переход на неё написаны сотни статей, однако почти все они больше теоретические и описывают ситуацию лишь верхнеуровнево. Редко где прочтёшь про то, как люди бесшовно вынесли высоконагруженный кусок монолита в отдельный сервис без даунтайма и факапов или даже с ними. Интересно узнать, какими же инструментами они пользовались, как подготавливались, каких подходов придерживались и какие выводы на будущее сделали. Всё это — полезный опыт, который может помочь избежать проблем. Вот я и подумал, что стоит им поделиться.
В прошлой статье я рассказывал о том, как мы обновляли версию PHP в нашем монолите. А сегодня я хочу показать, как же мы от него избавляемся. Под катом расскажу об инструментах и подходах, которые мы используем.
Эта статья основана на моём выступлении в рамках совместных митапов Яндекс Еды и Яндекс Лавки, которые проходили в разных городах. Если вам проще воспринимать информацию на слух, то запись можно посмотреть по ссылке. Хотя в статье будет немного больше информации.
Краткая история
Для погружения в контекст расскажу небольшую историю нашего сервиса:
- 2015 год. Стартовал проект FoodFox. Как и любой стартап, он развивался бурно, в каких‑то местах срезались углы — главное было победить конкурентов.
- 2017 год. Яндекс покупает стартап и приводит туда много новых разработчиков. Кода становится всё больше и больше.
- 2020 год. Приходит понимание того, что можно расти намного быстрее, если использовать уже существующие наработки команды разработчиков Яндекс Такси. На тот момент основной язык этого сервиса был С++, и почти все микросервисы были написаны на нём с применением фреймворка userver. Тогда мы решили по возможности реализовывать всю новую функциональность на C++. Все PHP-разработчики пошли учить плюсы — я в том числе.
- 2023 год. В Яндекс Еде больше 180 микросервисов. И всё ещё большой монолит. Теперь его существование очень мешает, поэтому мы начали активную фазу его распила.
Приглядимся к монолиту
Чтобы показать вам, с чем мы имеем дело, я попробовал оценить сложность проекта. Для анализа воспользовался инструментами: PhpMetrics, PhpLoc и PhpInsights. Например, так выглядит эволюция сложности сервиса с 2015 года. Подробнее про график — в книге «Чистая архитектура».
Эволюция
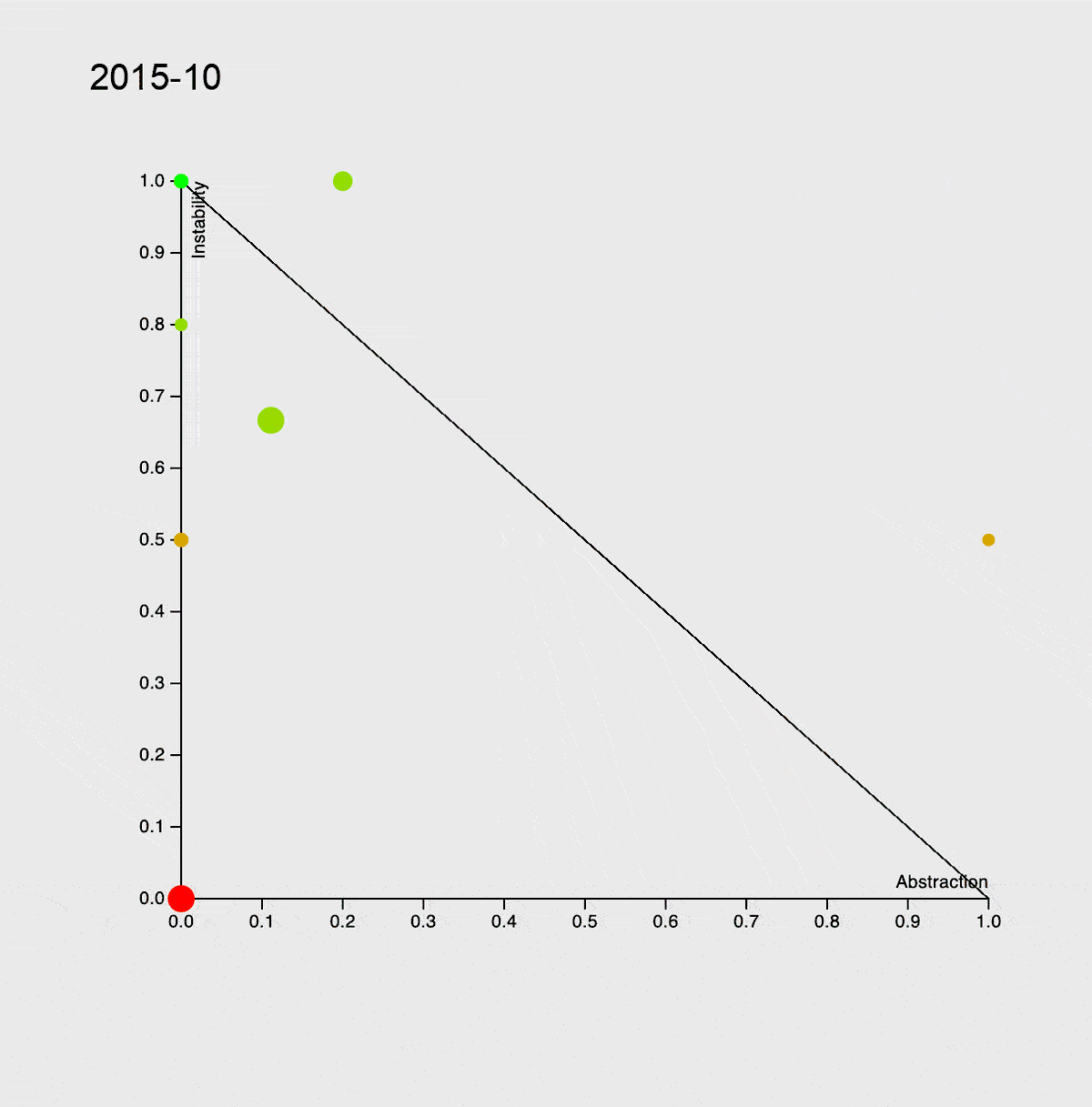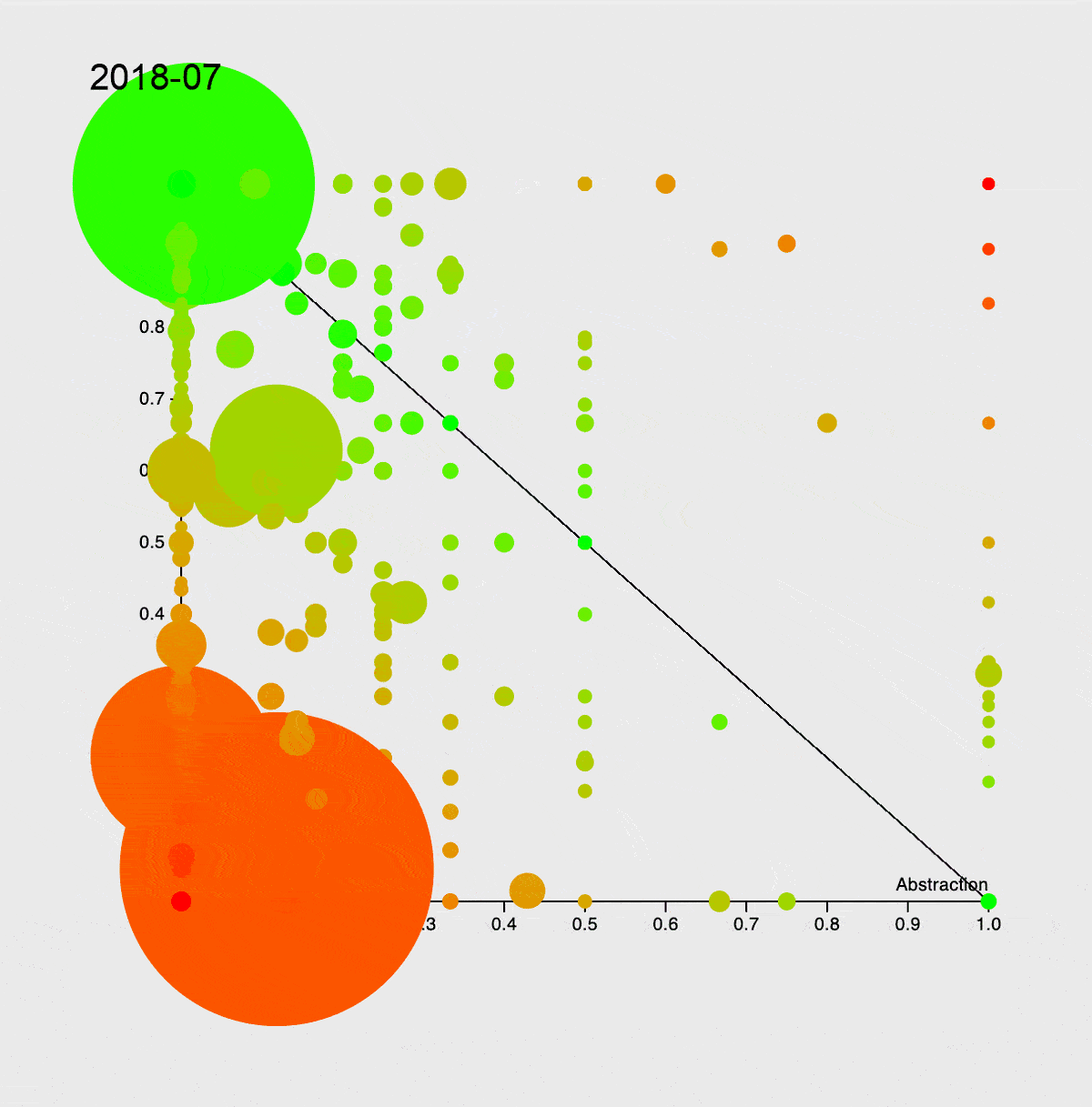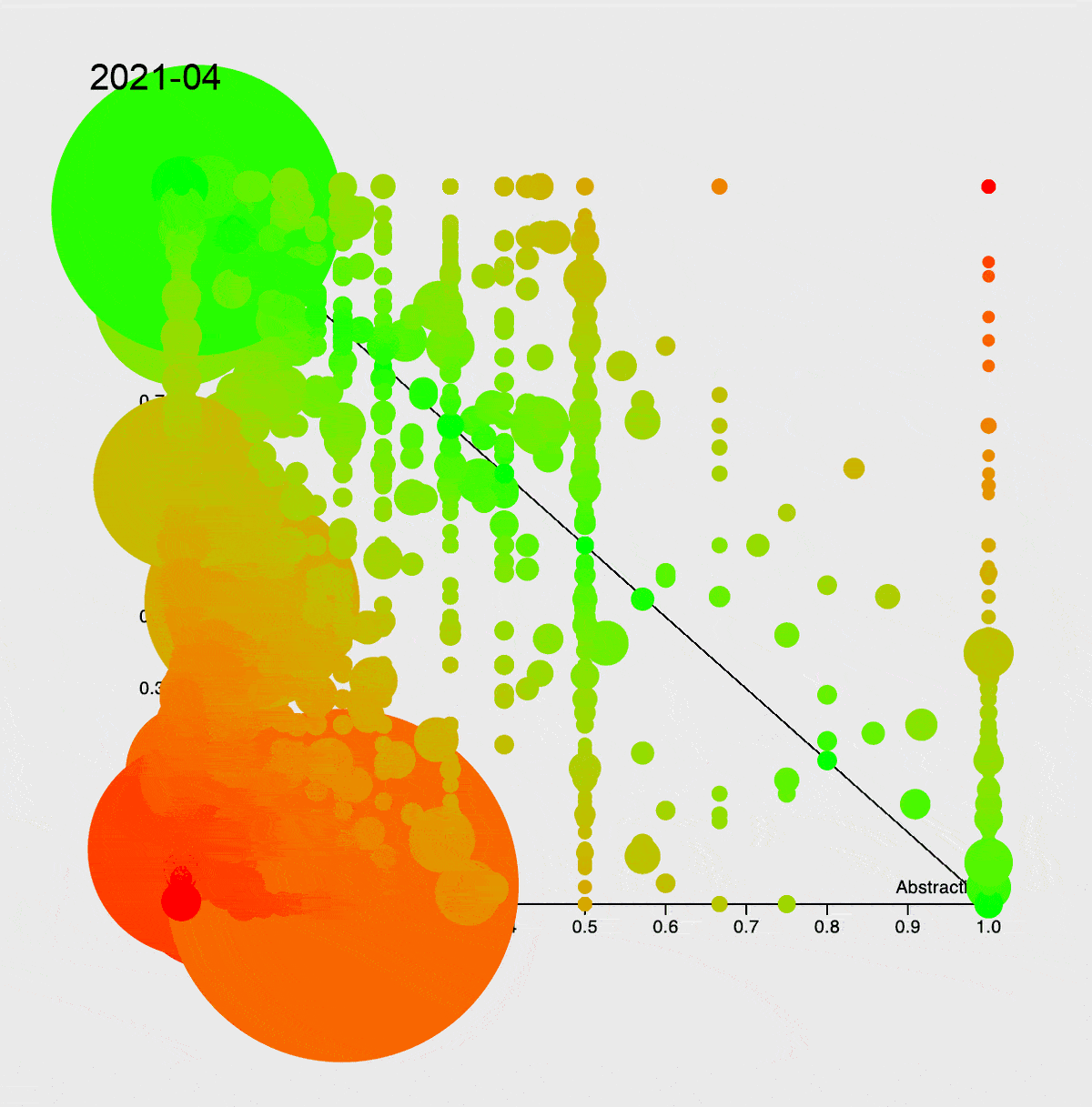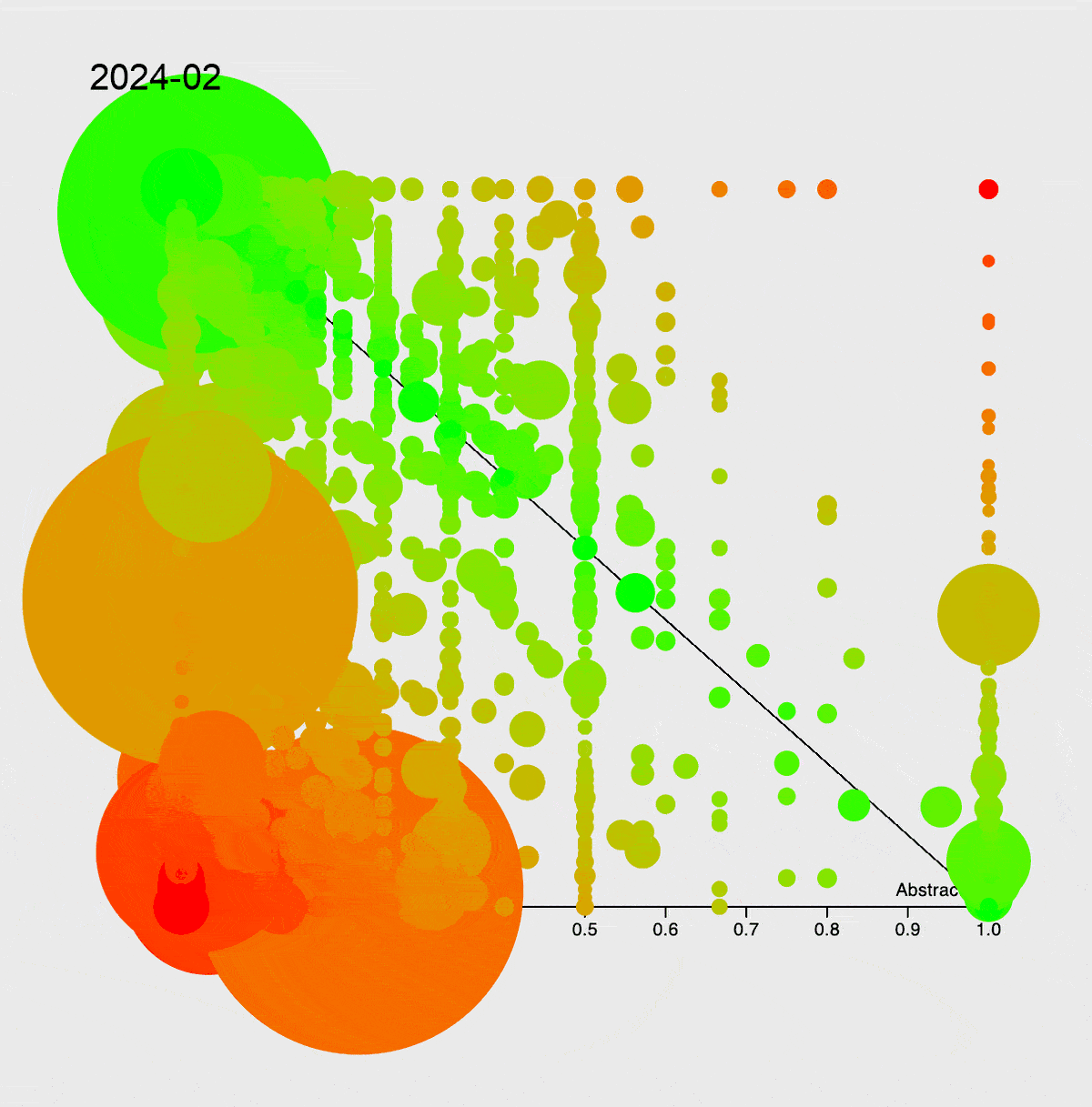
Стоит отметить, что самые большие красные круги — это Entity и Dto, которые, естественно, передаются без использования интерфейсов, что и приводит к такой сильной связности. Никто же не думает о распиле монолита в самом начале, а когда наступает время, приходится много рефакторить, в том числе подменять использование конкретного объекта работой с интерфейсом.
Текущее состояние:
| Метрика | Значение |
|---|---|
| Average Complexity per LLOC | 0,23 |
| Average Complexity per Class | 4,50 |
| Maximum Class Complexity | 285,00 |
| Average Complexity per Method | 1,84 |
| Maximum Method Complexity | 147,00 |
Наш стек и нагрузка:
- Язык: PHP8,
- Фреймворк: Symfony6,
- БД: MySQL,
- Средний RPS: ~3000.
Так чем же нам мешает монолит? Вопрос, скорее, риторический. С монолитом вполне можно ужиться, но это очень сложное соседство. В нашем случае в пользу распила было несколько причин.
Отсутствие экспертизы. Так как мы начали переходить на C++, людей, умеющих и желающих писать на PHP, с каждым месяцем становится всё меньше и меньше. Экспертов, которые знают, что и как устроено в нашем монолите, можно пересчитать по пальцам.
Проблемы с релизами. Релизы у нас выходят ежедневно. И когда релизится от 17 до 70 пул‑реквестов в день, вероятность того, что что‑то пойдёт не так, очень высока. В итоге из‑за частых проблем они доезжали не каждый день, и к тому же на релизный флоу отвлекалось много разработчиков, чтобы понять, в чьём пул‑реквесте скрылась проблема.
Сложность кода. Код тоже становился всё сложнее и запутаннее. Входной порог для разработчиков рос, а разработчики, как я и говорил, уже забывали PHP и переходили на C++. К тому же сложность кода обусловлена большой заложенной функциональностью и большим объёмом легаси.
Зона ответственности. Со временем зона ответственности размывается, и сложно контролировать, кто за что отвечает. По логике, если что‑то есть в конкретном сервисе, то за это отвечает тот, кто отвечает за весь сервис. Другими словами, бесхозных сервисов нет. А вот в монолите есть условная табличка в БД, которую используют одновременно пять команд. Но кто за неё отвечает? Непонятно.
Локальное развёртывание. Развернуть монолит в Docker на маке локально стало проблематично — требовались мощные машины.
В общем, жизнь с таким набором проблем — не сахар. Да и в целом эти вещи тормозят развитие сервиса. А нам нужно улучшать метрику time‑to‑market. Но перед тем, как засучивать рукава и браться за инструмент, нужно подумать над тактикой и стратегией.
Итак, мы решили распилить монолит
Во всяком серьёзном деле нужен подготовительный этап. Поэтому дальше я дам несколько советов тем, кто хочет заняться обновлением архитектуры своего сервиса. Надеюсь, что они помогут обойти те грабли, которые могут встретиться на этом тернистом пути. Возможно, не всё будет актуально именно для вашего монолита, но в целом все советы ниже достаточно универсальны.
Сложности, с которыми вы столкнётесь
- Вам нужно будет редактировать очень много кода, который влияет на весь проект. Как минимум вам придётся выпиливать базовые сущности и подменять их DTO того же интерфейса.
- Нужно расцеплять связанность объектов БД и выносить работу с ними за интерфейс. И это не всегда простая задача. Иногда приходится полностью пересматривать реализацию функциональности, потому что выпил таблички из джойна приводит к сильной деградации по производительности. А табличку выносить всё ещё нужно.
- Нужно продумать множество планов для разных ситуаций. Например, как правильно всё это тестировать. Ведь вы будете вносить изменения в кучу кода и создавать пул‑реквесты на тысячи строк, потому что всё связано и нельзя выпилить по одному. Здорово, если у вас 100% покрытие тестами, но, к сожалению, на практике это не всегда так.
- Придумать, как сохранить схему API в новой парадигме для старых клиентов. Ведь вы не всегда просто выносите as is, а думаете наперёд и немного можете менять логику или даже парадигму работы кода.
- Придумать, как убедиться, что старая и новая функциональности работают одинаково. Например, эндпоинты списка адресов могут отдавать одинаковый список, но немного не в том порядке. Или дедупликация происходит немного по‑разному. Иногда это неочевидно: вроде всё работает, ошибок нет, но потом приходит продакт‑менеджер и говорит, что всё изменилось и нужно это исправлять.
- Предусмотреть вариант, как откатить переключение, если что‑то пошло не так. Как оказалось, не всегда есть готовый план Б.
Что нужно сделать, чтобы распил прошёл успешно
Наши команды постепенно выносили свою функциональность в отдельные сервисы. При этом все использовали разные подходы и с разной степенью успеха. Такая ситуация приводила к тому, что каждая команда набивала свои шишки на одних и тех же граблях.
Мы постарались подойти к этому вопросу более системно. Перед активным распилом монолита мы поработали над его устойчивостью к ошибкам разработчиков. Для этого мы:
- написали чекер, который требует от разработчиков писать unit и приёмочные тесты на новую функциональность;
- добавили линтеры с жёсткими уровнями проверок;
- написали генератор клиентов по yaml-файлам;
- создали разные мелкие инструменты, которые позволяют переключаться со старой функциональности на новую и контролировать эти переключения;
- обложились логами и метриками, настроили хорошие дашборды.
Иными словами, мы сделали так, чтобы рефакторинг был максимально безопасным, переключения — контролируемыми, а вся рутина — автоматизированной.
Наши инструменты и подходы
Итак, чтобы безопасно вынести какую‑то часть монолита, мы используем следующие инструменты:
- Auth‑proxy;
- API‑proxy;
- сервис экспериментов.
Каждый инструмент заслуживает отдельной статьи, поэтому я кратко опишу только то, чем мы пользуемся при распиле.
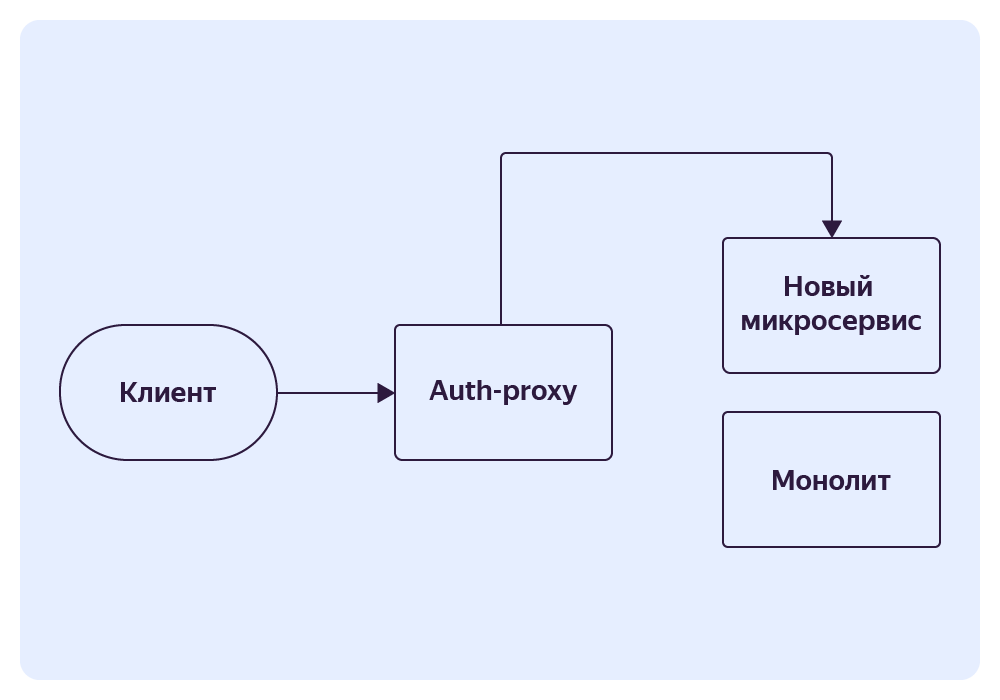
Auth-proxy
Это Gateway API‑сервис, в который поступают все запросы от клиентского приложения. Он отвечает за авторизацию пользователей и роутинг запроса в нужный сервис. Это стандартный общеизвестный паттерн.
Наш сервис, помимо своих прямых обязанностей, может задавать разные правила для одного эндпоинта и регулировать вероятности выбора этого правила. Это означает, что мы можем задать два правила, и они будут срабатывать с указанной вероятностью. Это позволяет постепенно и плавно перенаправить трафик с монолита на новый сервис.
Если обобщить, вы можете создать сервис, который полностью дублирует часть функциональности монолита, и вам просто нужно постепенно переключить трафик.
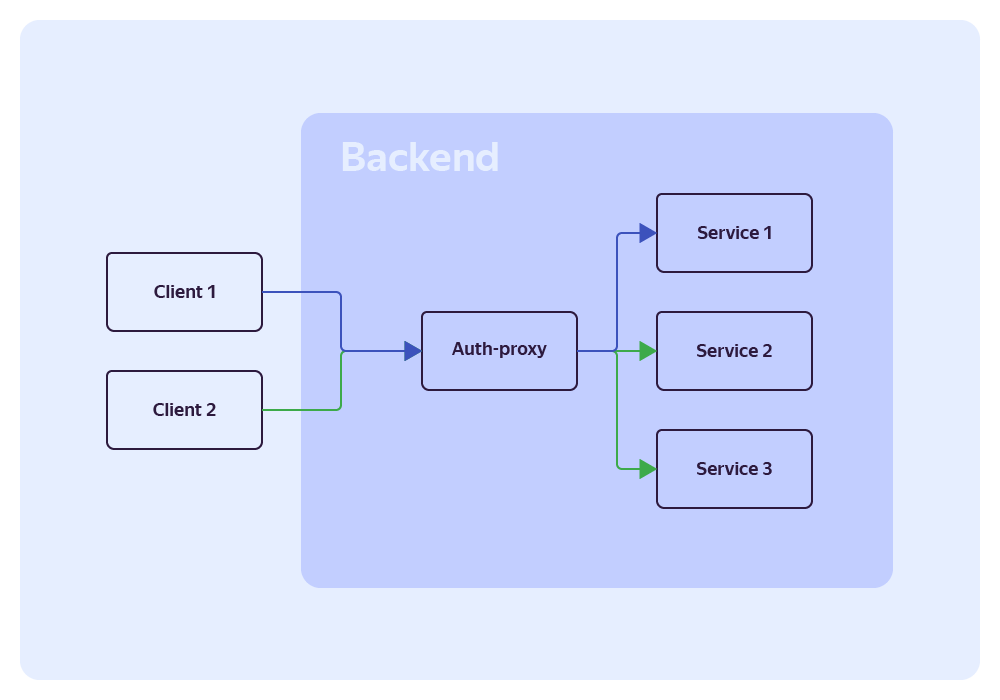
API-proxy
Это сервис‑фасад, выполняющий интегрирующую функцию над микросервисами. В зависимости от ситуации мы используем разные варианты переключения трафика. Приведу пример самого безопасного. Так выглядит общая схема в момент переключения.
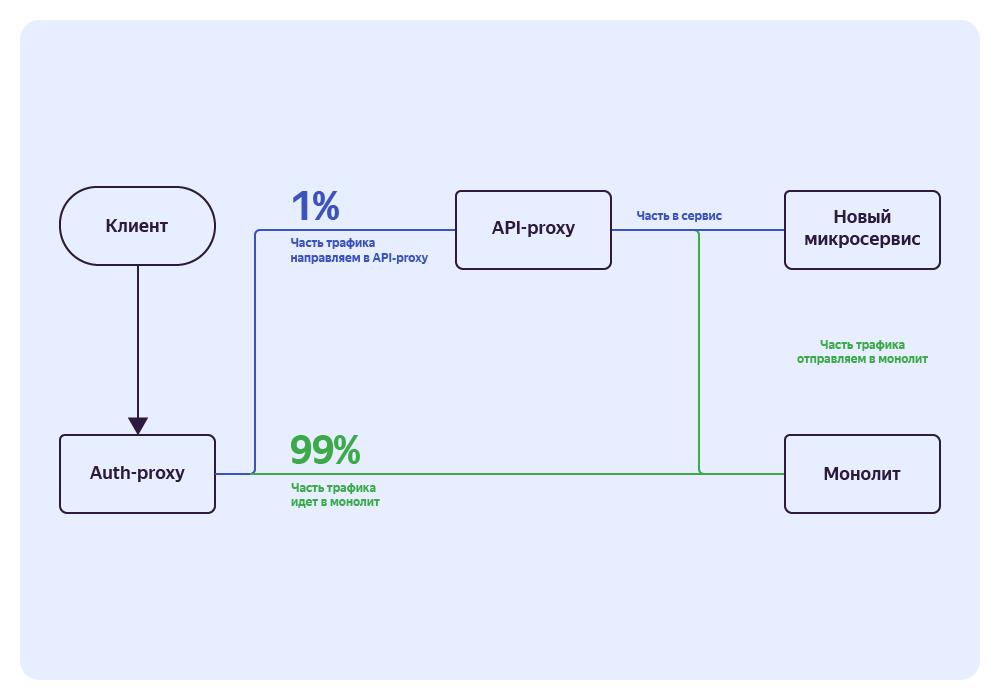
Предположим, что у нас есть сервис, который предоставляет ту же самую функциональность, что и монолит. Но перед переключением трафика мы бы хотели убедиться, что он работает точно так же.
Мы пользуемся Auth‑proxy, чтобы отделить минимальную часть трафика для исследования и направить её на API‑proxy. Например, 1% от всего трафика.
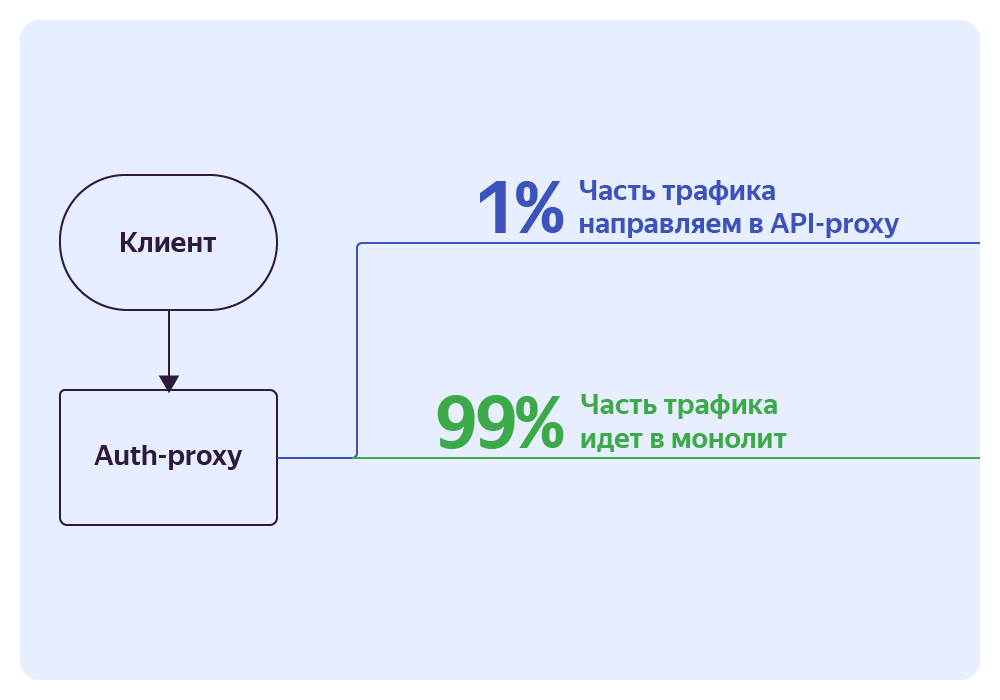
Далее в API‑proxy мы делим запрос на две части: одна уходит к монолиту, а вторая — к новому сервису. При этом мы берём ответ монолита, а ответ сервиса игнорируем.
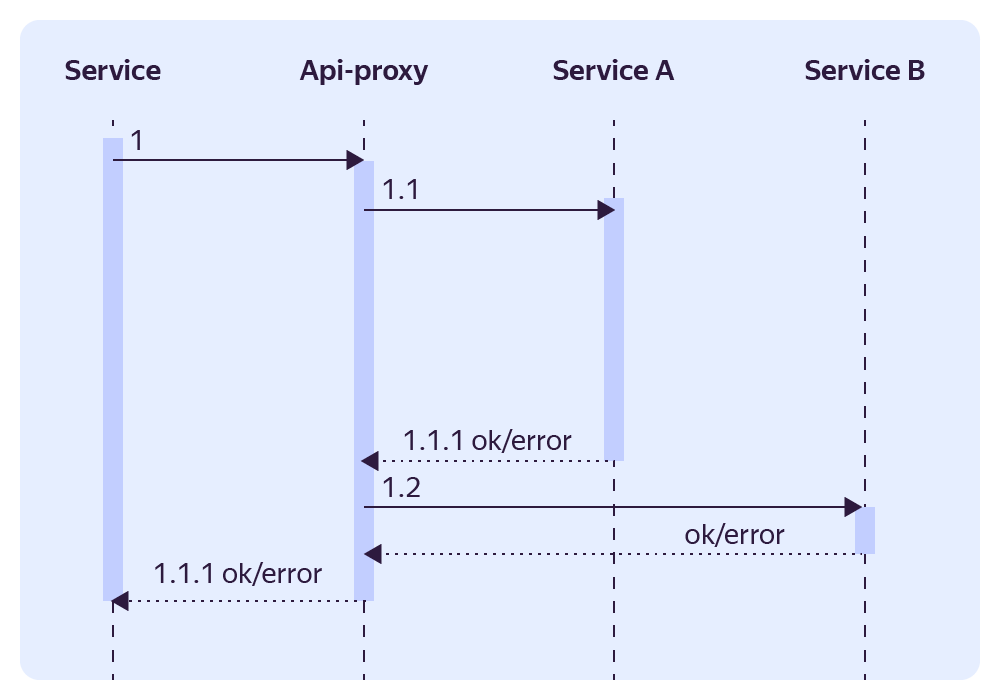
После того как мы посмотрим логи и убедимся, что сервис работает корректно и возвращает в точности такой же ответ, как и монолит, можно начать отдавать ответ этого сервиса и постепенно увеличивать на него трафик.
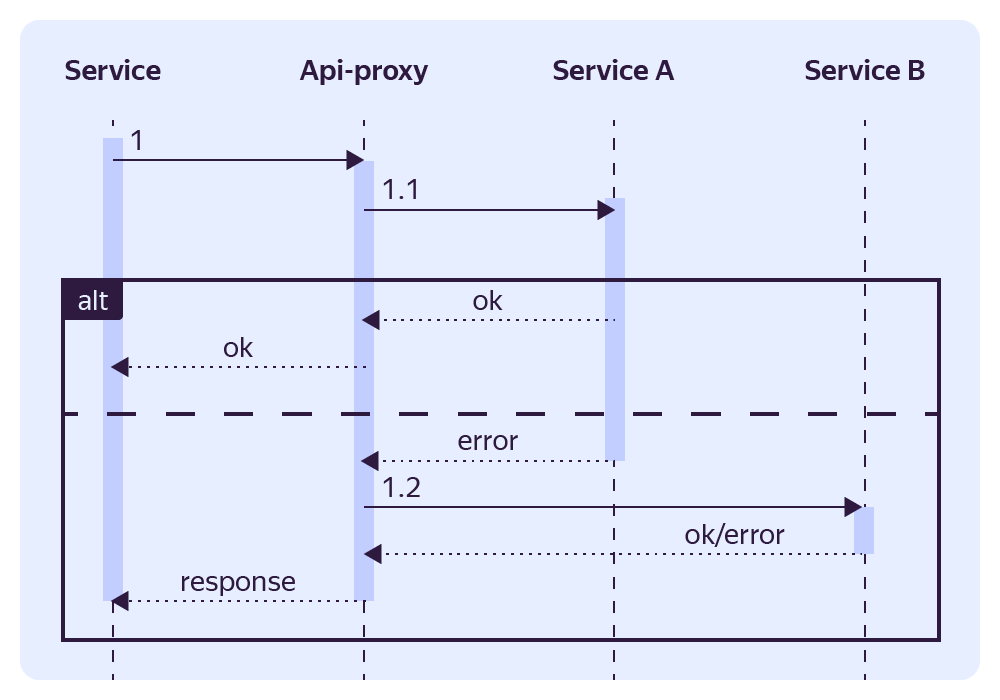
Когда будет ясно, что сервис работает хорошо, держит нагрузки, и никаких проблем не предвидится, убираем все лишние прослойки и просто оставляем в Auth‑proxy одно правило на этот сервис.
Например, вот так выглядит описание правила в API-proxy:
responses:
- id: response-banners
status-code: 200
body:
- key: banners
value#concat-arrays:
- value#xget: /banners/response/body/banners
- value#xget: /new-banners/response/body/banners
fallbacks:
- id: banners-fallback
status-code: 200
body#object:
- key: banners
value#array: []
Тут мы создали новый сервис работы с баннерами, и теперь нам нужно на него переключиться. Настраиваем эндпоинт, который возвращает список доступных пользователю баннеров. Разделяем запрос на поход в два сервиса, а дальше мержим результат. При этом, если ручка сервиса выдаст что‑нибудь, что отличается от кода ответа 200, то мы просто вернём пустой массив.
Таким образом, мы уверены в ручке монолита (она же давно работает). Так что понемногу начинаем создавать новые баннеры, а если вдруг сервис начинает работать некорректно (например, не справляется с нагрузкой), то из списка исчезнут только новые.
Сервис экспериментов
Это сервис, который помогает разделять запросы пользователей на группы, основываясь на параметрах запросов. Просто необходимый инструмент, чтобы включить какую‑то функциональность на определённую группу людей.
Например, мы хотим переключить новую функциональность только на сотрудников Яндекса, чтобы в случае фейла минимизировать негативный эффект. В админке сервиса экспериментов настраиваем группу и задаём список пользователей. Далее при запросе мы берём данные пользователя и формируем запрос к сервису экспериментов, чтобы узнать, к какой группе относится пользователь. Группа уже определит, по какому флоу мы пойдём дальше.
{
"experiment_name": "user_swich",
"kwargs": {
"user_id": "324234",
"application": "ios",
"country": "ru",
}
}
А так выглядит настройка эксперимента в админке.

В коде делаем примерно так:
<?php
if($this->experiment->getValue($request) === ”DatabaseStepStrategy”) {
# выполняем код для сотрудников Яндекса, которые используют iOS и только в России
} else {
# этот код выполняется для всех остальных
}
Ответом сервиса экспериментов может быть число, булевое значение, строка или произвольный JSON.
Сервис обладает обширным набором функций, но для нашей цели мы обычно используем переключение этапов на группе пользователей и плавное попроцентное переключение этапа.
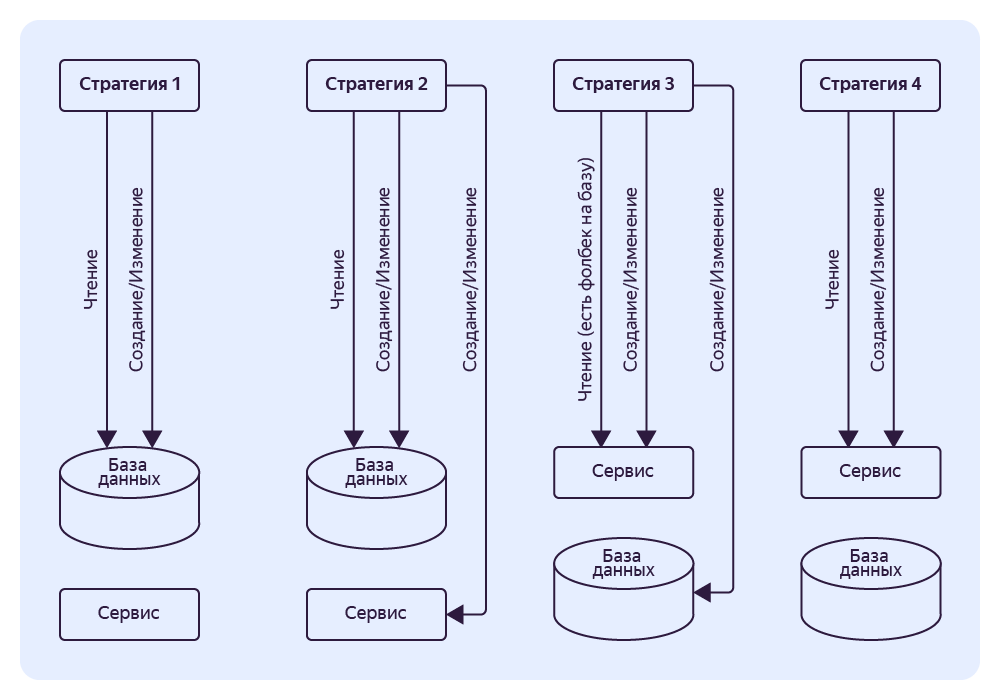
Стратегии
Стратегии — это главный подход, который мы используем для переключения со старой функциональности на новую.
Представьте, вам нужно вынести какую‑то сущность из монолита и переключить функциональность на сервис. Что вам для этого нужно сделать? Можно во всех местах, где используется функциональность, написать множество IF, а можно понять, какой функциональностью обладает выносимая сущность, и описать это в виде интерфейса.
Разрабатываем первую реализацию этого интерфейса и выносим туда текущий код. Основная задача — обеспечить работу с сущностью только через интерфейс.
Когда наша сущность отделена интерфейсом, мы пишем ещё три реализации этого интерфейса и называем их стратегиями (Паттерн Strategy). Каждая реализация — это один из этапов. Обычно они такие:
- Первая стратегия → работаем только с базой данных.
- Вторая стратегия → работаем с базой данных, в фоне ходим в сервис (читаем и пишем данные).
- Третья стратегия → работаем с сервисом с фолбэком на базу.
- Четвёртая стратегия → работаем только с сервисом.
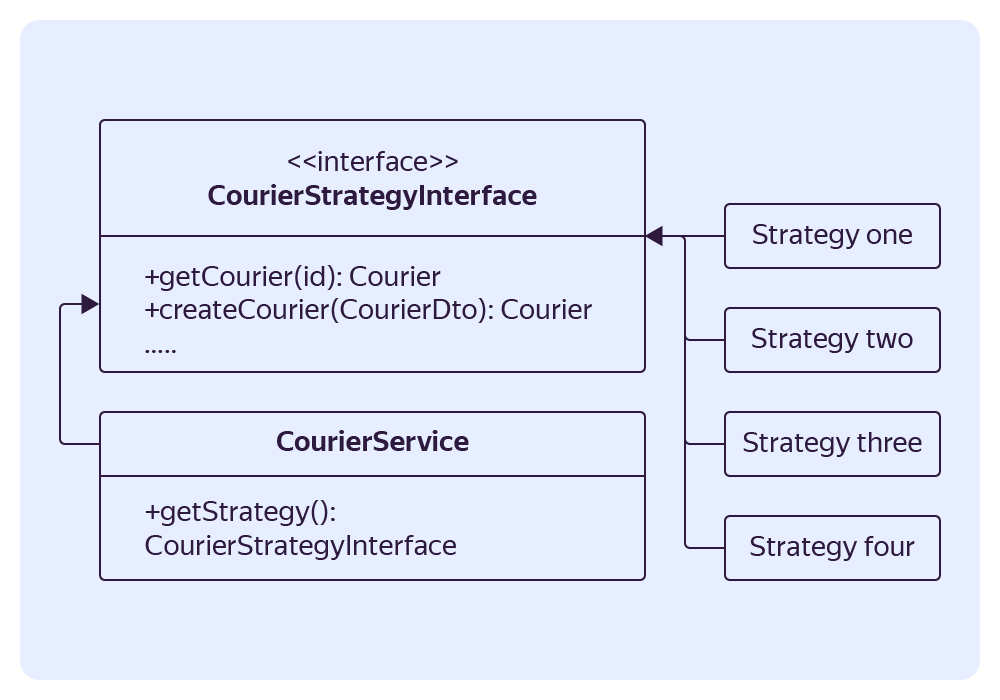
Примерно так выглядит метод в сервисе CourierService:
<?php
public function getCourier(): CourierStrategyInterface {
return $this->getStrategy()->getCourier();
}
Дальше в каждой стратегии мы реализуем своё поведение.
Примеры
Итак, мы прошлись по основным нашим инструментам и подходам. Давайте теперь на примерах посмотрим, как и что мы выносили. Примеры будут упрощены для простоты понимания, но всё равно они близки к реальности.
Отправка нотификаций
Самый простой пример. У нас есть метод, который отправляет оповещение на e‑mail пользователя.
<?php
public function sendNotifications(int $userId, string $message, string $title): bool
{
$user = $this->userRepository->findById($userId);
mail($user->getEmail(), $title, $message);
return true;
}
Чтобы ничего не менять в коде, нам нужно сделать сервис, который по тем же параметрам сможет отправлять нотификацию. Хорошо, создаём сервис, тестируем его, генерируем клиент и подключаем.
<?php
public function sendNotifications(int $userId, string $message, string $title): bool
{
if ($this->featureFlags->isEnabled('service_email_notifications')){ // переключалка функциональности
try{
return $this->getPostRequest(['userId' => $userId, 'message' => $message, 'title' => $title]);
}catch {
// пишем в логи, игнорируем исключение, отправляем mail по-старому
}
}
$user = $this->userRepository->findById($userId);
mail($user->getEmail(), $title, $message);
return true;
}
Здесь мы используем эксперимент, чтобы направить часть нотификаций через новый сервис. Если вдруг мы получим ошибку, то сработает фолбэк на старую функциональность.
Но такой метод работает не всегда. Например, в этом случае мы решили, что лучше отправим нотификацию дважды, чем не отправим ничего. А если бы мы выносили в отдельный сервис списание денег, то лучше упасть при первой ошибке, чем списать деньги дважды.
После того как мы полностью переключились на новый сервис — просто выпиливаем старый код и пользуемся библиотекой, как раньше.
Сервис стран
Когда мы захотели вынести информацию по странам в отдельный сервис, мы проанализировали запросы, которые нам пришлось бы расцепить. Ведь теперь вместо БД нужно будет ходить в сервис за вынесенной информацией.
Я заметил, что почти везде таблица country использовалась для того, чтобы обменять двухсимвольный код страны на ID для джойна. Поэтому мы сделали миграции и избавились от числового идентификатора страны в пользу строкового. Таким образом, мы ушли в сотнях мест от необходимости ходить за данной информацией в сервис стран по HTTP.
До:
SELECT r.name
FROM regions r JOIN countries c ON r.country_id = c.id
WHERE c.code = 'ru';
После:
SELECT r.name
FROM regions r
WHERE r.country_code = 'ru';
По сути мы ушли от числового ID к строковому, что позволило нам уменьшить зависимость.
Что касается мест, где была нужна не только связь, но и какая‑то другая информация, мы пошли по стандартному пути. Сначала создали сервис с админкой и настроили репликацию данных в сервис. Потом сгенерировали клиента в монолите для запроса к сервису стран, закешировали результаты внутри монолита и переключили в монолите поход в сервис на чтение. Затем переключили фронтовые ручки на поход в сервис и, наконец, закрыли старую админку.
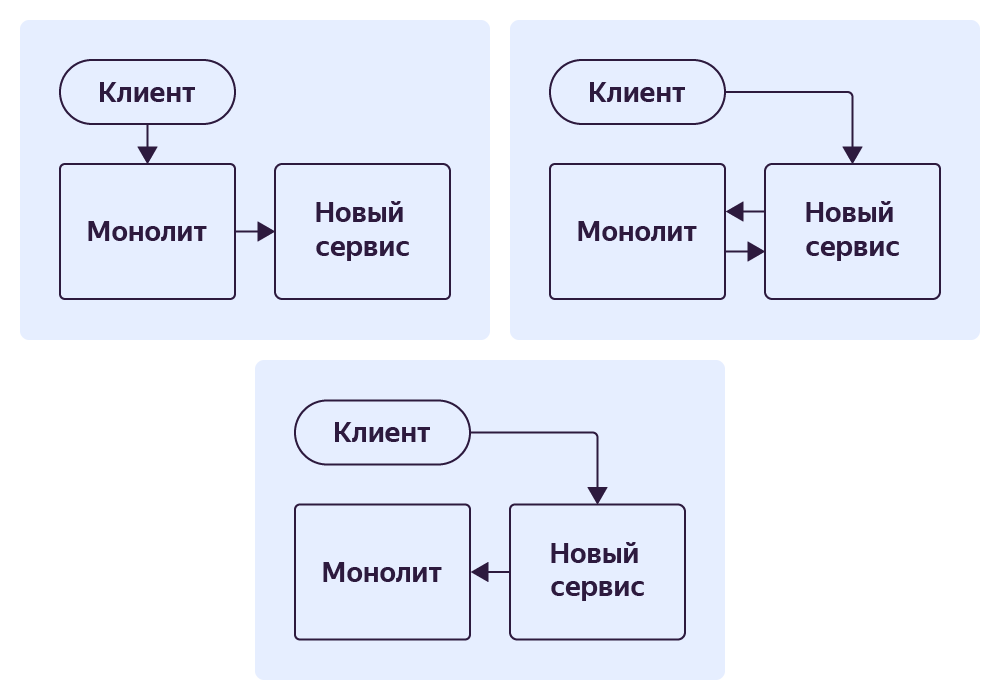
Вынос эндпоинта получения оффера
Один из самых сложных, объёмных с точки зрения информации эндопинтов в монолите — это офферы. Он возвращает всю информацию, которая нужна клиенту: от списка промоакций до временных слотов, в которые могут принять заказ. К тому же это то место, где очень часто меняется код.
Чтобы избавиться от этого эндпоинта в монолите, мы сделали Proxy‑сервис. Он принимает запрос и проксирует его в монолит, а также проксирует ответ монолита в обратную сторону.
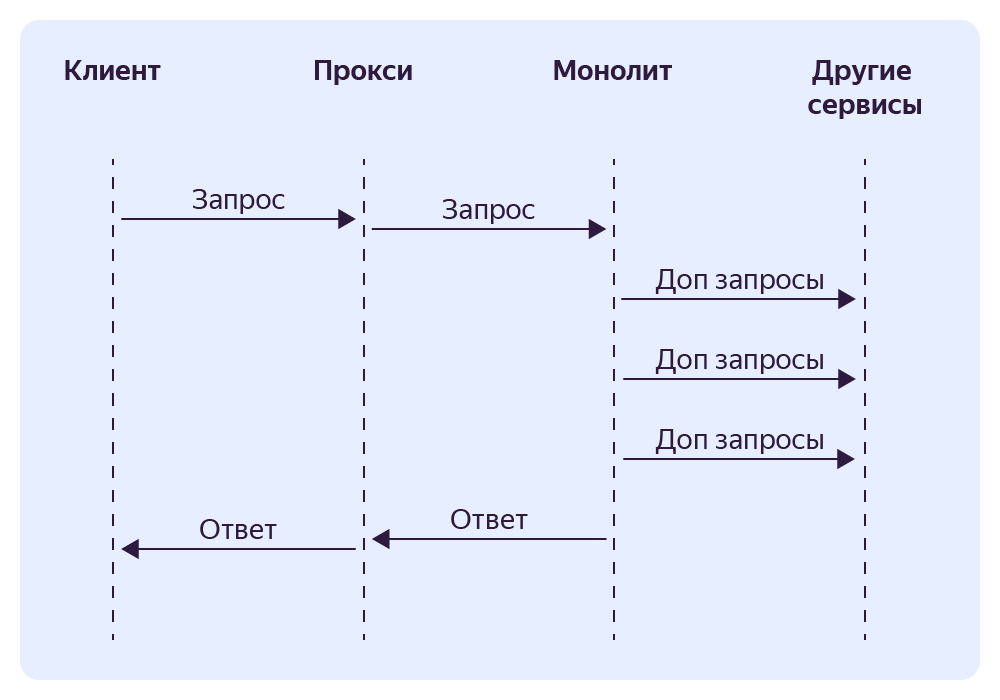
Далее в Proxy‑сервисе мы начали частично реализовывать функциональность для расчёта части ответа (например, список промоакций). Как только сервис научится рассчитывать этот список, мы шлём монолиту информацию о том, что ему больше не нужно тратить ресурсы на формирование списка промоакций. Сам список мы прикрепляем к ответу монолита в Proxy‑сервисе.
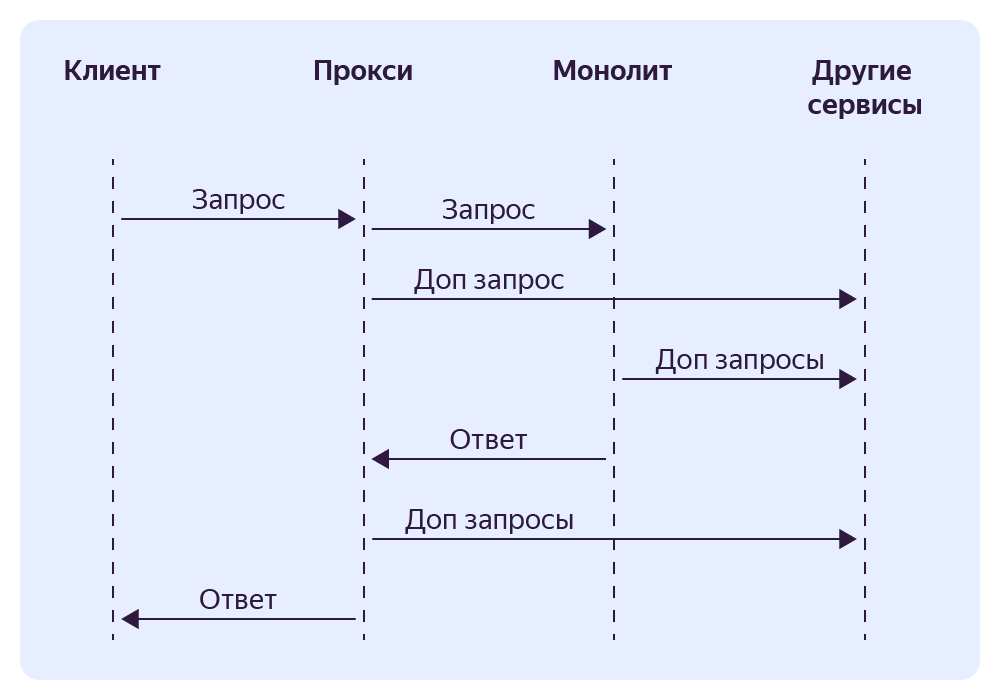
По мере того как мы реализуем функциональность в сервисе, мы выпиливаем эту же функциональность в монолите. В итоге мы доходим до момента, когда этот эндпоинт в монолите перестает использоваться, и мы удаляем этот код.
Вынос пользователей
Пользователи — это базовая сущность, которая пронизывает весь монолит и почти все сервисы. Чтобы вынести эту сущность в отдельный сервис, нам пришлось очень постараться. Мы начали с того, что закрыли всю работу с сущностью пользователя за интерфейсом.
<?php
interface EaterDataClientInterface
{
public function findById(string $eaterId, bool SwitchSoftDeleted = false, bool $noCache = false): ?EaterInterface
public function findByIds(array $ids, ?InputIdBAsedPagination $pagination = null): IdPaginatedEaterCollection;
public function delete(string $eaterId): DeleteResponce
public function ban(string $eaterId, string $reason): BanResponse;
public function unban(string $eaterId): UpdateResponce;
}
Наш монолит работает на Symfony, а сущность «пользователь» — это Entity с магией доктрины, которая перестанет работать, когда мы её вынесем. Поэтому мы создали новый интерфейс и везде заменили им Entity/User.
Дальше мы создали сервис, предварительно рассчитав предполагаемый RPS и подобрав серверы и хранилища под заданные параметры. Когда сервис был готов, мы реализовали в монолите заготовленные стратегии. Сначала включили первую, где запись и изменения пользователей идут в базу и в сервис.
Убедились, что всё хорошо. Запустили скрипт доливки всех пользователей в сервис. Проверили, что расхождений нет, и включили вторую стратегию с обязательным фолбэком на базу, чтобы в случае проблем мы вернулись к старому сценарию.
Снова убедились, что всё хорошо — включаем третью стратегию, при которой запись первично идёт в новый сервис. Всё здорово, значит, переключаемся на четвёртую, финальную стратегию и радуемся, что всё прошло гладко.
Но, к сожалению, гладко обычно не бывает
Несколько предостережений из личного опыта:
- При переезде в новый сервис данные могут переливаться несколько дней. Нужно подумать, что делать, если они перельются не полностью или с ошибками.
- В результате у вас появляется две разные базы, поэтому вам нужно придумать, как их сверять. Иногда бывают такие моменты, когда данные начинают расходиться. У нас за неделю при первой попытке расхождение было в 100 пользователей.
- Если вы нашли не все места в коде, которые ходят в базу, нужно убедиться, что больше никто не ходит напрямую в таблички.
- Если вы выпиливаете какую‑то базовую функциональность, вам, скорее всего, придётся переписывать все тесты и фикстуры.
Итоговые советы
Распилить монолит — нетривиальная задача, требующая множество усилий множества людей. Но можно сделать этот процесс более стабильным и предсказуемым. Держите пару советов:
- Готовьтесь к тому, что вам придётся рефакторить много кода. Очень много кода. Так что нужно позаботиться, чтобы этот процесс был простой и без багов.
- Пишите как можно больше логов, относящихся к переключению. И настройте как можно больше метрик.
- Заранее подготовьте и проверьте в бою инструменты, которые помогут вашему переезду.
- Автоматизируйте всё, что можно автоматизировать, — сэкономите время.
- Используйте как можно меньше костылей (в будущем скажете себе же спасибо).
- Используйте статические анализаторы кода, чтобы минимизировать количество ошибок и мелких, досадных багов.
- Тщательно тестируйте новые функции в тестовой среде. Распиливание монолита — комплексная и сложная задача, часто забываются какие‑то костыли, которые жили годами и про которые забыли при переносе. И только при тестировании или в продакшене вы сможете об этом узнать. Лучше, если при тестировании.
- Переключайтесь очень плавно. Держите под рукой план на случай, если что‑то пойдёт не так. Например, что вы будете делать, если вы уже полностью переключились, и мастером данных стал новый сервис, а вы поняли, что есть проблема и нужно переключиться обратно — как не потерять данные?
- Не нужно торопиться. Убедитесь на 100%, что всё ок.
И желаю всем удачи в распиле монолитов!



