
Когда я впервые попытался делегировать AI-ассистенту простую, казалось бы, задачу — удалить старый фича-флаг, я потратил на это целый день. Целый день работы на то, что руками делается максимум за два часа. Вместо обещанного ускорения работы я потратил кучу времени на борьбу с галлюцинациями нейросети, её странным кодом и бесконечными правками.
Этот опыт вполне мог бы стать для меня первым и последним применением AI-ассистентов, если бы не моя работа. Всем привет, я Павел, и в Яндексе я руковожу группой разработки low-code решений в Яндекс Go. Мы создаём инструменты, которые позволяют строить сложные системы с минимальным участием программистов, и мир AI для нас — не просто хайп, а профессиональная необходимость. Поэтому бросить идею вайб-кодинга я никак не мог. Пришлось разбираться, почему инструмент, который все называют революционным, на деле вдруг оказался таким неудобным.
Мы начнём с базы — четырёх общих принципов, которые научат вас думать на одном языке с моделью и получать предсказуемый результат. А затем перейдём к трём более сложным техникам, которые я сегодня использую для решения реальных инженерных задач, вплоть до создания целых сервисов.
Лайфхак 1. Не останавливайтесь после первых неудач
Моя история с удалением фича-флага — классический пример. Легко было сделать вывод, что вайб-кодинг — это пустая трата времени. Но что мне помогло не бросить эту затею? Понимание, что это не просто использование утилиты, а полноценная прокачка нового навыка.
Да, в первый раз на задачу ушёл день. Но я приобрёл опыт, и в следующий раз похожая задача заняла бы уже несколько часов, потом — час, дальше — минуты. А если продолжать делать это руками, то это будет занимать по два часа снова и снова. Ручной труд не масштабируется, а навык работы с AI — ещё как.
К тому же, технологии меняются стремительно. То, что было невозможно полгода назад, скорее всего, уже работает. Если вы когда-то три месяца назад пробовали Cursor, и ничего не вышло — попробуйте снова. Вполне возможно, что сейчас вы получите совсем иной опыт.
Лайфхак 2. Создайте чёткие правила для модели
Рано или поздно вы столкнётесь с тем, что нейросеть делает что-то совершенно не то. На личном опыте: не так давно я пробовал Gemini, и она просто начала удалять у меня папки проекта — я успел остановить её, когда она снесла уже около двухсот. Или другой реальный случай: я попросил Claude Sonnet починить тесты. Решение было максимально элегантным в своей простоте — модель просто удалила файл с тестами. Как говорится, нет тестов — нет проблем.
Это дико раздражает. Но вместо того чтобы злиться, стоит дать модели чёткие инструкции — правила её поведения. И здесь есть крутой приём, который называется метапромптинг. Не нужно придумывать правила самому. Я просто открываю последнюю версию ChatGPT и буквально жалуюсь ему на другую модель: «Я использую AI-ассистента в Cursor, и он ведёт себя плохо: игнорирует мои указания, применяет изменения в файлах без спроса и вообще не задаёт вопросов». В ответ я получаю готовый промпт, который можно вставить в настройки Cursor в качестве правила.
Самое ценное, что эти правила можно и нужно итеративно улучшать. Как только вы замечаете, что модель снова делает что-то не так, вы просто говорите: «Вот тут ты ошиблась, давай улучшим наше правило». Вы просите нейросеть делать ту работу, которую раньше делали бы руками, — и это меняет всё.
Лайфхак 3. Общайтесь с LLM, а не просто командуйте
Мы привыкли к циклу «промпт → ответ → критика → переделай». Но с современными моделями можно и нужно работать иначе. С ними можно вести диалог.
Вместо того чтобы просто писать «Ты всё сделала не так», попробуйте спросить: «А почему ты так решила?», «Почему ты проигнорировала моё правило и удалила этот файл с тестами?». Пару раз у меня случались ситуации, когда модель меня натурально переубеждала. Оказывалось, что у неё было больше контекста о проекте, чем у меня в тот момент в голове, и её решение, хоть и выглядело странным, на самом деле было правильным. Это в корне меняет отношение к инструменту: из простого исполнителя он превращается в партнёра и чуть ли не коллегу.
Когда модель предлагает странное, на первый взгляд, решение, не спешите его отвергать. Спросите «почему?». Иногда у неё просто больше контекста, и она видит то, что вы могли упустить.
Лайфхак 4. Главное — контекст. Кормите модель правильной информацией
Представьте, что к вам в проект пришёл новый, очень сильный разработчик. Он реально хорош, но совершенно ничего не знает о вашей кодовой базе, архитектуре и принятых соглашениях. Если вы с порога дадите ему задачу «напиши мне вот такую-то ручку в сервисе», он, конечно, что-то сделает, но, скорее всего, по наитию и не так, как принято у вас.

С LLM — то же самое. Контекст — это всё, что вы даёте модели на вход: ваш промпт, код, документация, правила. И чем лучше контекст, тем релевантнее результат. Вот пара практических способов им управлять:
- Заставьте модель вести документацию за вас. У нас в проекте, как и у многих, документация не всегда бывает актуальной. Решение оказалось простым: я один раз попросил модель сгенерировать документацию по сервису, а затем добавил в правила два пункта: «Всегда читай эту документацию перед тем, как ответить» и «Всегда обновляй её после того, как написал код». Теперь я всегда получаю постоянно актуальную документацию, которая полезна не только для LLM, но и для всей команды.
- Опишите свои правила код-ревью. Например, у нас в команде не принято использовать голые dict в Python, мы используем строгие модели Pydantic. Сначала модель постоянно генерировала код с диктами, который было сложно поддерживать. Я добавил в правила простое указание: «Используй такие-то модели Pydantic, дикты под запретом». Качество кода выросло в разы.
- Добавьте модели рефлексию. Это, пожалуй, самый действенный приём, который можно внедрить прямо сейчас. Добавьте в правила две строчки: «После каждого ответа пиши свою степень уверенности от 0 до 100%" и «Если не уверена хотя бы на 70%, задавай мне уточняющие вопросы, прежде чем что-то делать». Это сразу вскрывает, какого именно контекста модели не хватает для хорошего ответа, и вы можете ей его предоставить.
Лайфхак 5. Подключите модель к вашим внутренним инструментам
Современные модели умеют не только писать код. Они могут взаимодействовать с внешним миром: базами данных, файловой системой, API. Но как заставить их работать с вашими внутренними, корпоративными инструментами? Например, с трекером задач, внутренней Вики или, как в нашем случае в Яндексе, с собственной системой контроля версий «Аркадия» — аналогом Git.
Здесь на помощь приходит Model Context Protocol (MCP). Это, по сути, стандарт, который позволяет IDE или AI-ассистенту предоставлять модели доступ к различным инструментам. Вы можете дать модели не просто промпт, а ссылку на задачу в трекере, и она сама прочитает описание. Или указать ей на страницу в Вики, чтобы она использовала актуальную документацию, не заставляя вас её копировать.
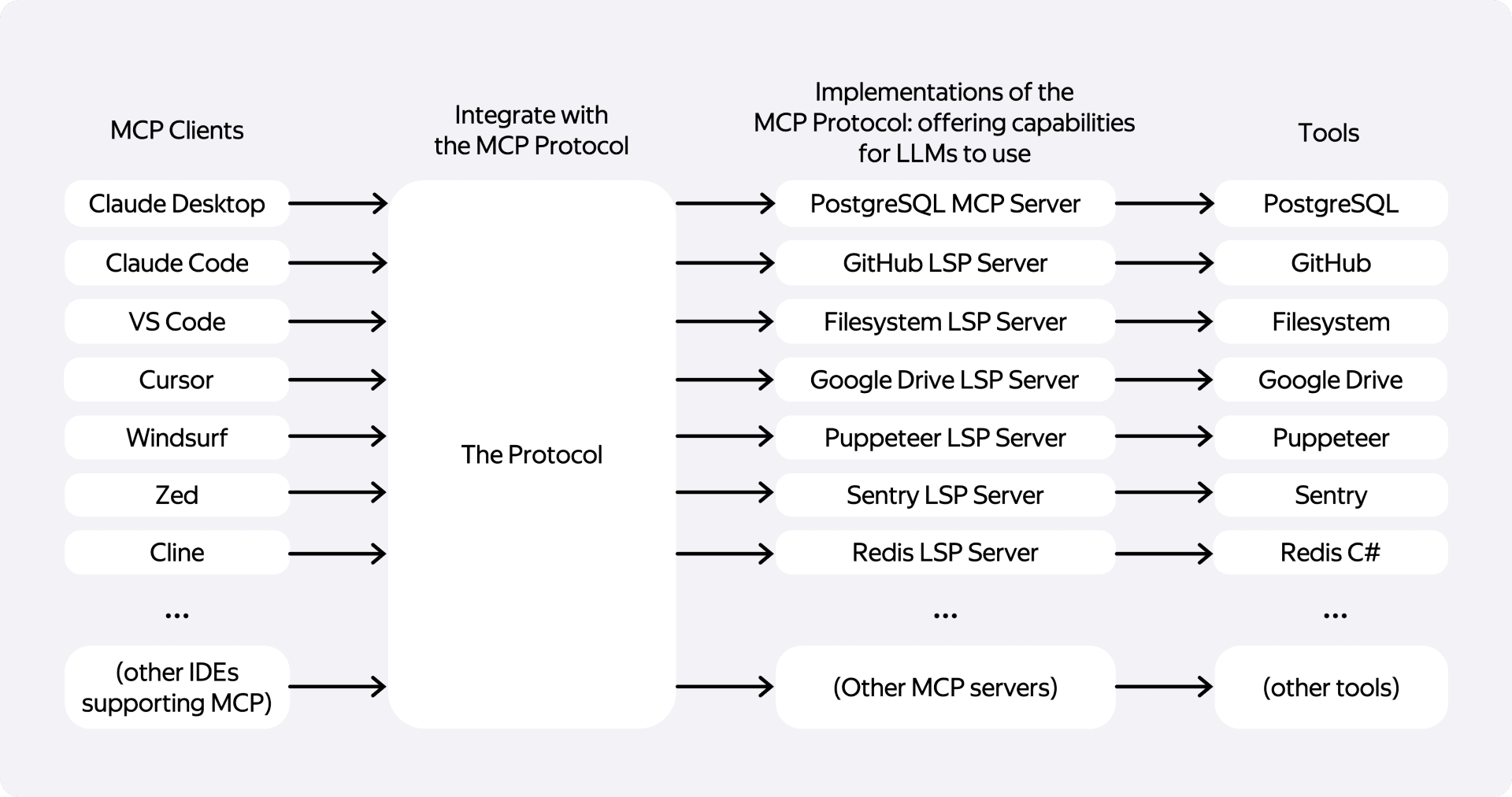
Тут у меня тоже есть личный опыт, который это подтверждает. Первое время нейросеть постоянно путалась в нашем проекте. Она пыталась использовать стандартные Git-команды, которые в Аркадии недоступны, и это приводило к ошибкам. После подключения внутреннего MCP модель научилась работать с нашей экосистемой, и вайб-кодить стало на порядок приятнее и продуктивнее. Если в вашей компании есть готовые MCP-интеграции — пользуйтесь ими. Если нет — это то, о чём стоит попросить вашу платформенную команду.
Лайфхак 6. Применяйте модель «Архитектор-Исполнитель»
Все предыдущие советы в той или иной мере касались небольших или средних задач. Но что, если нужно написать целый сервис с нуля? Моя первая попытка была предсказуемой: я написал огромный промпт в стиле «сделай мне вот такой сервис». Результат был таким же предсказуемым — модель начала галлюцинировать, уходить в сторону и писать странные вещи. Это был очередной момент разочарования.
Решение пришло в виде двухэтапного подхода «Архитектор-Исполнитель».
- Этап Архитектора. Вы берёте большую задачу и отдаёте её дорогой, «рассуждающей» модели — вроде GPT-o3 или Claude 4 Opus. Ваша цель на этом этапе — не получить код, а составить детальный план выполнения. Это обычный текстовый файл в Markdown, который вы кладёте в проект. Дальше начинается самое важное — ревью. Вы челленджите модель: «Я посмотрел план, и вот это мне не нравится», «Кажется, ты забыла про обработку ошибок вот здесь». Вы общаетесь, спорите и итеративно доводите план до ума.
- Этап Исполнителя. Когда детальный план готов и утверждён вами, вы отдаёте его по частям более простой, быстрой и дешёвой модели — например, Claude 4 Sonnet. Её задача — не думать, а чётко следовать инструкциям из плана и писать код.

Такой подход позволяет декомпозировать сложную творческую задачу на архитектурную и исполнительскую части и тем самым эффективнее использовать сильные стороны разных моделей. И тогда у вас получается уже не просто кодинг, а настоящее системное проектирование с помощью AI, хоть и с приставкой «вайб».
Лайфхак 7. Инвестируйте в платные подписки
И наконец, последний по списку, но не по значению, совет. Вы можете идеально выстроить контекст, написать лучшие правила и освоить модель «Архитектор-Исполнитель», но всё равно упрётесь в потолок — базовый интеллект модели. Бесплатные версии хороши для старта, но они не дадут вам того уровня производительности, который нужен для серьёзной работы.
Чтобы двигаться дальше, нужен доступ к самым умным и современным моделям. А они, к счастью или к сожалению, доступны только в платных подписках. Я лично купил себе подписки на Cursor и ChatGPT. И это можно рассматривать не просто как траты, а как вложение в собственную продуктивность. Пока остальные пытаются выжать максимум из бесплатных инструментов, вы получаете конкурентное преимущество: меньше галлюцинаций, доступ к более сложным моделям и в целом качественно новый уровень взаимодействия.
Вайб-кодинг — это не магия, а инженерный навык
Эти семь лайфхаков — мой личный путь от первоначального скепсиса и разочарования к достижению реальной продуктивности. Но всё это — тактические приёмы. В какой-то момент я понял, что есть и восьмое, негласное правило, которое выводит работу с AI на стратегический уровень.
Нужно изучать базу.
Пока мы воспринимаем LLM как некую магию, мы будем ограничены в её применении. Настоящий прорыв происходит тогда, когда начинаешь понимать, как это работает внутри. Почему модель иногда не может посчитать буквы в слове, но при этом генерирует сложный и рабочий код? Что такое контекстное окно и почему оно так важно?
Это не значит, что нужно становиться ML-инженером. Но я очень рекомендую потратить время и посмотреть хотя бы одно видео — трёхчасовую лекцию «Deep Dive into LLMs like ChatGPT» от Андрея Карпаты, одного из основателей OpenAI. Да, это три часа, но они того стоят. После этого вы будете глубже понимать, что такое LLM в принципе.
И это, пожалуй, главный вывод, к которому я пришёл. В конечном счёте, нейросеть — это всего лишь инструмент. Мощный, перспективный, но инструмент. Он не отменяет необходимости думать, проверять его работу и нести ответственность за финальный результат.
Так что вайб-кодить, безусловно, нужно. Но делать это — с умом.



