
Привет, меня зовут Вадим. Я делаю платформу надёжности в Яндекс Go. Инструментов для улучшения надёжности много, поэтому перед нашей командой всегда стоит выбор, что делать сейчас, а что отложить на месяц, квартал, год. Под катом я покажу пример инструмента для приоритизации таких проектов, а по пути мы разберёмся с тем, что такое надёжность технических систем, из чего она состоит и как её можно считать.
Что такое надёжность
Давайте синхронизируемся, что же мы будем понимать под надёжностью в этой статье.
Представьте простой сервис, который принимает запрос и возвращает ответ.
Обычно так и работает, да?
Реальность, как правило, немного сложнее: перед сервисом стоят балансеры, которые решают, в какую из реплик пойдёт запрос. На входе, возможно, стоит Nginx или что‑то подобное, а каждый запрос нужно авторизировать. Потом может захотеться проверить RPS‑лимиты или сделать ещё какую‑то дополнительную логику. Начинка может быть разной, но запрос точно не попадёт в обработку просто так.
Даже после того, как отработает вся входная логика, запрос не начнёт выполняться: например, из‑за механизма троттлинга, который помогает избежать избыточной нагрузки и не даёт сервису упасть, исчерпав все ресурсы. Это тоже логика, которая развивается и может работать неправильно: например, из‑за некорректного обновления.
Но и это ещё не всё: сервис работает не сам с собой, а с какой‑либо базой данных, надёжность которой надо посчитать отдельно.
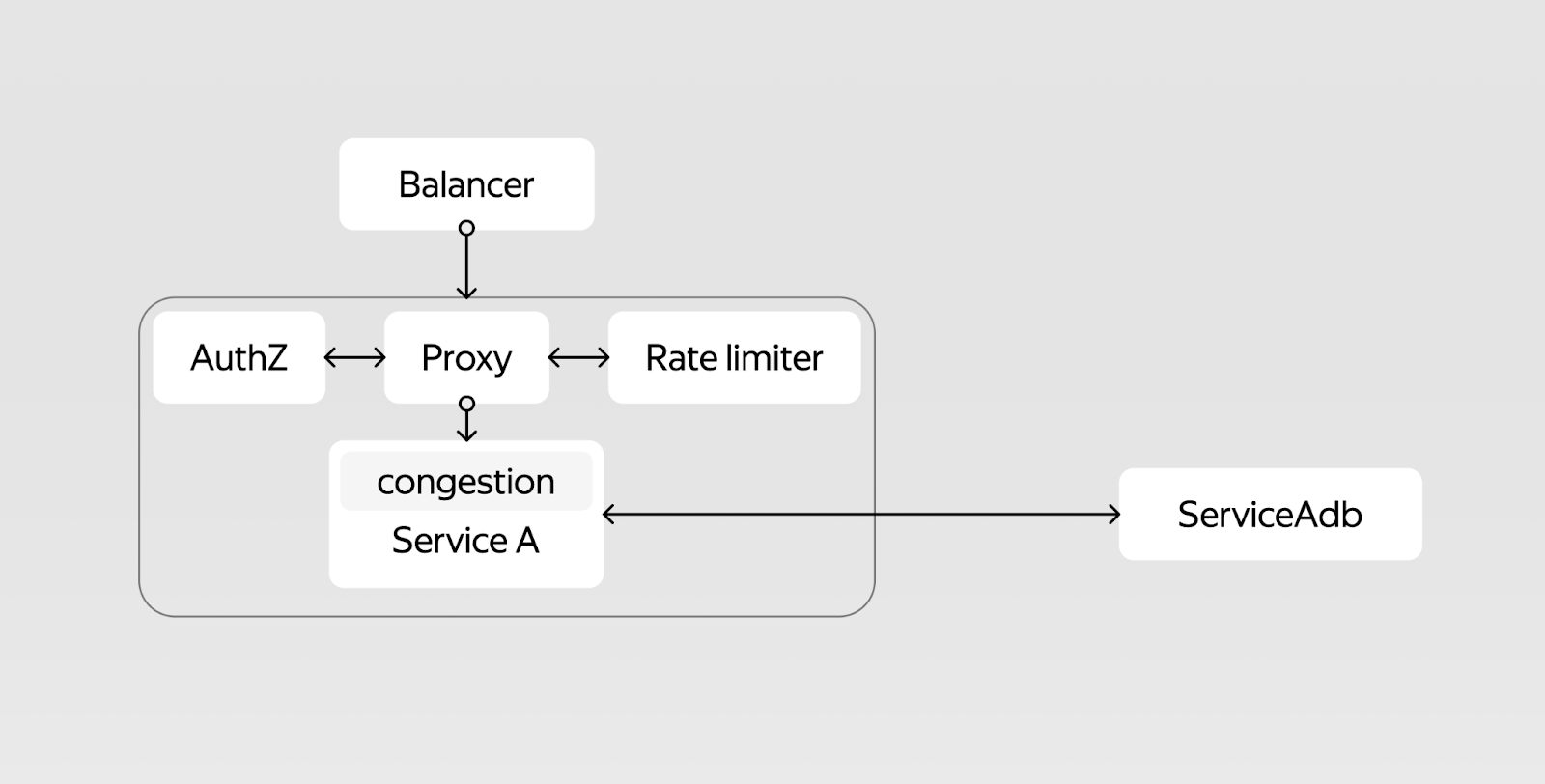
Так простой сервис превратился в систему из множества элементов, каждый из которых может отказать. И как это посчитать?
О девятках
Немного теории. Есть много определений, но в самом близком к IT‑миру надёжность, или  , — это вероятность того, что система на протяжении заданного интервала времени будет выполнять свои функции без отказов. Проще думать и считать её так: надёжность — доля безотказной работы за весь период времени. И переводят её в термины девяток:
, — это вероятность того, что система на протяжении заданного интервала времени будет выполнять свои функции без отказов. Проще думать и считать её так: надёжность — доля безотказной работы за весь период времени. И переводят её в термины девяток:

Четыре девятки означают, что сервис безотказно работает 99,99% всего времени и недоступен не более 52 минут в год. А если девяток пять, то за год сервис может прилечь всего на 5 минут 15 секунд. Много это или мало зависит от конкретного продукта и решаемой задачи. Например, если сториз в Телеграме сломаются на пять минут в год, вы вряд ли расстроитесь. А вот если вам нужно срочно уехать в аэропорт и вы пять минут не можете найти способ это сделать, то, скорее всего, начнёте паниковать.
Из чего складывается недоступность
Что такое пять минут недоступности и из чего они складываются? Хороший пример — плохие релизы.
Если сервис большой, то внутри него происходят сотни релизов в год. И даже если настроить сложную систему мониторингов, алертов и откатов, плохие релизы могут оказаться хитрее и обойти все ловушки для багов.
Пошагово плохой релиз выглядит примерно так:
- Мы деплоим сервис. Сервис не возвращает ошибки или плохие коды ответов, но портит выходные данные. За первые 10 секунд мы могли бы выключить реплику с плохим релизом и начать откат, но канарейка была настроена только на Health‑чеки от сервиса и статистику кодов ответов. Очень жаль.
- Сервис отправляет метрики, но в хранилище метрик они попадают не сразу, а раз в определённый период времени, и только потом отображаются на графиках — до тех пор мы не видим проблем и считаем, что сервис нормально работает. Тем временем плохой релиз уже 20 секунд работает минимум на одной реплике и продолжает раскатываться на следующие, а сервис на два уровня выше или вообще в другом вызове начинает возвращать ошибки.
- Бизнесовые метрики начинают падать. Но мы не узнаем об этом, пока не получим алерт о проблемах в бизнес‑логике. А он придёт не сразу, потому что пересчитывается не после каждого добавления метрик в БД, а раз в заданный интервал времени. К тому же поверх алертинга может стоять шумодав на случай ложных срабатываний, если залагают метрики. Итого до момента, когда мы узнаем, что что‑то сломалось, может пройти минута.
- Ура! Через 60 секунд на офисном мониторе появилась большая красная плашка, от Телеграм‑бота пришло сообщение или даже позвонил робот. На чтение деталей и реакцию уйдёт ещё полминуты.
- Допустим, мы точно знаем, как нужно откатывать релиз: бежим в наш любимый браузер, вводим нужный URL и за каких‑то шесть кликов добираемся до нужной кнопки. В таком случае уже через 20 секунд после алерта релиз поедет обратно. Дальше есть несколько возможных сценариев:
- Предположим, у нас есть двухкратный запас железа, поэтому самая свежая и предыдущая версия релиза работают одновременно. Это значит, что мы можем просто взять и переключить балансер, и на замену версии уйдёт минимум времени. Но такие системы встречаются очень редко.
- Чаще всего старый релиз куда‑то скачан, но не запущен. В таком случае достаточно будет отключить текущую реплику и запустить старую. Если он поднимется достаточно быстро, а за 90 + 20 = 110 секунд успели обновиться не все реплики, оставшихся может хватить для обработки всех запросов. В противном случае сервис будет недоступен 30–40 дополнительных секунд.
- Самый плохой случай: старую версию релиза нужно скачать. Из‑за этого откат может растянуться на минуты.
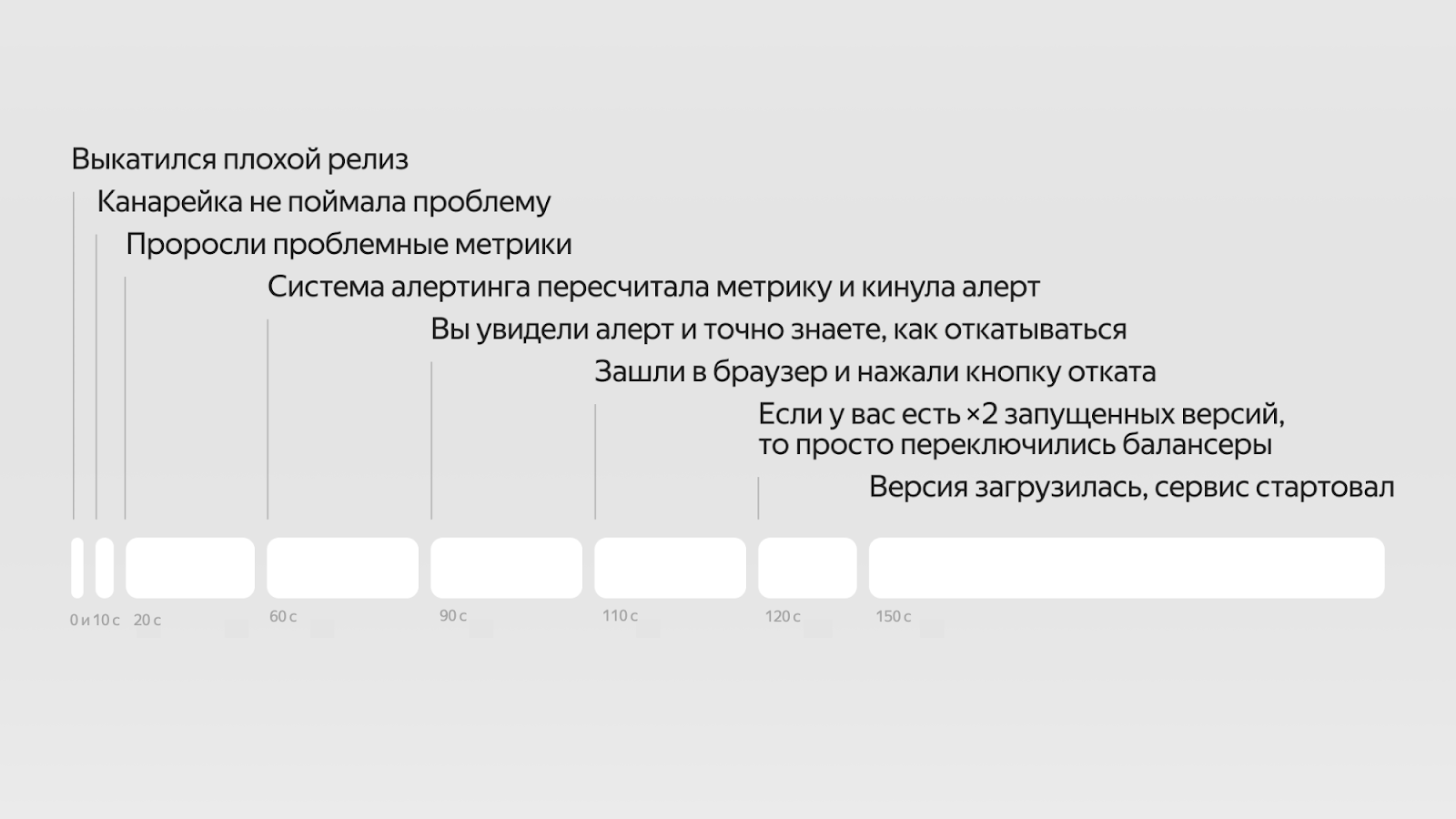
В оптимистичном случае мы потратили бы две с половиной минуты на откат одного плохого релиза в год. Без хорошей системы алертов, своевременных мониторингов, удобного инструментария и автоматики откат может значительно затянуться.
Что делать со сложными системами
Если для выполнения запроса должны отработать несколько последовательно соединённых элементов, то надёжность такой системы вычисляется перемножением надёжностей всех её элементов:

Надёжность двух последовательно соединённых элементов с надёжностью 90% по этой формуле:
90% × 90% = 81%
Если в системе есть параллельная фолбэк‑логика для дублирования элементов (быстро поставить задачу в очередь не получилось — сходи напрямую в сервис; в кеше нет данных — выбери их из БД), формула другая:

Два элемента надёжных на 90% по этой формуле обеспечат 99% надёжности всей системы.
Считаем надёжность
Вернёмся к нашему сервису: с межсервисной авторизацией, Rate Limiter, троттлингом, бизнес-логикой и БД. Его можно представить как последовательный алгоритм: чтобы выполнилась логика, должны сработать все элементы системы.
processRequest() {
authorize();
if(rateLimiter.check) {
moveToHandlerFromQueue();
communicateWithDb();
doBusinessLogic();
}
}
Вспомним формулу из предыдущего раздела: чтобы посчитать надёжность системы, перемножим надёжности каждого из её элементов. Если все элементы очень надёжные (по пять девяток каждый), для сервиса из пяти последовательно соединённых элементов получим:
 = 0,999 995 = 0,99 995 = 99,995% ~ 26 минут 18 секунд недоступности
= 0,999 995 = 0,99 995 = 99,995% ~ 26 минут 18 секунд недоступности
Если вспомнить, что в схеме был Nginx, через который работали авторизации и рейт‑лимитер, а сам Nginx тоже умеет интересно сбоить от подкрученных настроек, то у нас есть шестой элемент:
= 0,999 996 = 0,99 994 = 99,994% ~ 31 минута 33 секунды
31 минута — пока что не очень большая цифра: звучит, конечно, плохо, но жить можно.
К сожалению, беда не приходит одна, а микросервисы не встречаются по одиночке. У нас, как правило, есть много сервисов с разной надёжностью. Они вызывают друг друга напрямую или через очереди. Получается дерево вызовов, или зависимостей:
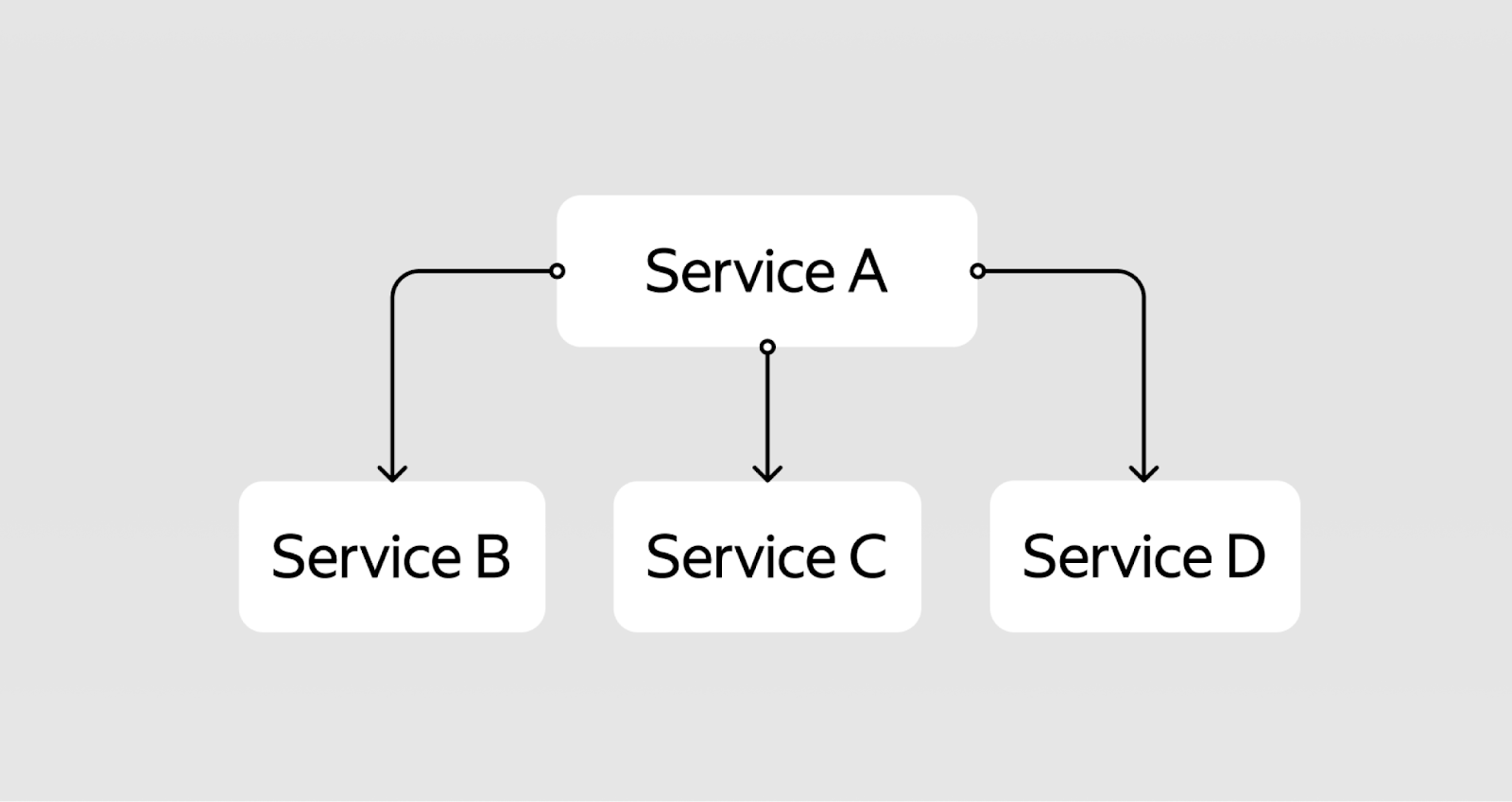
Например, сервис A собрал данные сервиса B и смёржил их с данными из базы. Потом сходил в сервис C и отправил оттуда какое‑то уведомление. И, наконец, заглянул в сервис D, чтобы записать данные туда и передать их дальше. Это всё ещё последовательный алгоритм, и у каждого из этих сервисов — своя надёжность.
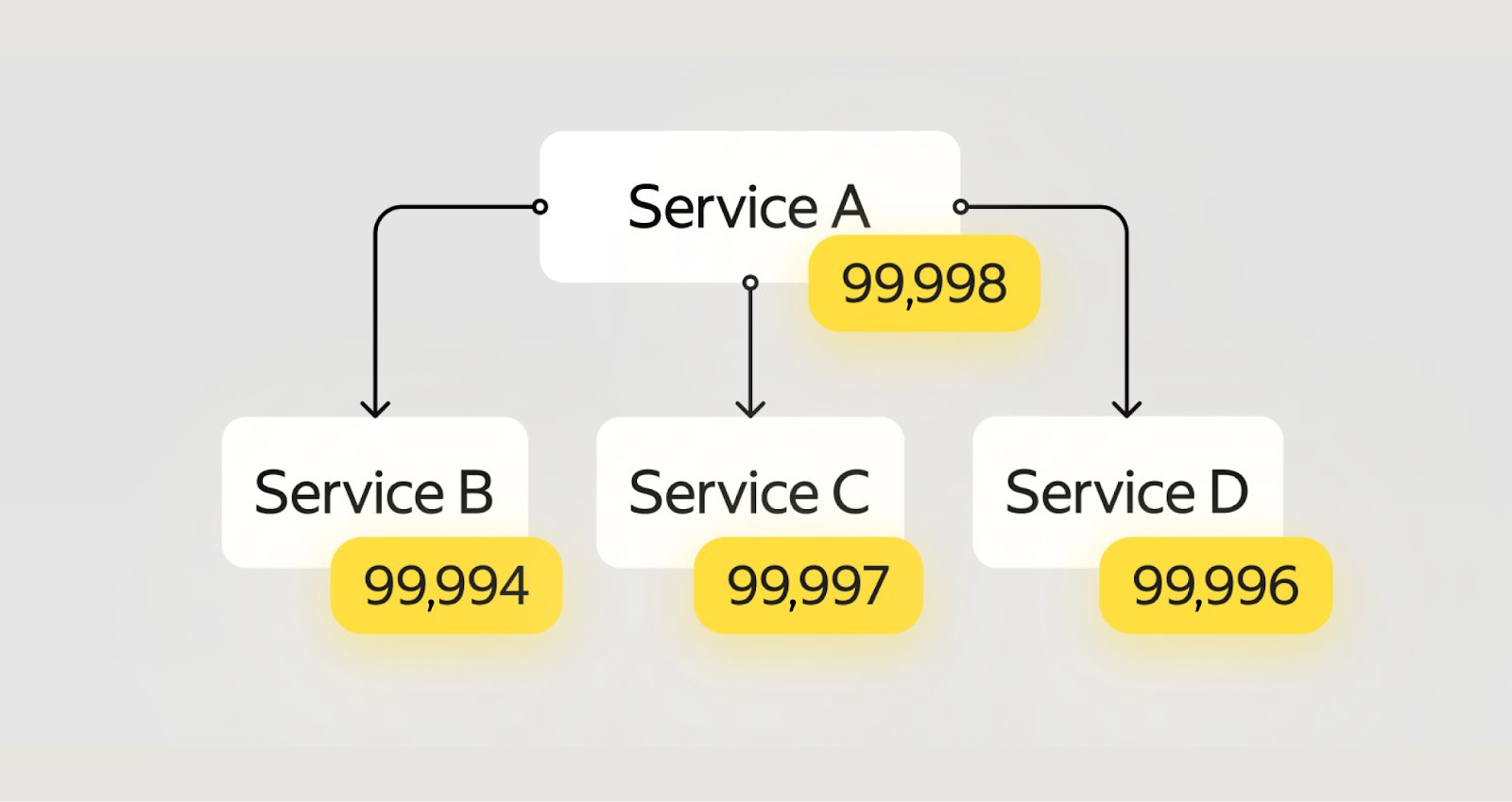
Как посчитать надёжность такой системы?
Видим последовательно соединённые элементы — умножаем их надёжности:
= 0,99 998 × 0,99 994 × 0,99 997 × 0,99 996 = 0,99 985 ~1 час 13 минут недоступности
Начинает звучать страшно, но по‑прежнему терпимо.
Но беда всё ещё не приходит одна. Из докладов и статей мы знаем, что в проде большинства продуктов, которыми вы пользуетесь каждый день, как правило, больше четырёх сервисов. Скажем, у Uber — 3000 микросервисов, у Яндекс Такси — больше 800.
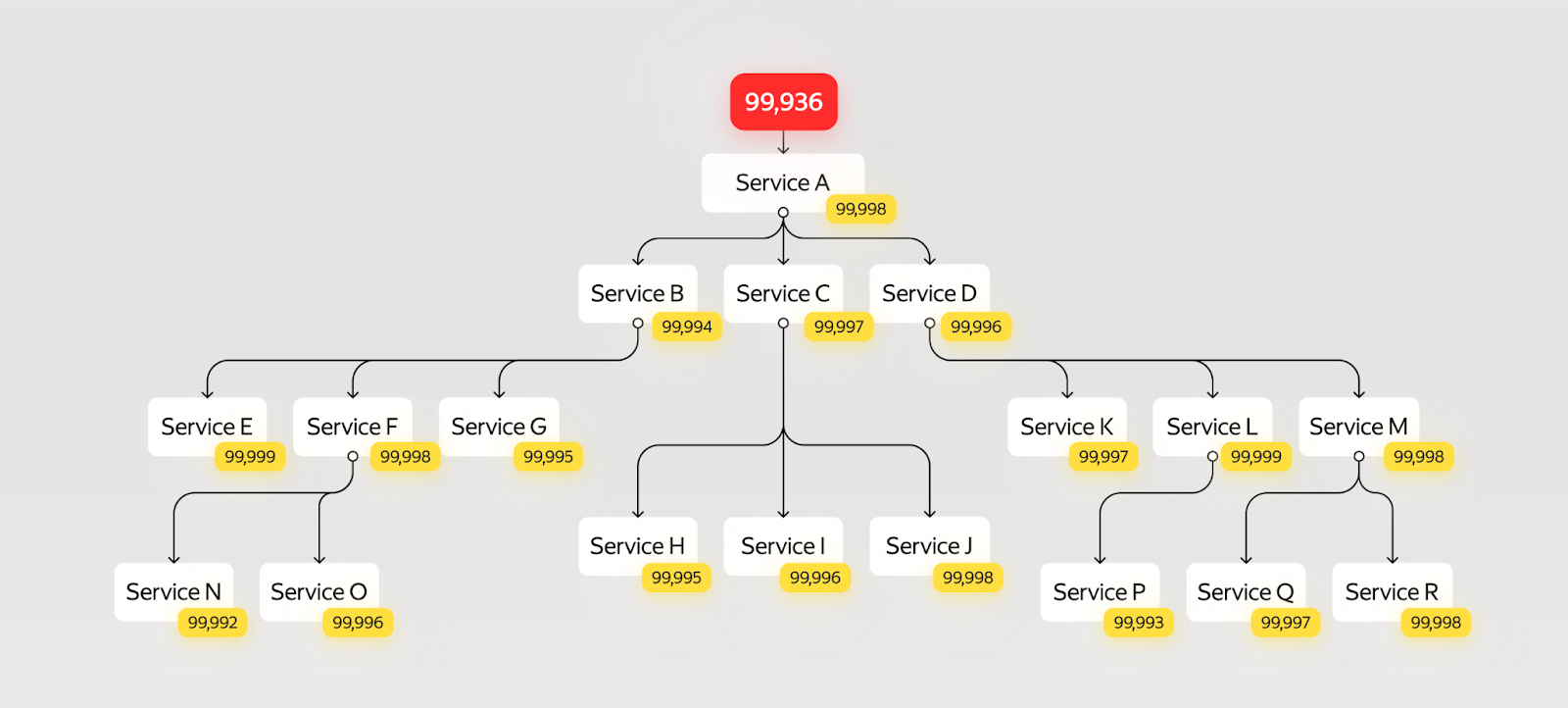
Если вы любите рассматривать деревья трассировок так же, как и я, то, скорее всего, знаете, что один входящий запрос приводит к вызовам в десятках сервисов. Чаще всего это последовательный алгоритм, где у каждого из сервисов — своя надёжность. Перемножив все надёжности с картинки выше, получим 99,93%. То есть мы потеряли четыре девятки и получили 5,5 часов недоступности в год.
Давайте попробуем это исправить.
Повышаем надёжность
Action Items по инцидентам
Самый простой способ — проводить ретроспективы инцидентов и устранять причины поломок. То есть после каждого инцидента или раз в определённый период команда анализирует, что можно улучшить, чтобы проблемы не повторялись.
Предположим, мы давно работаем над системой и обнаружили, что сервис F стал часто сбоить по разным причинам.
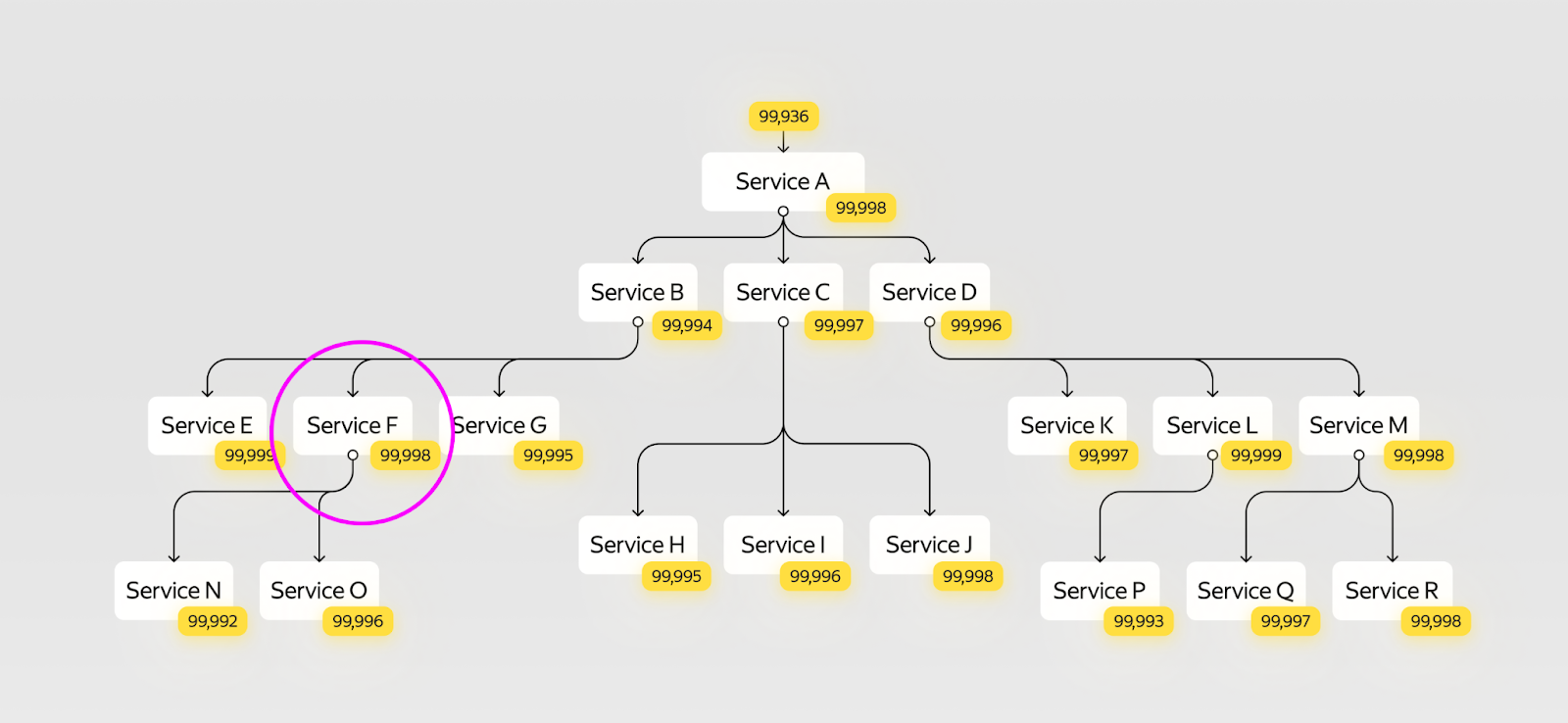
Если проанализировать сервис, то может выясниться, что он неоптимально спроектирован и его нужно переписать. Например, избавиться от лишних внешних зависимостей и собрать всю логику в одном месте.
Итак, чтобы сделать Zero Downtime для сервиса F с картинки выше, нам понадобится:
- Создать новое хранилище, которое будет хранить данные из трёх старых сервисов.
- Переписать логику сервиса F так, чтобы миграция данных не отставала: пока она не закончится, данные должны сохраняться и в новом хранилище, и в старом.
- Мигрировать существующие данные из сервисов N и O.
- Написать новые версии обработчиков, чтобы они работали только с новым хранилищем.
- Поправить сервис B так, чтобы он начал ходить в новые ручки (и ещё хорошо бы плавно переключать трафик).
- После перенаправления трафика в новые обработчики аккуратно отключить сервисы N и O, удалить старый код из сервиса F.
Звучит как сложный и долгий план с большим количеством изменений в системе, любое из которых может закончиться инцидентом. К тому же обновлённый сервис F1 не будет супернадёжным при первом релизе — он ещё не проверен на продакшне под разными профилями нагрузок и не встречался с аномалиями в данных. Мы получим долгосрочный выигрыш в надёжности, но заплатим за это краткосрочными рисками во время реализации.
Проверим, стоила ли игра свеч:
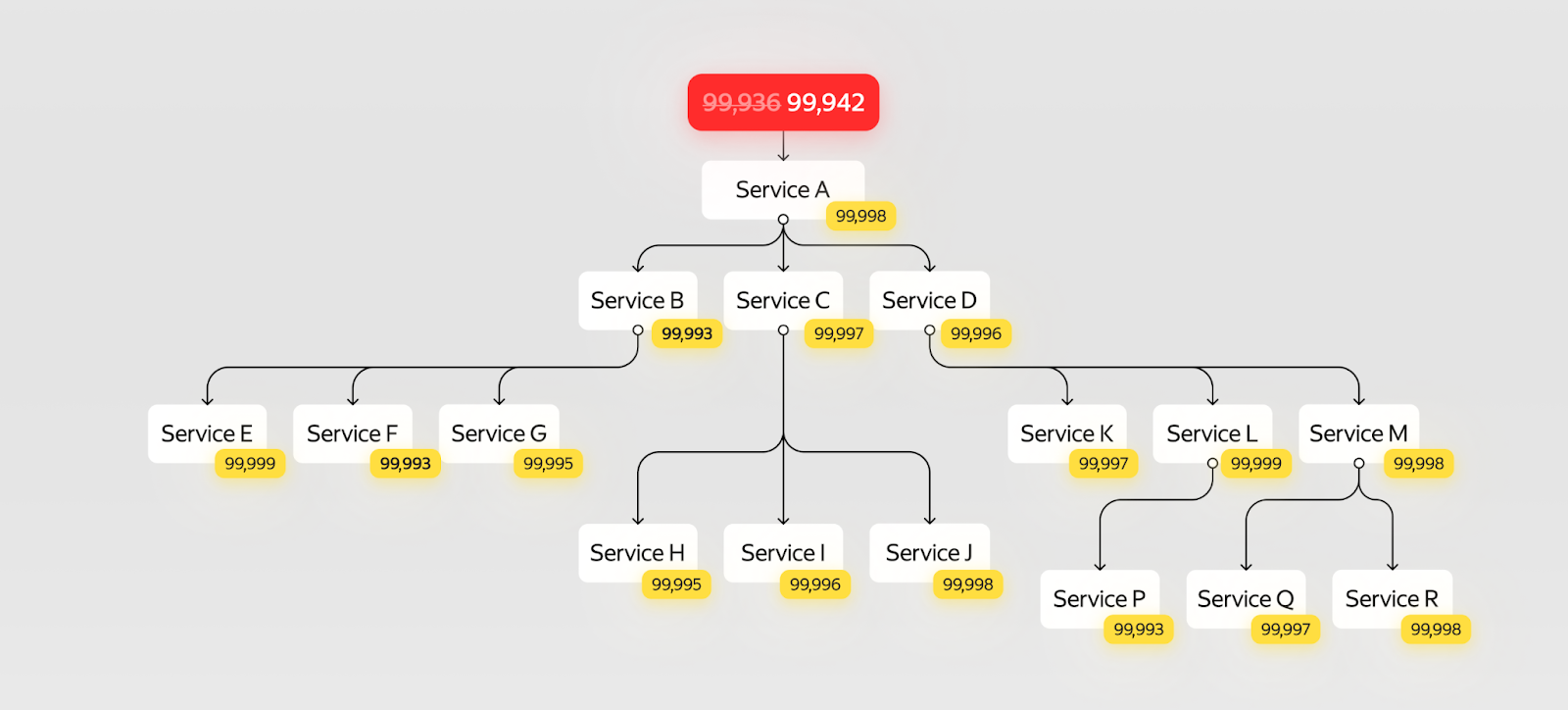
На первый взгляд надёжность нового сервиса стала сильно ниже, чем у исходного. Но у нашей модели запросов есть очень полезное свойство — можно посчитать суммарную надёжность поддерева. И тогда станет заметно, что надёжность обновлённого участка на самом деле сильно выросла: 99,993% > 99,986%.
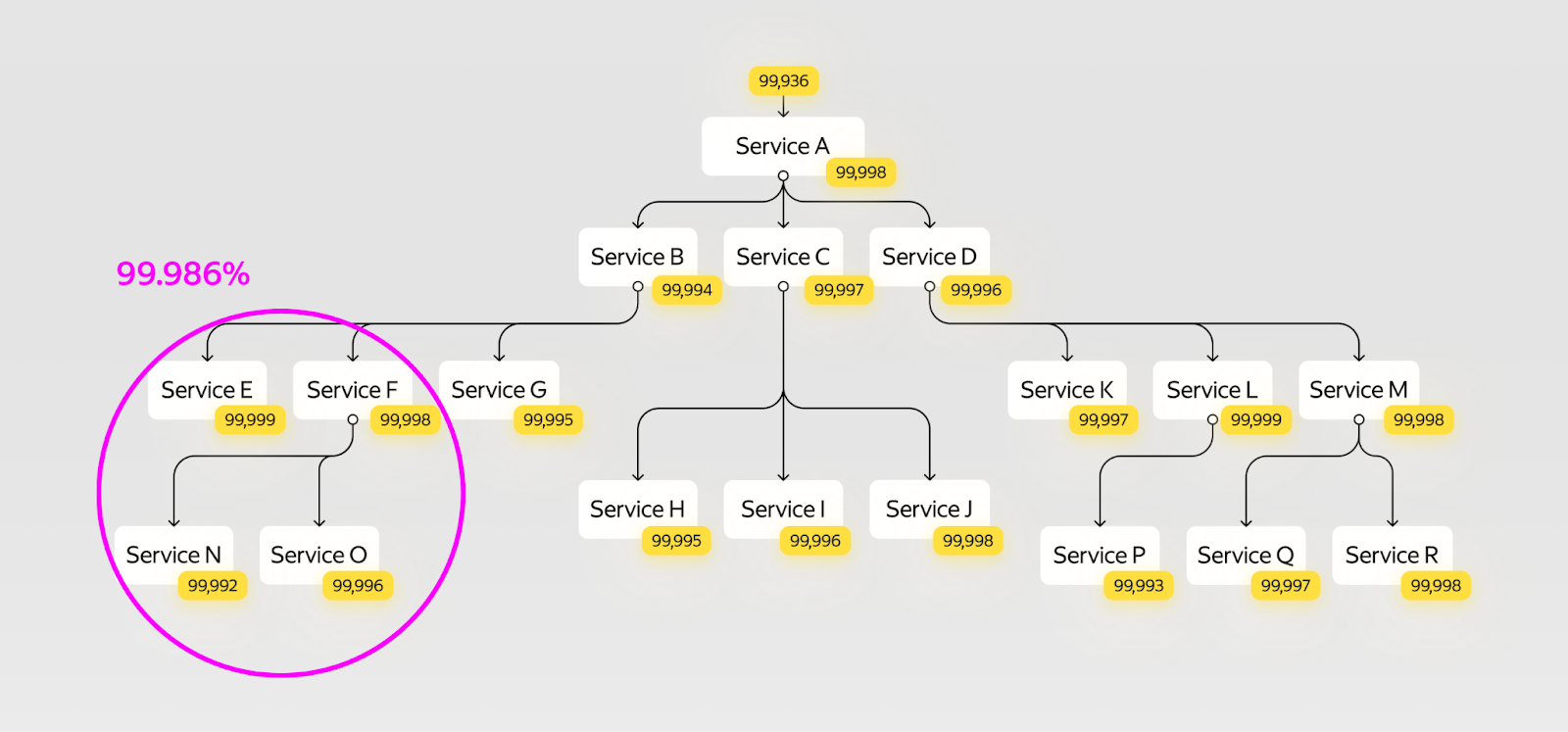
В итоге мы получим изменение надёжности, которое уменьшит время недоступности с 5,5 до 5 часов в год. И риск появления опасного инцидента.
Проблема в том, что чем больше общая надёжность системы, тем меньше будут влиять на неё точечные изменения. А рефакторинг при этом всё ещё может занять много человеко‑часов. Нужно придумать что‑то другое.
Постмортемы и разметка инцидентов
К счастью, многие вещи не нужно придумывать, потому что это уже сделал кто‑нибудь другой. Итак, постмортемы.
Про них немало написано и рассказано, поэтому в статье ограничусь краткой справкой о том, как это устроено:
- На каждый инцидент мы заводим специальный тикет, где описываем, что пошло не так, какие инструменты помогли или помешали решить задачу, что отработало как надо и где корневая причина проблемы.
- Считаем, как инциденты повлияли на бизнес. Например, так: «сервис был недоступен четыре минуты» или «мы потеряли пять тысяч заказов».
- Выявляем самую важную причину недоступности: группируем инциденты по корневым причинам и сортируем по значительности их влияния. Например, мы правим горячие конфиги (это те, которые не подкладываются с релизом, а сразу доставляются на сервис). За релизами присматривает «канарейка», а конфиги бесконтрольно залетают на все поды сразу. Из‑за этого мы можем сделать недоступным какой‑нибудь сервис.
Простое решение — сделать все конфиги холодными. Но у меня есть предложение получше: давайте сделаем «канарейку» на конфиги!
Исходная система была недоступна 5,5 часов: она состоит из множества сервисов, почти в каждом из которых, скорее всего, есть конфиги. А около конфигов обычно водятся люди, которые любят их крутить.
Мы меняем сервис конфигов, добавляя в него свою «канарейку». Можно совсем чуть‑чуть увеличить надёжность каждого сервиса, но в итоге подрастёт надёжность всех сервисов, которые используют конфиги.
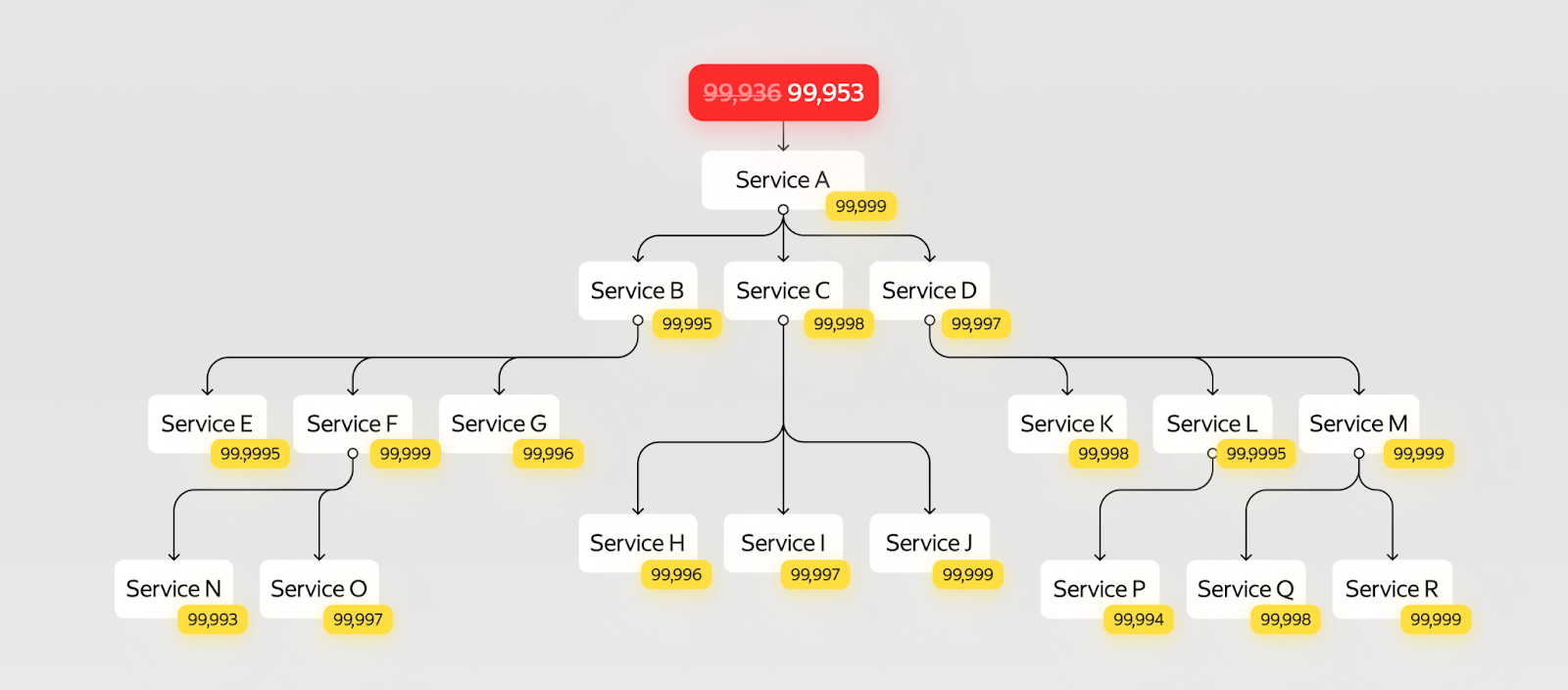
В итоге вместо 5,5 часов недоступности мы получим 4 часа в год — в несколько раз лучше, чем в первом сценарии! А благодаря тому, что мы ведём постмортемы несколько лет, у нас всегда есть ранжированный по степени критичности список корневых причин, которые можно починить следующими.
При анализе постмортемов вы с большой вероятностью часто будете использовать слово «платформа». Именно поэтому оно есть в названии нашей команды.
Изоляция критичного контура
Сервис A вызывает сервисы B, C и D. Давайте проверим, а точно ли нам нужен вызов и результат, например сервиса B. Возможно, его стоит чем‑нибудь заменить так, чтобы система продолжила работать, даже если откажет любой сервис из этого поддерева.
Для наглядности предположим, что мы делаем сервис такси. Если нужно отправить машину к пользователю, точно ли важно знать цвет машины и показывать пользователю ошибку, если сервис, извлекающий цвет из хранилища данных об авто, недоступен? Не лучше ли показать машину без цвета?
Чтобы это реализовать, возьмём запрос и найдём первый сервис, в который он приходит из входящей proxy. Проанализируем каждую зависимость: попробуем вычеркнуть её и найти способ сделать так, чтобы система продолжила работать и без этого сервиса.
Например, вычеркнув из поддерева всех вызовов поддерево вызовов сервиса B, можно увеличить надёжность системы от 5,5 часов недоступности в год до 3 часов 20 минут.
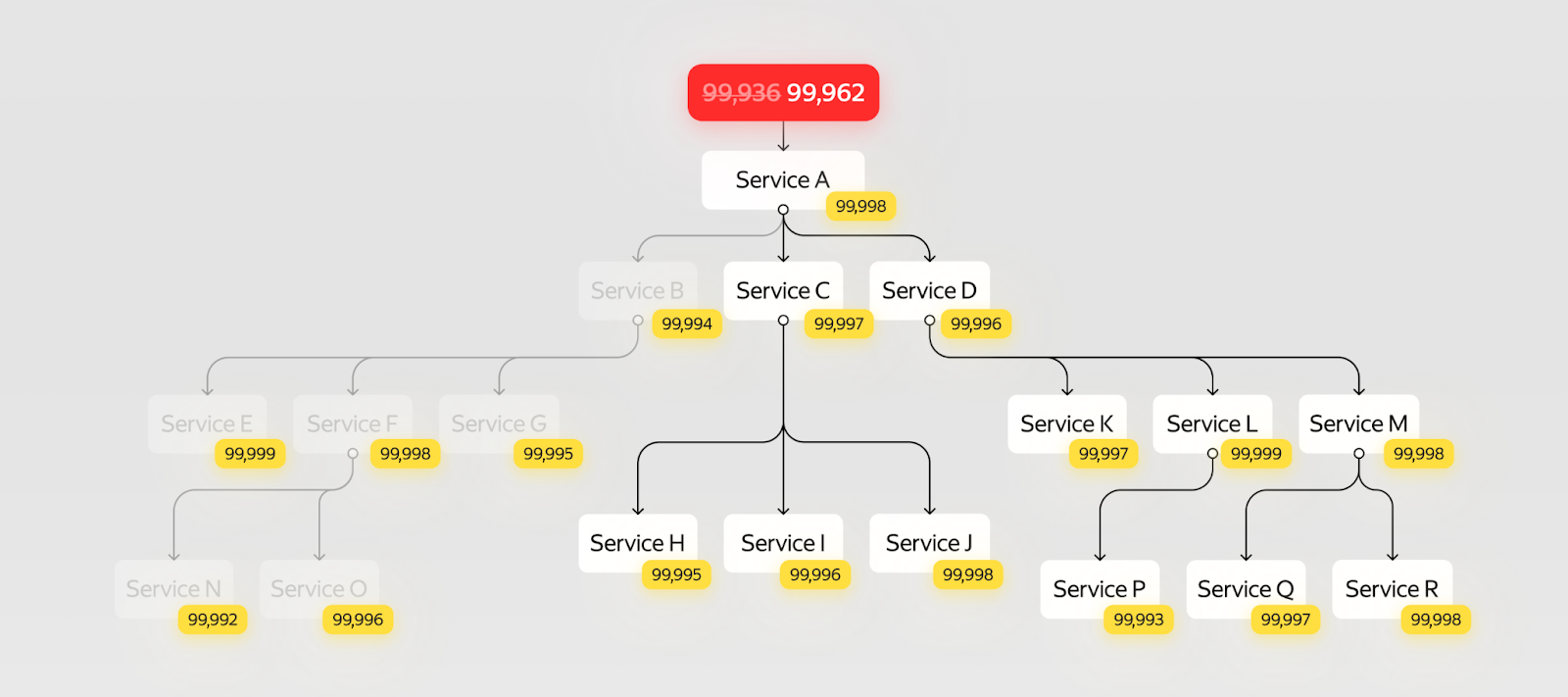
Это очень крутой результат: даже лучше, чем в прошлом варианте. А ещё внести это изменение может быть значительно проще, чем править платформу, но это требует большего знания домена.
Какие есть способы избавиться от зависимости между сервисами с учётом бизнес‑логики? Есть несколько сценариев, например заглушки, кеш, фолбэки, теневые реплики.
Сценарий первый. В примере с цветом машины достаточно сделать заглушку: если запрос вернул ошибочный код ответа или завершился таймаутом, мы заменяем ответ на пустой, а итоговая надёжность поддерева составит почти 100%.
Сценарий второй. Заглушка не поможет, если мы хотим показать список доступных пунктов выдачи товаров или что‑то похожее. Сервис вернёт данные с учётом габаритов заказа, расписания и других параметров, но показывать пустой список при его доступности нельзя — за 5 минут недоступности клиент найдёт товар на другом маркетплейсе. Да, там не будет доставки по кнопке, зато всё будет работать.
Решение: сделать простой key‑value кеш, который будет возвращать список всех пунктов выдачи в указанном городе. С этим поможет простой Redis, который, кстати, обладает собственной надёжностью. А ещё логика, которая пополняет этот кеш, тоже может иметь надёжность ниже 1.
Надёжность системы считается по формуле для параллельно соединённых элементов и складывается из надёжности исходного сервиса, который может отказать, и надёжности кеша:

Если данных не очень много, они не очень быстро устаревают и есть понятный ключ — key‑value кеш отлично справится, а заодно снизит нагрузку на кластер.
Сценарий третий. А что, если нужно сказать, через сколько приедет машина, а сервис пробок или карт недоступен? Можно посчитать расстояние между точками A и B, поделить на разрешённые в городе 60 км/ч и сказать, что машина приедет примерно за это время. Другими словами, написать фолбэк‑логику, которая решает задачу упрощённо с допустимым качеством.
Иногда таких фолбэков может быть даже несколько — время подачи машины можно считать по графу дорожной сети без учёта пробок, если недоступны только пробки, либо по расстоянию между точками, если невозможно построить маршрут по графу.
Фолбэки могут быть тяжеловесными или использоваться для долгих деградаций. Поэтому иногда для них пишут отдельный переключатель режимов, который включает резервную логику и возвращает основную обратно в зависимости от статистики. У такого переключателя тоже будет своя надёжность. А формула надёжности станет произведением надёжности механизма фолбэков на надёжность параллельно соединённых элементов. Больше вариантов фолбэков — выше надёжность, но она никогда не выше самого механизма фолбэков. Чувствуете, как я люблю писать слово «фолбэки»?
Сценарий четвёртый. Если ни один из трёх вариантов выше вам не подходит, ситуацию может исправить Shadow Replica, или теневая реплика.
Представьте: пользователь вызывает автомобиль, а вам нужно найти ближайших водителей и отправить каждому из них предложение взять заказ. Key‑value кеш не подойдёт, потому что сложно построить ключ, когда данные часто меняются и зависят от положения пользователя. В этом случае иногда можно создать копию данных прямо в памяти процесса и отправлять в неё быстрые запросы, а обновлять данные в фоне. Но такое решение создаёт дополнительные проблемы с надёжностью.
Первая проблема — память. На линии много водителей, и они должны одновременно попасть в каждую реплику сервиса: для этого понадобится очень много оперативной памяти. Звучит некритично, но это важно учитывать, особенно если реплик много. Можно построить геошардированные сервисы, но для этого нужен механизм маршрутизации запросов в зависимости от географии, а это тоже дополнительная точка отказа, которую теперь нужно будет учитывать.
И не забывайте, что все эти данные придётся переналивать после каждого релиза сервиса — то есть настоящее дублирование и повышенная надёжность у сервиса будут только при полностью готовой теневой реплике, в остальное время доступность зависимости будет критична для работы сервиса. Если данных достаточно много и реплика создаётся в течение получаса, то мы получим (0,5 * число релизов в год) часов в год, когда этот механизм не будет работать.
Ещё одна проблема — когда зависимость становится недоступна, данные о положении водителей на карте очень быстро устаревают. Мы избавимся от проблемы на 15 минут, но при бóльшей недоступности механизм перестанет работать или начнёт предлагать заказы водителям, которые далеко от пассажиров или уже ушли с линии, если вы не учли такой сценарий.
В итоге надёжность либо повысится незначительно, либо и вовсе уменьшится из‑за проблем с логикой работы слепков данных. Поэтому теневые реплики — опасный способ. Используйте его только, если точно уверены в том, что делаете.
Что делать, если ни заглушка, ни key‑value кеш, ни Shadow Replica не подходят? Поискать, можно ли что‑нибудь переписать и отрефакторить так, чтобы стал доступен хотя бы один из этих вариантов. Получилось — отлично, не получилось — пора переходить к следующей зависимости или искать в глубине дерева вызовов более локальное место для изоляции.
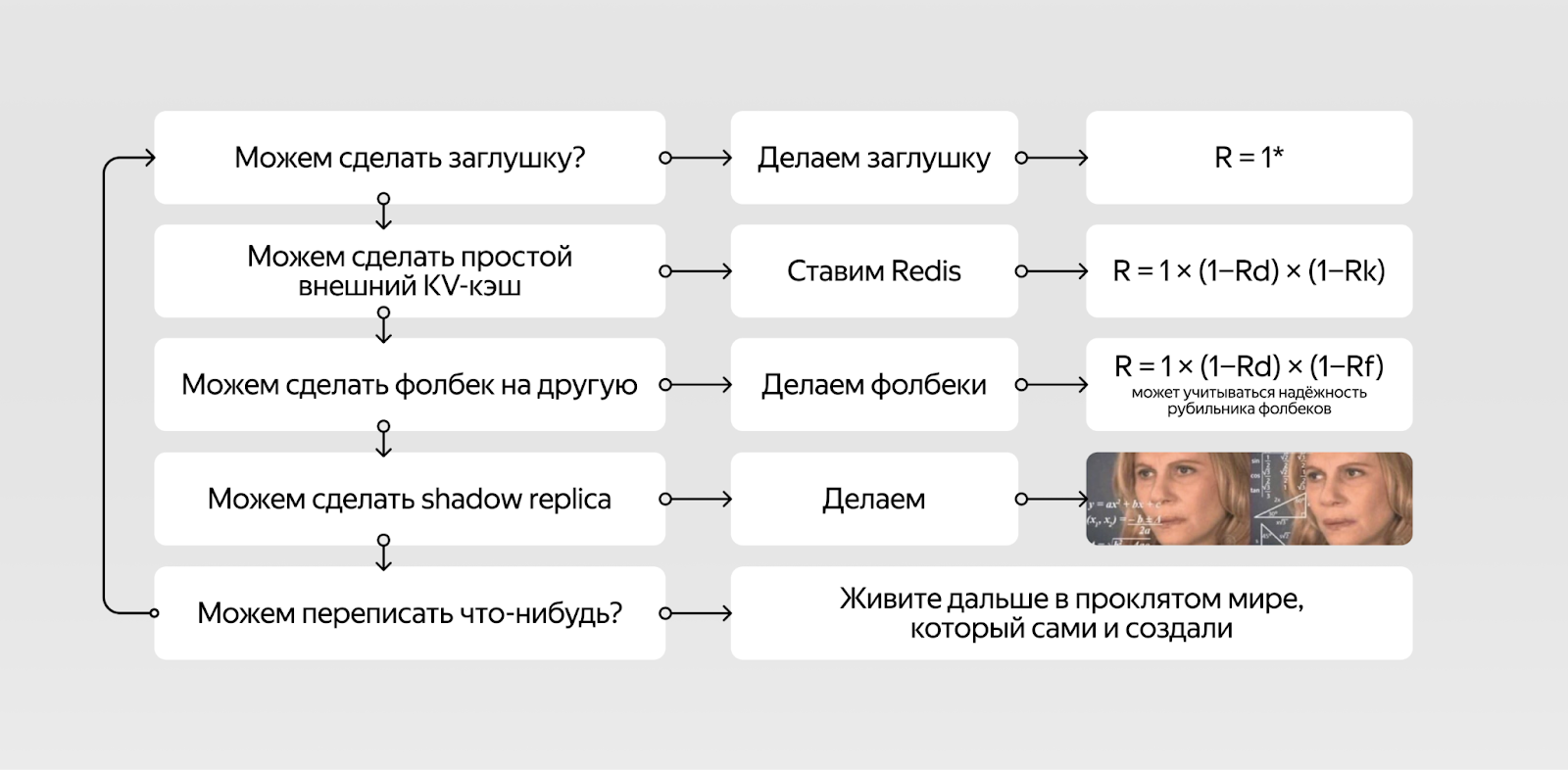
Найти и проверить границы критичного контура помогает хаос‑инжиниринг. Последовательно отключаем зависимости первого уровня и убеждаемся, что сервис работает, — значит, мы правильно изолировали критичный контур. Если сервис упал, то зависимость критичная.
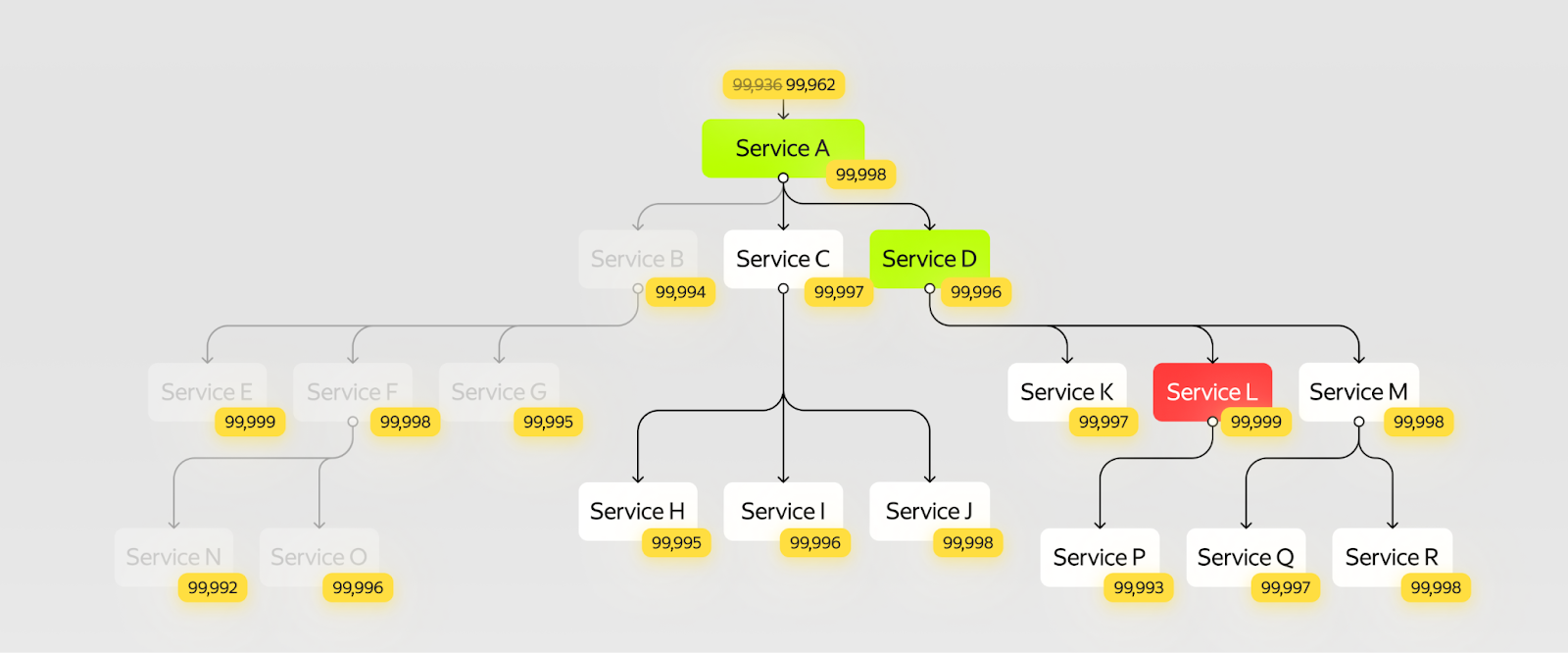
Если избавиться от критичности не удалось, то можно изолировать сервис уже от его собственных зависимостей, повторив алгоритм с их последовательным отключением.
Уменьшение Blast Radius
Плохой релиз может задеть клиентов из любого города. Инцидент, связанный с одной страной, забивает очередь сообщений и приводит к проблемам сразу везде. И даже формула надёжности учитывает именно общую доступность сервиса.
А что, если вместо одного большого кластера сервисов сделать несколько изолированных, которые не будут влиять друг на друга? Изменения смогут накатываться на отдельные кластеры и не затрагивать всех пользователей сразу, а проблемы с ресурсами и сетью не сломают совсем всё.
Формула надёжности изменится:

 кластера 1
кластера 1  доля запросов 1
доля запросов 1 
 кластера 2
кластера 2  доля запросов 2
доля запросов 2 
 кластера
кластера
 доля запросов
доля запросов 
Такая схема применима совсем не везде, но разделять пользователей по кластерам может быть полезно — если бизнес достаточно изолирован по географиям или нужно дать отдельный SLA для части пользователей, а значит им стоит выкатывать только уже проверенные временем на других кластерах релизы.
Почему эта модель не работает
Стоп, что?
На самом деле количественно оценить надёжность микросервисов по таким формулам не получится: модель не отражает реальность.
Во‑первых, формула для последовательно соединённых элементов работает только для независимых элементов. Наши сервисы не живут в изоляции, они пользуются общими механизмами авторизации, сетью и платформой. Поломка одного элемента может привести к всплеску нагрузки в очередь сообщений, которая потратит весь Rate Limit к сервису и повлияет на распределение задач из очереди не только внутри этого элемента, но и внутри всего кластера. Перегруженный сервис будет возвращать ответ с большим Latency, что не вызовет ошибки в нём, но может выесть бюджет времени запроса в каком‑то другом сервисе.
Во‑вторых, для микросервисов сложно определить их собственную надёжность без зависимостей. Можно посчитать доступность сервиса А и вычесть из неё недоступность зависимостей, но эта метрика никак не поможет. Можно было бы попробовать оценить внутреннее качество сервиса частично, но нам‑то важна доступность системы с учётом зависимостей.
Но всё не так плохо. Чтобы принимать решения, необязательно знать точную надёжность сервисов. Но важно учитывать:
- На надёжность сервиса влияет не только его внутренняя надёжность, но и взаимодействие с зависимостями. Так считаются SLI/SLO, и именно на основе этих цифр нужно принимать решения. Если сервис не соблюдает SLO из‑за ненадёжных зависимостей, то это хороший индикатор того, что стоит сходить к коллегам и поработать над решением вместе.
- На надёжность системы влияет только надёжность критичного контура, поэтому общая надёжность хорошо коррелирует с размером этого контура. Иногда можно воспользоваться этим и принимать решения, опираясь не на расчёт надёжности, а на данные о количестве сервисов.
- Даже без точных цифр можно оценить ожидаемый тренд изменений в сервисах.
Reliability + Resiliency: надёжность + устойчивость
Можно считать, что с надёжностью мы разобрались. Но есть ещё одна проблема. Мы уменьшили время недоступности до 3,5 часов — почему не до нуля? Об этом есть история.
Предположим, у нас есть прекрасный серверный жёсткий диск: современный, в характеристиках обещают, что среднее время работы до отказа — 100 лет. Для продукта из сотен микросервисов и БД понадобится несколько тысяч таких дисков: например, 3 тысячи. Как часто они будут выходить из строя?
Есть простая формула, по которой можно посчитать среднее время между отказами, — MTTF:
MTTF = среднее время отказов одного элемента / количество элементов = 100 лет / 3 000 дисков = 12 дней
По этой оценке каждые 12 дней должен ломаться один диск. В реальности для больших чисел порядка 100 лет, это работает несколько иначе, потому что распределение времени выхода из строя неравномерное. Но раз в пару месяцев у вас действительно будет отваливаться какой‑нибудь диск. И иногда это будет приводить к инцидентам.
Оптоволоконные кабели между дата‑центрами тоже умеют регулярно разрываться при помощи экскаваторов, а значит иногда это будет происходить в нескольких местах и между разными дата‑центрами одновременно, так что на любую катастрофоустойчивость найдётся катастрофа побольше.
Получается, что предотвратить все инциденты не получится. Что делать?
Короткий ответ: перестать заниматься надёжностью. Точнее, заниматься не только надёжностью, но и устойчивостью. Это свойство системы оставаться в работоспособном состоянии или быстро восстанавливаться после поломки.
Есть быстрый способ проверить, в чём именно проблема системы: в надёжности или в устойчивости. Предположим, что мы уменьшили недоступность системы до 200 минут в год:
- Если 200 минут — это 100 инцидентов по две минуты, то в системе происходит слишком много инцидентов. Стоит сгруппировать их по корневой причине и поискать проблему надёжности. Вылечить её можно будет либо изолировав критичный контур, либо поработав с постмортемами и инцидент‑менеджментом.
- Если недоступность складывается из 10 инцидентов по 20 минут, то каждый инцидент с большой вероятностью уникален: предсказать, что и как сломается в следующий раз, не получится. Это значит, что нужно работать не над уменьшением числа инцидентов, а над скоростью восстановления системы. Или учиться быстрее находить корневые причины. Вспомним картинку из начала поста:
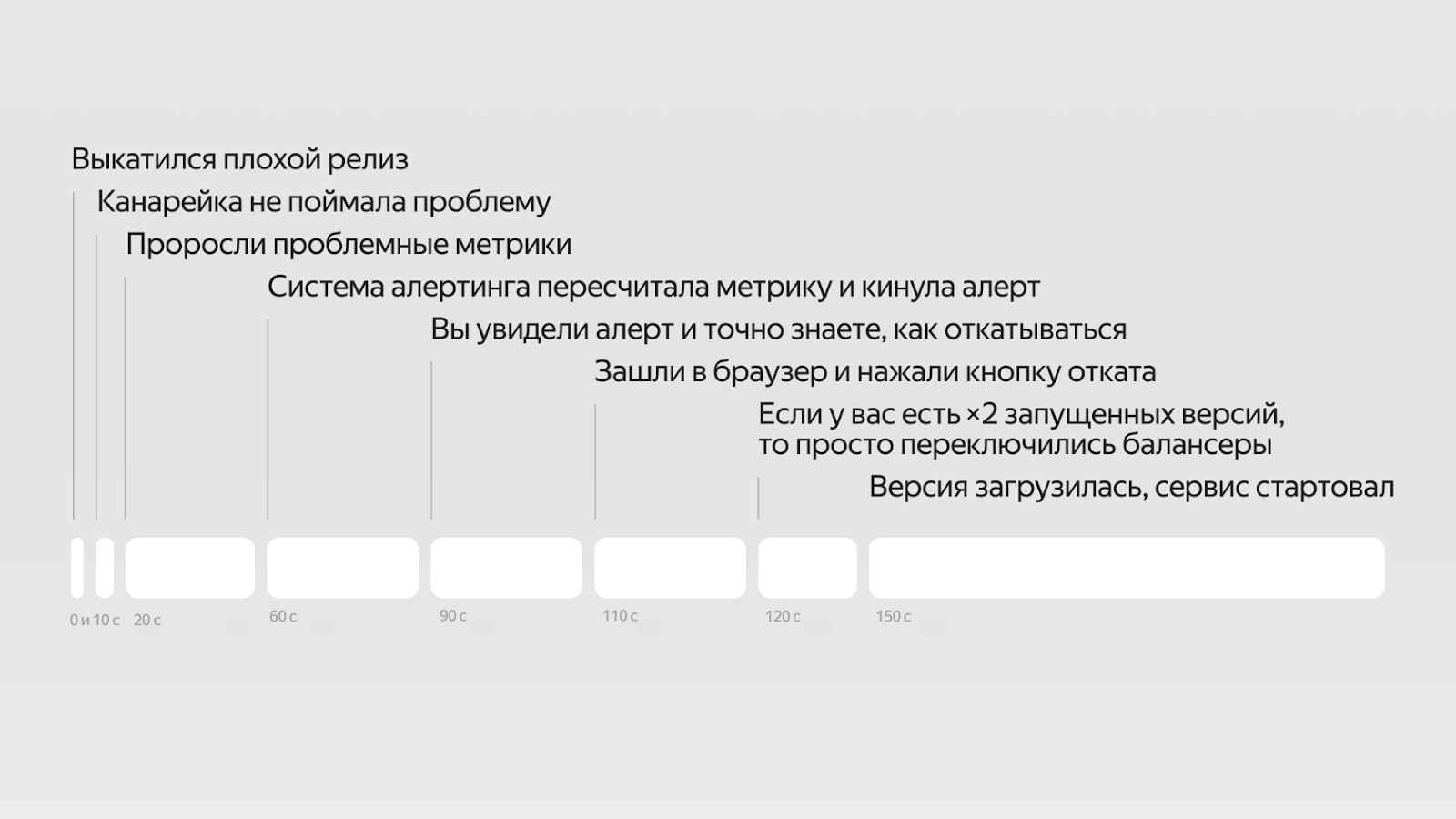
Если ускорить откат релиза, время инцидента уменьшится. Ускорим доезд метрик и алертов — сократим время инцидента ещё больше. Если «канарейка» ловит не метрики конкретного сервиса, а ещё и бизнес‑метрики всей системы, то можно быстро откатиться к беспроблемной версии и устранить проблему за несколько десятков секунд.
Поэтому, когда вы имеете дело с редкими длинными инцидентами, важно анализировать время нахождения корневой причины и время восстановления и искать способы их сократить. Именно этим занимается моя команда платформы надёжности: пока мы уменьшаем MTTR/MTTRC, продуктовые команды занимаются надёжностью сервисов.
Вся статья в 7 пунктах
Давайте попробуем подвести итоги:
- Для того, чтобы обеспечить надёжность всей системы, недостаточно сделать надёжными отдельные её элементы.
- Чинить локальные проблемы для каждого инцидента может быть невыгодно.
- Вести постмортемы классно. Чтобы через два года сказать себе спасибо, начните вести их прямо сейчас.
- Не все решения во имя повышения надёжности на самом деле повысят её.
- Уменьшайте Blast Radius, изолируйте критичные сервисы от некритичных, Например, в Такси из 800 с лишним сервисов критичными для нас являются около 30.
- Восстанавливайтесь быстрее: избавиться от всех инцидентов не получится.
- Чтобы написать статью о надёжности, мне пришлось употребить слова «надёжность» и «надёжный» 76 раз.
Спасибо, что дочитали до конца. А как оценивают и повышают надёжность (77 раз!) в вашей команде? Приходите обсудить в комментариях.



