
Привет! Меня зовут Максим, и я отвечаю за оркестрацию в логистической платформе Маркета. Сегодня я хочу рассказать, как мы управляем физическим миром с помощью кода и почему логистика — это одна из самых интересных и недооценённых IT-областей.
На мой взгляд, самое интересное в логистике — её двойственность. С одной стороны, её принципы интуитивно понятны каждому. Что нужно, чтобы фура из Москвы в Питер привезла максимум пользы? Правильно — загрузить её товарами под завязку. Как ускорить работу сотрудника на сортировочном центре? Сгруппировать несколько заказов в одну большую коробку, чтобы он сканировал один штрихкод вместо десяти. Всё это кажется простым и очевидным.
А с другой стороны — это колоссально сложная система. Чтобы ваш заказ преодолел путь от полки склада до пункта выдачи, его касаются десятки рук — кладовщики, водители, сортировщики, курьеры. И всё это происходит в рамках жёстких ограничений: нам нужно найти идеальный баланс между скоростью доставки, которую мы пообещали, качеством сервиса и затраченными ресурсами. Когда таких заказов сотни тысяч в день, задача становится совсем нетривиальной, потому что очевидные решения перестают работать.
Именно для управления этой сложностью мы и создали нашу платформу оркестрации. В этой статье я не смогу охватить всё, что мы делаем, но постараюсь рассказать подробнее и про нас, и про нашу архитектуру, про то, как она эволюционировала со временем и как развивается прямо сейчас. Но для этого нам придётся начать с ключевого вопроса: что же мы называем оркестрацией?
Что мы называем оркестрацией
Итак, как мы уже выяснили, чтобы ваш заказ добрался до вас, с ним должны поработать десятки людей на множестве объектов — от склада до ПВЗ. Как они узнают, что именно нужно сделать с конкретной коробкой? Что будет, если они сделают что-то не то? Или если вы вдруг захотите отменить заказ, когда тот уже в пути?
В нашей логистической платформе мы решаем эту задачу через чёткое разделение ролей: есть оркестрация и есть исполнители. Исполнители — это наши логистические объекты и люди, которые непосредственно работают с товарами в физическом мире: склады, сортировочные центры, пункты выдачи заказов и курьеры.
У каждого своя зона ответственности. Основная задача исполнителя — выстроить максимально эффективные внутренние процессы. А основная задача оркестрации — эффективно использовать всех этих исполнителей, чтобы выполнить обещания, которые мы дали пользователю. Проще говоря, оркестрация раздаёт задания всем участникам цепочки и следит за их исполнением, а каждый исполнитель фокусируется на своей части работы.
Четыре всадника логистики
И что же тут сложного, спросите вы? Казалось бы: дали задания, исполнители их выполнили, заказ доехал, все счастливы. И, да, в подавляющем большинстве случаев именно так и происходит. Истина, как всегда, в деталях. Некоторые интересные нюансы могут превратить простую картину в по-настоящему сложную инженерную задачу. Давайте на них посмотрим.
1. Заказы существуют только в голове у пользователя
Первый и, пожалуй, фундаментальный нюанс — это разница доменов. Как вы думаете, с чем работает логистика? Скорее всего, первым на ум приходит «заказ». Это логичная и понятная для пользователя сущность. Но для физического мира её не существует.
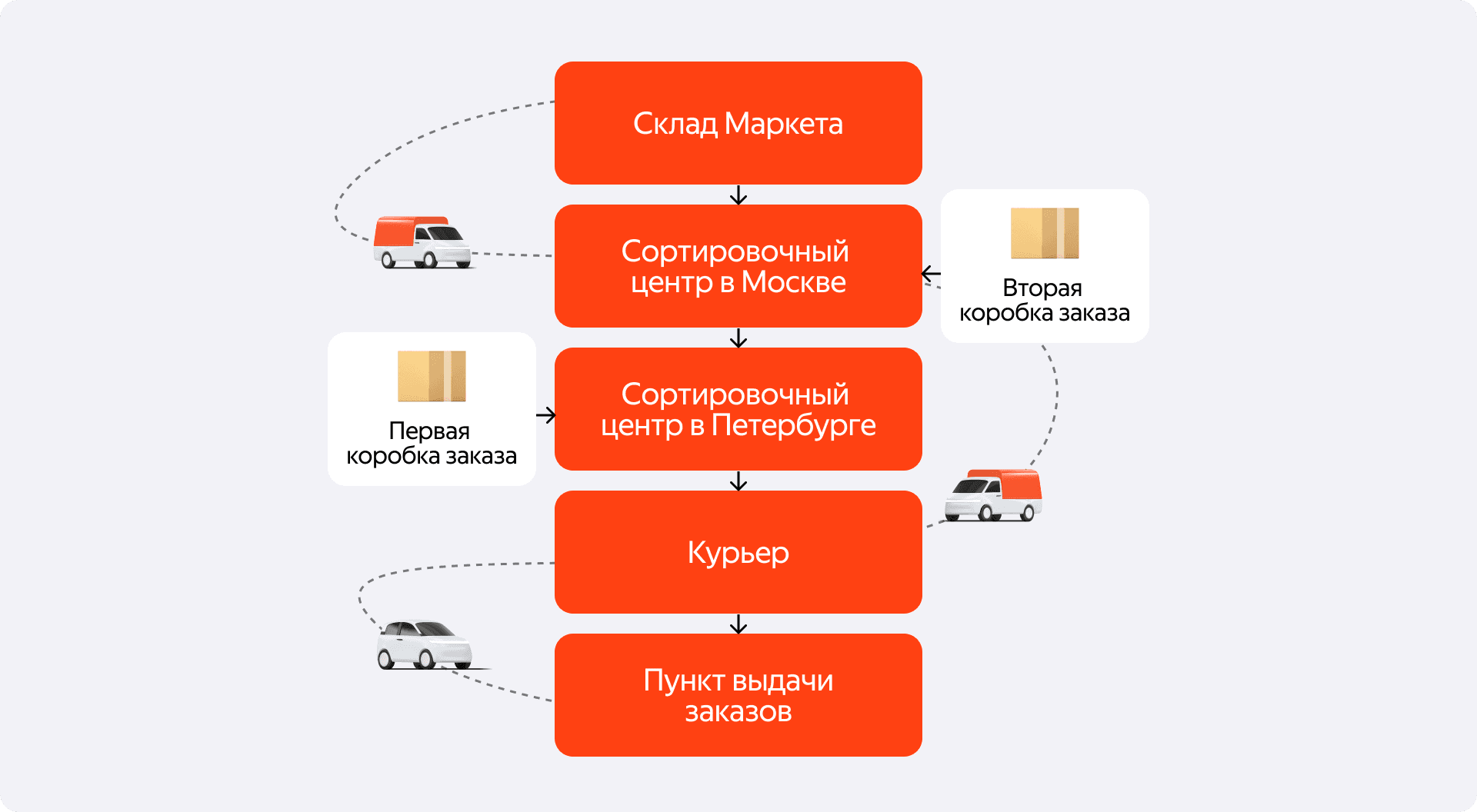
На складе лежат товары. Между объектами мы перевозим грузоместа — коробки и палеты, в которые эти товары упакованы. Пользователю мы тоже выдаём товары. Получается, что сам по себе «заказ» — это абстракция для клиента, а наша система должна транслировать её в операции с физическими объектами. И здесь начинаются сложности. Один заказ может состоять из нескольких грузомест, и с точки зрения логистики каждое из них — независимая единица. У каждой коробки своя жизнь, свой путь и своя история. И если с одной из них что-то пойдёт не так, оркестратор должен уметь это обработать, не затрагивая остальные части заказа.
2. Логистика — это не только доставка «туда»
Когда мы говорим «логистика», обычно представляем себе путь товара к покупателю. Но это лишь часть картины. Чтобы товар можно было доставить, он должен сначала как-то попасть на склад — это процесс поставки. Иногда партнёр хочет забрать свой товар — это изъятие. А ещё есть возвратный поток — когда пользователь отказался от товара в ПВЗ или вернул его после покупки.
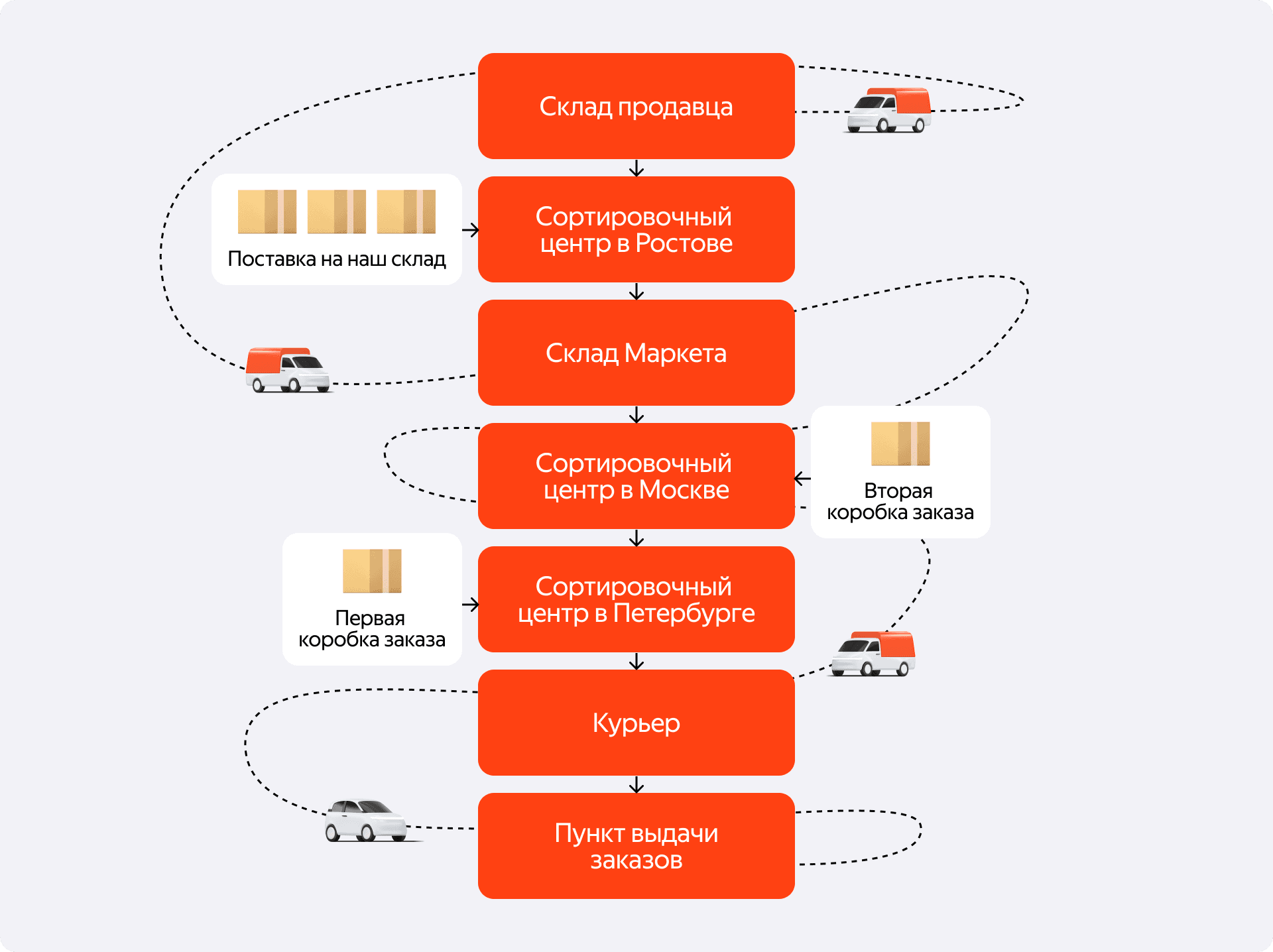
Полный флоу обработки всех этих сущностей также лежит в зоне ответственности оркестрации. При этом бизнес-логика для них кардинально отличается. Заказы должны доехать до клиента максимально быстро, ведь мы пообещали ему конкретную дату. А вот возврат может ехать и дольше — на обратном потоке мы не хотим тратить лишние деньги. Оркестратор должен понимать эту разницу и для каждого типа грузоместа строить оптимальный маршрут, исходя из его бизнес-цели.
3. «Моя коробочка уехала не туда»
Представьте, что коробку с вашим заказом по ошибке положили не в ту машину. Она гарантированно уедет в неверном направлении, и теперь её нужно спасать. Чтобы это сделать, система должна мгновенно отреагировать в тот момент, когда ошибка будет обнаружена — то есть когда коробка приедет на «чужой» склад и её отсканируют.
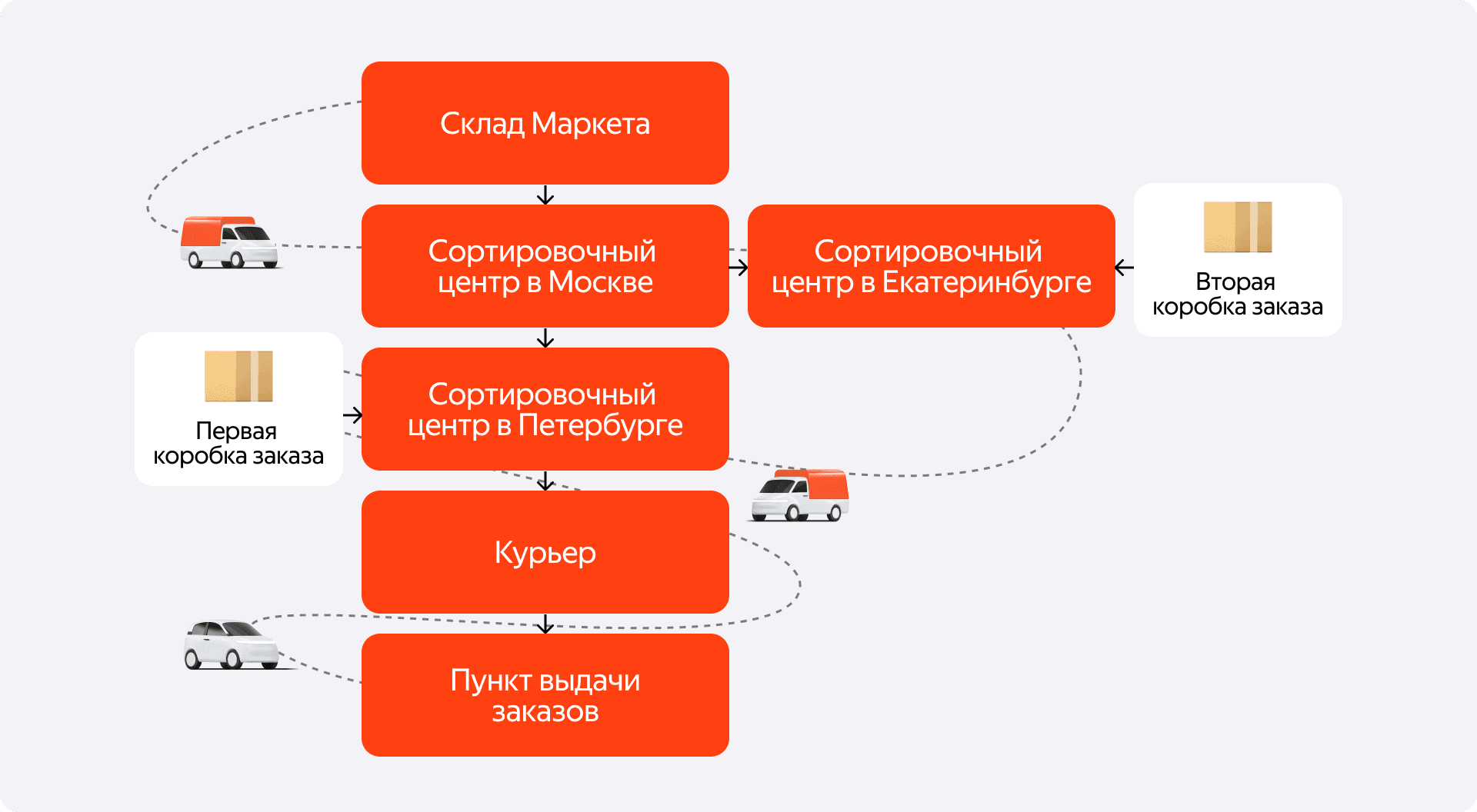
В этот момент оркестратор должен в реальном времени перестроить для неё маршрут из новой точки, выдать новые задания исполнителям и, если нужно, сообщить пользователю об изменении сроков. Самое главное — для сотрудника склада, который принял эту коробку, она не должна выглядеть как-то по-особенному. Он просто сканирует штрихкод и получает от системы чёткую инструкцию, что делать дальше, даже не задумываясь, что у этого грузоместа уже есть своя неудачная история. И да, мы это всё умеем и успешно делаем.
4. Искусство батчинга
А теперь давайте представим склад в Москве, с которого можно заказать товары в Ростов. Допустим, с этого конкретного склада объёма заказов не хватает, чтобы каждый день заполнять целую фуру до Ростова. Но со всех московских складов вместе — вполне набирается. Для этого в Москве есть сортировочный центр, куда привозят товары с разных складов, чтобы объединить их в одну большую партию на Ростов.
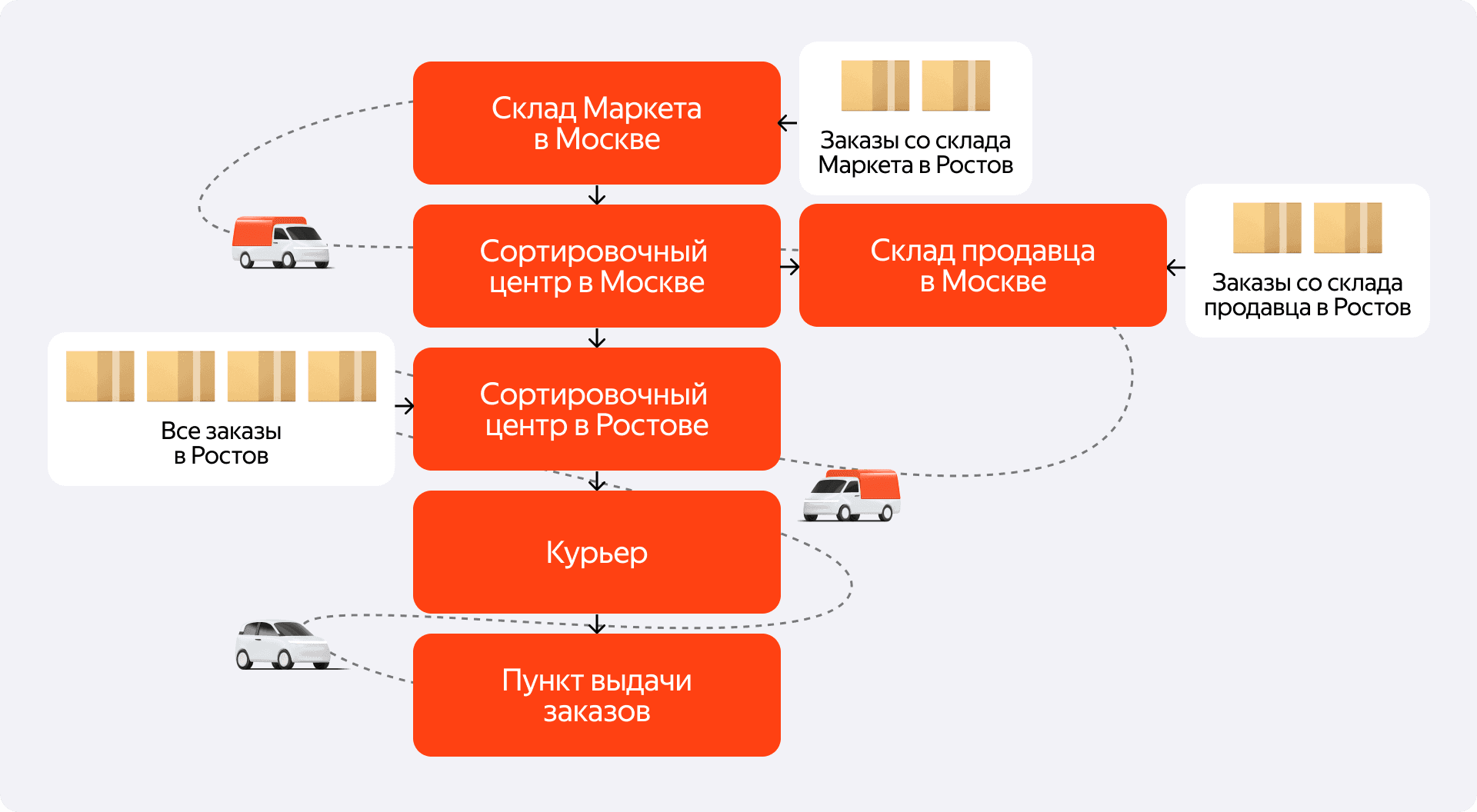
Но что, если на исходном складе мы всё же смогли собрать несколько палет, которые целиком едут в Ростов? Было бы крайне неэффективно разбирать их на сортировочном центре, чтобы потом снова собрать. Этот процесс объединения и есть батчинг. И происходить он может на любом логистическом объекте.
Конкретному исполнителю — складу или СЦ — не обязательно знать про общие объёмы и полные маршруты. Поэтому оркестратор даёт ему рекомендации в более абстрактной форме: «вот эти коробки было бы здорово объединить и отправить дальше как есть». Но это именно рекомендация, а не приказ. Ведь мы не знаем, в какой момент эти коробки окажутся на СЦ. Если они приедут с большим разрывом во времени, исполнителю будет невыгодно ждать и собирать полупустую паллету. Наша платформа умеет работать и с такими гибкими сценариями.
Семь слоёв абстракции над физическим миром
Чтобы справляться со всеми этими вызовами, в ходе эволюции архитектура нашей оркестрации стала слоёной. Она позволяет нам отделять бизнес-логику от физического исполнения и гибко работать с разными типами задач и партнёров. Давайте я кратко расскажу про каждый из этих слоёв, двигаясь от внешнего пользователя вглубь системы.
L0-L2: внешний мир и его переводчики
Всё начинается с L0 — внешних пользователей. Это покупатели на Маркете, мерчанты, которые продают у нас товары, или пользователи Яндекс Доставки. Они взаимодействуют с L1 — системами для работы с внешними пользователями, например, с приложением Маркета. Для нас этот слой — чёрный ящик. Мы не должны знать, как он устроен, но именно оттуда приходят запросы к логистике.
Чтобы изолировать нашу внутреннюю кухню с учётом специфики каждого такого потребителя, существует L2 — логистические фасады. Этот слой — своего рода «переводчик». Например, Маркету нужно получать один набор событий о движении заказа, а Яндекс Доставке — другой. Фасады берут на себя эту адаптацию, реализуют специфичные для потребителя API и позволяют нам не тащить эту логику в ядро платформы.
L3-L4: ядро логики
Здесь начинается самое интересное. L3 — это оркестраторы-владельцы бизнес-сущностей. На этом уровне система «мыслит» категориями заказов, поставок и возвратов. Именно здесь зашита бизнес-логика. Например, если коробка заказа уехала не туда, её нужно во что бы то ни стало доставить пользователю. А если заблудилась коробка возврата, её можно отправить на ближайший склад, если это выгодно и разрешено договором с продавцом.
А вот на следующем уровне, L4, находится core-платформа перевозки грузомест. Здесь мы переходим от бизнес-домена к чистому логистическому домену товаров и грузомест. Этим сервисам всё равно, что лежит в коробке — заказ, возврат или поставка. Их задача — дать универсальные задания на превращение товаров в грузоместа (первая миля), их перевозку по сети (средняя миля) и выдачу получателю (последняя миля). На этом слое нет никакой специфики, связанной ни с бизнес-сущностью, ни с типом исполнителя.
L5-L7: уровень исполнения
Наконец, нам нужно передать задания в физический мир. L5 — это фасады для исполнителей и процессные сервисы. У каждого исполнителя — будь то наш собственный склад или внешний партнёр вроде Почты России — своё API. Этот слой занимается конвертацией общих команд из L4 в конкретные вызовы API каждого исполнителя.
Также здесь живут процессные сервисы: именно они отвечают на вопросы в духе «что делать с коробкой, которая приехала не туда?» — это рантайм, который нужен исполнителям в моменте.
Дальше идут L6 — сами исполнители — системы ПВЗ, СЦ, складов, которые для оркестрации тоже являются чёрным ящиком, и L7 — пользователи исполнителей: кладовщики, курьеры и сотрудники ПВЗ, которые непосредственно работают с товарами.
Вне этой иерархии у нас есть и другие логистические рантайм-сервисы, которые отвечают за расчёт даты доставки при оформлении заказа или за бронирование товара на складе. Но основная логика движения грузомест живёт именно в описанной слоёной архитектуре.
Пределы роста, или что пошло не так
Эта концепция отлично работала. Она помогла нам навести порядок, разделить зоны ответственности и даже вошла в наш внутренний лексикон — командам стало проще говорить на одном языке. Но по мере того, как продукт развивался, а бизнес-задачи усложнялись, мы стали всё чаще натыкаться на фундаментальные ограничения этого подхода.
1. Жёсткие слои и дублирование данных. Главное правило было простым: любой слой X общается только со своими соседями — X-1 и X+1. Если компоненту на слое X нужны были данные из слоя X+2, их приходилось либо проксировать через X+1, либо кэшировать на уровне X+1. Когда речь идёт о заказах, это террабайты данных. Такой подход порождал не только огромное дублирование, но и постоянную головную боль с обеспечением консистентности в асинхронной системе.
2. Слишком сложные L3-оркестраторы. Идейно оркестраторы на слое L3 должны были отвечать только за уникальную бизнес-логику своих сущностей. Но в реальности они делали много одинаковой работы: создавали задания для первой, средней и последней мили, обрабатывали схожие корнер-кейсы. В итоге каждый такой оркестратор превращался в мини-монолит. Создать новый — например, для обработки аномалий, когда на складе нашли что-то неопознанное — было долго и сложно.
3. Негибкий флоу для сложных схем. Классическая цепочка «первая миля → средняя → последняя» оказалась слишком жёсткой. Представьте, что мы заказываем у крупного поставщика большой объём товара для пополнения дарксторов Лавки в Москве и Питере. Товар приезжает на наш распределительный центр в Москве. Там происходит последняя миля — потоварная приёмка поставки. А затем сразу же первая миля — сборка принятого в новые грузоместа для отправки в Лавки. То же самое произойдет и на распределительном центре в Питере. Чтобы поддерживать такую схему в рамках одной сущности приходилось идти на сложные ухищрения.
4. Размытые границы ответственности. Иногда было совершенно непонятно, на каком слое должен жить тот или иной сервис. Классический пример — сервис маршрутов. Маршрут грузоместа — это вроде бы зона ответственности core-платформы L4. Но что делать, если грузоместа ещё нет, например когда его не собрали на первой миле, а маршрут для будущего заказа уже нужно построить и где-то сохранить? В таких ситуациях лучшее, что мы могли делать — размещать логику там, где это было технически возможно, а не там, где это было правильно архитектурно.
Эволюция, а не революция
Тут важно начать с главного: архитектура 2.0 — это не снос старого здания, а что-то вроде его капитальной перестройки с сохранением несущих стен. Мы не отказываемся от слоёного подхода, но делаем его более гибким и мощным.
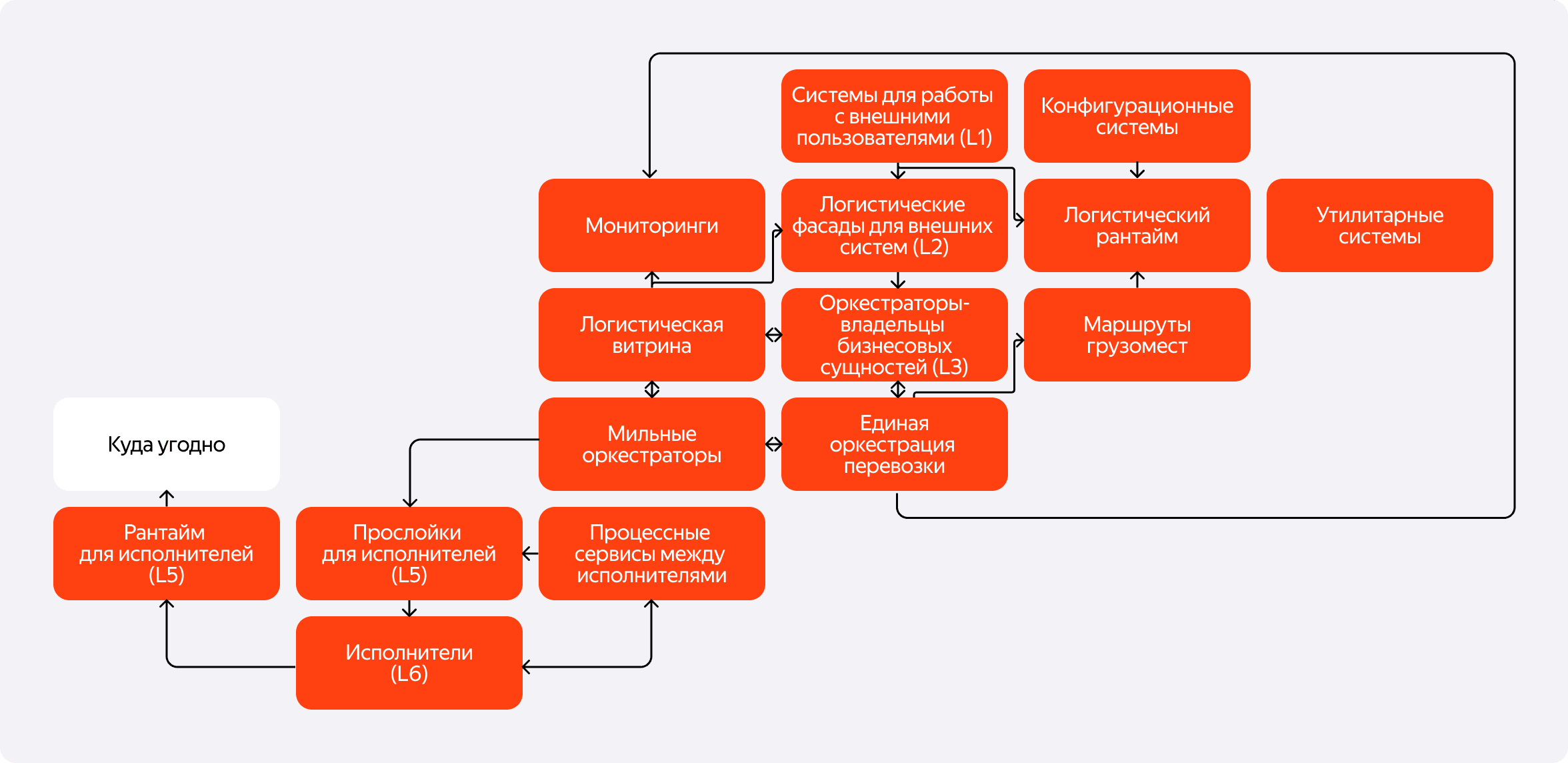
Ключевая идея эволюции в том, что мы не трогаем уровни, которые прекрасно работают и выполняют все свои функции. Слои L0-L2 и L5-L7 остаются практически неизменными. Все обновления сосредоточены в самом сердце системы — на слоях L3 и L4, где и крылись описанные выше проблемы.
Вот ключевые изменения, которые мы внедряем:
1. Единый оркестратор перевозки и «лёгкие» L3
Чтобы уйти от дублирования логики в сложных L3-оркестраторах, мы выделили всю общую механику управления грузоместами в единый оркестратор перевозки. Теперь именно он отвечает за выполнение стандартных циклов «первая-средняя-последняя миля».
Сами же L3-оркестраторы становятся максимально простыми и лёгкими. Их единственная задача — хранить в себе уникальную бизнес-логику своей сущности и говорить единому оркестратору, что нужно сделать, а не как. Например, L3 заказов говорит: «Для этого заказа нужно запустить цикл перевозки». А L3 возвратов: «А для этого возврата тоже нужен цикл, но если что-то пойдёт не так, можешь вернуть его на ближайший склад». Благодаря этому мы теперь можем легко создавать новые L3 под любую нестандартную сущность — хоть под те самые аномалии. Более того, такая связь one-to-many позволяет нам для одной бизнес-сущности запустить несколько последовательных циклов перевозки, элегантно решая кейс с поставкой для Лавки.
2. Мильные оркестраторы
Чтобы сделать флоу перевозки гибким, мы разбили его на составные части. Теперь единый оркестратор даёт задания мильным оркестраторам — отдельным компонентам, отвечающим за свою «милю». У каждой мили свой флоу, свои особенности и свой оркестратор. Это позволяет нам собирать нужный процесс из готовых кубиков, как из конструктора, под конкретную задачу.
3. Логистическая витрина
Для решения проблемы дублирования и консистентности данных мы вводим новую группу сервисов — «Логистическая витрина». Это централизованное хранилище данных, которые нужны разным сервисам платформы, но не являются критичными для их собственных транзакций. Теперь вместо того, чтобы пробрасывать терабайты данных через несколько слоёв, сервисы будут хранить у себя только самое необходимое, а за остальной информацией обращаться к витрине. Это наш единый источник правды о логистических сущностях.
4. Выделенные сервисы маршрутов и мониторингов
Наконец, мы выносим сервисы с размытой ответственностью в отдельные, чётко очерченные группы. Появляются «Маршруты грузомест» и «Мониторинги». Их задача — не принимать решения, а поставлять информацию. Например, сервис мониторинга не будет сам переносить дату доставки. Он лишь сообщит L3-оркестратору заказа: «По моим данным, этот заказ опаздывает». А уже L3, обладая всей полнотой бизнес-контекста, примет решение, что с этой информацией делать. Это вносит ясность и делает систему гораздо более предсказуемой.
Главное — не бояться перемен
Вся эта история, которую я рассказал — от первой версии архитектуры, которая помогла нам справиться с растущей сложностью, до её осознанной эволюции — на самом деле об одном. Хорошая архитектура — не та, что создана раз и навсегда, а та, что способна постоянно меняться и адаптироваться под новые вызовы.
И если решение, которое отлично работало вчера, можно эволюционно довести до более совершенной версии, это значит, что и предыдущий шаг был правильным. Архитектура 1.0 не была ошибкой — она была хорошей, потому что позволила нам дорасти до задач, которые вскрыли её пределы, и дала прочный фундамент для следующего шага.
В завершение хочу поделиться несколькими мыслями, которые кажутся мне важными в этом процессе:
- Не бойтесь менять архитектурную концепцию. Если вы чувствуете, что новые задачи плохо ложатся в старую парадигму, важно не упорствовать, а начать анализировать, чего именно не хватает в текущей версии.
- Прорабатывая архитектуру, как можно больше общайтесь с продуктом. Это помогает понять, какие вызовы ждут вас в среднесрочной перспективе, и заложить решения, которые не придётся переделывать через полгода.
Надеюсь, наш опыт был вам интересен и полезен.



