
Представьте: вы захотели купить себе айфон. Заходите на любимый маркетплейс, долго выбираете, читаете отзывы, добавляете в корзину. Затем переходите в чекаут, уже готовы оплатить и… не можете выбрать адрес доставки. Поле просто не заполняется. После нескольких безуспешных попыток перезагрузить страницу вы, расстроившись, покидаете сайт и идёте смотреть предложения у конкурентов.
А что, если я скажу, что это не гипотетическая ситуация? Такой кратковременный инцидент действительно произошёл в Маркете в 2025 году — у части пользователей сломалась возможность выбора адреса. Мы быстро заметили проблему с помощью алерта, сработавшего в нашей системе Real-Time мониторинга.
Этот случай — отличная иллюстрация того, почему мы в Маркете движемся к тотальной RT-фикации. Наша цель — не просто фиксировать инциденты, а дебажить их максимально оперативно. А в идеале — вообще предсказывать и избегать. Меня зовут Максим Левшин, я аналитик-разработчик в Яндекс Маркете, и в этой статье я расскажу, как устроен наш мониторинг, который позволяет находить и чинить баги за считаные минуты.
Почему Маркету тесно в рамках обычных метрик
Маркет — это огромный и сложный продукт. И я говорю не просто о количестве товаров на витрине. За ним стоят десятки команд, сотни страниц, виджетов и блоков, множество источников трафика, сложные логистические схемы и куча способов доставки. В такой системе смотреть только на общие, интегральные метрики — всё равно что измерять среднюю температуру по больнице. Например, представим ситуацию: число заказов экспресс-доставки резко упало, а стандартный алерт не сработал. В таком случае мы ожидаемо будем терять деньги и лояльность пользователей, даже не подозревая о проблеме.
Раньше поиск причин инцидентов нередко превращался в долгие, почти детективные расследования, и стало очевидно, что нам нужен дашборд, который сможет ответить на вопрос «что именно сломалось?» в любом из нужных разрезов — по платформам, типам и схемам доставки, источникам трафика. Система, которая позволит оперативно отреагировать на непредвиденный сбой, где бы он ни произошёл.
Давайте я расскажу, как мы её построили.
Как устроен наш RT-мониторинг
Наш дашборд построен по простому принципу: сверху — самые важные элементы, которые нужно мониторить всегда, а дальше по мере скролла вниз критичность снижается. Вся система держится на нескольких ключевых компонентах.
О принципах проектирования систем мониторинга читайте в статье «Дашборды здорового человека: опыт Техплатформы Городских сервисов»
Компонент 1. Алерты — наша первая линия обороны
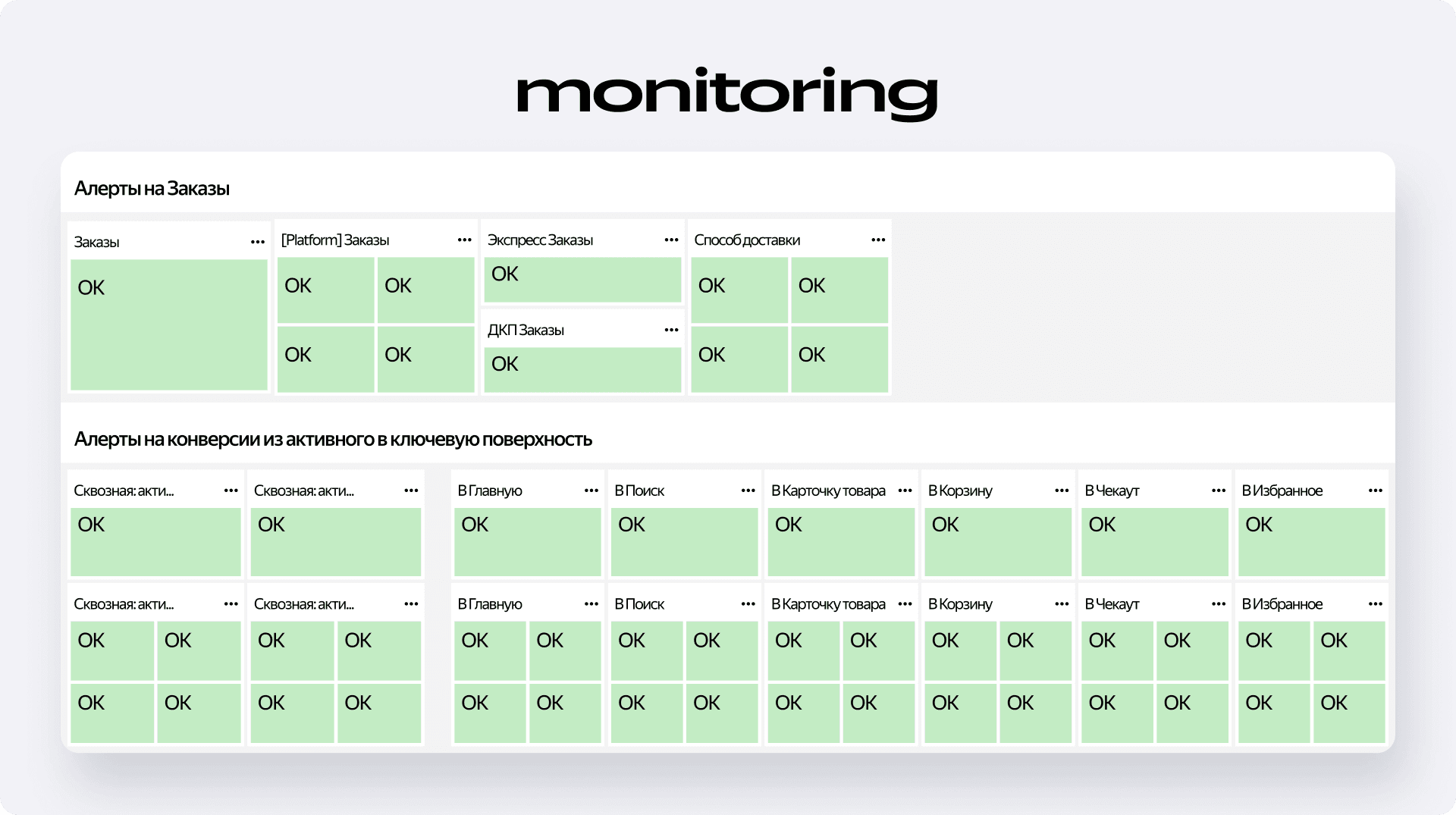
В самом верху страницы — алерты. Это главный элемент всего мониторинга, ведь именно по их состоянию мы отслеживаем здоровье Маркета. Мы настроили их на самые критичные метрики:
- Заказы — суммарные, но с разбивкой по платформам, способам, типам и схемам доставки.
- Конверсии — из активного пользователя в открытие ключевых страниц и из открытия страницы в целевое действие на ней.
Как это работает?
Давайте разберёмся, как система понимает, что-то пошло не так. Процесс, который мы называем seasonal adjusted, выглядит так:
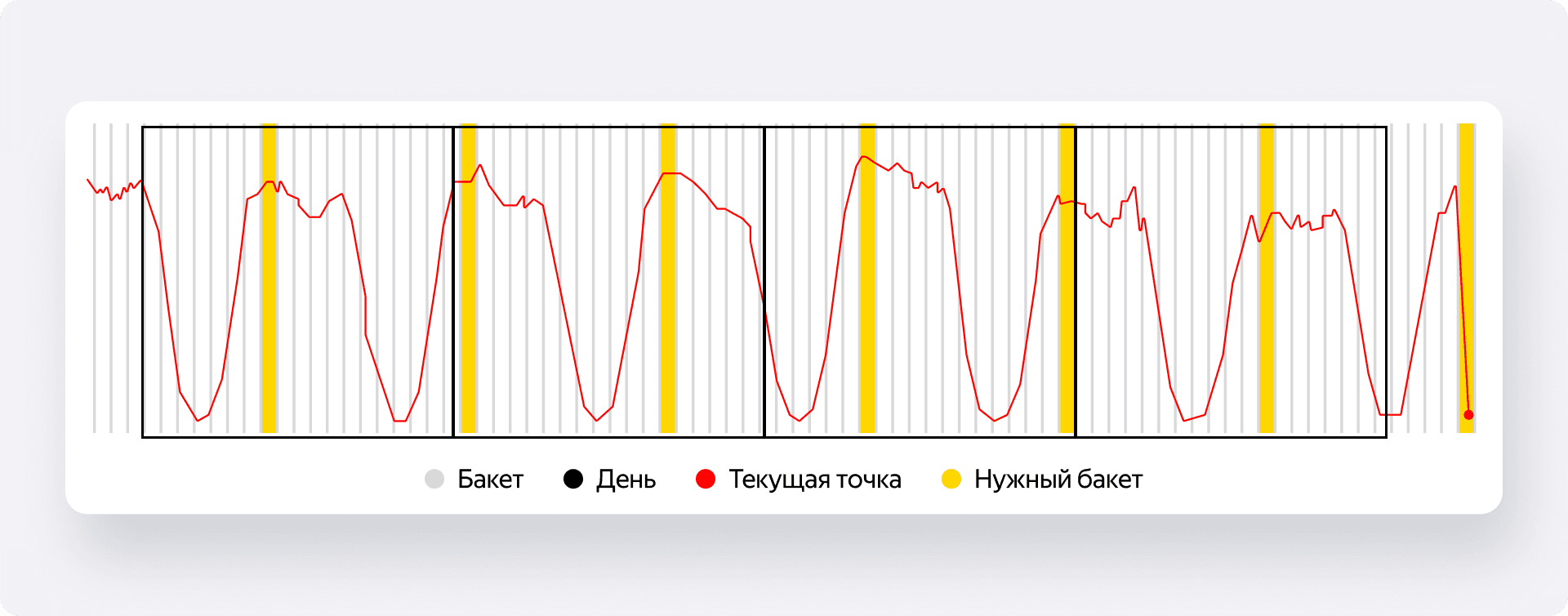
- Делим дни на «бакеты». Каждый день за предыдущий месяц делится на определённое количество временных отрезков. Когда приходит новая точка — скажем, за 12:10, — система берёт для анализа аналогичные бакеты за прошлые периоды.
- Считаем скользящее среднее (moving_avg). Внутри этих исторических бакетов мы находим скользящее среднее с разными окнами (например, за 5, 10, 15 минут).
- Строим эталонное распределение. На основе этих исторических скользящих средних мы строим нормированное распределение. Это наша модель нормального поведения метрики в это время суток.
- Сравниваем. Теперь мы берём скользящее среднее для текущей точки (наших условных 12:10), нормируем его по тем же параметрам, что и исторические данные, и смотрим, на сколько стандартных отклонений оно отличается от эталона. Если отклонение превышает заданный порог — срабатывает алерт.
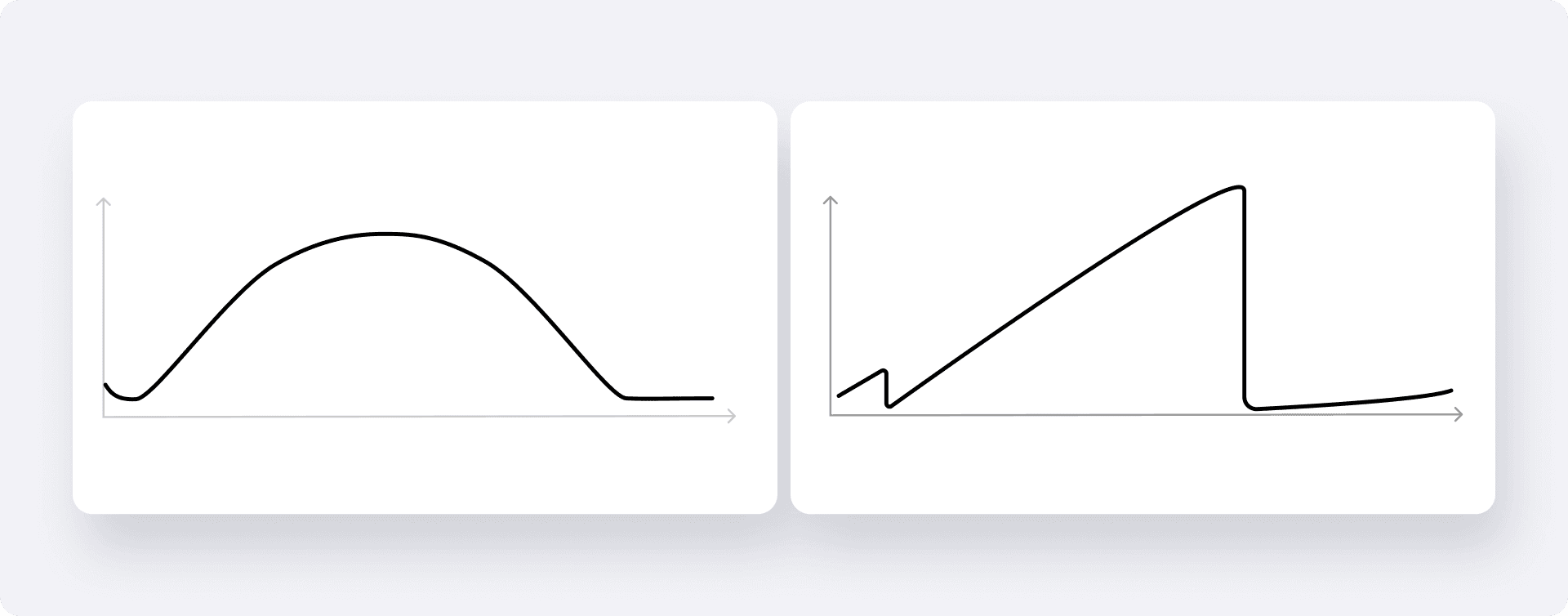
Зачем нужны разные окна? Представьте, что произошло резкое падение показателей. Скользящее среднее за 5 минут моментально улетит вниз, и алерт сработает почти сразу. Но что, если падение не резкое, а медленное и постепенное? Здесь как раз и помогает более широкое окно — например, в 15 минут. Дело в том, что чем шире окно, тем ниже дисперсия скользящего среднего. Такой 15-минутный тренд получается более гладким и стабильным по сравнению с короткопериодным.
Поэтому небольшое, но планомерное снижение заказов — которое узкое окно списало бы на допустимые колебания в рамках своей дисперсии — для широкого окна уже будет значимым отклонением от нормы. Это и позволяет нам отлавливать медленные деградации. В момент прихода точки система вычисляет алерты по всем заданным окнам, но срабатывает только тот, где отклонение оказалось наибольшим.
Компонент 2: Накопительные суммы — как прошёл день?
Ловить аномалии — это полдела. Нам важно понимать, как мы идём в течение дня относительно других дней. Для этого мы используем кумулятивную сумму и кумулятивный дифф — накопленную разницу в абсолютных и относительных значениях.
Здесь тоже есть своя техническая особенность. В языке запросов Monium, который мы используем, нельзя просто просуммировать значения предыдущих точек. Зато можно использовать интегрирование, что, по сути, и является суммой от первой точки до текущей. Мы пользуемся этим, чтобы получать накопленную сумму. Раз в день мы обнуляем результат, чтобы каждый новый день начинать с чистого листа. Такие суммы у нас настроены на заказы, DAU, добавления в корзину, а также на ключевые страницы — главную, карточку товара, корзину и чекаут.
Ещё на эту тему читайте в статье «Реалтайм-аналитика: почему нельзя просто взять и посчитать деньги в микросервисах»
Компонент 3: Воронки и источники трафика — где именно болит?
Это подводит нас к последнему ключевому компоненту. Мы разложили срезы по платформам и источникам трафика на всю пользовательскую воронку. Это помогает оперативно понять, где и какой блок отвалился.
Вот реальный пример: срабатывает алерт на падение добавлений в корзину на карточке товара. При этом мы смотрим на график и видим, что общее количество кликов не изменилось. Что произошло? Открываем срез по источникам трафика и видим, что мы по какой-то причине стали увеличивать по определённым часам трафик с пушей. Допустим, в 12:00 мы шлём много пушей, и пользователи начинают массово заходить на маркетплейс. Если эти пуши ушли внепланово, они размывают конверсию, что и вызывает алерт. Источник трафика в данном случае — идеальный инструмент для дебага таких кейсов.
Тот самый инцидент
Теперь, когда мы разобрали теорию, давайте вернёмся к истории, с которой начали, и посмотрим, как наш мониторинг отработал в боевых условиях. В тот день мы в целом шли хорошо по заказам, но днём случился настоящий шторм.
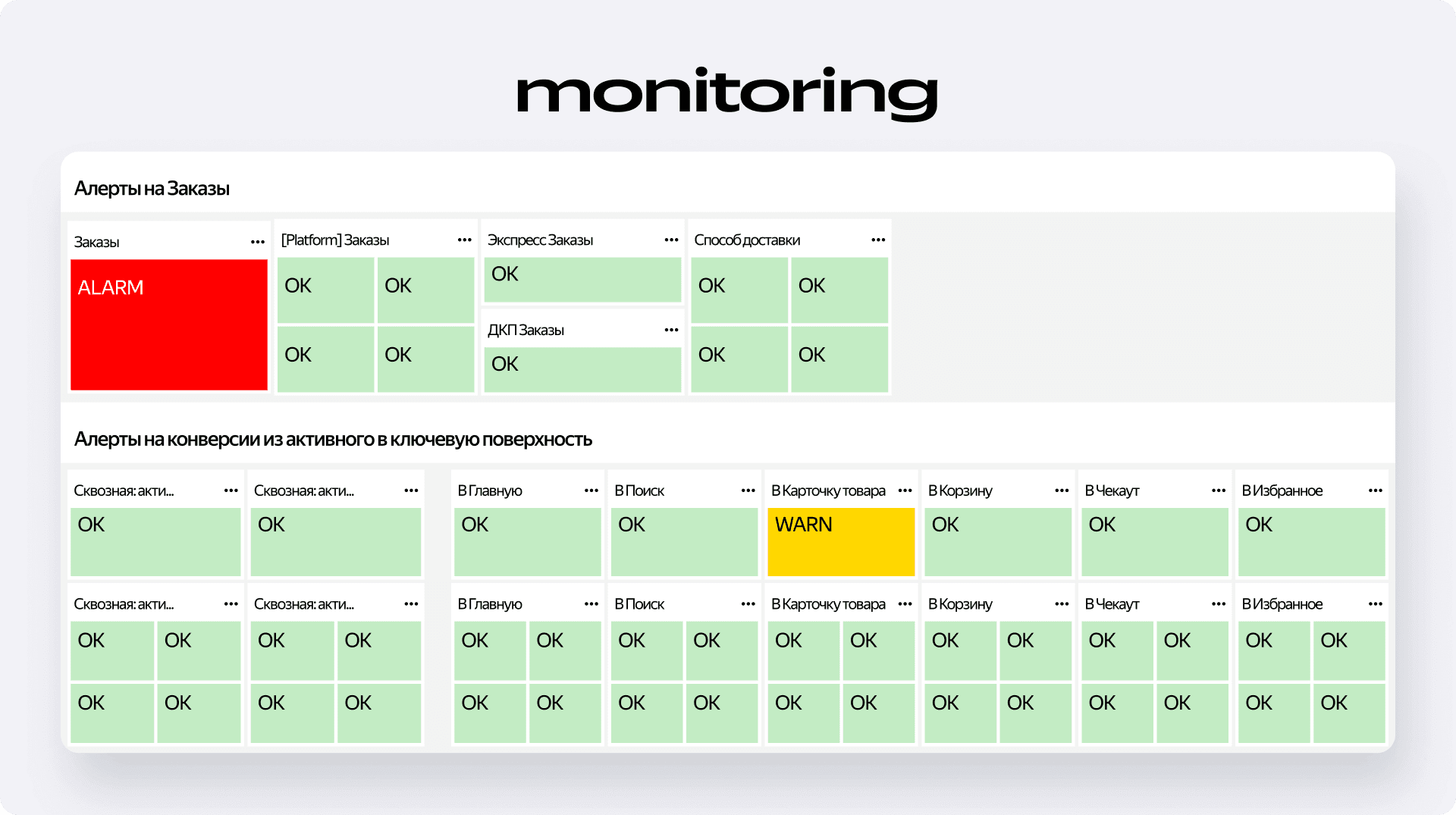
Что мы увидели в первую минуту?
Система зафиксировала резкое падение сквозной конверсии в страницу подтверждения заказа, которая открывается после успешной оплаты. Одновременно с этим сработали все алерты на заказы и на чекауте. На дашборде зажглись красные плашки ALARM с отклонением — сигнал, который невозможно проигнорировать.
Но данные воронки чекаута показали не только само падение, но и прямую реакцию пользователей на него — количество заходов на страницу чекаута начало расти. Что это значит? Это значит, что пользователи, столкнувшись с проблемой, не уходили сразу, а пытались перезаходить на страницу снова и снова, надеясь, что она заработает. Наш мониторинг зафиксировал и это аномальное поведение, что позволило быстрее локализовать проблему.
Как мы оценили масштаб бедствия?
Чтобы понять, как этот инцидент повлиял на день в целом, мы обратились к графикам накопительных сумм. На них было отчётливо видно, как кривая нашего дня после определённого времени резко ушла в ещё более глубокое пике. Это наглядная демонстрация того, как локальный, но значительный сбой может повлиять на заказы.
С другой стороны, этот кейс показал, что система работает именно так, как мы и задумывали: она не просто сигнализирует о проблеме, а даёт богатый контекст для её быстрой диагностики. Мы видим не только что сломалось, но и где, как именно, и даже можем оценить, как это повлияло на поведение пользователей.
Что дальше
Надеюсь, на этом реальном примере вам стало чуть более понятно, как работает наш мониторинг и какую ключевую задачу он решает. Его цель — не просто строить красивые графики, а превращать всю сложность огромного продукта в управляемую систему сигналов. Конечно, на этом работа не закончилась. Следующим большим этапом стало отделение технических проблем от влияния маркетинговых активностей.
В завершение хочу сказать огромное спасибо всем, кто сделал этот проект возможным. Внутренним командам за предоставление сигналов. А также Олегу Титову, Семёну Левенсону и Джорджио Ди Сарра за разработку сигнала, Никите Белоусову за помощь в создании алертов и Ване Цубилину за помощь в построении подневных накопительных сумм.



