
Рекомендательные системы (RecSys) — это область машинного обучения, в которой на результат часто больше влияет оптимальность кода, обслуживающего ML-модели, чем тщательно подобранные гиперпараметры.
Меня зовут Марк Нарусов, я занимаюсь машинным обучением в Яндекс Лавке. Наша команда в том числе отвечает за рекомендации: от предложений к корзине до карточек товаров и главной страницы. В этой статье я расскажу, как именно устроены рекомендации в Лавке, почему мы решили убрать кандидатогенерацию, с какими техническими проблемами столкнулись, как мы их решали и чего достигли.
И хотя на первый взгляд может показаться, что это чисто ML-задачи, на деле в нашей работе всё тесно связано с бэкендом. Команда отвечает не только за рекомендательную логику, но и за весь микросервис, отдающий рекомендации по REST API. Этот сервис мы разрабатываем в том же контуре и на том же фреймворке — userver, что и наши коллеги-бэкендеры из Лавки.
Недавно в команде мы пошли на довольно нестандартный шаг: отказались от стадии кандидатогенерации в рекомендациях. Обычно считается, что без этой стадии невозможно выдерживать рантайм-нагрузку: слишком большой объём данных, слишком высокая стоимость инференса. Но у нас получилось — и результат оказался даже лучше, чем мы ожидали.
Как устроены рекомендации в Лавке
Когда мы говорим про рекомендации в Лавке, важно понимать, что это не одна система, а сразу несколько поверхностей: корзина, карточки товаров, фид с медиа на главной странице. У них много общего, но кое-какие отличия всё-таки присутствуют. Где-то мы рекомендуем то, что человек уже заказывал. Где-то — наоборот, стараемся показать что-то новое, чтобы пользователь мог открыть для себя интересный товар. Мы называем это «дискаверийностью». В карточке товара мы решаем задачу item2item — подбираем товары, похожие на выбранный. Даже ранжируем товары в разделе «Вы покупали».
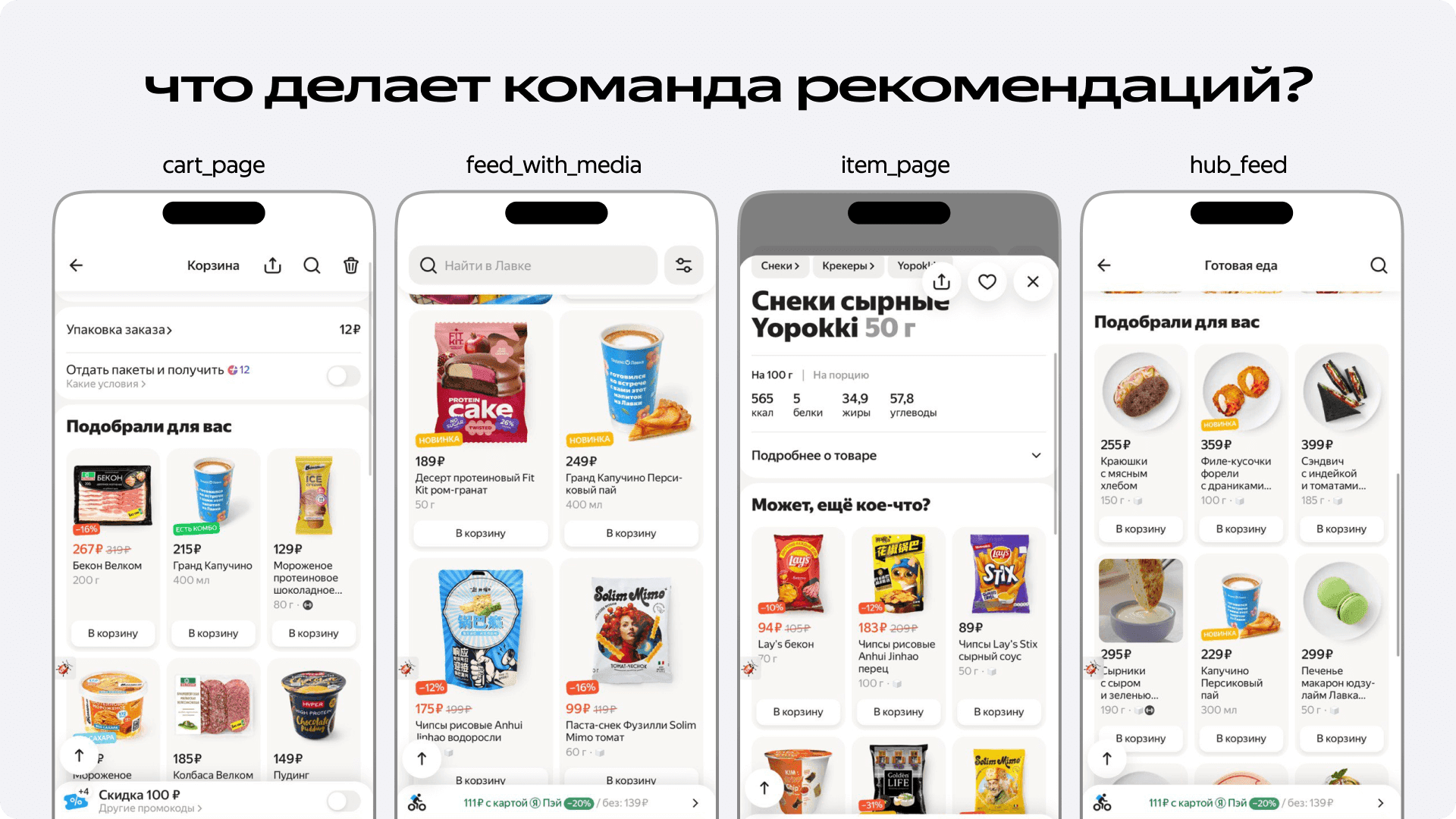
Всё это работает благодаря нашей ML-инфраструктуре, которая строится вокруг DJ — рекомендательного фреймворка, разработанного внутри Яндекса. На нём работают рекомендации Маркета, Еды, Авто.ру, Алисы, Карт и других сервисов.
Логика рекомендаций на каждой поверхности у нас представляет из себя некоторую DJ «программу». Программа — это набор компонент, исполняющихся на C++. DJ-компонента, в свою очередь — оформленное в класс действие. Например, применение Сatboost’а, расчёт фичей на основании эмбеддингов.
Для удобного переиспользования разными сервисами у каждой DJ-компоненты есть конфиг, представляющий из себя «сообщение» (message) протокола сериализации protobuf. Для упрощения, можно думать про поля этого message’а как именованные аргументы функции. Чтобы использовать компоненту, достаточно вставить в конфиг программы её вызов с выбранными параметрами. Так как программы и компоненты конфигурируются через текстовый формат протобуфа, такие конфиги сильно разрастаются в размерах. Например, в используемом нами в продакшене конфиге со всеми программами больше миллиона строк, и весит он 50+ мегабайт. Естественно, составляем мы его не вручную.
Для компиляции pbtxt конфигов мы используем привычный ML-специалистам язык — Python. Для удобства мы организуем дополнительные абстракции уже в питонячей обёртке.
В результате получается, что описываем рекомендательную логику мы на Python, а отрабатывает она на С++. А это значит, что настраивать и переиспользовать такой конфиг можно даже без знания плюсового кода. И когда к нам приходит новый ML-разработчик, он быстро включается в работу, даже если плохо знает C++. Так было и у меня: я начинал с Python, и только на стажировке стал подтягивать C++.
Как обычно работают рекомендательные системы: стадия кандидатогенерации
В любой промышленной рекомендательной системе, особенно когда речь идёт о миллионах или миллиардах объектов, есть одна общепринятая схема: сначала происходит кандидатогенерация — отбор ограниченного набора товаров, с которыми дальше будет работать модель. Без этого этапа система просто не справится с объёмом.
Во всей Лавке больше десятка тысяч уникальных SKU по всем складам. Но в конкретный момент времени, на одном дарксторе, это число ближе к 3000–5000. При этом на выходе от нас требуется всего 20 релевантных товаров — именно столько нужно отдать бэкенду в одном ответе.
Если бы мы пытались скорить абсолютно все позиции, что есть в Лавке, пользователь ждал бы выдачу 2–3 секунды, и это в лучшем случае. С такой задержкой нельзя составить удобную «бесконечную» ленту из рекомендаций. Но даже если брать только товары в наличии, прогнать по ним полноценную модель — это всё ещё дорого.
Поэтому в начале рекомендации в Лавке проектировали по классической многостадийной схеме:
- Кандидатогенерация: из всего множества товаров в ассортименте выбираем до тысячи айтемов.
- Извлечение фичей: описываем каждый товар числовыми признаками.
- Скоринг: модель ранжирует кандидатов по убыванию релевантности опираясь на извлечённые признаки.
- Постобработка: добавляем бизнес-логику, рекламу, диверсификацию выдачи и т. д.
Кандидатогенерация — это способ быстро и дёшево сузить пространство поиска. Чаще всего она работает на эвристиках или лёгких формулах. В нашем случае это:
- Айтемы из пользовательской истории.
- Топы по покупкам.
- Айтемы, популярные в нужной пользовательской группе.
- Товары, часто покупаемые с продуктами из пользовательской истории.
- iALS.
- HNSW индекс по айтемным эмбедам из трансформера с поздним связыванием.
- Другие статичные и коллаборативные кандидатогенераторы.
Но здесь есть одна важная особенность: как бы ни были хороши кандидатогенераторы, само наличие этого шага на практике означает, что мы не даём ранжирующей модели увидеть всё. Мы как бы заранее за неё решаем, что имеет смысл рассматривать, а что — нет.

Кандидатогенерация — это необходимость, а не фича. Она даёт выигрыш по скорости, но накладывает ограничения на качество рекомендаций, особенно, конечно, на полноту (recall). Чем меньше остаётся кандидатов после кандидатогенерации, тем меньше пользователь увидит товаров, которые ему могут потенциально понравиться.
Понимая этот факт, мы предпринимали немало усилий чтобы сделать сужение пула кандидатов от кандидатогенерации менее болезненным для итогового качества выдачи.
Например, мы обучали отдельную модель для ранжирования кандидатогенераторов в рамках применения так называемого «Миксиджена» (DJ-компонента MixingCandidateGenerator). Можно представить множество потенциальных айтемов как набор упорядоченных списков — кандидатогенераторов. Сначала Миксиджен инициализирует по одному указателю для каждого кандидатогенератора, причем каждый указатель изначально ссылается на первый (нулевой) элемент в соответствующем списке.
С параметрами batch_size и max_size компонента проделывает ceil(max_size / batch_size) шагов:
- Ранжирует кандидатогенераторы по убыванию их релевантности.
- Берёт лучший, достаёт из него batch_size кандидатов.
- Инкрементирует указатель на этот кандидатогенератор на batch_size.
Для ранжирования кандидатогенераторов по релевантности на каждом шаге работы Mixigen’а используется градиентный бустинг, специально обученный на подмножестве фичей которые не учитывают айтемы (ведь скорим мы не их) и ohe-кодированную фичу-индикатор кандидатогенератора (is_history, is_ials, etc.). При применении соответствующая фича-индикатор заполняется единицей и подаётся модели вместе с другими.
В Яндексе принято обучать такой градиентный бустинг на попадание в топ выдачи, но у нас хорошо работало и учить его напрямую на целевое действие — добавление в корзину.
Хоть с точки зрения ML’я кандидатогенерация была устроена хорошо, в техническом её аспекте были проблемы.
В каждом отдельном кандидатогенераторе мы сначала набирали кандидатов, а только потом фильтровали их по наличию, пагинации и другим бизнес-требованиям. В худшей ситуации это означало, что в отобранном списке могло не оказаться ни одного доступного товара. Так, топ-200 товаров по покупкам мог давать ценных кандидатов пользователям в Москве или Санкт-Петербурге, но по итогу полностью отфильтровываться из выдачи по неналичию в Екатеринбурге или Иркутске. Если бы мы не использовали пост-фильтрацию, а смотрели на фильтры при наборе кандидатов из базы данных, то сразу бы гарантированно набирали 200 доступных.
Также эффективность самой фильтрации оставляла желать лучшего — без углубления в подробности, в узких по производительности местах по неосторожности использовались неоптимальные структуры данных.
В какой-то момент мы заметили, что количество товаров, которые мы скорим ранжирующим градиентным бустингом, меньше количества всех товаров в наличии в дарксторе в один момент времени не на порядок, а всего в несколько раз. Тогда мы подумали, что мы можем достаточно оптимизировать код, чтобы оценивать сразу все товары, проходящие фильтрацию.
Как мы решились отказаться от кандидатогенерации — и что пришлось оптимизировать
Первое, что пришлось пересобрать — это логика фильтрации. Раньше мы сначала отбирали кандидатов, а потом проверяли, есть ли они в наличии. Чтобы не тратить ресурсы на загрузку ненужных айтемов в память и не проходить дважды по длинному списку, мы решили отказаться от постфильтрации.
Теперь мы проходились по всем товарам в базе данных, проверяли каждый из них на прохождение фильтров, и только потом клали в итоговый вектор кандидатов. Такой проход занимает 50 мс в 95 перцентиле, что приемлемо при дедлайне ответа всего микросервиса в 300 мс.
Но далее оказалось, что набор кандидатов — не самое тяжёлое место. Основная нагрузка легла на следующую стадию — извлечение фичей. Там мы столкнулись с неожиданным: даже без обращения к внешним сервисам мы выбивались за лимит в 300 мс. Причём выбивались значительно: при первой выкатке — естественно, только на команду — больше 500 мс могло уйти только на то, чтобы описать айтемы нужными признаками.
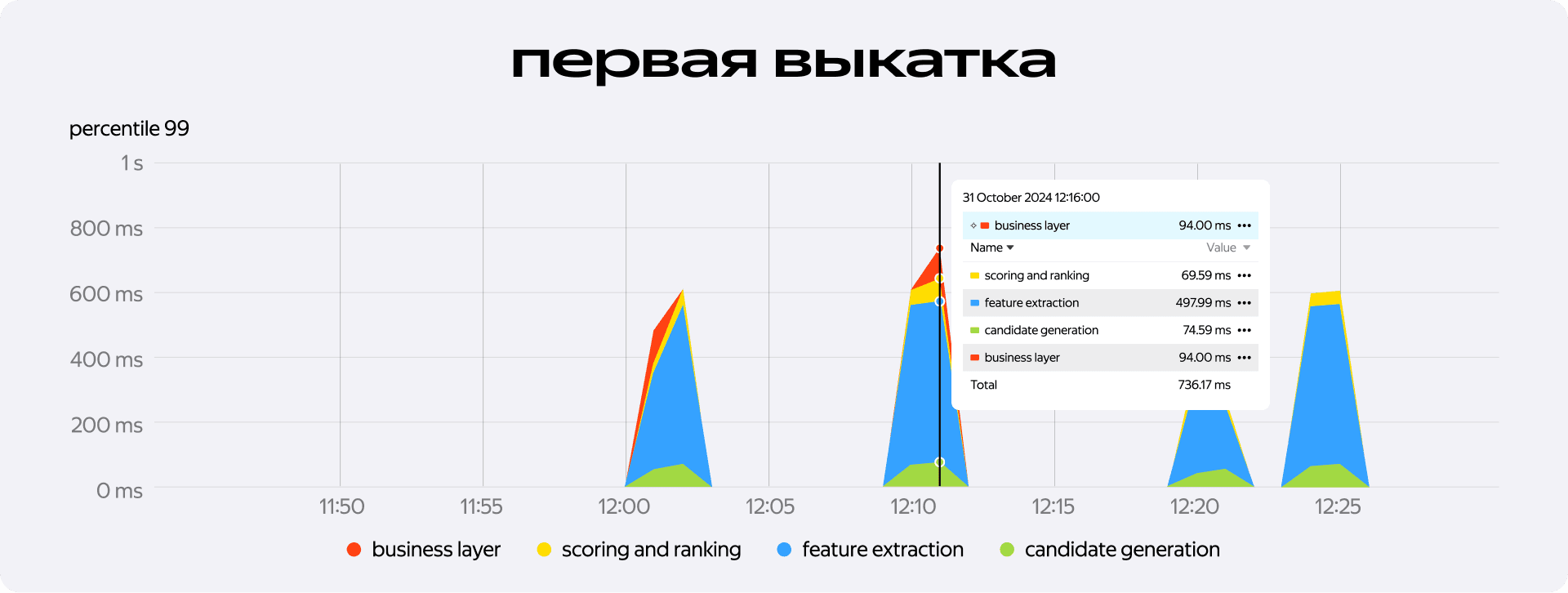
Чтобы вернуть систему в рабочие временные рамки, мы начали профилировать всё, что происходит в процессе экстракции фичей.
В процессе профилирования мы сделали таблицу, где напротив каждой фичи выписали её ранг в важности фичей градиентного бустинга, а также время, занимаемое на её расчёт. К счастью, большинство важных фичей оказались незатратны в извлечении. Например, предпосчитанные в оффлайне счётчики по пользовательской истории (сколько раз я купил молоко «Домик в Деревне» за последнюю неделю), а также косинусные расстояния user x item (насколько мой вектор сонаправлен с вектором молока «Домик в Деревне» в коллаборативно выученном семантическом пространстве).
Но также мы нашли и ресурсоёмкие операции. Например, чтобы посчитать фичу про сопокупаемость товара-кандидата с товарами из истории пользователя, мы многое делали в рантайме.
Некоторые вводные для понимания расчёта этой фичи:
- Для хранения информации о товарах мы используем in-memory бинарную базу дынных, единица которой — профиль.
- В профилях товаров можно хранить ссылки на другие товары, присваивая каждой ссылке определенное числовое значение (Value) — произвольное вещественное число.
- Такую конструкцию можно представить как взвешенный граф, где вершинами являются товары, а рёбрами — связи между ними с весами, отражающими степень сопокупаемости товаров.
- Для степени сопокупаемости мы не ограничивали количество ссылок, исходящих от одного профиля.
- Сами ссылки хранятся в упорядоченном по значению виде, что помогает при наборе кандидатов, но не при поиске по ID вершины, на которую ссылаемся.
Теперь сам алгоритм:
- На каждый товар-кандидат:
- На каждый товар из истории пользователя:
- Найди профиль кандидата в базе данных.
- В профиле кандидата найди взвешенную ссылку на данный товар из истории.
- Если находишь, запиши Value этой ссылки для дальнейшей агрегации.
- Сагрегируй получившийся список значения в статистики (максимум, минимум, среднее, и т. д.).
- На каждый товар из истории пользователя:
Несложно заметить, что без дополнительных оптимизаций такой алгоритм занимает O(n^2) или O(n * m), где n — количество товаров-кандидатов, а m — количество товаров в истории пользователя.
Насчитывание именно таких статистик и было, помимо других, на критическом пути нашей стадии расчёта факторов.
Агрегированные скоры сопокупаемости на выходе были далеко не на самых последних местах по важности факторов, но в итоге мы от них отказались в пользу производительности. Сам алгоритм можно было бы оптимизировать (например, кэшировать результаты поиска по графу в рамках запроса — незачем сначала искать сопокупаемость пельменей из пользовательской истории к сметане в кандидатах, а потом искать сопокупаемость сметаны из истории с пельменями в кандидатах), но мы решили потратить разработческие ресурсы на выкатку рекомендаций без кандидатогенерации.
Мы убрали из обучения фичи с расчётом на критическом пути — около сотни, четверть от общего числа. Затем замерили качество офлайн. Когда убедились, что соотношение скорости и качества нас устраивает, запустили эксперимент на пользователях.
Результаты тестов и рост Discovery
После того как мы отказались от кандидатогенерации, переработали фильтрацию, почистили фичи — мы запустили A/B тест. Нужно было понять: действительно ли все наши усилия были не напрасны.
Результаты порадовали — статистически значимые приросты мы увидели и на общей выручке Лавки, и на метриках Discovery.
Раньше нам удавалось растить и выручку, и Discovery, но по отдельности. Сложно показывать пользователю и больше нового для него, и в то же время растить конверсию — всё-таки ML в e-grocery — это про повторные покупки с сильно играющей роль «историчностью» товаров. Но вкупе с другими изменениями, отказ от кандидатогенерации позволил улучшить рекомендации сразу во многих аспектах.
Когда систему ограничивают эвристики, она часто показывает одно и то же: то, что вы уже брали, или то, что и так покупают все. В то время как новинки, редкие позиции, свежие категории просто не успевают пробиться в выдачу. Сейчас же, когда модель стала видеть весь ассортимент сразу, если товар подходил — она его показывала, в то время как раньше он бы не продвигался по воронке дальше кандидатогенерации.
Что будет дальше?
Итак, мы убрали кандидатогенерацию — и не развалились. А даже наоборот — стек стал проще, чище и лучше. Мы больше не тратим ресурсы на поддержку кандидатогенераторов, их сортировку, и модель, которая их ранжирует. Рекомендации теперь не зависят от набора эвристик или костыльных кандидатогенераторов. Модель работает напрямую с полным списком товаров на складе.
Теперь фокус — на фичах. На том, как лучше описать товар и пользователя, чтобы модель делала свою работу точнее. Но об этом уже в следующий раз.
Особое спасибо Дане Ткаченко за идею проекта и Джавиду Фаталиеву и Ефиму Соколову за его реализацию.



