
В Яндексе мы уделяем огромное внимание стабильности сервисов. За годы работы мне довелось плотно заниматься вопросами надёжности как в Еде, так и в Лавке. И чтобы не закостенеть в рутине, я считаю, что полезно иногда бросать себе вызов и задавать неудобный вопрос: «А не ерундой ли я занимаюсь?».
Давайте на минуту перевернём всё с ног на голову и доведём ситуацию до абсурда. Мой провокационный тезис для начала разговора — надёжностью заниматься не нужно.
Взглянем на математику. В индустрии считается, что аптайм три девятки — 99,9% — это норма. Если у вас в компании выстроены базовые процессы и есть грамотные инженеры, такой уровень можно поддерживать почти на автомате. Но чтобы прыгнуть выше и добиться четырёх девяток — 99,99%, нужно уже упороться.
Четыре девятки означают, что вам нельзя лежать больше минуты в неделю. Тут уже хочешь не хочешь, но придётся нанимать отдельных SRE, внедрять сложные практики инцидент-менеджмента, проводить учения и бесконечно капать на мозги командам за пятисотки.
Узнать больше о процессах SRE можно в статье «Инженерия надёжности в Маркете: принципы, процессы и реальные кейсы»
И всё это ради того, чтобы терять не 0,1% заказов, а 0,01%.
Проведём мысленный эксперимент. Представьте, что команда принесла новую фичу. Она упрощает поддержку, экономит операционные расходы, сокращает Time-to-Market — ну просто мечта для любого бизнеса. У неё есть только один минус: она роняет заказы на 0,1%. Назовём эту фичу «Ненадёжность». Примут ли её продакты и аналитики? Скорее всего, да. Профит очевиден, а падение в рамках статистической погрешности.
Казалось бы — Viva la revolution! Можно распускать отдел надёжности и спокойно пилить продукт. Но если бы всё было так просто, я бы не писал этот текст.
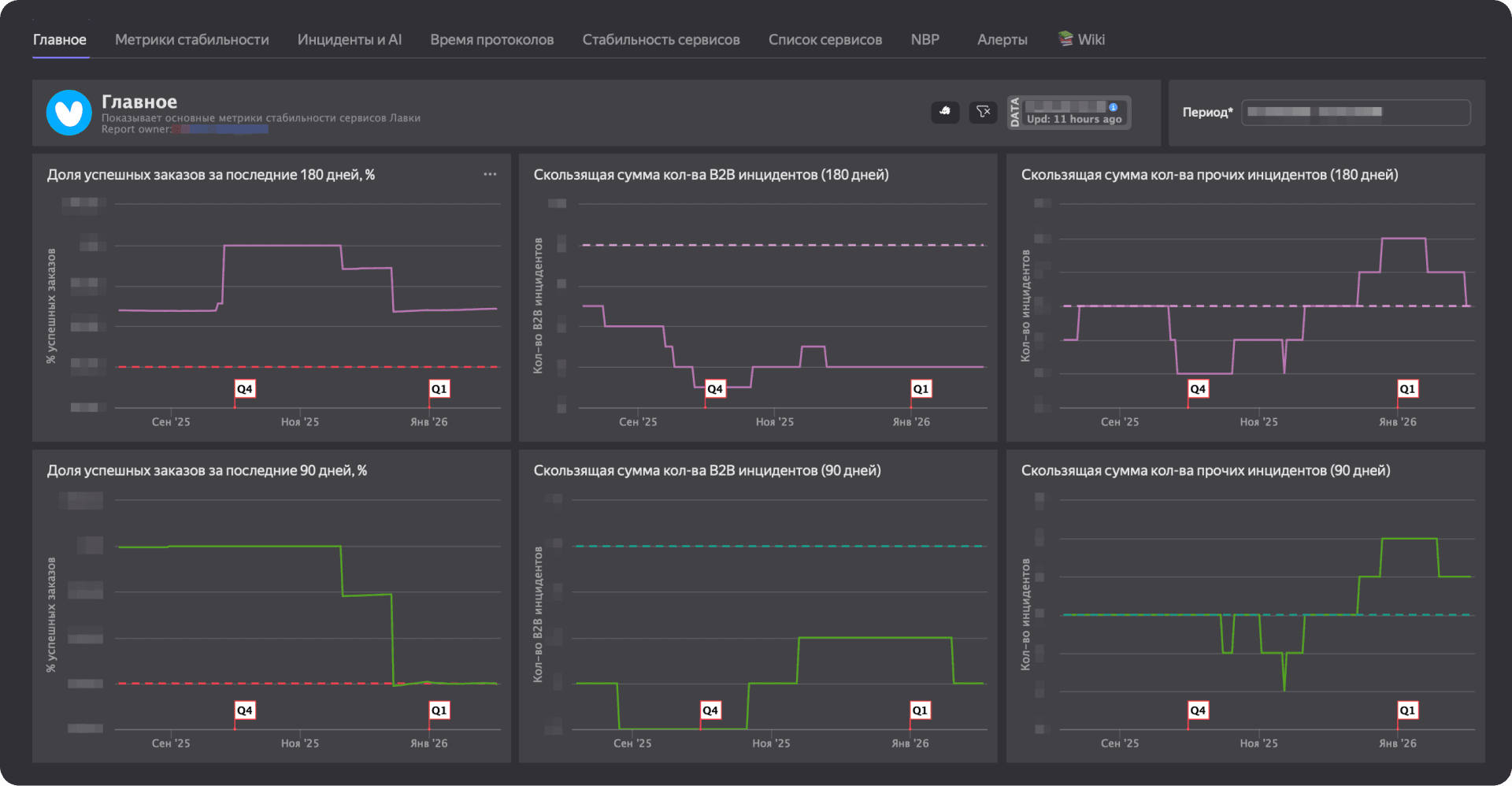
В реальности надёжность — это не только цифры на дашборде, но ещё и реальные деньги и, что гораздо важнее, репутация. Недавно я составил внутренний манифест — стратегию надёжности, где зафиксировал майндсет и конкретный план действий. В этой статье я поделюсь частью этого документа: разберём, как превратить здравый смысл в системный процесс, почему три девятки — это всё-таки мало и как предотвращать пожары, вместо того чтобы постоянно их тушить.
Почему надёжностью всё-таки нужно заниматься
Уверен, вы и так уже прекрасно поняли, что мой тезис о ненужности надёжности — это провокация. Финансовые выкладки говорят об обратном. И дело тут не только в цифрах аптайма. Критически важно различать два состояния системы во время сбоя: когда сервис просто лежит и вы недозарабатываете, и когда вы приняли заказ, но не смогли его выполнить.
Второй сценарий гораздо страшнее. Потому что это не просто упущенная выгода — это нарушение обязательств перед пользователем, который уже заплатил деньги и ждёт свой заказ. Здесь мы получаем двойной удар: и прямые финансовые потери, и долгосрочный репутационный ущерб. И вот уже в таком контексте разница между тремя и четырьмя девятками становится вполне себе внушительной.
Именно поэтому я решил зафиксировать стратегию надёжности документально. Казалось бы, зачем записывать прописные истины? Ведь в том плане, которым я хочу поделиться, нет ничего революционного — это просто здравый смысл, упакованный в список задач. Но парадокс в том, что в погоне за сложными инженерными решениями мы часто упускаем именно такие, самые очевидные вещи.
Как не сломать всё, причиняя добро
Даже если убрать руки с клавиатуры и вообще никак не трогать сложную распределённую систему, то она всё равно довольно быстро начнёт деградировать — энтропия возьмёт своё. Но мы не можем её не трогать: мы постоянно хотим нанести пользу, а потому катим релизы практически нон-стоп, по 50 в неделю.
И каждый деплой всегда сопряжён с рисками. Можно ошибиться в коде, подтянуть бажную зависимость, неверно рассчитать нагрузку или забыть проковырять сетевую дырку. Причин упасть всегда больше, чем глаз, следящих за выкладкой. Поэтому надеяться на авось нельзя, нужно системно повышать предсказуемость релизов. Вот что мы для этого делаем.
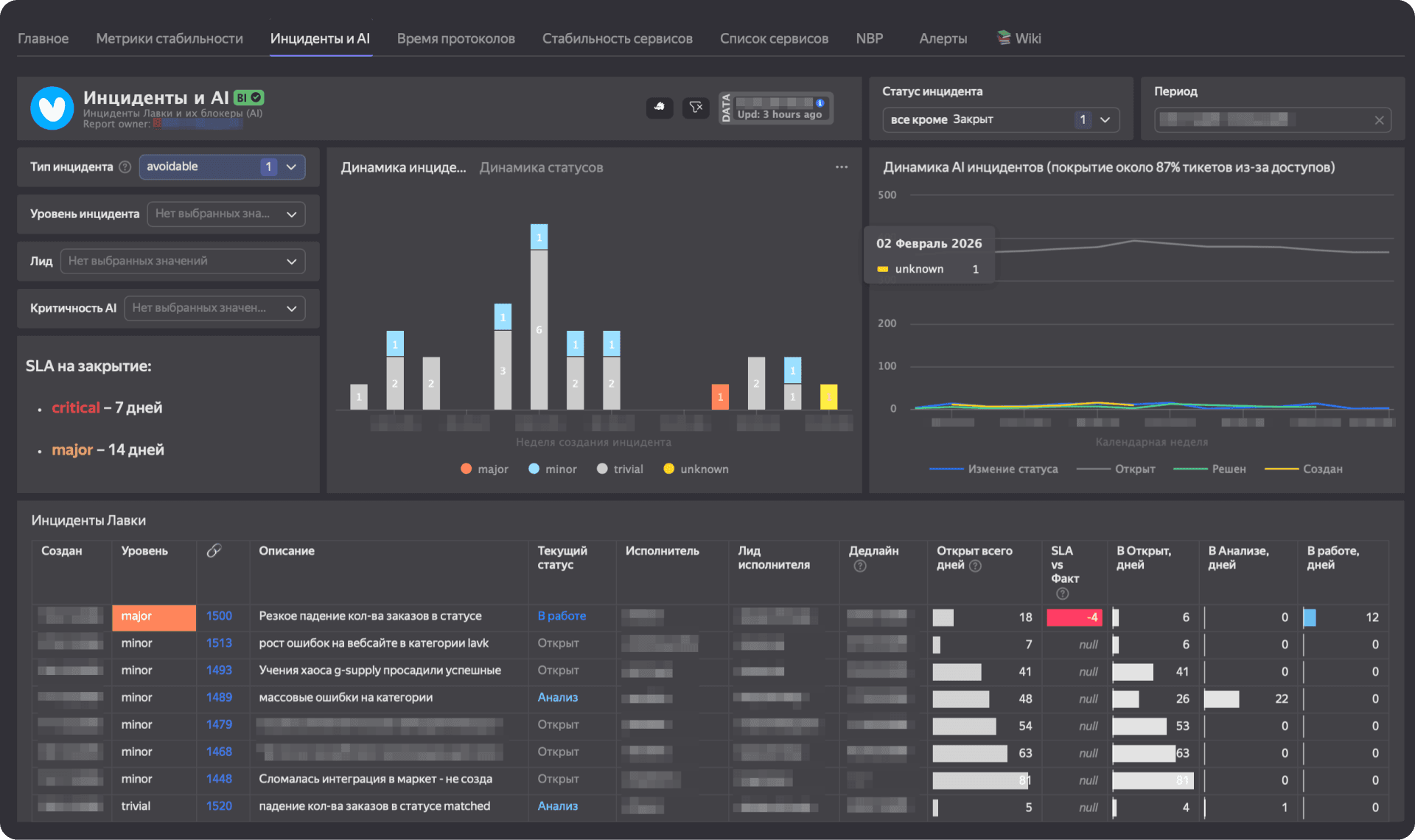
Подробнее о работе с релизами читайте в статье «Катим в прод, не тестируя. Как команды Яндекс Еды осознанно перестали тестировать часть кода»
Автоматическое нагрузочное тестирование в CI
Сделать функциональные тесты в пайплайне — это база. Но они не спасут от специфических проблем рантайма. Обычные тесты не спровоцируют корки, утечки памяти или проезды по памяти. Они не покажут, что вы случайно сделали вложенный цикл, выбрав неудачную структуру данных, и повысили алгоритмическую сложность.
Поэтому перед каждой выкладкой стоит запускать автоматическое нагрузочное тестирование микросервиса в изолированном load-окружении. Сервис должен поработать под полной нагрузкой хотя бы 10–15 минут. Этого достаточно, чтобы убедиться, что утилизация ресурсов и тайминги ответов не деградировали по сравнению с прошлым релизом. Да, внедрение требует усилий — нужно поддерживать запросы в актуальном состоянии. Но это та самая солома, которую необходимо подстелить.
End-to-end тесты в продакшене
Изолированных тестов мало. Нужно регулярно проверять capacity системы в целом с помощью нагрузочного тестирования в проде. Это помогает своевременно заметить нехватку запаса прочности или выловить кривой релиз, проскочивший между проверками.
Тестировать можно по-разному, но критически важно для транзакционного сервиса проверять полный цикл заказа. Главное — не забывать помечать в системе тестовые заказы как тестовые, чтобы не сломать аналитику и бухгалтерию.
Тотальная автоматизация регресса
Если у вас много ручного тестирования (что часто бывает с клиентскими релизами), ошибок из-за человеческого фактора не избежать. А в случае с бекендом, который у нас релизится по 50 раз в неделю, проверить всё руками физически невозможно — никакой QA-отдел не справится с таким потоком без автоматизации. Скорее всего, придётся придумывать ротацию паков тестов, а это всегда риск пропустить баг. Единственный выход — автоматизировать 75–90% сценариев. Это даст возможность гонять полный пакет регресс-тестов на каждый релиз.
Декомпозиция изменений
Ну и понятная, но сложная в реализации вещь — катиться лучше маленькими кусочками. Чем меньше релиз, тем меньше шанс, что сработает принцип «одно лечим — другое калечим». Разбиение приложения на модули, уход от монолитов, причём и на беке, и на фронте, изоляция блоков — всё это сокращает импакт изменений. Отдельно отмечу BDUI-подходы, которые тоже сильно помогают в изоляции логики, но это тема для отдельного большого разговора.
Работа с тем, что вот-вот настанет
Ок, с релизами разобрались, но инциденты случаются не только из-за свежего кода. Иногда бывают такие ситуации, когда мы знали (ну или могли знать), что упадём, но не сделали достаточно, чтобы этого избежать. И вот тут в игру вступает стратегия предотвращения.
Борьба с рецидивами
Инциденты неизбежны, это факт. Но нет ничего хуже, чем наступить на одни и те же грабли дважды. Поэтому каждый разбор полётов в идеале всегда должен заканчиваться списком Action Items. Главная проблема в том, что написать их мало — их надо выполнить. И чем раньше, тем ниже вероятность повторения.
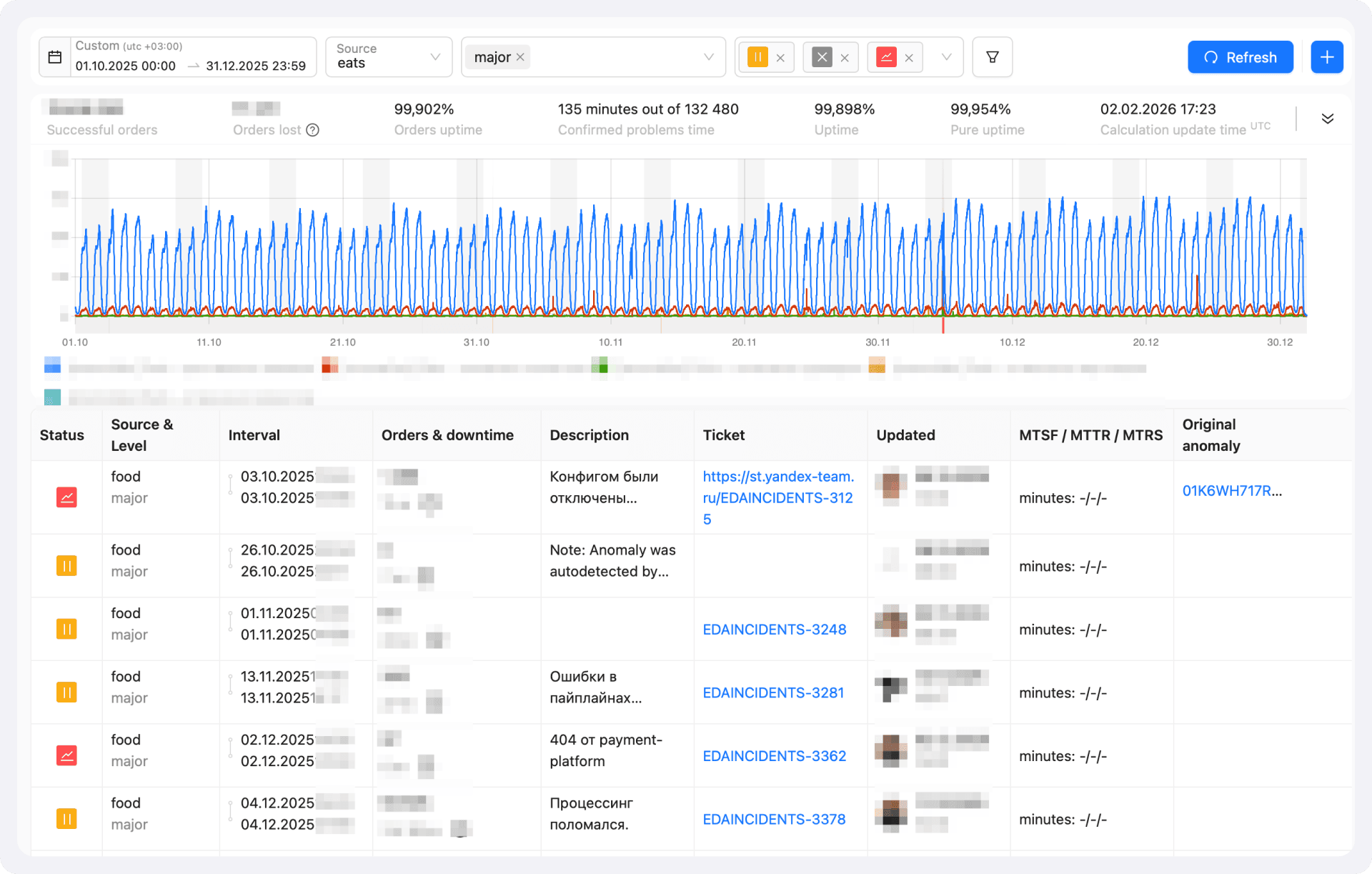
Мы постепенно сокращаем SLA на выполнение таких задач. Здесь важно не перегнуть палку: не нужно вешать жёсткие дедлайны на всевозможные nice-to-have идеи, родившиеся в процессе обсуждения. Строгий SLA касается только задач, которые в лоб предотвращают повторное падение или драматически снижают импакт от него.
Внимание к первым звоночкам
Часто перед большим инцидентом появляются едва заметные сигналы. Это может быть точечная жалоба пользователя, попавшего в неудачный эксперимент. Или багрепорт уровня blocker из релиза, который только начал раскатываться в сторах. Или даже простое обращение от коллеги, который открывает приложение каждые 10 минут и замечает лаги.
Если отмахнуться от этих сигналов, можно упустить ситуацию. Поэтому соблюдение SLA на обработку таких обращений — это тоже инструмент надёжности. Это помогает заметить проблему на ранней стадии и купировать эффект до того, как она положит весь сервис.
Об инструментах для оперативного отслеживания подобных аномалий читайте в статье «Найти баг за 60 секунд: Real-Time мониторинг Яндекс Маркета»
Учения и хаос-инжиниринг
Очень важно проводить регулярные учения. Например, имитировать потерю одного из дата-центров. Цель не только в проверке запаса прочности. Изменение топологии сети само по себе может вызвать неожиданные последствия — от проблем с автофейловером БД до metastable failure. Лучше найти эти проблемы в условиях контролируемого шторма, чем во время реальной аварии.
Автоматическое управление ресурсами
Бывало у вас такое: железа под сервисом вроде достаточно, а в пятницу вечером оно почему-то начинает стремительно заканчиваться? Вместо того чтобы судорожно искать свободные сервера вручную, мы внедряем автоматику. Система должна сама замечать нехватку ресурсов быстрее инженера и докидывать их. А когда нагрузка спадает — перекидывать мощности, например, на аналитические вычисления. Это не только надёжно, но и утилизирует простой оборудования.
Реагирование, чтобы не летать вслепую
Когда катишь важный и опасный релиз, палец всегда на кнопке отката, один глаз на деплое, другой на графиках. Максимальное сосредоточение. Тут всё понятно. Но бывают и обратные ситуации.
В сложной распределённой системе с кучей сервисов, баз и балансеров неизбежно ведро алертов. И какой-то из них постоянно мигает. Тут-то частенько и попадают в ловушку: «А, этот алерт горит уже неделю, там известная проблема, пользователей не аффектит. А этот — фолсил вчера, я его замьютил».
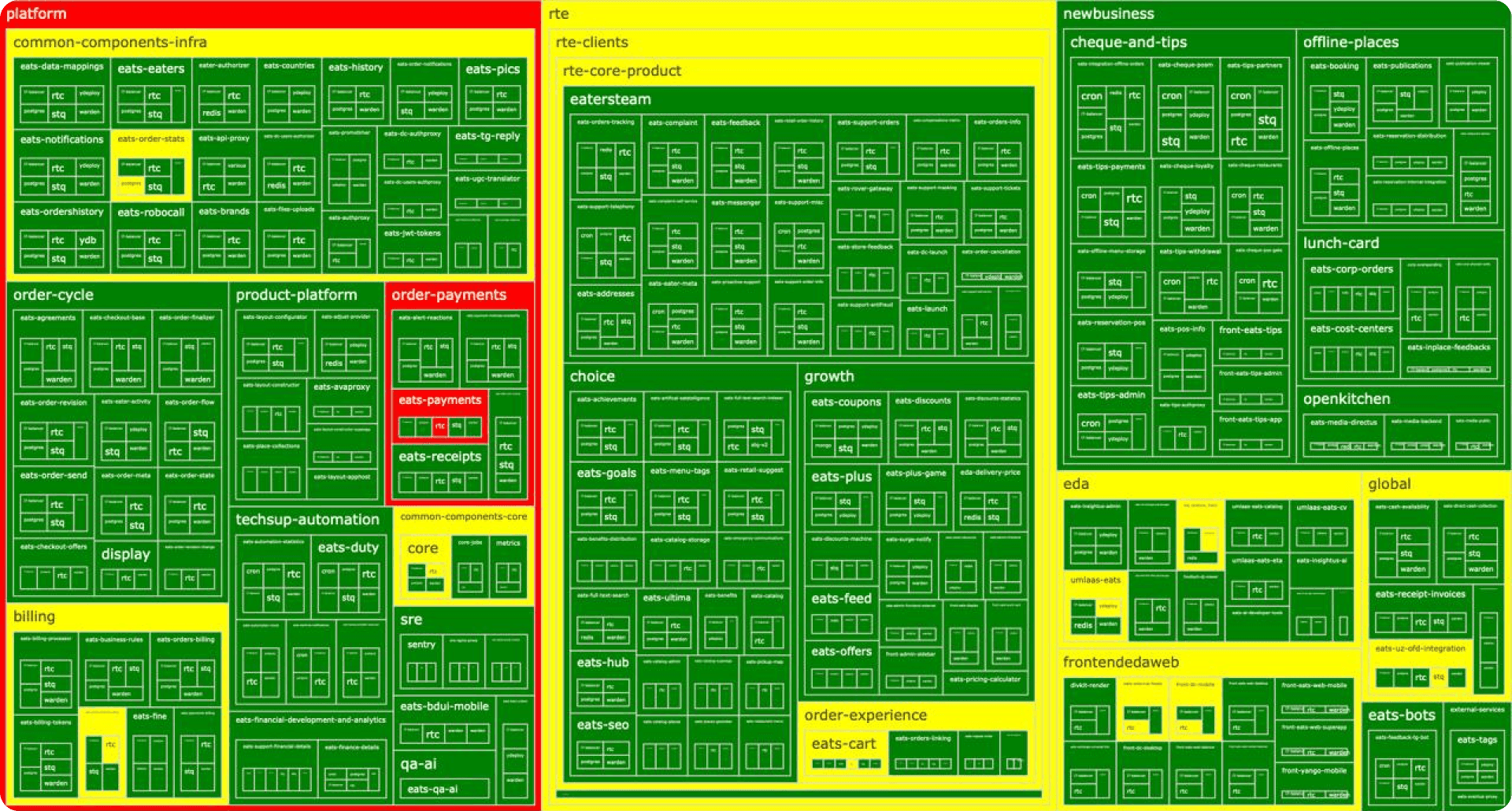
Такое игнорирование приводит к слепоте, как баннерная, когда мы не замечаем надоедливую рекламу, только алертной. Это как с лампочкой «Check engine» в машине. Некоторые ездят с ней годами. Но даже если она загорелась из-за какой-то ерунды, в результате вы рискуете пропустить уже реально важную проблему.
В мониторинге сервисов принцип тот же. Нужно держать высокий Alerts Uptime — долю времени, когда не горит ни один алерт. Этот показатель должен приближаться к целевому аптайму самой системы. Всё это стоит визуализировать в виде полотна с плитками, где любой не-зелёный кусочек должен вас сразу же триггерить. Некритичные сигналы уводим в отдельный диагностический канал, а реально критичные настраиваем так, чтобы их невозможно было не заметить.
Как грамотно организовать такую визуализацию метрик, читайте в статье «Дашборды здорового человека: опыт Техплатформы Городских сервисов»
Эскалация и роботы
Чтобы критичный сигнал точно дошёл до адресата, нужна жёсткая эскалация. В том числе телефонная. Если дежурный проспал пуш, робот должен дозвониться до запасных, вплоть до CTO.
Автоматика должна инициировать и сам протокол инцидента: создать чат, призвать ответственных, задать первичные вопросы. Если дежурный не явился в протокольный чат — система должна сама повысить severity инцидента и начать писать в общие каналы коммуникации, потому что ситуация явно вышла из-под контроля.
Слепая зона бэкенда
Ещё один важный момент — мониторинг со стороны клиента. Бывало у вас такое: по метрикам бэкенда всё зелёное, 200 OK, а фича не работает? Причин может быть очень много: пустое тело ответа, нарушение контракта схемы, логическая ошибка, ещё что-то.
Приложение не должно просто рисовать заглушку «ой, что-то пошло не так». Оно должно отправлять метрики и алертить. Причём следить нужно не только за синтаксическими, но и за семантическими ошибками. Например, синтаксически корректная, но абсолютно пустая выдача — это тоже сигнал тревоги, который бэкенд сам по себе может и не заметить.
Снижение ущерба: купировать и деградировать красиво
Ущерб от любого инцидента можно снизить всего двумя способами: либо быстрее купировать проблему, либо переключиться в режим деградации. Звучит банально, но всё самое главное — в реализации.
Автоматизация отката
Так как львиная доля инцидентов — прямое следствие неудачного релиза, правило номер один кажется очевидным: просто откати изменения как можно скорее. Вы не представляете, сколько раз на разборах полётов я повторял команде мантру: «Сначала откатывай, потом думай». Один коллега даже набил себе татуировку с этим текстом на руке.
Помогло ли это? Нет.
В стрессовой ситуации люди ведут себя нелогично, тянут время, надеются починить по-быстрому и в итоге делают только хуже. Вывод, к которому мы пришли: единственный надёжный способ заставить это правило работать — исключить человека из уравнения. Процесс отката должен быть автоматизирован.
Учения и инструкции
Действия людей во время починки часто бывают неорганизованны из-за волнения или нехватки опыта. Им нужно с этим помогать. Например, проводить учения именно по восстановлению сервиса, доводя типовые действия до автоматизма.
Многие команды практикуют такой формат: один участник неочевидно ломает сервис (лучше в тестовом окружении), а другой пытается найти причину и починить. Это развивает фантазию и стрессоустойчивость. Кроме того, на случай типовых поломок должны быть инструкции — не талмуды на 50 страниц, а короткие, быстродоступные гайды: где какие рубильники, фолбеки и кейсы переключения.
Гонка со временем
Бывало у вас такое: алерт сработал чётко, вы молниеносно прожали откат, но следующие пару часов со слезами на глазах наблюдаете агонию сервиса? Это происходит, если приложение стартует слишком долго.
Причины могут быть разными. Например, сервис долго набирает инмемори-кеши, без которых не может обслуживать трафик. Или по системе гуляет запрос-убийца, который валит поды в coredump, а новые поднимаются медленнее, чем падают старые. Даже простая операция масштабирования (докидывания подов) под внезапный рост нагрузки превращается в гонки со смертью. Поэтому оптимизация времени холодного старта — это не вопрос удобства разработки, а вопрос выживания в инциденте.
Про реальный кейс поиска и устранения подобных узких мест можно прочитать в статье «Как мы Сурж чинили: история поиска узких мест в highload-системе Яндекс Еды»
Режимы деградации
И, наконец, про работу в нештатном режиме. Мы называем это тыквами — режимы продуктовой или технической деградации. Идея проста: лучше работать хоть как-то, чем вообще никак.
Если мы не можем показать пользователю все тысячи ресторанов, которые теоретически доступны, давайте покажем хотя бы 50 высокоранжируемых. Если в выдаче будут хоть какие-то варианты, то половина аудитории всё равно останется сытой и довольной и даже не заметит подвоха. А вот пустой экран заметят все.
Какие именно режимы деградации реализовать, зависит от семантики конкретного экрана, вашей фантазии и договорённостей с бизнесом. Нужно смотреть на конкретную ситуацию и понимать, как урезать использование до минимально приемлемого уровня. Но почти всегда частичная работоспособность лучше полной тишины. Вывод прост: купируйтесь и деградируйте.
Заключение
Что ж, подведём итоги. В начале статьи я ворчал и провокационно заявлял, что надёжностью заниматься не надо. На самом деле — надо, и ещё как! Финансовые выкладки это только подтверждают. Особенно если помнить, что при инцидентах вы не только упускаете новые заказы, но и фейлите те, что уже приняли, нарушая свои обязательства.
Главный вывод из моей стратегии может прозвучать странно: купируйтесь и деградируйте. Забейте на попытки сохранить идеальную работу системы любой ценой, если она уже падает. Иногда лучше отбросить часть функциональности или показать меньше контента, чем лечь полностью.
В конечном счёте наша задача — не набить четыре девятки в отчёте, а построить процесс, который позволяет быстро замечать проблемы, локализовать их и восстанавливаться.
Здоровья вашим сервисам. А если что-то всё же пойдёт не так — не проморгайте. И не привыкайте, пожалуйста, к горящим алертам.
Кстати, эта статья выросла из нескольких заметок в моём телеграм-канале. Там я продолжаю рассказывать про внутреннюю кухню Яндекс Лавки, управление командами и процессы разработки. Иногда ворчу на IT-тренды, иногда разбираю неочевидные инженерные грабли, а иногда просто делюсь мыслями, которые помогают не сойти с ума в нашей профессии. Если вам близок такой подход, основанный на здравом смысле — заглядывайте, буду рад подискутировать.



