

Спасибо Николаю Смирнову как соавтору и команде за помощь со статьёй.
Лавка — сервис быстрой доставки продуктов. Один из важнейших сценариев использования сервиса для покупателя — это поиск. Примерно 30% товаров добавляются в корзину именно из его результатов. А ещё, если в пользовательской сессии был успешный запрос в поиск, вероятность совершения заказа вырастает на 10–15%. То есть, если клиенту нужен конкретный продукт и он его быстро находит через поиск, вероятность совершения заказа становится выше.
Корректная и качественная организация поиска — нетривиальная задача, поэтому иногда приходится придумывать нестандартные решения, чтобы всё работало как нужно. В этой статье я расскажу историю развития поиска в Лавке от самого начала до текущего момента. Нам пришлось объединить всю силу и мощь целых трёх движков, чтобы пользователи получали точный и актуальный результат. Параллельно погрузимся в различные технические детали, проблемы и прочие нюансы.
Как ищет Лавка
Разобраться, как работает поиск в Лавке, нам поможет Миша — абстрактный пользователь нашего сервиса. Однажды вечером Миша хочет найти в поиске Лавки что-нибудь «Из Лавки» (это продукты под собственной торговой маркой). Он вбивает в поисковую строку свой запрос и видит результаты:
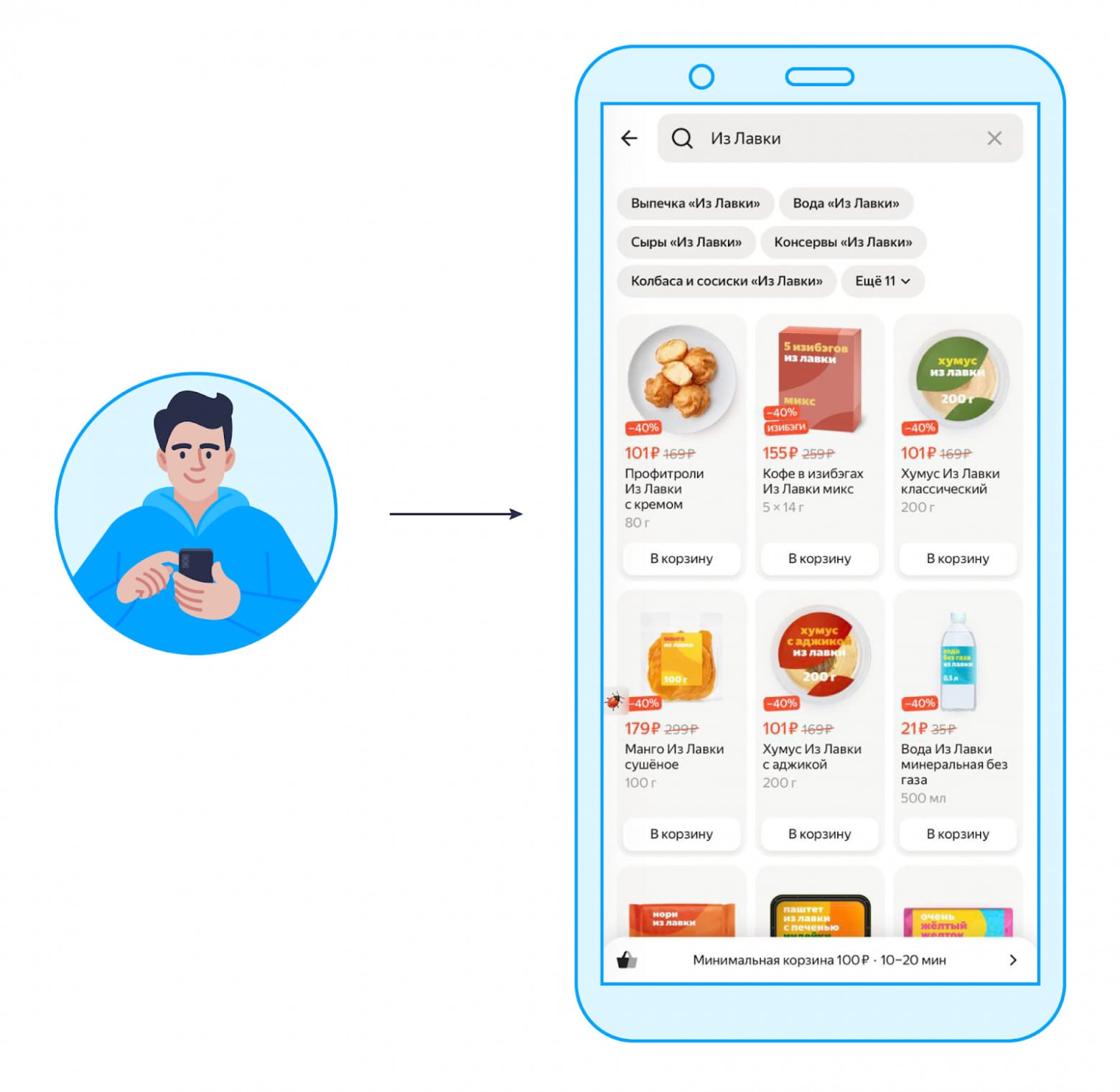
На скрине можно увидеть, из чего состоит поисковая выдача в приложении. Первое — это категории. Это то, по чему вы кликаете и попадаете в некоторое место в каталоге (например, в категорию «Молочные продукты из “Лавки”» или в «Бананы»). Второе — сами товары, о поиске которых мы сегодня в основном и будем говорить.
Но прежде чем переходить к самой истории, обозначим несколько особенностей поиска в Лавке, которые необходимо учитывать при разработке.
- У нас есть важные составляющие, такие как дарксторы (ещё мы называем их «лавками») — это склады, откуда пользователям доставляются товары. На каждой «лавке» есть определённое количество товаров в наличии — его мы называем остатком. Важно учитывать значения остатков на каждой конкретной «лавке»: на разных складах в наличии может быть разный ассортимент. Если поисковый движок не умеет учитывать остатки на складах, придётся фильтровать товары по этому критерию после получения выдачи и, возможно, ходить в движок несколько раз, чтобы в итоге показать пользователю достаточное количество товаров (что несёт дополнительные расходы в производительности). Ну и, конечно же, мы не можем продать пользователю то, чего по факту у нас нет.
- У нас префиксная модель поиска (то есть, поиск по префиксу запроса): с его помощью мы можем подсказывать покупателю то, что он вероятнее всего ищет. Например, когда покупатель набирает «моло» с определённой долей вероятности он ищет молоко, и благодаря префиксному поиску мы можем сразу показать ему молоко или молочные продукты. То есть мы хотим сразу отдавать поисковую выдачу, как только пользователь что-то ввёл. Эта модель существует в противовес часто используемой модели поиска: сначала пользователь вводит весь запрос, и только потом начинается весь процесс. Соответственно, это накладывает некоторые ограничения на реализацию.
- Необходимо искать не только товары, но и категории, чтобы предоставить пользователю возможность исследовать каталог и выбрать наиболее подходящие результаты.
Кастомный движок
Самым первым решением для поиска в Лавке товаров и категорий был алгоритмический самописный движок — internal. Внутри — алгоритм Ахо-Корасик с исправлением ошибок (то есть опечаток) с помощью расстояния Левенштейна. Работает это просто: есть несколько кэшей с номенклатурой по товарам, категориям и другим параметрам. Они обновляются почти в реальном времени и все сливаются в индекс, поверх которого уже реализована логика поиска.
Но этот движок ничего не знает про склады и остатки на каждом из них. Поэтому после получения выдачи от движка на клиентский бэкенд (сервис client-api) приходится отфильтровывать выдачу по этим параметрам.
Собственно, в тот момент, когда у нас использовался этот поисковый движок, путь запроса Миши выглядел так:
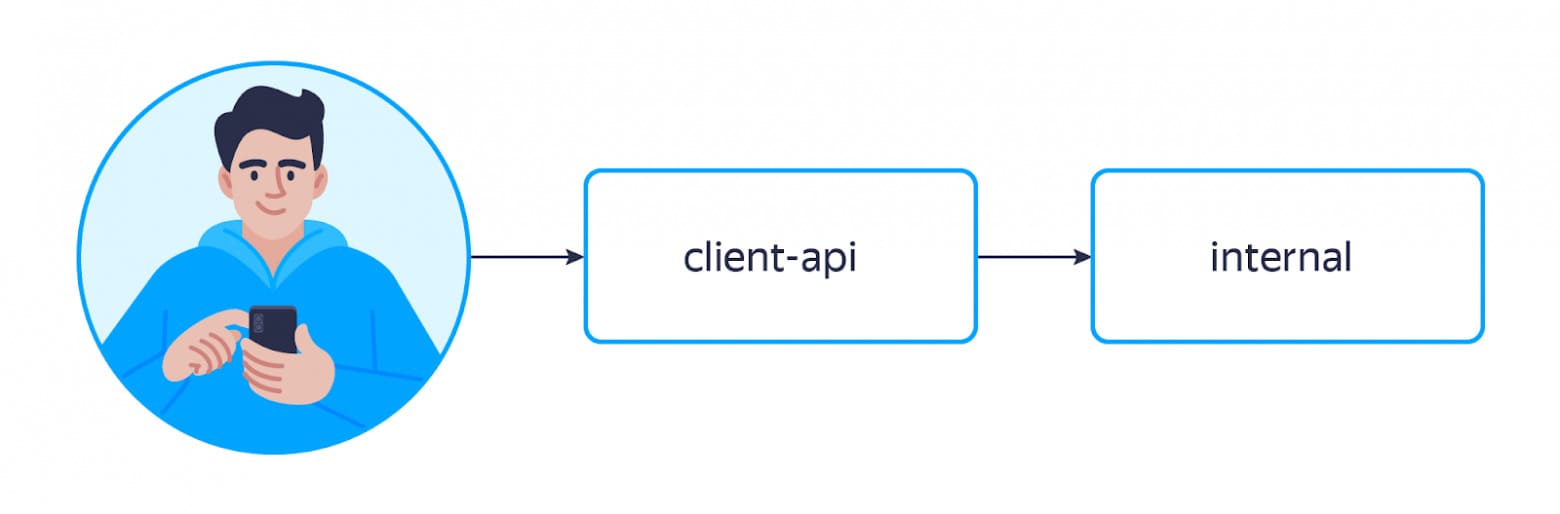
Работает движок довольно быстро — порядка десятка миллисекунд на запрос. Это позволяет ходить за результатами поиска часто, набирать много товаров и получать довольно широкую выдачу. Однако он может выдавать не самые релевантные результаты.
Например, было несколько ситуаций, которые возникали из-за неструктурированности каталога и описаний товаров:
- При индексации мы склеивали категорию товара, чтобы как-то использовать тот факт, что у нас товары объединены в группы. Из-за этого иногда случались глупости: у нас была категория «Сёмга и авокадо» и вы по запросу «авокадо» могли найти сёмгу.
- Ещё был товар с названием «Гречневая лапша с цукини и ореховым соусом “Братья Караваевы”». «Братья Караваевы» — бренд, но по запросу «каравай», учитывая исправление ошибок, мы могли в итоге найти лапшу, хотя пользователь искал каравай и ожидал увидеть в результатах выдачи хлеб или что-то похожее.
Подобные проблемы с качеством, конечно, можно решить своими силами, но, учитывая, что мы всё-таки живём в большой поисковой компании, хотелось попробовать использовать более мощные внутренние решения.
SaaS
SaaS (Search as a Service) — внутреннее решение Яндекса для полнотекстового поиска из коробки. При использовании этого движка вводится понятие документа. Под ним подразумевается всё, что вы хотите — главное, правильно выгрузить по заранее заданному формату (то есть вы можете индексировать абсолютно любые объекты от веб-страниц до товаров). Тут можно гибко настраивать различные факторы для поиска, управлять весом этих факторов, обучить и использовать альтернативную ML-модель для ранжирования, включать и отключать различные настройки вроде переводов, опечаточника и прочего. Всё это делается довольно удобно.
Мы проводили A/B-тесты по переходу с нашего движка на SaaS в базовой комплектации и получили положительные результаты. Например, доля выдач, на которую кликнули (то есть добавили товар в корзину или просто кликнули на товар после того, как он отобразился в выдаче), выросла на 3%. Пользователи стали охотнее добавлять товары в корзину из выдачи и стали использовать поиск чаще, что означает рост доверия к инструменту.
Но найти простое решение без существенных доработок, позволяющее быстро доставить до SaaS информацию о том, что товар привезли в лавку или о том, что он там закончился, не удалось. Он не знает про склады и остатки, собственно, как и самописный движок. С этим также приходилось разбираться на клиентском бэкенде.
Технически это работало так: есть крон-таска, которая выгружает во внутреннее распределённое хранилище YTsaurus все товары, категории и их связи с товарами, а затем делает запрос в ответственный за индексацию SaaS-микросервис ferryman. Когда ferryman получает запрос, он понимает, что выгрузилась новая партия данных, идёт в указанное место в хранилище и забирает эту партию. Так как он хранит у себя всю историю прошлых выгрузок (снапшотов), он сравнивает новый снапшот с прошлым, вычисляет дельту и закидывает её в индекс SaaS. Теперь можно идти за поисковой выдачей.
При поиске через SaaS путь запроса Миши стал выглядеть так:
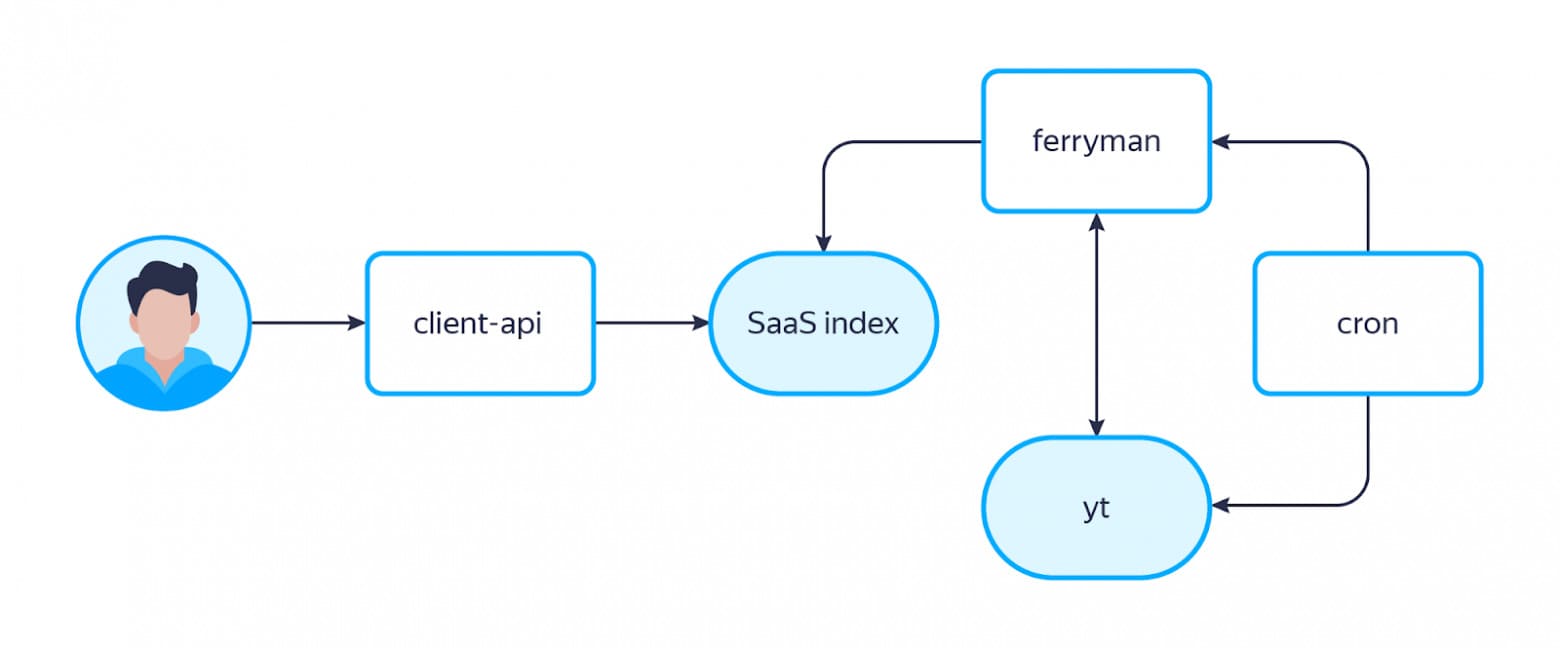
При этом стоит понимать, что свой движок мы никуда не дели: так как SaaS поддерживается внешней командой, мы стали использовать internal в качестве фолбэка, чтобы отдать пользователю выдачу в случае поломки SaaS. Да, она будет с качеством похуже, но всё же будет.
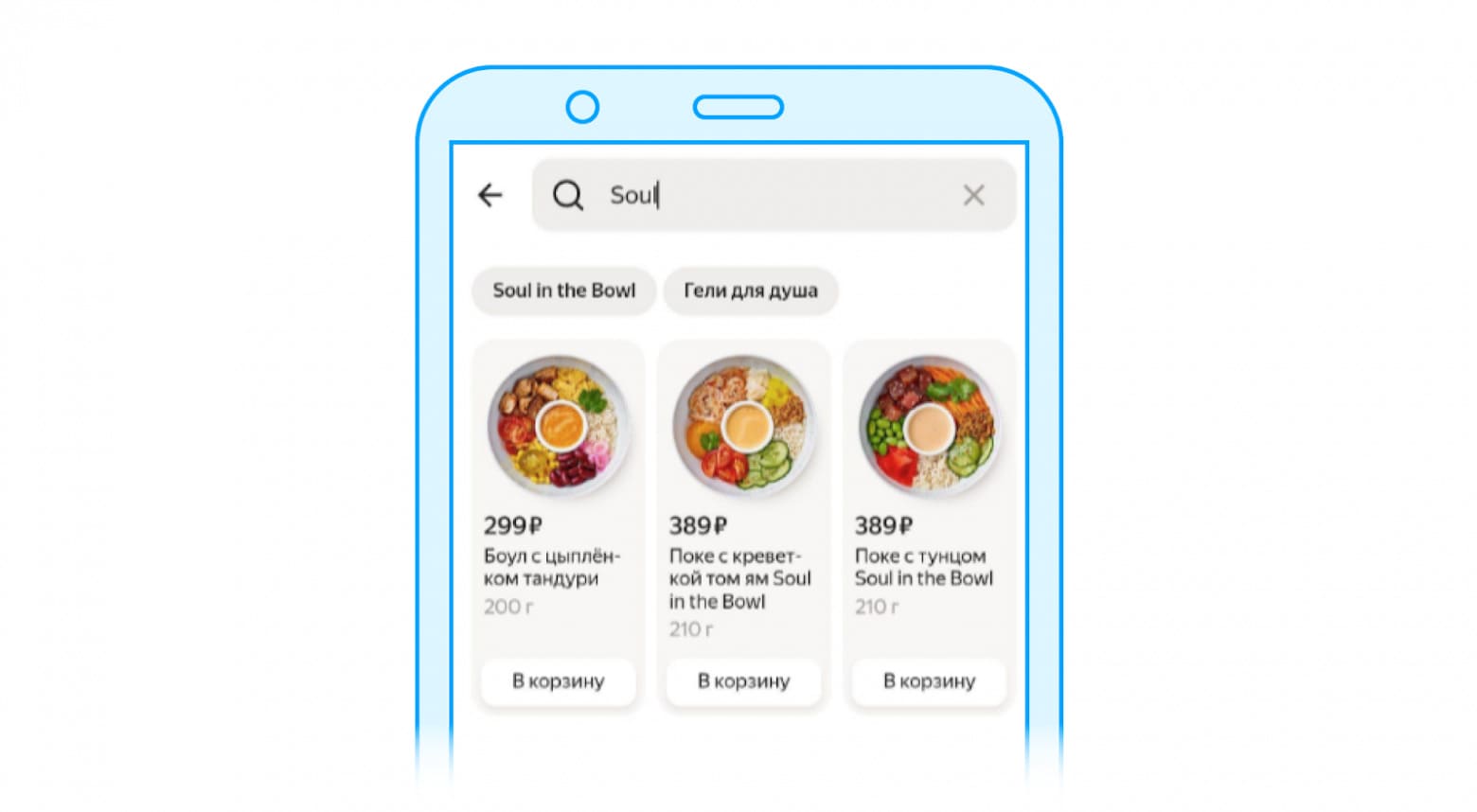
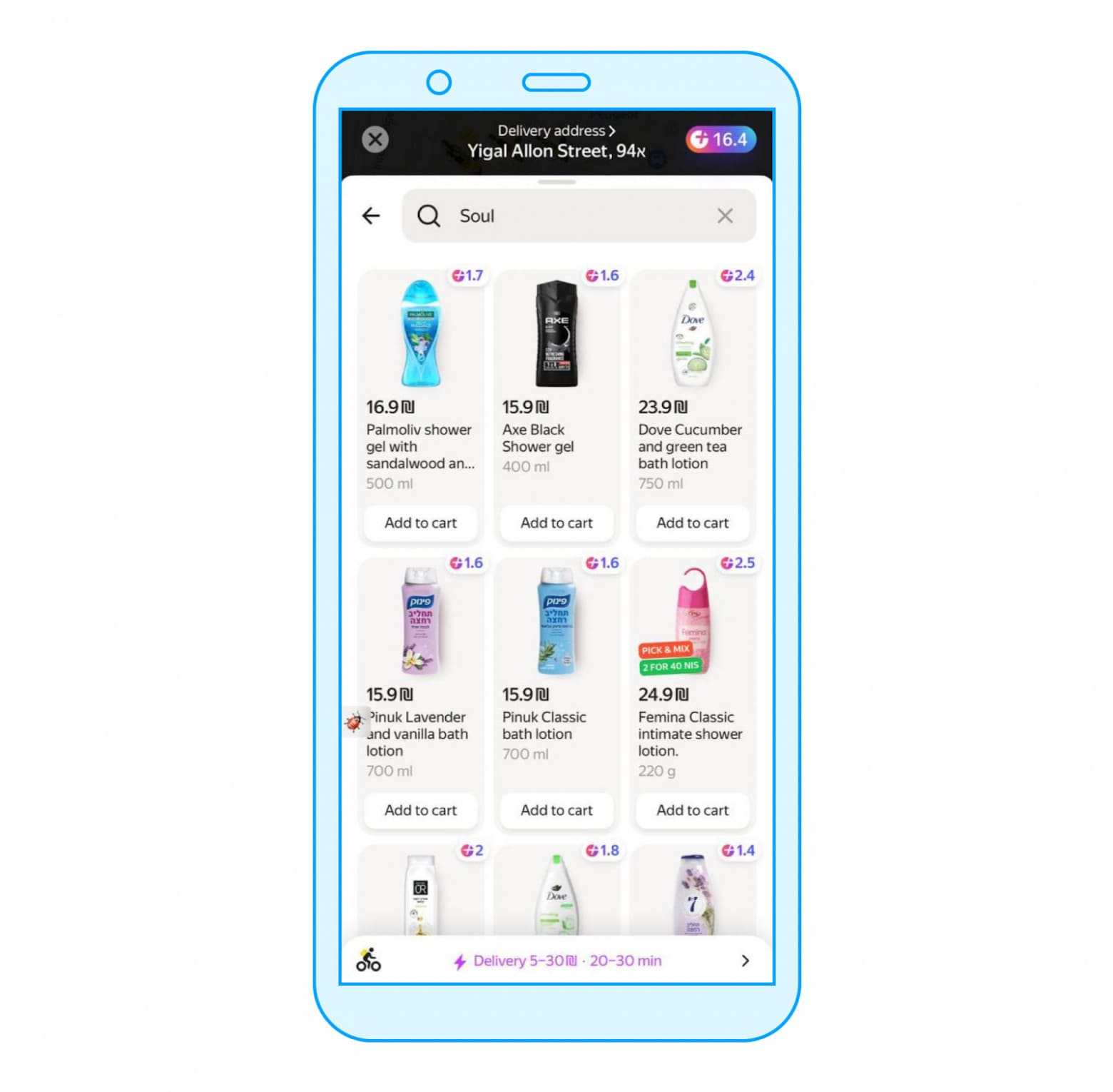
Тут были и забавные артефакты. Внутри SaaS есть переводчик, который мы используем в силу присутствия Лавки как сервиса вне РФ. И если вы в поиске вводили «soul» (что на русский переводится как «душа»), то вы получали в категориях «Гели для душа». Сейчас, конечно, такого у нас не встретить.
Маркетный репорт
Позже мы попробовали перейти на маркетный репорт — это движок Яндекс Маркета для полнотекстового поиска. Важная особенность этого движка в том, что он продуктово максимально близок к нашим задачам. Репорт создавался именно для того, чтобы искать товары: внутри уже есть логика учёта складов и остатков на них, — а это ровно то, что нам нужно. А ещё ранжирующая модель репорта обучена под e-com специфику, что позволяет тратить меньше усилий для получения более релевантных результатов.
Мы получили хорошую прокраску метрик и решили оставить его в качестве основного движка для поиска товаров: количество релевантных выдач, на которых пользователь кликнул на товар или добавил что-то в корзину, увеличилось на 25% , а ещё поиском стали пользоваться в бо́льшем количестве сессий. При этом мы учли, что маркетный репорт всё-таки не реализовывает префиксный поиск: пришлось добавить поисковой прокси между нашим бэкендом и движком Маркета. Но об этом позже.
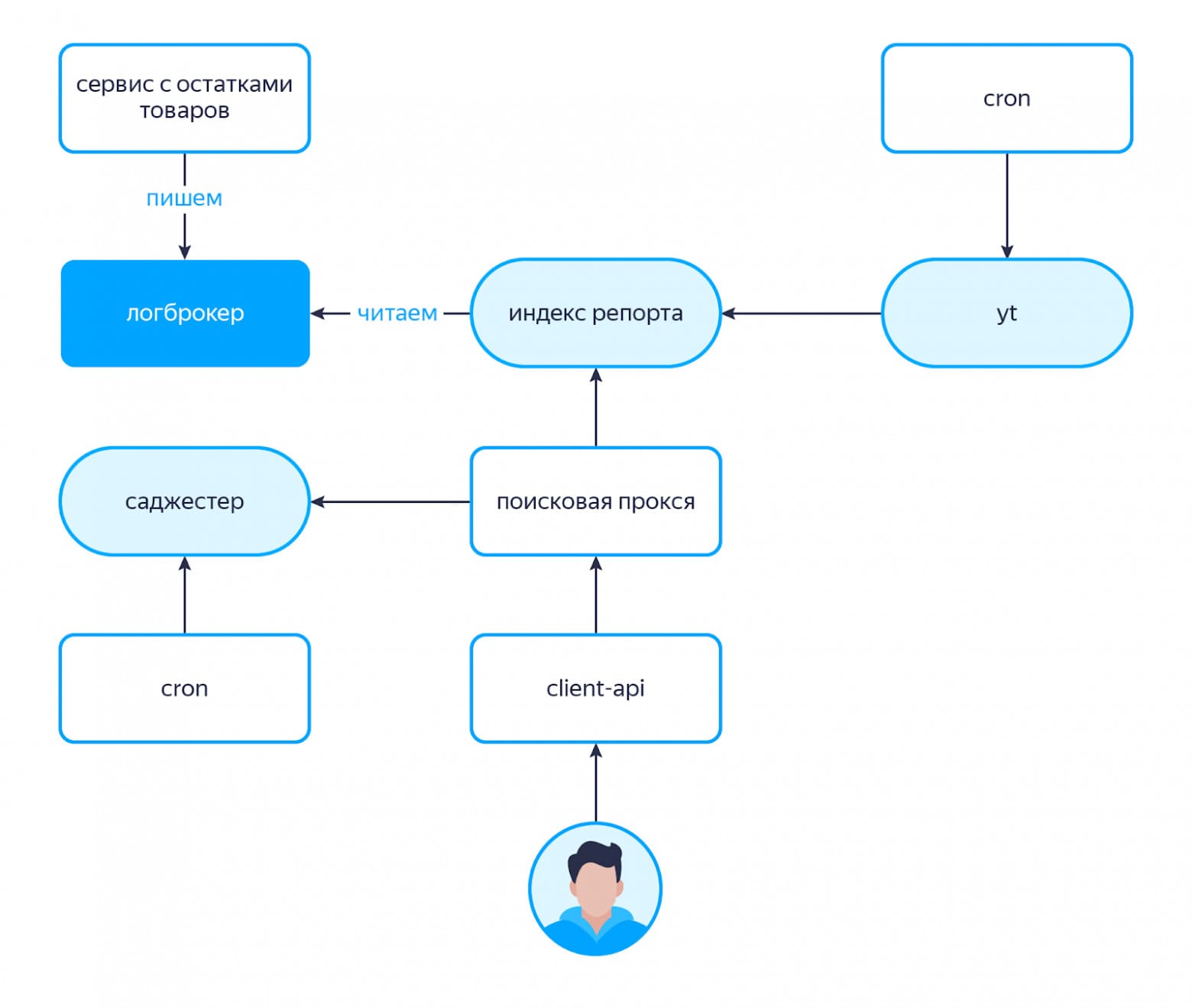
Информацию в маркетный репорт мы можем доставлять двумя путями.
Первый путь — это медленный контур. У нас есть крон-таска, которая выгружает информацию о товарах в YTsaurus по заранее заданному индексатором протоколу, после чего данные отправляются в поисковый индекс.
Поисковый индекс варится несколько раз в сутки и, соответственно, если мы добавили какие-то новые товары на даркстор, нужно прождать от 5 до 12 часов, пока эти товары прорастут в поиск. Проще говоря, минус этого решения в том, что новинки уезжают в поиск медленно.
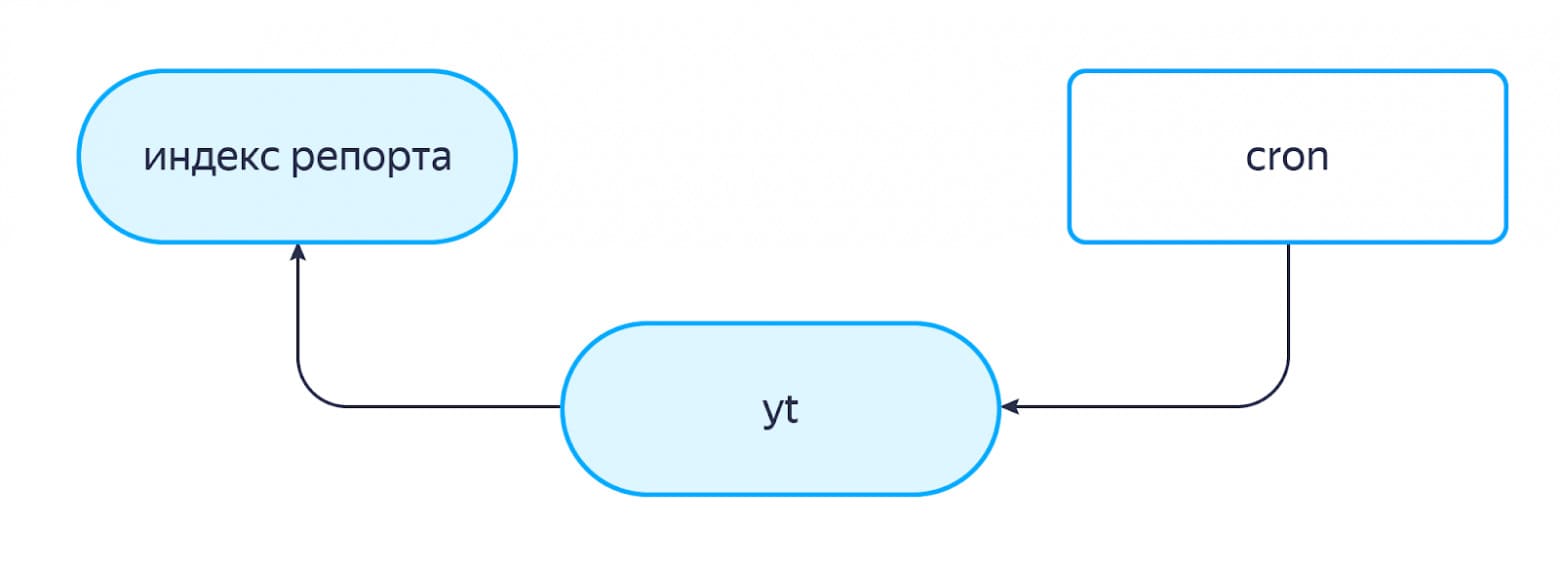
Второй путь — быстрый контур. Это не альтернатива медленному, а скорее вспомогательная часть, позволяющая быстро обновлять некоторые атрибуты товаров.
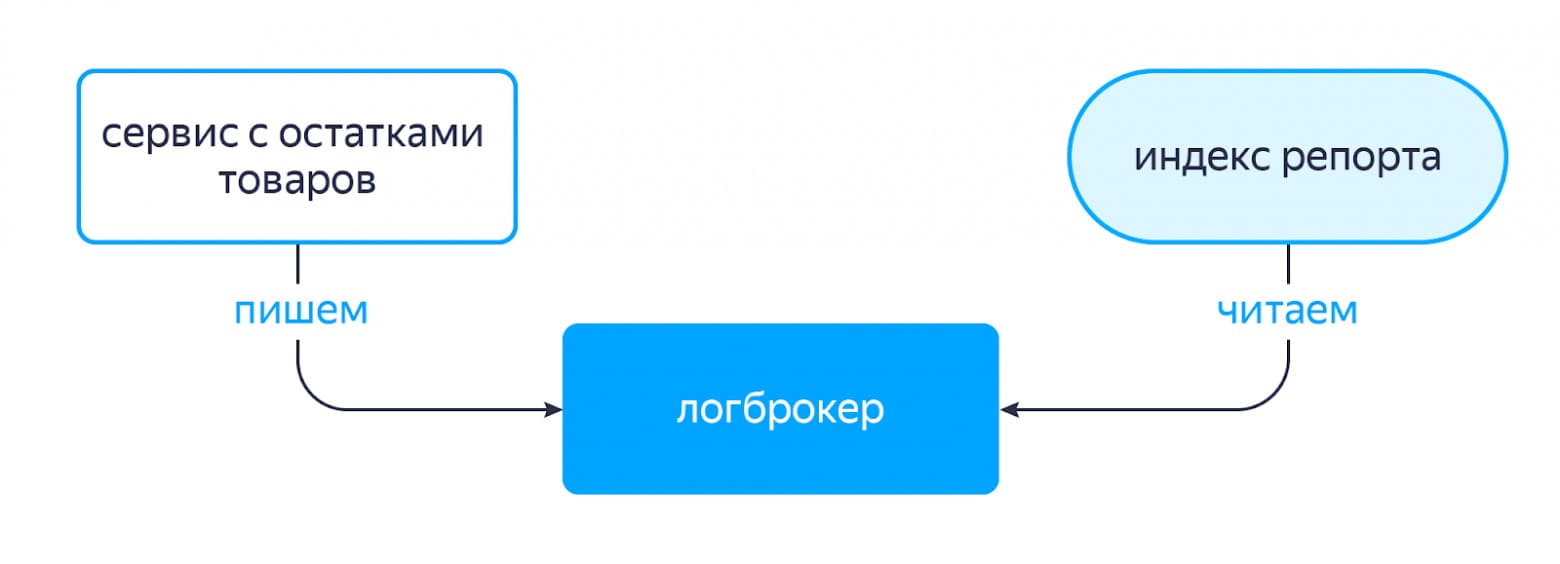
У нас есть сервис, который отвечает за хранение остатков товаров на складах. Когда в базе данных этого сервиса меняются значения остатков для каких-то товаров, срабатывают триггеры, которые инициируют запись сообщения в топик логброкера с информацией о том, у какого товара какой атрибут изменился. И индекс репорта умеет следить за такими вещами: читать данные из нужных топиков, забирать себе информацию и обновлять данные внутри индекса. Работает это довольно быстро, что помогает движку возвращать более актуальные по остаткам товары, в отличие от SaaS и internal-движка.
Прокси
Как я уже говорил, между нашим бэкэндом и маркетным репортом стоит поисковый прокси. Это отдельный сервис, который реализует лавкоспецифичную логику. Разберёмся, что делает прокси.
Прежде всего он реализует префиксный поиск, в который не умеет репорт. По начальной части введённого в поисковую строку слова сервис пытается понять, что хочет найти пользователь. Коллеги из команды саджеста, которые делают главную поисковую страницу, когда-то расширили свой сервис специально для Лавки и возвращают нам набор дополнений для частичного запроса от пользователя.
Откуда он берёт дополнения? Во-первых, у нас есть регулярный процесс, который выгружает номенклатуру Лавки в индекс саджестера. Во-вторых, пользователи иногда могут вести «моло», а потом продолжить до «молотки». Если саджестер увидит, что K пользователей сделали так несколько раз (то есть пользователи продолжают какой-то префикс до какого-то конкретного слова или словосочетания), он запомнит этот факт и сможет выдавать это продолжение на следующие запросы по префиксу.
Соответственно, для «моло» мы могли получить в качестве дополнения «молоко» и «молочные продукты» из номенклатуры и внезапно «молотки» (хотя, вроде, в Лавке мы их не продаём), просто потому что пользователи такое часто пытались у нас искать. С каждым дополнением возвращается число — его вероятность. Так у дополнения «молоко» в Лавке большее значение вероятности, чем у «молоток».
Так мы реализуем логику префиксного поиска и по возвращённому набору из N дополнений ходим в репорт за получением поисковой выдачи.
Изначально вместо саджестера использовалось префиксное дерево или trie. Эта структура данных позволяет по последовательности символов — ключам узлов дерева, по которым запрос спускается до нижних уровней, — найти наиболее частотные ветви (дополнения к префиксу). Дерево регулярно перестраивается на основе запросов пользователей, поэтому эта модель также может подстраиваться под «молотки», если пользователи часто их ищут по префиксу «моло». После того как мы реализовали логику походов в саджестер, префиксное дерево стало фолбэком на случай его поломки.
Кроме того, маркетный репорт разрабатывался для поиска на русском языке, а у Лавки задачи немного шире. Сейчас Лавка работает в двух странах — России и Израиле. Для поиска за рубежом запрос на иностранном языке проходит этап перевода на русский.
Кстати, у задачи определения языка поискового запроса есть вероятностное решение. С текстом и региональными настройками из сессии пользователя в качестве подсказки мы ходим в сервис Яндекс Переводчик. Он определяет наиболее вероятные оригинальные языки запроса и возвращает переводы с числовыми значениями веса, характеризующими уверенность в результате. Вес участвует в определении позиции товара в поисковой выдаче и может понизить её при неоднозначности перевода.
Про переводы есть ещё один интересный факт. Если вы приезжаете в Израиль, то можете воспользоваться киллер-фичей — ввести что-то на русском. Если запрос не очень сложный и есть подходящие товары где-то на вашей израильской лавке, то вы по русскоязычному запросу получите вполне релевантную выдачу товаров на иврите. Мелочь, а приятно.
Однако тут же могут быть и стьюпиды. В уже знакомом примере с «душой». Если, находясь в Израиле, ввести «soul», то довольно успешно мы найдём гели для душа (и для души, конечно же).
Подобные проблемы — это точка роста в качестве нашего поиска, над которым мы продолжаем работать.
ML-переранжирование
Итак, после того как к нам вернулось N поисковых выдач от репорта по указанным дополнениям и переводам, задача прокси — смёржить товары из нескольких выдач в одну и вернуть на клиентский бэкенд список идентификаторов. Там они обогатятся информацией для отображения: заголовком, картинкой, ценой и прочими атрибутами.
На каждый товар из поисковой выдачи репорта приходит число, означающее релевантность для запроса покупателя. В простом подходе можно было бы отсортировать все товары из N выдач по убыванию релевантности и вернуть пользователю. Но мы поступаем немного иначе: используем релевантность от репорта, как один из параметров формулы вычисления вероятности клика по элементу выдачи. В числе таких параметров есть популярность товара в Лавке, его цена, вес перевода и другие признаки. Таким образом мы сортируем конечную поисковую выдачу по убыванию вероятности клика и показываем пользователю наиболее подходящие товары в топе.
Раньше роль этой формулы играла линейная комбинация важных признаков товара, каждый со своим весом. Но потом мы изменили этот подход: обучили формулу пересчёта релевантности на кликах пользователей, используя CatBoost. С помощью подобной модели мы пытаемся предсказать вероятность клика пользователя на товар, после чего переранжируем результаты с учётом этой вероятности. Модель также умеет учитывать изменения: если пользователи по запросу «Кола» почему-то вдруг стали чаще кликать на другую газировку, это будет учтено. В итоге такая газировка окажется выше в результатах, просто потому что пользователи считают, что так для них правильно.
После внедрения новой формулы основная метрика поиска — релевантность — значительно выросла. Эта метрика вычисляется с помощью ручной разметки в Толоке. Толокерам отправляется пара: поисковый запрос в префиксной форме (то есть, ещё не дополненный саджестером) и поисковая выдача товаров. И они должны оценить качество поиска с точки зрения релевантности найденных товаров. Так люди помогают машинам делать поиск в Лавке лучше.
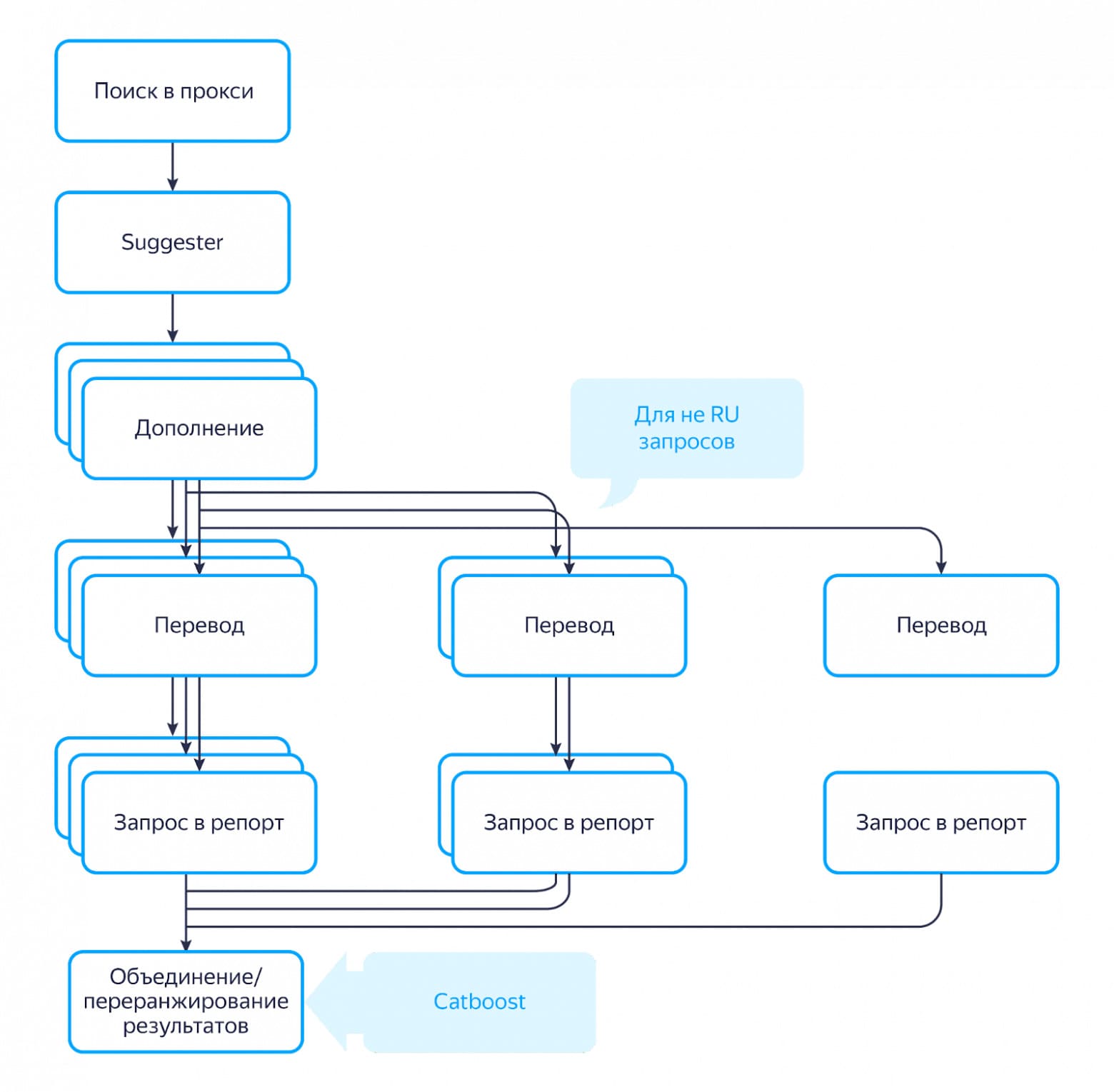
Если обобщить, то вся цепочка работы с репортом выглядит вот так:
Как мы подружили три движка
Сейчас репорт используется для товаров, SaaS — для категорий, а internal — для страховки.
Почему же мы не оставили какой-то один движок, ведь сейчас нужно поддерживать сразу три? Во-первых, у нас должно быть своё решение, которое мы сможем быстро починить и использовать как фолбэк на случай, если какой-то из двух других движков сломается (эту роль как раз выполняет internal). Во-вторых, задача поиска категорий скорее похожа на типичную задачу полнотекстового поиска, с чем успешно справляется SaaS (с текущей релевантностью порядка 95%, а это мы его ещё не сильно качали).
Также в качестве успешной коллаборации двух движков можно упомянуть поиск раскупленных товаров: иногда в выдаче можно увидеть товары, которых нет на остатках. Их нельзя купить, но можно подписаться на них. Когда товар появится в наличии, пользователь получит уведомление и сможет поскорее сделать заказ с любимыми вкусняшками (а ещё это помогает нам прощупать спрос на отсутствующие товары).
Так как репорт не возвращает товары, которые отсутствуют на остатках, для каждого запроса мы параллельно ходим в internal. Из полученных оттуда товаров мы выбираем те, у которых нулевые остатки, после чего выбираем несколько товаров, которые наиболее близки пользователю. Их мы врезаем на некоторые позиции в выдачу от прокси. Получается такая композиция из двух поисковых движков.
Руководить этой дружной когортой помогает один из сервисов клиентского бэкенда. Это сервис, который взаимодействует с фронтендом, предоставляет клиентское API и содержит некоторую логику построение каталога, походов в поисковые движки и прочее.
В эндпоинте поиска в зависимости от конфига выбирается поисковый движок, в которой мы идём с различными настройками и параметрами. Также тут есть логика фолбэков поисковых движков в зависимости от их работоспособности. После получения результатов от движка выдача фильтруется по различным признакам, например, по остаткам, дарксторам (если движок не поддерживает) и доступности. И, собственно, дополняет готовую выдачу информацией, необходимой клиенту для отображения товара пользователю.
Какие же проблемы у нас бывают сейчас? Иногда мы получаем обращения, что новинки не доезжают в поиск. Здесь всегда стоит в первую очередь посмотреть, как давно товар появился: бывает, что он появился пару часов назад и у него просто не было времени прорасти в индекс.
Ещё из проблем, которые можно было встретить — дублирование категорий в поисковой выдаче.
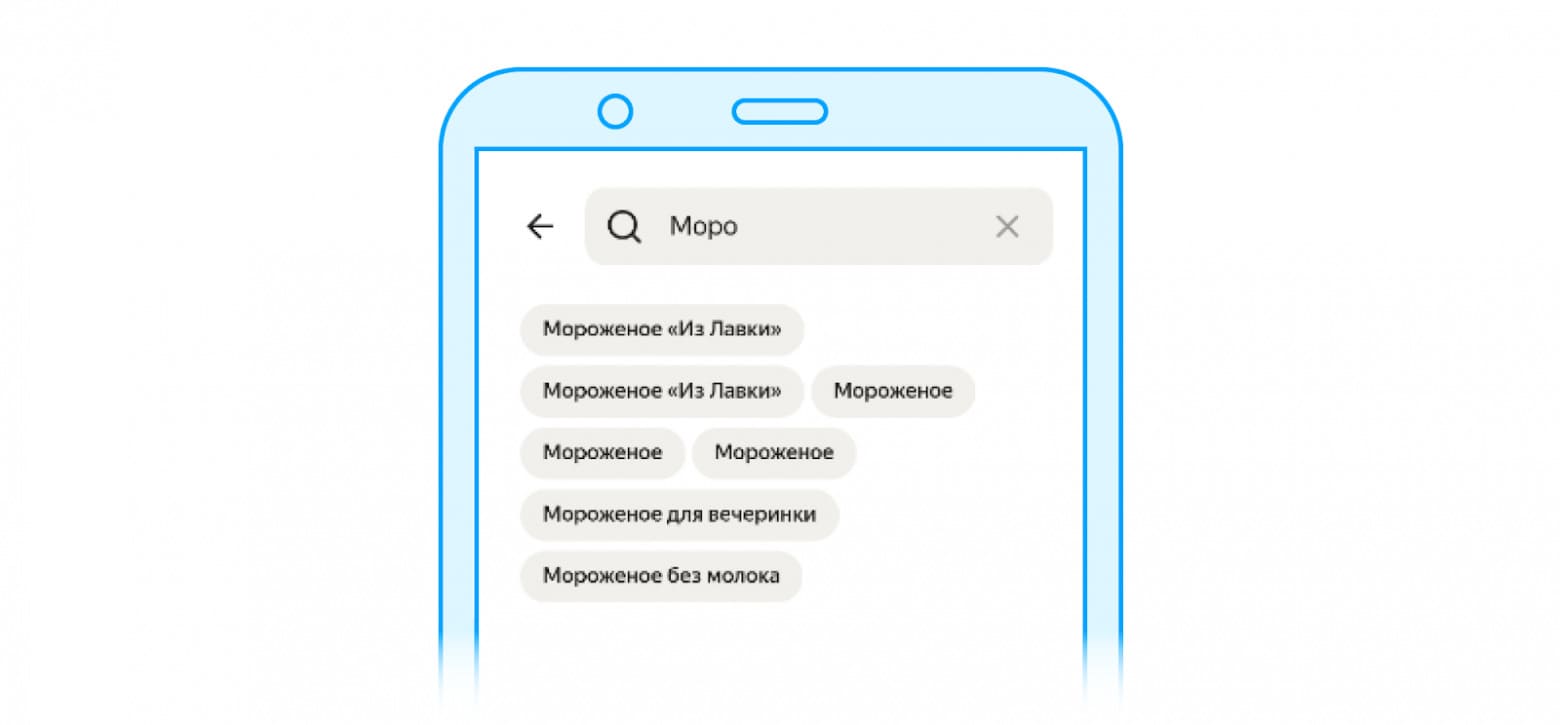
На самом деле тут вы видите не категории, а подкатегории — составные части категорий. Бывает так, что в нескольких разных категориях в каталоге встречаются подкатегории с одним и тем же именем. То есть, если пользователь кликнет на первое «Мороженое "Из Лавки"» и на второе «Мороженое "Из Лавки"», он попадёт в разные подкатегории с точки зрения каталога, потому они будут с разным наполнением. Но пользователю это не сильно понятно: он видит два одинаковых названия и думает: «Мне показали одно и то же». Эту проблему мы поправили.
Несмотря на то что поиск со своей задачей справляется, местами всё же возникают вопросы с точки зрения качества. Тут есть ещё возможности для развития, например, с точки зрения новых ранжирующих моделей, так и с точки зрения отдельных подходов и компонент (например, переводов).
Что мы получили в итоге:
- У Лавки есть своя e-com специфика, которую стоит учитывать при получении корректной поисковой выдачи: например, склады и наличие товаров на них.
- У нас одновременно работает три поисковых движка:
- Самописный алгоритмический internal, который быстро обновляется и умеет эффективно отдавать результаты. При этом у него есть проблемы с качеством в силу своего подхода к решению задачи поиска. Несмотря на это, его всё же можно считать хорошим фолбэком на случай непредвиденных ситуаций.
- Полнотекстовый движок SaaS, у которого есть множество точек для кастомизации. Он успешно работает для поиска категорий, но при этом не учитывает нашу специфику.
- Маркетный репорт с прокси, который наиболее близок нам по бизнесовым требованиям. У него хоть и есть некоторые проблемы с качеством выдачи в силу наших решений, чтобы подстроить его под лавочную специфику (эти проблемы совсем другого уровня, нежели у internal), тем не менее он хорошо справляется с основной задачей — находить нужные пользователю товары.
С точки зрения поиска у нас всё-таки не самая обычная история: как минимум потому что у нас сразу несколько поисковых движков. Да, поддерживать сразу три — сложнее, чем один. Работать с двумя из них в целом непросто: мы не владеем этими движками и иногда повлиять на некоторые доработки довольно сложно. Однако это даёт нам гибкость при решении различных задач, устойчивость во время поломок и, возможно самое важное — экономию времени на то, чтобы сделать Лавку действительно удобной.
Возможно, если у вас похожий кейс, не стоит стремиться покрыть всё одной технологией, а, при наличии ресурса, попробовать использовать несколько технологий для различных частей одной крупной задачи бизнеса.



