
С момента прошлого релиза фреймворка 🐙 userver для С++ прошло чуть больше полугода. За это время мы многое сделали:
- сильно оптимизировали работу фреймворка и обогнали основных конкурентов в бенчмарках высокопроизводительных фреймворков;
- значительно упростили конфигурирование;
- обзавелись
install, докер-образами, Yandex Cloud-образом и DEB-пакетами; - обросли новой функциональностью, включая серверные мидлвари для HTTP, и YDB-драйвером;
- перешли на новую ежемесячную схему релизов и упростили версионирование.
Топ-15 в Techempower
За полгода работы мы оптимизировали многие части userver и поднялись в топ-15, обогнав многих очень именитых ребят.
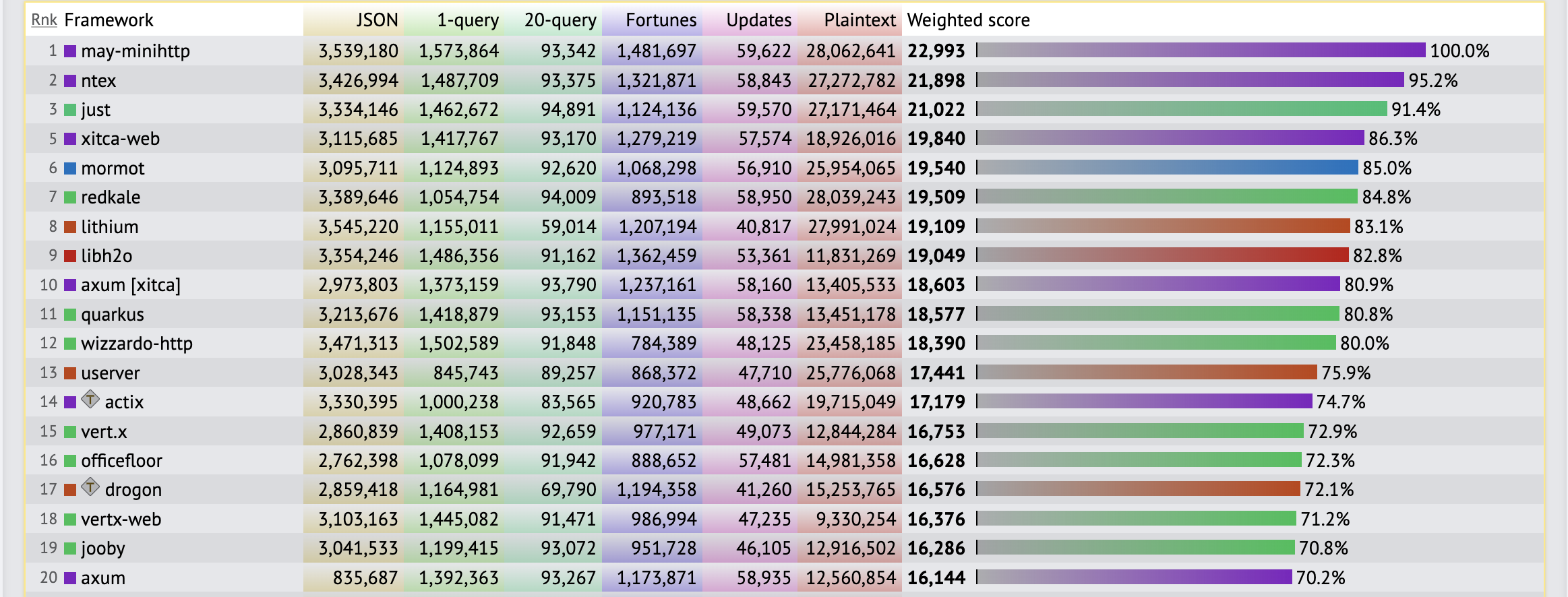
И даже в этих синтетических бенчмарках, не имеющих ничего общего с продовыми решениями, мы продолжаем переживать мигания сети (в отличие от большинства из топа), падения и восстановления баз данных, а код на userver остаётся понятным и линейным, без «лапши» из колбеков.
Нас так и распирает рассказать о некоторых креативных оптимизациях, так что…
Тайные возможности PostgreSQL протокола
Когда клиент общается через libpq с сервером PostgreSQL, то на каждый запрос на выполнение SQL библиотека libpq запрашивает (D)escribe для этого запроса. В результате сервер отправляет данные по именам полей и прочую служебную информацию. Подобные данные могут занимать более половины размера ответа сервера, если запрос возвращает множество колонок и малое количество строк.
🐙 userver с первых версий прозрачно для пользователя превращает все запросы в Prepared Statements и шлёт на сервер только аргументы запроса в бинарном виде (libpq использует менее компактный текстовый вид). Это позволяет экономить сетевой трафик, а серверу выполнять запросы чуть быстрее.
В версии 2.0 механизм был улучшен: теперь кешируется и (D)escribe запроса, а сами запросы на сервер идут без запроса метаинформации. В результате сетевой трафик экономится до двух раз, а CPU-нагрузка на сервер и клиент снижается.
Сейчас мы предлагаем соответствующие расширения в libpq, чтобы все фреймворки и библиотеки, использующие эту библиотеку, могли воспользоваться улучшением.
Расширенный контроль над PostgreSQL pipelining
PostgreSQL-протокол позволяет склеивать несколько запросов в один сетевой поход. Мы этим пользовались, начиная с версии 1.0. В результате если в коде приложения делается три SQL-запроса: на начало транзакции (BEGIN;), выставляются таймауты и делается SELECT/INSERT — в сервер базы данных улетит один запрос, а два сетевых похода сэкономятся.
В TechEmpower-бенчмарке есть ситуации, когда делается множество SELECT-запросов подряд. Для таких случаев во второй версии userver мы предоставили класс storages::postgres::QueryQueue.
Оптимизация машинной инструкции lock add
Переходим к очень низкоуровневым вещам. В процессорах есть атомарные инструкции — неделимые операции над памятью. Например, если вы хотите подсчитать количество обрабатываемых сервером запросов на данный момент, то где-то должна быть атомарная переменная, а каждый новый запрос должен её модифицировать:
std::atomic<std::size_t> requests_count{0};
void DoProcess(const Request& request) noexcept;
// Вызывается конкурентно из множества системных потоков
void Process(const Request& request) {
++requests_count;
DoProcess(request);
--requests_count;
}
Атомарные инструкции — это самый базовый низкоуровневый примитив. На них и системных вызовах строится большинство высокоуровневых примитивов синхронизаций — мьютексы, семафоры, cond var, RCU и т.п.
Вот только на большой нагрузке эти инструкции начинают тормозить. Невинный ++requests_count; превращается в lock add машинную инструкцию. И если разные ядра процессоров попытаются одновременно выполнить её, то фактически они выстроятся в очередь и будут выполнять её последовательно. В результате, некоторым ядрам CPU не повезёт: они будут терпеливо ждать, пока другие ядра работают. На больших системах при специфичной загрузке подобные инструкции могут приводить к микросекундным задержкам.
Хороший фреймворк должен предоставлять пользователям различную информацию о своём состоянии, чтобы можно было быстро находить проблемы на проде и диагностировать множество проблем. У нас в userver много метрик… очень много метрик. И большинство из них — атомарные операции. Вот только на наших скоростях и нагрузках, затраты на атомарные операции видны в анализах производительности (перфы и флейм-графы).
И тут на помощь приходит RSeq. Можно заставить систему завести по обычной переменной на каждом ядре процессора и сделать так, чтобы ядра обращались только к своей переменной или фолбечились на атомарную в случае неудачи. Как ни странно, такой подход даёт выигрыш в производительности даже на одном ядре, уменьшая цену инкремента переменной с ~4.42 ns до ~1.67 ns. На множестве потоков эффект более ощутимый: можно превратить 411 ns на 64 потоках в 7 ns.
Все желающие посмотреть код, или даже воспользоваться подобным механизмом в своём проекте, прошу в исходники userver.
Прочее
Разумеется, это не все оптимизации — обо всём в рамках одной статьи и не рассказать. Мы используем coarse-часы, у нас есть множество трюков для ускорения работы исключений (об этом даже будем рассказывать на C++ Russia), применяем техники из рендеринга изображений для создания примитивов синхронизаций, используем асимметричные fence, позволяем компиляторам строить для нас контейнеры (например, есть рассказ о utils::TrivialBiMap) и делаем много всего другого интересного.
При этом идёт работа и по уменьшению потребления оперативной памяти. За полгода мы смогли уменьшить потребление памяти для некоторых типов нагрузки на сотни мегабайт. Замеры пользователей в чатике поддержки показывают, что мы потребляем в 4 раза меньше CPU и чуть меньше оперативной памяти, чем аналогичный сервис, написанный на Go-lang.
Упрощение конфигурирования
Конфигурирование современных систем — весьма мудрёная задача. Многие серверные конфиги могут занимать несколько экранов и быть раскиданы по множеству файлов. Мы не исключение.
Но зачастую можно найти хорошие дефолты, подходящие большинству приложений, или даже полностью убрать проставление параметров, вычисляя их на лету.
В userver 2.0 мы проделали большую работу по упрощению. Размеры туториалов сократились практически вдвое за счёт упрощения конфигурации:
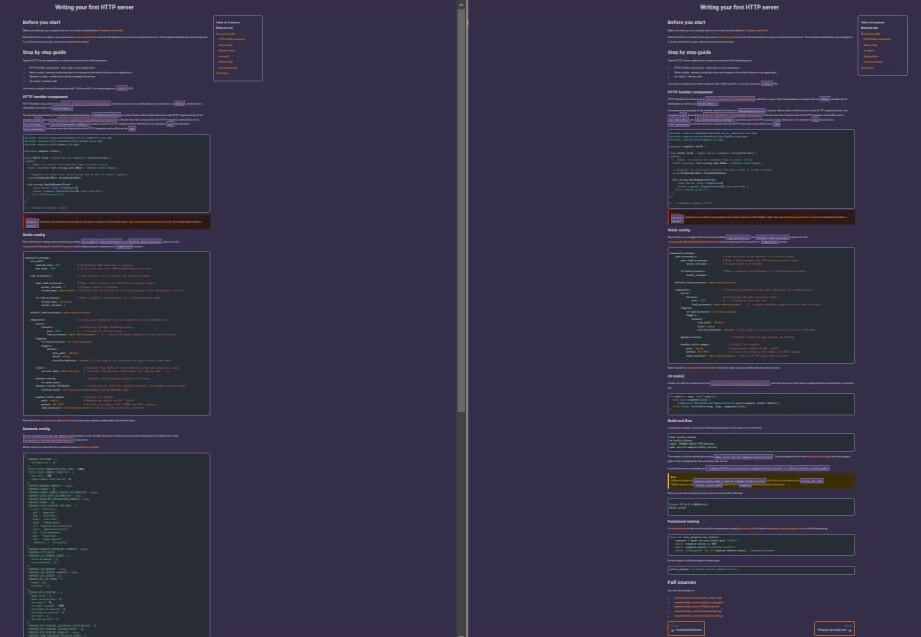
Самое значительное изменение — переработка динамических конфигов. 🐙 userver позволяет создавать конфиги, которые можно менять на лету без рестарта сервиса. Как правило, подобные динамические конфиги используются как рубильники для экстренных случаев, содержат таймауты для различных ручек и запросов или используются как включалки/выключалки экспериментальной функциональности.
Во фреймворке полно подобных конфигов и часто добавляются новые. При этом дефолтные значения, как правило, подходят всем, и их изменение не требуется при прототипировании решений или невысоких нагрузках.
В итоге у переработанных динамических конфигов теперь есть зашитые в коде дефолты, которые можно посмотреть из командной строки. Ушла необходимость в отдельном файле фолбеков, а соответственно, и упростились все сервисы-шаблоны (пример).
Docker, install, .deb и Yandex Cloud
Первая проблема, с которой сталкиваются разработчики на C++ при использовании любого фреймворка, — проблема сборки. Десятки компиляторов и операционных систем, сотни флажков сборки, тысячи версий зависимых библиотек… и в результате поставить нужные зависимости и собрать проект — весьма нетривиальная задача.
Чтобы упростить нашим пользователям жизнь, за полгода мы добавили возможности собирать пакеты для дистрибутивов, поддержали скрипты установки и сделали уже готовые для разработки образы:
ghcr.io/userver-framework/ubuntu-22.04-userver-pg:latest— образ с предустановленным фреймворком, расширенным набором разработческих репозиториев и сервером PostgreSQL. Другими словами — всё, что нужно для сборки, отладки и прототипирования. Все сервисы-шаблоны переведены на этот образ, а образ пересобирается еженедельно со свежей версией userver.ghcr.io/userver-framework/ubuntu-22.04-userver-base:latest— образ со сборочными зависимостями. Для тех, кто предпочитает подключать userver как поддиректорию в CMake.- userver at Yandex Cloud Marketplace — возможность создать виртуалку с userver в Облаке в пару кликов. Для тех, кто предпочитает разрабатываться на мощном облачном железе.
Новая функциональность
За полгода многое во фреймворке стало ещё лучше.
Драйвер для PostgreSQL научился автоматически вычислять количество соединений для данного пода в кластере и теперь не требует сложной конфигурации в большинстве случаев. Появилась поддержка LISTEN/NOTIFY для подписки на события и нотификаций через базу данных PostgreSQL.
Во многих местах фреймворка дополнительно улучшена диагностика, чтобы сделать разработку ещё проще и понятнее. Добавлено множество документации и примеров, многие части фреймворка разнесены по отдельным мидлварям для более гибкого конфигурирования. Огромное количество новой функциональности, landing page, багфиксов и улучшений было добавлено внешними контрибьюторами, за что вам огромное спасибо! Вы лучшие!
Кстати, userver обзавёлся драйвером для YDB и альфа-версией драйвера для Kafka! Что плавно подводит нас к следующей теме…
Релизный цикл и дальнейшие планы
Мы осознали (по подсказке наших пользователей), что релизиться раз в полгода — неудобно, а semver из трёх частей — немодно и непрактично. Поэтому мы планируем делать релизы практически ежемесячно. Скоро выйдет 2.1, затем 2.2… А ещё через полгодика изменений накопится достаточно много, чтобы выпустить релиз 3.0.
Разумеется, работа над фреймворком продолжится. У нас много пользователей, в том числе за пределами Яндекса, и даже за рубежом. Мы видим, что фреймворк людям интересен, а это мотивирует продолжать дальнейшую работу.
В ближайших планах — доработать Kafka-драйвер, значительно расширить документацию по Kafka и YDB, улучшить tutorial. Также на подходе кодогенерация из JSON схем в С++ парсеры, сериализаторы и структуры. И у нас есть идеи и по дальнейшему улучшению производительности.
На этом пока всё, до новых встреч!





