
Всем привет! Меня зовут Саша Фишер, я руководитель службы надежности Яндекс Такси. В статье расскажу про инструменты, которыми мы обеспечиваем бесперебойную работу сервиса, в том числе при повышенных нагрузках и в сезонные пики.
Высокий сезон — время, когда нагрузка может повышаться в несколько раз. Конечно, самый топ — Новый год. Это период с 22:00 31 декабря до 3:00 1 января. Чтобы пережить эти пять часов, мы готовимся весь год. Кстати, в период с 1 по 6 января — наоборот, всё гладко и тихо. Но кроме Нового года, в декабре есть и другие часы повышенной нагрузки — так называемые корпоративные пятницы. Это последние три пятницы декабря с 17:00.
Как устроено Такси
Прежде всего, Яндекс Такси — это инфраструктура городов, в первую очередь миллионников. Такси — такая же часть транспортной доступности в городе, как троллейбусы и метро.
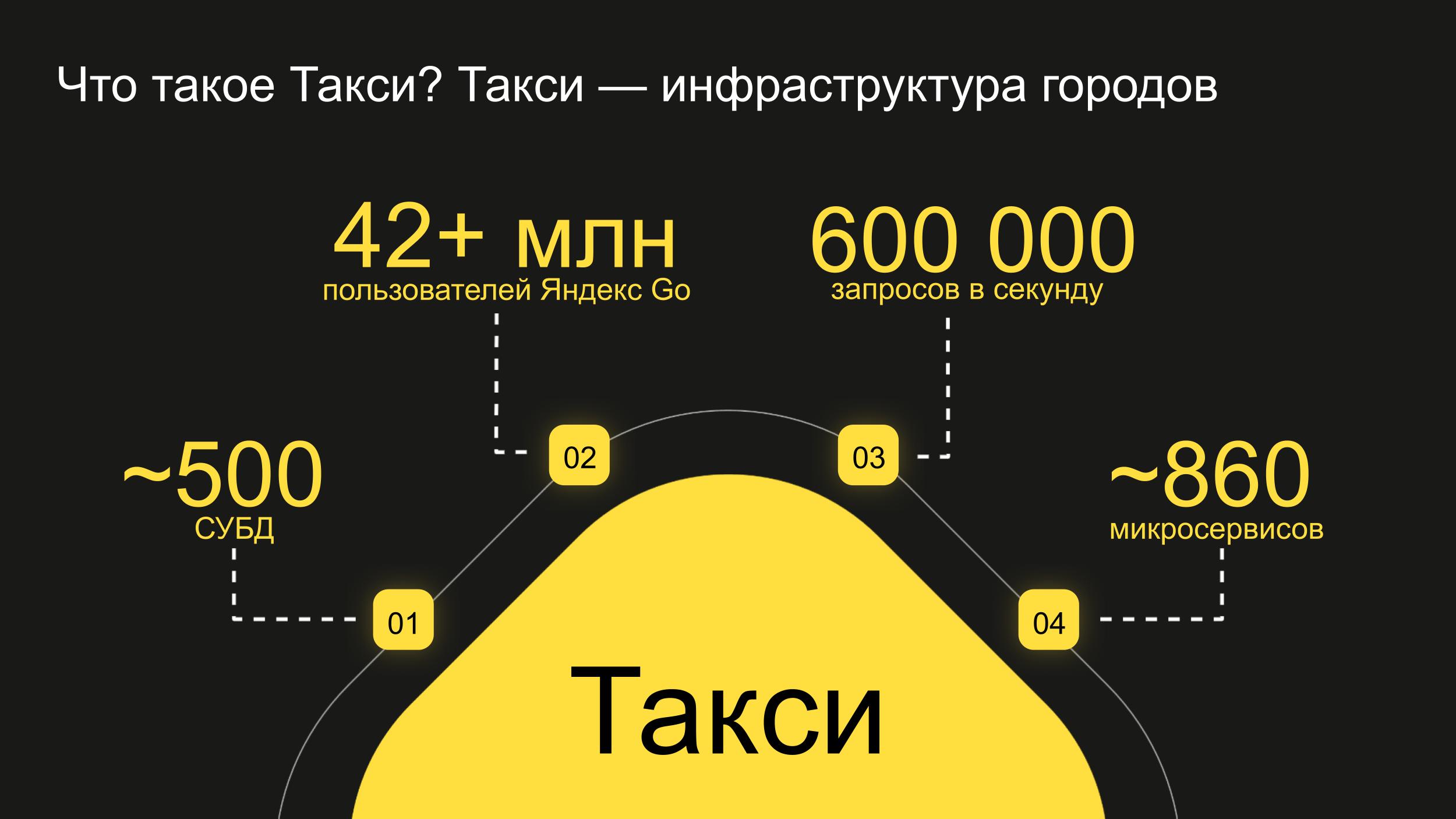
У нас микросервисная архитектура: больше 800 микросервисов и 500 баз данных. 90–99% нашей инфраструктуры размещено в облаках. На точках входящего трафика RPS примерно 600 тысяч.
Наши языки и фреймворки:
- userver (С++) — фреймворк сердца Такси, внутри него большой запас надежности и отказоустойчивости;
- FastCGI2 (C++) и py2 (Python) — legacy-фреймворки, которые не развиваются, мы туда ничего не пишем;
- backend-py3 (Python 3) — живой фреймворк;
- Goliath (Golang) — будущий фреймворк на Golang, который мы планируем массово внедрять;
- MJ Kotlin — потенциально возможный фреймворк на Kotlin.
Метрики надежности
Чтобы что-то улучшить — это нужно измерить. А чтобы что-то измерить — нужно понимать, что и как мы измеряем. У нас 4 основных метрики:
1. Availability SLO (Service Level Objective)
Все, кто работал с надежностью и SRE, знают про четыре девятки. Есть сервисы, у них есть рейт успешных запросов, мы его замеряем — это и есть девятки. Не буду обманывать, что четыре девятки у нас везде, но мы к этому стремимся.
2. MTTR (Mean Time To Recovery)
Первая специфическая метрика — среднее время восстановления, то есть сколько времени за инцидент мы в среднем лежим. Или не лежим, но значительно деградируем.
В инцидент-менеджменте все случаи сбоев прокрашиваются статистикой, мы делим их на мажорные и минорные. Лежали полчаса и больше — мажор. Лежали всего пять минут — минор. К мажорам и минорам разное отношение, у них разные процессы инцидент-менеджмента и приоритизация. Если клиент не может заказать такси в течение пяти минут, он перезакажет его через шесть минут и уедет — столько можно подождать. Если же такси везде не работает час — это серьезная проблема, причем на уровне города. А так как Яндекс Такси — провайдер сервисов для Яндекс Доставки, Яндекс Лавки и так далее, негативные последствия мультиплицируются.
Фокус на метрике MTTR мотивирует нас быстро подниматься. Fail fast: упали — отжались — поднялись.
3. MTTRC (Mean Time To Root Cause)
Среднее время нахождения корневой причины. Во-первых, по этой метрике мы понимаем, насколько хорошо у нас работает observability. Если корневую причину находим быстро — observability хорошее. Если не так быстро — плохое.
В пятидесятом перцентиле метрика равна 7 минутам. То есть 7 минут — медиана нахождения корневой причины по мажорным инцидентам примерно с июля 2023 года. Но в девяностом перцентиле — это примерно тридцать минут! Наша цель — сократить нахождение корневой причины в девяностом перцентиле до трех минут.
4. ROCOF (Rate of Occurrence of Failures)
Последняя метрика — количество инцидентов. Она показывает, насколько хорошо мы сделали свою домашку. Если мы проактивно поработали над причинами инцидентов — они не произойдут и метрика улучшится.
Не поверите, но метрики сложно улучшать... из-за сложности. Когда у тебя 860 микросервисов, а тут внезапно происходит инцидент — нахождение причины и починка выглядят примерно так:

Дальше я расскажу про инструменты, которые либо упрощают эту сложность, либо помогают нам ориентироваться в нашей развесистой микросервисной архитектуре.
Инструмент 1: хаос

У нас в команде надежности есть специальные люди, которых мы называем «хаоситы». Рекомендую посмотреть их доклад с Яндекс Go Infra Meetup #2: «Сломай меня полностью. Chaos Engineering». Его авторы Максим Ивашковский и Андрей Матвеев — те программисты, которые этот хаос и писали.
Чего мы достигаем, создавая хаос:
- находим критичные сервисы;
- находим неявные зависимости между некритичными и критичными сервисами;
- тестируем согласованность тайм-аутов в цепочке сервисов;
- увеличиваем знание о поведении системы при ошибках.
Наш хаос — не классический вариант Netflix, который выключает pod или сервер. Он делает fault и error injection. У нас больше 800 сервисов, и мы хотим знать, какие из них действительно критичны.
Например, у нас есть микросервис, который показывает цвет машины такси, когда вы открываете приложение. Казалось бы, он некритичный, но как в этом удостовериться? Угадать невозможно, и не надо — поручите это хаосу. Когда в сервисе включаются тайм-аут или пятисотки, можно выяснить, насколько он влияет на поведение пользователей и водителей.
На текущий момент у нас три базовых сценария хаоса:
- Управляемое замедление сервиса — такое, чтобы он укладывался в deadline propagation timeout.
- Имитация метастабильного состояния. Метастабильное состояние — это когда ваша система была так неустойчива, что для ее падения хватило одной соломинки, и после падения она не поднимается. Трафик приходит, но система не восстанавливается, уже не выдерживает.
Смотрите доклад, чтобы узнать больше о метастабильных состояниях
Мы смотрим, как вся система себя поведет. Есть, например, микросервис, который отдает кандидатов на заказ: пассажир заказал такси, и сервис под него находит двадцать водителей. Что будет при отказе этого сервиса? Система не будет работать. - Отдача от имени сервиса 500. При этом мы умеем управлять процентом отдаваемых 500-x ошибок, например пишем в конфиге хаоса: пусть 1% всех запросов отдает пятисотки.
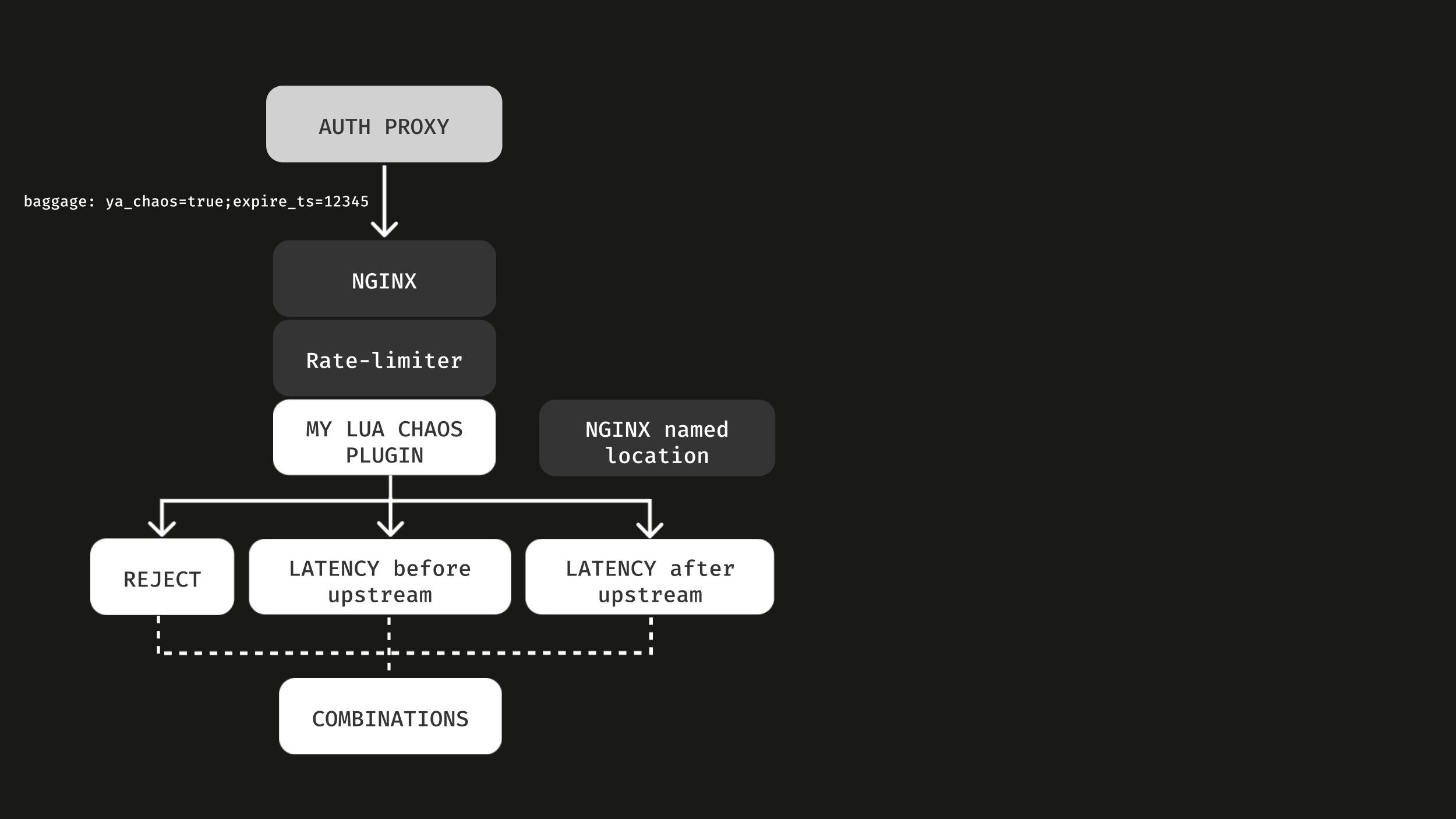
Это то, как хаос реализован технически. Есть авторизационный прокси, через который мы прокидываем контекст с помощью HTTP-заголовка baggage (это стандарт W3С) и включаем хаос.
Дальше работает наш плагин на Lua к nginx. Через него мы всё и делаем.
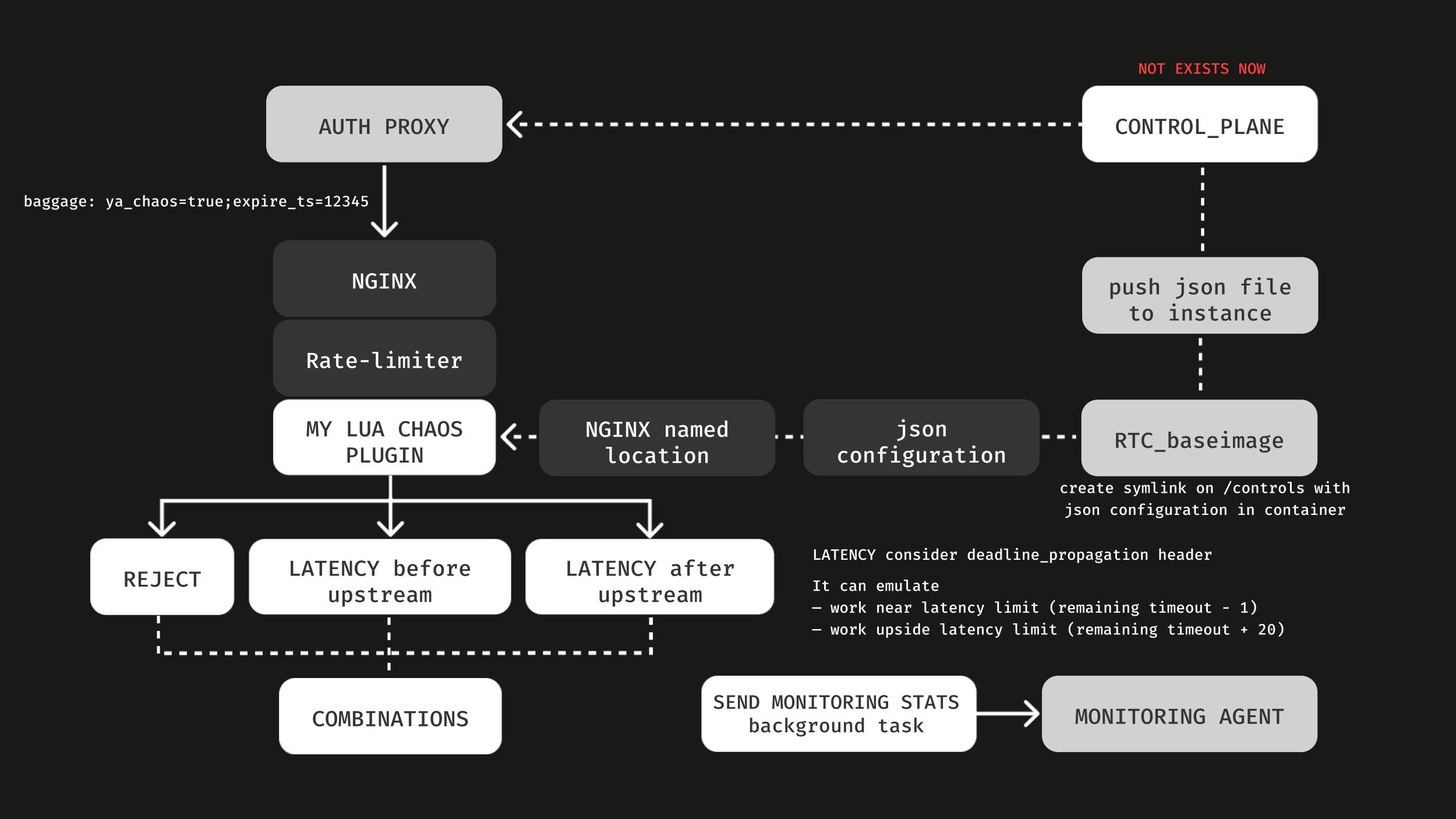
У нас есть подобие control plan, сейчас не оформленное никакой админкой: ни GUI, ничего подобного. Это система, которая кладет JSON-файл в каждый сервис в pod’ы в нашем облаке. В этих файликах написаны сценарии того, как и что делать. На схеме эта часть расположена сверху справа.
А справа снизу — observability. Мы посылаем статистику, чтобы знать, как у нас включен хаос, какие там метрики. Всё сделано просто.

Как мы планируем развивать хаос в 2024 году:
- создать сервис control-plane для настройки расписания и процентовки инъекций;
- создать админку для управления этими настройками и вручить ее командам сервисов, чтобы за учения каждого отвечала команда, которая его пишет;
- проводить регулярные учения с инъекциями по расписанию;
- делать иррегулярные инъекции по усмотрению владельцев;
- добавлять новые сценарии.
Инструмент 2: срезание нагрузки
Представим, что у нас произошли каскадные отказы: один сервис потянул за собой другой, и система сложилась, как карточный домик. Час пик, 18:00, пятница, вечер, 29 декабря. Мы вошли в метастабильное состояние: нагрузка идет не прекращаясь, и это не позволяет нам подняться. Мы хотим иметь рубильник, который срежет нагрузку достаточно, чтобы система заработала.
Degradation mode
Первый способ срезания нагрузки — деградация сервиса, так называемая graceful degradation, когда есть потребность именно снизить нагрузку.
Мы реализуем его так:
- отключаем анимацию поиска;
- отключаем мультизаказы (мультизаказ — возможность сделать сразу несколько заказов для разных точек и разных клиентов: ваших друзей, родных);
- отключаем в базе mongo write concern (MongoDB — наша главная БД);
- повышаем интервалы поллинга в разных частях;
- срезаем ретраи на критичных ручках;
- отключаем постановку части задач в очереди.
За счет выключения функциональности, которая не суперважна, мы делаем всё, чтобы облегчить работу сервиса. Главное — пользователь должен иметь возможность уехать.
Деградация может идти в двух режимах: мягком и тяжелом. На практике почти всегда при серьезном инциденте мы сразу включаем тяжелую деградацию и увеличиваем емкость примерно на 20%. Наша цель — +50%.
Retries, RPS limits

Второй вариант срезания нагрузки — управление ретраями — родился из амплификации. Когда система легла и вошла в метастабильное состояние, клиенты начинают ретраить запросы постоянно. Этим они создают амплификацию X10, при которой подняться уже невозможно: нет железа, чтобы выдержать такую нагрузку.
Ретраями нужно управлять, и управляем мы ими с помощью HTTP-заголовков. Причем они поддерживаются как на клиентах — то есть в Яндекс Go и в водительском продукте Яндекс Про, так и в ручках на бэкенде.
Есть четыре стратегии:
- После N-ного ретрая используется последний тайм-аут из списка.
- Exponential back-off, когда мы ретраимся с постоянным замедлением: 500 мс, 1000 мс, 2000 мс...
- Остановка после третьего ретрая (Retry-Action:stop).
- Полный запрет на ретраи (при жесткой деградации).
Есть и глобальная стратегия ретраев, и отдельные настройки в каждой критической ручке сервисов. Все наши 860 микросервисов разделены на тиры: A, B и C.
- Tier A — сервисы, без которых Такси не работает. Если лежит любой из этих сервисов — всё, такси конец, приехали.
- Tier B — сервисы, без которых мы можем поработать 15–20 минут. При инциденте они приведут к деградации бизнес-показателей и заказов не сразу, а минут через 20–30.
- Tier C — сервисы типа «Цвет машины». Если мы его отключим, то продолжим работать дальше.
Инструмент 3: виртуальные заказы
Виртуальные заказы — это не классическое нагрузочное тестирование. В классическом исполнении мы генерируем тысячу RPS в какой-то эндпойнт с каким-то HTTP::payload. Запускаем Apache Bench или Yandex Tank — и вуаля: мы создали нагрузку X10.
Но если система не монолит, а микросервисная — такая нагрузка не показывает ее емкость, не показывает взаимодействий между ее частями. И если ты нагрузил одну ручку — это совершенно не означает, что другая ручка выдержит у тебя этот X10.
Емкость в Такси — количество заказов в системе, причем количество заказов в разной стадии: предзаказы, поиск водителя, пассажир едет, пассажир завершает заказ. Все эти заказы живут внутри, и есть четкое количество, которое мы можем переварить. И виртуальные заказы тестируют именно емкость, нагрузку на всю систему.
При подготовке к высокому сезону у нас было всего 70 учений, из них 22 — учения виртуальных заказов. Мы нашли все слабые места: тут нет RPS-лимитов, здесь не хватает процессора, здесь сервис начинает пятисотить по неизвестной причине при нагрузке X2... Расставили таски, всё пофиксили. Снова запустили, снова дали нагрузку. И так двадцать два раза, чтобы Новый год прошел без сучка и задоринки.
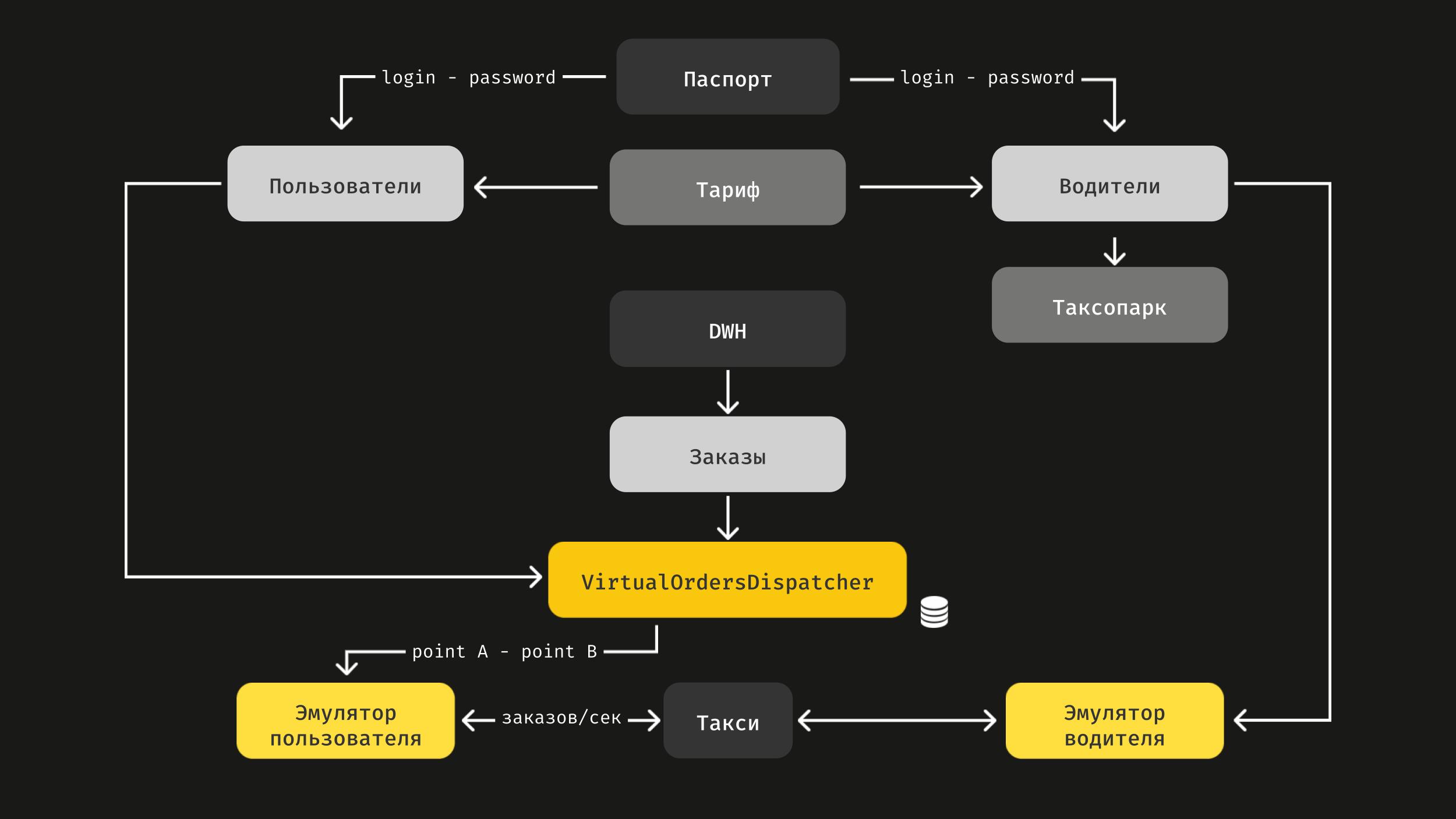
Выше схема реализации виртуальных заказов. Наша платформа соединяет людей, которые хотят уехать («Пользователи»), и людей, которые готовы их подвезти («Водители»).
Поэтому у нас есть симулятор водителей, где живут сгенерированные водители с именем и фамилией, например «Робот Давидович», и есть таксопарки, к которым эти водители привязаны. Есть виртуальные пассажиры и диспетчер, VirtualOrdersDispatcher, который соединяет их с водителями.
В схеме учитывается тариф. Разные тарифы дают разную нагрузку, потому что поиски Maybach и Kia Rio разные.
Итак, мы говорим системе: сгенерируй нам, пожалуйста, тысячу заказов в секунду. Сервис создает виртуальных водителей, которые едут по реальным историческим маршрутам, предзагруженным раньше. Они едут с реальной скоростью, например, по тарифу «Эконом», — скажем, 60 километров в час. А мы смотрим, как это работает.
Кроме этого, мы виртуально нагружаем еще и клиентские ручки. Скажем, в приложении вам сразу показываются цены. Эти цены — тоже нагрузка, потому что они рассчитываются для пяти тарифов сразу и складываются в базу, а это ее нагружает. Вы еще ничего не сделали, даже кнопку заказа не нажали, а произошло уже много вычислений, в которых поучаствовали двадцать микросервисов. Нагрузку на эти микросервисы мы таким образом и тестируем.
Инструмент 4: eventboard/observability
Eventboard — часть observability, это класс софта, который показывает все изменения на продакшне.
Видеть изменения важно, потому что до 50% инцидентов — последствия наших релизов. Мы выкатили какой-то конфиг или релиз, и стало хуже. Эмпирически определилось, что у нас имеет место rate of change: надежность обратно пропорциональна количеству изменений, которые мы внесли в систему. Если мы не видим эти изменения в удобном простом виде, их можно искать очень долго.

Посмотрим подробнее на observability. Это наш главный дашборд, классическая Grafana. У него простая цель — за десять секунд понять, где проблема. Все картинки иллюстрируют воронку заказов: созданные заказы, найденные водители, завершенные заказы... Главная метрика (по центру) — отношение назначенных заказов к созданным. 100% она достигает редко, но в норме всегда выше 90%.
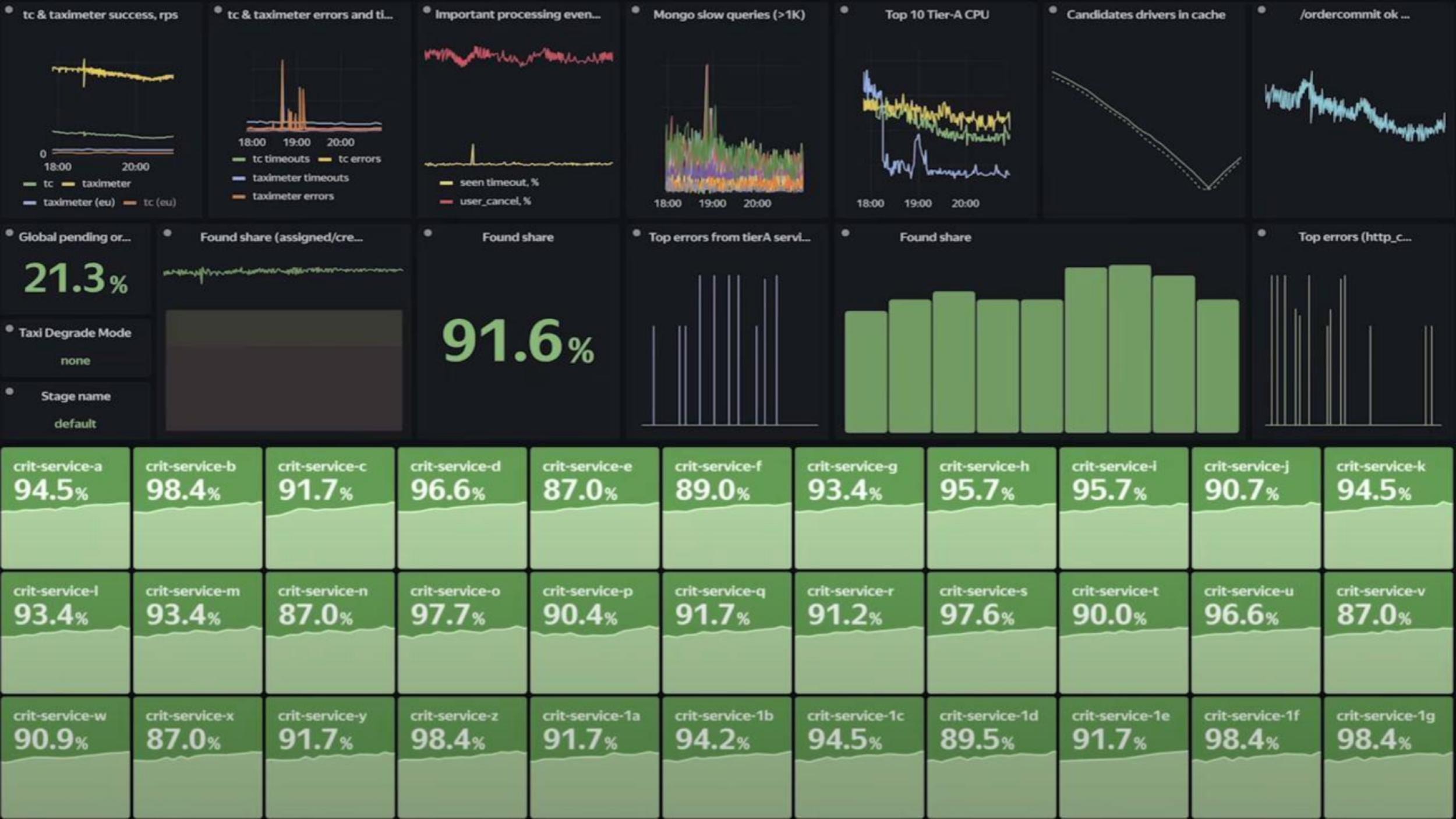
На картинке выше так называемый иконостас. Те самые 36 сервисов Tier A, без которых Такси не может работать, и их SLO. Если эти кубики желтенькие или красненькие, значит, что-то не так, пора чинить.

Eventboard — лента событий на продакшне. Кроме того, что мы видим события, у нас есть фильтры. Мы можем выбрать конкретные события и прямо отсюда включить режим деградации.
Справа от молнии есть кнопочка массового отката. Если мы считаем, что к инциденту могла привести любая выкатка, то откатываем всё в течение пяти минут во время инцидента, не рефлексируя. Это сильно сокращает нам время и улучшает метрику MTTR.
Инструмент 5: симуляции инцидентов
Есть и нетехнические средства обеспечения надежности. Инцидент-менеджмент работает, но у нас не так много происшествий, и это, что удивительно, нам мешает. Из-за нехватки инцидентов мы не всегда понимаем, что надо загодя чинить, где стоит проактивно копать, что нужно превентивно улучшить. Приходится создавать инциденты своими руками. Этим заняты две группы людей.
- Координаторы — люди, которые во время инцидентов в Такси распределяют задачи и управляют процессом. В основном это тимлиды разработки, которые отвечают за какой-то компонент: водителей, клиентов, эффективность. Это опытные разработчики, которые неплохо знают, как работает Такси, и у них есть представление о системе в целом.
- Группа SRE-эксплуатации. Люди, отвечающие, в числе прочего, за инфраструктуру. Есть интерфейс, где рандомный алгоритм выбирает, кто сегодня ломает Такси, а кому придется чинить. Симуляции происходят каждую неделю. Тот, кто чинил на этой неделе, ломает на следующей. Мы случайным образом выбираем одного координатора и одного SRE от эксплуатации, они всегда работают в паре.
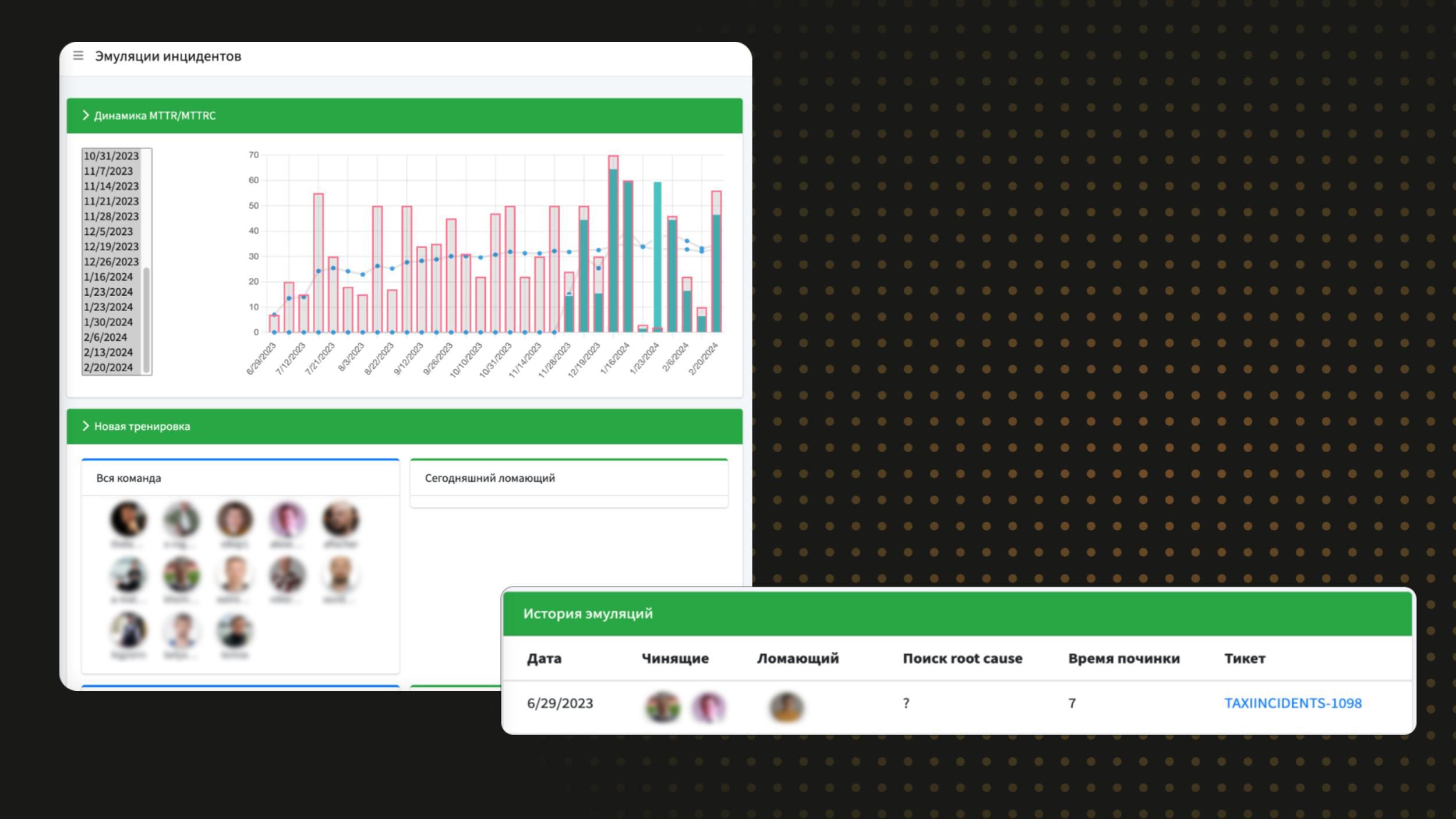
Когда человек что-то ломает, мы смотрим на метрики. График выше — динамика MTTR и MTTRC. Не очень хороший график, сейчас там среднее — примерно 30–40 минут, потому что в симуляции не прекращается гонка вооружений. Чем лучше наши инструменты observability, тем больше те, кто ломает, пытаются эти инструменты обойти или выключить.
Последние симуляции состояли в том, что человек сначала ломал инструмент, которым можно было поломку устранить, а потом доламывал остальное, чтобы усложнить процесс починки, иначе мы бы сразу это увидели, откатили, и оно починилось бы. Эта гонка вооружений позволяет нам совершенствовать инструменты.
Симуляция инцидентов — очень важный инструмент, который позволяет не потерять навык. Пусть у тебя не очень много инцидентов на проде, но ты тренируешься каждую неделю.
Инструмент 5½: Moonshots
Moonshots — венчурные проекты, в которые мы инвестируем и на которые делаем ставку, но мы не уверены, что они сработают. Потому что пока еще мы нигде не видели их в действии.
Autorecovery
В какой-то момент стало понятно, что есть предел скорости починки Такси человеком — примерно 10–15 минут с момента поломки. Человеку о поломке сообщил робот, сотрудник дошел до ноутбука, залогинился, посмотрел графики, нашел поломку, починил. 10–15 минут — число для топовых координаторов. В разгар рабочего дня можно управиться и быстрее, но в среднем это так. Получаем, что оптимизировать метрику MTTR, среднее время починки, невозможно, если мы делаем ставку на людей. Мы сделали ставку на робота, который принимает решение сам, — Autorecovery.
Некоторое время назад он доказал, что может работать неплохо. Сейчас он запущен в продакшне в dry run — говорит, что должен делать, но фактически ничего не делает, поскольку его действия — включение деградации. В боевом режиме он может откатить всё, и если сработает неверно — мы начнем деградировать направо и налево.
SreGPT
Второй инструмент — SreGPT. Он нужен для улучшения метрики MTTRC, среднего времени нахождения причины. Всё просто: мы хотим скармливать YandexGPT все наши метрики и логи, чтобы дальше нейросеть сказала: «С вероятностью 80% корневая причина проблемы — в таких-то базе, сервисе и конфиге».
Здесь мы на стадии очень-очень раннего RnD. Пока не могу сказать, сработает это у нас или нет, но глубоко убежден, что через пару лет это станет стандартом индустрии.
Резюмирую. Все описанные инструменты используют совершенно разные подходы и механизмы и оптимизируют разные метрики. При этом каждый из них помогает проходить пиковые нагрузки и обеспечивать круглогодичную надежность в каком-то стандарте. Надеюсь, за время чтения у вас уже возникли идеи того, какие из этих инструментов могут быть полезны именно вам.



