
Привет! Меня зовут Олег Табота, я руковожу командой общих компонентов в Яндекс Еде. Когда я решил рассказать, как устроена наша разработка изнутри, передо мной встала дилемма. Можно было бы составить подробный гайд по нашим 400+ микросервисам, описать пайплайны деплоя и структуру команд. Но такой обзор не передаст главного — как у нас на самом деле работается. Потому что технологии — это лишь инструмент.
Поэтому я выбрал другой путь. Я расскажу вам историю. Историю Иннокентия — нашего собирательного образа нового разработчика. Его путь за первые полтора месяца — это, конечно, не обязательная программа для всех, а скорее один из возможных маршрутов. Но он отлично показывает, как устроена работа в Яндекс Еде на самом деле.
Мы вместе с ним пройдём через наш буткемп, чтобы понять, как инженеры находят свою команду. Погрузимся в его первые задачи на Go и C++, чтобы увидеть наш стек в действии. А потом дойдём до самого интересного — его первого инцидента в продакшене. Потому что именно в такие моменты и проявляется настоящая инженерная культура.
Итак, всё начинается не с выбора конкретной команды или проекта, а с процесса онбординга.
Буткемп — найм в компанию, а не в команду
Как обычно происходит найм? Вы проходите собеседования в конкретную команду или на конкретный проект. Но что, если спустя месяц после выхода на новую работу вы вдруг поймёте, что задачи не такие уж интересные, как казалось, или отношения с командой просто не складываются? Для вас это ненужный стресс, а для компании — серьёзный риск того, что ценный специалист уйдёт, и придётся заново запускать весь долгий и дорогой процесс найма.
Мы решили пойти другим путём. Мы нанимаем разработчика не в конкретную команду, а в Яндекс Еду целиком. Этот процесс мы называем буткемпом.
На практике это выглядит так: Иннокентий, пройдя собеседования, становится полноценным сотрудником, но его первая рабочая цель — не написать код какой-то фичи, а найти «свою» команду. В течение нескольких недель он работает в разных командах — обычно по две-три недели в каждой. За это время он не просто знакомится с людьми и вникает в домен, а сразу погружается в рабочий процесс и берёт задачи из бэклога наравне с другими инженерами команды.
Главное здесь — двусторонний выбор. И разработчик, и команда в конце этого периода решают, подходят ли они друг другу. Такая система решает сразу несколько проблем. Кандидат получает команду, в которой ему будет по-настоящему комфортно и интересно. А команда — вовлечённого специалиста, чей осознанный выбор основан не на впечатлениях от собеседований, а на реальном опыте совместной работы над их задачами.
Мы ищем не просто разработчика на позицию, а человека, который найдёт у нас свою команду. Идеальное совпадение — это когда выбор делают обе стороны.
И вот наш Иннокентий попадает в буткемп. Но прежде чем он выберет команду и погрузится в её домен, ему предстоит познакомиться с общим технологическим ландшафтом Еды.
Первое знакомство — наш техрадар и микросервисы
В основе Яндекс Еды лежит микросервисная архитектура — сейчас у нас более 400 собственных сервисов, не считая интеграций с Такси и Лавкой. А чтобы помогать командам выбирать правильные и поддерживаемые технологии при создании новых сервисов, мы и ведём собственный техрадар.
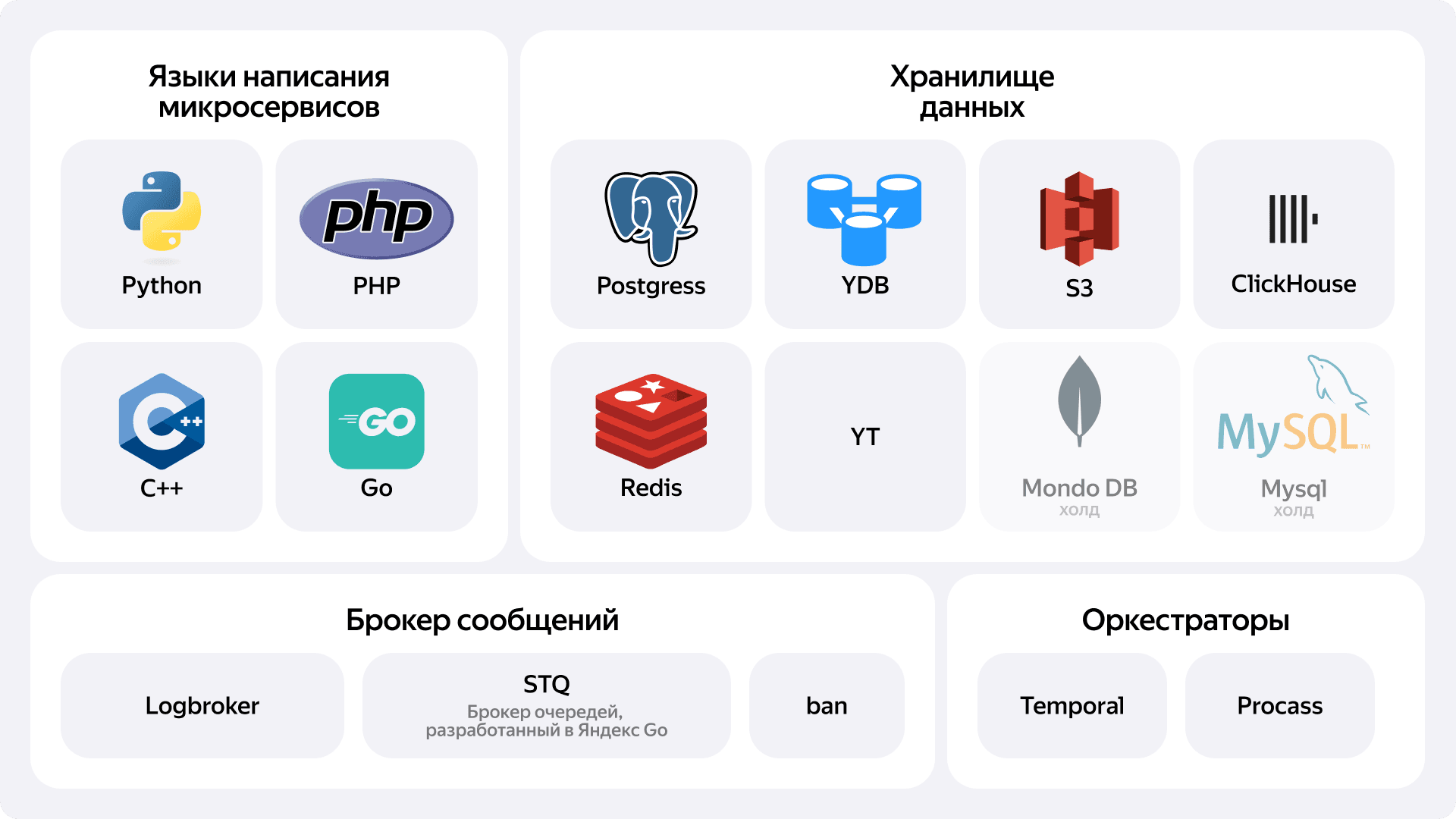
Вот несколько выдержек из него, которые помогут понять наш стек:
- Языки. Акцент в новой разработке делается на Go, на котором в данный момент написано около 40 сервисов, и C++ с более чем 200 сервисов. Именно здесь сосредоточена основная масса сложных и интересных задач. У нас также есть сервисы на Python и PHP, но они находятся в статусе hold. Это значит, что такие технологии мы не рекомендуем использовать в новых проектах. Мы не инвестируем в их развитие и оказываем минимальную поддержку, а у каждой команды есть долгосрочная цель переезда с них на аналогичное решение.
- Хранилища данных. Наш основной выбор — PostgreSQL. Также активно используем YDB, ClickHouse, S3 и Redis. В статусе hold находятся MongoDB и MySQL.
- Брокеры сообщений. Здесь у нас два основных инструмента: Logbroker и Stq — наш собственный брокер очередей, разработанный в Яндекс Такси.
Хорошо, а что представляет собой какой-нибудь из этих 400+ микросервисов? Среднестатистический сервис в Еде — это довольно компактный юнит:
- Около 10 эндпоинтов.
- Одна собственная база данных.
- Работает минимум на трёх подах в трёх разных дата-центрах, один из которых — канареечный.

Отправка логов и метрик, получение флагов экспериментов, конфигов или секретов — всё это берёт на себя сайдкар. Это избавляет разработчиков от необходимости реализовывать одну и ту же инфраструктурную обвязку в каждом сервисе и позволяет сосредоточиться на бизнес-логике.
Теперь, когда у Иннокентия есть общее представление о технологическом ландшафте, он готов сделать следующий шаг — выбрать несколько команд для более плотного знакомства.
Первые рабочие задачи
Понимая, какие технологии у нас используются и какие доменные зоны есть, Иннокентий выбирает несколько команд, которые ищут кандидатов.
Команда Интеграций (GoLang/Goliath)
Первая остановка — команда, которая занимается бесшовной API-интеграцией с нашими партнёрами. Их главная задача — в реальном времени понимать, какой ассортимент и по какой цене доступен в каждом заведении. Если мы дадим пользователю заказать товар, которого уже нет в наличии, мы можем получить отмену и негативный опыт.
Иннокентию достаётся, на первый взгляд, простая задача: получать от партнёров данные за 90 дней. Проблема в том, что их API отдаёт данные только за один день. Чтобы поддерживать актуальность, нам пришлось бы делать по 90 запросов в минуту на каждое заведение. А если партнёров много — это уже серьёзный трафик, который может быть воспринят как DDoS.
Почему бы просто не попросить партнёров доработать API? Реальность такова, что у нас сотни партнёров. Кто-то готов к доработкам, но это займёт месяцы. А функциональность нужна сейчас.
Иннокентий, пообщавшись с тимлидом, излагает свой план в RFC (Request for Comments — наш стандартный формат для обсуждения технических решений). Идея проста: данные в будущем не требуют такой же сильной актуальности, как данные за сегодня, поэтому их можно обновлять реже. Он предлагает завести Redis и кешировать ответы от партнёров, причём TTL кеша будет зависеть от давности запрашиваемых данных. После обсуждения и комментариев от коллег — например, о том, что время задержки должно регулироваться через динамический конфиг — Иннокентий приступает к разработке.
Его первый релиз проходит под присмотром ментора. Он собирает релиз, разворачивает его на канареечный стенд, 10 минут внимательно изучает логи и метрики и только после этого докатывает на продакшен. Хоть Иннокентий и катил релиз, но в релизе он не изменял текущее поведение сервиса, а просто выкатил какой-то логически законченный кусок кода. Еще несколько таких релизов, и пазл соберется, вся задача будет решена.
Спустя 3 недели, Иннокентий выкатывает свой последний PR и готовится включать фиче-флаг, чтобы новая функциональность заработала. Иннокентий включает его и снова наблюдает за системой. В этот раз всё прошло гладко — функционал получился хорошим и завёлся с первого раза.
Команда Логистики (C++)
Далее Иннокентий переходит в логистику. Эта команда отвечает за то, чтобы заказы доставлялись до конечного потребителя максимально эффективно. Здесь находится один из самых сложных доменов Еды, и ребята в основном пишут на C++ с использованием фреймворка userver.
Перед Иннокентием ставят задачу: помочь команде переключить создание заявок на новый эндпоинт. Старый и новый API сильно различаются: в новом гораздо больше полей, другой формат данных. Это сделано для того, чтобы уменьшить количество походов в смежные сервисы. Но как убедиться, что при переключении ничего не сломается? Как сравнить два совершенно разных контракта?
Иннокентий находит элегантное решение — свести всё к одной сущности. Он описывает DTO, который включает в себя все необходимые поля из обоих API, и дорабатывает код так, чтобы и старый, и новый эндпоинт заполняли этот единый объект. Теперь задача сводится к сравнению двух экземпляров одной структуры. Если они идентичны до момента логирования, значит, и дальше по коду всё будет работать одинаково.
Он запускает новый функционал в режиме DRY-RUN: система одновременно дёргает оба эндпоинта, но вызов нового прерывается сразу после записи лога. Собрав достаточно данных, Иннокентий выгружает их и проводит детальное сравнение структур. После нескольких итераций поиска и исправления расхождений команда уверенно запускает новую функциональность.
Решив задачи в двух командах, Иннокентий стал смелее. Он решил попробовать себя в команде роста, где его ждала задача иного характера — кросс-командная и затрагивающая сразу несколько сервисов.
Первый инцидент в продакшене
В команде роста Иннокентию доверили задачу посложнее — добавить новую, только недавно спроектированную механику применения скидок. Проект был масштабным: чтобы реализовать его, Иннокентию пришлось написать код в шесть разных сервисов, принадлежащих разным командам. Он написал около 4000 строк кода, создал 15 пул-реквестов и научился договариваться с представителями смежных юнитов.
При 400+ микросервисах вопрос не в том, случится ли инцидент, а в том, насколько быстро и слаженно мы на него отреагируем.
Когда все его пул-реквесты прошли ревью и были готовы к выкатке, Иннокентий приступил к последовательному релизу своих доработок в продакшен. Но в этот раз не везде удалось прикрыть изменения фиче-флагами, и процесс пошёл не так гладко, как предыдущие.
Звонок от системы мониторинга
Через 15 минут после начала релиза на телефон дежурного команды поступает звонок. Спокойный металлический голос произносит: «Количество заказов сильно упало по сравнению с недельным показателем. Если хотите остановить эскалацию, нажмите 5».
Это сработал наш инцидентный протокол. Одновременно с этим дежурного призывают в автоматически созданный телеграм-чат. Там уже есть ссылки на сработавшие алерты и ключевая информация: 15 минут назад был релиз сервиса А — того самого, который раскатывал Иннокентий.
Иннокентия тут же зовут в Zoom. Атмосфера напряжённая. Он нервничает, ведь откатывать релизы ему ещё не приходилось. Но рядом оказывается его ментор — он помогает собраться и найти нужную кнопку. Одно нажатие — и через пять минут релиз откачен. Заказы возвращаются в норму, но сервис заблокирован для новых выкаток, пока причина не будет найдена и устранена.
Анализ инцидента
Теперь Иннокентий тратит всё оставшееся рабочее время на анализ. Это не похоже на техническую поломку, ведь проблема затронула только часть заказов. Он начинает группировать упавшие заказы по разным срезам и довольно быстро находит закономерность: сбой происходил только с теми заказами, где применялась определенная скидка.
Дальше он фильтрует логи по тегам конкретных проблемных заказов, чтобы восстановить картину произошедшего. Он ищет ошибки уровня WARN или ERROR, но ничего не находит. Это наводит на мысль, что проблема не в падении сервиса, а в бизнес-логике. Иннокентий возвращается к своему пул-реквесту и вместе с более опытным коллегой начинает вчитываться в код.
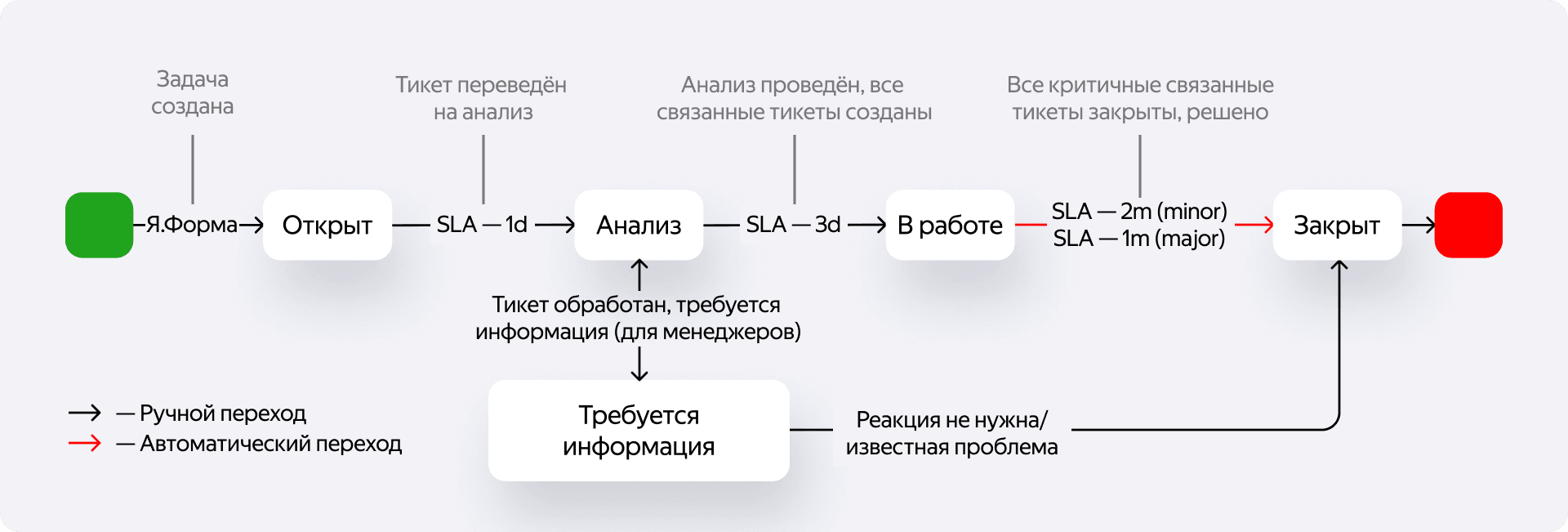
Вскоре баг находится. Код Иннокентия воспринимал весовые товары как штучные, из-за чего скидка считалась невалидной. Как следствие, заказ просто не создавался.
Теперь дело за малым: исправить баг, написать дополнительные тесты, покрывающие этот кейс, и… подробно описать произошедшее в инцидентном тикете. В редких случаях так бывает, что баг не отлавливают ни на ревью, ни в тестах, ни в тесткейсах тестировщиков. Чтобы такое происходило как можно реже, мы разбираем каждый инцидент придумывая действия, меняя подходы, реализовывая дополнительный функционал, или инструмент, чтобы исключить возможность возникновения подобных ошибок в будущем.
Разбор полётов — обязательная часть нашего процесса.
Чиним систему и процессы, а не ищем виноватых
По каждому инциденту у нас создаётся тикет на разбор. Цель этого процесса — не найти виноватого, а понять, что привело к проблеме, как сделать систему устойчивее и как в будущем реагировать на подобные сбои быстрее. Мы не ищем крайних — мы ищем пути для системных улучшений.
Иннокентий приступает к заполнению тикета. Первым делом он размечает инцидент как минорный, так как потери составили менее 15% заказов. Робот уже сделал часть работы за него — автоматически приложил к тикету всю переписку из инцидентного чата и транскрипцию звонка из Zoom. Это помогает легко восстановить хронологию событий.
Иннокентий описывает, как инцидент выглядел со стороны пользователя, и прикладывает хронологию действий, время срабатывания алертов и графики, на которых проблема была заметна. И тут он задумывается: а почему его вообще призвали в инцидент? Почему он, раскатывая релиз, сам не увидел проблему и не откатился?
Он возвращается к графикам, на которые его команда смотрит во время релиза, и понимает — на них действительно не было никаких аномалий. Это значит, что на их сервисном дашборде просто нет подходящего графика. Иннокентий идёт искать дальше и находит главный дашборд Яндекс Еды, где собраны все ключевые метрики продукта. Там падение было видно отчётливо.
Из этого простого наблюдения рождается первый Action Item: добавить в процесс релиза для всех команд обязательную ссылку на основной дашборд. Теперь релиз-инженер будет смотреть не только на графики своего сервиса, но и на здоровье всего продукта.
Второй Action Item касается тюнинга алертов. Звонок прозвенел только через 15 минут, хотя мог бы и раньше. Нужно улучшить трешхолды — но сделать это аккуратно, чтобы не получить постоянно флапающий алерт.
Иннокентий также отмечает в тикете и то, что сработало хорошо: причину нашли быстро, просто посмотрев на ленту недавних релизов, а решение «сначала откатываем, потом разбираемся» было принято моментально и без колебаний.
На самом разборе Иннокентий рассказал всю хронологию, причины и предложил свои экшен айтемы. После небольшого обсуждения команда согласилась, что идеи хорошие, но докинула ещё несколько:
- Написать приёмочный тест, который бы покрывал этот кейс с весовыми товарами.
- Доработать логи и метрику, чтобы в будущем было легче определить причину отмены заказа.
Инцидент был исчерпан. Но главное — он привёл к конкретным улучшениям, которые сделают нашу систему надёжнее.
Завершение
На примере Иннокентия я постарался показать, как выглядит разработка в Яндекс Еде глазами обычного программиста. Конечно, это очень урезанная версия реальности. Но история Иннокентия — это не просто рандомная последовательность задач и событий. Она наглядно иллюстрирует среду, которую мы стремимся создавать внутри.
С одной стороны — у нас действительно сложный и масштабный продукт. Сотни микросервисов, высокие нагрузки, непростые домены, где много работы именно для C++ и Go-разработчиков. Это та среда, в которой интересно расти профессионально.
С другой — мы выстраиваем вокруг этой сложности поддерживающие процессы. Продуманный онбординг, который помогает найти свою команду. Культура менторства, которая не даёт остаться один на один с проблемой. И, что самое важное, — зрелый и системный подход к инцидентам, где ошибка — это не повод для наказания, а точка для роста всей системы.
В такой среде можно браться за амбициозные проекты, не боясь, что один неудачный релиз перечеркнёт всю работу. Наш опыт показывает, что именно этот баланс — между сложностью задач и безопасностью процессов — и позволяет инженерам делать свою лучшую работу.
P.S. А ещё я стараюсь делиться опытом не только в статьях о работе. В своё свободное время я веду личный сайт, где публикую заметки о других своих проектах — от настройки веб-серверов до обзоров различных книг. Если вам интересно, заходите в гости.



