
Привет, я Лёша Остриков. Восемь лет я писал код, потом ещё семь — руководил разработкой. Моим прошлым большим проектом была логистика Яндекс Маркета — мы с ребятами с нуля построили треть всей системы. А потом я влюбился в AI-агентов. Сейчас я работаю в Городских сервисах Яндекса и помогаю другим бизнес-юнитам внедрять AI-проекты.
Весь прошлый год прокачивался в навыках создания агентов, разбирался и учил других как писать MCP-сервера, а в конце года поучаствовал в одном очень крутом соревновании, про которое и хочу рассказать. Но статья эта не просто про соревнование. Самое интересное в ней — про концепцию замкнутого цикла обратной связи в AI системах, которую почти не сговариваясь внедрили разные люди в конце 2025, получив на своих задачах просто удивительные результаты. Но об этом чуть позже.
А пока мы начинаем, вот парочка важных ссылок:
- рассказ про соревнование на YouTube — для тех, кто любит слушать, а не читать;
- пост в канале, где есть ещё много интересного про дивный новый мир, в который мы летим на всех скоростях.
Погнали!
Так что там за соревнование?
В ноябре 2025 года, создатель канала “LLM под капотом” Ринат Абдуллин запустил ERC3 — соревнование по построению AI-агентов. Представьте себе эмуляцию сложной корпоративной среды: у вас есть развесистая внутренняя API на пару десятков ручек — сотрудники, проекты, клиенты, тайм-трекинг. И вишенкой на торте — корпоративная база знаний, эдакая локальная Wiki.
Нужно было спроектировать AI-агента, который от лица пользователя мог бы решать произвольные задачи, которые в него прилетают. Приходит, например, юзер и говорит — «Хочу уменьшить зарплату своего босса на 50 тысяч франков, помоги». Агенту нужно проверить — кто это вообще пришёл, кто его босс и позволяет ли его уровень доступа творить такие фокусы (спойлер: конечно же нет!). А затем выдать ответ в строго определённом формате.
Узнать больше о мультиагентных архитектурах можно в материале «Интеграция года или как подружить Алису AI с Городскими сервисами»
Основная сложность была в том, что вся структура работы компании, допуски и правила были размазаны по файлам в Wiki. Сделать агента, который просто вслепую дёргает API, недостаточно — он должен был понимать бизнес контекст организации и следовать разрешенным политикам.
Часть 1. Наивный подход и ручной тюнинг
Как вообще пишутся агенты? Рецепт, казалось бы, давно известен. Для старта организатор соревнования любезно выложил пример агента, который набирал около 30% на подходе SGR (Schema Guided Reasoning). Я решил не усложнять себе жизнь более сложной логикой и пошел самым проверенным путём: собрал классического React-агента, у которого есть модель, системный промпт, тулы и агентский цикл.
В чатах некоторые ребята пытались решать задачи «снизу вверх», настраивая логику на небольших моделях вроде Qwen 3 и OSS 120B. Я же выбрал обратную стратегию:
- Берём самую мощную модель — в моём случае это был Claude Opus 4.5.
- Получаем максимальный скор за счёт сырого интеллекта LLM.
- Оптимизируем и спускаемся до условной gpt-oss-120b.
Спойлер: до третьего пункта у меня дело так и не дошло.
Архитектура первой версии была максимально бесхитростной. Я попросил Claude Code набросать простейший системный промпт на основе части кусков корпоративной Wiki, которые у нас были. Промпт получился крошечным и описывал только самые базовые детали.
Затем я взял все доступные пару десятков API-методов, среди которых были: поиск сотрудников, данные по проектам, тайм-трекинг и другие, и просто сделал список tools один в один. Как есть, без объединения текущих и написания кастомных тулов.

Собрал бота, подключил тестовый фреймворк, нажал кнопку запуска и ждал чуда… В итоге агент сдал ровно 1 задачу из 16. Причём самую простую, где скорее всего, случайно угадал ответ.
Стало понятно, что на базовом промпте далеко не уедешь. Быстро прикрутил логирование, добавил цепочки вызовов тулов и уровень ризонинга — о чём конкретно думает на каждом шаге, почему принимает те или иные решения. И начал итрерироваться, разбирая каждую задачу отдельно и исправляя логику под нее.
Теперь рабочий процесс выглядел примерно так:
- Открываю трейс очередного провального запуска.
- Сажусь в обнимку с Claude Code анализировать логи.
- Выясняю, что агент, например, вообще не учёл специфическое бизнес-правило или проигнорировал важную строчку из Wiki.
- Говорю ассистенту: «Давай запишем это ограничение куда-нибудь в системный промпт».
- Повторяю по кругу.
Мы начали продвигаться. Промпт постепенно обретал структуру: появились отдельные секции с правилами и примерами (few-shots), возникли блоки с патчами для инструментов. Я снова и снова запускал бенчмарк. Агент снова падал, но уже на следующем шаге. Я снова открывал логи. И так далее.

Задачи потихоньку закрывались, а скор медленно полз вверх. Но драйв от классной интерактивной песочницы очень быстро сменился ощущением унылой рутины. Я просто копался в текстовых файлах, пытаясь ювелирно встроить новое правило так, чтобы модель его поняла, не сгаллюцинировала и случайно не сломала старые инструкции.
Глядя на этот бесконечный цикл ручных правок, начало появляться чувство, что что-то фундаментально идёт не так.
Часть 2. Замыкаем цикл
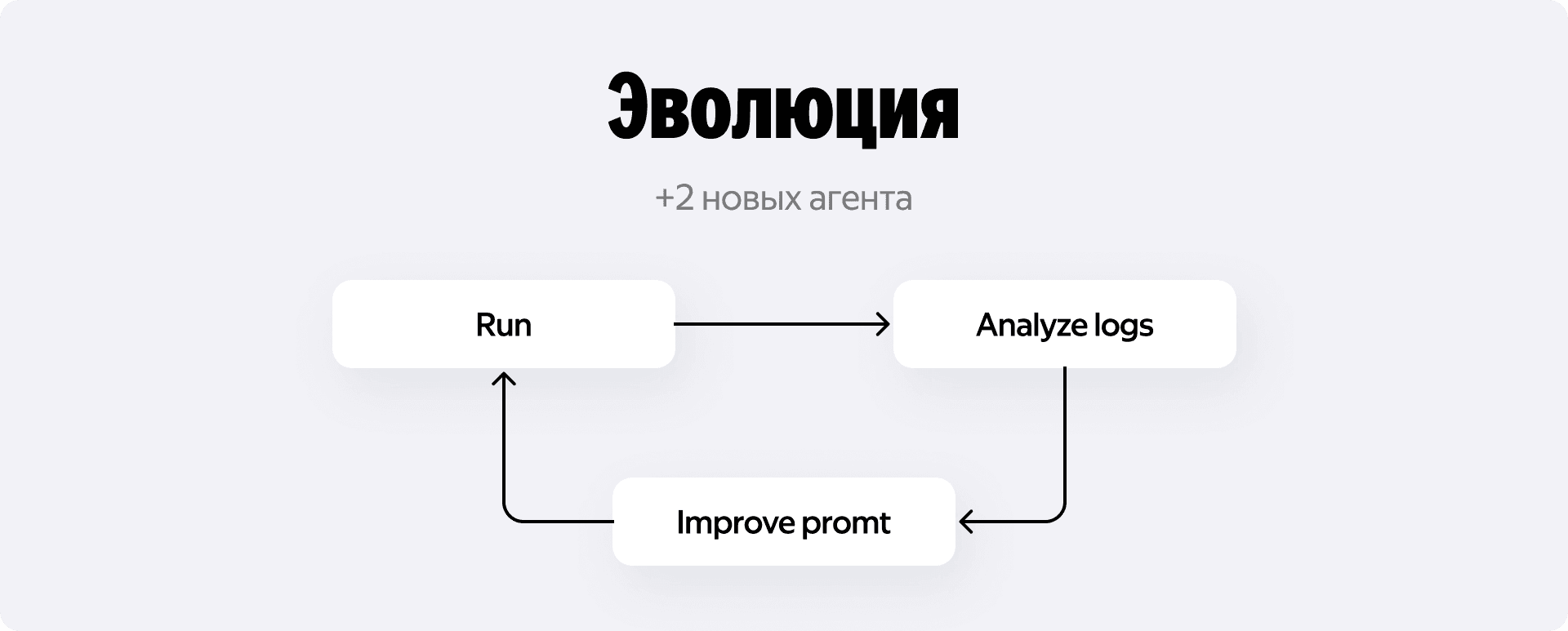
В какой-то момент, в очередной раз копируя кусок лога в чат с ассистентом, меня осенило. Весь рабочий процесс состоял из строго определённого, повторяющегося паттерна: запускаем задачу (run) → анализируем логи падения (analyze logs) → придумываем исправление (improve prompt).
Но погодите-ка. Мы же архитекторы AI-агентов. Если процесс можно разложить на части и попробовать автоматизировать, зачем делать это руками?
Беру и пишу двух новых агентов (ну как пишу, ставлю задачу и Claude Code пишет все это за 10 минут):
- Analyzer. На вход этот агент получал результаты выполнения тестов (eval_result) и секцию с неудачными попытками исправлений. Его задача — проанализировать трейс упавшей таски и выдать ответ в строгом JSON-формате. Внутри JSON он формировал поля root_cause (корневая причина провала), agent_mistake (что конкретно пошло не так) и missed_context (что агент упустил из Wiki). Но главное — он предлагал suggested_fix. Варианты исправлений были жёстко типизированы: добавить правило, пропатчить инструмент или добавить пример в промпт.
- Evolver. Этот дружочек брал выводы Анализатора, текущий базовый промпт и затем генерировал новую версию
И замыкаю всех трёх агентов в цикл: прогнать задачи, проанализировать логи, предложить улучшение промпта и по новой, пока не кончатся деньги на подписке.
Как только пайплайн был готов, я протестировал агентов, поправил баги, запустил скрипт и оставил его крутиться на полтора часа. Честно скажу: казалось, что идея гениальная, но на практике она с треском провалится. Был уверен, что система где-то зациклится или фундаментально сломается.
Но вместо этого - оно сработало.
Судя по логам, агент уверенно шаг за шагом проходил стадии эволюции. Иногда он ошибался: пытался вписать правку в rules, видел, что на следующем прогоне это не работает, делал откат и переносил логику в few_shots — прямо показывал на конкретном примере, как концептуально мыслить в подобной ситуации.
Конечно, процесс не был идеальным. Довольно быстро агент начал бездумно дописывать правила, и в какой-то момент их скопилось около сотни. Началось жуткое дублирование правил, инструкции стали противоречить друг другу. Систему пришлось дотюнивать: я научил Evolver’а компактизировать и дедуплицировать правила на лету.
За 80 поколений эволюции на бенчмарках система буквально выстрадала идеальный промпт. Оценки перестали флуктуировать: если у некоторых команд скор прыгал от 91% до 100% от запуска к запуску, то мой сетап консистентно выбивал сотку на тестовых бенчмарках. К концу цикла обучения системный промпт превратился в твёрдую собранную конструкцию весом около 5700 токенов — сущие копейки для контекстных окон современных моделей. Агент сам структурировал своё поведение, разбив промпт на четыре строгие фазы:
- PHASE 1: Context Gathering. Первым делом агент всегда дёргал ручку whoami, чтобы понять, кто к нему пришёл (внешний юзер или, например, CEO самой компании) и определить уровень доступов.
- PHASE 2: Permission Check. Жёсткая проверка прав по правилам из Wiki.
- PHASE 3: Data Retrieval. Логика работы с API: как вытягивать проекты, пользователей и фильтровать данные.
- PHASE 4: Response Formatting. Правила форматирования финального ответа и работы с ссылками.
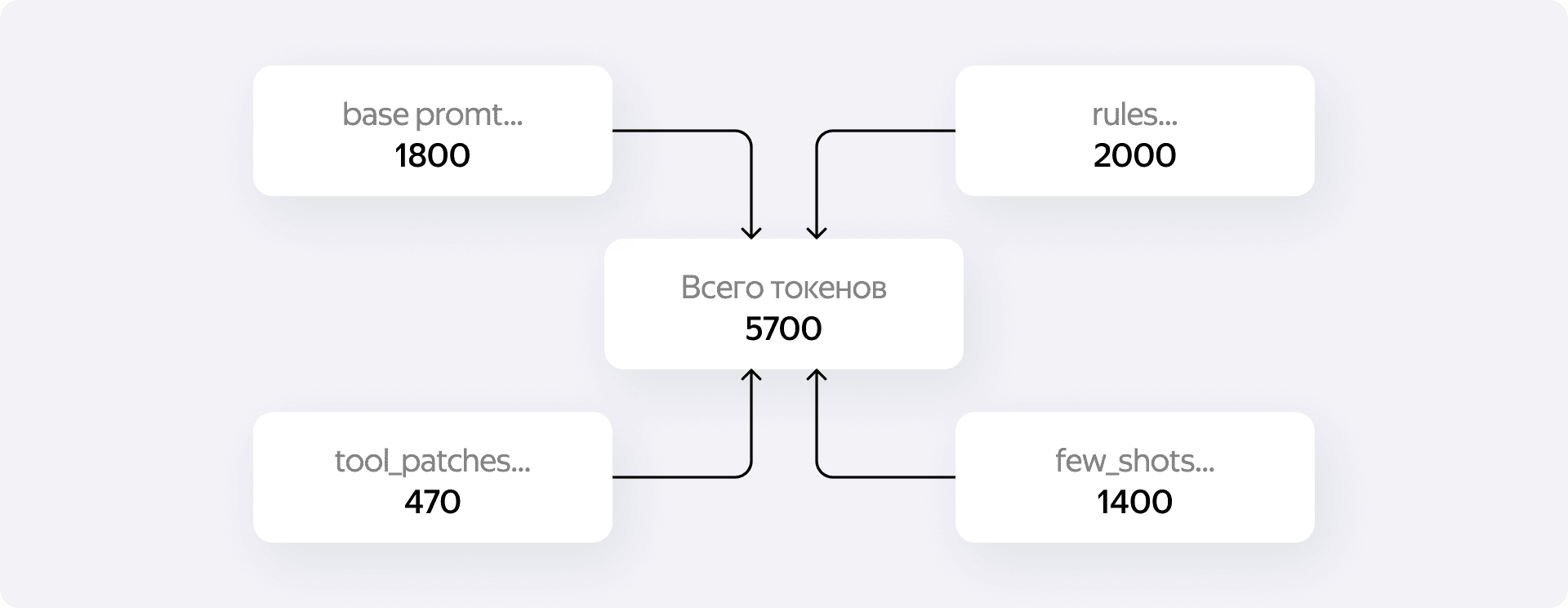
В итоговой версии промпта, с которой мы пошли на прод, ядром стали 34 выверенных правила, 21 few_shots пример и 16 патчей, описывающих, как более чётко использовать инструменты. И всё это без единой строчки ручного хардкода.
Часть 3. Столкновение с реальностью
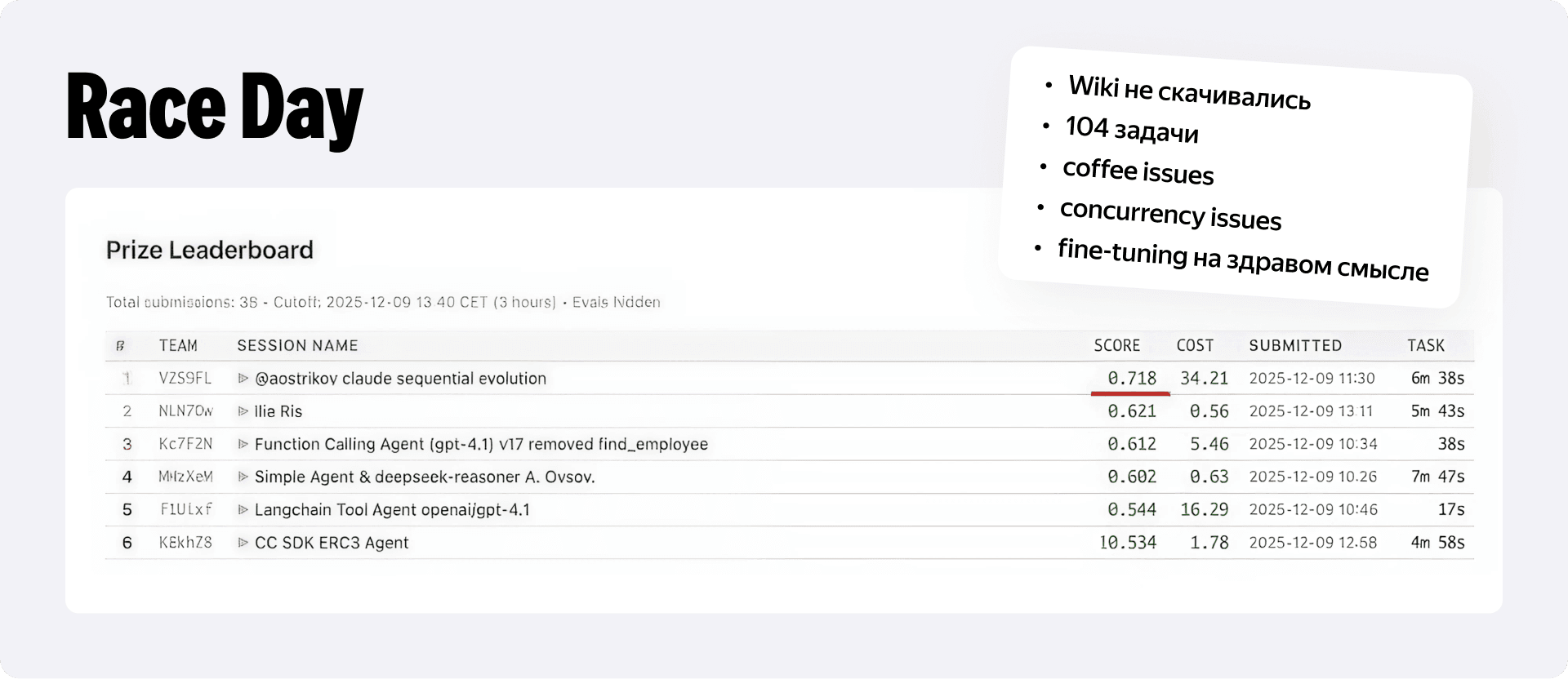
Девятого декабря стартовал финальный забег. По правилам у нас было всего три часа, а сдача результатов происходила вслепую — организатор скрыл оценки. На любой сабмишен платформа неизменно возвращала ноль, не давая понять, правильный ответ или нет. В этот день абсолютно всё, что могло пойти не так, пошло не по плану:
- Первые 15 минут я вообще не мог подключиться к платформе. Когда прорвался, увидел 104 задачи. Напомню, что до этого на тестовых бенчмарках их было 16 и 24.
- Каждая задача сдавалась платформе примерно по 2,5 минуты. Простая математика показывала, что в один поток мы физически не успеем прогнать весь пул за отведённое время.
- Надо было срочно вкручивать concurrency. Я вкрутил — она предсказуемо не заработала. Мгновенно полезли race conditions, пришлось дебажить и фиксить их прямо на ходу.
- В довершение ко всему отвалилось скачивание файлов Wiki, а в самый разгар суеты я пролил кофе на клавиатуру. Компьютер выключился на 40 минут и вместе с командой helpdesk (спасибо ребята!) мы оживили его за час до конца соревнования.
И несмотря на всё это, я всё-таки умудрился протолкнуть три сабмишена. Так как реальные оценки на платформе были скрыты, я попытался заоверфититься прямо в моменте. Это было похоже на «файн-тюнинг здравого смысла». Я попросил агента посмотреть на свои ответы ко всем 104 задачам и оценить их логику именно с точки зрения здравого смысла. И о чудо — Claude Code действительно нашёл пачку идеологических нестыковок в собственных решениях, после чего я успел прогнать конфигурацию через ещё один цикл эволюции.
Когда через неделю Ринат подводил итоги, выяснилось, что мой бот забрал первое место со скором 0.718
Но здесь нужно сделать честное признание. На стриме с разбором полётов мы смотрели решение Ильи, занявшего второе место. Его архитектура была красивее моей в миллион раз. Это был эталонный инженерный подход: агент адекватно планировал следующие шаги, использовал guardrails и работал на SGR. Именно про такие изящные системы хочется рассказывать на собеседованиях.
Моё же решение было простым и безжалостно заоверфиченным за счёт восьмидесяти поколений автоматической эволюции на мощнейшей модели. Оно победило не за счёт элегантности архитектуры, а за счёт грубой силы фидбэк-лупа.
Часть 4. Дорога к абсолютным 100%
После финала я немного выдохнул. В чатах участники начали постепенно подбираться к абсолютному максимуму на финальном бенчмарке, у ребят начали появляться оценки около 0.85, и тогда я подумал — почему бы тоже не добить результат?
Интересно, но спроектированная мной эволюция сломалась почти сразу. Скор поднялся с 0.71 до 0.76 и намертво упёрся в плато. Агент перестал находить новые решения, а система начала просто вхолостую сжигать токены.
Корневую проблему я понял довольно быстро. Она скрывалась в архитектуре инструментов. На старте я прокинул методы внутреннего API в tools агента один в один. Для сложных сценариев это оказалось фатальной ошибкой.
В некоторых задачах агенту приходилось делать около 150 вызовов API. Виной всему — отсутствие нормальной пагинации и особенности среды. Представьте ситуацию: ручка поиска проектов по сотрудникам временно не работает. Чтобы найти нужного человека и отфильтровать его проекты, LLM вынуждена методично листать страницы со всеми сотрудниками компании. Каждый такой запрос — это новый такт агента. Контекст пухнет, модель теряет фокус и риск галлюцинаций возрастает кратно.
Чтобы это победить, я поставил на паузу эволюцию промптов и начал писать композитные инструменты.
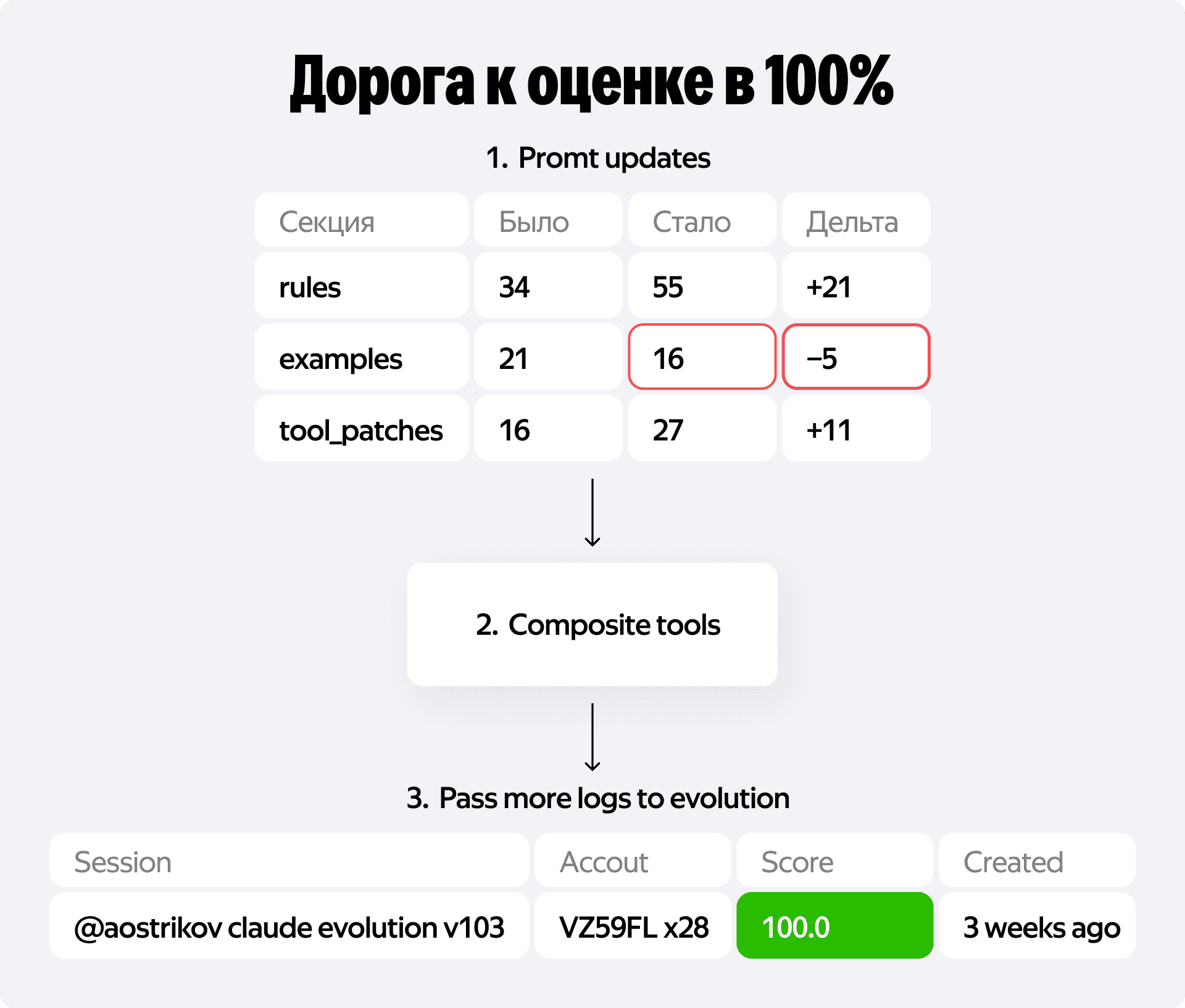
Я забрал логику агрегации из промпта и перенёс её в код. Вместо того чтобы мучить Claude сотней запросов, я написал ряд высокоуровневых функций — например, find_employees_by_skill или time_summary_by_project. Под капотом такой тул крутил обычные циклы, быстро выгребал данные по всем страницам API, фильтровал их и отдавал агенту готовую сводку. В итоге вместо 150 шагов рассуждений LLM тратила ровно один цикл. После этих правок я добрался до оценок в 0.93-0.95.
Параллельно я провёл серьёзный рефакторинг пайплайна:
- Компактизация контекста. Токены улетали с космической скоростью. Я агрессивно сжал системные промпты и форматы ответов от ручек, чтобы в контекстное окно влезало только самое важное.
- Долгосрочная память для эвалюатора. Я дал анализатору доступ к логам предыдущих попыток решения. Теперь агент-эволвер видел не только причину текущего фейла, но и всю ретроспективу прошлых запусков. Это жёстко запретило системе ходить по одним и тем же граблям.
Началась супер-изматывающая работа. Хорошо помню последнюю ночь: метрика застыла где-то на уровне 98–99%. В лидерборде рубились ещё три человека, и каждый хотел забрать заветные 100% первым. Я поцеловал жену на ночь, и твердо решил, что спать сегодня не лягу, пока не добью этот бенчмарк.
В итоге стратегия с композитными тулами и расширенной памятью сработала. Примерно в пять утра платформа выдала зелёный бейдж с результатом 100.0. К тому моменту это была уже 103-я версия агента. Я скинул скриншот с победой в Telegram-группу, закрыл ноутбук и больше к этому коду не прикасался — соревнование выжало меня без остатка.
Часть 5. Что это всё значит для будущего индустрии?
Дочитав до этого места, у вас наверняка уже возник закономерный вопрос: зачем я вообще рассказываю историю какого-то стороннего соревнования в блоге Городских сервисов Яндекса? Дело в том, что мой кейс не уникален. В начале 2026 года комьюнити начало массово делиться результатами экспериментов, которые выглядят как начало большого тектонического сдвига в индустрии.
- Разработчик Aigiz написал плагин для Chrome, который в реал-тайме переводит видео с русского на башкирский. Он отдал агентам написание кода, выбор моделей и параметров, замкнув цикл через строгие бенчмарки качества перевода. За 9 часов система сама перебрала десятки фиксов и выдала рабочий продукт.
- Ринат Абдуллин зациклил Codex на создание сложного парсера и вычислителя формул в стиле Excel/Google Sheets. Имея на входе только набор тестов, агент за 14 коммитов написал чистый алгоритм на Go с AST-деревьями и графами зависимостей.
- Команда Cursor запустила агентов, которые за неделю автономной работы написали с нуля сырой браузер, а другой пул агентов за ту же неделю собрал pull request, рефакторящий часть самого редактора с Solid.js на React.

У всех этих примеров есть один общий паттерн.
Во-первых, self-improvement loop не будет работать без жёсткой, желательно числовой метрики качества. Если вы просите агента «сделать красиво» или провести глубокий ресёрч, вы не сможете замкнуть цикл обратной связи. Модели нужна конкретная оценка: тест пройден или тест упал.
Во-вторых, агенту критически важно уметь планировать следующие шаги и иметь доступ к истории своих прошлых ошибок. Бесконечные повторения одной и той же таски без памяти о граблях лишь сжигают бюджет.
В-третьих, порог входа обеспечивают исключительно тяжёлые модели уровня Opus 4.5 и GPT 5.2. Именно они в октябре-ноябре 2025 перешагнули некую незримую грань интеллекта, после которой генерируемый код остаётся адекватным и архитектура улучшается, а не пухнет до состояния неподдерживаемого мусора. Ну и да, на всё это вам понадобится просто неприлично большое количество токенов.
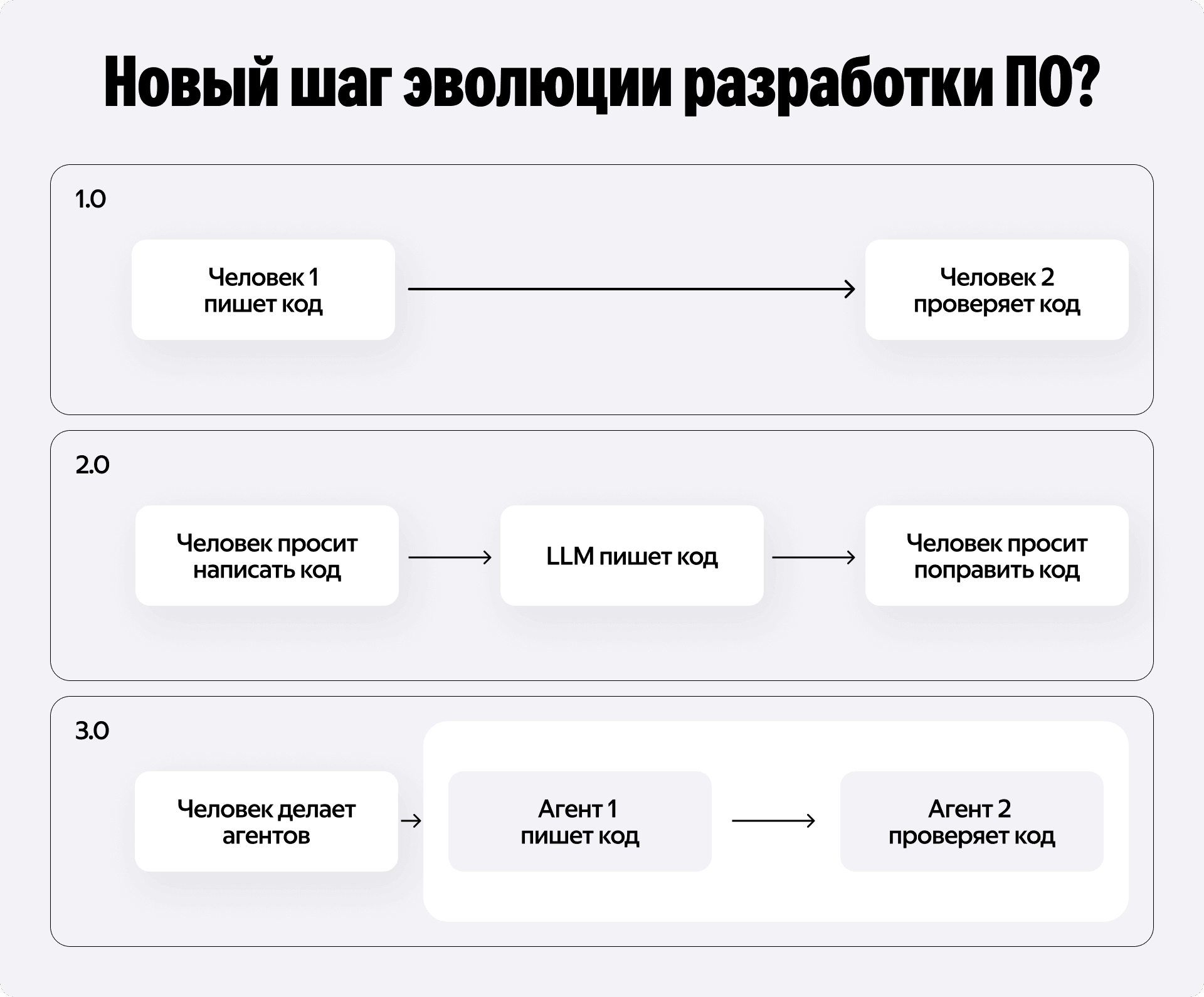
У нас на глазах происходит новый виток эволюции разработки ПО. Раньше мы писали всё руками. В прошлом году случился бум вайбкодинга — разработчик просил LLM написать куски кода и мы все радовались ускорению в 5-10 раз на этом участке. Но сейчас, мы уже видим примеры нового тренда, если вы замкнёте в цикл написание кода + оценку качества + планирование нового шага у вас есть шансы ускорить решение таких задач в десятки раз.
Подробнее об этом рассказываем в статье «7 лайфхаков для вайб-кодинга, которые я хотел бы знать с самого начала»
Давайте перенесём это на наши реалии работы с бэклогом. Представьте нашу традиционную продуктовую разработку. При правильном мастерстве оркестровки вы можете замкнуть весь контур: агент сам заводит тикет, пишет код по спецификации, сам себя ревьюит, фиксит баги по результатам тестов, выкатывает результат и пишет отчёт. Именно так будут выглядеть процессы разработки в адекватных командах через годик, а где-то это уже случилось.
Великая эра агентов приближается. Самый частый вопрос, который я слышу: «Как развиваться инженеру, если весь код скоро будут писать агенты?»
Мой ответ прост. Прекратите бояться и инвестируйте время в то, чтобы стать AI-fluent и научиться получать результат от агентов. Огромная пропасть лежит между начинающим вайбкодером и Gen-AI инженером, который умеет оркестрировать агентами. Научитесь управлять контекстом, писать скиллы, выстраивать петли обратной связи. Установите и потрогайте сами OpenClaw, поймите в чём его изюминка. Поймите, в чём отличие архитектуры агентов 2026 года (langchain/adk/pydantic ai/openai-agents-python) и агентов новой эпохи (local harness/openclaw clones + claude code/codex/opencode + бизнес логика в скиллах). На мой взгляд, именно эти навыки сейчас в разы важнее зубрёжки классических алгоритмов и структур данных.
Просто найдите задачу, которая вас драйвит, и попробуйте решить её по-новому.
P.S: Кому захочется вообще космоса, недавно рассказывал, как можно начать путь AI-трансформации компаний в целом: там довольно смело и масштабно. Обязательно посмотрите.



