
Обычно на проектирование и запуск собственного рекламного движка с нуля закладывают не меньше полугода. Процесс длинный и не терпит спешки — нужно продумать и защитить архитектуру, написать и протестировать код, провести сотни симуляций для подбора коэффициентов в формулах, а затем плавно раскатить систему на пользователей и замерить результаты.
Мы бросили себе вызов, решив уложиться ровно в один квартал. Это само по себе стало отличной проверкой инженерных процессов. Но всё становится ещё интереснее, когда к этому добавляются жёсткие ограничения реально высоконагруженного продакшена.
Меня зовут Денис Токарев, я руковожу службой разработки рекламы в Яндекс Еде. Чтобы вы лучше понимали рабочий контекст, приведу немного цифр. Ежемесячно сервисом пользуются больше 20 миллионов уникальных пользователей, На платформе представлено более 143 тысяч ресторанов и магазинов. Внутри самого приложения есть больше пяти разных поверхностей для внедрения рекламы — различные карусели, поиск, основной каталог. И вся эта инфраструктура генерирует среднюю нагрузку на рекламный движок свыше 600 RPS.
В какой-то момент перед командой встала чёткая продуктовая задача — реализовать удобный и понятный инструмент, который позволит ресторану получать дополнительные заказы. При этом нам нужно было найти баланс между тремя разнонаправленными целями:
- Вырастить инкрементальные заказы партнёра.
- Снизить долю его рекламных расходов.
- Что-то заработать самим.
Качество пользовательской выдачи при этом должно было как минимум остаться на прежнем уровне, а в идеале — вырасти.
Чтобы рестораны могли прозрачно прогнозировать свои затраты на продвижение, мы решили строить систему по модели CPA. В нашем случае это означает оплату исключительно за совершённый заказ, а не за клики или показы объявления.
При этом всём время ответа ручки рекламного движка не должно превышать 200 миллисекунд в 99 перцентиле. Мы были обязаны строго укладываться в эти тайминги, чтобы не тормозить скорость работы приложения для конечного пользователя.
В этой статье я расскажу, как мы декомпозировали эту систему и всего за три месяца построили архитектуру, способную фильтровать десятки тысяч кандидатов, рассчитывать ML-предикты и проводить аукционы в условиях жёстких лимитов времени.
Почему не Яндекс Директ?
Перед тем, как бросаться в собственный код, логичным шагом было посмотреть в сторону уже готовых решений. Именно так мы и поступили, и далеко ходить не пришлось — рядом всегда был Яндекс Директ. Это отличная мощная система с широким функционалом и API, которую довольно просто интегрировать. Мы сказали: «А почему бы и нет?» и запустили первую версию на Директе. Но довольно скоро столкнулись с двумя серьёзными проблемами.
Первая проблема — техническая. Чтобы лучше понять суть, представьте простую задачу: вам нужно отсортировать массив из чисел. Что вы будете для этого использовать? Конечно, можно не мелочиться и сразу взять квантовый суперкомпьютер. Он совершенно точно справится с задачей. Но если вдруг понадобится немного изменить логику расчётов — вы надолго увязнете в процессе настроек. Всё потому, что этот инструмент избыточен для задачи.
То же самое случилось и у нас. Директ — огромная машина. Каждый раз, когда приходили новые бизнес-требования для Еды, нам приходилось тратить непозволительно много времени на их поддержку. И из-за этого сильно страдал TTM.
Вторая проблема касалась непосредственно процесса заведения рекламы. Вот как этот пользовательский путь выглядел для рекламодателя: владельцу ресторана нужно было залогиниться в админку Еды; нажать кнопку «запустить рекламу»; затем перейти и залогиниться в систему оплаты; пополнить кошелёк и только после этого запустить кампанию. Слишком много шагов. И мы это ясно видели по метрикам, когда на этапах перехода в биллинг и пополнения кошелька часть кампаний просто отваливались — партнёры, которые их заводили, не доходили до финала.
Нам же в идеале хотелось прийти к такому состоянию, когда ресторан может запустить продвижение буквально в пару кликов и сразу начать получать заказы.
Тогда-то мы и поняли, что нам нужен собственный гибкий инструмент. Движок, который позволит напрямую управлять состоянием аукциона и быстро реагировать на любые изменения бизнеса.
Если посмотреть на целевую архитектуру сверху, процесс выглядит так. Пользователь заходит в приложение Яндекс Еды. Уходит запрос в наш микросервис каталога. Там мы фильтруем кандидатов — находим все рестораны, которые могут доставить заказ в нужную точку. Затем отправляем их в аукцион, финально ранжируем и отдаём выдачу пользователю. Дальше мы собираем и обрабатываем события показа и кликов, чтобы в будущем проклеить конверсию в заказ.
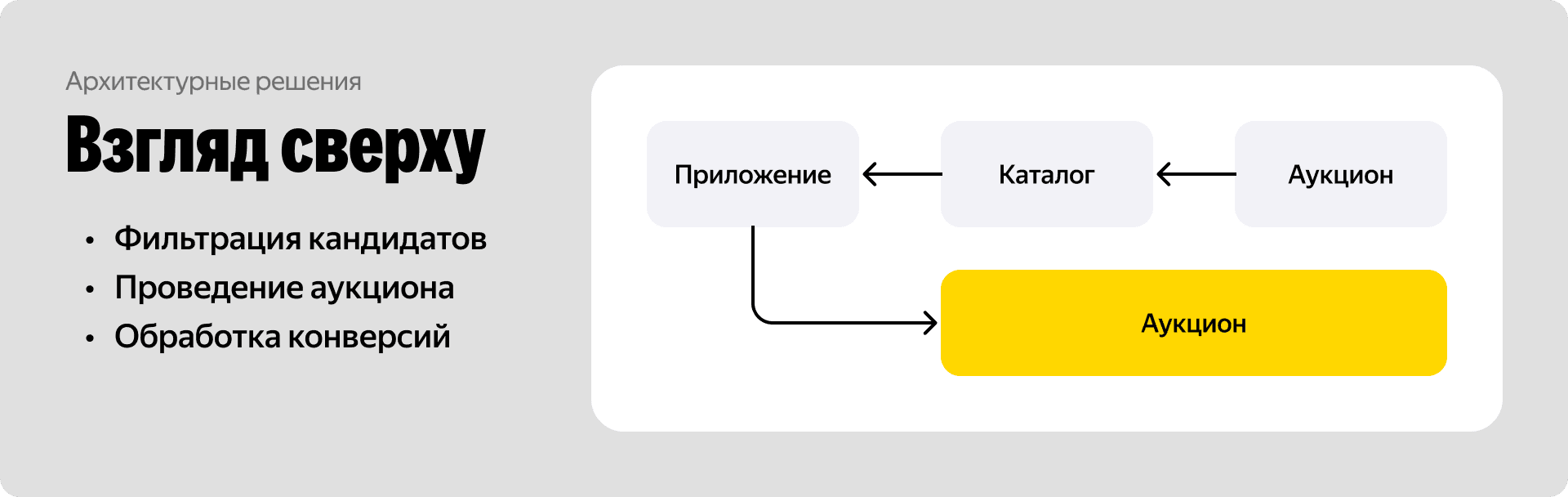
Как будто бы звучит не сказать чтобы сильно просто, но и не очень-то сложно на самом деле. Однако, если разобраться и переложить этот паттерн на наш масштаб, то вот какие сложности тут есть:
- нужно выбрать подходящие рестораны из десятков тысяч доступных кандидатов и сделать это быстрее 50 миллисекунд в 99-м перцентиле;
- затем рассчитать вероятность заказа в конкретном ресторане и предсказать потенциальную выручку сервиса;
- наконец, провести сам аукцион с учётом всех предиктов, уложившись в общий лимит 200 миллисекунд;
- и в довершение научиться точно определять факт конверсии и удерживать с рекламодателя корректную сумму за рекламный заказ.
Задача 1: выбрать подходящих кандидатов из десятков тысяч за <50 мс
Начнём с первого этапа пайплайна — фильтрации кандидатов. У нас есть пользователь, который открыл приложение и хочет сделать заказ. И есть десятки тысяч ресторанов в системе. Нам нужно моментально понять, какие из них доставляют по нужному адресу.
Тут важно проговорить один момент. Зона доставки ресторана — это не простой круг или квадрат. Это вообще довольно сложный полигон произвольной формы. При этом в плотно застроенных районах, например в Москва-Сити, в одну точку могут одновременно доставлять тысячи заведений.
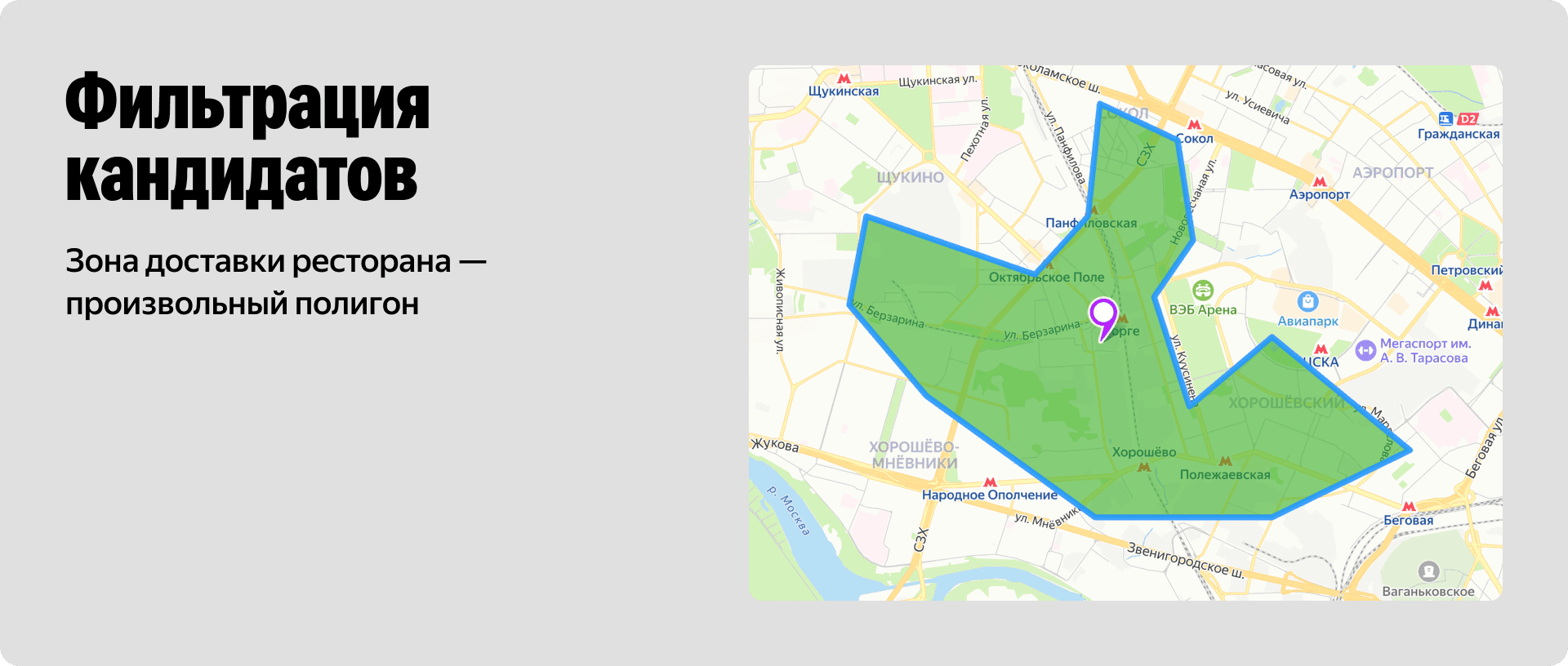
Чтобы сервис не упал под такой нагрузкой, нам нужно было отсеять неподходящие рестораны и собрать итоговый пул кандидатов быстрее чем за 50 миллисекунд в 99-м перцентиле. Для решения таких геометрических задач обычно используют геоиндексы. Подходов здесь много, и мы решили последовательно проверить несколько алгоритмов.
Узнать больше об оптимизации выборок можно в материале «Миллионы товаров и тысячи аптек: переворачиваем архитектуру Яндекс Еды»
GeoHash
Сначала посмотрели на классический алгоритм GeoHash. Его логика довольно проста — вся карта бьётся на квадраты. На каждом следующем уровне вложенности родительская зона делится на ещё более мелкие квадратики. Берём координату, кодируем её в двоичное представление, чередуем биты и получаем большое бинарное число. Затем кодируем его в Base64-строку, и каждой ячейке на карте присваивается своё строковое значение.
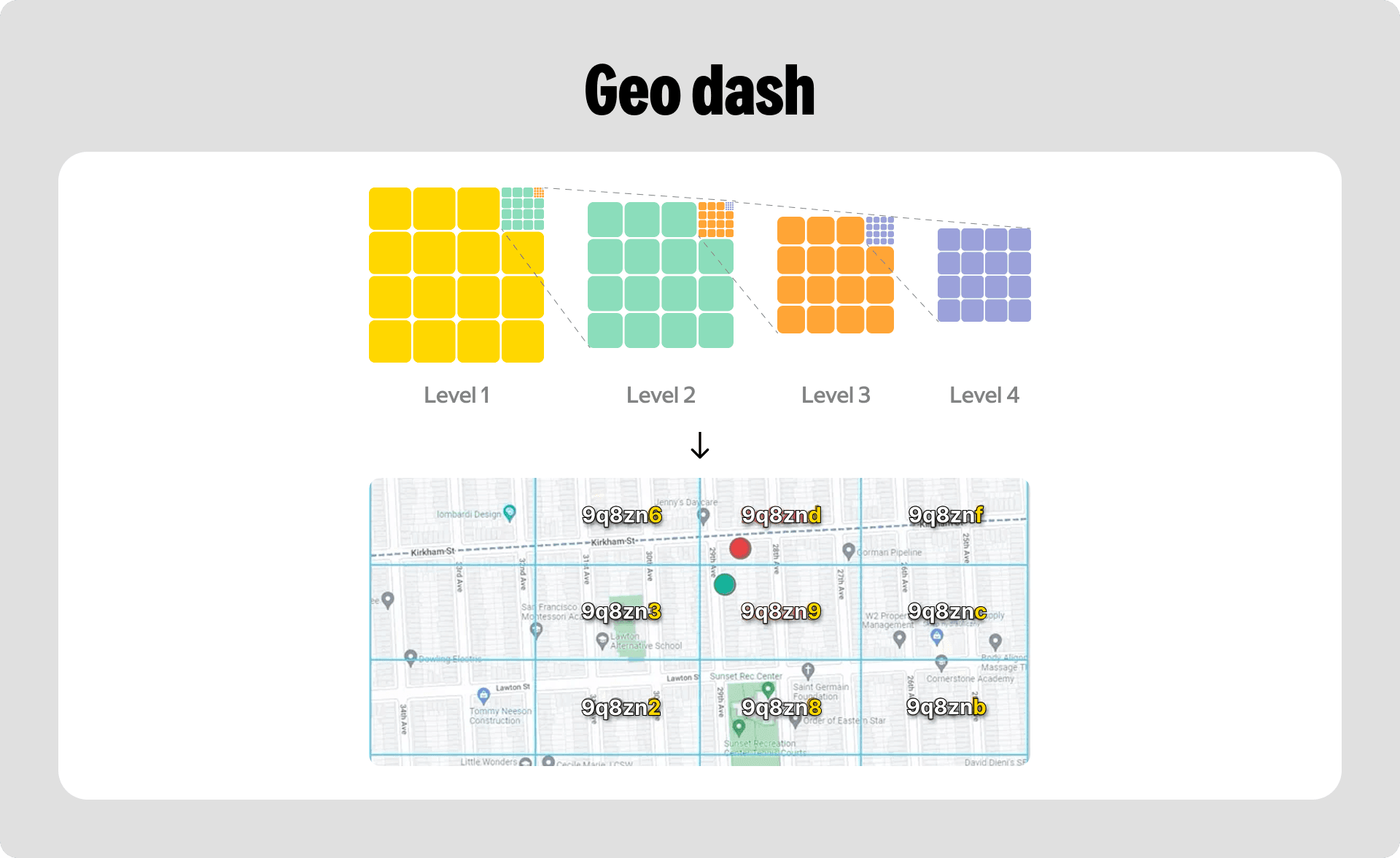
Но для наших условий этот метод не подошёл. Во-первых, чем выше должна быть точность разбиения, тем длиннее получается строка. А значит, нужно больше памяти для хранения этих данных. Во-вторых, полигоны доставки у нас произвольной формы, и описывать их строгими квадратами крайне неэффективно.
Uber H3
Следующий кандидат — алгоритм H3 от Uber. Здесь весь земной шар покрывается гексагонами, и тоже есть несколько уровней вложенности. Но и у этого подхода тоже есть своя архитектурная особенность: в нём нет строгой иерархии.
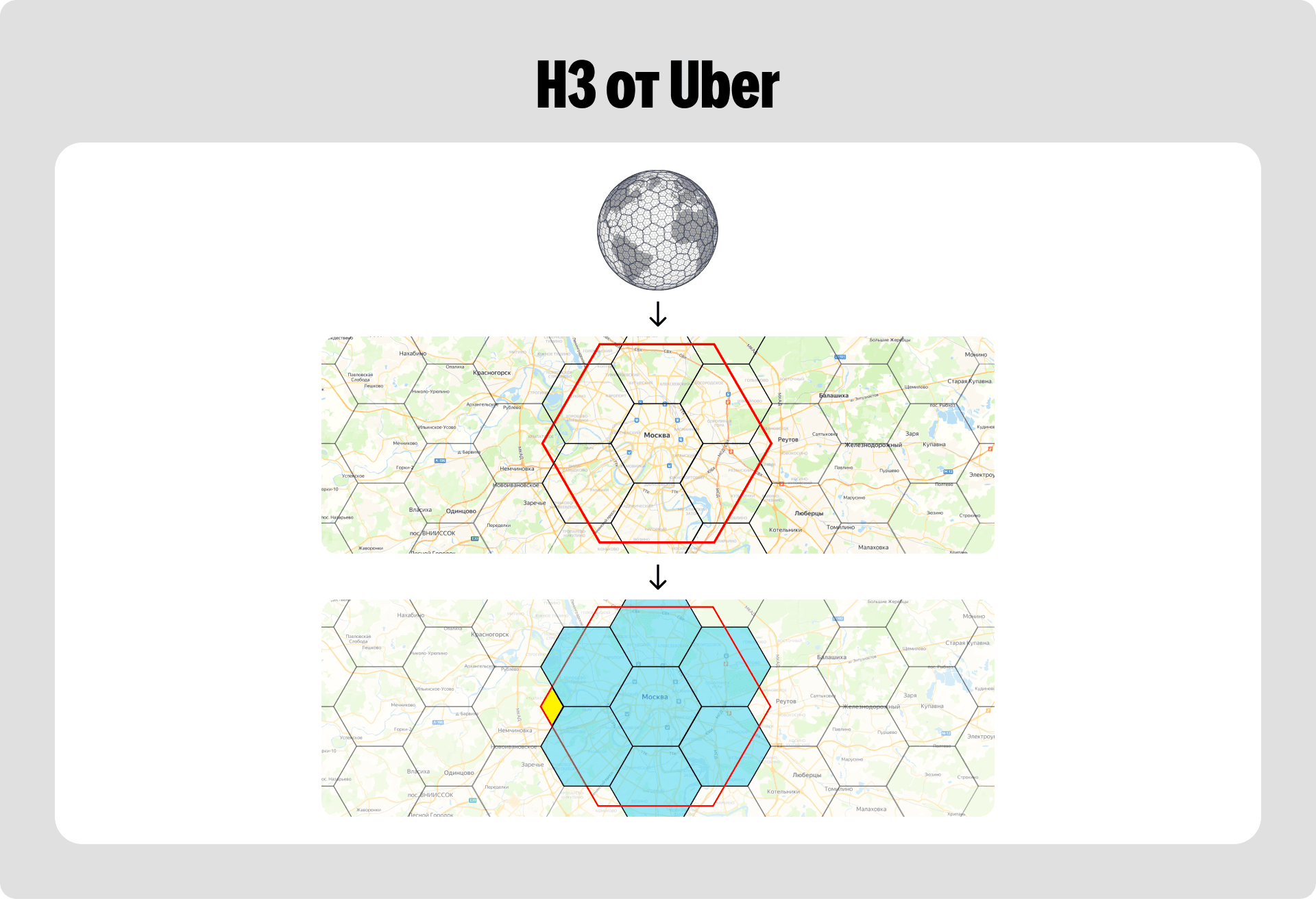
Гексагон верхнего уровня не содержит в себе точное и конечное число гексагонов нижнего уровня. На стыках образуются некоторые выколотые области — пустоты. Если использовать H3 в чистом виде, то при поиске алгоритму придётся делать множество дополнительных проверок в этих пустотах. Из-за этого, конечно же, растёт время поиска, и мы просто не укладываемся в тайминги.
R-tree
В итоге мы всё-таки взяли за основу структуру R-tree. Этот алгоритм позволяет создать ту самую строгую иерархию, которой нам не хватило в гексагонах Uber.
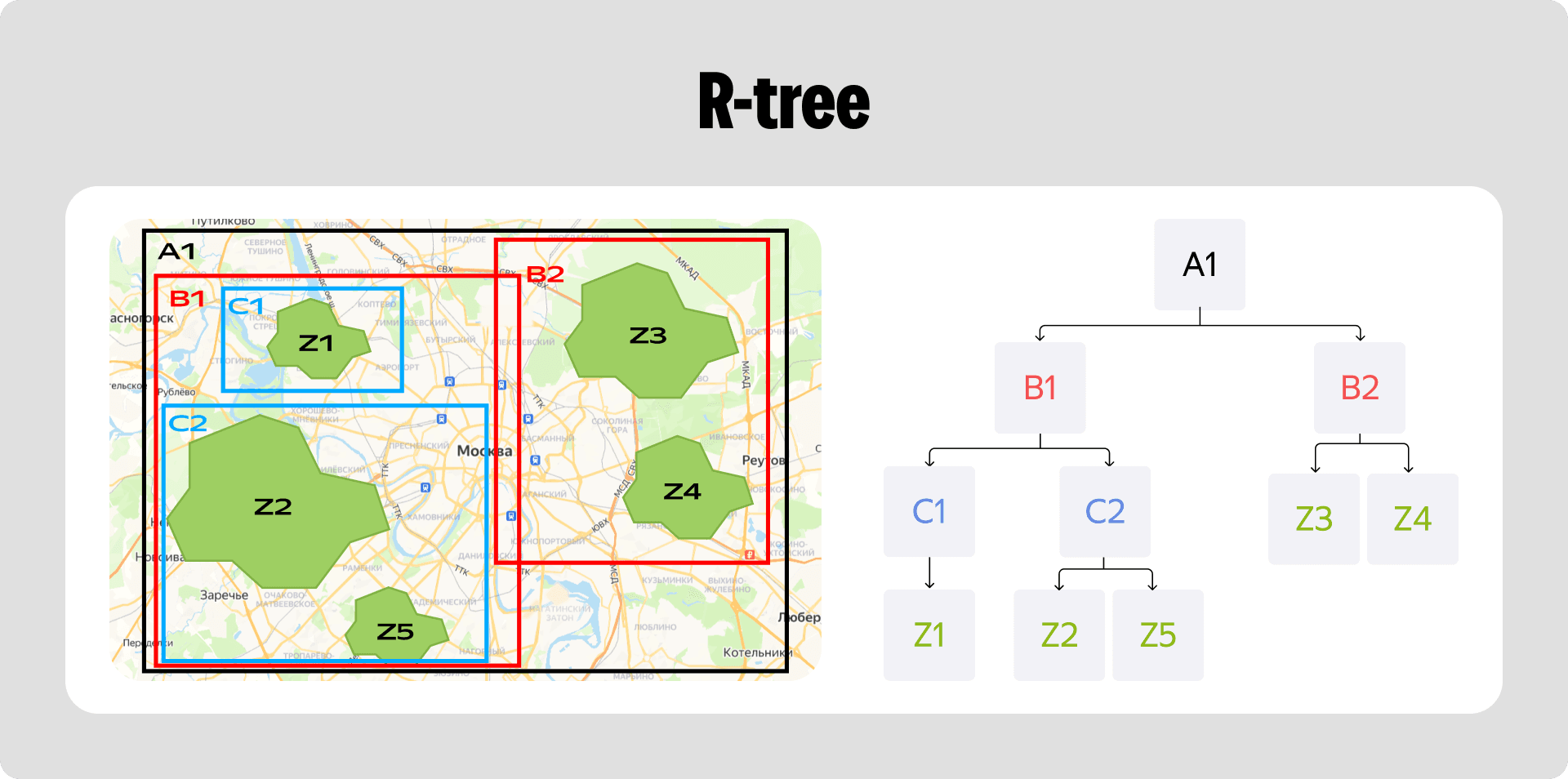
Мы решили строить бинарное дерево: на каждом уровне у одного узла будет не более двух потомков. Изначально мы описываем группу зон доставки большим прямоугольником. Внутри него выделяем зоны поменьше и описываем их вложенными прямоугольниками. И так далее, пока не получим чёткую древовидную структуру. Обычно поиск нужной зоны в таком дереве занимает логарифмическое время.
Казалось бы — решение найдено. Но нет.
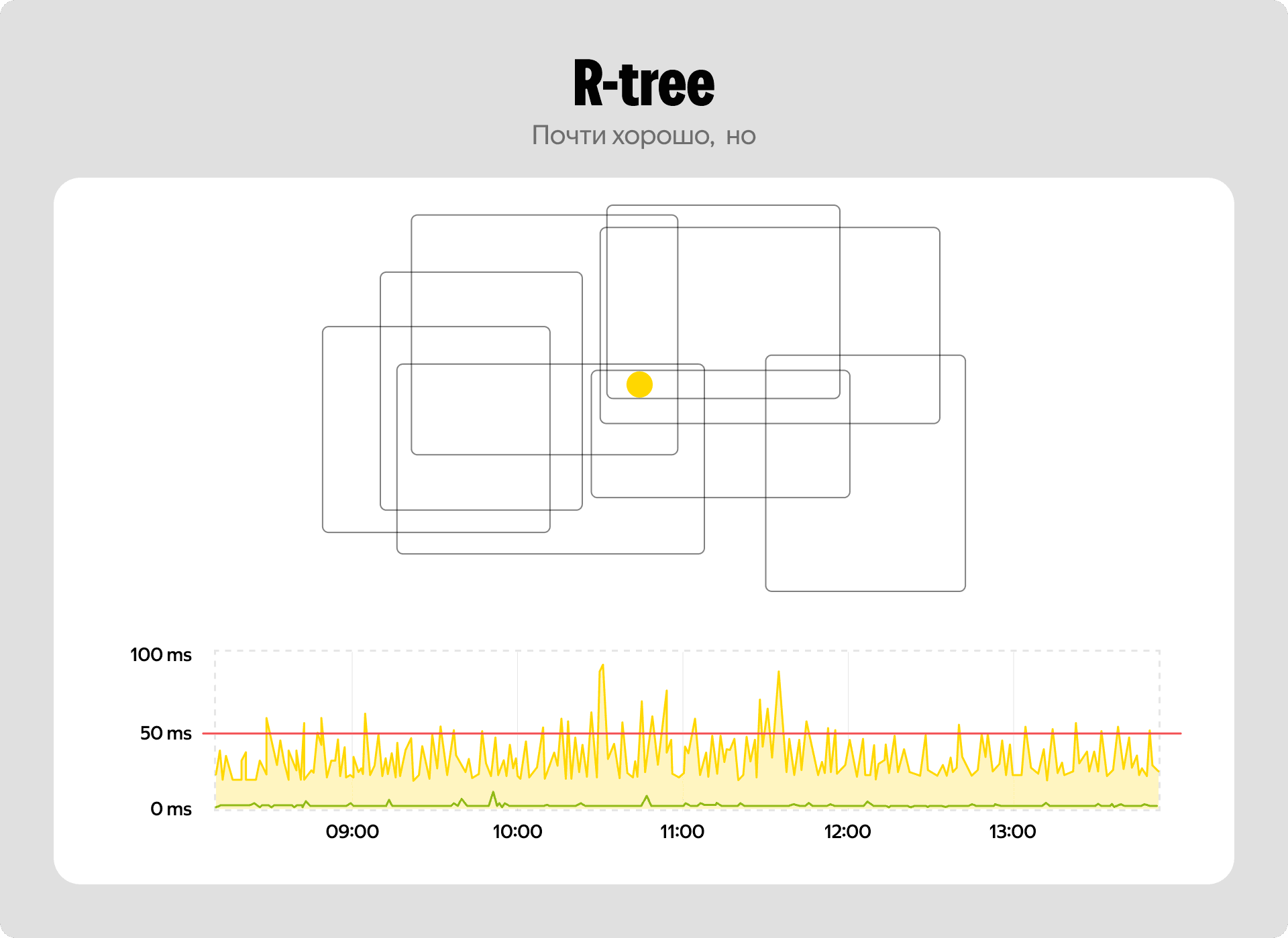
Вспоминаем про плотные зоны вроде центра Москвы. Когда несколько тысяч ресторанов доставляют в одну точку, описывающие их прямоугольники начинают сильно наслаиваться друг на друга. В таких условиях R-tree деградирует. В худшем случае сложность поиска становится линейной, и на графиках мы увидим неприятные выбросы — в 99-м перцентиле время ответа уверенно пробивает потолок в 50 миллисекунд.
Финальное решение: гибридный подход
Раз ни один алгоритм не решает задачу идеально, мы приняли решение собрать гибрид и взяли лучшее от двух систем.
Теперь H3 работает у нас как грубый первичный фильтр. Он очень быстро отсекает всю карту до масштабов небольшой зоны внутри конкретного гексагона. А дальше в дело вступает R-tree. Так как область поиска уже сильно сужена, R-tree не страдает от критического наслоения прямоугольников и моментально находит нужные пересечения.
В таком виде худший сценарий поиска всегда сохраняет логарифмическую сложность. Сейчас гибридный геопоиск стабильно работает и укладывается в 45 миллисекунд в 99-м перцентиле.
Задача 2: ML-предикты и борьба с таймаутами
Геопоиск отработал, и у нас на руках есть отфильтрованный пул ресторанов-кандидатов. Дальше в дело вступает машинное обучение. На этом этапе нам нужно понять две вещи — с какой вероятностью конкретный пользователь сделает заказ в конкретном заведении и какую потенциальную выручку сервис от этого получит.
Для удобства расчётов зафиксируем переменные. Вероятность заказа мы обозначаем как purchase, а потенциальную выручку сервиса — как margin.
Чтобы ML-модель могла выдать точный предикт, ей нужен качественный исторический датасет. Мы берём логи взаимодействия пользователей с ресторанами за последние полгода. Сюда входят полученные выдачи, клики по ресторанам, переходы в меню, клики по конкретным блюдам, добавления в корзину и созданные заказы.
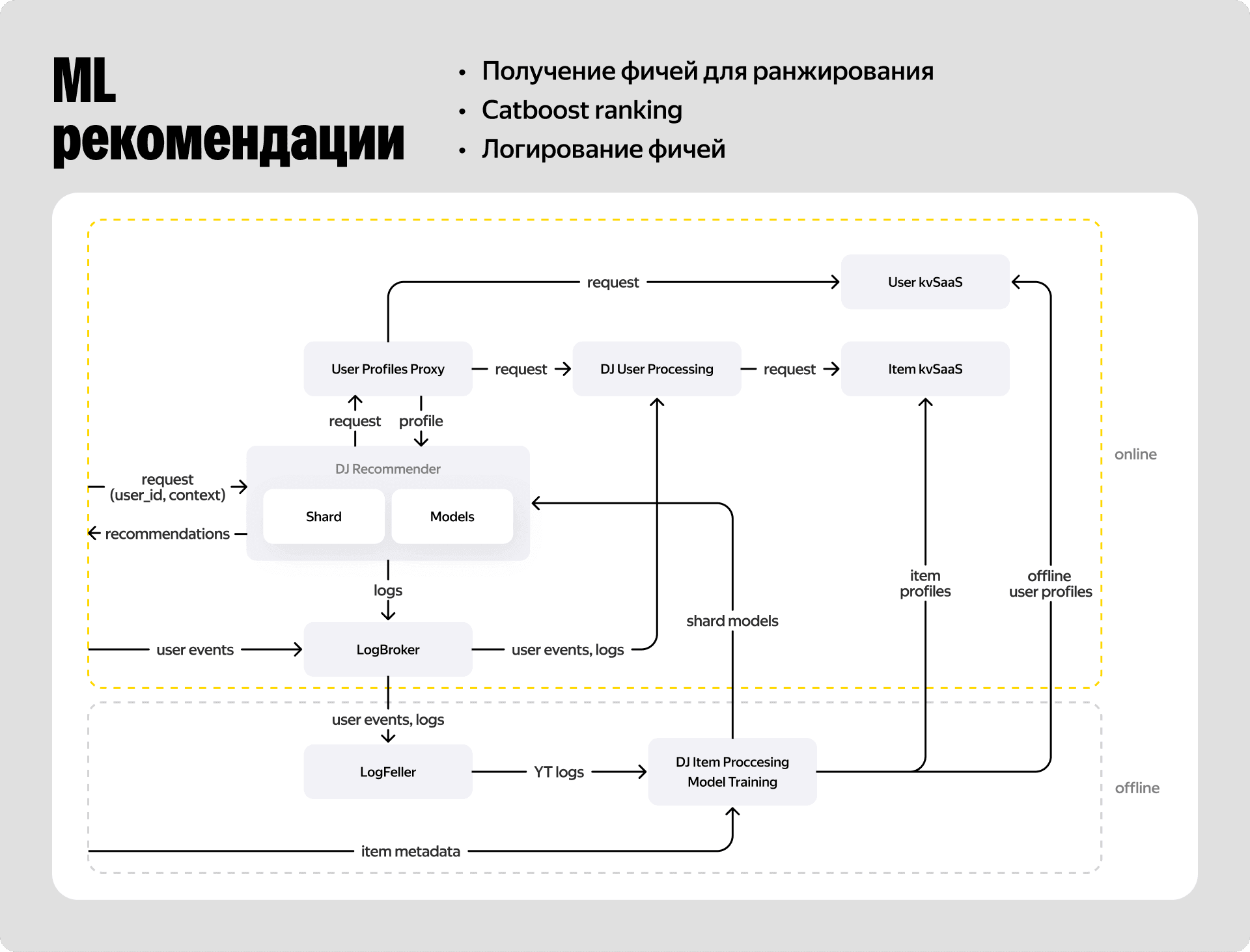
На основе этих данных формируются признаки для ранжирования. Что именно мы передаём в модель:
- геофакторы — текущее расстояние от пользователя до ресторана;
- динамические параметры — стоимость доставки прямо сейчас и наличие высокого спроса;
- историю взаимодействия — заказывает ли пользователь здесь постоянно или пришёл впервые;
- метрики самого заведения — рейтинг ресторана и отзывы.
Собранные фичи отправляются в модель на базе CatBoost. На выходе мы получаем финальную нормированное число — ту самую вероятность заказа. Вычисления здесь действительно тяжеловесные, поэтому под ML-инференс мы закладываем весьма щедрый тайм-аут — целых 500 миллисекунд.
Ещё на эту тему можете прочитать в статье «Скорим всё: как мы упростили ML-стек рекомендаций в Лавке и отказались от кандидатогенерации»
Точка отказа и fallback-решение
Тяжёлые вычисления всегда создают риски. Если сервис начнёт тормозить или отдавать пятисотые ошибки, весь дальнейший флоу сломается.
Это на самом деле критично, потому что аукцион технически невозможно провести без предиктов от ML. Переменные вероятности и выручки строго необходимы для финальной формулы ранжирования. Без них мы не сможем отранжировать и поднять ресторан в выдаче, а значит, и партнёр, и сервис потенциально могут недополучить прибыль.
Чтобы такого не произошло, мы реализовали простое, но надёжное fallback-решение.
Мы собираем логи за последние 30 дней и раз в сутки запускаем фоновый пересчёт. На выходе получается плоская таблица в базе данных. В ней для каждого ресторана по ключу place_id лежит заранее рассчитанное усреднённое значение вероятности заказа и маржинальности.
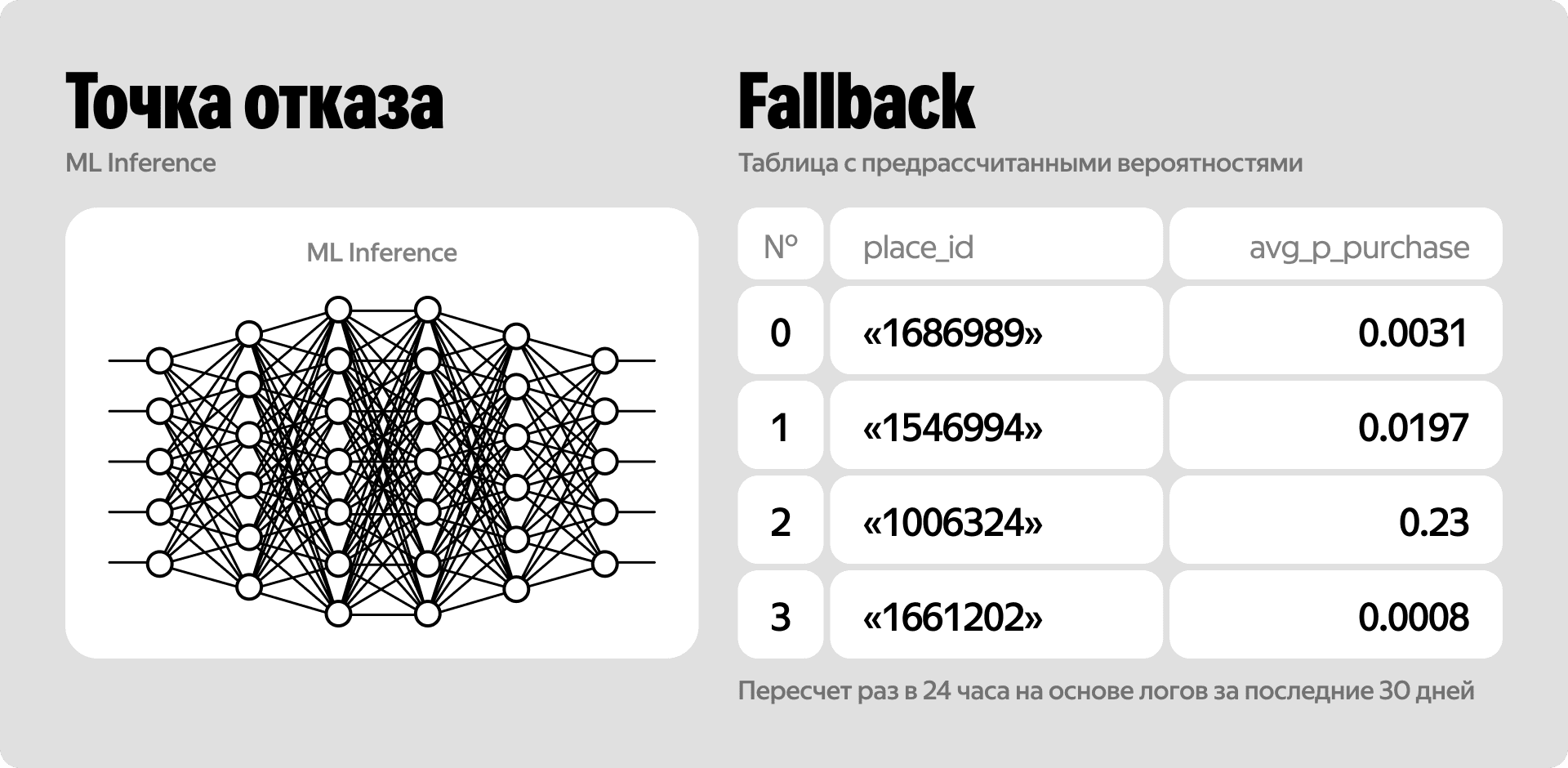
Конечно, если вдруг случится непредвиденное: основной инференс упадёт и мы уйдём в фолбек, мы полностью потеряем персонализацию. И тогда мы отдадим в аукцион не вероятность для конкретного пользователя с учётом его вкусов, а просто среднюю температуру по сервису для данного ресторана. Даже такое среднее значение — это несравнимо лучше, чем получить ноль и прервать цепочку.
Задача 3: аукцион и органическая толерантность
Кандидаты отобраны, предикты вероятности и выручки рассчитаны. Теперь нужно отранжировать рестораны и сформировать финальную выдачу. Напомню про жёсткий тайминг — на ответ всего движка у нас заложено 200 миллисекунд.
Чтобы гарантированно укладываться в эти рамки, мы написали микросервис на C++. За логику ранжирования в нём отвечает самописная и легковесная C++ библиотека auction_lib, в которую зашит алгоритм математического представления аукциона. После того как аукцион проведён, все полученные метаданные отправляются в соседний сервис clickdaemon. Он шифрует эту информацию в просмотровые и кликовые ссылки — они сыграют ключевую роль на этапе проклейки конверсий.
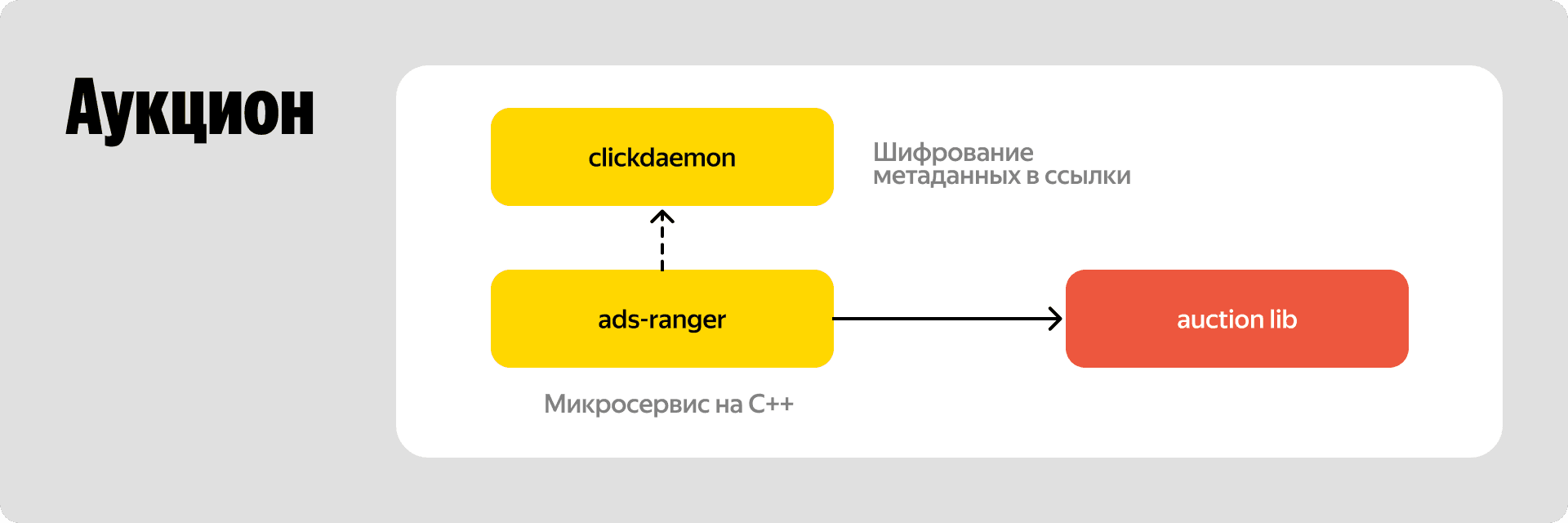
Выбор модели аукциона
В рекламных технологиях есть несколько классических подходов к проведению аукциона. Самый базовый — аукцион первой цены, где победитель платит ровно ту сумму, которую поставил.
Мы также рассматривали продвинутую модель VCG (Vickrey-Clarke-Groves). В ней весь трафик бьётся на базовый и дополнительный. Участники платят за базовый объём по ставке последнего прошедшего рекламодателя, а дальше сумма растёт по лесенке. В итоге получается, что партнёр платит только за дополнительно полученный трафик. Технически это, конечно, очень красивая концепция, но мы от неё отказались. Во-первых, такую сложную математику крайне тяжело объяснять рекламодателям, а во-вторых, в будущем это теоретически может сильно усложнить аудит биллинга.
В итоге мы остановились на модели GSP — аукционе второй цены. В нём побеждает участник с наибольшим итоговым скором, но платит он ставку своего ближайшего конкурента снизу плюс небольшую дельту. Это создаёт честную атмосферу для партнёров и защищает их от переплаты.
Формула ранжирования и баланс метрик
Что должно получиться на выходе из auction_lib? Нам нужна одна конкретная цифра — финальный скор, по которому мы отсортируем рестораны.
Здесь мы снова сталкиваемся с необходимостью балансировать разнонаправленные бизнес-цели: растить заказы партнёра, снижать его долю рекламных расходов и при этом не забывать про выручку платформы. Итоговый скор вычисляется как функция от трёх переменных:
- purchase — вероятность заказа;
- bid — рекламная ставка партнёра;
- margin — потенциальная маржинальность от заказа для сервиса.
Упрощённо концепция выглядит так:
score = F(A * purchase, B * bid, C * margin)
Чтобы найти правильный оптимум, мы провели сотни симуляций. Коэффициенты A, B и C позволяют нам гибко управлять поведением аукциона. Если мы увеличим коэффициент A, то органическая вероятность заказа для конкретного пользователя получит больший вес при ранжировании, чем рекламные деньги партнёра. Правильная настройка этих весов даёт бизнесу нужную свободу маневра.
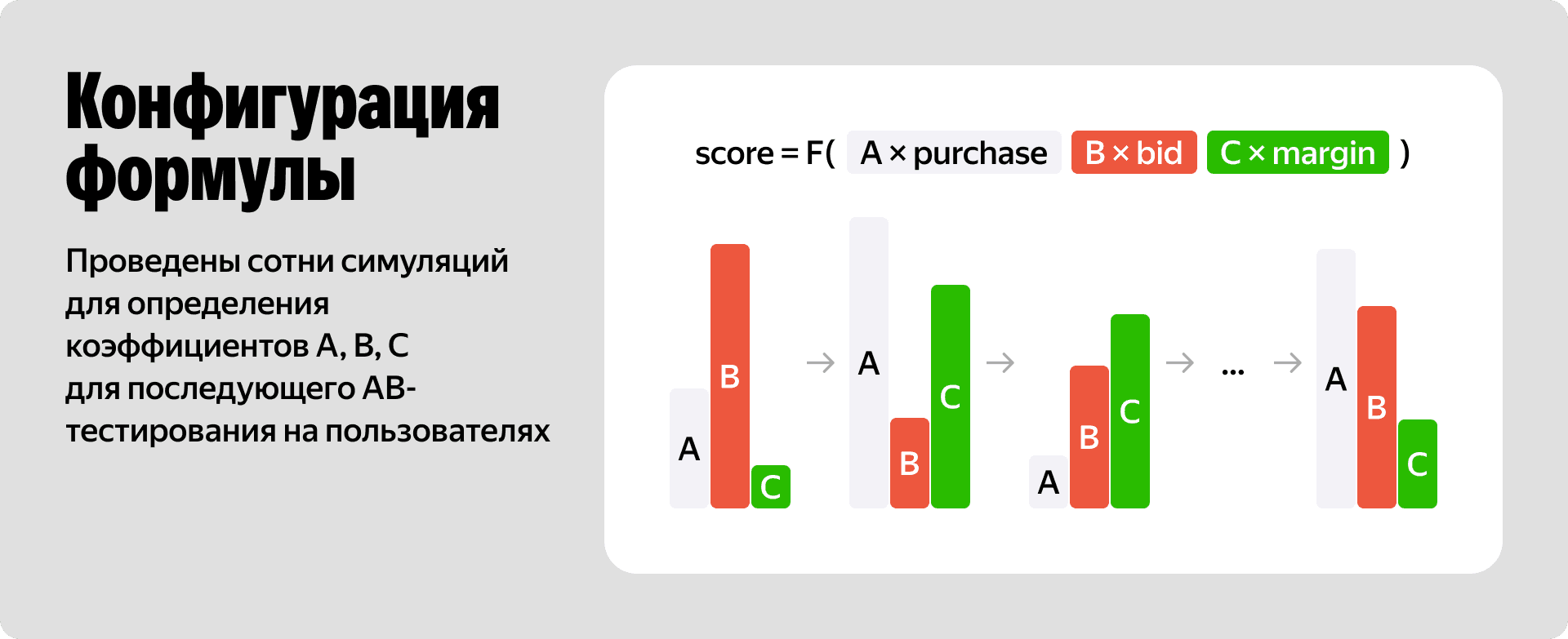
Амнистирование ставки и продуктовые фичи
В аукционе второй цены итоговая сумма списания называется амнистированной ставкой — brokeredFee. Давайте разберём её логику на небольшом примере.
Представим запуск некоего гипотетического продвижения. Мы вводим понятие минимальной ставки для участия в аукционе — minBid. Пусть она будет равна 10 рублям. А теперь логичный вопрос — что произойдёт, если после проведения аукциона и расчёта скоров итоговая ставка brokeredFee окажется кратно меньше minBid?
В физическом смысле это означает следующее — ресторан победил в аукционе не потому, что залил денег в рекламу, а потому, что его вероятность заказа (purchase) перевесила ставку в формуле. То есть заведение оказалось максимально релевантным для конкретного пользователя.
Для обработки таких кейсов мы ввели параметр organic_tolerance — органическую толерантность. Мы задаём для неё определённый порог в диапазоне от нуля до minBid. Логика работы максимально прозрачная: если амнистированная ставка brokeredFee падает ниже порога органической толерантности, мы просто обнуляем её.
Важно, что в таком случае мы не списываем с ресторана деньги вообще. Мы считаем, что партнёр был поднят в выдаче органически, благодаря высокому качеству своего продукта и точному попаданию в запросы пользователя.
Задача 4: атрибуция конверсий по модели Last-Click
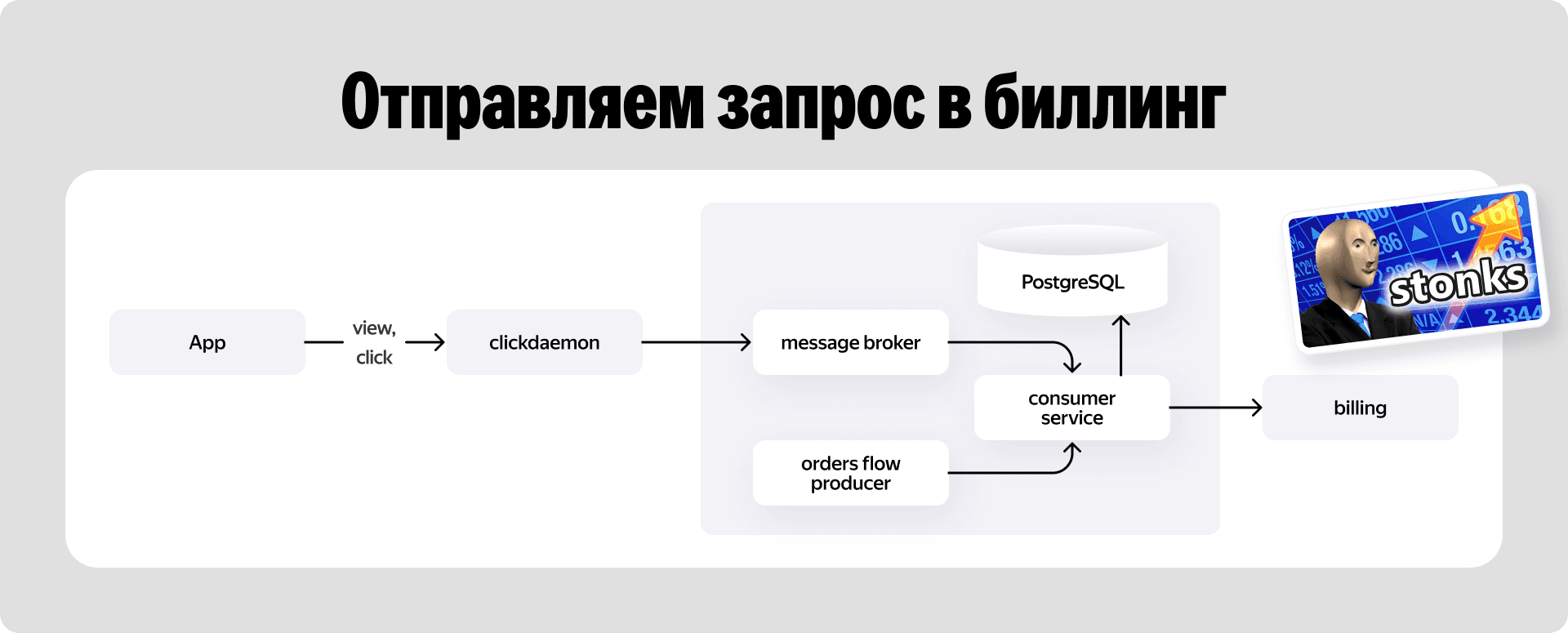
Сбор кликовых логов устроен следующим образом. Если рекламная карточка ресторана попадает во вьюпорт, приложение дёргает просмотровую ссылку. Если пользователь нажимает на карточку — уходит кликовая ссылка.
Оба запроса летят в микросервис clickdaemon. В предыдущем блоке я упоминал, что именно он запаковывает результаты аукциона в ссылки. На этапе показа или клика он делает обратную операцию — извлекает метаинформацию и отправляет сырые события в наш рекламный топик через брокер сообщений. На выходе из топика мы получаем чёткий набор параметров: какой пользователь кликнул, по какому ресторану и какая амнистированная ставка закрепилась за этим действием.
Параллельно рекламный консьюмер слушает второй топик — общий поток статусов всех заказов Еды. Это необходимо для того, чтобы найти пересечения рекламных кликов с реальными покупками.
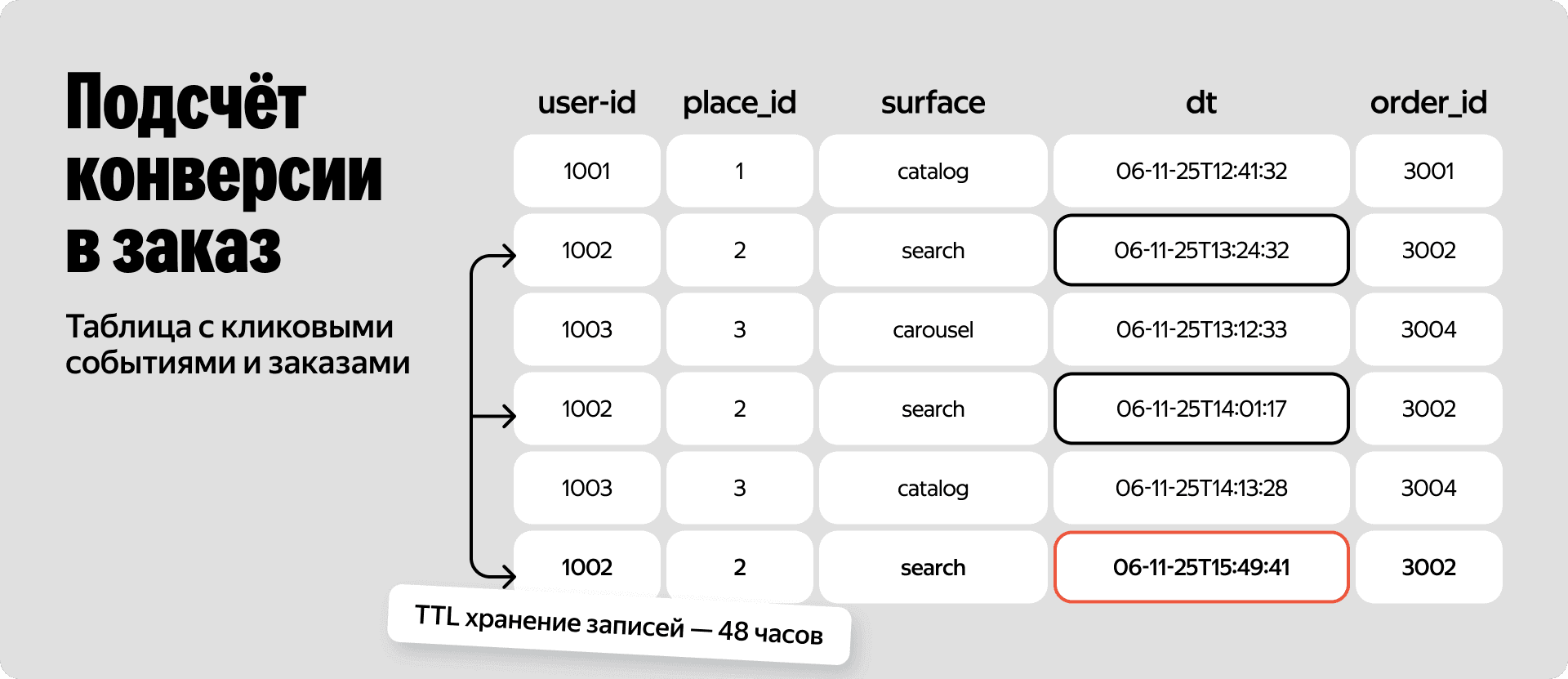
Матчинг в PostgreSQL
Всех потенциальных кандидатов на проклейку конверсии мы складываем в плоскую таблицу в PostgreSQL. Долго хранить эти данные нет смысла, поэтому мы выставили TTL записей на уровне 48 часов.
Структура таблицы выглядит просто, мы пишем в неё следующие колонки:
- user_id — идентификатор пользователя;
- place_id — идентификатор ресторана;
- surface — поверхность, на которой прошёл аукцион (каталог, поиск или карусель);
- order_id — номер потенциального заказа;
- dt — таймстемп рекламного события.
Но как из этого массива логов выбрать единственно верную запись для биллинга? Для этого мы фильтруем таблицу и находим строки, где полностью совпадают пользователь, ресторан, поверхность показа и итоговый заказ.
После этого мы берём событие с максимальным таймстемпом (dt). Это и есть реализация модели атрибуции Last-Click. Технически мы считаем, что именно самый последний клик привёл пользователя к покупке.
Как только мы находим эту финальную строку, мы извлекаем из неё значение амнистированной ставки и отправляем запрос в биллинг. Система удерживает стоимость рекламного заказа с ресторана. Цикл сделки замкнулся.
Финал
И вот таким образом мы всего за один квартал запустили собственный рекламный движок. И главное — выполнили все продуктовые и технические требования, которые стояли перед нами на старте.
С инженерной точки зрения мы не просто собрали узконаправленный сервис под нужды Еды. На выходе мы получили гибкую модульную архитектуру и легковесную библиотеку auction_lib. И эти компоненты отлично масштабируются. Теперь мы можем расширять их функционал и спокойно отдавать в пользование соседним сервисам внутри всего Яндекса.
Изначальное ограничение в 200 миллисекунд на ответ аукциона выглядело сурово. Но гибридный геопоиск, надёжный фолбек для ML и быстрый расчёт ставок на C++ сделали своё дело. Мы кратно сократили время работы ручки — до 50 миллисекунд в 99-м перцентиле. Получается, мы не просто встроили сложный рекламный механизм в систему, но и в целом ускорили формирование выдачи для конечного пользователя.
А главное — мы полностью перестроили пользовательский путь для партнёров. Владельцам заведений больше не нужно проходить долгие квесты с отдельными регистрациями и пополнением кошельков. Запуск продвижения и получение первых инкрементальных заказов занимает всего пару кликов.
Когда мы только взялись за написание собственного движка с нуля, идея о том, чтобы сделать это за три месяца, казалась слегка безумной. Но здесь хочется вспомнить слова Нельсона Манделы — оно всегда кажется невозможным, пока ты это не сделаешь.



