
Привет, меня зовут Демид Дорогинин, я разработчик интерфейсов в Яндекс Лавке.
Почти любая интересная фича — будь то ассистент или сложный алгоритм — рождается из личной боли. Ты сталкиваешься с проблемой, видишь, как что-то работает, и думаешь: «Блин, а ведь можно сделать лучше». Наш голосовой помощник — именно такой случай.
Всё началось с простого желания — заказывать продукты быстрее. Открываешь Лавку и вместо того, чтобы долго скроллить историю или копаться в каталоге, хочется просто сказать: «Дай мне две газировки, одну шоколадку и пачку чипсов». И чтобы приложение само, каким-то магическим образом, поняло, какую именно газировку ты берёшь всегда и какие чипсы тебе нужны.
И здесь мы столкнулись с интересным парадоксом. Умная колонка с Алисой уже год или два умела заказывать из Лавки голосом, а наше собственное приложение — нет. Это создавало логичный разрыв в пользовательском опыте: человек привыкал дома давать команды колонке, а потом, оказавшись на улице, открывал приложение, интуитивно искал знакомую иконку микрофона — и не находил её. Стало очевидно — без голосового ввода опыт получается неполным, и это пора было исправлять.
В этой статье я расскажу, как мы прошли путь от идеи, рождённой на внутреннем хакатоне, до production-ready решения. Поговорим о том, как за три дня собрали работающий MVP, почему его архитектура на клиенте была тупиковой и как мы пришли к более надёжной системе на веб-сокетах и тулзах, которая теперь позволяет нам не просто добавлять товары в корзину, а строить по-настоящему умные сценарии.
Три дня на проверку гипотезы
Идея, само собой, уже давно витала, но непонятно было, как к ней подступиться? Если делать всё по-честному, с той планкой качества, которая принята в продуктовых проектах, то разработка голосового помощника — это история в лучшем случае на несколько месяцев, причём с совершенно непредсказуемым результатом. Ты никогда не знаешь, как поведёт себя такой ассистент на старте. Может, ты попросишь его добавить две колы, а он положит в корзину два попкорна — и что с этим делать?
И здесь нам очень повезло — звёзды сошлись. В компании как раз анонсировали внутренний хакатон, темой которого были AI-проекты. Мы подумали, что это идеальный шанс собрать быстрое MVP и понять, стоит ли игра свеч. И раз уж у многих идея голосового ввода уже сидела где-то на подкорке, то команда с нужными компетенциями собралась достаточно быстро. Цель выбрали простую и понятную: за три дня сделать что-то рабочее.
В результате за время хакатона нам удалось написать действительно большой объём кода и сделать вполне рабочую, хоть и не без огрехов, фичу. Человек мог наговорить заказ, ассистент распознавал речь, добавлял товары в корзину и умел по команде переходить на экран оформления.
Но дьявол, как всегда, крылся в деталях реализации. То, что подходит для хакатона, редко годится для продакшена. Давайте разберёмся, как был устроен наш MVP и почему в дальнейших версиях нам пришлось его полностью переделать.
Архитектура: две итерации голосового помощника
Хакатонный прототип выполнил свою задачу — он показал, что идея работает. Но под капотом это было классическое MVP-решение: быстрое, функциональное, но хрупкое и не готовое к реальным нагрузкам.
Версия 1.0 (MVP): SpeechKit и вся логика на клиенте
Мы, естественно, были не первыми, кто хотел интегрировать Алису в своё приложение. Похожие решения уже были у Еды и Облака, но их реализации представляли собой готовые высокоуровневые инструменты. Нам они не подходили из-за жёстких ограничений, поэтому мы решили работать с технологией на более низком уровне.
Сначала была идея взять C++ реализацию SpeechKit. Но она весит 140 мегабайт. Интегрировать её в наш основной бэкенд было сложно, а если тащить на BFF (Backend-for-Frontend) — возникала другая проблема. Наш BFF написан на JavaScript, а значит, эти 140 мегабайт пришлось бы переписывать под него.
Поэтому мы пошли хардкорным путём. Взяли лёгкую клиентскую библиотеку, а сам парсер портировали вручную. Одному из разработчиков пришлось в буквальном смысле переписать 5000 строк кода сложной логики с C++ на JavaScript.
В итоге вся магия обработки переехала на клиент, и архитектурно это стало узким местом. Библиотека общалась с Алисой обычными HTTP-запросами, а наш фронтенд реагировал на ответы походом в бэкенд Лавки. Получалось, что если не внедрять дополнительную логику проверки — отдала нам Алиса что-то новое или нет — то при частоте ответов 60 раз в секунду мы бы с той же скоростью пинговали собственный сервер.
Вот как выглядел этот процесс в деталях:
- Пользователь наговаривал заказ.
- Библиотека отправляла аудиопоток на серверы Алисы и в ответ получала распознанный текст.
- Этот текст тут же подхватывал наш огромный JS-парсер. Его задачей было конвертировать сырые фразы от Алисы в понятные системе данные.
- На выходе мы получали что-то вроде
{ "молоко": 2, "шоколадка": 1 }. - Эти данные улетали на наш бэкенд. К счастью, сервер уже умел работать с таким форматом благодаря текстовому ассистенту, поэтому он просто брал объект и шёл с ним в поиск Лавки.
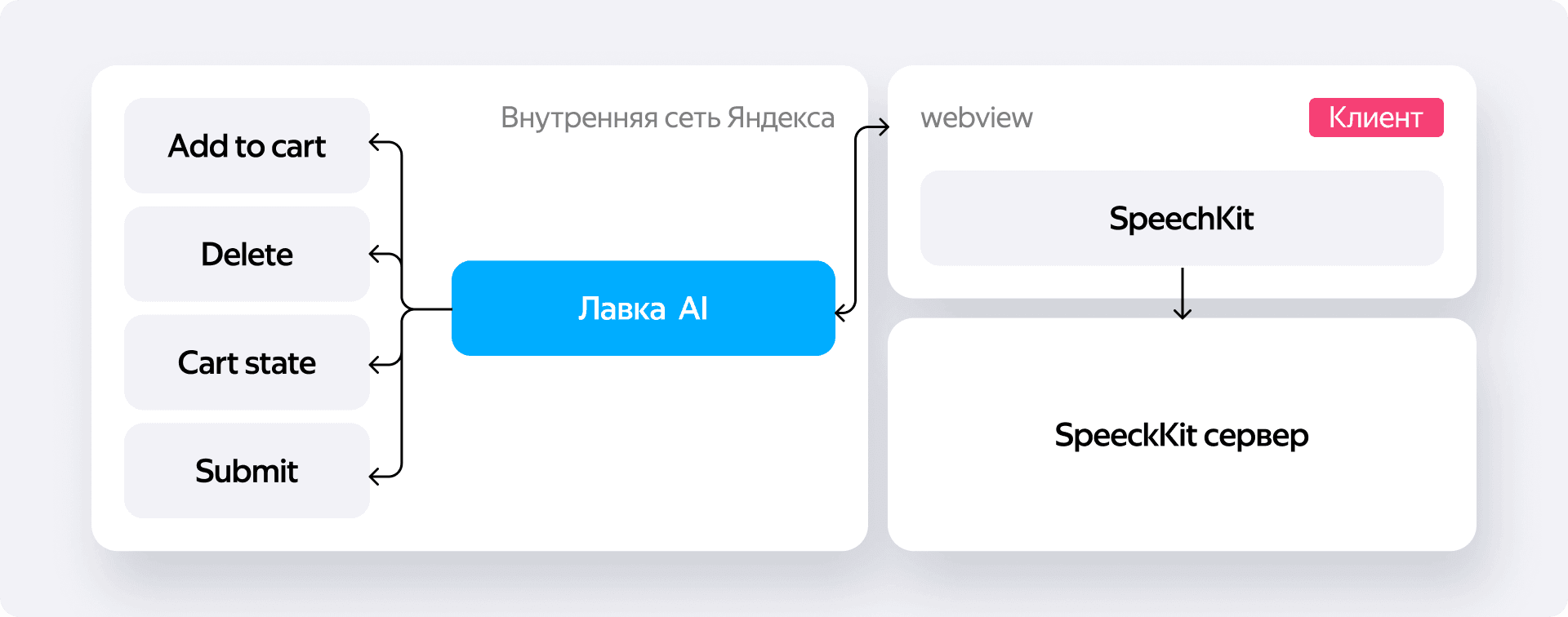
Помимо этого, мы научили систему выцеплять из речи ключевые слова — например, если человек говорил «оформи заказ», мы отлавливали эту команду и сразу переводили его на экран корзины.
Для трёхдневного хакатона это было отличное решение. Но у него было два огромных архитектурных минуса.
- Во-первых, вся логика парсинга скачивалась пользователю. Это не очень хорошо, когда приложение разрастается за счёт такого тяжёлого функционала.
- Во-вторых — и это главное — у нас не было устойчивого соединения с сервером. Мы должны были постоянно отправлять на бэк промежуточные результаты распознавания по мере того, как человек говорил: «добавили молоко», «добавили молоко два», «добавили шоколадку». Это порождало огромный поток запросов. Если бы в этой цепочке что-то пошло не так, мы рисковали мощно заддосить сами себя.
Версия 2.0 (Production): WebSockets, open source и модульность
Стало ясно, что клиентскую реализацию нужно менять на что-то более надёжное и масштабируемое. Для продуктовой версии мы ушли от решения Алисы в пользу опенсорсной библиотеки от OpenAI. Этот переход решил сразу две наши главные проблемы.
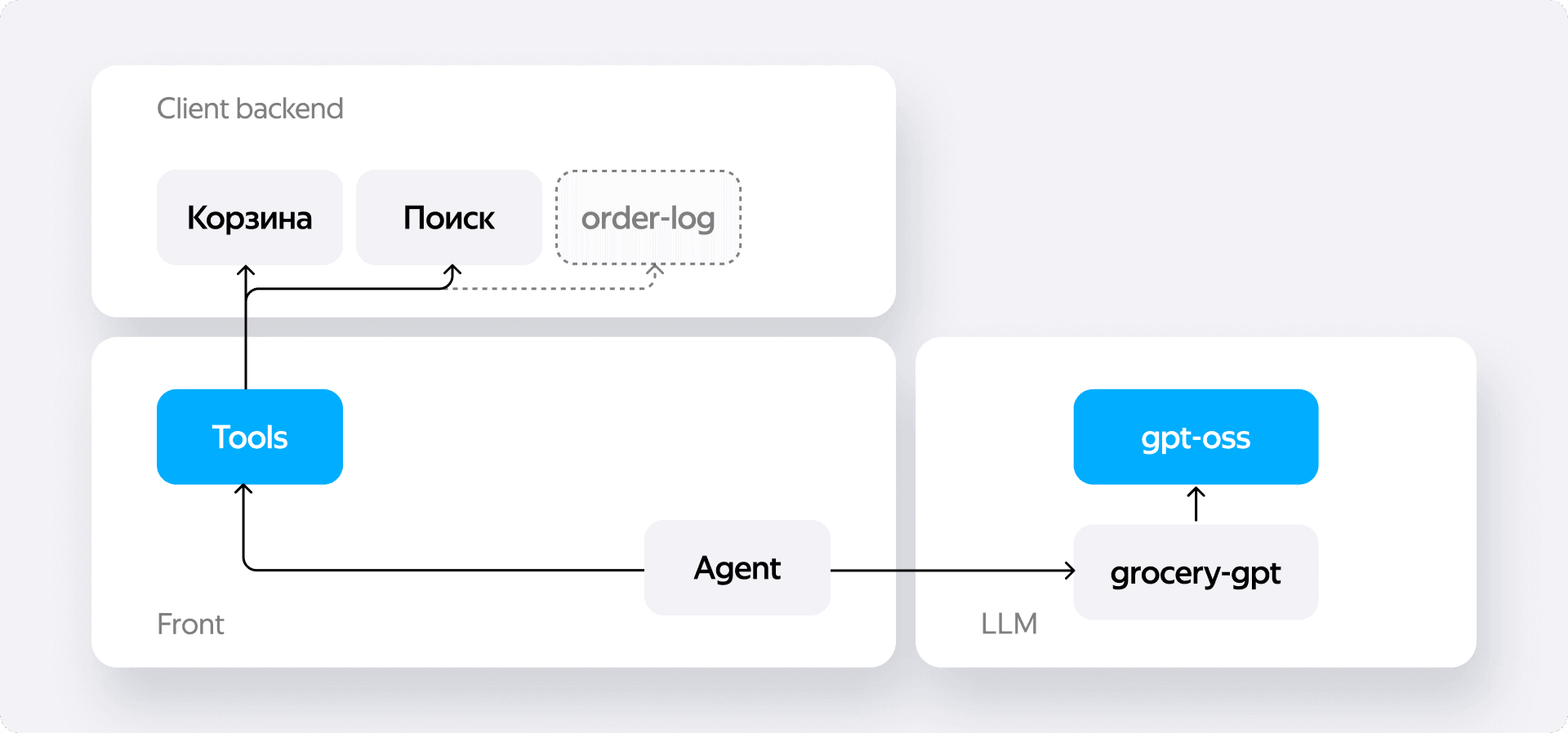
Первое — мы получили постоянный коннект с сервером через WebSockets. Вместо того чтобы бомбардировать бэкенд десятками мелких запросов, мы устанавливаем одно соединение и просто стримим данные по мере их поступления. Это и надёжнее, и эффективнее.
Второе, и это самый главный плюс, — новая библиотека умеет работать с готовыми тулзами. Это модульный подход, который позволяет подключать к AI-ассистенту различные инструменты: пойти в историю заказов, обратиться к поиску, посмотреть содержимое корзины. Такая архитектура делает код гораздо более стройным, понятным и, что важнее всего, расширяемым.
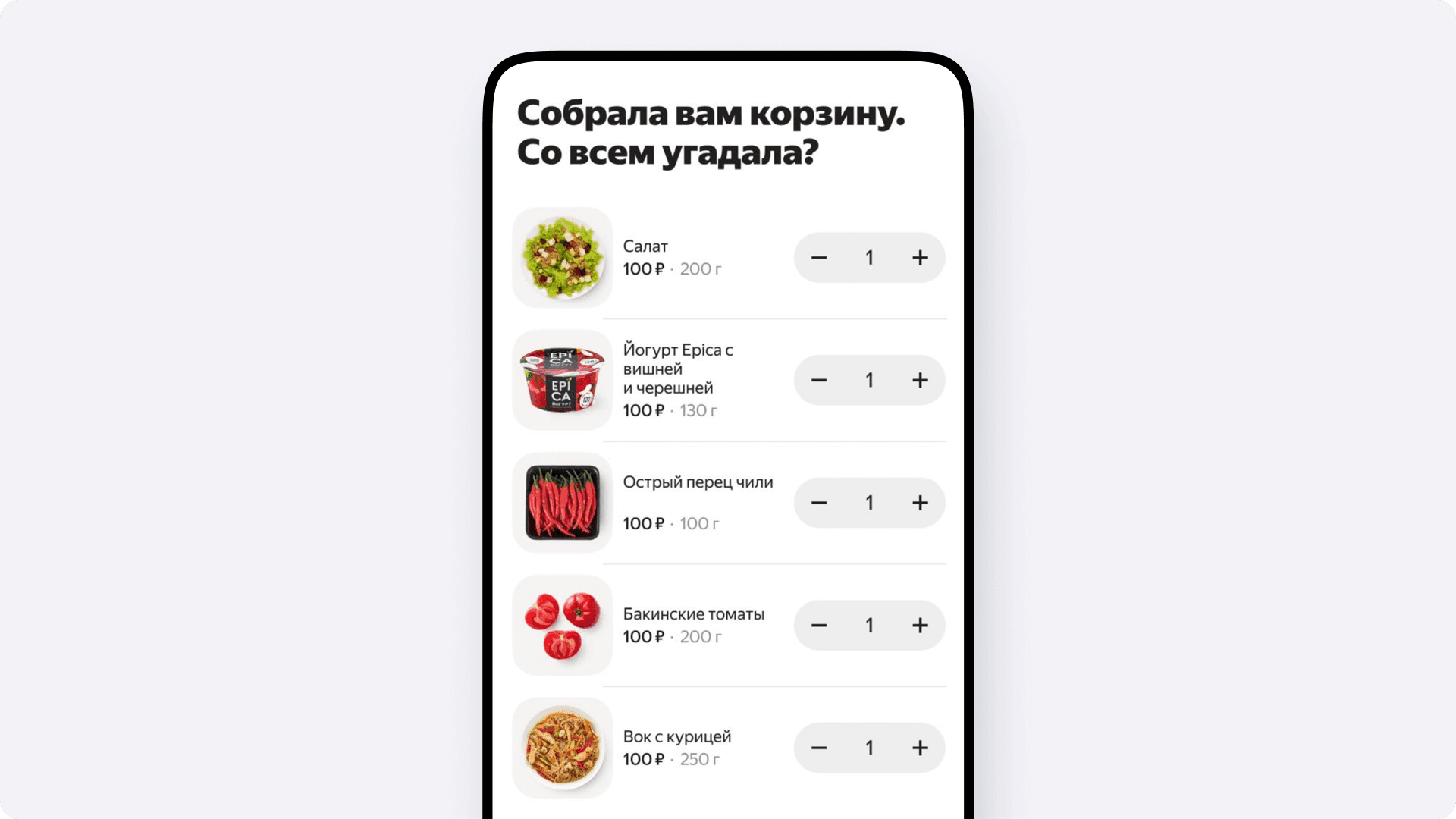
Например, человек говорит: «добавь шоколадку», а у него в корзине их уже десять. Вместо того чтобы слепо добавлять одиннадцатую или перетирать заказ, система может использовать тул для работы с корзиной, понять, что такая позиция уже есть, и просто увеличить её количество.
Конечно, и здесь не обошлось без своих сложностей. Например, наш бэкенд изначально не умел отправлять веб-сокеты на сторонний сервер — только читать с них. Поэтому нам потребовались свои надстройки. Но это были уже решаемые инженерные задачи, а финальная архитектура получилась куда более адекватной и готовой к развитию.
От MVP к продукту
Чтобы наша идея и наш MVP после хакатона не уехали пылиться на полку, а превратились в полноценную фичу, им нужна была поддержка.
И здесь нам снова повезло. Инициатива пошла не снизу вверх, а наоборот. Идея очень понравилась нашему руководителю, Никите Толстому, и именно он стал главным драйвером её развития. Он собрал всю хакатонную команду и поставил вопрос ребром: «Окей, вот у нас есть прототип. Что нам нужно, чтобы дотащить его до прода — хотя бы для начала раскатить на команду, а потом и на пользователей?»
Это был тот самый момент, когда мы все вместе сели и продумали, чего именно не хватает MVP для реальной жизни, наметили план доработок и превратили наброски в полноценный проект.
И если на прототип у нас ушло три дня, то работа над версией, которую не стыдно будет выкатывать на пользователей, займёт, по нашим оценкам, не меньше двух месяцев. Это наглядно показывает разницу между быстрой проверкой гипотезы и созданием стабильного, масштабируемого решения.
Сейчас проект живёт в духе стартапа внутри Лавки. Готовая фича раскатана на очень ограниченную аудиторию — даже не на всю команду, а на нескольких человек, которые активно ею пользуются, тестируют и дают фидбэк. Это позволяет нам в безопасной среде отлаживать механику и готовиться к более широкому запуску.
Что дальше?
Сейчас наш главный фокус — довести до ума основную функциональность. Мы решаем очевидные, но важные задачи. Например, что делать, когда человек говорит: «Добавь хлеб», а его разновидностей в Лавке десятки? Идеальный флоу, к которому мы стремимся, выглядит так: сначала ассистент заглядывает в историю заказов — если пользователь постоянно берёт белый нарезной батон, то, скорее всего, он и нужен. Если истории нет, мы предлагаем на экране несколько релевантных вариантов, и человек может голосом уточнить: «добавь первый» или «добавь Бородинский».
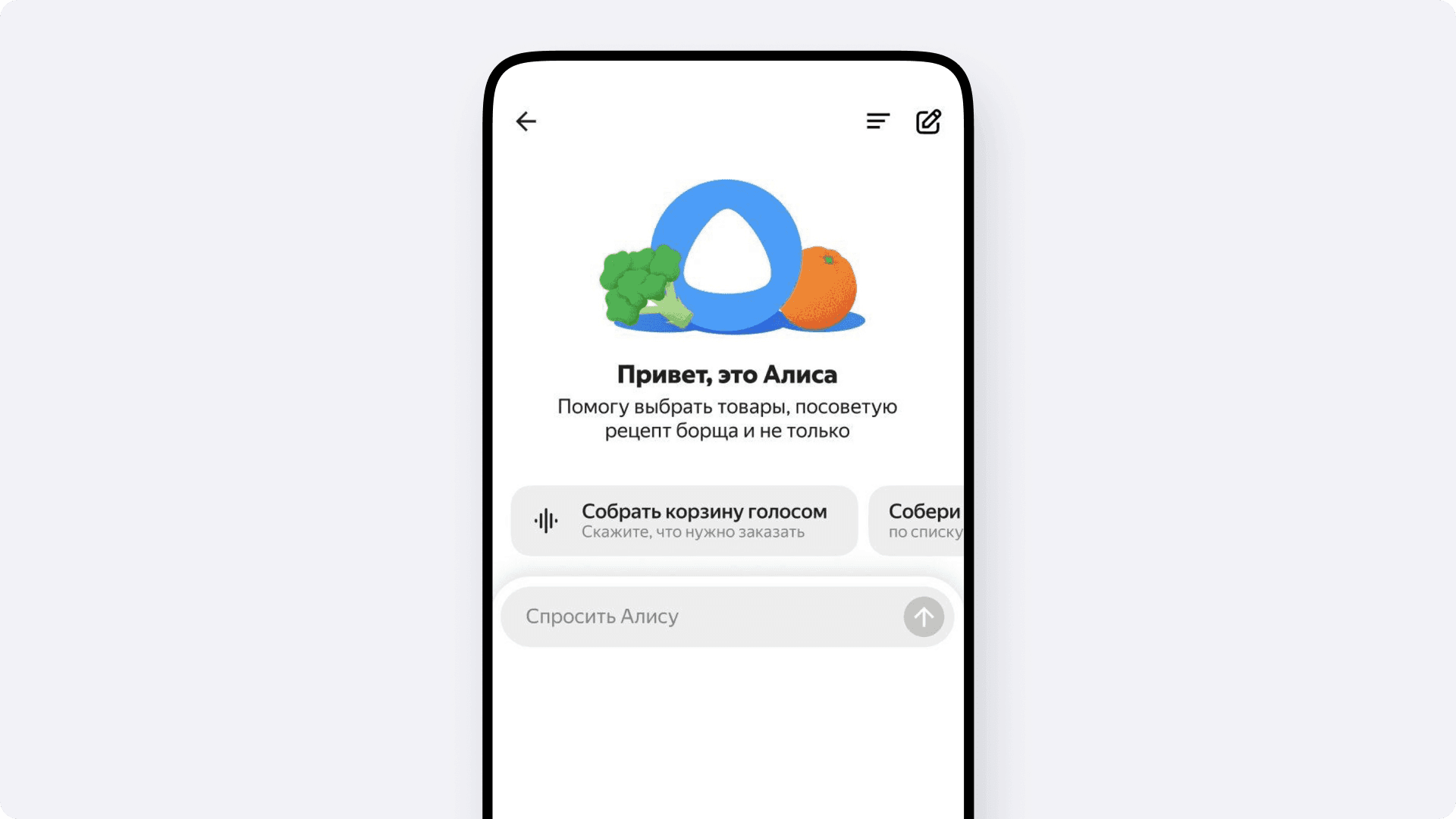
Но настоящее развитие ассистента начнётся тогда, когда мы выйдем за рамки простых команд. Анализируя опыт нашего текстового AI-помощника, мы видим, что часто пользователь и сам не знает, чего хочет. Запросы вроде «добавь все ингредиенты для борща» или «собери корзину на неделю для семьи из трёх человек» — это реальные потребности, которые мы хотим закрыть. Только представьте: вы просто говорите в телефон «закажи мне всё для солянки», и заказ уже едет к вам.
И здесь наша архитектура с тулзами, на которую мы перешли, раскрывает свой главный потенциал. Эта модульность позволяет нам легко расширять возможности. Нужен инструмент для работы с рецептами? Мы просто его подключаем, и это никак не ломает остальной функционал. Если какая-то фича окажется невостребованной — её так же легко можно отключить.
Пока что ассистент доступен очень ограниченному кругу людей, но в скором времени мы планируем выкатить его на всех пользователей. Мы заложили надёжный фундамент, и теперь начинается самое интересное — строить на нём по-настоящему умный продукт.



