
Привет! Меня зовут Валера Ильин, я руковожу группой компьютерного зрения и бизнес-логики робототехники Яндекс Маркета. Сложив два и два, можно понять, что рассказ будет о том, как мы делаем компьютерное зрение на складе Маркета.
Зачем нам роботы
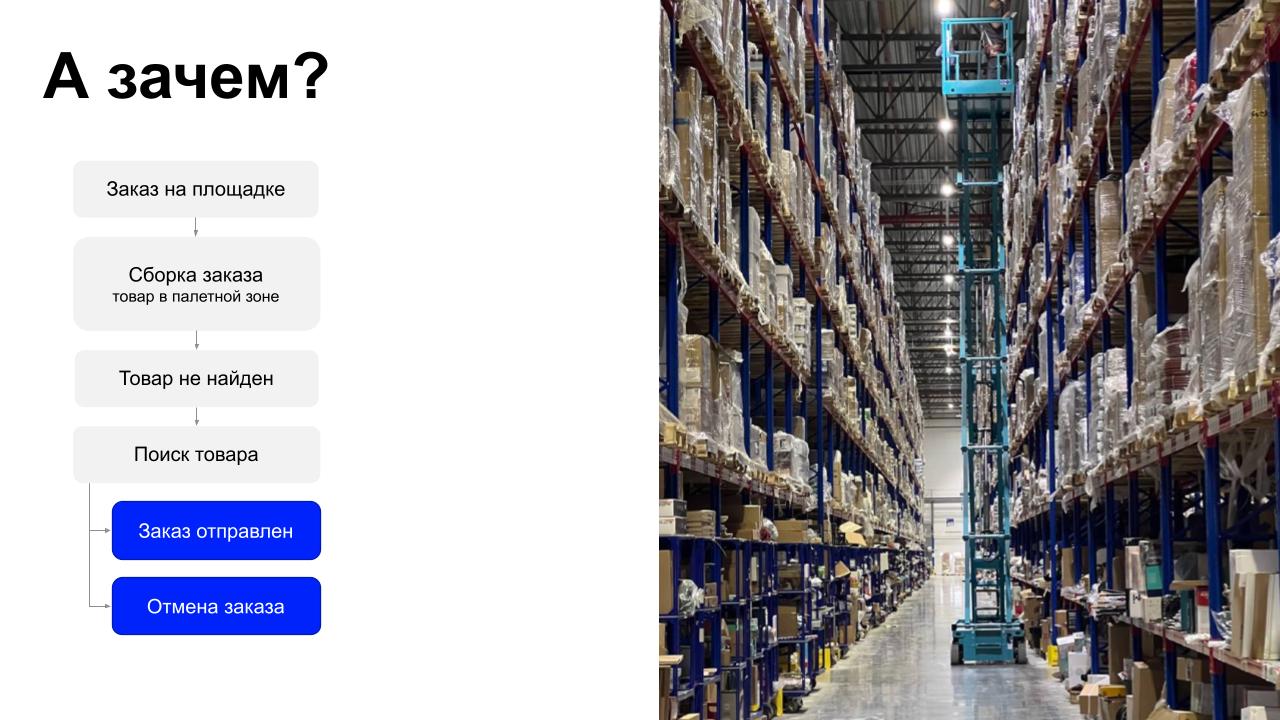
По всем логистическим фронтам идёт повальная автоматизация-роботизация. Её цель — повысить скорость и надёжность бизнес-процессов. Первым процессом, который мы доверили роботу, стала инвентаризация.
Представим пошагово, как работает склад любой торговой площадки, будь то Яндекс Маркет или OZON.
- Вы делаете заказ и этим запускаете весь процесс.
- Начинается сборка вашего заказа. Сборщик получает задание и собирает ваш заказ в палетной зоне, отыскивая товары на полках.
- Если товара нет на палето-месте, начинается поиск.
- Если в течение четырёх часов товар нашли, заказ отправят. Если не нашли, отменят. Это и операционные, и репутационные издержки, которые нам очень хотелось бы сократить.

Чтобы минимизировать эти проволочки, на больших складах реализован процесс циклической инвентаризации.
При циклической инвентаризации человек ходит по складу и сканирует товар в ячейках, указанных в маршрутном листе. Таким образом значения попадают в систему. Он может это делать при помощи ричтрака, снимая каждый товар для сканирования, или ножничного подъемника. Производительность такого человека — около 300 палето-мест за смену. Всего мест — 20 тысяч, и сотрудники склада завершают один цикл инвентаризации примерно за 3 месяца. Если время жизни палеты на складе существенно меньше этого срока, то такая операция не помогает устранить все ошибки размещения, и нужно более быстрое решение, например робот.
Наша машинка
Честнее всего рассказать о том роботе, который уже работает на складе и приносит пользу. Это робот-инвентаризатор Spectro, которого мы начали разрабатывать примерно полтора года назад на базе текущих процессов и инфраструктуры склада Яндекс Маркета в Софьино.
Первым делом мы приехали на склад и увидели, что для идентификации на палетах уже есть этикетки, а на палето-местах — опорные метки. Само собой напросилось решение: давайте создадим автономное устройство, которое будет носиться вдоль стеллажей, сканировать палето-места самостоятельно, определять ячейку и палету в ней.
Хочется представить дрон, который порхает вдоль полок, ориентируясь по QR-кодам. Но я когда-то работал в «летающем» стартапе, который делал дронов, и знаю, с какими усилиями в плане разработки это может быть связано. К тому же решение будет не таким безопасным, как хотелось бы, и придётся останавливать операции в аллее на время работы дронов. Мы выбрали более простой и надежный вариант, который по всем параметрам выигрывал у концепции дронов.

Spectro — автономная телега два на один метр с 12-метровой мачтой. Такой робот самостоятельно объезжает весь складской блок площадью 20 тысяч квадратных метров за два часа. Не бойтесь, людей он не сбивает, а притормаживает рядом с ними, у него есть лидар.
Робот сканирует 20 тысяч палет в час и за сутки объезжает склад четырежды. Всего на Маркете у нас 3 робота. Суммарный накат уже перевалил за 10 тысяч километров.
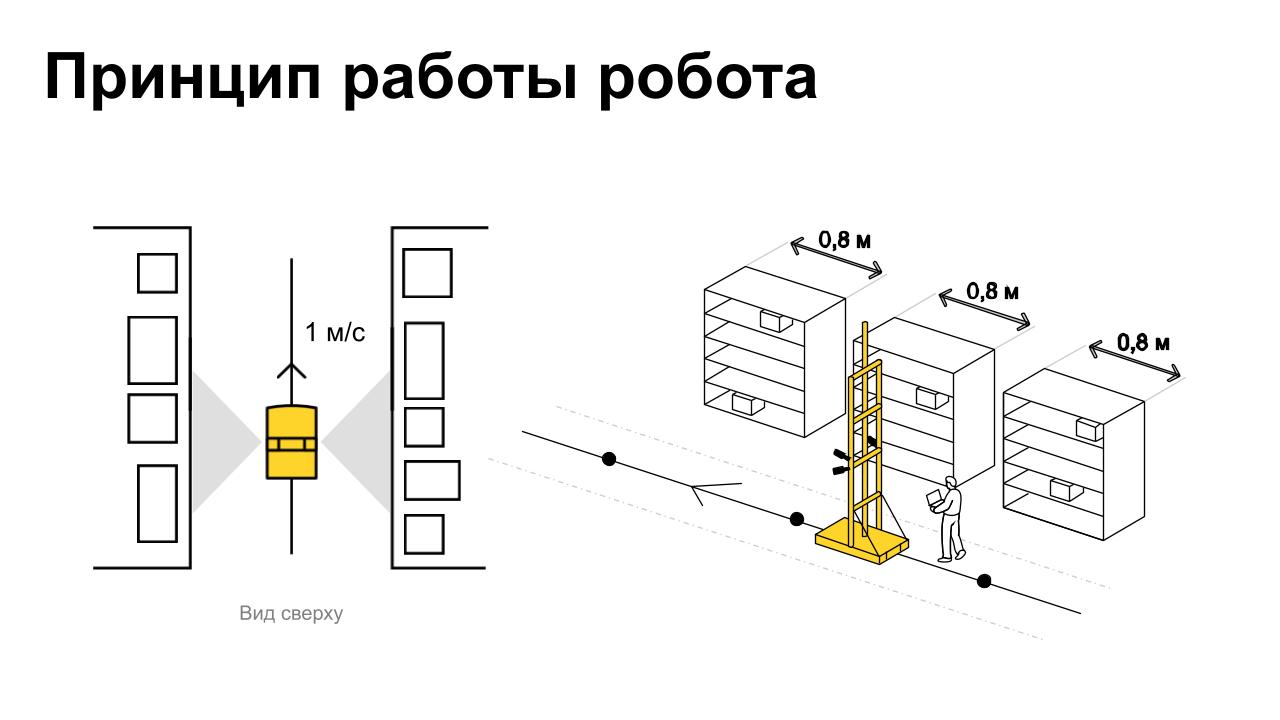
Первые тесты показали, что целевая скорость нашего робота — один метр в секунду. Скорость обусловлена прежде всего тем, что при запуске в такой сложной среде за роботом нужно ходить, чтобы отлаживать вручную, а 1 м/с — это наиболее комфортная скорость для разработчика. В дальнейшем — и для оператора.
Складской стандарт палето-места при этом — 80–90 см, то есть мы должны сканировать одно место быстрее, чем за секунду.
Выбор камеры

Первый вопрос в разработке компьютерного зрения — выбор камеры. Нам, как стартаперам с микрокомандой, хотелось взять готовое решение, чтобы быстро перейти к разработке собственно зрения.
Перед нами было три пути:
- Взять готовую IP-камеру типа Hikvision или уличных камер видеонаблюдения.
- Взять камеру у соседей по Яндексу, которые делают беспилотный транспорт. Классная коллаба с использованием внутреннего продукта.
- Взять промышленную камеру, которых на рынке масса.
Расскажу о каждом варианте подробнее.
1. IP-камеры

Плюсы IP-камер — невысокая стоимость, настроенные из коробки оптика и софт, а также простое подключение по Ethernet PoE.
Два главных минуса — задержки передачи данных по протоколу RTSP, а также rolling shutter, то есть искажение изображений при съёмке на ходу. При скорости в 1 м/с оба минуса критичны.
Менее критичные минусы — габариты и крепления. Камера на картинке весит 1–2 килограмма, её страшно подвешивать на высоте 11 метров, ведь там всё качается.
2. Камера с автопилотов Яндекса

Камера автопилотов — внутренний продукт Яндекса для установки в беспилотниках.
Плюсы: это готовое решение, есть производство и люди, которые уже в теме.
Минусы: нужно дорабатывать оптику и сенсор. А ещё — такую камеру не поставишь на высоту 11 метров, её устройство сериализации-десериализации (преобразования потока данных) не позволяет работать с таким длинным кабелем.
3. Промышленная камера

Мы остановились на промышленной камере. Здесь есть всё необходимое: и гибкость настройки, и удобство подключения. Глобальный затвор, то есть одновременное считывание всех пикселей с матрицы, позволяет избежать rolling shutter. Столкнулись с проблемой с оптикой, но решили и её.
Нас смущал кастомный SDK, особенно у китайских производителей, где из-за недоделок могли потребоваться патчи. И ещё один минус — дороговато. Но стоило того.

Мы поставили на робота 10 промышленных камер на разной высоте, по 5 с каждой стороны. Подсчитали, что пяти кадров в секунду с каждой камеры нам будет достаточно. Справа на картинке — примеры боевых фото стеллажей.
Пять кадров в секунду с разрешением 1104 на 2448 — это видеопоток около 100 Мбит/с на камеру. Солидный видеопоток, поскольку воткнуть в одну гигабитную карту все 10 камер уже сложно. В связи с этим на первом нашем решении мы использовали два вычислителя, от чего впоследствии отказались. Также было полезно, что наши камеры поддерживали программную и аппаратную синхронизацию, о чем расскажу дальше.
Обработка кадров
Этапов обработки кадров всего шесть:
- Получение кадра и формирование пакетов/батчей.
- Привязка кадра к определённому палето-месту.
- Определение отсутствия/наличия палеты на палето-месте.
- Детекция расположения меток на фото.
- Декодинг меток.
- Агрегация и регистрация результатов.
Далее — про каждый этап отдельно.
1. Получение кадров
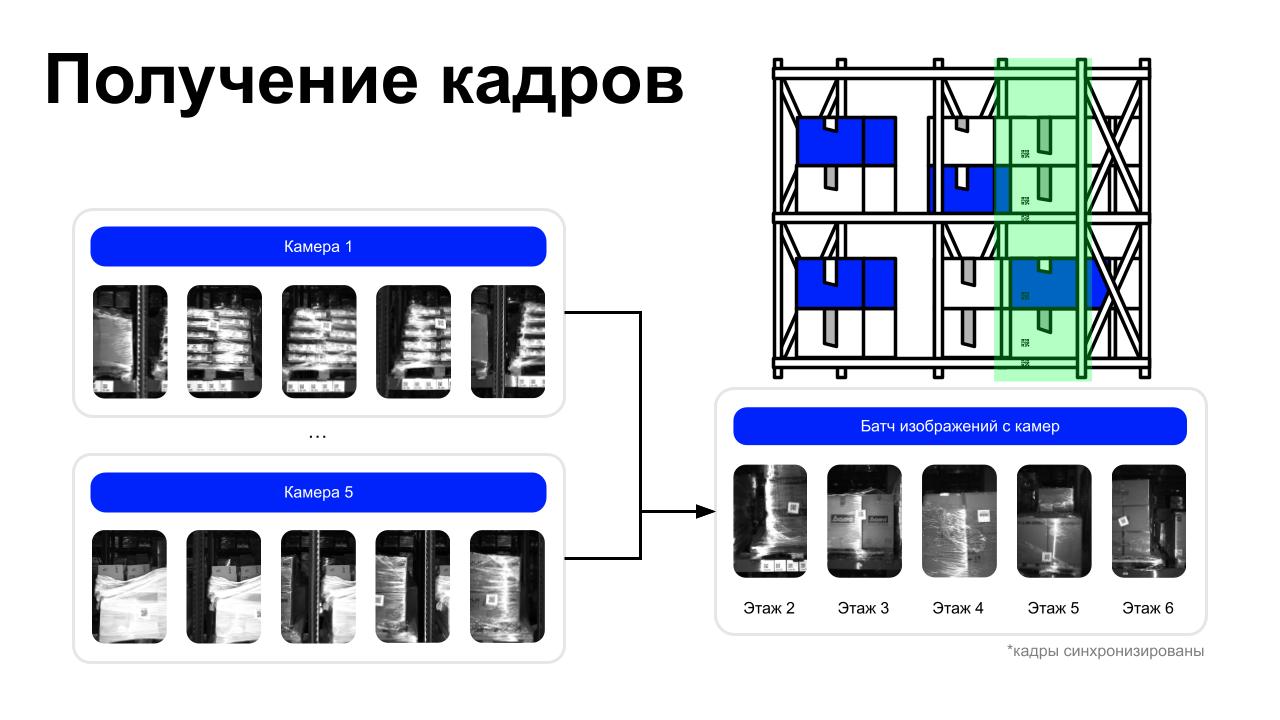
Батч — это пять одновременных фото с одной стороны робота, которые мы тащим по всему пайплайну. Это снимок всего стеллажа от пола до потолка, разбитый на пять частей.
Мы сразу же решили, что будем делать эти фото камерами, отправлять их друг за другом в очередь, и для наших задач хватит программной синхронизации. На старте мы были наивными.
2. Определение места робота
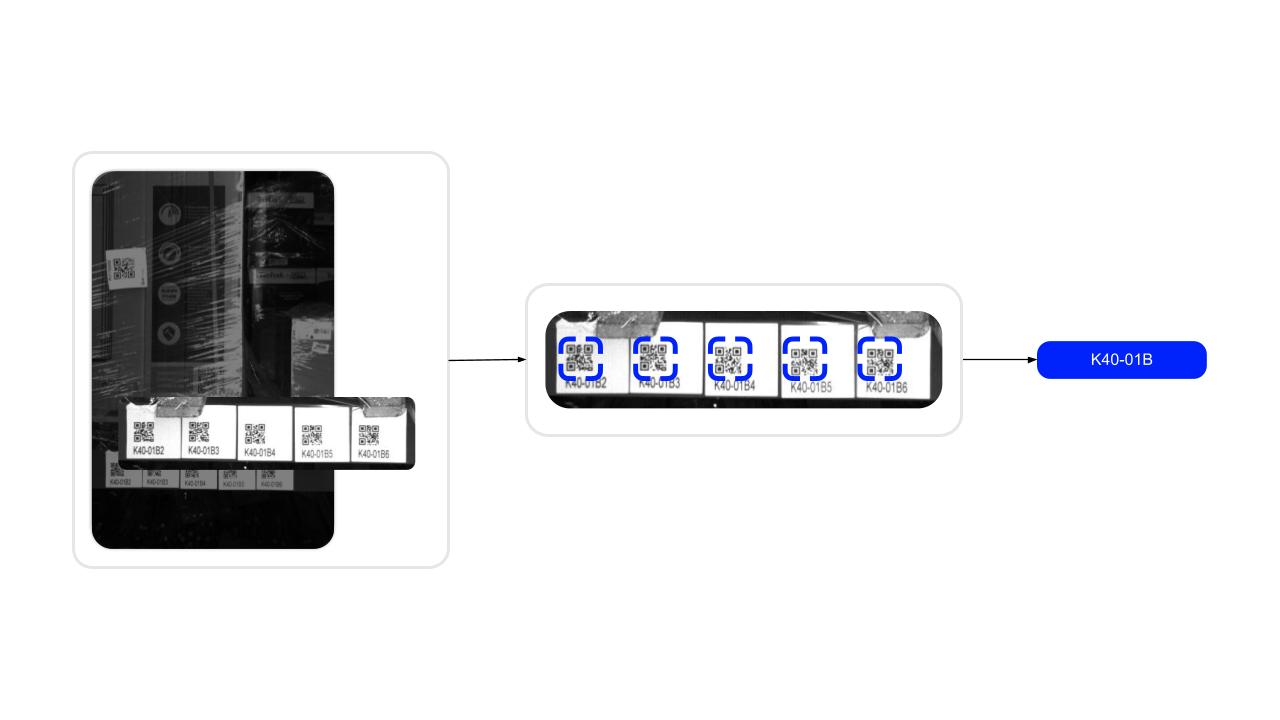
Палето-место мы опознаём по готовой инфраструктуре склада — QR-меткам на полках. Это не rocket science, и мы решили, что для распознавания кодов хватит обычного опенсорсного QR-декодера. Помните про наивность? Для датасетов его и правда хватило, но донеся это решение до робота, мы столкнулись с проблемами.
3. Определение наличия палеты на палето-месте

Узнав адрес палето-места, надо понять, лежит что-то на нём или нет.
Два изображения слева — это типичное отсутствие палеты. Изображение справа — типичное наличие. Работник склада видит это элементарно и даже не задумывается, пусто на полке или нет. Нам же для робота нужно подключать машинное обучение.
Чтобы распознавать наличие или отсутствие палеты на полке, мы сделали фотки, разметили данные («есть палета — нет палеты»), обучили модель… и она не сошлась. Возникла традиционная проблема: толокеры, делавшие разметку, похоже, сами не понимали, пустует место или нет. На среднем фото, например, видно, что палета, кажется, присутствует. Но это не та палета — она лежит в заднем ряду. На таких изображениях мы ловили много ложноположительных результатов.
Проект пришлось переформатировать, и после этого модель сошлась. Сейчас мы используем этот же подход в разметке на новых объектах, и ошибок практически нет.
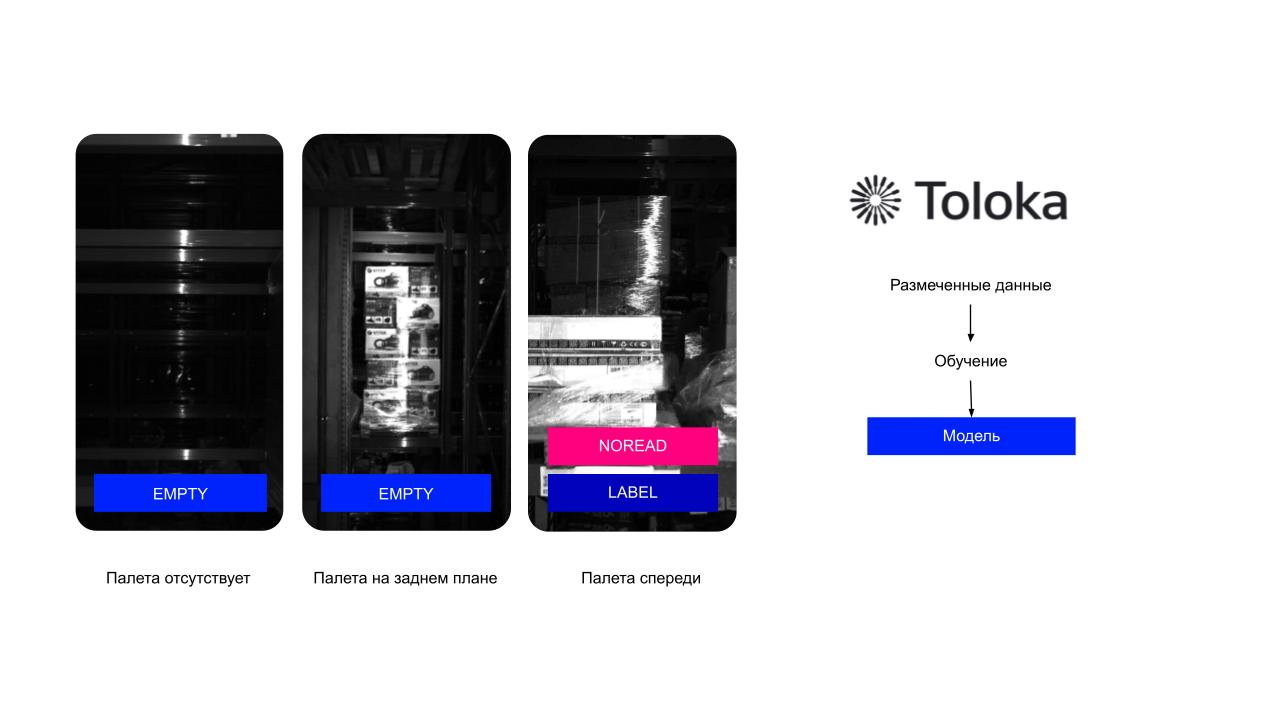
В бизнес-логике мы предусмотрели три варианта возможных результатов сканирования нашей системы:
- EMPTY — палета отсутствует;
- NOREAD — палета перед нами, но отсканировать этикетку на ней мы не смогли;
- LABEL — сканирование этикетки прошло успешно.
4. Детектор меток

Коды нужны, чтобы идентифицировать палеты. На складе уже была инфраструктура штрихкодов, и в первый же приезд мы договорились с Маркетом, что поменяем штрихи на QR-коды, которые распознаются лучше на дальней дистанции (спойлер — сейчас наши роботы справились бы и со штрих-кодами). За 40–50 дней, пока мы делали железную оболочку робота, склад обновился, и мы стали запускать первые тесты.
Оказалось, что наш опенсорсный QR-декодер не работает «из коробки». Например, не умеет обрабатывать очень большие фото, где QR-код занимает считаные проценты их площади.
И мы решили обучить одноклассовый детектор меток поиску QR-кодов на фото, чтобы в дальнейшем их распознавал декодер.
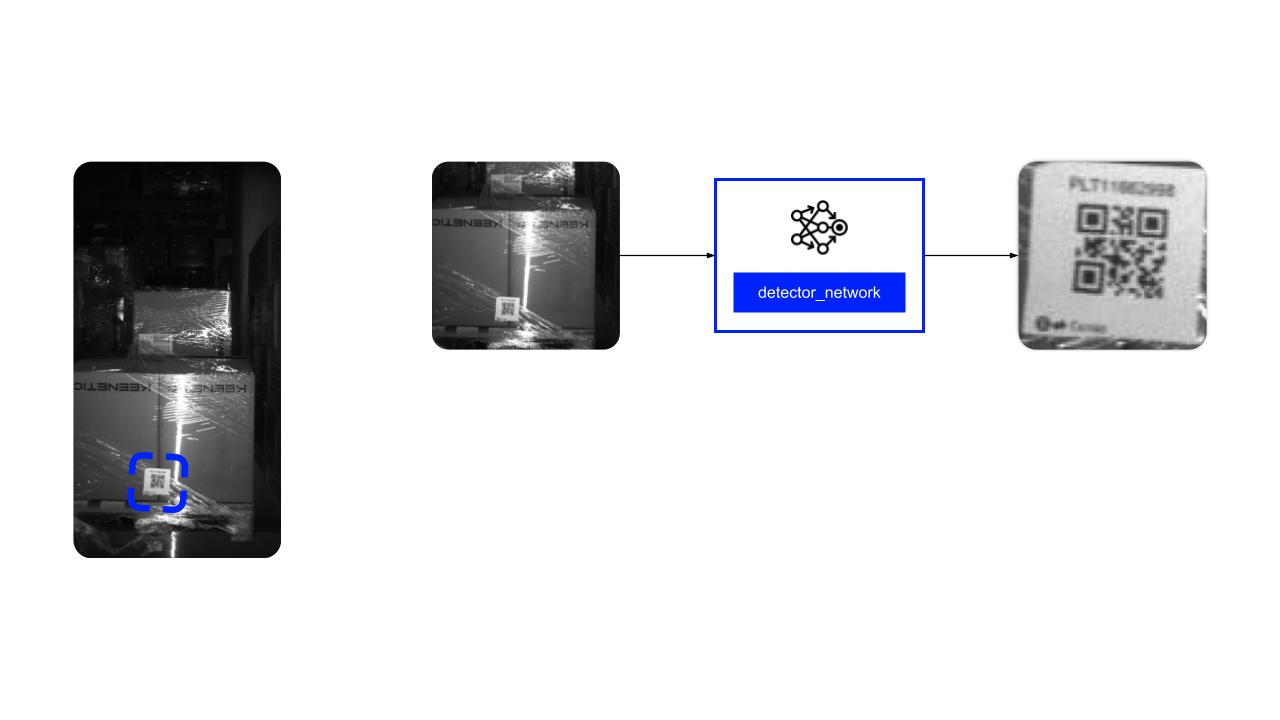
Большие фото снова отдали толокерам для разметки. Толокеры разметили тонны картинок. В итоге мы получили модель, которая помогает отыскать не только красивые метки, но и этикетки, которые распознать не получится, как бы мы ни старались, потому что они замяты или испорчены.
Кажется, пайплайн готов? Но при запуске на роботе мы упёрлись в перфоманс. Предсказуемое решение номер ноль — уменьшить модель — не сработало: модель и так была небольшая.
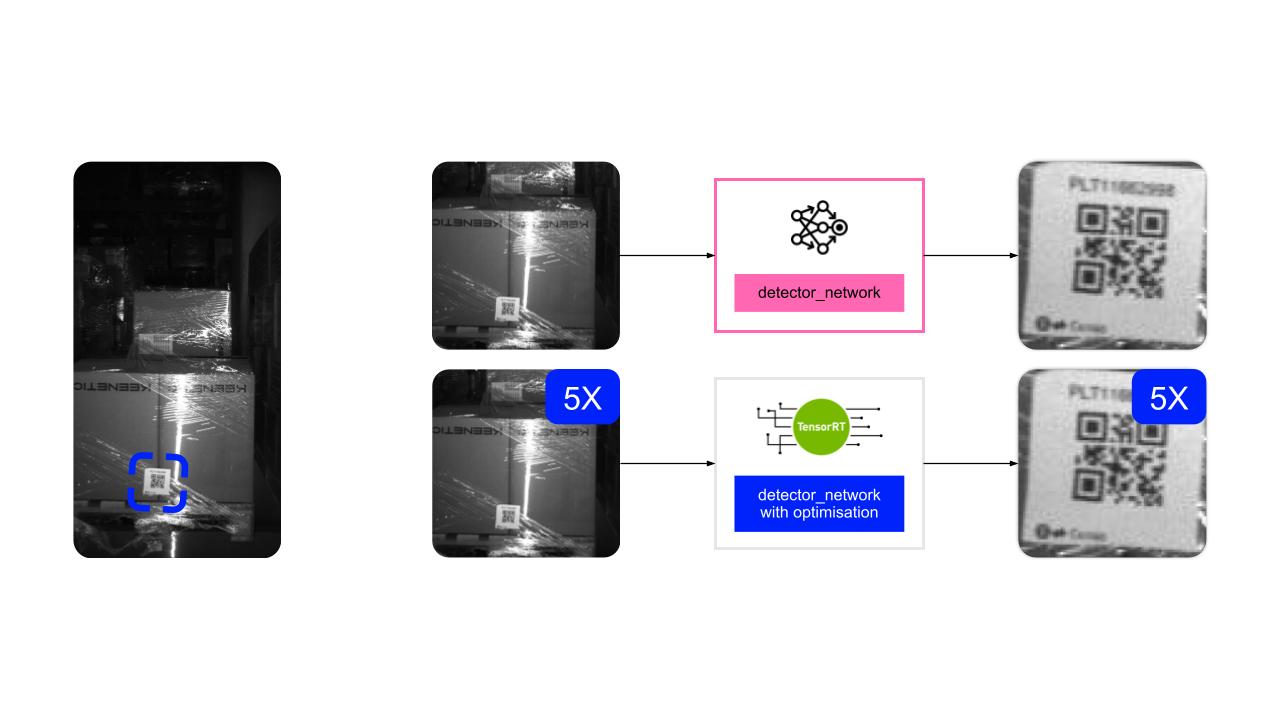
Пришлось оптимизировать софт и инференс под нашу платформу Jetson: добавили батчевание и инференс на TensorRT. Перформанс полечили и готовы запускаться.
5. Декодер меток

С декодером, кажется, всё понятно, но он, к сожалению, не справляется со всеми метками без препроцессинга. Это издержки готового решения, под которые приходится дорабатывать зрение робота, что также влияет на перфоманс. Но есть откровенно плохие метки, которые никакой препроцессинг не лечит, такие записи мы относим к классу NOREAD.
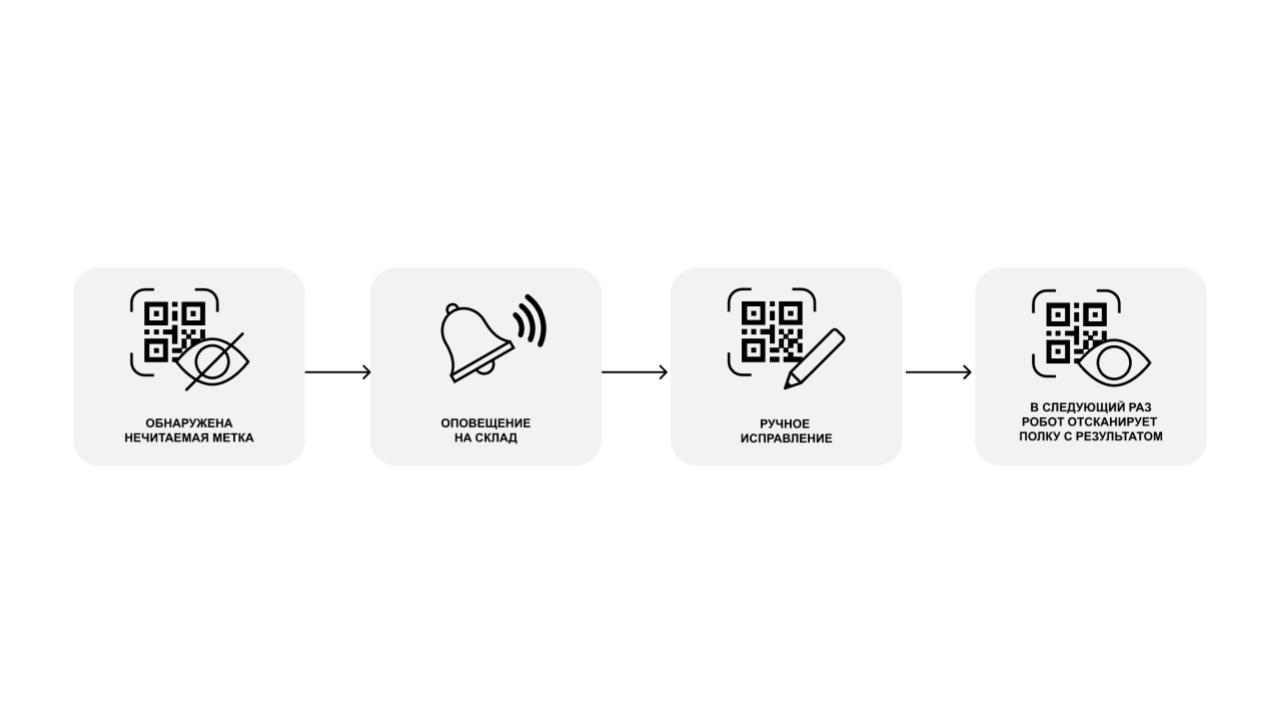
Для NOREAD-записей мы выстроили процесс обратной связи со складом: формируем тикеты на исправление нечитаемых этикеток, сотрудник склада меняет или переклеивает метку, и в следующие проезды у нас всё хорошо.
6. Агрегация и сохранение результатов

Агрегация результатов — финальный этап, когда мы принимаем решение о регистрации палеты по набору кадров, привязанных к одному и тому же месту. Здесь всё тривиально и построено на эмпириках, однако бывают интересные моменты, когда этикетки свисают с соседних мест и портят всю малину.

После агрегации результатов мы их сохраняем. На роботе — собственный бэкенд с платформой x86. Написать бэкэнд для сохранения результатов было интересно, поскольку мы создавали его в первую очередь для отладки. В итоге получили решение, которое должно было «жить» рядом с модулем управления роботом и телеметрией, обрабатывая как минимум 10 RPS с картинками.
Первые грабли
Целевая метрика, которую мы выбрали для тестов, — ReadRate. Это отношение успешных сверок к общему количеству палето-мест. Для подсчёта человек отправлялся на склад и вручную сканировал все ячейки в одной аллее, а мы сверяли эти результаты с данными, которые распознал робот.
Первый запуск робота показал ReadRate, равный 15%, то есть робот распознал меньше 1/6 палет, распознанных человеком. Катастрофа. А мы-то уже планировали открывать шампанское, поскольку на датасетах всё было хорошо.

Что случилось? На картинке выше — идеальный мир, где все коды детектированы и распознаны верно. Этот мир мы видели на датасетах.

А это мир реальный. Здесь в качестве QR-кода мы пытаемся распознать какое-то бревно. Выяснилось, что у нашего опенсорс-декодера внутри тоже есть собственная сетка детекции QR-кодов. И он точно так же локализует область и выполняет декодинг.
Сталкиваясь с трудностями, декодер внутри себя пытается итеративно улучшать фото и применять фильтры, пока декодинг не удастся. И если, например, мы даём картинку, на которой априори QR-кода нет, она обрабатывается намного дольше обычного.
Мы стали анализировать, что мы вообще распознаём, и увидели, что детектим в основном всякую ерунду.
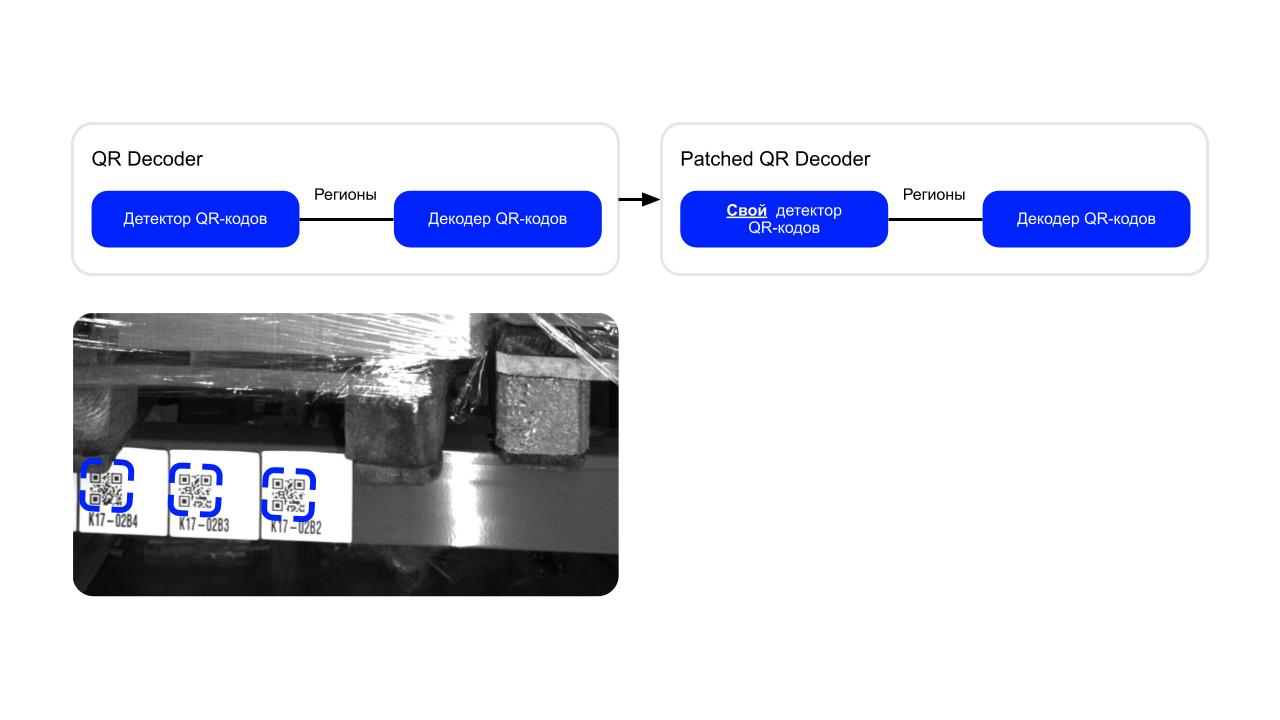
Решение — пропатчить декодер так, чтобы оставить в нём исключительно декодер без детектора, но гарантировать, что ему подаётся адекватное изображение.
Мы отключили внутренний детектор, дообучили свой внешний детектор, и всё удалось, началось итеративное улучшение.
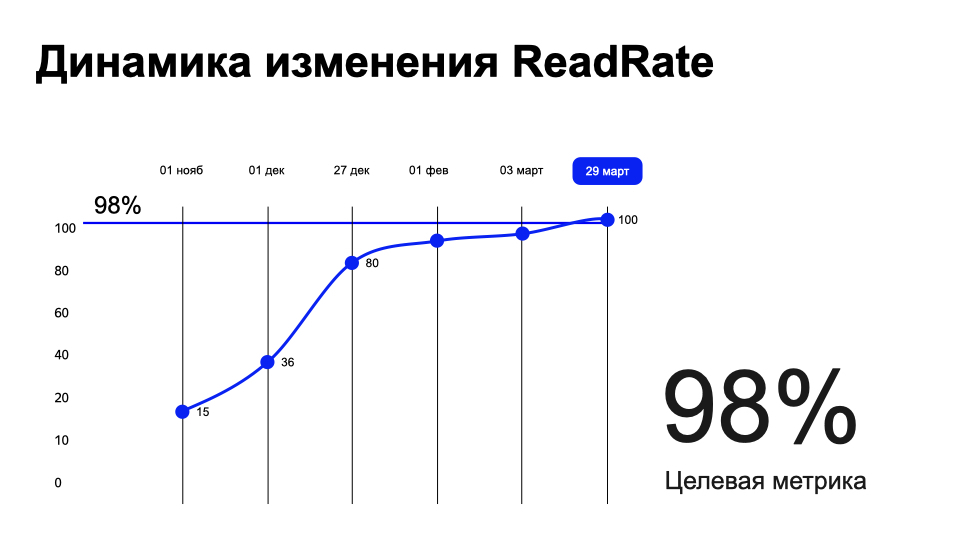
Успех доказывается графиком роста ReadRate за 5 месяцев разработки. Целевую метрику — условно, 90% и выше — мы выставляли себе сами, но после общения с Маркетом поняли, что она должна быть не ниже 98%, потому что только тогда от робота будет польза и Spectro выпустят в прод.
Первые месяцы шла борьба за перфоманс. А когда мы дошли до 90%, вскрылись глубокие проблемы с синхронизацией кадров.
Вторые грабли
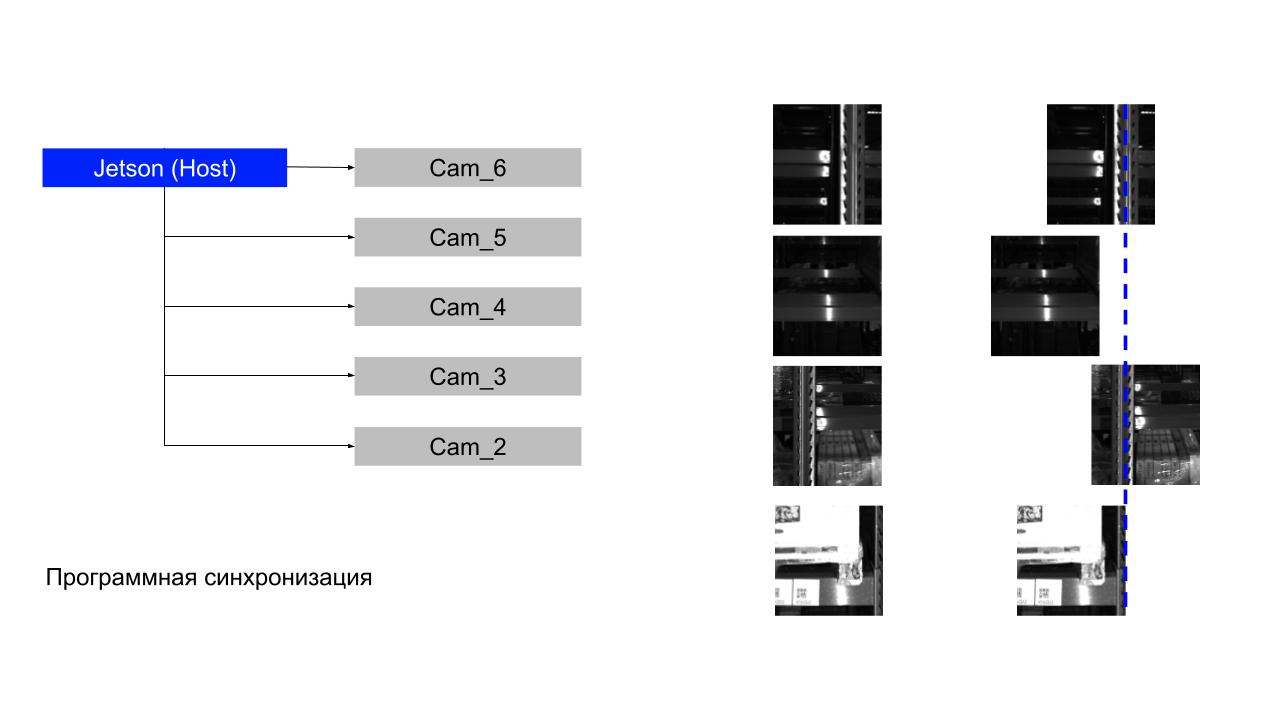
Программная синхронизация у нас строится на очередях, и оказалось, что мы используем неверную схему.
Jetson как управляющее устройство получал кадры со всех камер и должен был их выстроить в единую вертикаль. Колонка посередине — то, что мы от него получали, хотя очевидно, что кадры должны быть выровнены иначе (как в примере справа). Это заметно даже по балке, которая показана синим пунктиром.
Для начала мы на уровне SDK камеры синхронизировали кадры программно и получили минимальную задержку между ними — всего 40 мс. На той платформе, на которой мы запускались, это было уже достижением. Но на подходе была вторая версия нашего робота, и мы решили вложиться в аппаратную синхронизацию.
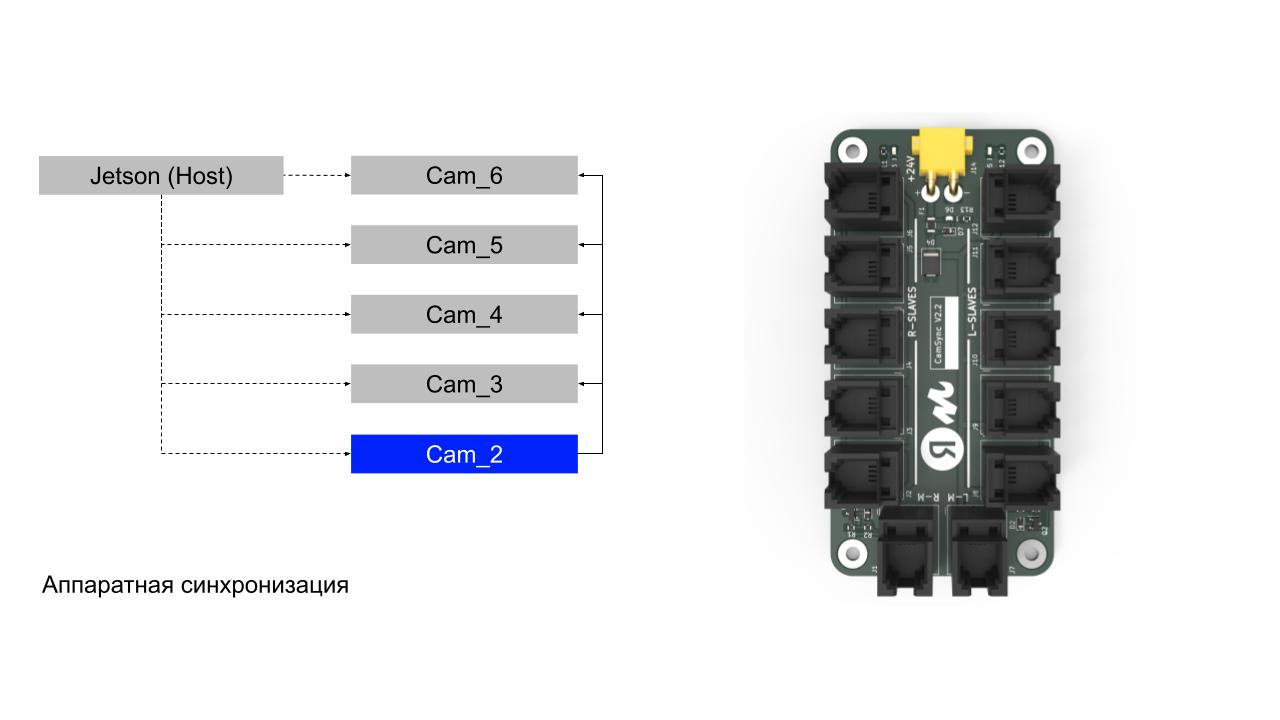
Ребята из соседней команды развели и собрали нам плату синхронизации. Суть в том, что мастер-камера раздаёт синхросигнал на остальные камеры, и итоговая задержка в этом случае — не более 2 мс. Всеми этими доработками мы добились ReadRate в 100%!
Итоги и бизнес-эффект
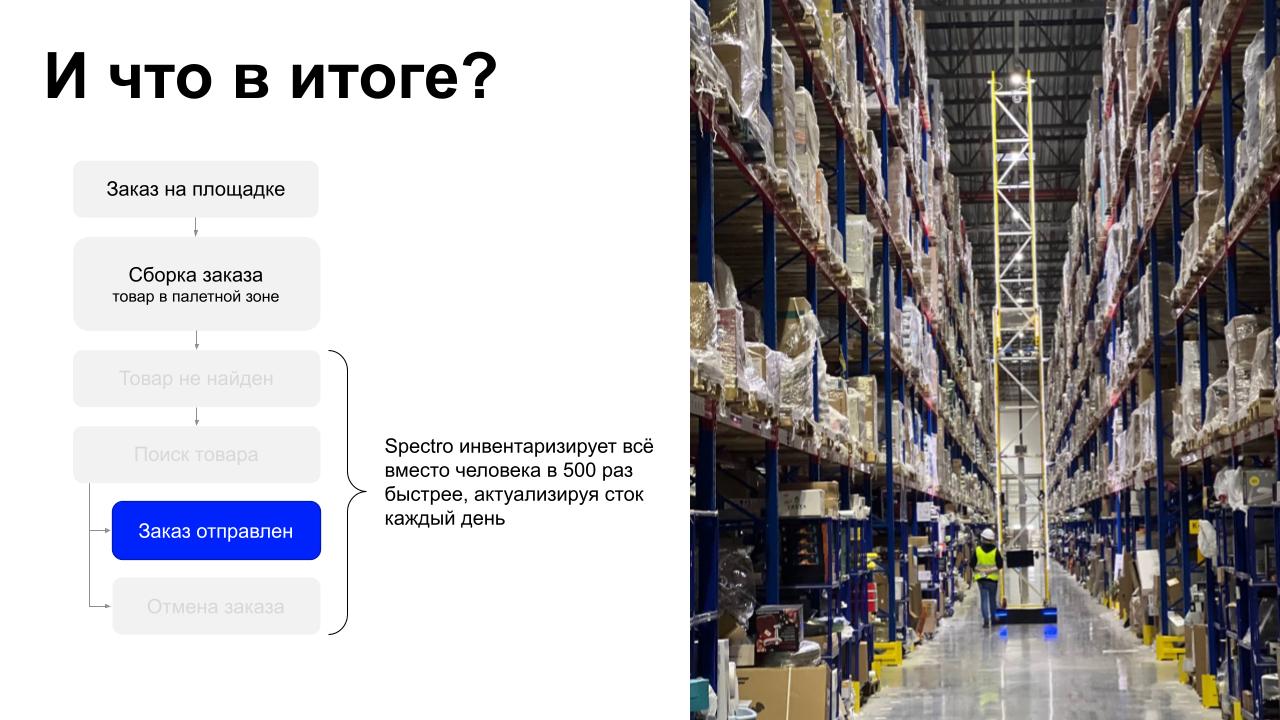
Вернёмся к исходной схеме заказа товара. Нам удалось исключить из неё вариант «ищем и не находим». На складе ежедневно катается робот, он замечает расхождения, и мы генерируем задания на исправления. Сейчас склад вычищен и робот каждый день поддерживает сток и обнаруживает новые ошибки.
Насколько Spectro производительнее человека? Робот проезжает аллею целиком за 3,5 минуты и сканирует за это время полторы тысячи палето-мест. Это быстрее человека в 500 раз.
Мы идём к модели непрерывных поездок робота, чтобы он умел актуализировать сток в реальном времени. Польза здесь уже не в инвентаризации, а в риалтайм-обновлении.

Какого бизнес-эффекта мы достигли? Активная фаза разработки перед большим накатом закончилась в марте 2023 года, мы согласовали процессы и начали накат робота с мая.
Уже в первом запуске мы нашли и подтвердили 332 расхождения. Сейчас за день мы находим от 3 до 7 расхождений. Команда инвентаризации подхватывает эти результаты и исправляет их.
Склад процветает, заказы не отменяются, люди приходят к нам снова и снова.
Сейчас мы масштабируем продукт и смотрим на запуск нашего робота не только на складах Маркета, но и на других. Для этого универсализируем функциональность робота, делаем его более умным и эффективным. Строим аналитическую платформу, которая использует сканы от робота и позволяет сказать складу о его состоянии что-то большее, чем положение конкретного товара.



