
В аналитике Яндекс Go долгое время параллельно работали два контура обработки данных — потоковый и батчевый. Они читали одни и те же сырые события и считали одни и те же метрики. Но иногда могли давать разные результаты. Например, real-time пайплайн показывал рост GMV на 5%, а батчевый пересчёт — падение на 2%. Когда разные системы дают разные цифры, возникает закономерный вопрос: а каким данным вообще верить?
Мы решили убрать эту неопределённость и сделать стриминг единственным источником правды. А все переносы и трансформации данных между слоями хранилища доверить Apache Flink.
Но проблема была в том, что Flink на тот момент не умел работать с YTsaurus — системой, вокруг которой построен наш Lakehouse. Готовой интеграции не существовало, а требования к нашей платформе были жёсткие: сотни тысяч сообщений в секунду на запись, десятки тысяч lookup-запросов и E2E обработка данных менее 5 секунд.
Значит, коннектор между Flink и YTsaurus нужно было писать с нуля.
Меня зовут Данил Сабиров, я руковожу группой развития потоков обработки данных в DMP Яндекс Go. В этой статье я расскажу, как мы строили этот коннектор и какие архитектурные решения понадобились, чтобы он стабильно работал под высокой нагрузкой.
Учим Flink писать в YTsaurus
Построение RAW и ODS слоёв начинается с выгрузки данных. Нам предстояло научить пайплайн надёжно и быстро сохранять потоки событий, поэтому разработка началась именно с Sink-коннектора.
Запись в YTsaurus идёт в динамические таблицы — это локальный аналог HBase. Процесс обязательно оборачивается в транзакцию, куда мы добавляем изменения, так называемые модификации. Изучив исходники YTsaurus-клиента, мы нашли полезную особенность — добавленная в транзакцию модификация сразу улетает в базу, а не копится в памяти клиента. Чтобы не грузить сеть одиночными вызовами, мы реализовали батчинг — отправляем модификации пачками, не дожидаясь закрытия транзакции.
При этом у базы есть свои жёсткие лимиты:
- Одна транзакция живёт не дольше одной минуты.
- Транзакция вмещает максимум 100 000 записей.
- Ключи в параллельных транзакциях не должны пересекаться.

Жизненный цикл коннектора
Ключевым контрактом для нас стал интерфейс SinkWriter<InputT>. В методе open() мы инициализируем клиента базы данных, в write() ведём учёт и накопление сообщений, во flush() на каждый чекпоинт Flink вычищаем буферы и коммитим транзакцию, а в close() освобождаем открытые ресурсы.
В теории вроде бы всё просто, но на практике есть нюанс, связанный с проблемой гарантии задержек. Представим, что входной поток слабый — одно сообщение в секунду. Чекпоинты во Flink по умолчанию срабатывают раз в две минуты. Значит, коннектор будет держать данные в незакрытой транзакции те же две минуты, а нам требовался сквозной SLA менее пяти секунд.
Мы решили это через запуск специальной shadow task. В методе open() стартует таймер, который принудительно инициирует отправку данных и коммит с заданным интервалом, не дожидаясь срабатывания лимитов транзакции или сигнала чекпоинта. В методе close() эта задача аккуратно останавливается, чтобы исключить утечку потоков выполнения.
Обработка ошибок и провокация Backpressure
Базы данных могут тормозить под нагрузкой. Мы встречали клиенты к БД с безлимитными внутренними буферами — они бесконечно глотали неограниченный поток данных, не успевая отправлять данные в БД. Это приводило к падениям по OOM.
Наш коннектор обязан честно поддерживать backpressure. Если YTsaurus не справляется, мы жёстко блокируем вызовы методов write и flush. Буферы Flink перед коннектором начинают переполняться, механизм backpressure каскадно раскатывается по графу выполнения вплоть до source-операторов и безопасно замедляет чтение из источника.
Также мы заложили правило — при сбоях во время записи или флаша всегда делать ретрай. Это значительно быстрее и дешевле, чем ронять весь коннектор и заставлять Flink переотрабатывать стейт с последнего чекпоинта.
Эмуляция партиционирования
Просто коннектор способный писать в одну таблицу нас не устраивал. Для полноценного переезда на стриминг требовалось достичь функционального паритета с батч-процессингом, где активно используется партиционирование.
YTsaurus из коробки не поддерживает партиции в динамических таблицах. Поэтому мы эмулируем эту механику — каждая партиция создаётся коннектором на лету в виде отдельной физической таблицы. Маршрутизация конкретного сообщения в нужную таблицу определяется по полю event time.

На стыке дней данные часто идут внахлёст, поэтому коннектор должен уметь писать в несколько партиций параллельно. Мы поставили перед этими писателями слой абстракции — YTsaurus Writer Pool. Он менеджерит сообщения. Прилетает ивент для открытой партиции — пул отдаёт его активному писателю. Приходит сообщение из новой партиции — пул придерживает ивент, создаёт нового писателя, и запись продолжается. Старые партиции со временем автоматически закрываются для защиты от утечек потоков.
Трекинг бизнес-даты через кастомные метрики
Вторая важная фича батча — понимание бизнес-даты. Аналитикам и смежным системам всегда нужно знать, за какой период данные уже гарантированно прогружены и больше не придут.
Flink поддерживает кастомные метрики для мониторинга здоровья коннектора — размера буферов, частоты коммитов. Мы решили, что текущая бизнес-дата отлично ложится в эту концепцию. В open() мы объявляем нужные метрики, в write() извлекаем таймстемпы прямо из потока данных, а во flush() обновляем значения.
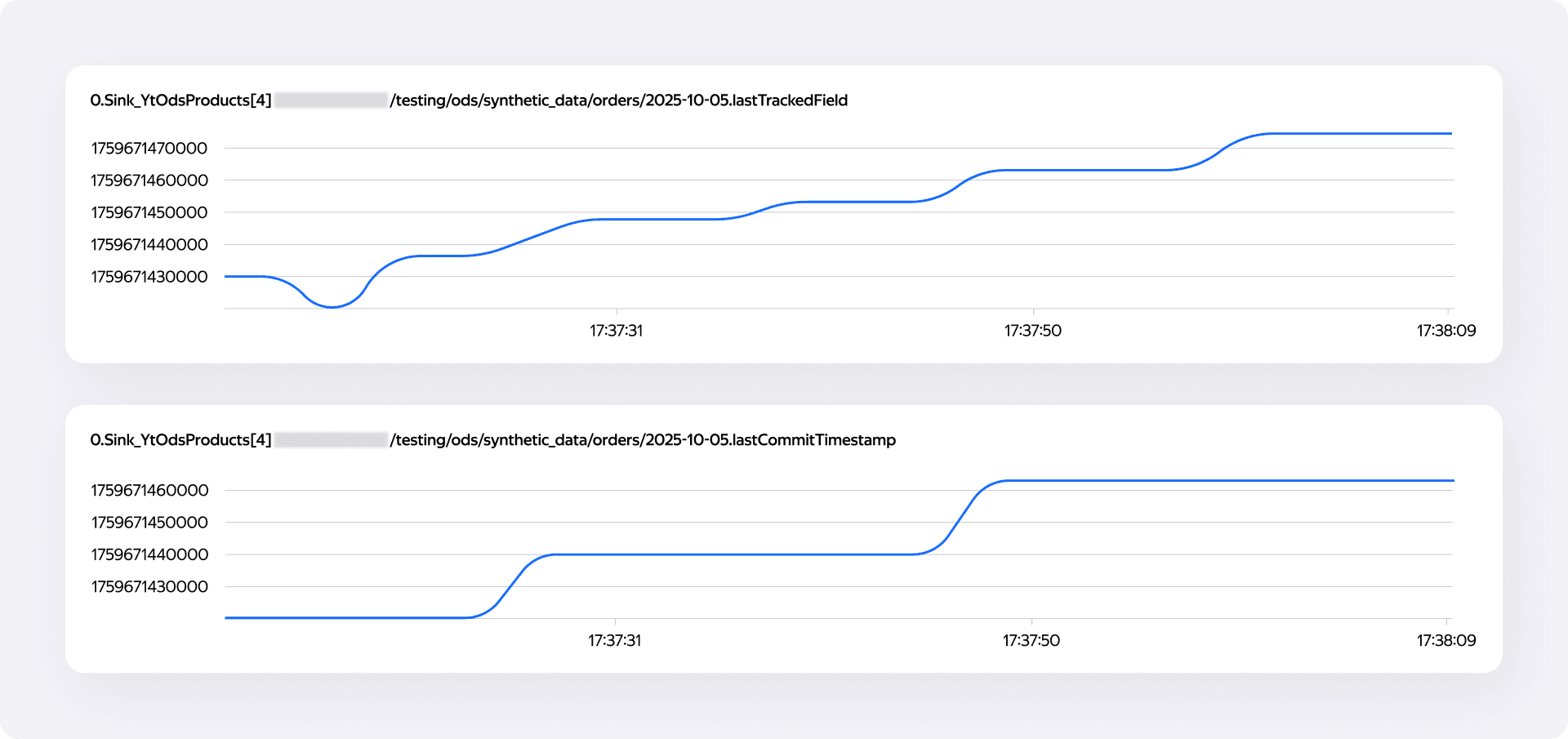
Поскольку на одну партицию работает сразу несколько параллельных писателей, каждый из них репортит свою локальную правду. Конечные пользователи не ходят во Flink напрямую — они обращаются в Яндекс Мониторинг, который забирает эти метрики и отдаёт агрегированное, истинное значение бизнес-даты.
Решаем проблему перегрузки таблетов
Когда мы достигли паритета функциональности между батч-процессингом и стримингом, настало время выводить коннектор в продакшен. Но сделать это нельзя без проверки его производительности под реальным трафиком, который он и должен выдерживать.
Поначалу всё шло отлично: при постепенном увеличении нагрузки до 10 мегабайт в секунду коннектор работал стабильно. Однако попытка пойти дальше и поднять рейт вскрыла серьёзное узкое горлышко. На графиках резко пополз вверх процент неудачных записей. Коннектор непрерывно ретраил, очередь росла, и формировался критический лаг. В какой-то момент мы отправляли в повторную обработку до 30% всех данных.
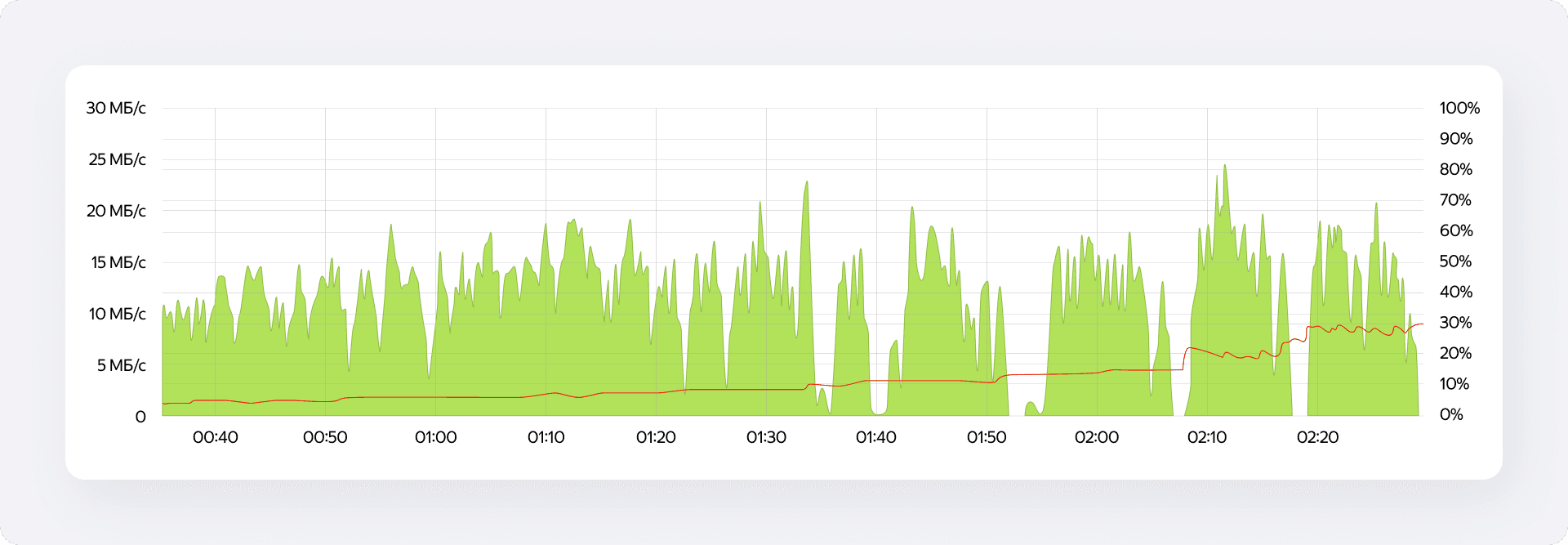
Анализ логов показал, что мы упираемся в саму базу данных. И причина тут во внутренних механизмах хранения YTsaurus. Дело в том, что динамические таблицы разбиты на шарды, которые здесь называются таблетами. Каждый такой таблет отвечает за свой строго определённый диапазон ключей.
Сложность в том, что в момент создания новой таблицы, а я напомню, что мы генерируем их на лету под каждую новую партицию, так вот по умолчанию в ней создаётся ровно один таблет. Этот единственный шард охватывает абсолютно весь диапазон ключей. При резкой подаче интенсивного потока данных он моментально перегружается, и база останавливает приём новых сообщений.
Очевидное решение — подготовить свежесозданную партицию к нагрузке и сразу разбить её на нужное количество таблетов.
Но чтобы движок YTsaurus смог решардировать таблицу, мы обязаны явно указать ему границы диапазонов ключей для каждого нового таблета. А поскольку мы работаем с непрерывным потоком данных, то мы просто не знаем, с какими именно ключами придут следующие ивенты и как выглядит их полный диапазон.
Хеширование и стратегия Uniform
Обойти это ограничение нам помогло использование вычисляемых колонок. Вместо того чтобы пытаться угадать или собрать диапазоны реальных бизнес-ключей, коннектор вычисляет хеш от ключевых колонок. Хеш всегда принимает предсказуемое числовое значение. Это свойство позволяет нам применить стратегию uniform — мы берём весь возможный числовой диапазон хешей и равномерно делим его на равные интервалы по числу нужных нам таблетов.
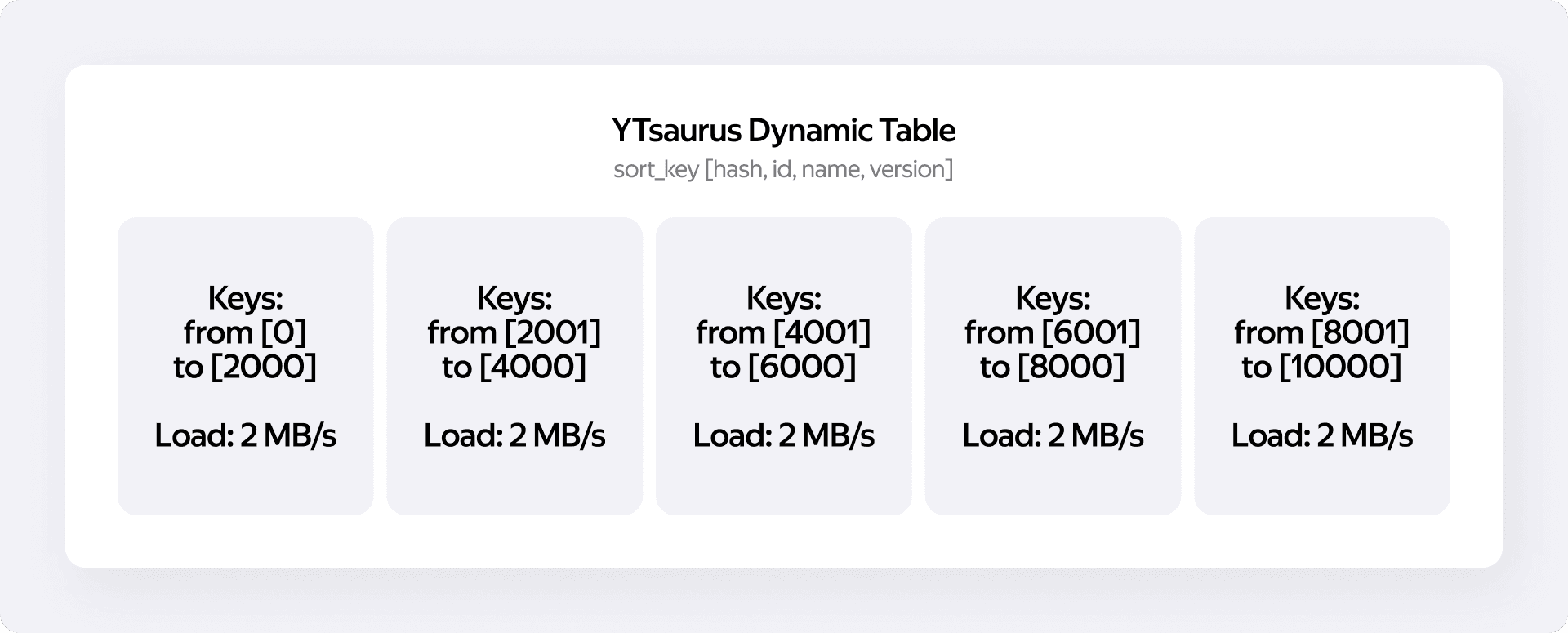
Теперь алгоритм работы YTsaurus Writer при смене партиции выглядит так:
- Создаётся новая физическая таблица в YTsaurus.
- Коннектор немедленно выполняет её решардирование, распределяя ключи по таблетам на основе хеша.
- Только после этой подготовки таблица начинает принимать поток модификаций.
Внедрение пре-решардирования полностью сняло проблему перегрузки единичных шардов. Таблицы с первой секунды жизни готовы принимать целевую нагрузку, графики ретраев ушли в ноль, а разработка Sink-коннектора на этом успешно завершилась. Мы закрыли сценарии записи и перешли к следующему вопросу — лукапам.
Как разогнать чтение со 100 до 15 000 RPS
Для построения ODM-слоя нам требовалось обогащать потоки в реальном времени. Классический пример: летит ивент заказа такси, и нам нужно прямо в процессе подтянуть профиль пользователя из одного справочника, а его платёжную информацию — из другого. В терминах Flink SQL это выражается через объединение потоков: LEFT JOIN ... FOR SYSTEM_TIME AS OF.
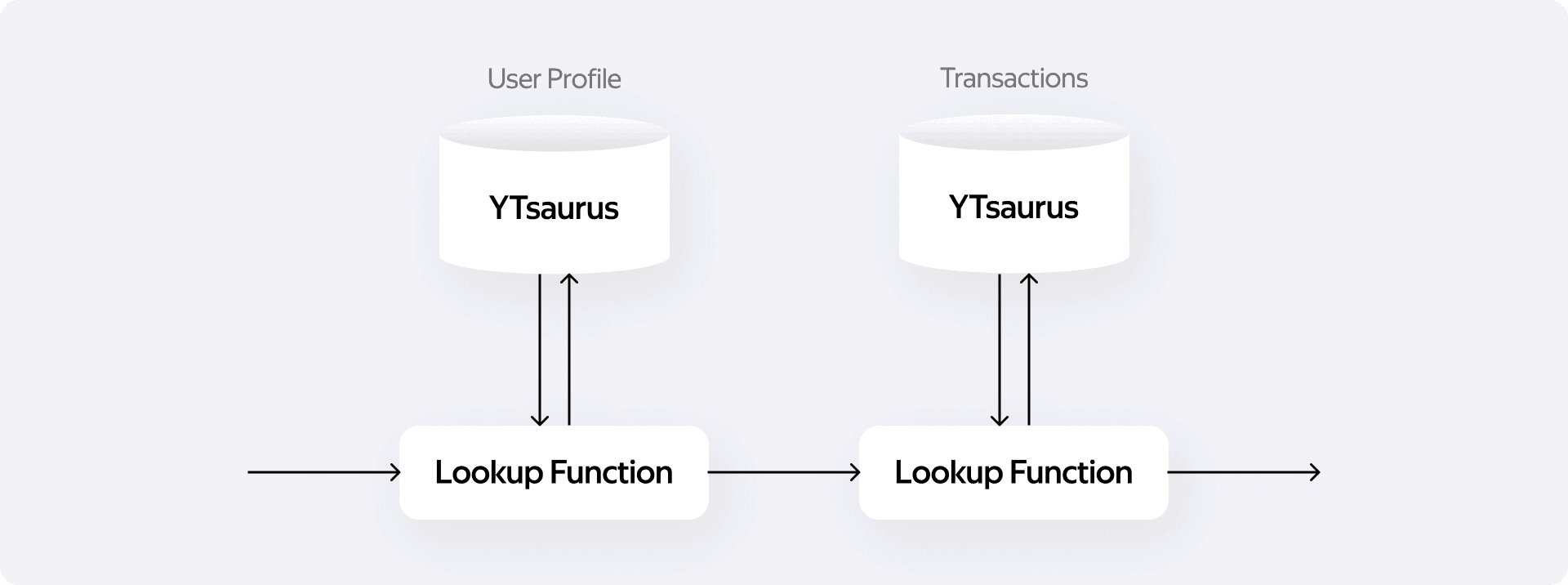
Чтобы это заработало с YTsaurus, нужно было сделать Lookup-коннектор. В отличие от Sink-коннектора, где мы эффективно батчили модификации, интерфейс LookupFunction работает иначе. Метод lookup() вызывается на каждый входящий ивент, и мы не можем накапливать сообщения — нужно идти во внешнюю систему сразу же.
Вот только когда на синхронном MVP мы запустили тесты, то практически сразу упёрлись в потолок: 100–150 сообщений в секунду. Что было, мягко говоря, чуточку ниже нашей целевой планки в 10 000 RPS. И проблема тут крылась в самом подходе: наш RPC-прокси в YTsaurus физически не успевал обрабатывать последовательные синхронные запросы с нужной скоростью.
Учимся выполнять лукапы асинхронно
К счастью, Flink умеет делать асинхронные лукапы. Для этого существует класс AsyncLookupFunction. Самое приятное в этой миграции было то, что нам вообще не пришлось переписывать ядро синхронного коннектора.
Нам лишь потребовалось создать наследника AsyncLookupFunction. В методе open мы развернули ThreadPoolExecutor, в который попадали задачи на вызов синхронной реализации lookup-коннектора. Flink взял на себя оркестрацию параллельных запросов. Мы оставили дефолтное значение ёмкости в 100 одновременно выполняемых лукап-операций и мгновенно получили рейт в 15 000 RPS из коробки.
Справедливости ради, таких цифр удалось достичь ещё и благодаря гибкости самого YTsaurus: он умеет хранить динамические таблицы не только на дисках и SSD, но и in-memory, что критически важно для высоконагруженных лукапов.
Не ходим в БД без повода
Даже при наличии 15k RPS генерировать лишнюю нагрузку на базу — не очень хорошая инженерная практика. Проанализировав паттерны пользователей, мы выделили два основных сценария работы со справочниками и внедрили под них разные стратегии кэширования:
- Partial Lookup Cache. Сценарий, когда есть огромная таблица, из которой джоинится лишь узкий диапазон частотных записей. Включается буквально двумя строчками конфигурации Flink и позволяет задать размер кэша и TTL. Работает как в синхронной, так и в асинхронной реализации коннектора.
- Full Lookup Cache. Сценарий, когда есть небольшой справочник, который редко обновляется. В этой стратегии таблица полностью загружается в память, и сетевые походы в базу выполняются только чтобы актуализировать справочник в заданные моменты времени.
Впрочем, реализация Full Cache оказалась не без подвоха. Если посмотреть в исходники Flink, для инициализации такого кэша требуется ScanRuntimeProvider. Да, вы всё поняли верно: чтобы включить полный кэш для лукапов, нам пришлось написать Scan-коннектор. Тема разработки Scan-коннекторов — это отдельный хардкор, но для задачи инициализации кэша мы написали упрощённую версию, которая батчом вычитывает таблицу в память. И эта фича стала просто хитом: сейчас в проде работают пайплайны, где крутятся десятки in-memory справочников.
Добавляем коннектору гибкости
Последним требованием пользователей стал отказоустойчивый лукап. Если кластер YTsaurus умирает, коннектор должен переключиться на резервную инсталляцию. Задача звучит вроде бы просто до тех пор, пока не задашь встречный вопрос: «А куда именно идти коннектору, когда живы сразу все кластеры?»
Логика выбора кластера зависит от конкретной бизнес-задачи. Одному пайплайну нужен первый доступный кластер. Другому — кластер с самыми свежими данными. Третьему — строго приоритетный кластер, статус которого отдаёт внешняя система.
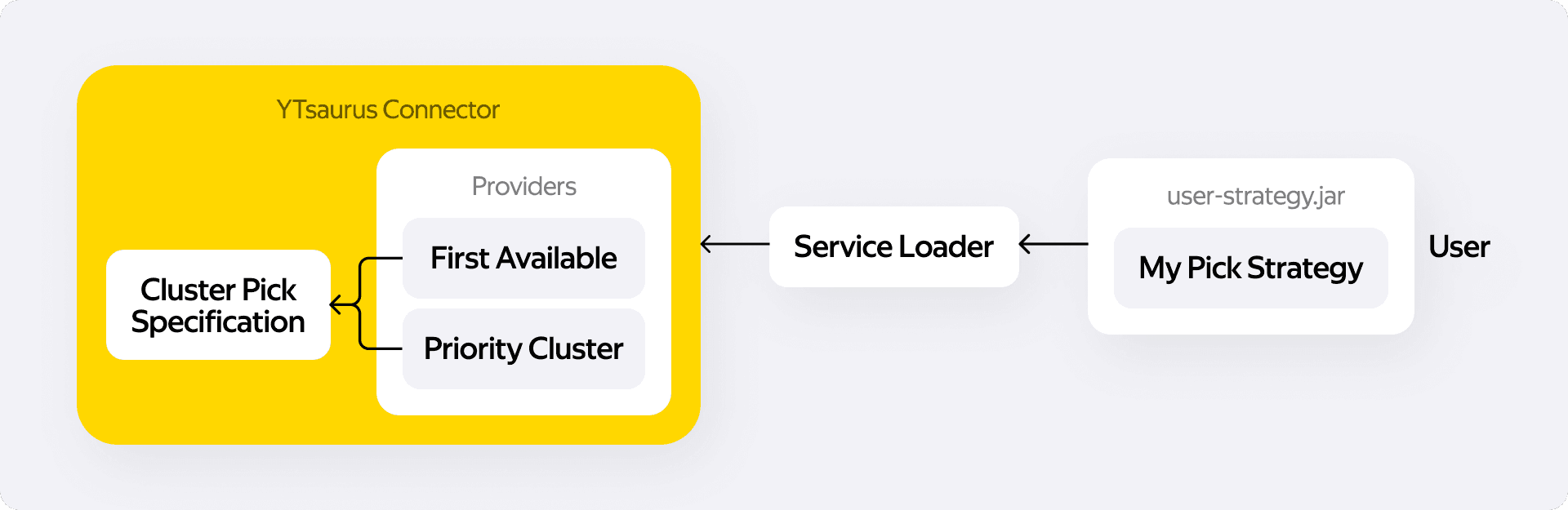
Чтобы не хардкодить все возможные стратегии маршрутизации и не заставлять инженеров форкать наш коннектор под каждую новую хотелку, мы применили технологию Java Service Provider Interface (SPI).
Мы описали контракт по которому коннектор выбирает кластер и реализовали пару дефолтных стратегий. Если дата-инженеру нужна специфическая логика выбора базы, он пишет свой плагин, пакует в .jar и кладёт в classpath. В методе open() наш коннектор через ServiceLoader обнаруживает эти пользовательские реализации и динамически подгружает их в рантайме. Изящно, расширяемо и никакого дублирования кода.
Как же нам пересчитывать данные загруженные через Apache Flink
Итак, мы успешно решили задачи записи и обогащения потоков, но впереди оставалась ещё одна монументальная задача — пересчёт исторических данных.
Построение ODS-слоя из сырого RAW-потока исторически опиралось на два разных вычислительных механизма. В стриминге трудился Apache Flink со своим Table API и SQL, а для масштабных исторических пересчётов запускались MapReduce-операции на базе YQL.
А что означают два одновременно работающих движка? Правильно! Двойную работу. Дата-инженерам приходилось поддерживать две кодовые базы, которые обязаны выдавать строго идентичный результат. Если пользователь писал сложную UDF для Flink, её нельзя было просто взять и перенести в батч — приходилось искать или с нуля писать аналоги на YQL. Дублирование закономерно плодило баги и приводило к рассинхрону в метриках.
Flink как Map-операция
Мы решили избавиться от дублирования и перевести вычисления на единый стандарт. Если Flink отлично справляется с трансформациями в стриминге, почему бы не заставить его пересчитывать историю прямо внутри инфраструктуры YTsaurus?
Архитектура YTsaurus обладает крайне полезным свойством: внутри фазы Map можно запускать абсолютно произвольные изолированные процессы. База общается с ними через стандартные потоки ввода-вывода — stdin и stdout.
Мы взяли ядро Flink и упаковали его как вычислительный движок прямо внутрь Map-операции. Механика работает следующим образом:
- YTsaurus забирает на себя тяжёлую работу по чтению с дисков и оркестрации распределённого выполнения.
- База нарезает входные данные на сплиты и подаёт их бинарным потоком в stdin нашего процесса.
- Flink подхватывает этот поток, прогоняет через логику пайплайна и отдаёт результат в stdout.
- YTsaurus читает выходной поток и прозрачно складывает данные в финальные таблицы.
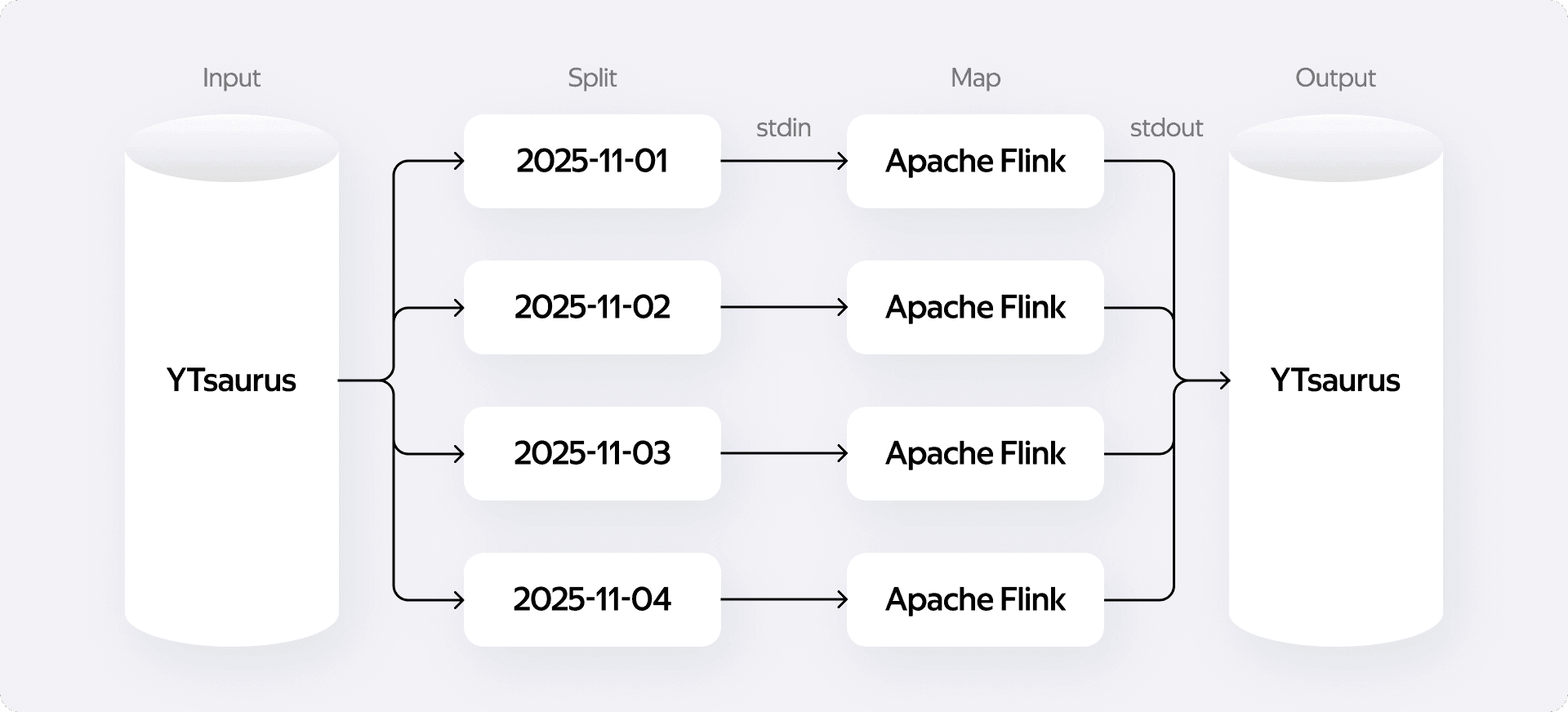
Чтобы надёжно подружить эти системы, нам снова пришлось открыть IDE и написать для Flink специализированные stdin/stdout-коннекторы.
Ограничения и профит
У такого решения, несмотря на все его плюсы, есть одно строгое ограничение. Упаковка Flink в Map-фазу подходит исключительно для stateless-операций. Сделать сложную агрегацию с окнами таким способом не выйдет. Но для плоских преобразований данных и фильтрации сырого потока — а именно из этого состоит логика пересчёта ODS-слоя — подход ложится безупречно.
Что эта унификация дала платформе и конечным разработчикам:
- Бесконечная масштабируемость. Мы получили возможность линейно масштабировать инстансы Flink под любые объёмы данных YTsaurus. Теперь мы можем пересчитывать логи за месяцы и годы без оглядки на ограничения стримингового кластера.
- Один джоб для всего. Один и тот же код Flink-пайплайна стал универсальным. Он одинаково хорошо работает и в real-time стриминге, и в тяжёлых исторических пересчётах.
- Единые UDF. Пользовательские функции заработали везде. Разработчики пишут сложную бизнес-логику один раз для Flink, и она без малейших изменений исполняется в MapReduce.
- Скорость вычислений. Наши бенчмарки показали, что добавление абстракции в виде потоков ввода-вывода практически не влияет на производительность. Более того, в специфичных сценариях нативный Flink внутри Map-операции отрабатывает даже быстрее классического YQL-запроса.
Что мы поняли в итоге
Весь этот путь затевался ради одной цели — дать бизнесу консистентные цифры без огромных задержек. И мы её достигли. Сейчас в продакшене крутятся сотни Flink-джобов, которые нативно работают с YTsaurus. Мы уверенно держим суммарный рейт записи свыше полумиллиона сообщений в секунду, а сквозные задержки упали с нескольких десятков минут или даже часов до считанных секунд. На базе этих данных рекомендательные системы строят полноценный real-time процесс, а пересчёт истории больше не требует поддержки дублирующего кода на другом языке.
Глядя на финальную архитектуру, я могу с уверенностью сказать: Apache Flink даёт достаточно богатый API для интеграции практически с любой системой, а YTsaurus отлично вытягивает задачи потоковой обработки данных.

Но главный вывод, к которому мы пришли, лежит не в плоскости кода. Самое важное при создании платформенных инструментов — не разрабатывать их в вакууме. Если бы мы писали коннектор исключительно по своему изначальному плану, он получился бы рабочим, но плоским. Именно реальные пользователи с их жёсткими и порой нетипичными требованиями заставили инструмент эволюционировать. Без них у нас бы не появились ни Full Lookup Cache для чтения целых справочников, ни механизма отслеживания бизнес-даты. Чужие инженерные боли делают ваш продукт по-настоящему зрелым.
Мы не стали прятать результат внутри компании. Наш коннектор к YTsaurus уже отправлен в open source. Вы можете свободно его загрузить, протестировать запись в динамические таблицы, настроить лукап-операции под свои пайплайны и забрать готовый YSON-форматтер. Пользуйтесь, изучайте подходы и применяйте в своих проектах — уверен, наш опыт сэкономит вам не одну неделю на настройку высоконагруженной интеграции.



