
Мир по-прежнему разрывается между двумя лагерями. С одной стороны: «Ааааа, боже мой, всех программистов скоро заменят нейросети, срочно учимся махать киркой в шахтах». С другой: «Кайф, теперь будем вайбкодить в смузешных, придумывая стартапы, а ваши когерентности кешей оставьте кому-то другому».
Но тем не менее люди это всё активно внедряют. НейроТЗ, нейроревьюер, автоописания пул-реквестов, нейропомощники в IDE, нейроанализ спринтов и вот это вот всё. Для полной картины там не хватает только нейропользователей. Хотя, есть сервисы, которыми только они и пользуются.
Сам я нейросети щупал давно и методично. Платный ChatGPT у меня был почти с релиза и прожил до сентября 2024-го. А в конце 2025-го у меня снова появилась личная лицензия. Кроме того, пробовал я и разных AI-код-ассистентов.
Но при всём этом я всё ещё не умею вайбкодить
Может, это я какой-то ущербный. Но мои задачи, даже сферические в вакууме и отдельно от кодовой базы, такие агенты без меня написать так и не смогли.
Кто это вообще говорит?
Помимо того, что я живой мем, я, по мнению окружения, нерд или гик.
У меня есть много весёлых pet-проектов, но я не собираю их в Docker. Ну ладно, телеграм-бота собираю, но это я пробовал git actions в момент релиза. Обычно я передаю бинарники через scp, потом захожу на машину и стартую их через nohup.
У меня есть мини-серверная стойка из Raspberry Pi, и когда надо на всех что-то запустить или перезапустить, я использую pssh, потому что эти ваши новомодные контейнеры — это от лукавого.
Если мне нужна web-страничка, я не тащу React, Vue и прочую лабубу. Я просто пишу HTML и прямо на нём JavaScript. Профессиональные фронтендеры, подозреваю, AJAX не видели уже лет десять, а у меня он до сих пор в каждой второй страничке.
Я знаю и щупал много фреймворков. Для Python исторически тянусь к Tornado, для C++ — к Poco. Не потому что другого не видел: пробовал userver, Drogon Framework, Django, Flask, Boost.Asio и разное другое. Я даже как-то умудрился подключить nginx как C++-библиотеку — неделю занимался этим извращением, за три часа написал простенький сервер и бросил.
А ещё я пишу в текстовом редакторе. Когда в Яндексе только появился CLion и всем закупили лицензии, я честно попробовал, две недели потерпел и вернулся в emacs. Потому что я открыт к новому, но закрыт для того, что мне не нравится: Open/Closed принцип.
Короче: я любопытен, знаком со многими технологиями, но, как правило, предпочитаю сидеть на первых изученных из них, которые из-за этого и называю трушными, до тех пор, пока новая не покажет своё РАДИКАЛЬНОЕ превосходство.
Реальный опыт с AI в разработке: что работает, а что не очень
На тот момент вывод у меня был очень простой: вайбкодинг как магическая кнопка — это миф.
Быстро набросать типовой интерфейс, дописать рутину, сделать то, что раньше было лень, — пожалуйста. Но как только ты хотел сделать что-то сложное, объёмное, конкретное, нестандартное или из узкоспециализированной области, сразу же начинались проблемы.
Карты
Как-то мне понадобилось сделать демку с геоданными: собрать простую мапредьюс-джобу, выгрузить точки и быстро склепать страничку с тепловой картой. Джобу я написал сам, потому что там было 35 строк, а промпт писать дольше.
Но потом начался сущий ад. Агент пытался смешивать API Яндекс Карт с Google Maps. Google хотел ключи и привязку платёжной карты. Старое API Я.Карт уже было неактуально, новое требовало плясок с ключами и HTTP Referer, причём отдельно выяснилось, что localhost:8080 и 127.0.0.1:8080 для этой вселенной почему-то не одно и то же.
Потом оказалось, что examples для React, Vue и TypeScript есть, а на голом JavaScript даже пример из документации умеет отвечать чем-то в духе custom layer is not supported. В итоге я раскопал древнюю библиотеку с последним коммитом где-то во времена палеолита и переписал всё с помощью пинков и мата.
Схема была одна: пишешь промпт, смотришь, почему не работает, пишешь промпт к промпту, психуешь, откатываешь, делаешь сам. Повторяешь восемь раз. Там, где надо читать доку, разбираться с административной вознёй вокруг ключей и искать обходные пути вместо красивых решений, вайбкодинг не просто не помогает, а откровенно мешает.
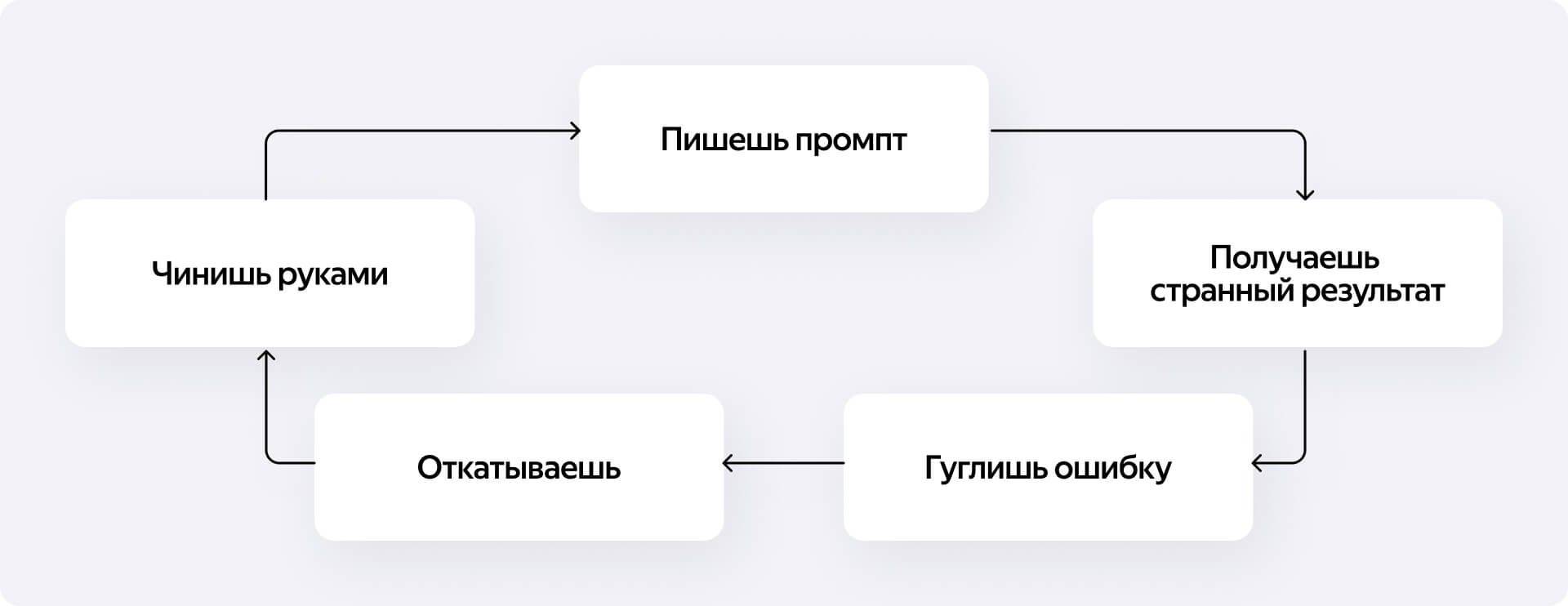
В итоговом проекте от агента осталась примерно фраза «сделай границы для карты в HTTP-странице». Без него я бы сделал всё раза в три быстрее. Поэтому, когда мне кто-то говорил: «ну это же демка, её навайбкодить за пять минут можно», у меня начинали дёргаться сразу оба глаза.
Bevy
Для справки: Bevy — это игровой движок на Rust, а Rust — это то, что некоторые называют языком программирования.
Bevy очень хорош ровно до того места, где у него ломается обратная совместимость между версиями. У них в официальной документации для этого даже migration guides написаны. Агент, разумеется, решил, что это всё для слабаков, и начал галлюцинировать страшной смесью 12-й, 13-й и 14-й версий.
На просьбу «поправь под 16-ю» он бодро отвечал «да, вы правы» и галлюцинировал уже смесью с 11-й по 14-ю. В своих искренних потугах был похож на ребёнка, который очень старается помочь, но делать ничего не умеет. Приходилось говорить: «Да, зайчик, ты большой молодец», а потом тайком выкидывать его поделку, потому что это мусор.
Но тут был и полезный кусок опыта. Когда у тебя уже есть критическая масса окружающего кода, он действительно неплохо мимикрирует под стиль. Зелёную полоску патронов над башней он навайбкодил нормально.
А вот на задаче «разверни жуков по направлению движения» не вывез и зачем-то изобрёл новую систему отслеживания угла. Радиальную. Систему. Вращалось в ней всё как угодно, только не по нужной траектории.
Потом я это ещё и вычищал вручную, потому что забыл закоммитить до промпта и случайно закрыл чат, а вместе с ним пропала кнопка revert changes. Ненависть.
Большие правки
Но и на рабочей рутине без цирка не обходилось. Просишь перенести функцию строк на сорок из view.cpp в другой файл, специально даёшь контекст, прототип и все типы, а этот ирод начинает плодить по триста строк, метаться, переделывать и в итоге заканчивает чем-то уровня TODO: потом дописать функцию. Спасибо, родной.
Ещё одна системная беда: он слишком хорошо мимикрирует. Показываешь ему обработку одного типа и просишь написать похожую для другого, а он честно штампует ещё один кусок копипасты. Без него я бы, возможно, написал общую функцию или шаблон. С ним мы быстро, эффективно и качественно плодим копипасту.
Или вот ещё идея: описать в промпте или настройках среды, как всё компилировать, а потом сказать: «Компилируй и чини, пока не соберётся». Иногда так и происходило. А иногда агент попадал в прекрасный цикл: после неудачной сборки откатывал предыдущую версию, потом снова вносил ровно ту же правку, снова ломал, снова откатывал.
Если не смотреть, что он делает, можно довольно бодро отправить компанию в глубокие долги, просто наблюдая, как красиво он компилирует одну и ту же ошибку.
Именно на сложных задачах вся магия обычно и заканчивалась: начинались галлюцинации, лишний код, странные решения и бесконечные попытки чинить одно другим. Вайбкодинг как волшебная кнопка «сделай хорошо» у меня не работал.
Но есть важный нюанс: при всём этом я всё равно бегал за такими агентами на работе. Проходил корпоративные круги допуска, пытался менять привычный сетап и вообще терпел то, что обычно терпеть не люблю. Потому что это были действительно сильные ассистенты. Они здорово ускоряли рутину.
Рутина и автодополнение
Автодополнение там работает не по принципу «допиши вот эту строчку», а по принципу «смотри, я тут тебе ещё полфункции дописал». Пишешь комментарий, что должна делать функция, и он сам дописывает функцию. Не нравится галлюцинация? Не нажимай Tab. Продолжаешь писать, и в какой-то момент красавчик внезапно понимает: «Ааа, так вот что ты пишешь», после чего начинает попадать очень точно.
Отдельный кайф был в рефакторинге: переименовал переменную в начале и дальше пошёл по коду цепочкой Tab, Tab, Tab, словно играешь на пианино, а не ковыряешься два часа в одинаковых местах.
Он отлично выполняет ту работу, которую особенно лень делать самому: вынести лямбду в функцию, расписать комментарии, чуть причесать структуру.
Скрипты и утилиты
Во мне живёт инстинкт инженера: если есть любая повторяющаяся задача, пусть даже её выполнение и занимает 10 минут, я всё равно напишу для её автоматизации скрипт. Да, на скрипт я, скорее всего, потрачу часа три, а следующий раз вообще забуду, где он лежит и начну писать заново, но это уже детали. Так вот тут, в части автоматизации, я был в полном восторге.
Написал я однажды крошечный скрипт, который просто запускал несколько других скриптов. Шесть унылых строк. Добавил в контекст нужные файлы и сказал: «Вынеси параметры, сделай --help напиши доку».
И эта фантастическая штука превратила мои шесть строк в полтораста: с проверкой аргументов, созданием папок, логами каждого шага, справкой, примерами запуска и прочими вещами, которые я терпеть не могу делать сам. Просто блеск.

Плюс периодически оно использовало синтаксические конструкции, которые я не знал, и приходилось у него же учиться.
Визуализация и мелкие задачи
Однажды мне понадобилось визуализировать текстовый файл формата <path>:<line> <digit> <function>. Я описал формат, попросил собрать интерфейс и получил вполне живую страницу: поиск, саммари, вменяемый вид. Это и был образцовый вайбкодинг. Я почти не трогал код, оно быстро заработало и даже придумало пару полезных фич само.
Правда, как только я захотел конкретную штуку, а именно чтобы по клику на файл открывался выпадающий список, магия тут же кончилась: список стабильно был пустой. В какой-то момент я сдался и попросил сделать гиперссылки на отдельные страницы. Потому что миллионы мух до меня уже делали гиперссылки, и мне, видимо, тоже не надо было выёживаться. Выглядело это ужасно, и внешним пользователям такое показывать нельзя, но для внутреннего использования и визуализации — идеально!
Нейро ПР
С нейроревью у меня тоже отношения сложные. С одной стороны, комментарии в духе «здесь переменная названа requests, хотя обрабатывается один запрос» бывают полезны. С другой, контекст он не чувствует вообще.
Канонический пример: в документации userver написано, что catch (…) использовать нельзя. Я нахожу такой catch, удаляю его, а нейроревью говорит: «Критическая проблема: вы потеряли обработку нестандартных исключений. Решение: вернуть catch (…)». Ну спасибо. Решение, получается, убрать мой ПР. И так раз за разом. Поэтому я до сих пор не уверен, нейроревью в среднем экономит время или просто тратит его более технологичным способом.
Вот и получается
Вайбкодинг здорово выручал, когда нужно было быстро набросать типовой интерфейс, дописать рутину, сделать то, что раньше было лень, пожалуйста. При этом AI-ассистента я рекомендовал вообще всем. Он ускорял работу, забирал на себя рутину, заставлял чаще формулировать, что именно должна делать функция, и даже местами учил синтаксису. Правильный режим работы с ним был очень здоровый: не «сделай за меня», а «помоги мне быстрее и чище сделать самому».
Что изменилось за год
Спустя примерно год я уже не просто щупал LLM, а пользовался ими каждый день, и мнение моё менялось не то чтобы драматически, но вполне заметно.
И вот тут, по-хорошему, должна была бы начаться нравоучительная часть, где я гордо сообщаю, что был прав, хайп сдулся, а настоящие программисты по-прежнему сидят в emacs и передают бинарники через scp, как деды завещали.
Проблема в том, что время шло, нейросети совершенствовались, инструменты менялись, контекстные окна раздувались, агентность лезла изо всех щелей, а некоторые вещи, которые вчера ещё выглядели как плохой стендап с галлюцинациями, вдруг начали получаться. Не всегда. Не везде. Не без мата, опять же. Но уже заметно чаще.
И в какой-то момент я с неприятным для себя удивлением обнаружил, что весь предыдущий текст всё ещё актуален, но уже с оговорками.
Сложнее всего мне, честно говоря, было даже не с самими инструментами, а со статьями про них. Вечное «смотрите, как теперь всё просто», «вот проблема, вот лайфхак, вот прорыв». Проблема в том, что пока дочитаешь такой текст, он уже может устареть. Причём не только в хорошую сторону: сегодня все радуются новой фиче, а через пару месяцев её тихо “соптимизировали” до неузнаваемости.
Модели стали лучше, хотя до магии им далеко
Вместе с этим я стал заметно больше писать промптами, потому что оно и правда становилось всё лучше. С одной стороны, всё лучше и лучше писало код. Для локальных, быстрых и относительно изолированных задач промпты — просто отличные.
С другой, всё лучше и лучше прятало баги. Его цель — не написать работающий код. Его цель — написать код, который выглядит настолько правдоподобно, что ты сам на секунду захочешь поверить, будто он рабочий.
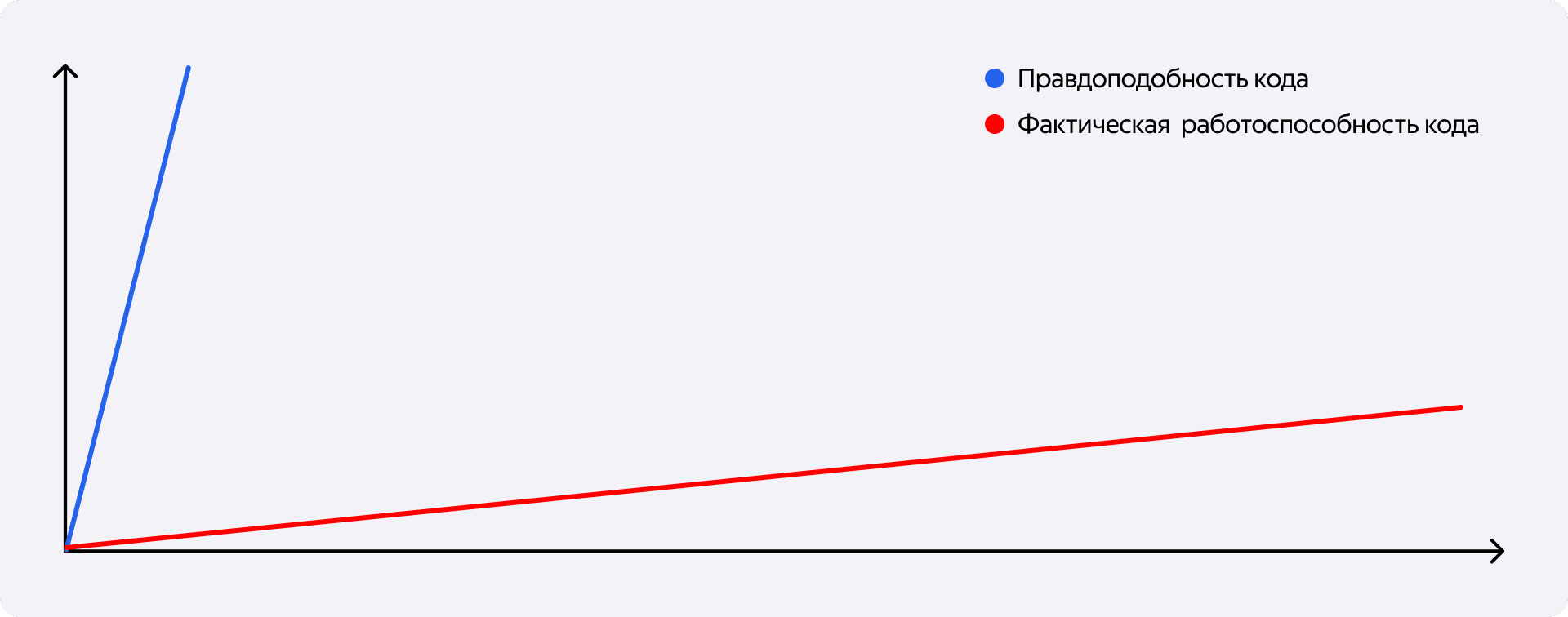
А ещё лучше — чтобы его спокойно приняли в review: у тебя качество подсказок измеряется не качеством кода, а количеством принятых правок, даже если ты потом ходишь по этим правкам и выковыриваешь из них баги, выверять всё равно приходится тщательно.
Тут, правда, есть важный нюанс. Постоянно думать «а правильно ли это работает?» в среднем и продуктивнее, и приятнее, чем бесконечно думать «а как это вообще написать?», чтобы к моменту готового текста у тебя уже не осталось сил на мысль о правильности. В этом смысле LLM реально помогают сдвинуть фокус туда, где он и должен быть у инженера.
Эволюция ассистентов
С прорывом в атомной энергетике, когда человечество 'покорило атом', его просто попытались воткнуть в существующие производственные процессы. По сути мы сейчас раскаленный урановый стержень всё так же просто поливаем водой, а пар вращает турбину для выработки электричества, как делали все предыдущие 70 лет. Так и к LLM попытались прикрутить какие-то существующие решения.
Хороший пример — индексирование проекта. Идея красивая: агенту заранее скармливают кодовую базу, чтобы он не гадал по соседним файлам, а лучше понимал контекст. По ощущениям работало это очень по-разному, но сам вектор правильный: меньше угадываний, больше понимания системы. Правда, однажды у меня эта красота попыталась проиндексировать удалённую папку по sshfs, закончила файловые дескрипторы и так капитально уложила мне ноутбук, что я вообще не думал, что такое возможно.
Следующим этапом подъехали MCP — когда ассистенту дают не только рот, но и руки: доступ к документации, внешним системам и рабочим инструментам. Иногда это правда удобно. А иногда я выделял кусок кода, просил завести подзадачу в трекере, а агент сначала зачем-то шёл собирать контекст по проекту, потом создавал тикет и творчески переписывал то, что я уже сам написал ему в окно. По сути мне за мои же деньги просто перенесли текст из IDE в трекер. Технологично, ничего не скажешь.
Как использовать AI и не пожалеть об этом
Из всего моего опыта у меня даже вырос один супермегалайфхак, которым я теперь пользуюсь постоянно. По работе мне регулярно приходится копаться в чужих проектах. И вечно один и тот же вопрос: с какого файла вообще начинать читать?
Ткнёшься в точку входа — и идёшь десять тысяч лет через слои middleware, bootstrap, обвязки и прочие ворота в никуда. Основной код при этом находится где-то дальше, за семью include и тремя поколениями архитектурных решений.
Поэтому я теперь иногда делаю наоборот. Ставлю задачу нейросетке и даю ей сделать её так, как она сама это понимает. Главное тут не то, что получится хорошо. Главное, что она полезет менять файлы, которые хотя бы похожи на правильные.
И после этого мне гораздо легче читать код: я уже знаю, где логически находится нужная часть системы, откуда начинать и куда смотреть. Главное потом не забыть удалить весь этот нагенерённый код и заново пойти мелкими, точечными промптами или вообще руками.
Если вы оставляете результат большого промпта в проекте, и при этом это не демо, MVP или pet project, то подумайте лишний раз: точно ли оно вам нужно? Некоторые очень и очень опасные ошибки, которые оно внедряло мне под видом «правильного кода», были настолько хорошо замаскированы под рабочий код, что лучше бы оно честно написало «я не знаю».
Документация и ТЗ
Ещё одна вещь, которая у меня со временем встала на место, — это документация и ТЗ.
Я вообще не умею сначала придумать ТЗ во всех деталях, а потом начать его кодить. Потому что ТЗ во всех деталях — это и есть код. Только на русском, а ещё сильно хуже и менее конкретно.
Когда пишу сам, я набрасываю верхнеуровневый код, смотрю, как это выглядит, переделываю, ещё раз смотрю, снова переделываю, и в какой-то момент меня начинает устраивать увиденное. Но тут выясняется, что половина задачи уже сделана, и ТЗ писать как будто поздно.
Вот в этот момент мне нейросеть и нужна. Во-первых, она очень хорошо вычищает временные решения, старые легаси-названия и прочие археологические артефакты от предыдущих попыток. Во-вторых, красиво оформляет и форматирует то, что я накидал как сумел. И в-третьих, её можно попросить написать краткую и ёмкую доку: что эта штука делает, как в целом устроена и где у неё основные ручки.
То есть сделать именно ту работу, на которую я обычно смотрю как кот на купание.
Найм и уровень инженера
А вот в найме, что забавно, почти ничего не поменялось.
Меня и раньше не очень интересовало, знает ли человек какой-то конкретный API или конкретный фреймворк. Меня интересовало, как он мыслит и насколько у него в голове собрано базовое инженерное понимание. Всё конкретное доучивается в процессе. С LLM это осталось неизменным.
Если человек не понимает, чем hash map отличается от map и что вообще такое кэш, то его странно называть инженером. LLM в такой ситуации его ещё и добьёт: уверенно расскажет, что всё нормально, так и надо, а у человека не хватит квалификации понять, где именно его обманули, когда всё перестанет работать.
А если человек в целом понимает, чем асинхронность отличается от параллельности, то он наверняка сможет выучить конкретный корутинный движок и с LLM, и без. Просто с LLM, скорее всего, побыстрее.
Что там с производительностью?
Ну и главный вопрос: увеличивают ли LLM производительность разработчиков? Вопрос дискуссионный. Исследований много, и они очень стараются прийти к противоположным результатам. Поэтому тут больше ориентируются на субъективные ощущения самих разработчиков.
Моё субъективное ощущение: да, меня они ускоряют примерно раза в два по закрытым задачам. По написанным строчкам, возможно, и раз в пять, но это уже за счёт той самой копипасты, о которой писал выше.
Проблема в том, что разговоры про пользу ассистентов часто упираются в миф, будто разработчик 80% времени программирует, а всё освободившееся время радостно тратит на то, чтобы программировать ещё больше.
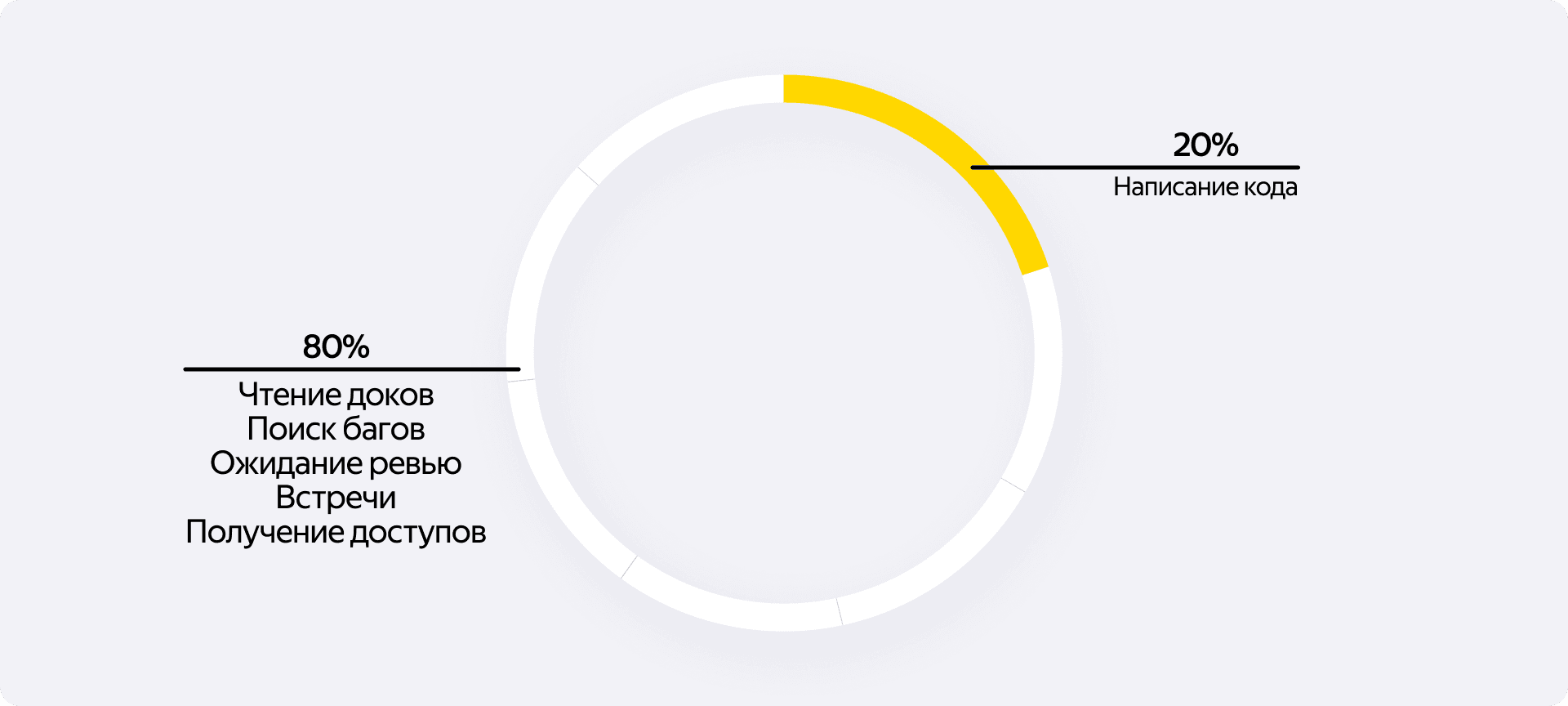
В реальности разработчик 80% времени тратит на «понять, почему ничего не работает», а ещё на «почитать доку», «выяснить, почему доки нет», «найти человека, который знает, как это работает», «получить доступы», «дождаться PR-review», «посетить все 100500 встреч по проекту», даже те, которые могли решиться буквально одним письмом.
И вот тут ассистенты действительно хороши. Они помогают не только писать код, а разбираться вокруг задачи: быстрее понять чужой проект, сделать документацию, переименовать что-то в десяти файлах, предположить, где у тебя ошибка, которую ты в упор не видишь, дописать тесты с corner cases, написать скрипты для тестинга, визуализировать текстовые данные, собрать makefile по истории команд в консоли, чтобы потом оптимизировать рутину, и много чего ещё.
А код, когда он уже концептуально понятен, они тоже помогают писать быстрее, хоть это и не основная часть нашей работы.
Итого
Не нужно ожидать, что эта штука напишет серьёзный код за вас. В этом отношении вайбкодинг всё ещё миф.
Им прикольно сделать весёлую игрушку, стартовый прототип, MVP или какую-нибудь локальную одноразовую утилиту. Но не полноценное продакшн-решение, в котором потом жить тебе, твоей команде и несчастному дежурному через полгода.
Если окажется, что AI — это пузырь, и он просто очень дорогой для решаемых им задач, то он видоизменится и займёт свою нишу, где реально стоит сжигаемого электричества и приносит пользу. Так обычно и бывает: самые громкие обещания исчезают, а полезные вещи спокойно занимают свои рабочие ниши. Моё ощущение, что в IT это уже произошло — здесь AI действительно экономит время и снимает рутину. А самое главное — стоит своих денег.
Если попытаться сшить весь этот опыт в одну мысль, то мир изменился не так уж сильно, как кажется по заголовкам в интернете.
Нейросети не заменили инженеров и не превратили разработку в волшебной кнопки «сделай красиво». Они не сняли с человека ответственность, не отменили необходимость думать и не научились стабильно писать серьёзные системы без присмотра.
Зато они неплохо забрали то, что разработчики любят меньше всего: рутину, бойлерплейт, механические правки, поиск по чужому коду, черновую документацию, однотипные задачи и «страх чистого листа».
Ну а я всё ещё полон оптимизма, что однажды меня полностью заменит нейросеть, и я наконец-то отдохну, в отпуск там схожу на пару месяцев. Ну или хотя бы просто буду работать поменьше.



