
Привет! Меня зовут Егор Пильник, я разработчик в телефонии Яндекс Такси (Calltech). Сегодня Calltech обслуживает разные бизнесы внутри экосистемы и суммарно пропускает через себя более 150 миллионов звонков в месяц.
Когда-то телефония решала простую утилитарную задачу — она маршрутизировала вызовы и соединяла абонентов по заданным сценариям. Но в современных реалиях этого становится мало. Продуктовые команды хотят глубоко анализировать обращения, чтобы улучшать работу сервисов для пользователей и партнёров.
Нам нужно помогать специалистам следить за качеством ответов поддержки, а ещё — снимать с операторов типичную рутину. Для этого мы внедряем на первую линию умных AI-агентов на базе LLM. Они помогают колл-центрам в часы пиковых нагрузок и при этом оставляют возможность бесшовно переключать звонок на человека. А чтобы всё это работало, нам необходимо надёжно, быстро и с оптимальными затратами на инфраструктуру превращать телефонный разговор в текст.
Текстовые нейросети отлично работают с символами, но телефония живёт в мире непрерывных RTP-потоков звука. Чтобы подружить эти два мира, мы построили собственную платформу работы с речью (Speech-to-Text). В этой статье я расскажу, как мы проектировали систему под такие объёмы и с какими сложностями столкнулись на пути.
Часть 1. Синхронное распознавание
До эпохи генеративных сетей голосовые боты работали как жёсткие конечные автоматы. Классический пример — старый робот заказа такси. Он вёл клиента строго по линейному скрипту: спрашивал про точку А, затем про точку Б, называл стоимость и оформлял заказ. Но такая архитектура не предполага гибких отступлений от сценария. Если на вопросе про точку Б клиент вдруг говорил: «Ой, а добавьте ещё детское кресло», алгоритму просто не хватало контекста для обработки нового запроса, и он переводил звонок на оператора.
Сейчас для первой линии поддержки у нас уже есть AI-агенты. Запрос бизнеса понятен: мы хотим автоматизировать ответы на частые вопросы с помощью LLM, чтобы робот мог общаться с клиентом голосом в реальном времени.
Кажется, что сложного? Написали промпт, подключили нейросеть — и готово.
Но чат и голосовой звонок — это два разных мира. В текстовом чате всё просто: пользователь отправил сообщение, бот подумал и прислал ответ. В телефонии приходится учитывать жёсткие тайминги, сетевые задержки и перебивания — когда клиент внезапно говорит «нет-нет, подожди». А ещё нужно очень быстро отдавать синтезированный голос обратно в линию без неловких пятисекундных пауз.
Сравниваем подходы к подключению LLM к голосовым потокам
Интегрировать LLM в телефонию можно тремя способами и у каждого из них есть как свои плюсы, так и минусы.
1. SIP-трансфер Самый простой путь — воспринимать AI-агента как ещё один телефонный номер. Мы просто переводим звонок на внешнюю платформу по протоколу SIP, а дальше она всё делает сама.
- Плюсы: быстрый запуск. Можно использовать готовых вендоров.
- Минусы: меньше контроля над сессией и ограниченная наблюдаемость. При таком подходе становится сложнее отслеживать контекст дилога и управлять перебиваниями. К тому же не все внешние решения поддерживают нужную модель интеграции, чтобы бесшовно вернуть клиента обратно в наше IVR-меню, если потребуется помощь живого специалиста.
2. Разделение логики Чтобы вернуть контроль, мы разделяем ответственность. Внешняя LLM работает только с текстом, а ядро телефонии забирает на себя всю работу со звуком. Пайплайн выглядит так: голос клиента → синхронный STT (распознавание) → LLM → TTS (синтез) → линия.
- Плюсы: высокая управляемость бизнес-логики. Мы управляем звонком, пишем логи диалога и в любой момент можем переключить вызов на человека.
- Минусы: сложная оркестрация. Нам нужно самим бороться за миллисекунды между распознаванием, генерацией токенов и синтезом речи.
3. Нативный коннектор к AI‑агенту на уровне медиа Это самый свежий, гибкий и инженерно сложный путь. Мы не отдаём звонок по SIP и не дробим его на текст. Вместо этого платформа поднимает отдельный коннектор (WebSocket или gRPC) и стримит сырой аудиопоток прямо в AI-сервис, получая обратно ответный поток.
- Плюсы: AI-агент становится управляемым медиаканалом внутри нашей платформы. Оркестратор видит сессию, контролирует жизненный цикл коннектора и может мгновенно прервать бота.
- Минусы: максимальная сложность реализации. Приходится на низком уровне работать с медиа, синхронизацией потоков и сетью.
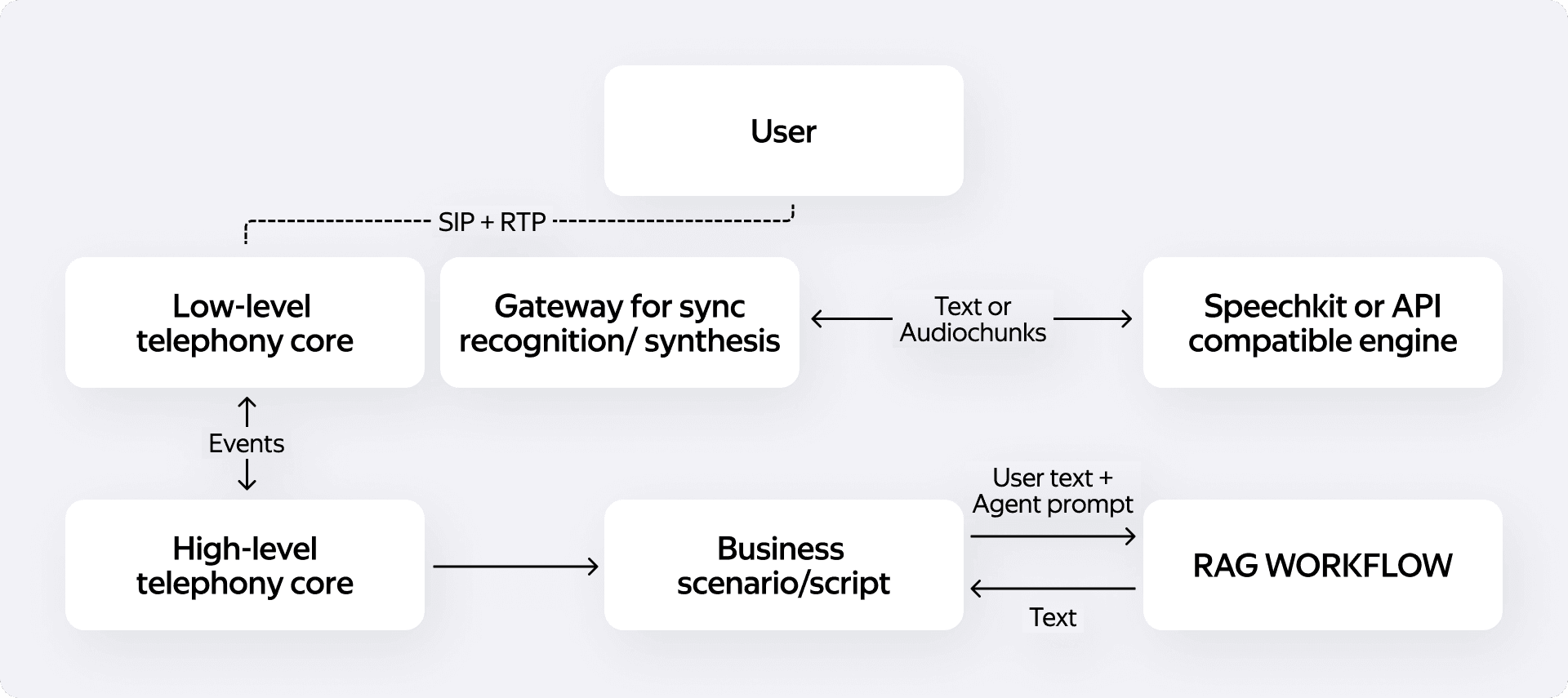
Устройство медиа-коннектора для потоковой передачи RTP-трафика
Исторически для синхронного распознавания мы использовали YandexCloud SpeechKit. Архитектура потоковой передачи медиа выстроена вокруг его интерфейсов.
Когда появилась потребность подключать другие ML-движки, мы решили жёстко ограничить количество разных протоколов в ядре телефонии. Мы стараемся не писать кастомные адаптеры под каждое новое API. Вместо этого переиспользуем уже проверенные интерфейсы — в первую очередь gRPC/Protobuf-контракт от SpeechKit — как унифицированный внутренний стандарт.
Как только начинается фаза диалога с ботом, наша платформа добавляет в звонке дополнительный медиаканал. Мы берём живой RTP-трафик из линии и на лету открываем двунаправленный gRPC-стрим к системе распознавания.
В одну сторону непрерывно передаются аудиофрагменты. В обратную сторону к нам асинхронным потоком сыплются текстовые гипотезы. Причём мы получаем промежуточные результаты ещё до того, как человек закончит фразу — это критически важно для быстрых ответов.
Автоматизация первой линии поддержки в пиковые часы нагрузок
В моменты пиковых нагрузок — плохая погода, утренние часы-пик или праздники — количество обращений резко возрастает. Раньше в таких ситуациях время соединения со специалистом увеличивалось, и водителю приходилось ждать ответа дольше обычного.
Теперь система работает умнее. Если мы видим, что все операторы заняты, то мгновенно переводим звонок водителя на AI-агента. Водителю достаточно описать свою ситуацию естественным голосом в реальном времени. Благодаря нашему синхронному пайплайну нейросеть понимает суть проблемы, консультирует человека или фиксирует обращение в тикете — и всё это без участия оператора.
Забирая на LLM-агентов всё больше звонков, мы ощутимо разгружаем штат поддержки и существенно сокращаем время ожидания в типовых сценариях.
Часть 2. Асинхронное распознавание
Если в синхронном флоу мы бьёмся за каждую миллисекунду, то в асинхронном распознавании правила игры меняются. Здесь на первый план выходят отказоустойчивость, масштабируемость и стоимость хранения. Сразу уточню важный момент: мы не расшифровываем все разговоры подряд. Транскрибация запускается выборочно и только по запросу продуктовых команд для конкретных целевых сценариев.
Но даже при таком точечном подходе объёмы получаются внушительными. Сейчас наша система обрабатывает больше 1,5 ТБ аудио в день — это около 20 миллионов записей в месяц. И мы готовы к дальнейшему росту.
Управление потоками данных и биллинг при запуске STT-задач
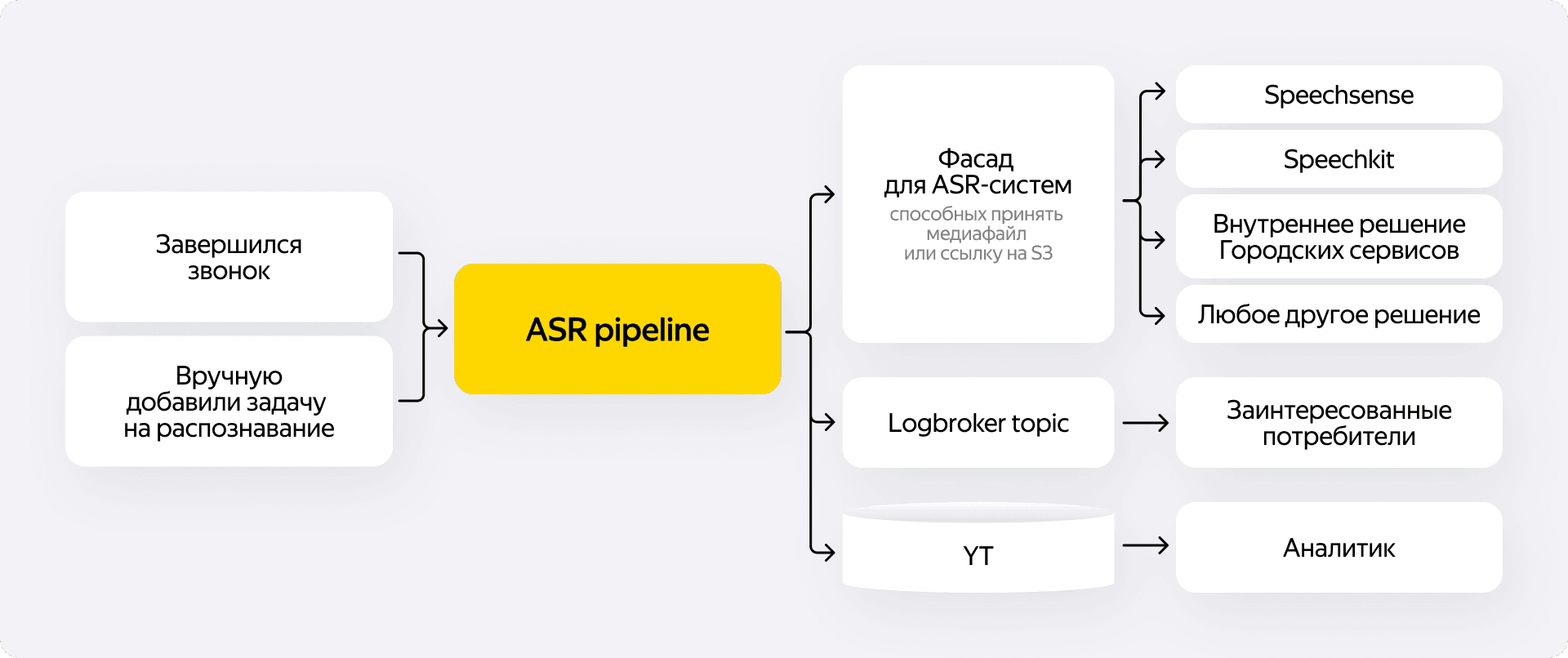
Как только звонок завершается, стартует конвейер обработки. У нас есть две точки входа: автоматическая и ручная.
Автоматика встроена прямо в ядро телефонии. Звонок заканчивается, система смотрит на метаданные — длительность, причину завершения, логин оператора — и сама инициирует транскрибацию. Это отлично работает для массовых сценариев.
Но автоматика покрывает не всё. Часто у продуктовых команд есть своя сложная бизнес-логика. Например, нужно расшифровать только те звонки, которые связаны с отменой заказа в конкретном районе. Наша платформа о таких деталях не знает. Поэтому продуктовый бэкенд сам фильтрует записи и дёргает ручку нашего API.
Важный нюанс — клиент не может просто так отправить звонок в любую систему распознавания. Каждый запрос проходит строгую авторизацию. Мы проверяем права вызывающего сервиса и только после этого запускаем пайплайн.
Доставить аудио до ASR-системы можно двумя путями:
- Через gRPC-стрим. Мы непрерывно переливаем аудио чанками — так система работает со SpeechSense и SpeechKit.
- Через общее хранилище S3. Мы кладём тяжёлый аудиофайл в бакет, а в ASR-систему отправляем только ссылку. Чтобы не тратить лишние деньги, на бакетах висит жёсткий TTL. Ровно через сутки файл удаляется согласно политике жизненного цикла хранения.
Выбор паттерна Polling для управления сотнями тысяч корутин
В моменте у нас может крутиться до 100 000 задач на распознавание. Ждать результат синхронно при таком объёме — непозволительная роскошь.
Во-первых, держать сто тысяч корутин в ожидании ответа слишком дорого по железу. Во-вторых, это небезопасно. Если в дата-центре моргнёт питание и стойка перезагрузится, мы просто потеряем весь контекст ожидания.
Идеально было бы получать результат реактивно — через push-уведомления от ASR-системы. Но в текущих движках такого функционала нет, а дорабатывать внешнюю платформу нецелесообразно. Поэтому мы используем паттерн Polling.
Внутренняя модель транскрибации работает быстро: 50-й перцентиль (p50) составляет всего 20 секунд. Наши асинхронные воркеры периодически опрашивают ASR: «Уже готово?». Как только результат получен, задача успешно закрывается. Если воркер упадёт во время поллинга, ничего страшного не произойдёт — задачу просто подхватит другой инстанс.
Дистрибуция результатов: Postgres vs YT
Готовый текст мы не просто сохраняем в базу, а пушим в шину событий Logbroker. Благодаря этому все заинтересованные потребители — аналитика, CRM, дашборды контроля качества — узнают о завершении обработки реактивно и сразу забирают данные себе.
Но где хранить миллионы расшифровок для истории?
Держать такие объёмы в транзакционном PostgreSQL слишком дорого. Поэтому там лежат только горячие данные с TTL в три месяца. Для долгосрочного хранения мы написали сервис репликации. Он периодически собирает результаты в пачки и переливает их в YT — внутреннюю платформу распределённого хранения данных Яндекса.
Здесь мы получаем двойную выгоду:
- Эффективное масштабирование. В YT тексты могут безопасно храниться годами. Благодаря этому можно эффективно наращивать объёмы хранилища по мере роста, не раздувая при этом бюджет на инфраструктуру.
- Глобальная аналитика. YT — это единая экосистема данных. Благодаря ей аналитики могут сопоставлять обезличенные тексты обращений с техническими логами сервисов. Например, если пользователи массово звонят с сообщением об ошибке, мы можем связать суть их проблемы с метриками конкретного релиза или системного сбоя. Если бы расшифровки лежали запертыми в локальном PostgreSQL, такая кросс-сервисная аналитика была бы физически невозможна.
Саммаризация диалогов с помощью LLM для экономии места на дисках
Транскрибировать 100% звонков — не самоцель, а фундамент для трёх больших продуктовых процессов.
Тотальный контроль качества (СКК). Автоматические инструменты позволяют анализировать качество на значительно большей выборке, чем ручная проверка. Мы пишем звонки в стерео: один канал для клиента, второй для оператора. Это позволяет системам аналитики делать глубокие выводы. Перебивал ли оператор клиента? Использовал ли слова-паразиты? Звучал ли уверенно? Были ли нарушения скрипта? Алгоритм автоматически превращает всё это в метрики на дашборде.
Автоматизация поддержки. Представьте: клиент звонит с проблемой. Раньше оператору приходилось параллельно разговору вручную описывать суть обращения в тикете. Теперь звонок завершается, аудио улетает в транскрибацию, полученный текст прогоняется через LLM для суммаризации, и в CRM Такси мгновенно создаётся готовый тикет с короткой выжимкой проблемы. Мы снижаем когнитивную нагрузку на сотрудников — они могут полностью сосредоточиться на помощи человеку, а не на ручном заполнении полей. А заодно мы оптимизируем ресурсы платформы, поскольку краткие текстовые саммари занимают значительно меньше места на дисках, чем исходные аудиофайлы.
Роботы проверяют роботов. Когда наш синхронный голосовой LLM-бот общается с человеком, мы точно так же отправляем этот звонок в асинхронную аналитику. Текстовый лог диалога проверяется на галлюцинации нейросети, зацикливания или моменты, где ИИ потерял контекст. Получается красивая концепция — нейросети говорят с людьми, а наша инфраструктура помогает людям контролировать нейросети.
Итоги
Сегодня телефония — это уже не просто коммутатор, переключающий звонки между линиями, как было когда-то. По сути, мы превратили её в надёжный инструмент развития.
Мы начинали с утилитарных задач маршрутизации, а пришли к системе с двумя независимыми, но одинаково важными контурами. Нам пришлось научить платформу быть одновременно быстрой и выносливой. В реальном времени мы непрерывно передаём аудиопоток в систему распознования речи, чтобы виртуальный помощник мог мгновенно реагировать на запросы и человек получаал помощь без задержек и пауз в диалоге. А в фоне — методично обрабатываем терабайты записей, чтобы бизнес мог контролировать качество и автоматизировать рутину операторов.
Главный вывод, к которому мы пришли за время работы над архитектурой: чтобы LLM действительно приносила пользу сервису, под ней должен работать надёжный инженерный фундамент. Вам нужно уметь управлять сетевыми таймингами, оркестрировать аудиопотоки на низком уровне и строить отказоустойчивые конвейеры для тяжёлой аналитики.
Именно этот невидимый транспортный слой STT-маршрутизации делает интеграцию искусственного интеллекта возможной. Мы научились бесшовно связывать живую человеческую речь и машинную логику. Да, это сложно, но когда ты видишь, как система стабильно выдерживает высокие нагрузки и берёт на себя тысячи звонков одновременно — понимаешь, что всё было сделано не зря.



