
Абсолютное большинство поездок в такси — 99,99% — проходят в штатном режиме. Любые инциденты на этом фоне выглядят как микроскопическая статистическая аномалия. Но когда у тебя есть технический диплом и инструменты машинного обучения, попытаться свести к минимуму что-то настолько страшное в реальном физическом мире, как ДТП, становится делом чести.
Меня зовут Филипп Ульянкин. Я руковожу группой технологий безопасности в Техплатформе городских сервисов Яндекса. Мы делаем общие ML-компоненты для Go, Лавки, Доставки и других юнитов. Моя команда занимается в том числе антифродом и строит алгоритмы для предотвращения ДТП.
Несколько лет назад мы запустили «безопасный диспатч» — контур, который вмешивается в распределение заказов между водителями, чтобы снизить общую аварийность. Система всё это время вполне успешно работала в фоне. И вот недавно мы решили её обновить.
Наверняка вам знакома такая ситуация. Вы открываете старый проект, чтобы дотюнить его и выкатить несколько классных новых фич. Но тут выясняется, что инженеры, которые писали первую версию, давно ушли на другие задачи, документация отсутствует, а внутри запрятано несколько совсем неочевидных костылей. Вот примерно то же самое случилось и с нами.
Эта статья — моя история того, как мы пытались улучшить старую систему. Мы поговорим об инфраструктурных проблемах, сложных гео-экспериментах и компромиссах между точностью модели и выручкой бизнеса. Если вам приходилось обновлять легаси-алгоритмы, договариваться с продуктовыми менеджерами об обсчёте метрик и чинить тесты — вы точно узнаете в нашей истории себя.
Что такое «Безопасный диспатч» и как он работает
Чтобы понять, что такое безопасный диспатч, нужно сначала вспомнить, как устроен обычный. В каждый момент времени в городе есть некоторое количество пассажиров, которые хотят уехать, и некоторое количество свободных водителей вокруг них. Система собирает их всех в батчи и распределяет заказы так, чтобы было быстро и комфортно всем участникам поездки – и водителю, и пассажиру.
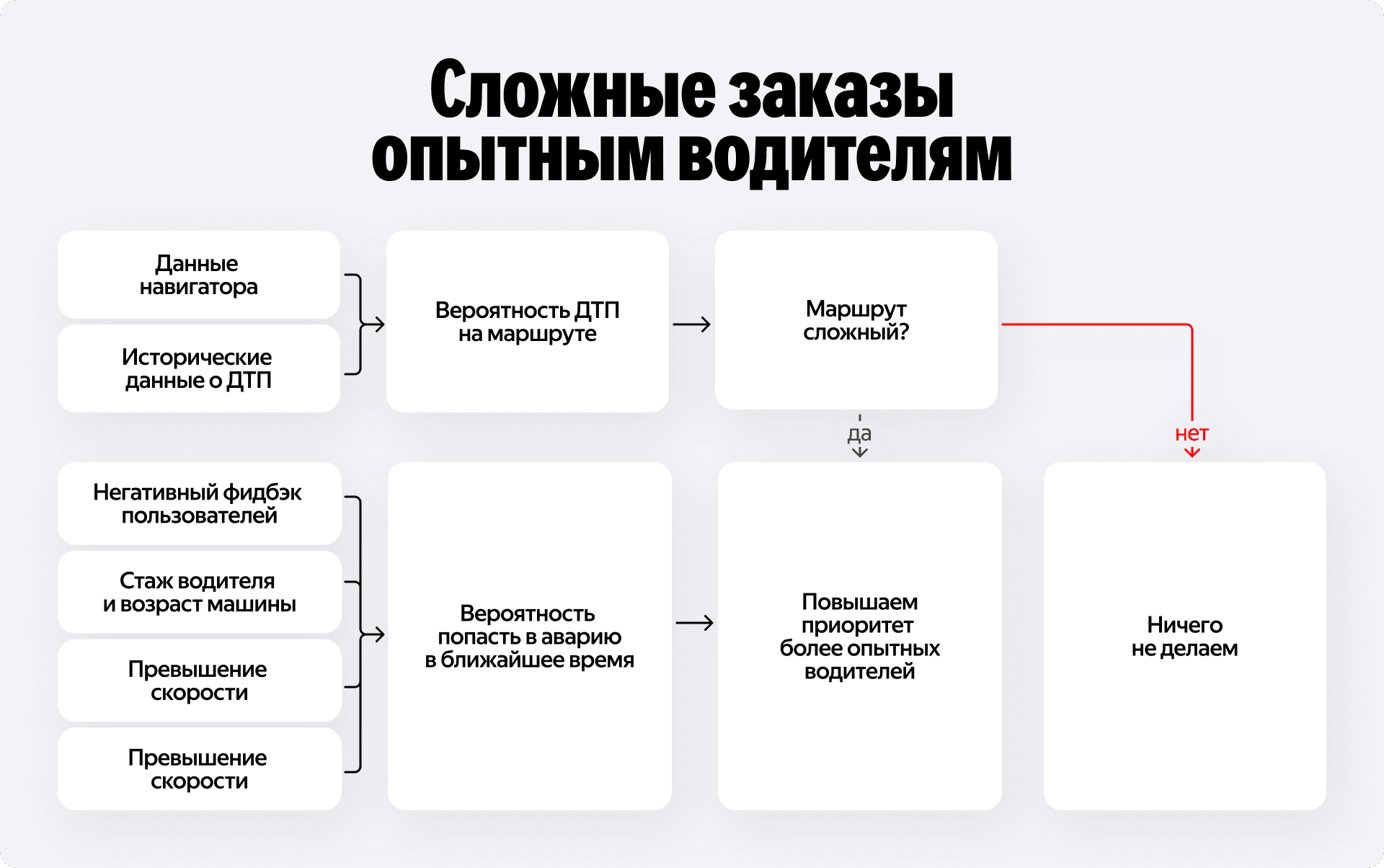
Мы решили вмешаться в этот мэтчинг и переиграть его. Идея простая — увеличить время ожидания, чтобы снизить риск ДТП. Для этого нам понадобилось оценить две метрики: сложность будущего маршрута и опытность конкретного водителя.
Как мы оцениваем маршрут
Мы взяли статистику по инцидентам из навигатора и покрасили дорожный граф в разные цвета. Количество ДТП на каждом участке дороги мы нормировали на её пропускную способность. На тепловой карте сразу выделились крупные автострады и проспекты. Там плотный и быстрый трафик, поэтому риск ДТП статистически выше. Теперь, когда пассажир заказывает такси, система сразу видит, насколько сложным будет путь.

Как мы оцениваем водителя
Параллельно мы обучили ML-модель. Её единственная задача — предсказывать вероятность того, что каждый конкретно взятый водитель попадёт в ДТП в ближайшие 24 часа. В качестве фичей модели мы используем:
- стаж водителя и возраст машины;
- частоту превышений скорости по данным GPS;
- резкие маневры по акселерометру смартфона;
- отзывы и оценки от пассажиров.
На основе предсказаний модели мы разделили всех водителей на пять категорий аварийности — от самых надёжных до менее опытных.
Сборка системы в продакшене
В режиме реального времени всё работает так: поступает новый заказ, система проверяет маршрут. Если он безопасный — мы вообще не вмешиваемся. Но если путь предстоит сложный, а система назначила на него водителя из группы с высоким риском, мы искусственно завышаем для этого водителя время подачи, и заказ переходит к более опытному таксисту, даже если он находится чуть дальше. Менее опытный водитель не останется без работы. Он моментально получает другой, более простой заказ с маршрутом попроще — например, короткую поездку на спокойных улицах внутри знакомого района.
Что мы получили на старте
Когда мы запустили технологию и провели первый масштабный эксперимент, результаты нас на самом деле впечатлили. Общее количество ДТП с участием такси в России снизилось на 3,5%. Это означает, что алгоритм в реальном времени предотвращает каждую тридцатую аварию. При этом цена за такое повышение безопасности оказалась минимальной — время ожидания машины для пассажира выросло в среднем всего на 10 секунд.
Мы отмасштабировали схему на все крупные города и оставили технологию работать в формате вечного A/B-теста с разбиением 90 на 10. И она успешно крутилась в таком виде больше трёх лет. Ровно до тех пор, пока мы не решили сделать её ещё лучше. И вот тут-то начались проблемы.
Что же могло пойти не так?
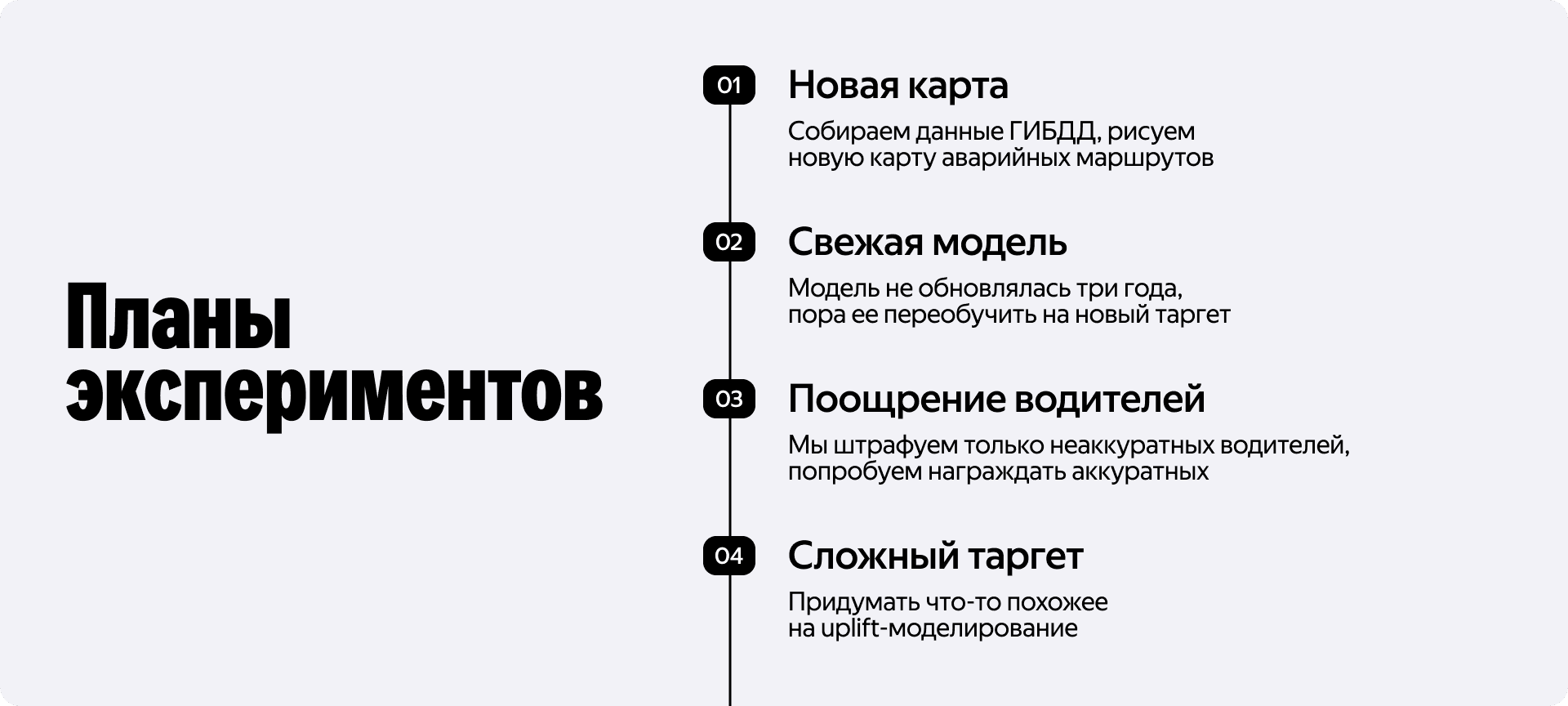
Со временем у нас появилась идея использовать данные ГИБДД для обновления карты инцидентов и переобучить модель на новый таргет. Дальше мы хотели начать поощрять аккуратных водителей, а не только штрафовать потенциально опасных. А в перспективе — придумать что-то похожее на uplift-моделирование.
Казалось, мы согласовали этот roadmap со всеми техническими смежниками. Но… не со всеми. В какой-то момент к нам пришли смежники из водительского продукта с резонным вопросом — а что там с деньгами?
Мы привыкли гордиться тем, что роняем аварийность ценой крошечной задержки времени подачи. Но у бизнеса, кроме этой, есть ещё 30 других метрик. А раз уж у нас годами крутился вечный A/B-тест, продуктовая команда попросила обсчитать влияние нашей модели на всю экономику сервиса.
Мы выгрузили данные и увидели не очень радостную картину: время подачи из-за безопасного диспатча действительно росло незначительно. А вот доля отмен заказов оказалась пугающе высокой. Из-за алгоритма серьёзно проседал Completion Rate (CR) — метрика заказов, которые успешно завершились.
После всего этого наш безупречный, казалось бы, план действий пришлось резко переписывать. Амбициозные проекты и сложные модели отложились на неопределённый срок. А вместо этого мы сфокусировались на более приземлённых задачах:
- Найти общий язык с бизнесом. У нас и у продуктовой команды были разные пайплайны подсчёта метрик. Нужно было договориться о единых правилах, заново обсчитать все старые эксперименты и смотреть на одни и те же дашборды.
- Автоматизировать аналитику. Экспериментов планировалось много. Писать кастомные скрипты под каждый тест долго и неэффективно, поэтому мы решили сделать единый пайплайн, который считает всё по кнопке.
- Научиться фильтровать пробки. Если мы перестанем учитывать в выборке маршруты, которые стоят в плотной пробке, мы отпустим часть водителей из-под ограничений контура. Это должно починить CR и снизить количество отмен.
- Повысить точность ML-модели. Чем лучше мы понимаем, кто из водителей более склонен к лихачеству на дорогах, тем реже мы ошибаемся в распределении заказов. Точная модель будет значительно слабее влиять на бизнес-метрики.
Так, отказавшись от строительства сложных моделей, мы перешли к обсчёту A/B-тестов. В условиях такого сервиса как Такси у них есть своя особая специфика.
Хардкорная математика в действии
Автоматизировать обсчёт A/B-тестов легко только на бумаге. Когда вы выводите эксперименты в реальный физический мир с машинами, улицами и сложной географией, велик шанс, что что-нибудь непременно сломается. Мы столкнулись с тремя проблемами
Проблема первая: сетевые эффекты
В классическом вебе можно поделить пользователей на тестовую и контрольную группы по ID. В такси этот подход не работает, потому что водители конкурируют друг с другом за одни и те же заказы в едином пространстве.
Представьте, что мы разбили батч таксистов на две части. Если алгоритм штрафует водителя из тестовой группы и отодвигает его в очереди, заказ тут же перехватывает водитель из контрольной группы. Просто потому что он оказался рядом. Две группы коррелируют друг с другом, контрольная группа перетягивает в себя заказы из тестовой. Это портит результаты эксперимента и делает их обсчёт недостоверным.
Чтобы отвязаться от сетевых эффектов, мы проводили эксперимент в формате switchback. Главная идея такого подхода – дробить сущности не по ID, а по времени. Алгоритм работает так: каждые 17 минут система подкидывает монетку и решает, включаем ли мы в этой итерации штрафы за аварийность для всей тарифной зоны или нет. В итоге все водители всегда находятся в одинаковых условиях.
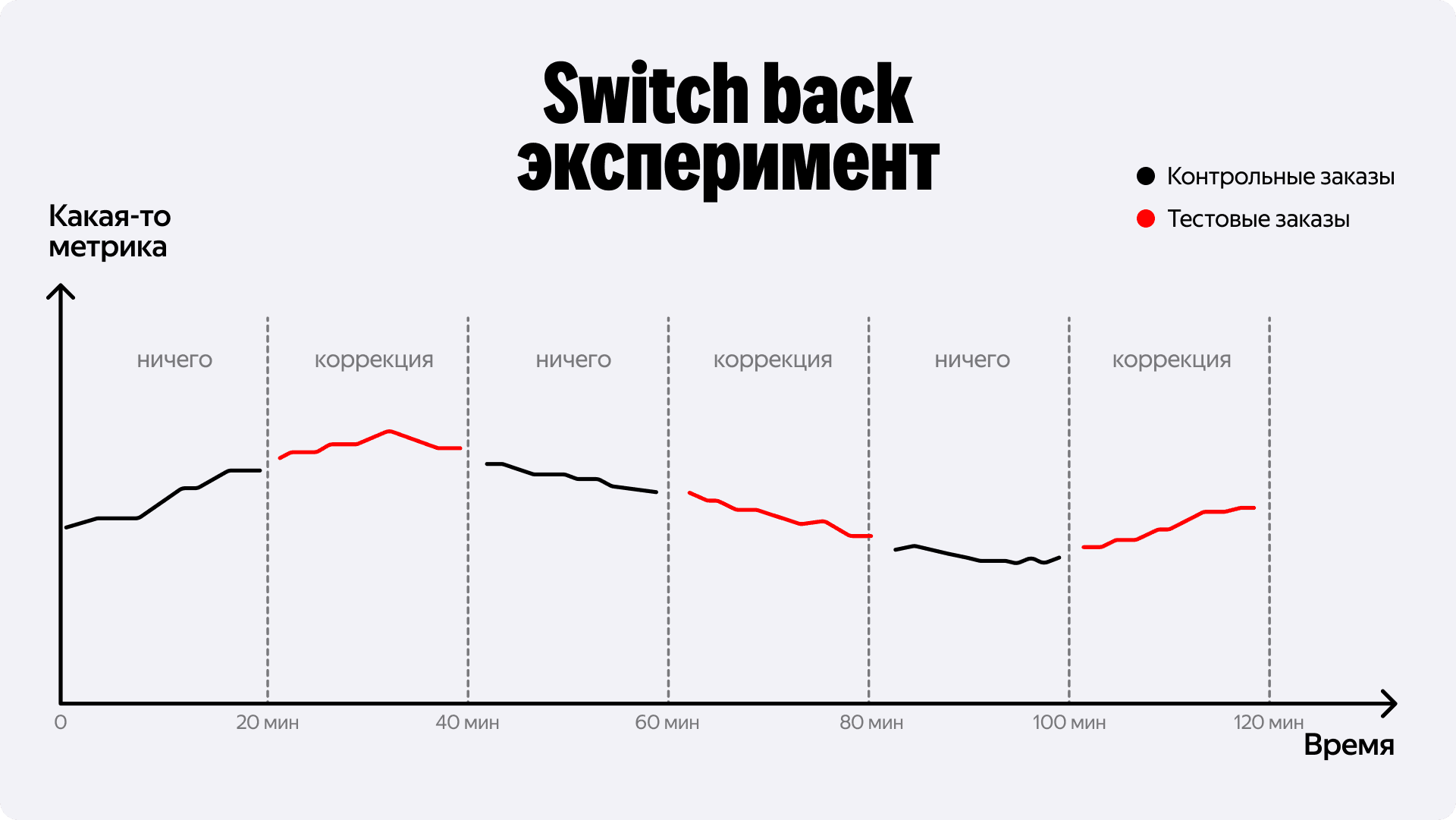
Интервал мы выбрали неслучайно. Главное условие — чтобы это было простое число. Иначе моменты переключения совпадут с сезонностью внутри дня — например, алгоритм будет работать только по утрам, а вечером отключаться. Простое число позволяет периодам двигаться ото дня ко дню. В моменты, когда мы переключаем поведение системы могут возникать заказы, попадающие в оба временных промежутка. Для фильтрации таких краевых случаев на границах временных интервалов мы просто срезаем события по краям на N секунд.
Проблема вторая: нечувствительный таргет
Как я уже говорил, ДТП — крайне редкое событие. А когда какое-то событие происходит редко, то для достижения статистической значимости нужно достаточно долго копить данные. У нас нет столько времени на проверку каждой продуктовой гипотезы.
Стандартная практика работы с нечувствительными метриками заключается в строительстве дерева метрик. На вершине этого дерева находится то, на что мы хотим влиять, но это крайне сложно. Чем ниже мы движемся по дереву, тем чувствительнее становится метрика и тем быстрее она красится. Мы решили построить аналогичное дерево для аварийности:
- Верхний уровень: количество ДТП на миллион километров. Красится очень долго, но мы хотим на них повлиять.
- Средний уровень: жалобы на опасное вождение и похвала за хорошее. Эти метрики чувствительнее, чем количество ДТП и их реалистичнее прокрасить. При этом они коррелируют с аварийностью и сонаправлены с ней.
- Нижний уровень: резкие маневры, детектированные на основе акселерометра в телефоне водителя. Если машину резко тряхнуло, значит, на дороге уже возникла потенциально аварийная ситуация. Такая прокси-метрика крайне чувствительна и реагирует на изменения в алгоритмах на порядок быстрее.
Проблема третья: метрики отношения и зависимость от географии
Switchback-тесты порождают серьёзную аналитическую боль: мы дробим эксперимент по времени, а финальные метрики хотим считать в разрезе заказов, водителей или километров. Срез рандомизации не совпадает со срезом расчёта.
Метрики, для которых так происходит называют метриками отношения. Метрика отношения — это дробь, где и в числителе, и в знаменателе находятся случайные величины. Если аппроксимировать их нормальными распределениями и поделить друг на друга, мы получим распределение Коши. У него толстые хвосты и бесконечная дисперсия. Классический подход на основе центральной предельной теоремы здесь не работает.
Ещё один фактор — география. Очевидно, что 100 километров пробега по ночной Твери совершенно не равны 100 километрам по утренней загруженной Москве.
Чтобы очистить расчёты от этих искажений, при обсчёте теста мы делаем гео-бакетирование. Мы разбиваем карту на отдельные зоны (геохеши) и считаем все события внутри одного геохеша за одно наблюдение. Да, выборка катастрофически режется, но зато мы избавляемся от географической зависимости.
А для самого обсчёта таких метрик мы используем перестановочные критерии или бутстрап. Если процесс нужно распараллелить и ускорить, отлично подходит пуассоновский бутстрап по наблюдениям — изящный метод, который инженеры Google предложили ещё в 2012 году.
Научившись корректно и быстро считать результаты, мы наконец-то приступили к продуктовым экспериментам. Первым делом нужно было вернуть бизнесу упавший Completion Rate.
Хорошая инженерия — это компромиссы
Наладив пайплайн A/B-тестов, мы вернулись к продуктовым задачам. Нам нужно было отбить падение бизнес-метрик и наконец-то внедрить новую ML-модель. И здесь нам пришлось искать ту самую золотую середину между сложной передовой инженерией и быстрыми, прагматичными решениями.
Эксперимент первый: фильтрация пробок
В плотном заторе риск серьёзного инцидента стремится к нулю. Если опасный скоростной маршрут прямо сейчас стоит в глухой пробке, то машины в любом случае будут ползти по нему медленно. А значит, и применять штрафы к водителям на таких маршрутах не нужно. Если мы отпустим эти поездки из-под контроля контура, то снизим количество отмен заказов.
Как решить такую задачу? Первая идея, которая приходит в голову внутри Яндекса – сходить к коллегам из геосервисов. Возможно, у них уже есть готовое API и из него можно было бы брать баллы пробок по десятибальной шкале. Однако мы решили не идти по такому пути — за такой интеграцией последовало бы примерно полгода инфраструктурной разработки. Это слишком долго.
Мы решили использовать те данные, которые уже есть в клиенте Go при создании заказа. Приложение умеет заранее рассчитывать прогноз времени в пути и расстояние. Поделив одно на другое, мы легко получаем ожидаемую среднюю скорость на маршруте. Практически без дополнительной разработки.
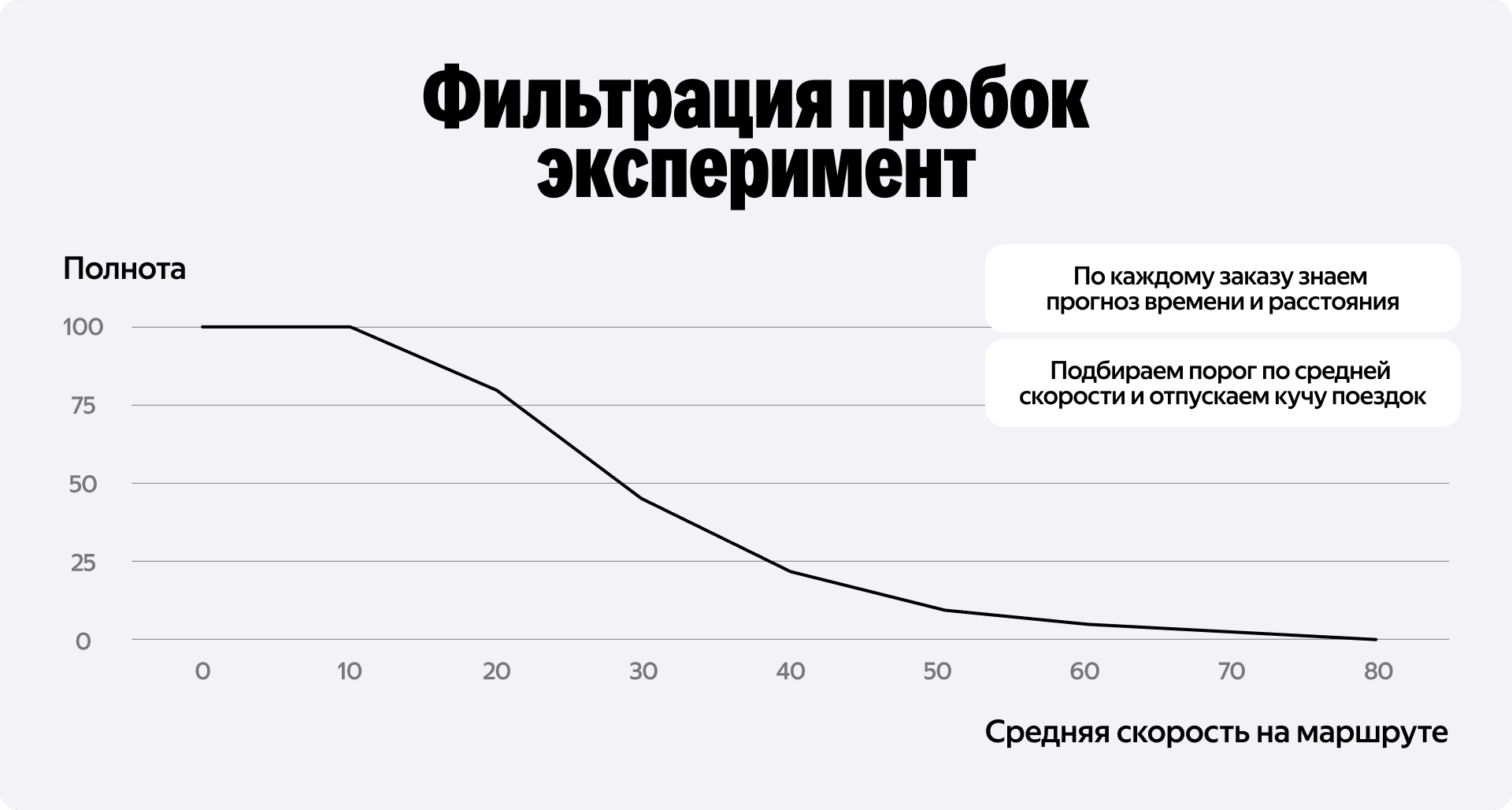
Так и поступили: построили кумулятивную кривую, отложив по оси X среднюю скорость, а по оси Y — количество аварий. График показал, что если мы установим порог отсечения в районе 15 км/ч, то сможем игнорировать контур безопасности для огромного числа относительно безопасных медленных поездок. При этом мы по-прежнему будем отлавливать 90+% опасных инцидентов.
Эксперимент второй: новый таргет
Параллельно мы занялись обновлением модели. У нас накопилось довольно много свежей, более точной статистики, на которую мы решили переобучить классификатор водителей.
Старая модель училась на данных службы поддержки и навигатора. А это весьма специфическая выборка: она сильно перекошена в сторону мелких происшествий. Водители могли просто притереться бамперами и разъехаться по европротоколу, но такое обращение всё равно будет зарегистрировано в саппорте. А вот то, что есть в базе ГИБДД — это уже крупные ДТП с пострадавшими, которые часто вообще не попадают в саппорт.
Получилось два множества данных, дополняющих друг-друга. Новый таргет – это прекрасно, но мы натыкаемся на проблему: старая и новая модели несравнимы по классическим метрикам классификации, так как обучены предсказывать таргет разной природы.

Другая проблема крылась в логике предсказаний. Если учить модель прогнозировать факт аварии в обозримом будущем, она быстро находит очевидную закономерность: водители, которые проводят на линии 10 часов в день, попадают в ДТП чаще тех, кто работает по 2 часа, банально потому что работают больше времени. И чтобы модель не начала дискриминировать активных водителей и отправлять их только на короткие заказы, таргет обязательно нужно нормировать — например, рассчитывать количество инцидентов на 100 километров пробега или на 24 часа работы.
Куда же без неожиданностей
Раскопки старой модели принесли ещё несколько неприятных сюрпризов. Мы перенесли её с обособленной базы данных на новое единое хранилище фичей и решили посмотреть, как эти фичи ведут себя в реальности.
Оказалось, что часть данных сильно деградировала. Например, модель активно использовала признак «превышение скорости по GPS». Но в последнее время полагаться только на сигнал GPS в Москве нельзя. Из-за этого значение фичи резко съехало, утащив за собой итоговый предикт.
Часто случается так, что при обучении градиентного бустинга инженеры смотрят на Feature Importance и оставляют кучу разных признаков с важностью примерно 1e-10 — просто на всякий случай, чтобы были. Но в продакшене любая из таких фичей может сломаться и испортить прогноз. Поэтому мы безжалостно вычистили модель от всего лишнего и неэффективного, а на оставшиеся сильные признаки повесили систему алертов.
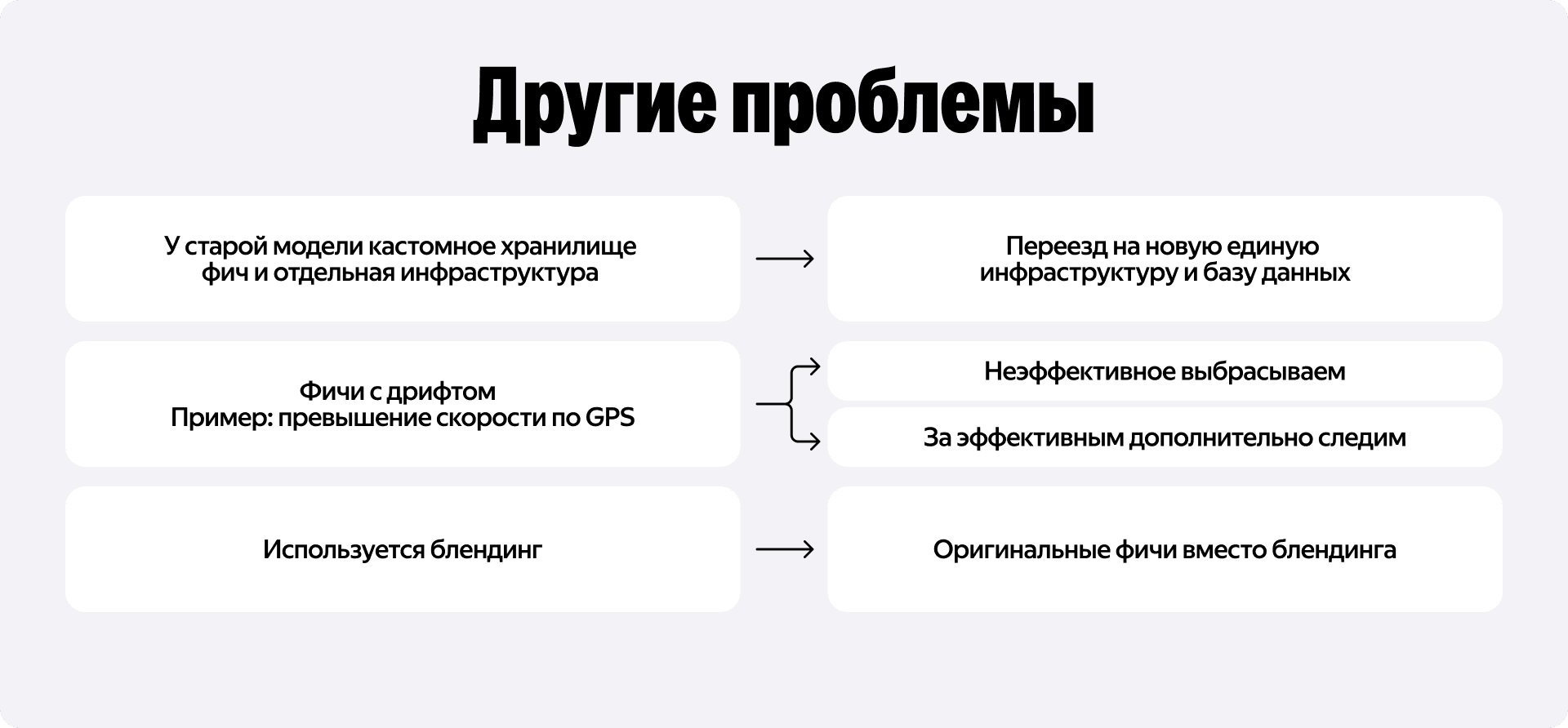
А ещё мы обнаружили в продакшене блендинг. Наша главная модель принимала на вход прогнозы от других, более мелких моделей — например, от детектора опасных манёвров. Это проблема, потому что при обновлении модели детекции опасных манёвров старую версию модели придётся продолжать поддерживать. Это жутко неудобно. Блендинг отлично работает на соревнованиях Kaggle, когда вам нужно выбить тысячные доли в метрике ради победы. Но вот в реальном бизнесе это нестабильный механизм, от которого мы предпочли полностью избавиться, перейдя на прямую подачу оригинальных признаков.
Какие уроки мы можем из этого вынести
Что же у нас получилось в итоге? Внедрение новой модели вместе с эвристикой пробок дало именно тот результат, который мы искали. На оффлайн-данных мы увидели, что можем выпустить из-под ограничений контура 40% водителей, сохранив полноту детектирования инцидентов на уровне 90%. А в самой аварийной группе мы даже смогли поднять полноту в три раза.
Только после этого, спустя целый год инфраструктурных раскопок, мы наконец смогли вернуться к нашему изначальному плану — тем самым более сложным подходам, которые мы теперь планируем делать дальше.
Какие уроки мы из этого можем извлечь?
1. Вы никогда не сможете договориться со всеми Когда вы планируете масштабный проект, смиритесь с фактом: вы точно поговорите не со всеми. Как бы тщательно вы ни собирали требования, обязательно появятся те, кому ваш проект интересен, но вы об этом не догадывались.
2. Время нужное на разработку всегда недооценивается Время нужное для разработки всегда недооценивается. Задачи, которые кажутся делом одной недели, растягиваются на месяцы из-за различных особенностей всплывающих прямо в процессе. Если есть возможность сначала реализовать простое решение, а затем перейти к более фундаментальной разработке – это всегда надо сделать.
3. Польза вечных A/B-тестов Держать долгосрочную контрольную группу — отличная практика. Вечный A/B-тест выручает в кризисных ситуациях. С метриками на руках легче вести переговоры. А ещё такой тест всегда покажет, работает ли до сих пор ваша технология в принципе или эффект от неё уже деградировал.
4. Код — это не ваш домашний питомец Мы часто относимся к своему коду как к любимому котику или собачке — бережём его и сильно страдаем, если с ним приходится расставаться. Когда вы сдуваете пыль со старых процессов, будьте готовы, что, возможно, придётся всё выбросить. В машинном обучении 99% написанного кода, собранных датасетов и сложных SQL-запросов рано или поздно отправится на помойку. Такова объективная реальность инженерии. Относитесь к своему коду как к телёнку. Заботьтесь о нём, но держите в голове, что в какой-то момент вы его отправите на убой.
Если подытожить, то не бойтесь избавляться от старого кода, сомневайтесь в готовых фичах и говорите с бизнесом на одном языке. Тогда любые, даже самые сложные системы, будут работать чётко и приносить реальную пользу.



