
Всем привет! Меня зовут Костя Ларгин. Уже больше семи лет я работаю в Яндексе, а последние пять руковожу мобильной разработкой в Яндекс Еде. На данный момент у нас больше двадцати команд. Каждый месяц — двести, а то и триста пулл-реквестов. Каждую неделю — релиз. В релизе — по пятьдесят новых задач. Иногда больше. При этом crash-free стабильно держится на уровне 99,99%, а количество инцидентов из-за мобильных приложений за год стремится к нулю. Неплохо, правда?
А что, если я скажу, что таких результатов мы добиваемся, не тестируя часть задач перед выкаткой в прод в привычном понимании этого слова? Звучит дико? Я вас понимаю. Я бы сам раньше так подумал. Как можно отказаться от тестирования в таком большом и сложном продукте, как Яндекс Еда?
Но так было не всегда. Такой подход — результат долгого и сложного пути. Мы многое пробовали, наделали кучу ошибок, спорили, переделывали процессы, искали нестандартные решения. И в итоге нашли свой способ. В этой статье я расскажу, с какими проблемами мы столкнулись, как выстроили текущие процессы и что получили в итоге — и хорошего, и не очень. А вы уже сами решите, нужен вам такой подход в вашей команде или нет.
Как мы жили (и страдали) в 2023-м
Чтобы понять, через что мы прошли, давайте перенесёмся в 2023 год. Тогда всё выглядело совсем иначе.
Началось всё постепенно. На регулярных встречах команд Android и iOS всё чаще стали слышаться вопросы: «Посмотрите, пожалуйста, пулл-реквесты», «Пулл-реквест слишком долго висит на ревью» и так далее. Первая мысль была, что команда начала, мягко говоря, забивать и саботировать процессы — мол, ревью никому не интересно. Я поговорил с несколькими людьми, напомнил, как важно делать код-ревью вовремя, повторил, что это — приоритет номер один. Думал, сейчас встряхнёмся и всё заработает.
Но нет. Вскоре на one-to-one ко мне стали приходить разработчики уже с конкретикой. «Костя, реквесты не смотрят», «Помоги, задача должна попасть в прод, а мы не успеваем из-за ревью». Я попросил скинуть примеры таких «зависших» реквестов. Открыл — и был в шоке. В одном — две тысячи изменённых строк. В другом — пять тысяч. Естественно, никто не хотел такое ревьюить.

И это были не какие-то единичные случаи. Я полез смотреть цифры, от которых мне стало ещё печальнее. В 90-м перцентиле время до закрытия пулл-реквеста — 42 дня. Представьте: больше месяца! До первого апрува — 11 дней. То есть почти две недели реквест просто лежит и ждёт, пока его хоть кто-то посмотрит и скажет «ок».
Стало понятно, что дело не в банальном разгильдяйстве и надо копать глубже — проверить сами процессы. Тогда мы работали по классической схеме Git Flow: под каждую задачу — отдельная ветка, в неё копится код: фиксы, фичи, потом всё это тестируется и только затем уже вливается в develop. На бумаге — вроде логично. Но на практике, особенно при растущем количестве команд и сложных фичах, такой подход начал всё сильнее тормозить.
А тут ещё и бизнес подключился. Пришли ребята и говорят: «Слушай, Костя, что-то вы редко релизитесь. Две недели ждать фичу — уже неприемлемо. Давайте как веб. Хотя бы раз в неделю, а лучше — каждый день». И вот тогда стало окончательно ясно: мы зашли в тупик. С одной стороны — огромные пулл-реквесты, которые тяжело ревьюить. С другой — запрос на регулярные и быстрые релизы. Так дальше не поедем, надо что-то менять.

Ищем решения
Сначала я сел и просто разобрался — что у нас вообще происходит и почему. Git Flow, по которому мы работали, тоже ведь не из воздуха появился. На бумаге всё было знакомо и вроде бы логично: две основные ветки — develop для разработки и master для стабильных релизов. Каждая задача делалась в своей feature-ветке, потом вливалась в develop. Когда нужно было релизиться — от develop отводилась отдельная релизная ветка, её тестировали, фиксили баги на месте, и только потом она уходила в master. А дальше — самое неприятное: все изменения из релизной ветки нужно было смёржить обратно в develop. За время тестирования другие команды уже заливали туда свежий код — и мы ловили регулярные конфликты.
Хотя схема была громоздкой, все к ней привыкли. С ней хотя бы было некое чувство контроля, что ничего не сломаем. Лить всё напрямую в master никто, конечно же, не решился бы. Но по мере роста фичей, команд и нагрузки система начала сбоить.
Я начал искать альтернативу и довольно быстро наткнулся на Trunk Based Development — практику, которая уже использовалась внутри Яндекса, особенно в бэкенде. А мы, мобильщики, о ней знали мало. И очень зря.
Суть TBD простая. Одна главная ветка — trunk. В неё вливаются все изменения, без промежуточных develop и master. Релизные ветки создаются от trunk, но обратно уже не мёржатся — просто живут параллельно до релиза. И получается, что конфликты исчезают почти полностью.

Получается, что TBD сам по себе подразумевает маленькие, частые коммиты. Ты не можешь залить в trunk огромную задачу целиком — это слишком рискованно. Поэтому приходится сразу дробить фичу на маленькие логически завершённые части. А маленький реквест значит — быстрое ревью. Проблема, с которой мы так мучились, вдруг начала выглядеть решаемой.
Но следом — новая загвоздка. Если мы начнём чаще вливать код в trunk, как быть с тестированием? Ресурсы QA у нас не бесконечны. Каждый новый инкремент — это отдельная точка, которую теоретически нужно проверить. При таком потоке тест-кейсы, регрессы и ручная проверка — просто утонут.
Решение напрашивалось само собой: если хотим внедрить TBD, придётся признать, что проверять вручную каждую промежуточную задачу — невозможно. Придётся отказаться от тестирования значительной части внутреннего кода до прода. Но, как вы понимаете, нельзя просто так прийти к команде и сказать: «Ребята, с завтрашнего дня мы не тестируем половину кода и льём всё в единственную ветку, удачи!». Первым шагом нужно было договориться с QA и пересобрать весь подход заново.
На пути к продакшену без тестов
Просто выбрать методологию, как вы понимаете, мало, нужно было продумать, как её внедрить в наши суровые реалии, особенно с учётом главного камня преткновения — тестирования. Вот как мы шли к нашему «безтестовому» продакшену.
Шаг 1. Договариваемся с QA
Это был, пожалуй, самый ответственный и деликатный момент. Я понимал, что просто прийти к QA и сказать: «Привет, мы тут решили часть задач больше не тестировать, верьте нам на слово, что всё будет хорошо» — это путь в никуда. Хотя, признаюсь, соблазн был.

Я объяснил коллегам из QA всю концепцию TBD и как она поможет нам решить проблему с долгими ревью. И ключевым моментом в моих аргументах стало использование фича-флагов (Feature Toggles).
Вот суть нашей идеи:
- Да, мы заливаем код в trunk. Маленькими порциями и без тестов.
- Но при этом всё новое надёжно закрыто фича-флагами.
- Код попадает в сборку, но для пользователей он выключен. Они его не видят. Он не ломает прод.
- Когда вся фича готова — собираем всё, что было под тоглами, и тестируем финальный шаг: удаление тоглов и включение фичи.
В теории звучит просто. На практике QA, как обычно, стали задавать кучу вопросов и приводить примеры, где такой подход может не сработать. Хотя постепенно всё же стали склоняться к тому, что идея имеет право на жизнь и её стоит попробовать. Но выдвинули важное условие: нужен удобный инструмент для управления тоглами. Чтобы можно было включить нужную фичу в любой момент — в середине разработки или перед её финалом.
Я пообещал, что такой инструмент будет. И после этого они сказали: «Ладно, идея интересная. Давай попробуем». Это и была наша первая большая победа.
Шаг 2. Формализуем процесс
Когда с QA договорились, следующим шагом нужно было чётко зафиксировать регламент, как теперь работаем. Чтобы все — от разработчиков до менеджеров — понимали правила игры. Я сел и написал документацию. Не формальную «ради галочки», а по сути. Вот что туда вошло:
- Hard Toggle — это такой же фича-тогл, только с блокировкой на проде. Его вообще нельзя там включить. Никак. Это и был наш страховочный парашют — если код ещё сырой, он точно не попадёт к пользователям.
- Все задачи дробим, оборачиваем в тоглы и вливаем в trunk. Это базовый принцип TBD. Каждая подзадача большой фичи — под Hard Toggle.
- Ревью — максимум сутки. Маленькие задачи = много ПР’ов. Если ревью будет тормозить, весь процесс встанет. Поэтому ввели SLA: не тянем больше суток.
- QA подключаются на этапе удаления тогла. Когда вся фича готова — тестируем, удаляем тогл, включаем. Только тогда она становится доступна.
- Есть исключения. Например, обновление критической библиотеки. Или системные изменения, которые невозможно закрыть тоглом. В таких случаях работаем по старинке — с полноценным тестированием. Главное — все такие исключения чётко прописаны.
С этим документом я пошёл к лидам других команд. Как и ожидалось — началась классика: — А что если… — А вот такой кейс… — А у нас вот это…
Но в целом ничего критичного. Просто максимально расширил и уточнил доку — и всё встало на свои места. Лиды согласились: процесс адекватный, можно жить.
Шаг 3. Продаём идею разработчикам
Следующий шаг — донести всё это до команды. Собрал всех, рассказал про новый подход. И тут, естественно, снова начался шквал вопросов:
— Пулл-реквестов станет в два раза больше! Мы и так зашиваемся, а ты хочешь добавить работы? — Мы утонем в этих тоглах! Кто их потом разгребать будет? — Давайте вообще ничего не менять. Ну жили же как-то без этого всего раньше.

Скепсис — вполне нормальная реакция. Тем более мы уже не первый месяц обсуждали проблемы с процессами. Но я уже настроился и не хотел всё останавливать. Мои контраргументы были такими:
- Да, ПР’ов станет больше. Но они будут короткими. А короткий ПР — это быстрое ревью. Плюс мы же договорились: SLA на ревью — максимум сутки.
- Тоглов тоже будет немало. Но мы сделаем нормальные инструменты для управления ими — без боли.
- И ещё важное. Большие фичи теперь будем выносить в отдельные модули. Мы давно хотели двигаться к модуляризации, и это отличный повод наконец начать. Вместо огромного монолита — изолированные части. Чище, понятнее, безопаснее.
Поговорили. Все выдохнули. Посомневались ещё немного, но в итоге сказали: «Ладно, давай попробуем».
Как мы это сделали
Согласие всех заинтересованных сторон мы получили, считай полдела сделано. Оставалось самое интересное — начать уже наконец-то реализацию. И мы пошли шатать процессы.
1. Инфраструктура и инструменты
-
Сначала — чат. Да, нужно больше чатов богу чатов! А если без сарказма, то это, конечно, может показаться мелочью, но создание отдельного чата — действительно важный этап. На общих встречах не все успевают задать вопросы, кто-то стесняется, кто-то отвлёкся, а потом они обязательно появляются.
-
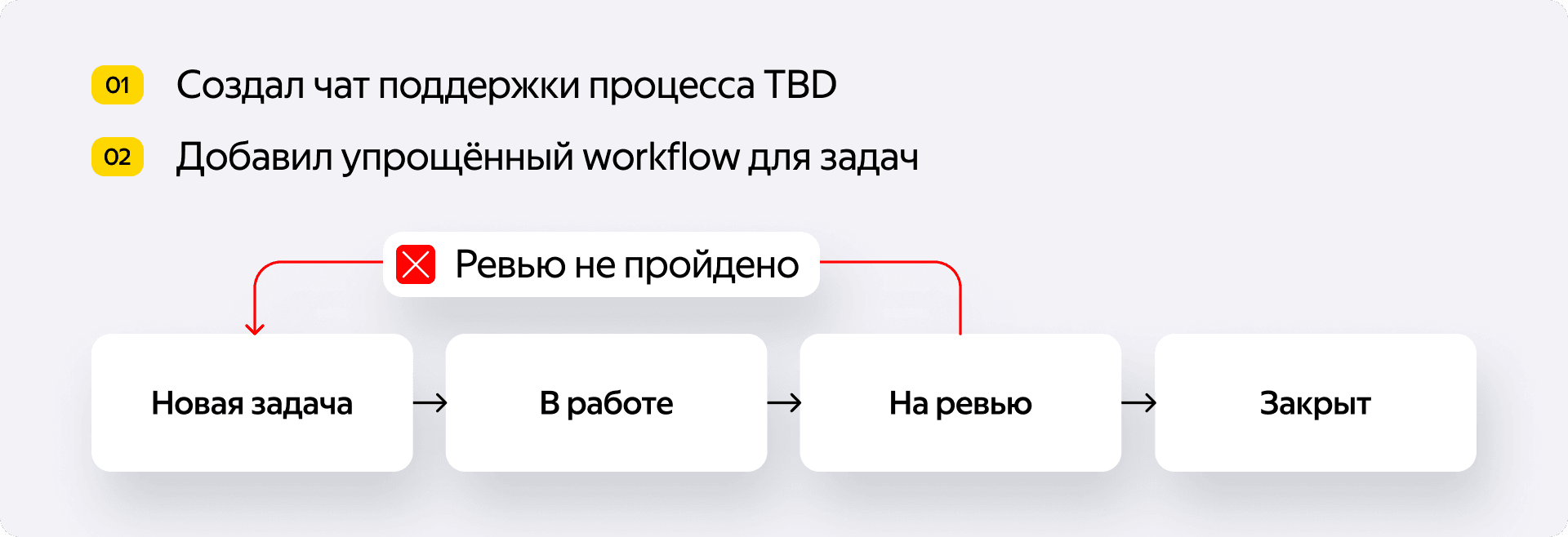
Отдельный workflow в трекере. Чтобы не путаться, мы завели для TBD-задач своё ответвление. Простое и без привычного этапа тестирования. Схема была такая:
- Новая задача → В работе → На ревью → Закрыта.
- Если ревью не пройдено — возвращается обратно.
- «Закрыта» — значит, код влили, но он всё ещё под тоглом. Пользователи его не видят. Он просто лежит в trunk и ждёт включения.
-
Hard Toggles. Тут нам повезло — у нас уже была система для раскатки фич на процент пользователей. Мы просто взяли её за основу. Добавили логику, которая гарантированно возвращала
falseв продакшене. Код под таким тоглом никак не мог активироваться случайно. А разработчики могли включать такие фичи локально — для этого мы доработали внутреннюю debug-панель. -
Ревью. Мы усилили статические анализаторы — они ловили мелочи типа форматирования ещё до ревью. Это сэкономило кучу времени и сил. Плюс мы сломали автоназначение ревьюеров — осознанно. Если большая фича дробилась на цепочку ПР’ов, их по возможности ревьюил один и тот же человек или как минимум узкий круг людей, которые уже в контексте нужных задач. Это сильно ускорило процесс.
-
Контроль тоглов. Чем их больше — тем легче забыть, что под ними вообще спрятано. Мы начали с простого: выводили список активных тоглов в консоль. Потом добавили визуализацию — график с динамикой. С разбивкой по командам. Синим цветом подсвечивались старые или неразмеченные тоглы — их надо было выпиливать. И знаете что? Такая визуализация отлично сработала: зависших тоглов стало заметно меньше.
2. Доверяй, но проверяй
А теперь — о штуке, которая помогла нам не развалиться в первые недели после запуска нового процесса. Немного читерская, но рабочая. Мы назвали это DevTest.
Что это вообще такое? Это когда разработчик не просто пишет код и отправляет на ревью, а сам его проверяет. По сценарию, с формой, с отчётом. Да, прямо сам берёт и тестирует свою задачу.
На практике это выглядит так:
В трекере появляется отдельная форма — чек-лист для DevTest. Там были простые, конкретные пункты:
- Что проверял?
- Какие шаги сделал?
- Что получилось?
- Какие граничные случаи учёл?
Разработчик заполняет этот чек-лист.
QA потом читает отчёт. Если всё выглядит хорошо — задачу можно условно считать протестированной. QA понимает, что разработчик не просто глянул одним глазом, а реально продумал, как и что проверить. Этого было достаточно, особенно для маленьких изменений под тоглом.
Что нам это дало
- Ответственность. Разработчик теперь не просто пишет код — он сразу думает, как его будут использовать. Это сильно влияет на качество.
- Экономию. QA не приходится гонять десятки мелких фич вручную. Они могут доверять DevTest и сосредоточиться на важных штуках.
- Контроль без контроля. Мы вроде как не тестируем — но на самом деле тестируем. Просто немного по-другому.
Плюс автоматические тесты — юнит, UI, интеграционные — никуда не делись. Они продолжают работать, покрывать регресс и страховать нас от крупных фейлов. DevTest в этом сценарии — некий компромисс. Не панацея, конечно. Но когда фича закрыта тоглом и идёт маленькими шагами — этого вполне достаточно.
Какой итог
Ну что, проделали кучу работы — пора бы уже понять, к чему это нас привело. А лучше всего об этом говорят цифры. Помните те жуткие 42 дня на закрытие пулл-реквеста в 90-м перцентиле? И 11 дней до первого ревью? А вот как стало сейчас:
- Время до закрытия ПР (90-й перцентиль) — 7 дней 13 часов
- Среднее время до закрытия PR — 3 дня 16 часов (а было 12)
- Время на шип ПР (90-й перцентиль) — 3 дня 5 часов
- Среднее время на шип ПР — 1 день 6 часов (раньше было почти 6)

Согласитесь, разница весьма внушительная! Сейчас наша цель — сделать так, чтобы максимальное время до первого апрува не превышало 23 часов. Ещё немного — и добьёмся.
В целом можно сказать, что процесс прижился. За последние 30 дней по новому TBD-флоу мы создали 32 задачи на Android и 18 на iOS. И это даже не полный охват — простые штуки вроде смены цвета кнопки по-прежнему делаем по-старому. Но для всего, что посложнее, TBD уже стандарт.
Но помимо цифр, есть и другие, не менее важные качественные улучшения, которые сложно выразить в числовом эквиваленте, но они тоже не менее важны в работе:
-
Меньше багов и конфликтов. Раньше фича вливала в develop огромную ветку, всё ломалось, и мы неделями разгребали последствия. Теперь код заходит в trunk маленькими кусочками под тоглами. Все видят, что происходит. Если кто-то собирается работать в том же месте, он видит, что там уже есть какой-то тогл, какие-то новые наработки. И все потенциальные конфликты и недопонимания решаются не в конце, когда уже всё сломалось, а прямо в моменте.
-
Еженедельные релизы. Раньше мы себе этого позволить не могли как раз из-за нестабильности develop и времени, которое уходило на фикс багов после мержа. Теперь, снизив количество этих внезапных багов и оптимизировав процесс тестирования, мы спокойно катим релизы каждую неделю. И это никак не ухудшило наши показатели регресса, количество багов не выросло, QA не напрягается больше обычного. Продакты, конечно, были очень довольны!
-
Модуляризация проекта. Мы требуем, чтобы новые фичи делались в отдельных модулях — и это отлично ускорило модуляризацию. Кодовая база стала чище, разбираться в ней легче.
-
Пропала релизная гонка. Раньше перед отведением релизной ветки все кидались вливать свои фичи: «Срочно надо, мы не успеем, нельзя ждать ещё неделю». Сейчас этого нет. Выпил тогла — это часто просто удалить пару строчек. Всё катится плавно. Мы даже график мёржей смотрели — раньше перед днём Х была гора пулл-реквестов, теперь всё равномерно распределено по неделе.
На этом месте вы можете задать мне вполне резонный вопрос: «Костя, ну а раньше-то как вы вообще жили? Эти проблемы ведь не с неба свалились. Еда с 2018 года существует. Почему всё начало ломаться только в 2023?»
А ответ тут очень простой: да, до определённого момента проблем действительно не было. Просто потому, что команда была небольшой, сам проект был значительно меньше и проще, да и задачи разработчиков редко пересекались. Мы могли совершенно спокойно делать свои наработки параллельно друг другу, а потом без особых проблем вливать их.
В таких условиях классический Git Flow работал вполне себе неплохо. Но Еда росла, команда разработки увеличивалась, проект становился всё сложнее и комплекснее. И в какой-то момент старые подходы просто перестали справляться с возросшей нагрузкой и сложностью. Тогда-то и посыпались те самые проблемы, о которых я говорил в самом начале: долгие ревью, огромные пулл-реквесты, общая нестабильность процессов. По сути, мы просто переросли наши старые процессы.
Так что переход на TBD был осознанной необходимостью, продиктованной изменившимися реалиями. Это была своего рода эволюция, которая нам позволила и накопившиеся проблемы решить, и заложить хороший фундамент для дальнейшего роста и развития.
Что в итоге
В конце этой длинной истории хочется ответить на вопрос, который, возможно, возник у некоторых читателей: «А нужно ли мне или моей команде пробовать Trunk Based Development?».
Однозначного ответа «да» или «нет» здесь, конечно, быть не может. Всё очень сильно зависит от вашего контекста, размера команды, сложности проекта и тех проблем, с которыми вы сталкиваетесь. Но, основываясь на нашем опыте, я могу дать несколько рекомендаций.
Кому, скорее всего, НЕ НАДО сломя голову бежать внедрять TBD:
Если у вас маленькая команда и небольшой проект, если у вас и так всё хорошо, задачи не пересекаются, а ревью проходят быстро — возможно, овчинка не стоит выделки. Как я уже рассказывал, мы сами долгое время прекрасно жили без TBD. Внедрение такого подхода — это довольно много телодвижений: нужно перестроить процессы, доработать инструменты, написать документацию, а главное — продать идею команде, которая, скорее всего, будет спорить и сомневаться.
Кому СТОИТ как минимум присмотреться к TBD:
Если у вас большая команда, вы работаете в условном «бигтехе» или над крупным продуктом, если вам до боли знакомы долгие ревью, огромные пулл-реквесты, нестабильность основной ветки разработки и неявные баги после мержа, вот тут TBD может стать настоящим спасением.
Надеюсь, наш опыт и те грабли, по которым мы прошлись, окажутся для кого-то полезными.



