
«Построить график заказов за месяц» — звучит как обычная задача, которую любой джун закрывает за пятничный вечер, не особенно при этом напрягаясь. Казалось бы, сделай SELECT count(*) … GROUP BY date и отдай JSON на фронтенд. Так-то оно так. Но всё меняется, когда в уравнении появляются масштабы и распределённая архитектура.
Представьте, что ваши данные — это не одна уютная база, а тысячи микросервисов, разбросанных по разным командам. Каждые сутки в системе проходит более 10 миллионов заказов и десятки миллионов финансовых транзакций. Активных исполнителей — миллион, плюс накоплен колоссальный объём исторических данных. При этом данные не просто лежат мёртвым грузом: они постоянно меняются. Статусы меняются, деньги пересчитываются, а транзакции могут внезапно прилетать задним числом.
Я — Вадим Зотеев, руковожу службой разработки в Яндекс Go. Мы делаем «Диспетчерскую» — веб-приложение для таксопарков и логистических компаний. Им важно видеть аналитику бизнеса в реальном времени: от общей статистики парка до детальных срезов по каждому водителю. И они не готовы ждать загрузки отчёта по 10 секунд — стандарт индустрии требует отклика быстрее 300 мс.
В этой статье я расскажу, как мы прошли путь от первых решений с полным пересчётом данных, который занимал 8 часов, до платформы реалтайм-аналитики с секундной задержкой. Мы разберём, почему стандартный OLAP не всегда спасает, как бороться с гонками при обновлении данных из прошлого и зачем нам пришлось писать свой low-code внутри компании.
Выбор стратегии поставки данных
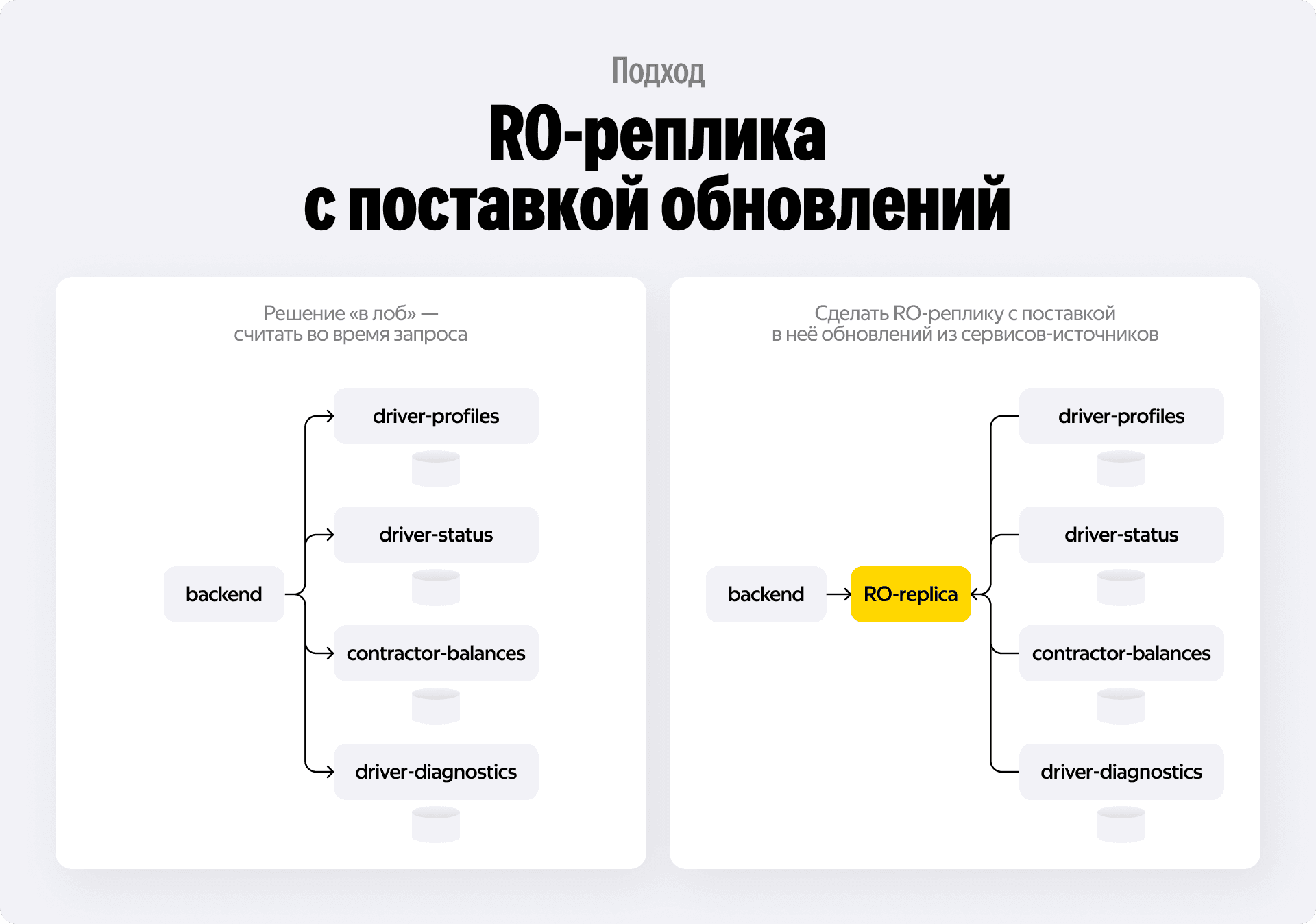
Первая мысль при решении такой задачи — пойти «в лоб». Почему бы не написать бэкенд, который в момент запроса пользователя сходит по HTTP или gRPC во все необходимые микросервисы — профили водителей, биллинг, статусы, соберёт данные, посчитает агрегат и отдаст ответ?
Ну, очевидно, потому что это не работает на масштабе. Когда источников данных десятки, а записей — миллионы, такой запрос будет выполняться вечность. Мы быстро упрёмся в лимиты сети и CPU, а масштабировать это будет крайне сложно.
Поэтому мы сразу переходим к концепции сервиса-реплики. Идея проста: мы создаём отдельное хранилище, куда собираем все необходимые данные из смежных систем, и строим отчёты уже на его базе. Главный вопрос здесь — как именно доставлять эти данные. Мы прошли через три стадии эволюции, и у каждой были свои причины и последствия.
1. Полный пересчёт
Это самый простой способ, с которого часто начинают MVP. Раз в сутки мы запускаем тяжёлую джобу, которая вычитывает всё из источников и полностью перезаписывает данные в реплике.
- Плюсы: это очень легко реализовать. У нас есть гарантия eventual consistency — если что-то пошло не так сегодня, завтрашний пересчёт всё исправит.
- Минусы: они фатальны для реалтайма. В нашем случае, когда бизнес ещё был молодым, мы жили с задержкой данных в 8 часов. Чтобы перелопатить такой объём, мы сжигали на MapReduce-кластере с YTsaurus около 2000 ядер CPU в течение этих 8 часов.
Подробнее о работе с этим хранилищем читайте в статье «Опыт создания коннектора к YTsaurus для Apache Flink под высокие нагрузки Яндекс Go»
2. Батчевая поставка
Попытка оптимизировать предыдущий пункт. Мы начали собирать изменения пачками, например, раз в час.
Результат: задержка снизилась до 1 часа, а потребление ресурсов упало на порядок — до ~100 CPU. Это уже приемлемо для внутренней аналитики, но всё ещё бесконечно долго для операционного директора таксопарка, которому нужно видеть ситуацию здесь и сейчас.
3. Стриминг обновлений
Это то, к чему мы пришли в итоге. Каждое изменение в сервисе-источнике: создание заказа, транзакция, смена статуса — тут же летит к нам через очередь сообщений.
Результат: задержка обновления данных — около 1 секунды. Потребление ресурсов на обработку потока — всего ~10 CPU.
Кажется, что выбор очевиден, не так ли? Стриминг выигрывает по всем фронтам: и по скорости, и по ресурсам. Но есть нюанс. Это самое сложное в реализации решение. Вам нужно организовать надёжный транспорт (CDC, Transactional Outbox), разбираться с дедупликацией и порядком сообщений.
Но самое страшное начинается не в транспорте, а в логике. Как только вы включаете стриминг, вы сталкиваетесь с гонками обновления данных. Данные в реплике всегда чуть-чуть отстают от источника. А ещё есть проблема холодного старта: вы запустили стриминг сегодня, но вам нужно как-то залить исторические данные за прошлый год. И пока льётся история, продолжают лететь реалтайм-обновления. Они начинают конфликтовать, и просто так мержить их нельзя.
Кроме того, встаёт вопрос хранилища. Что выбрать для реплики? In-memory, классическую SQL-базу или модный OLAP? Универсального ответа нет. Всё зависит от природы данных. Далее я разберу четыре конкретных кейса из нашей практики, где для каждой задачи пришлось подбирать свою архитектуру.
Кейс № 1: график заказов
Проще всего начать с классической задачи: построить график заказов за произвольный период с разбивкой по дням и тарифам. Главная особенность этих данных — их иммутабельность. Заказ, перешедший в финальный статус типа «выполнен» или «отменён», больше не меняется. Это сильно упрощает жизнь: нам не нужно думать про сложные обновления или конфликты версий. Нам просто нужно быстро агрегировать огромный массив строк.
Стандартное решение: OLAP и ClickHouse
Здесь напрашивается колоночная СУБД. В Яндексе мы активно используем ClickHouse в самых разных сценариях: от materialized views до кэширования тяжёлых отчётов.
Схема выглядит так: микросервис заказов пишет данные в шардированный PostgreSQL. Мы настраиваем CDC или другой механизм репликации, который переливает эти данные в аналитическую OLAP-базу. Когда пользователь запрашивает отчёт, наш Reader-бэкенд идёт в OLAP, выполняет агрегацию на лету и отдаёт результат. Просто, эффективно, масштабируемо.
Проблема роста и решение через предагрегаты
Но есть нюанс. Даже ClickHouse, знаменитый своей скоростью на больших объёмах, начинает потреблять ощутимые ресурсы CPU и диска, когда счёт идёт на миллиарды строк. Хранить каждый сырой ивент вечно — дорого и не всегда нужно. Пользователю редко интересны детали конкретного заказа трёхмесячной давности, ему важна общая динамика.
Мы оптимизировали это через предагрегаты.
Идея в том, чтобы заранее посчитать промежуточные итоги — например, количество заказов за каждый час или день.
- Фоновый процесс регулярно с некоторым интервалом вычитывает сырые данные за прошлый период.
- Он группирует их по нужным разрезам и складывает результат в отдельную таблицу
aggregated_orders. - Сырые данные за этот период можно удалить или перенести в холодное хранилище S3, освободив место на быстрых дисках OLAP-кластера.
Теперь при запросе отчёта Reader-бэкенд делает умный запрос: он берёт готовые исторические предагрегаты из aggregated_orders и домешивает к ним свежие сырые данные за текущий неполный период из основной таблицы.
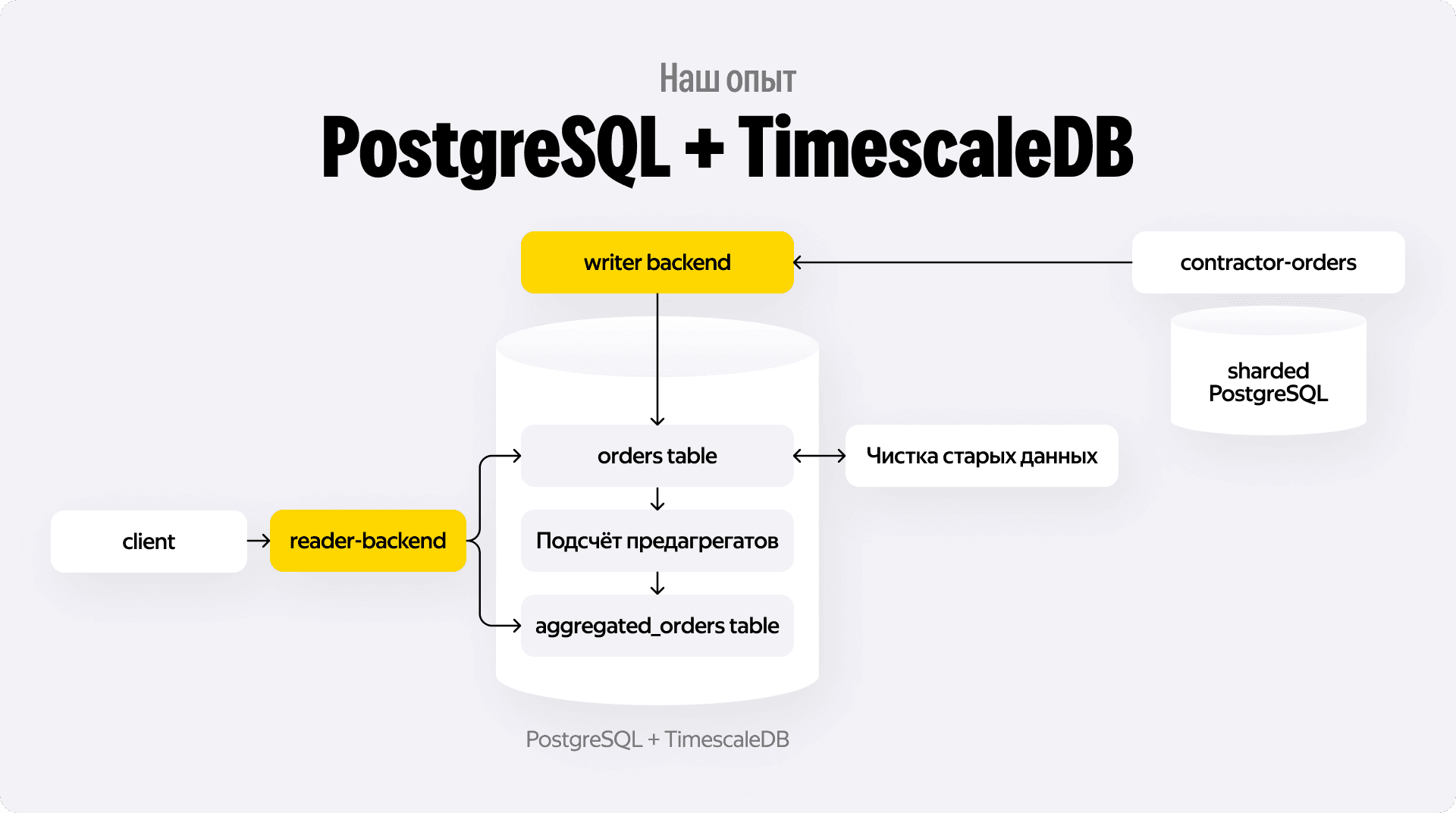
В нашем случае объём данных позволял не разворачивать отдельный кластер ClickHouse, а обойтись одним мощным сервером с PostgreSQL + расширением TimescaleDB. Это расширение превращает обычный Postgres в неплохую time-series базу, умеющую работать со сжатыми чанками данных. В итоге мы получили преимущества OLAP — быстрые агрегации, сжатие, оставаясь при этом в привычной экосистеме PostgreSQL и не усложняя инфраструктуру. Храним данные за полгода, и всё отлично помещается на один хост.
Кейс № 2: активные водители
Казалось бы, решение с предагрегатами универсально. Но что, если метрика хитрее, чем просто сумма? Представьте себе такую задачу: партнёр хочет видеть график уникальных активных водителей за произвольный период.
Допустим, в понедельник на линию вышло 1000 водителей. Во вторник — тоже 1000. Сколько уникальных водителей работало за эти два дня? И тут мы не можем просто сложить 1000 + 1000, потому что это будет в корне неверно. Скорее всего, значительная часть водителей работала в оба дня, и реальная цифра уникальных будет около 1100–1200.
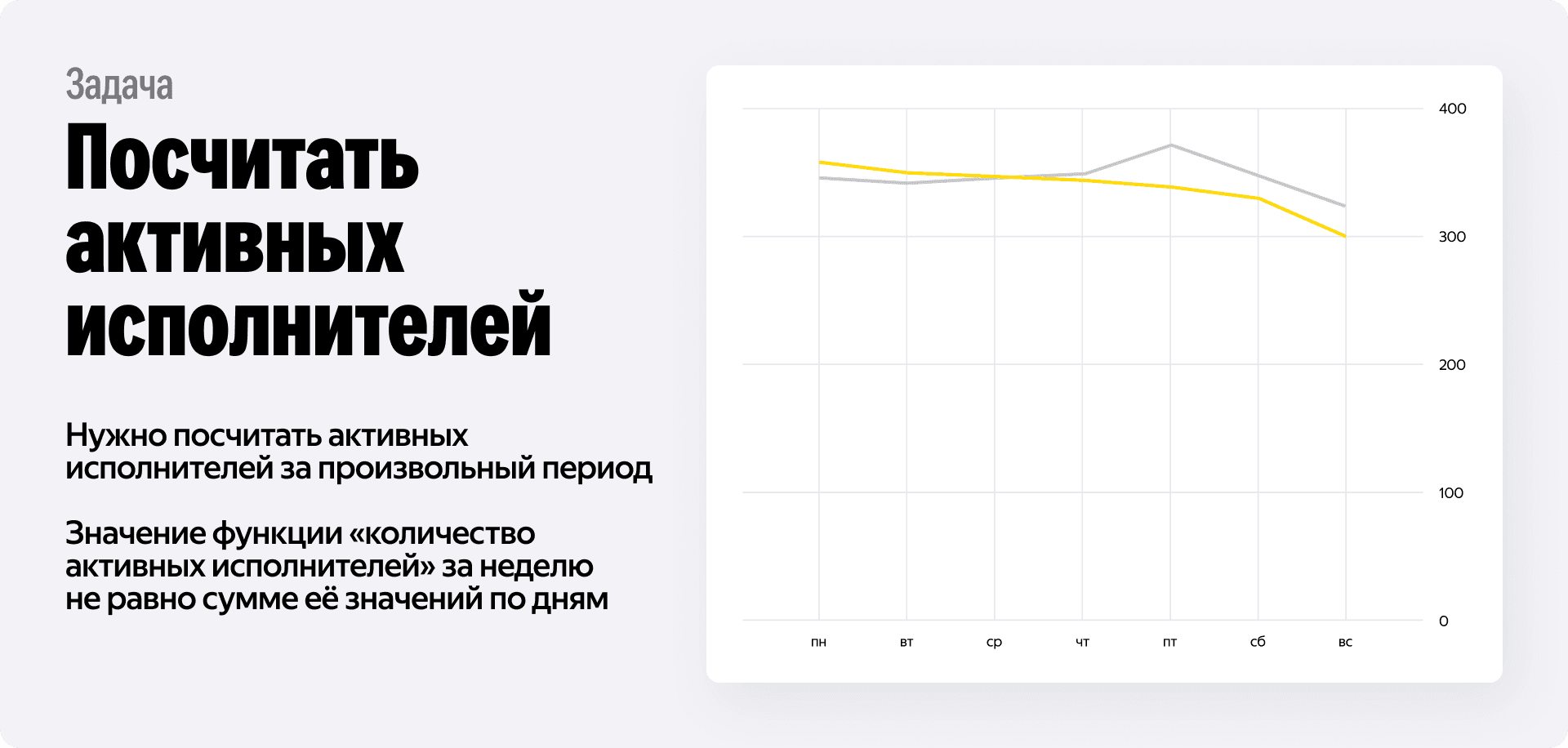
Это классический пример неаддитивной метрики. Сюда же относятся медианы, перцентили и любые COUNT(DISTINCT). Для таких функций нельзя просто так взять и просуммировать часовые или дневные предагрегаты. Результат будет бессмысленным.
Как мы это решаем?
Здесь приходится выбирать из двух зол:
- Честный полный пересчёт. Мы храним все сырые события выхода водителей на линию и в момент запроса делаем COUNT(DISTINCT user_id) по всему диапазону. Это даёт точный результат за любой произвольный период, но стоит дорого по CPU и IO.
- Фиксация интервалов. Мы заранее считаем уникальных пользователей за фиксированные окна: день, неделя, месяц. Пользователь не сможет выбрать произвольный период, например «с обеда вторника по утро четверга», а только предустановленный. Зато ответ будет мгновенным.
В нашем текущем масштабе мы пока справляемся полным пересчётом сырых данных. Мы оптимизируем хранение, используя эффективные типы данных и сжатие, но суть остаётся та же: для неаддитивных метрик ультимативного решения типа простых предагрегатов не существует. Если данных станет ещё на порядок больше — придётся переходить к вероятностным структурам данных или жертвовать произвольными интервалами.
Кейс № 3: доход и финансы
Если до сих пор все решения казались вам логичными, приготовьтесь — сейчас будет по-настоящему сложно.
Задача: отобразить финансовые показатели парка и каждого водителя в реальном времени. Какой был доход за сегодня? А за прошлую неделю? А сколько удержано комиссии? И тут опять основная часть сложности заключается в объёмах: десятки миллионов транзакций в сутки, миллиарды в месяц.
Но главная проблема даже не в количестве нулей, а в природе самих данных. Потому что финансовые события могут происходить «задним числом».
Представьте гипотетический сценарий:
- Водитель отлично выполнил заказ в понедельник.
- Ему начислили стоимость поездки — 500 рублей.
- Во вторник клиент снова открывает приложение и решает оставить чаевые за вчерашний комфортный сервис.
- В системе создаётся новая финансовая транзакция на +100 рублей.
Внимание, вопрос: к какой дате относится эта новая транзакция? С точки зрения технической даты (когда запись появилась в базе) — это вторник. С точки зрения бизнес-даты (когда была оказана услуга) — это понедельник.
Если мы строим отчёт по заработку за понедельник, эта сумма должна измениться. То есть данные за прошлый период обновились задним числом.
Почему OLAP здесь не спасает?
В аналитических СУБД типа ClickHouse и Vertica обновление данных — это дорогая и тяжёлая операция. Они заточены на APPEND ONLY. Когда у вас поток изменений задним числом достигает тысяч RPS, стандартный OLAP-подход с предагрегатами начинает захлёбываться. Вы не можете просто дописать новые чаевые в готовый агрегат, если хотите сохранить консистентность и возможность пересчёта.
Узнать больше о быстрой обработке данных можно в материале «Найти баг за 60 секунд: Real-Time мониторинг Яндекс Маркета»
Нам нужна транзакционность. Нам нужна OLTP-база. Но учитывая миллиарды записей, один сервер PostgreSQL здесь уже не справится. Нам нужно шардирование из коробки и строгая консистентность. Поэтому мы выбрали YDB — распределённую SQL-базу данных.
Гонка данных
При переходе на стриминг в OLTP мы столкнулись с интересным состоянием гонки. Представьте, что мы запускаем новую реплику. Нам нужно:
- Начать принимать реалтайм-поток изменений.
- Залить исторические данные за прошлый год.
Если в этот момент прилетит та самая компенсирующая транзакция за прошлый месяц, а мы как раз заливаем этот месяц из архива, может произойти коллизия. Кто победит: старая запись из архива или новая отмена из стрима?
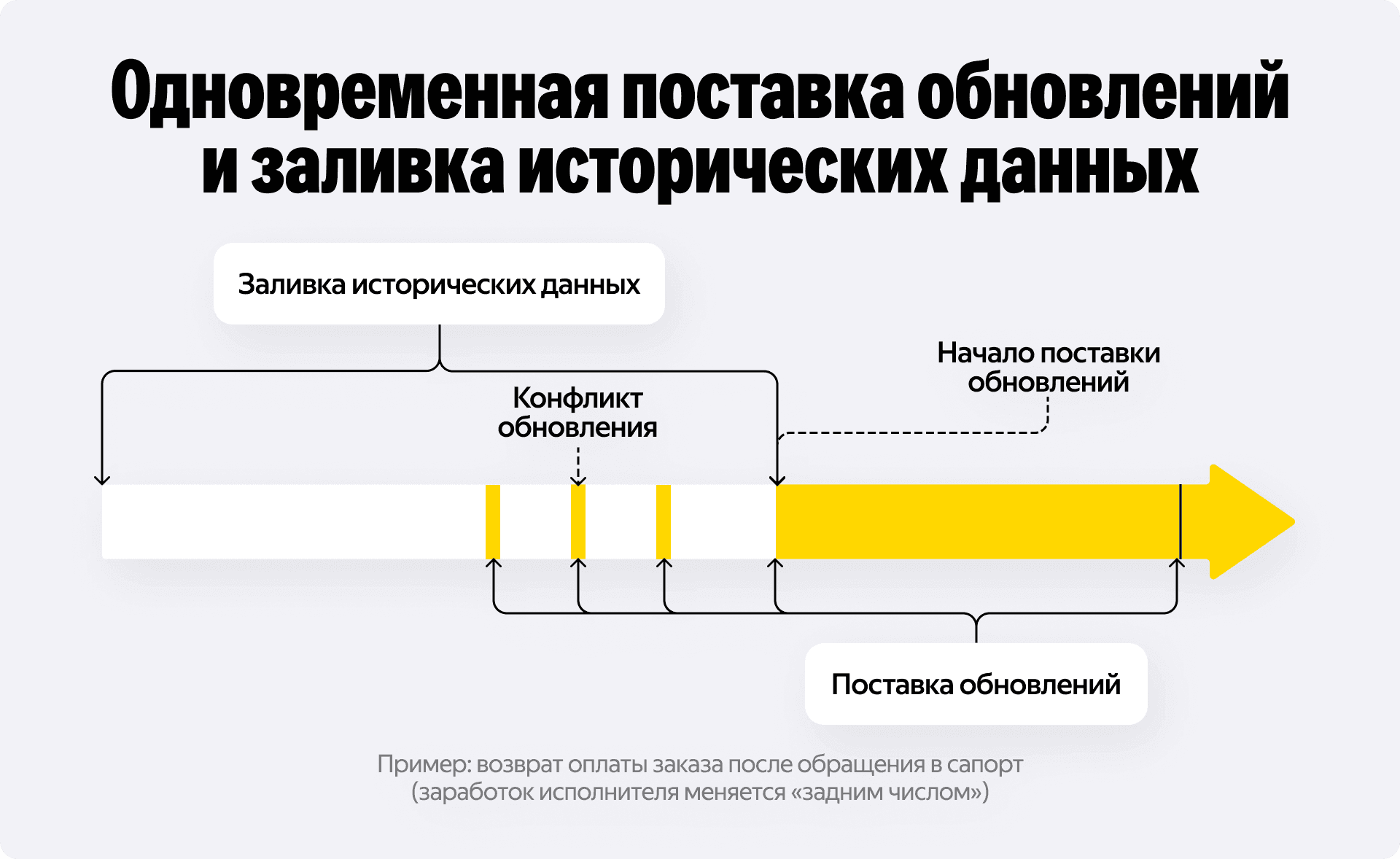
Мы решаем это двумя путями, через:
- Версионирование объектов. Каждое изменение имеет монотонно возрастающий
revision_idилиupdate_ts. При конфликте побеждает версия с большим ID. - Разделение дат. Мы жёстко разделяем
event_time(бизнес-дата) иprocessing_time(техническая дата). Все идемпотентные проверки опираются наprocessing_time.
Асинхронный пересчёт
Самое сложное — поддерживать актуальность предагрегатов (сумм заработка по часам/дням) в условиях мутабельности.
Казалось бы, решение очевидно: почему бы не использовать ACID-транзакции YDB? Пришло событие — в рамках одной транзакции записали его в таблицу сырых данных и тут же обновили счётчик в таблице агрегатов: UPDATE daily_stats SET amount = amount + Х.
Технически это возможно, но на наших объёмах (тысячи RPS на запись) мы не рискнули использовать кросс-табличные транзакции. В распределённой базе данных транзакция, затрагивающая несколько таблиц (и потенциально — несколько шардов), стоит дорого и может стать узким местом по производительности.
Вместо этого мы выбрали легковесные транзакции, которые всегда работают только с одной таблицей. А связность данных обеспечиваем через асинхронные очереди:
- Все входящие сырые события (транзакции) сначала сохраняются в таблицу raw_transactions. Это быстрая однотабличная вставка.
- Сразу после записи (или в той же транзакции очереди сообщений) мы ставим задачу воркеру: «Пересчитать агрегат водителя X за вторник».
- Воркер асинхронно вычитывает ВСЕ сырые транзакции за нужный интервал и одной атомарной операцией обновляет таблицу daily_aggregates.
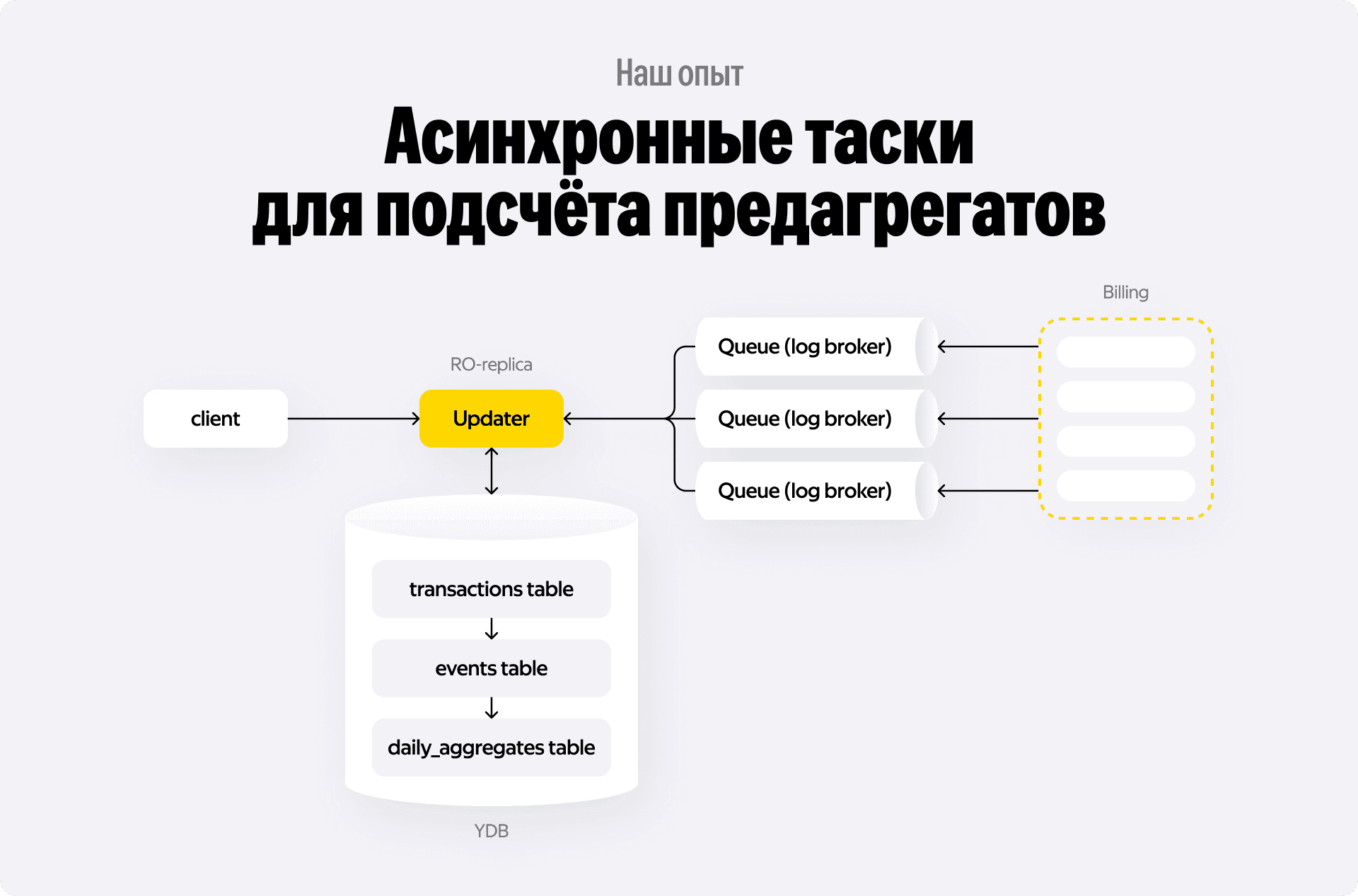
В результате получаем отличные преимущества:
- Скорость: мы не блокируем запись сырых данных ожиданием обновления агрегатов.
- Идемпотентность: сколько бы раз мы ни перезапустили пересчёт, результат будет одним и тем же — правильная сумма всех транзакций.
- Масштабируемость: мы линейно масштабируем систему, просто добавляя узлы, так как данные шардируются по паркам.
Да, такое решение сложнее в реализации, потому что нужны очереди, воркеры и мониторинг лага. Но оно единственное даёт 100% финансовую точность при минимальной задержке отображения. Задержка обновления данных у нас всего ~1 секунда, а потребление ресурсов — около 10 CPU на поток, в отличие от полного пересчёта, который съедал целый кластер.
Кейс № 4: фильтрация и сортировка
Перейдём к самой мультизадачной проблеме. В Диспетчерской таксопарка постоянно нужно фильтровать и сортировать списки объектов:
- «Покажи всех водителей со статусом „офлайн“, у которых есть детское кресло в машине, и отсортируй их по балансу».
- «Найди все жёлтые автомобили класса «Комфорт+" и отсортируй их по году выпуска».
Здесь у нас десятки миллионов обновляемых сущностей и снова та же самая боль: данные размазаны по разным микросервисам. Статус — в сервисе статусов, баланс — в биллинге, профиль — в сервисе профилей. Собрать всё это в одном SQL-запросе невозможно, потому что базы разные.
Ad-hoc решения
В 2020 году мы решали эту задачу «в лоб». Подняли отдельный сервис, который держал все нужные данные в памяти. Updater слушал шину данных, обновлял структуры в RAM, а API отвечало на запросы.
Быстро, дёшево, сердито. Но масштабируемость нулевая.
- Память. Мы быстро упёрлись в лимит по RAM, использовав 240 Гб. Данные постоянно росли, а железо всё-таки не резиновое.
- Холодный старт. При рестарте пода нужно было вычитать все данные из снапшота. Это занимало десятки минут, в течение которых сервис не отвечал.
- Сложность поддержки. Просто добавить новое поле для фильтрации означало переписать код апдейтера, пересобрать структуру в памяти и перезапустить сервис.
Переход к системному подходу
Поняв, что ad-hoc решения нас тормозят, мы решили построить универсальную платформу. Идея простая: если задача фильтрации и сортировки возникает постоянно для разных сущностей — водители, курьеры, автомобили, зачем каждый раз писать новый микросервис?
Мы создали единый сервис-конструктор, работающий по конфигу.
- Конфигурация. Разработчик описывает в YAML-файле структуру объекта: какие поля нужны, из каких топиков YDB topics их брать, какие типы данных использовать.
- Генерация схемы БД. На основе конфига платформа сама генерирует миграции для PostgreSQL. Создаются денормализованные таблицы с нужными индексами. Обычно B-tree или GIN для сложных фильтров.
- ETL на лету. Платформа поднимает консьюмеры для указанных топиков. Мы написали универсальный Updater, который умеет разбирать JSON-сообщения из разных источников и раскладывать их по колонкам в БД.
- Generic API. У нас есть одна универсальная gRPC/HTTP ручка, которая умеет работать с любыми объектами. Она принимает на вход имя сущности (например, driver) и набор фильтров (
WHERE status = 'offline' AND balance > 100), а на выходе генерирует оптимизированный SQL-запрос к нужной таблице.
Результат: минимальный Time-to-Market.
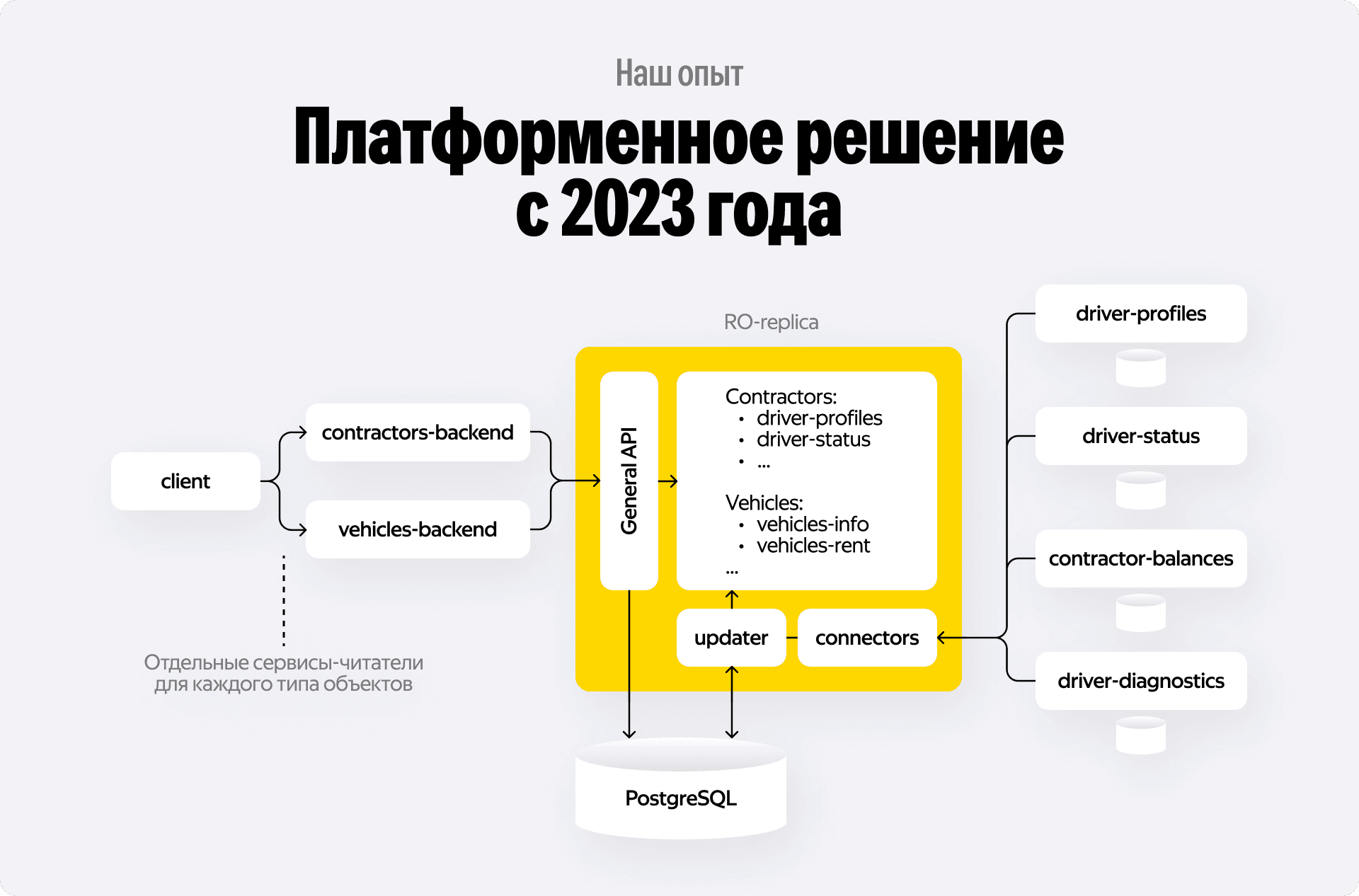
Раньше добавление нового фильтра занимало недели: разработка, тесты, деплой, прогрев кэша. Сейчас это занимает несколько дней. Продукт-менеджер может прийти с запросом, мы правим конфиг, накатываем миграцию — и данные уже льются в базу, а API готово к использованию.
Конечно, можно сказать, что мы получили мини-монолит: сложный сервис, который стал единой точкой отказа. Мы сознательно шли на этот риск. Потому что в результате нам удалось сэкономить сотни часов разработки, перестав писать однотипные перекладыватели JSON-ов. Считаем, что оно того стоило.
Шардирование
Давайте объединим то, о чём говорили в предыдущих разделах. Мы уже разобрали, как считаем финансовые агрегаты в условиях мутабельности данных (Кейс №3), и как строим универсальную платформу для фильтрации и сортировки (Кейс №4).
Но что делать, когда эти две задачи пересекаются? Представьте: нам нужно не просто посчитать общую сумму заработка парка, но и дать возможность фильтровать и сортировать сами исходные финансовые события (конкретные заказы, выплаты бонусов, удержания) в реальном времени. И всё это — на огромных объёмах транзакций.
В какой-то момент один экземпляр PostgreSQL, даже очень мощный, перестаёт справляться с таким потоком записи и одновременно тяжёлыми аналитическими запросами на чтение. Индексы пухнут, репликация отстаёт. В таком случае нужно масштабироваться горизонтально.
Ad-hoc вместо платформы
Здесь мы сознательно не стали использовать нашу универсальную Low-code платформу для фильтрации. Почему? Потому что она заточена под один инстанс БД. Шардировать универсальный конструктор — задача на порядок сложнее, чем шардировать конкретное прикладное решение.
Поэтому для финансовых событий мы вернулись к кастомной разработке, объединив её с тем самым решением на базе YDB, о котором я рассказывал ранее. Мы используем те же паттерны: стриминг, асинхронный пересчёт, идемпотентность.
Стратегия шардирования
Ключевой вопрос: как разбить данные? В нашем случае все финансовые события привязаны к конкретному партнёру — таксопарку. У нас их более 10 000. Шардирование по park_id идеально ложится на продуктовую логику:
- Запросы в Диспетчерской всегда идут в контексте одного парка.
- Парки изолированы друг от друга, нам почти никогда не нужны кросс-шардовые транзакции или джойны между разными парками.
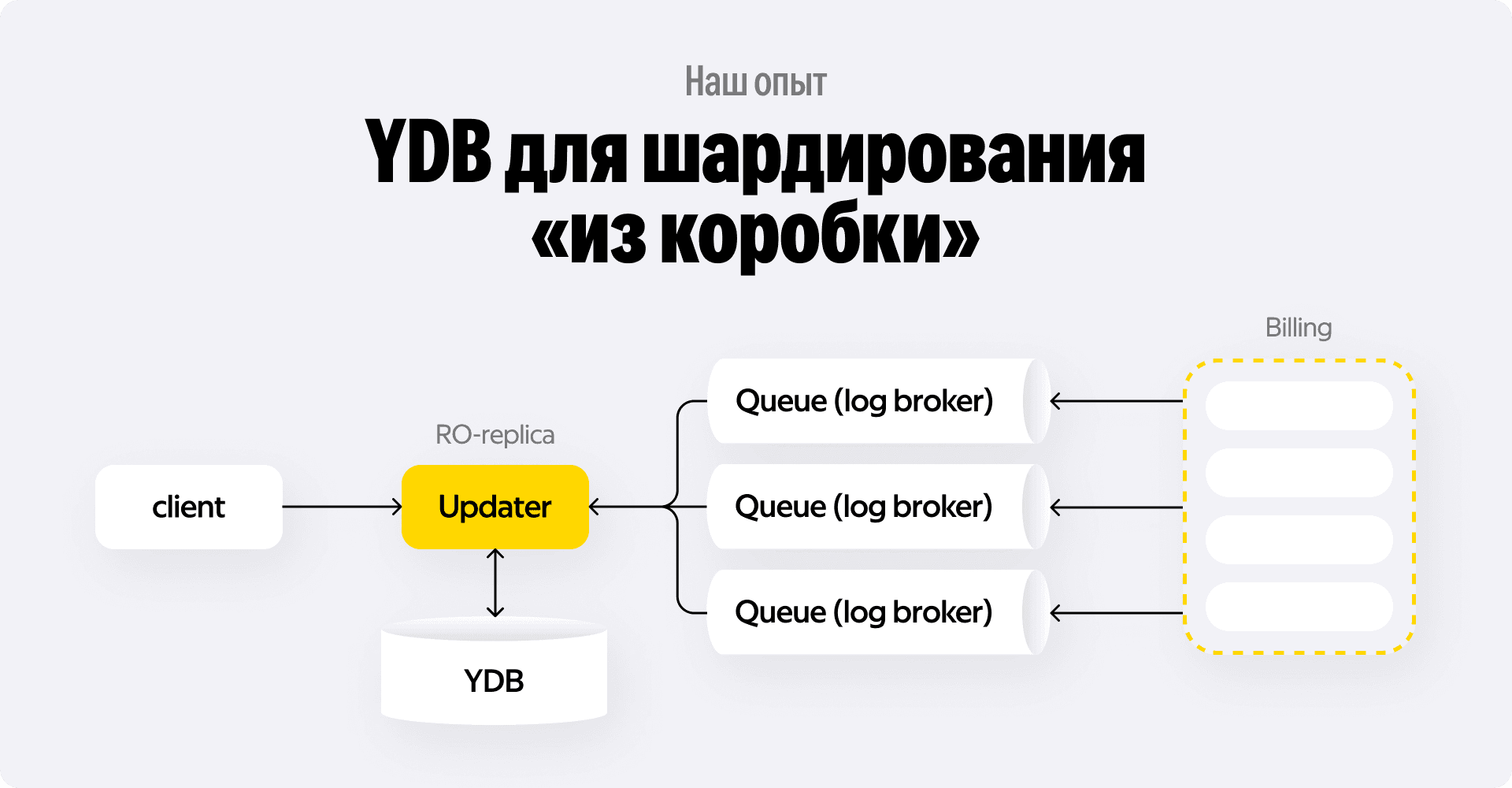
Вместо того чтобы городить самописный шард-менеджер над кластером PostgreSQL или использовать Citus, мы выбрали YDB. Это распределённая SQL-база данных, которая умеет шардирование и ребалансировку данных из коробки.
Нам это давало:
- Автоматическое масштабирование. Мы просто добавляем узлы, и YDB сама перераспределяет данные.
- Строгую консистентность. YDB поддерживает распределённые ACID-транзакции, что критично для финансов.
Правда, пришлось пойти на компромисс. Мы отказались от кросс-табличных транзакций в высоконагруженных сценариях. В YDB они возможны, но при нашем рейте обновлений в тысячи RPS на запись это могло бы стать узким местом.
Поэтому схема осталась прежней:
- Сырые транзакции летят в таблицу raw_events (шардирована по парку).
- Асинхронный воркер вычитывает их и обновляет предагрегаты в таблице aggregates (тоже шардирована по парку).
- Все операции происходят в рамках одного шарда (то есть одного парка), что гарантирует максимальную производительность.
Таким образом, мы получили линейно масштабируемую систему, способную переварить любой рост бизнеса, просто добавляя железо.
Что в итоге
Это был долгий и непростой путь от обычных скриптов с полным пересчётом данных за ночь до распределённой системы, которая обновляет финансовые отчёты за секунду. И главный урок, который я вынес из этого опыта: никаких универсальных решений никогда не существует.
Иногда лучшее решение — это скучный UPDATE в PostgreSQL раз в час. Иногда — сложный стриминг с дедупликацией и идемпотентностью. Всё зависит от природы ваших данных.
Чтобы вам было проще ориентироваться в этом зоопарке решений, я собрал небольшой Cheatsheet, которым мы сами пользуемся при проектировании новых аналитических фич в Яндекс Диспетчерской
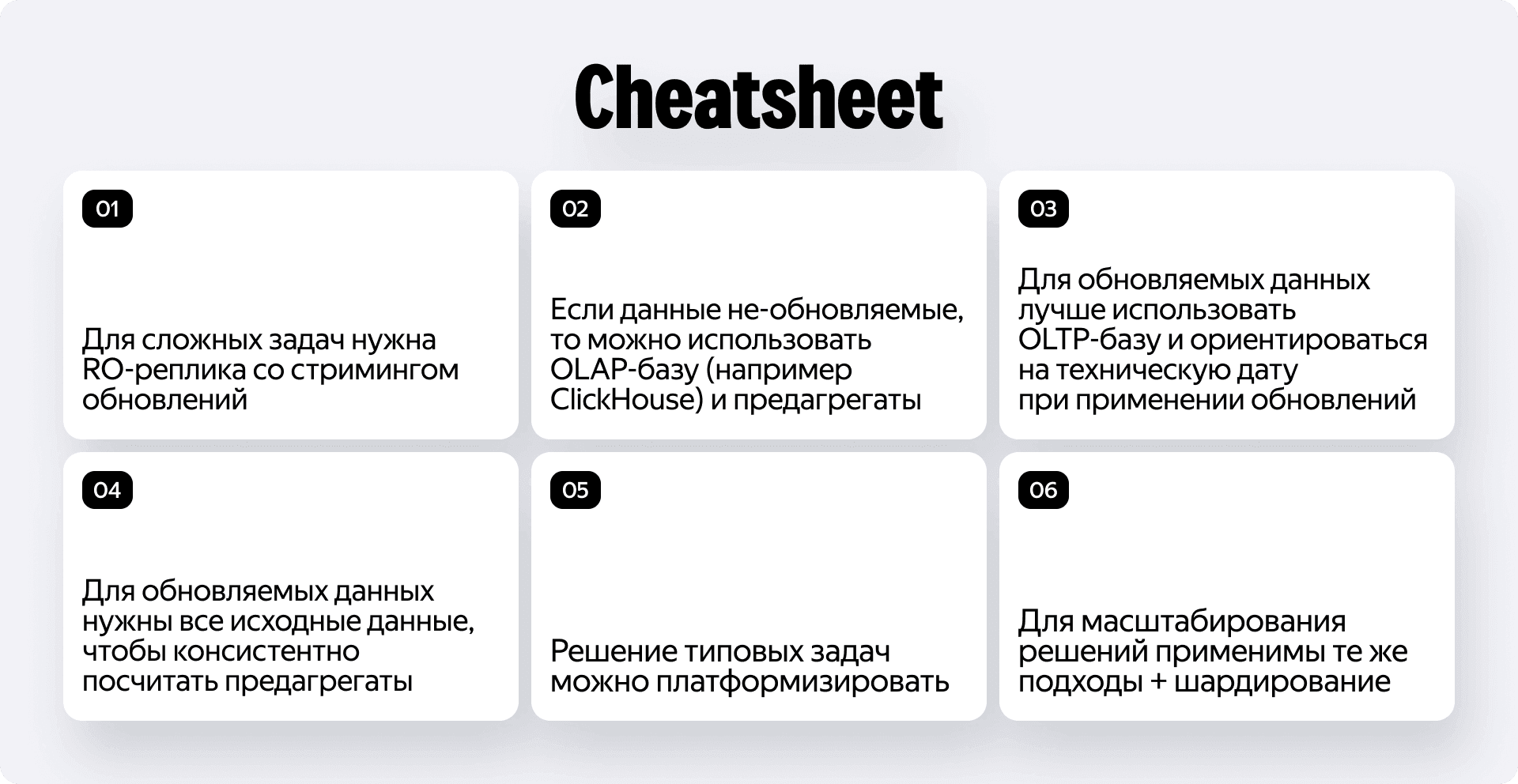
Надеюсь, наш опыт поможет вам не наступать на те же грабли, что и мы. А если вы сейчас проектируете свою систему аналитики — просто начните с вопроса: «А могут ли мои данные меняться в прошлом?». Ответ на него определит всю вашу архитектуру.



