
Всем привет, я Миша, руковожу одним из юнитов разработки в Яндекс Еде. Сегодня я расскажу, как мы переворачивали архитектуру нашего сервиса с ног на голову и почему классические правильные решения иногда могут приводить к фатальным последствиям для базы данных.
Представьте себе типичный сценарий заказа еды: вы заходите в приложение, выбираете любимый ресторан или магазин и уже внутри него ищете конкретное блюдо или товар. Вся архитектура Еды годами строилась вокруг этой логики — она была магазино- и рестораноцентричной. Вы сначала выбираете «где», а потом «что».
Но когда мы начали делать продукт Яндекс Аптеки, стало очевидно: здесь такой паттерн не работает. Стоит пояснить, что технически Аптеки построены на той же платформе Яндекс Еды, которая позволяет заказывать продукты из магазинов. Однако сценарий поведения пользователя здесь принципиально другой. Если у пользователя болит голова, ему всё равно, как называется аптека. Ему нужно найти конкретное лекарство, увидеть, где оно есть в наличии, и выбрать самое выгодное предложение. По сути, нам нужно было развернуть сценарий на 180 градусов: сначала выбрать товары, и только потом — аптеку.
И вроде бы на первый взгляд кажется: ну что здесь сложного? Но так только до тех пор, пока не посмотришь на цифры. Это миллионы товарных позиций. Тысячи аптек. И данные, которые меняются постоянно: цены скачут, а стоки заканчиваются в реальном времени.
Тогда перед нами встала очень непростая задача: как моментально показать пользователю минимальную цену на товар во всём регионе, имея под капотом миллиардный каталог? О том, как мы набили шишки на этом пути, к чему в итоге пришли и при чём тут JOIN LATERAL, я и расскажу в этой статье.
С чем нам приходится работать
У нас есть сущности магазинов и аптек, есть конкретные продукты (с их статичными характеристиками вроде производителя или цвета) и отдельно живёт то, что меняется чаще всего — цены и остатки. Над всем этим стоит мастер-карточка (SKU). Изначально это было просто эталонное описание товара, которое контент-менеджеры заводили вручную, но со временем SKU стала ключевым звеном — именно она связывает одинаковые товары от разных поставщиков в одну сущность.
Исторически мы получали и хранили данные в иерархии «Магазин -> Товар». Теперь же нам нужно было развернуть этот порядок и сделать товароцентричную витрину, причём архитектура должна была быть переиспользуемой — например, для зоотоваров или косметики в будущем.
И вот тут возникает проблема. На витрине мы должны показывать именно мастер-карточки. Но у сущности SKU нет собственной цены — это просто справочная информация. Что показывать пользователю? Разумеется, минимальную цену на этот товар во всём регионе. Задача сводилась к тому, чтобы на лету агрегировать данные из тысяч аптек, находить минимум и отдавать его на фронтенд. Казалось бы, классическая задача. И поэтому мы начали решать её классическим методом.
Попытка №1: нормализация
Мы в Яндексе, как и все, наверное, тоже любим экономить ресурсы, поэтому первой мыслью было сделать всё прямо по учебнику — через нормализованное хранение.
Спроектировали схему так:
- sku_to_product — таблица-связка, где храним соответствие sku_uid и конкретного product_id.
- available_product — таблица с динамическими данными: place_id, product_id и price.
Регион в базе решили не хранить ради экономии места — магазинов не так много, и мы могли разложить все аптеки (place_id) по регионам в in-memory кэше приложения.
План был такой: так как минимальная цена на товар в одном регионе одинакова для всех пользователей, нет смысла считать её в реалтайме на каждый запрос. Мы решили вынести расчёт в фон и складывать готовый результат в отдельную таблицу region_sku (region_id, sku_uid, min_price).
Обновлять эту витрину по расписанию (например, раз в час) нельзя — в фарме стоки очень маленькие, товар может закончиться за минуты. Поэтому мы завязались на топик с изменениями цен и остатков. Логика выглядела следующим образом:
- Прилетает событие: в аптеке X изменилась цена или закончился товар.
- Записываем изменение в available_product.
- Идём в sku_to_product и находим, к какой мастер-карточке (sku_uid) относится этот товар.
- Там же достаём список всех product_id, привязанных к этой SKU.
- Через in-memory кэш определяем регион и получаем список всех аптек (place_id) в нём.
- Делаем выборку из available_product по полученным спискам товаров и аптек, чтобы найти актуальный минимум.
- Обновляем запись в region_sku.
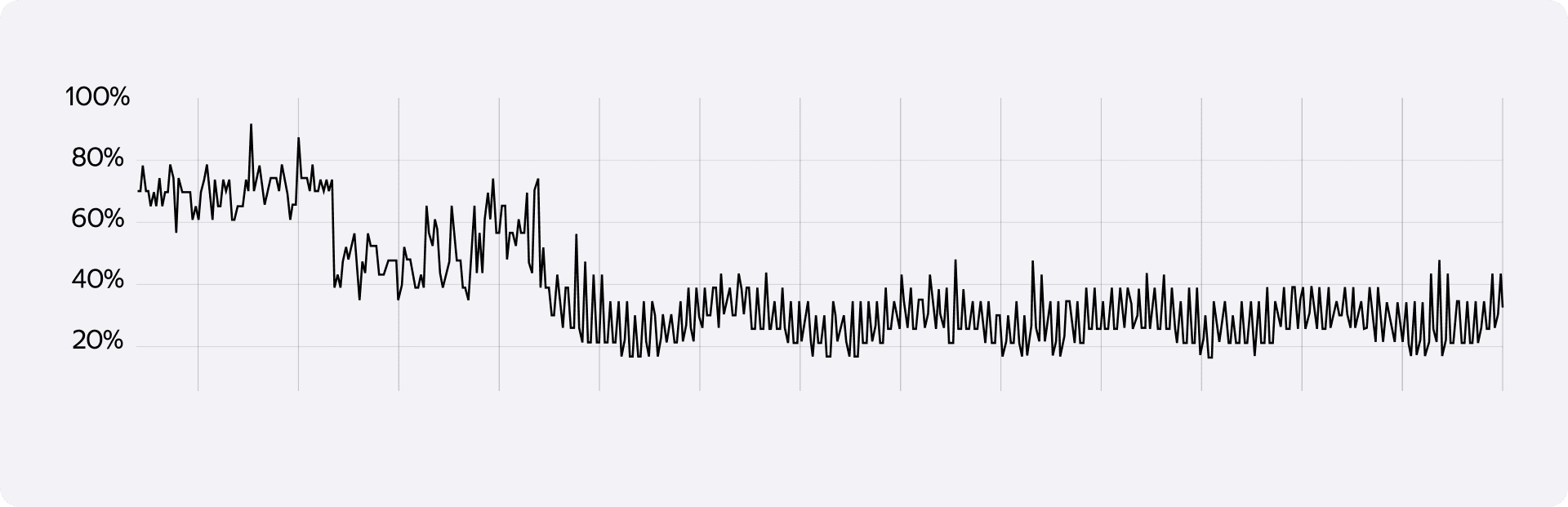
На бумаге всё вроде бы отлично. Но в реальности мы упёрлись в стену как раз на шестом шаге. Когда мы отправляли в базу запрос, где в одном IN(...) лежали все product_id (вариации товара), а в другом IN(...) — все place_id (аптеки региона), оптимизатор Postgres сходил с ума. Индексы переставали работать эффективно, и начинался Full Scan таблицы.
На фоне частоты обновлений — а в пике это до 20 сбатченных событий в секунду — CPU базы уходил в полку. Мы пробовали масштабироваться вертикально и накидывать ядра, пытались разбивать батчи айдишников и сплитовать запросы, но результат особо не менялся: база всё равно захлёбывалась. Парадоксально, но нормализация, призванная сэкономить ресурсы, в итоге их же и уничтожала.
Попытка №2: радикальная денормализация
После многочисленных попыток оптимизации запросов с IN(...) мы поняли, что обычным тюнингом тут не отделаешься. Нужно переосмыслить сам подход к хранению данных. Мы решили действовать радикально и уйти от нормализации к полной денормализации.
Идея была такая: вместо того чтобы джойнить данные на лету или делать сложные выборки, давайте сложим всё необходимое в одну плоскую таблицу. Чтобы все поля, по которым мы фильтруем или сортируем, лежали рядом.
Мы создали таблицу available_product_skus:
CREATE TABLE available_product_skus(
place_id BIGINT NOT NULL,
product_id TEXT NOT NULL,
sku_id TEXT NOT NULL,
region_id BIGINT NOT NULL,
price DECIMAL(18, 2) NOT NULL,
-- остальные поля
PRIMARY KEY (place_id, product_id, region_id)
);
Но сама по себе таблица — это полдела. Самое интересное началось, когда мы накатили правильные индексы. Проблема жирных IN сразу же ушла, потому что теперь все критерии поиска участвовали в индексе напрямую:
CREATE INDEX idx__available_product_skus__sku_region_price
ON eats_retail_sku_viewer.available_product_skus (sku_id, region_id, price);
CREATE INDEX idx__available_product_skus__product_id
ON eats_retail_sku_viewer.available_product_skus (product_id);
Конечно, тут были риски, и мы их прекрасно осознавали. Главный страх любого бэкендера при денормализации — жирные индексы убьют вставку. Было опасение, что при нашем потоке обновлений цен база встанет колом на записи, а нагрузка на мастер станет критической.
Однако замеры показали обратное. Оказалось, что стоимость поддержки индексов при вставке несопоставимо ниже, чем ресурсы, которые мы тратили на Full Scan при чтении в старой архитектуре. Потребление CPU базы упало буквально в разы. Даже тяжёлые корнер-кейсы, вроде массового обновления связей, когда товары переезжают из одной SKU в другую, проходили гладко.
Теперь поиск минимальной цены для одной конкретной мастер-карточки стал элементарным и мгновенным:
SELECT min(price)
FROM available_product_skus
WHERE sku_id = $1 AND region_id = $2;
Казалось бы, победа. Мы научились быстро считать минимум для одного товара. Но тут мы вспомнили, что на витрине у нас не один товар, а сотни. И нам нужно получить цены для них всех сразу.
Борьба за миллисекунды
Первым делом мы попробовали масштабировать решение в лоб: передать список sku_id и сделать GROUP BY.
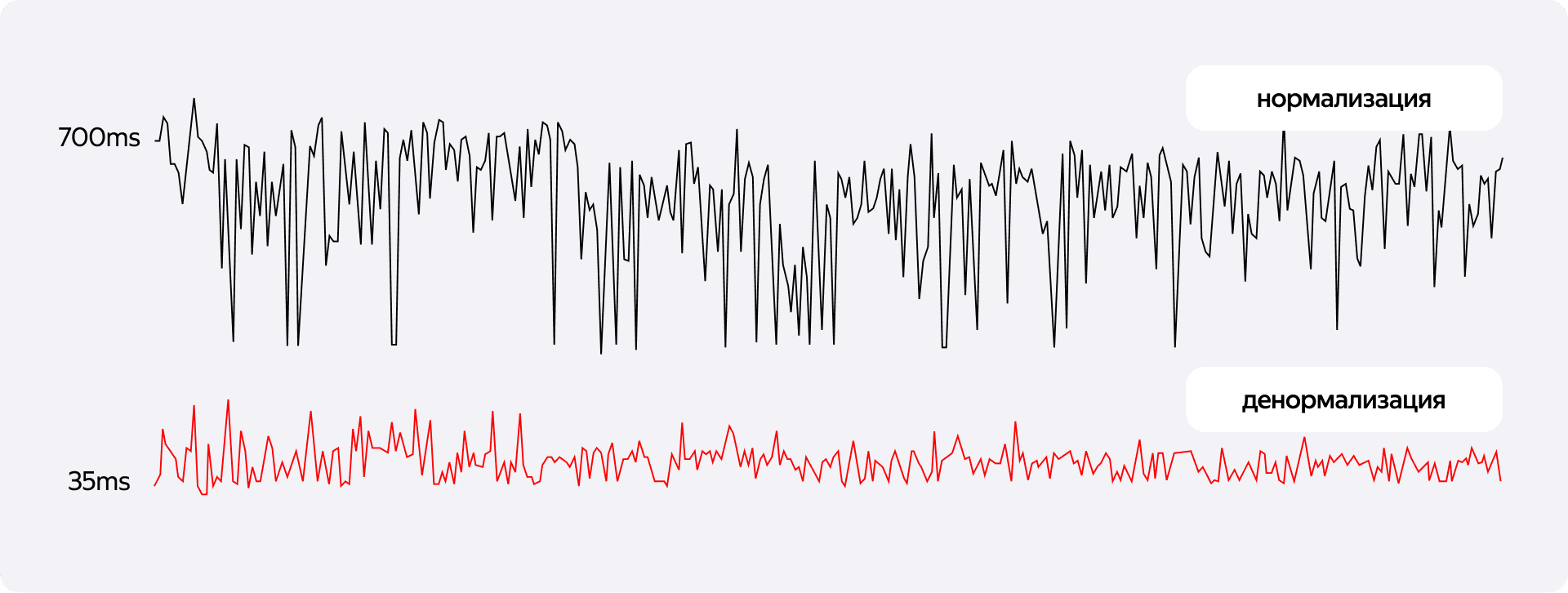
Результат не обрадовал: запрос выполнялся более 200 мс. Для высоконагруженного реалтайм-сервиса это почти что вечность. Проблема в том, что при группировке большого массива данных индексы используются недостаточно эффективно, и базе приходится перелопачивать лишние данные.
Мы начали искать альтернативные подходы к выборке «Топ-1 цены для списка товаров». Подсказку, как ни странно, дал AI — он предложил посмотреть в сторону JOIN LATERAL.
В итоге наш запрос трансформировался в следующую конструкцию:
WITH input_keys (sku_id, region_id) AS (
SELECT * FROM unnest($1::text[], $2::bigint[])
)
SELECT
s.sku_id,
s.region_id,
s.price
FROM input_keys ik
JOIN LATERAL (
SELECT
s_inner.sku_id,
s_inner.region_id,
s_inner.price
FROM available_product_skus s_inner
WHERE s_inner.sku_id = ik.sku_id
AND s_inner.region_id = ik.region_id
ORDER BY s_inner.price ASC
LIMIT 1
) s ON TRUE
Без LATERAL подзапрос был бы изолирован. С ним мы фактически реализуем цикл for на уровне SQL. Логика такая:
- Берём пару sku_id + region_id из входного массива.
- Для этой конкретной пары ныряем в таблицу available_product_skus.
- Благодаря индексу (sku_id, region_id, price) моментально находим одну самую дешёвую запись (LIMIT 1).
- Повторяем для следующей пары.
Вместо того чтобы пытаться сгруппировать и отсортировать огромную выборку целиком, мы делаем серию молниеносных точечных чтений. Это работает так же быстро, как если бы мы писали код в цикле приложения, но происходит внутри базы данных без оверхеда на сеть. Время ответа сократилось кардинально, и проблема производительности витрины была решена.
Выводы
Главный урок этой истории прост: в высоконагруженных системах академическая правильность часто проигрывает грубой эффективности. Денормализация, которой нас пугали в университетах как какой-то чумой, в нашем случае стала единственным рабочим выходом. Да, мы пожертвовали красотой схемы и объёмом хранилища, но взамен получили систему, которая не падает от наплыва обновлений.
Отдельно хочу подсветить JOIN LATERAL. Если вам нужно выбрать лучшее предложение из группы для множества ключей одновременно — это супер-инструмент. Он позволяет эмулировать цикл внутри SQL-запроса, избегая вытягивания лишних данных в память приложения.
Мы строили нашу товароцентричную архитектуру именно для аптек, но этот подход универсален. Если завтра нам нужно будет запустить витрину для зоотоваров или косметики, мы уже знаем: не стоит бояться жирных таблиц и нестандартных джойнов, если на кону стоят миллисекунды ответа пользователю. Реальные кейсы часто оказываются контринтуитивными и требуют решений, которых не найдёшь в методичке.



