
Владислав выступил с докладом на конференции Яндекс Go Dev Day&Night, где рассказал, как и зачем следить за производительностью SDK, какие метрики собирать и что с ними делать.
Привет! Меня зовут Влад Бардин, я iOS-разработчик в команде Яндекс Маркета и занимаюсь разработкой SDK (Software Development Kit) для BDUI, а конкретнее, отвечаю за его скорость. Наш SDK позволяет строить почти всё приложение полностью с бэкенда. Бóльшая часть разработки при таком подходе происходит именно на бэкенде и оттуда же можно достаточно сильно влиять на производительность контента.
Сегодня я хотел бы рассказать, зачем вообще следить за производительностью, когда вы разрабатываете такой фундаментальный SDK, какие метрики стоит собирать и как взаимодействовать с потребителями, то есть продуктовыми командами, которые используют ваш SDK в своих приложениях.
Что такое SDK и с чем их едят
Откуда вообще берутся SDK? Чаще всего это желание команд:
- эффективнее переиспользовать код;
- отделиться от релизных процессов основных приложений;
- лучше контролировать флоу разработки;
- встраиваться в другие приложения внутри компании или даже где-то снаружи.
В Яндексе полно таких SDK (Яндекс Плюс, умная камера и другие), и вы наверняка с ними сталкивались как пользователь. SDK нашей команды вы могли видеть, если пользовались Яндекс Маркетом или же видели ленту товаров Маркета в других приложениях Яндекса.
Следить за производительностью приложений — важное занятие, как минимум потому, что пользоваться быстрым приложением приятно. Если нет никакого контроля за скоростью приложения, то производительность в любом случае рано или поздно будет понемногу просаживаться. А потом это станет заметной проблемой на любом, даже самом флагманском устройстве.
Когда вы разрабатываете SDK, необходимо учитывать следующее:
- никто не захочет подключать к себе медленный SDK;
- каждая просадка в коде будет влиять на всех потребителей SDK;
- потребители ожидают быстрой реакции на возможные проблемы с производительностью.
Чтобы обезопасить себя от неожиданного потока недовольных потребителей SDK, мы решили попробовать следить за производительностью на нашей стороне — до того как новая версия попадёт в приложения Яндекса.
Но чтобы за чем-то следить, нужно сначала понять, какая функциональность ключевая, и разметить её метриками. Как я уже писал выше, мы разрабатываем SDK для BDUI, на котором можно строить экраны любой сложности — их контент и переходы управляются полностью с бэкенда.
Подробнее про BDUI можно посмотреть на первом и втором Yandex BDUI Conf или почитать статью Лёши Морозова про путь Маркета в BDUI.
И контент, и сама вёрстка приходят с бэкенда одним целым экраном, вся бизнес-логика живёт там же. Чтобы как-то отреагировать на действия пользователя, нам в большинстве случаев необходимо снова пойти в бэкенд, подготовить новый экран и оптимально обновить контент.

Итак, основная функциональность нашего SDK, на которую мы можем влиять с точки зрения производительности, — это работа с данными: их получение, последующая обработка, отрисовка и обновление. А также управление переходами между экранами.
Что нам хотелось с точки зрения метрик, исходя из основной функциональности:
- быть в курсе того, что происходит в коде: от нажатия до полного показа контента пользователю;
- иметь плавный скролл;
- знать о возможных утечках памяти (memory leaks).
В конечном итоге нам удалось выделить четыре основные метрики: фетчинг (http-запрос), декодинг, рендеринг, Hitch-рейт.
Метрики BDUI SDK
Фетчинг

Мы размечаем старт, подготовку запроса и конец, когда уже получили сырые данные. Дополнительно мы разбиваем время запроса на время до первого (TTFB) и последнего байта (TTLB), чтобы понимать, на какой стороне проблема — на бэкенде или у нас на клиенте.
Благодаря этой метрике, мы, например, поняли, что на Android время до первого байта почти в 1,5 раза больше, чем на iOS. Хотя, казалось бы, метрики должны быть сопоставимы, потому что работа по подготовке данных на бэкенде выполняется одна и та же, и клиентам остаётся только затратить какое-то время на установление коннекта с бэкендом.
Решили посмотреть, почему в Android такое время до первого байта. Оказалось, что для каждого запроса в бэкенд создавался новый коннект, поэтому простым использованием ConnectionPool в OkHttpClient удалось сравнять время с iOS и ускорить старт Android-приложения Маркета почти на 500 миллисекунд.

Декодинг

После запроса мы декодируем данные, размечаем старт и конец. Ответ достаточно большой, так как содержит всё состояние экрана, включая основные блоки — UI, аналитика, экшены, а также любой дополнительный контент, который может определить сам потребитель в отдельности. Поэтому необходимо предоставлять гранулярные метрики, которые покажут, какая часть ответа сколько декодилась. Это помогает выделить проблемные части при дальнейших оптимизациях.

Рендеринг

После декодинга мы также размечаем старт-конец рендеринга готового контента, дополнительно логируем время перевода данных в понятные для рендеринга модели и их диффинг при обновлении контента. Всё это позволяет получить понятную общую метрику — сколько всего времени занял показ контента от нажатия пользователя до полной отрисовки.
Концом рендеринга мы считаем момент, когда контент виден пользователю и когда отработали какие-либо экшены, заданные с бэкенда на событие onRender. Это нужно, чтобы понимать, когда пользователь уже может взаимодействовать с контентом, а не просто смотреть на него.
Эта метрика работает корректно в большинстве случаев, за исключением каких-либо кастомных секций (AsyncView, видео), жизненным циклом которых управляет сам потребитель SDK.

Hitch-рейт
Обязательно следим за плавностью скролла — метрикой HItch. Для пагинируемого контента, вроде бесконечной ленты или поисковой выдачи, мы собираем метрику отзывчивости скролла. Hitch показывает процент пропущенных кадров при скролле, т. е. сколько времени за скролл у пользователя не двигался экран.
Мы собираем именно Hitch, а не чистые FPS, потому что:
- простым количеством кадров сложнее оценить дискомфорт пользователя, т. к. оно не показывает возможные подёргивания и прерывания отрисовки;
- Hitch позволяет точнее определить критичность проблемы, т. к. показывает динамику отрисовки;
- с более точной метрикой Hitch можно настроить автоматический мониторинг на пороговые значения.
Эмпирическим путём мы выяснили, что на экранах Маркета даже 6% пропущенных кадров значительно влияют на отзывчивость интерфейса, поэтому в приоритете мы рассматриваем всё, что выше этого показателя.
Для сбора метрик мы используем платформенные API, которые позволяют отслеживать получение готовых кадров. В итоге мы знаем, когда должен прийти следующий кадр и когда он на самом деле пришёл. Дальше путём нехитрых вычислений мы можем подсчитать, сколько лишнего времени мы ждали кадры и экран не двигался.
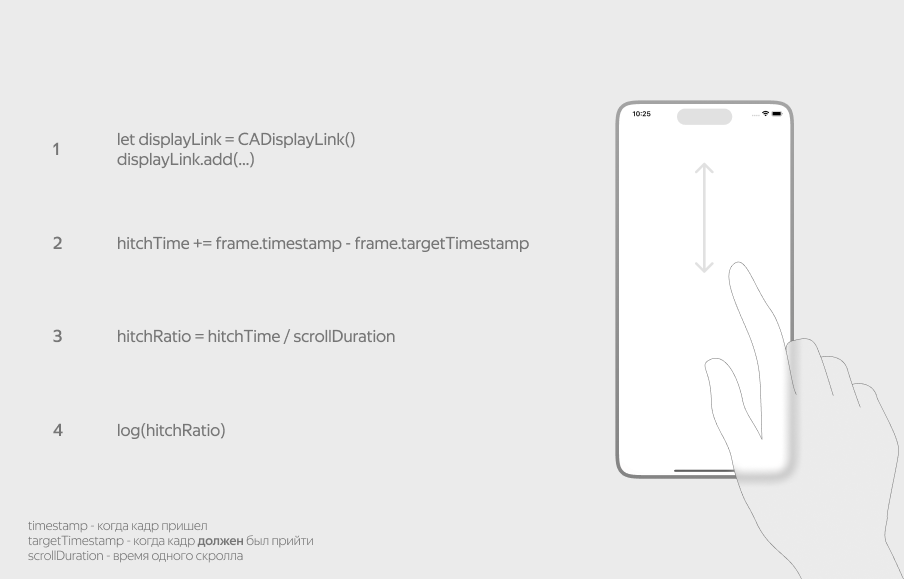
Hitch на iOS для вас любезно собирает сам Apple, и в Xcode Organizer можно проверить, как обстоят дела у вашего приложения. А если вы захотите обогатить эту метрику данными о конкретных экранах, экспериментах, девайсах, то можно попробовать реализовать свой механизм через подсчёт полученных кадров.
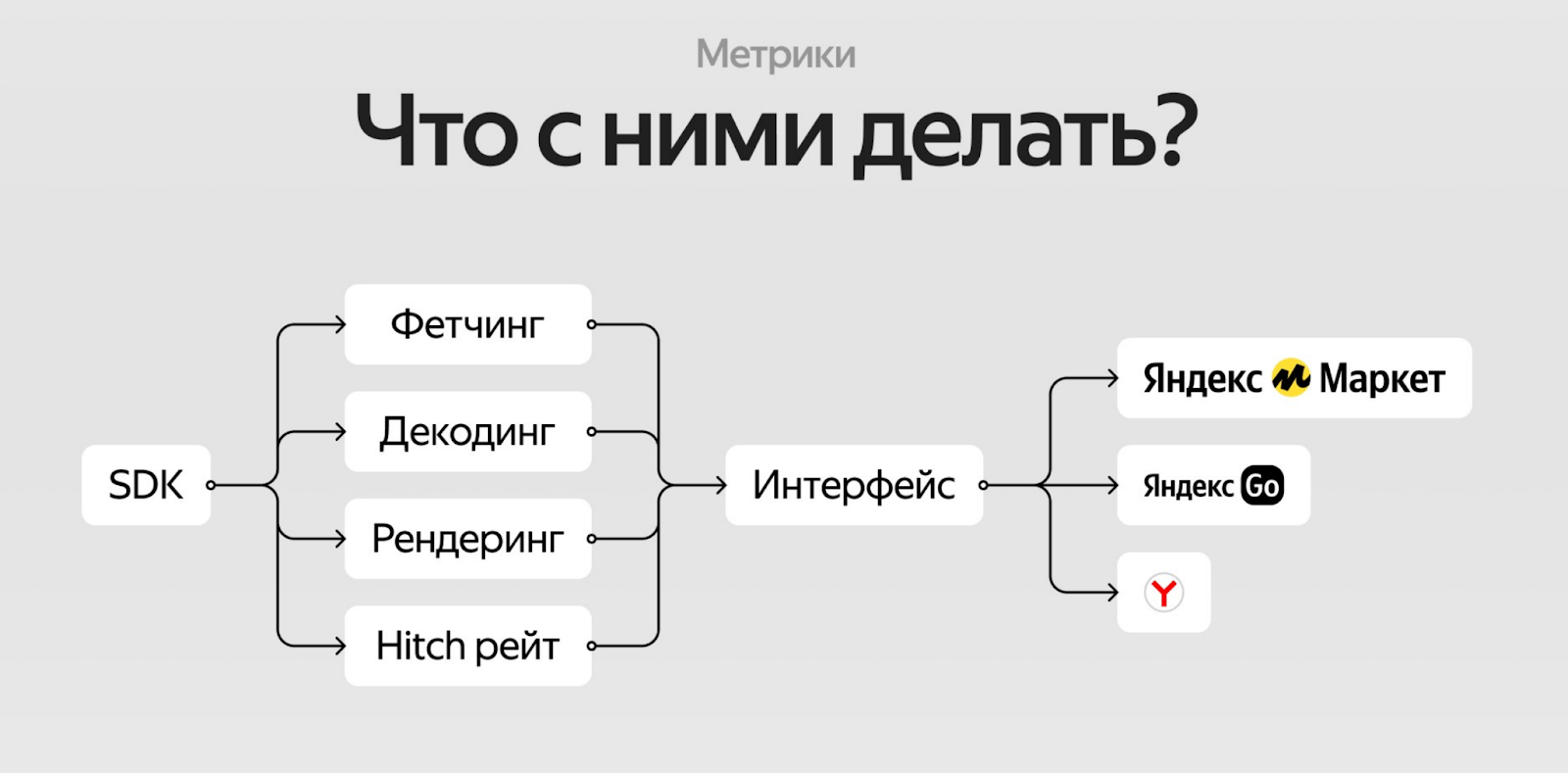
Собрали метрики, скомпоновали в какой-то понятный интерфейс и отдаём потребителям, чтобы они могли следить за этими данными у себя
В итоге мы получили интерфейс, который:
- даёт возможность потребителям следить за скоростью продуктовых экранов;
- позволяет собрать дашборд качества SDK по потребителям;
- помогает строить дальнейшую инфраструктуру по недеградации производительности.
Эти метрики очень полезны потребителям, но наша цель — это отслеживание просадок скорости до их попадания в новую версию SDK. Нам хотелось бы самим использовать эти метрики, чтобы не допускать деградации и улучшать производительность. Но как это делать, если вы разрабатываете SDK и у вас нет собственного приложения и базы пользователей, на которой можно было бы тестировать изменения? Ответом на этот вопрос для нас стали перф-тесты.
Перф-тесты
Перф-тест — обычный UI-тест, в котором мы запускаем заранее подготовленный контент в виде json: можем его поскролить, куда-нибудь нажать, при этом собирая все те метрики, которые мы разметили раньше. В результате теста мы получаем простой отчёт о том, какая метрика сколько выполнялась.
Запускать перф-тесты на симуляторе почти бессмысленно, потому что так невозможно получить реальную картину. Поэтому мы пользуемся внутренним решением, которое позволяет запускать перф-тесты на реальных устройствах.
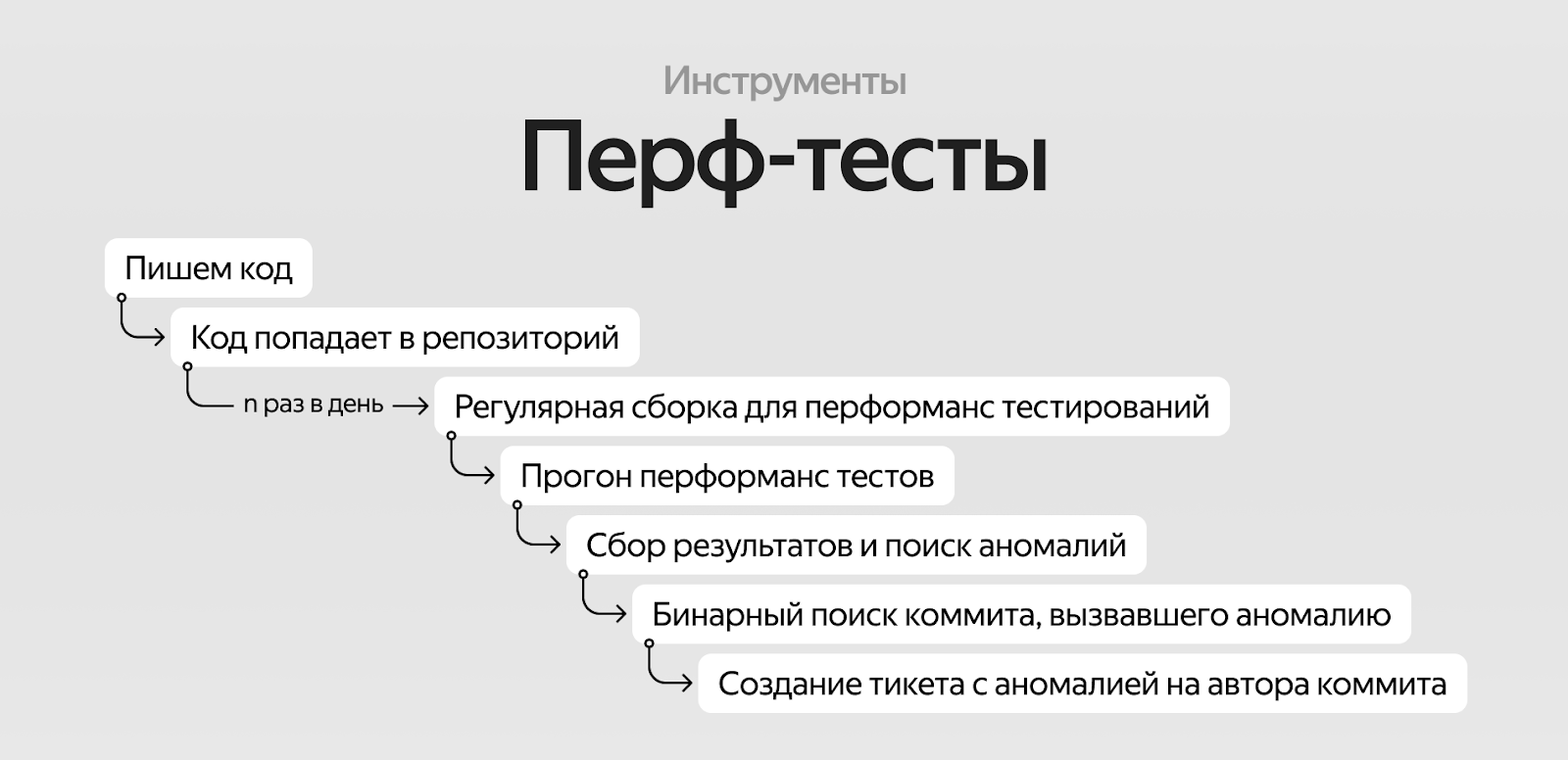
Пайплайн работы примерно следующий: мы пишем код, он попадает в репозиторий, и регулярно (в нашем случае шесть раз в день) система забирает код, делает сборку и прогоняет на ней перф-тесты на реальных устройствах. Мы собираем результаты, они появляются на графике. Подробнее про то, как это устроено, как выглядят фермы устройств, можно почитать в статье Паши Воробкалова.
Что нам дают такие перф-тесты:
- относительно реальные данные по тому, с какой скоростью работает ключевая функциональность SDK;
- контроль за адекватностью собираемых данных: кроме просадок будем видеть аномальные улучшения метрик;
- процесс по работе с просадками (планируем аномалии на спринт, видим авторов деградирующих изменений).
Итак, мы собрали все основные метрики и теперь можем ими пользоваться и отслеживать просадки в SDK. Но я упоминал, что мы хотим ещё следить за возможными утечками памяти. Это не совсем метрика, но, как оказалось, это то, за чем тоже нужно следить, чтобы не просаживать производительность.
Memory leaks
Однажды к нам принесли баг из продукта: при открытии поп-апа наш SDK триггерит запрос данных и количество этих запросов постоянно росло при использовании приложения, хотя ожидается ровно один запрос. И это негативно сказывалось не только на производительности приложения, но и на нагрузке на бэкенд, который в таких условиях получал в несколько раз больше запросов. Проблема была в утечках памяти.
Все предыдущие поп-апы при создании инициировали сущность, которая обрабатывала сигналы от SDK и реагировала на сигнал открытия, запрашивая данные. Из-за утечки эта сущность оставалась в памяти и продолжала реагировать на открытие новых поп-апов, таким образом мы получали нагрузку из-за уже закрытых поп-апов.
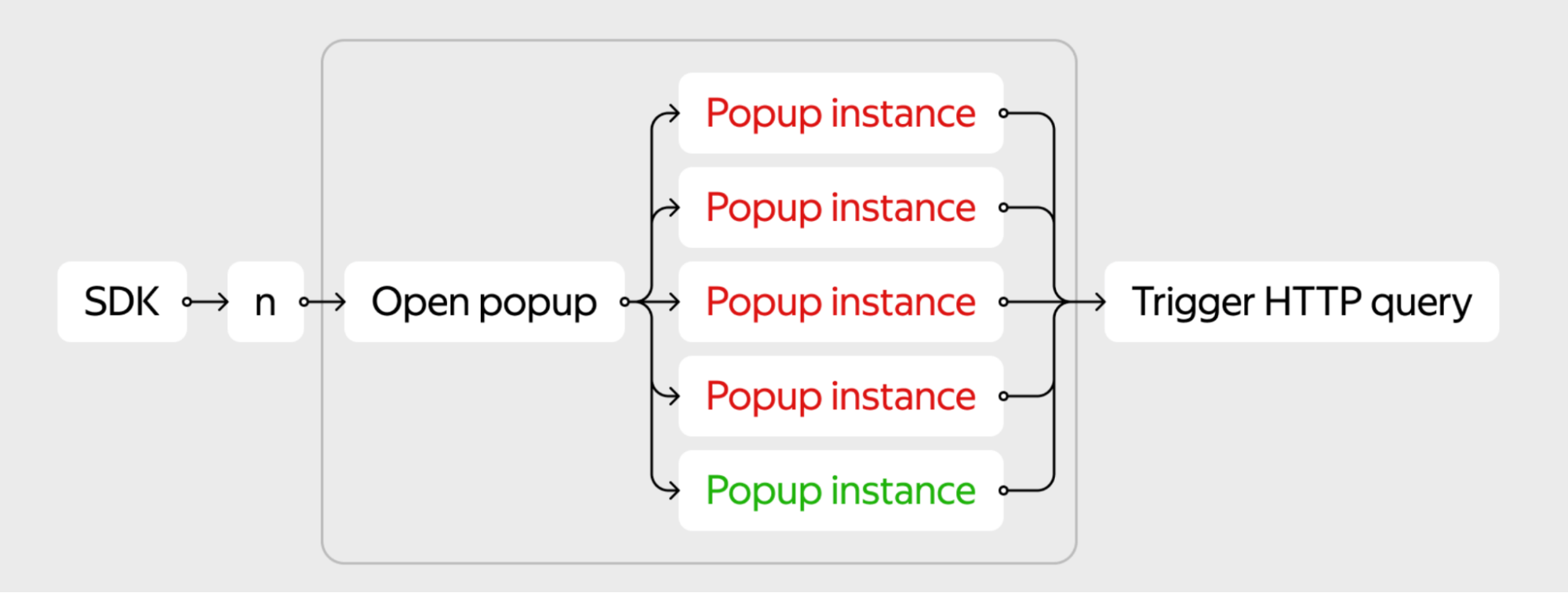
Утечки в этом конкретном кейсе мы починили, но хотелось бы обезопасить себя от таких проблем в будущем, поэтому мы решили интегрировать проверку на утечки в наши UI-тесты. Мы пишем мультиплатформенные тесты, но для сбора утечек использовали платформенные утилиты. UI-тест на примере известной нам утечки выглядит так:
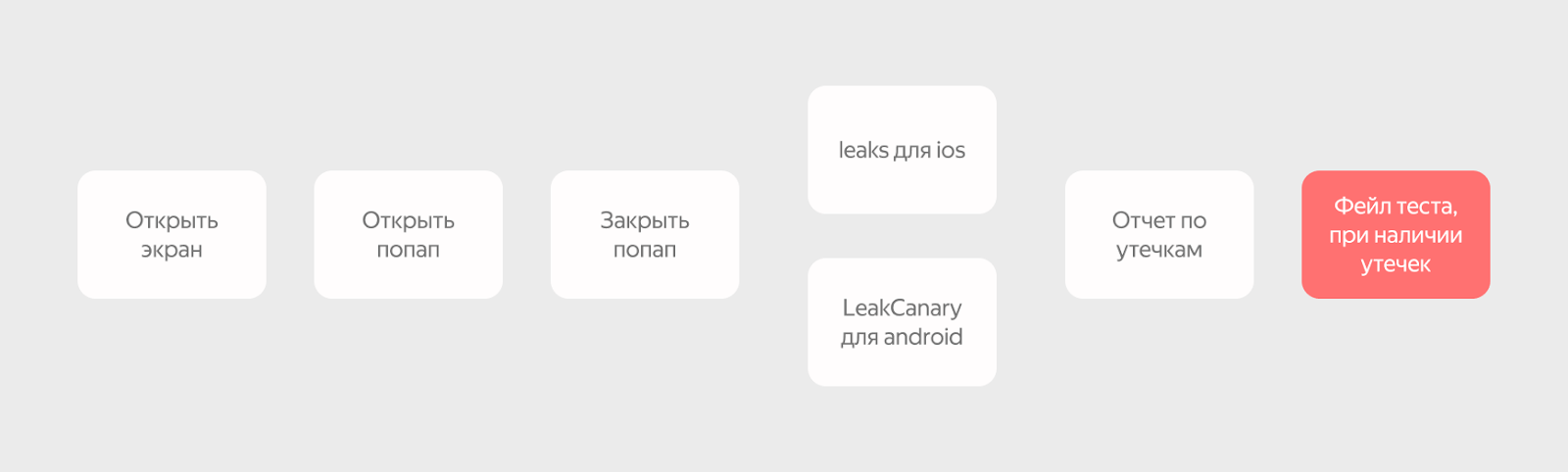
Для iOS мы используем встроенную в macOS утилиту leaks, которая сообщает нам о всех возможных утечках. На Android же мы используем библиотеку LeakCanary, которая позволяет настроить проверку более таргетно, поэтому на Android мы проверяем утечки только в компонентах нашего SDK.
В итоге мы выбрали тесты, которые проверяют основные сценарии навигации нашего SDK, и добавили в них проверку на утечки.

Эти тесты вполне могут покрывать все проблемы с утечками, но при построении теста стоит учитывать:
- что считается за утечку на платформе;
- различные конфигурации SDK у потребителей;
- в какие тесты добавлять проверку на утечки (добавляет значимое время к выполнению теста).
Что делать, когда собрали метрики
Мы собрали метрики, по ним у нас есть тесты на производительность и дополнительно — UI-тесты на утечки. Достаточно ли этого, чтобы полностью покрыть проблемы с производительностью? Для небольших SDK, которые представляют собой точку входа в какую-то функциональность, этого действительно может быть достаточно. Но для нас это не так.
Мы предоставляем SDK, который может являться фундаментом приложения, и от нас будут зависеть продуктовые показатели сервиса. Бóльшая часть разработки происходит на бэкенде, откуда команды могут сильно влиять на производительность экранов. Поэтому…
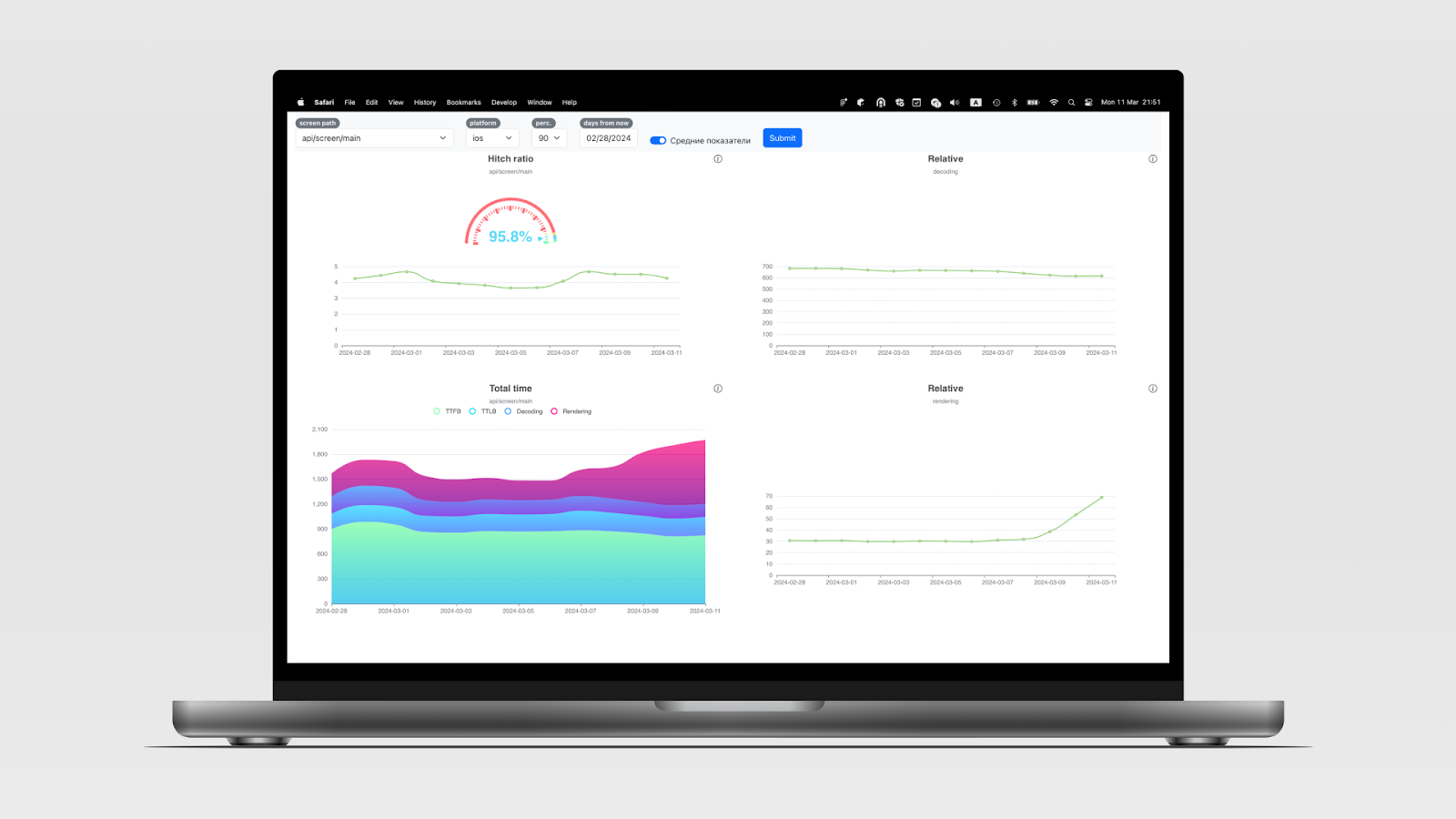
Что мы собираем на дашборде:
- график Hitch вместе с прибором, который показывает, какое значение мы считаем приемлемым и куда стоит стремиться;
- график Total time, который включает в себя все этапы работы нашего SDK;
- относительные метрики декодинга и рендеринга, чтобы отделить проблему изменений в SDK и на бэкенде;
- для пагинируемого контента показываем метрики фетчинга и декодинга для каждой страницы в отдельности.
Все эти данные можно фильтровать по датам, версиям приложения, экспериментам, квантилям.
Команды используют этот дашборд при планировании работ по ускорению или для проверки готовых результатов по ускорениям. Можно сравнить себя с соседними экранами по приложению или же просто заметить какие-то неожиданные просадки.
Но неудобство дашборда в том, что проблемы, которые команда увидит на этом дашборде, уже произошли у всех пользователей. И чтобы отлавливать эти проблемы чуть раньше, мы решили встроить метрики скорости в инструмент проведения экспериментов.
Наверняка и в ваших командах проводят эксперименты, и обычно при их приёмке смотрят на понятные бизнесу метрики оформленных заказов, заработанных денег, активных пользователей. В этот список мы решили добавить метрики скорости. Что нам это даёт?
- отлавливаем проблемы, когда с ними столкнулся небольшой процент пользователей;
- имеем возможность поправить производительность, остановив деградирующий эксперимент;
- работа по скорости ведётся не только силами нашей небольшой команды, но и с помощью разработчиков продуктовых команд.
Но чтобы использовать метрики скорости как показатель при приёме экспериментов, метрика должна быть качественная.
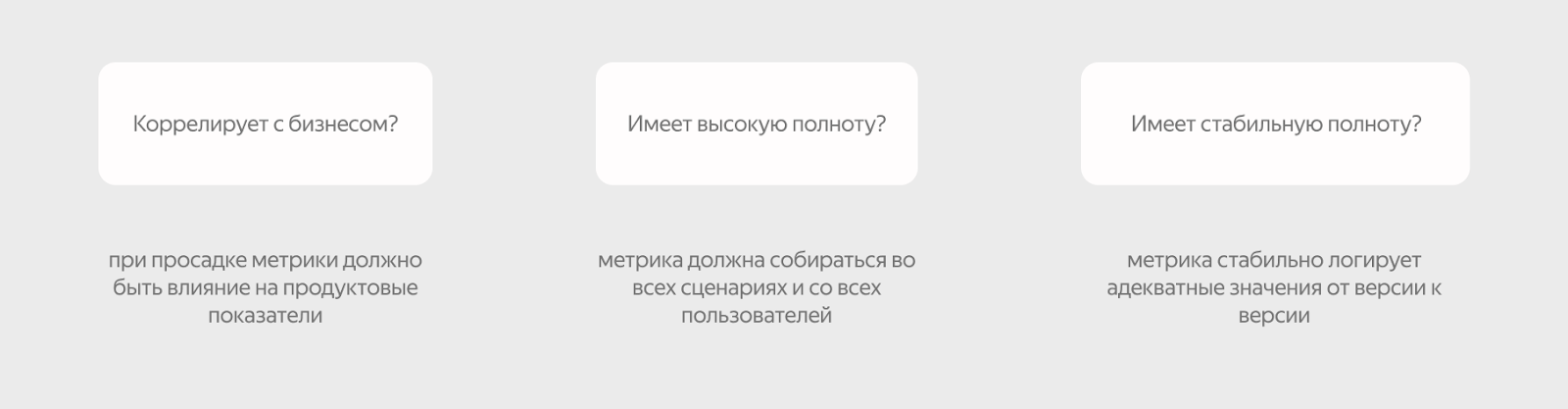
Критерии качества метрик
Мы выделили несколько критериев, по которым определяем, что метрика качественная и ей можно верить:
- корреляция с бизнесом;
- высокая полнота;
- стабильная полнота.
Но с чего мы вообще решили, что метрики скорости как-то влияют на бизнесовые показатели? Для нас может быть очевидно, что чем быстрее работает приложение, тем лучше. Но для бизнеса просто «очевидно» недостаточно — нужны пруфы. Поскольку ускорять что-то сложно, мы решили замедлить и провели эксперимент, в котором некоторая часть пользователей получала специально замедленную версию Маркета. Целью эксперимента было проверить, действительно ли скорость сервиса влияет на продуктовые показатели и работают ли метрики скорости.
По результатам эксперимента мы выяснили, что:
- снижение скорости загрузки экрана приводит к падению активности пользователей;
- снижение интерактивности (момента, когда пользователь может взаимодействовать с контентом) приводит к ещё большему падению активности;
- лояльные пользователи более терпимы к замедлениям;
- метрики скорости работают и коррелируют с продуктовыми показателями.
Люди меньше пользуются сервисом, меньше на нём покупают. Вывод простой: необходимо следить за скоростью приложения.
А чтобы соответствовать критериям высокой и стабильной полноты метрики, со стороны SDK необходимо:
- учитывать возможные различия API в разных версиях операционных систем, чтобы охватывать максимум пользователей;
- обрабатывать корнер-кейсы при сборе метрик (например, обработка сворачивания приложения при запросе за данными);
- иметь тесты на логирование и формат метрик.
Заключительные мысли
Производительность — достаточно сложная тема, к которой необходимо подходить комплексно, особенно если вы разрабатываете SDK. Недостаточно просто собрать метрики и ждать, пока они просядут. Необходимо:
- максимально заранее отлавливать просадки (перф-тесты, метрики в экспериментах);
- предоставлять понятные для потребителей инструменты отслеживания скорости (графики, дашборды);
- следить за качеством и стабильностью метрики.
Сейчас мы уже отлавливаем большинство проблем на этапе разработки и проведения экспериментов. Команды сами разбирают свои просадки, и на своей стороне мы видим неожиданные проблемы, скажем, при поднятии версии сторонней зависимости или проведении больших рефакторингов.
Но у нас ещё есть куда улучшать работу как с метриками, так и с командами. Мы уже наметили первые проекты по улучшению работы с производительностью:
- Поддержка актуальности перформанс-тестов. Необходимо автоматизировать сбор мок-данных для перф-тестов, чтобы следить за актуальным форматом, с которым работает SDK.
- Алертинг на просадки. Не все команды готовы регулярно следить за производительностью на дашбордах, но они вполне готовы реагировать на серьёзные проблемы с производительностью их экранов. Для таких команд необходимо иметь автоматические алерты на просадки.
- Сбор метрик с тестировщиков. Если мы не отследили просадку на момент разработки внутри SDK, то было бы здорово предоставить командам инструменты, чтобы собирать эти метрики при регрессе новых версий приложений. Это даст возможность отреагировать на серьёзные просадки до того, как приложения отправятся на ревью в сторы.
Идеал, к которому мы хотим двигаться в долгосрочной перспективе, — это полная автоматизация работы с производительностью SDK и его потребителями, что включает в себя:
- автоматическое создание мониторингов с трешхолдами на каждый новый продуктовый экран;
- автоматический алертинг с призывом ответственных за экран на все ключевые метрики скорости;
- автоматическое заведение дашбордов для новых экранов и приложений.
В итоге необходима максимальная информативность по всем метрикам, которые мы предоставляем, и полная автоматизация обзервабилити, чтобы снять большую фоновую работу по скорости. С ростом числа потребителей SDK справляться с этим самим будет всё сложнее. Чем более универсальный инструмент вы разрабатываете, тем сложнее контролировать то, как им пользуются, а подобная работа со скоростью становится просто необходимой.




