
Как определить, что такси едет слишком быстро, если его GPS-трек вдруг начинает рисовать идеальные круги посреди моря? И нет, это не гипотетическая задачка с технического собеседования, а самая что ни на есть суровая реальность.
Меня зовут Маша Медведева, я аналитик-разработчик в команде безопасности поездки Техплатформы Городских сервисов Яндекса. Мы с коллегами влияем на мир технологиями — предотвращаем инциденты и делаем всё, чтобы поездка в такси была максимально безопасной. И одна из наших ключевых задач — следить за скоростным режимом.
Почему это так важно? Всё просто: по данным ГИБДД, превышение скорости — самая распространённая причина ДТП. Более того, скорость усугубляет последствия аварий, которые происходят по другим причинам. Поэтому у нас давно работают алгоритмы, которые отслеживают нарушения скоростного режима.
Долгое время наша система работала стабильно и эффективно. Но массовые проблемы с геолокацией — GPS-спуфинг — попросту испортили наши данные во многих регионах. Треки водителей стали проходить сквозь дома, парки и даже акватории. Вследствие этого алгоритм начал массово ошибаться и наказывать невиновных, и в какой-то момент у нас просто не осталось другого выбора, кроме как полностью отключить его в десятках городов.
В этой статье я хочу рассказать о том, как мы искали выход из сложившейся ситуации. О гипотезах, которые не сработали, и о простом, но изящном решении, которое мы всё-таки в конце концов нашли.
Но прежде чем мы погрузимся в борьбу с аномалиями, давайте разберёмся, как наш алгоритм работал изначально — в мире, где координатам ещё можно было доверять.
Как мы находили нарушения скорости до эпохи спуфинга
Первая мысль, которая приходит в голову, — почему бы просто не смотреть на скорость из навигатора? Уверена, вы каждый день видите это число на экране, если ездите на машине. Но, к сожалению, этот подход не работает. Во-первых, при выезде из туннеля, когда GPS только находит спутники, навигатор может на мгновение показать огромную, нереалистичную скорость. Во-вторых, есть и менее очевидная причина — чисто техническая. Раньше в наших данных скорость могла храниться как в метрах в секунду, так и в километрах в час. И эти величины порой неотличимы друг от друга. Опираться на такие данные для применения санкций нельзя.
Поэтому мы решили пойти другим путём и опираться на сырые GPS-координаты водителей. Наш алгоритм состоял из нескольких ключевых шагов.

Сначала весь трек поездки мы разбиваем на 30-секундные интервалы. Дальше — этап фильтрации. Мы отбрасываем те интервалы, по которым у нас слишком мало данных, и те, где водитель за полминуты якобы проехал сто километров — таких машин, насколько мне известно, пока не изобрели.
Для каждого «чистого» интервала мы вычисляем две метрики: среднюю скорость движения и самое нестрогое скоростное ограничение на этом отрезке. Что значит «нестрогое»? Представьте, что за 30 секунд водитель сначала ехал по двору с ограничением 20 км/ч, а потом выехал на шоссе, где лимит 60 км/ч. В этом случае для всего интервала мы возьмём значение 60. Это защищает водителей от случайных и несправедливых срабатываний.
Этот алгоритм изначально был нацелен не на мгновенные всплески скорости, а на выявление длительных, осознанных нарушений. Поэтому его условие срабатывания — четыре последовательных 30-секундных интервала, где водитель стабильно превышает один и тот же скоростной лимит. Такой подход помогает находить именно затяжные превышения скорости на трассах и крупных шоссе. Короткие же и резкие манёвры — например, опасные ускорения — выявляет другой наш алгоритм, основанный на данных с акселерометра. Конечно, перед отправкой таких данных мы лишний раз проверяем, что в этот момент водитель действительно находится на заказе. Если все условия сходятся, данные уходят в специальную систему, которая применяет к водителю меры: от простого предупреждения до временного отстранения от сервиса.
Эта система хорошо справлялась и отлавливала длительные нарушения. Но всегда находятся водители, которые пытаются быть хитрее. Что они делали? Отключают GPS или переводят телефон в авиарежим, и мы просто перестаём видеть их координаты.

Мы научились бороться и с этим. Алгоритм находил в треке «дыры» — интервалы от трёх до шести минут, в которых мы не получали от водителя никаких координат. Дальше мы строили минимальный по расстоянию маршрут между двумя точками — последней, где мы видели водителя, и первой, где он снова появился. А потом считали, можно ли было проехать этот путь за время пропажи, не нарушая скоростной режим. Если нет — мы фиксировали нарушение и добавляли его к уже найденным.
Казалось, мы закрыли все основные сценарии. Алгоритм уверенно находил и отчаянных гонщиков, которые не прятались, и тех, кто пытался скрыть свои треки. Система работала очень хорошо.
GPS-треки сошли с ума
В 2022 году в силу целого ряда причин привычная нам реальность изменилась. В данных начали появляться треки, которые наша система не могла и не должна была интерпретировать. Это был GPS-спуфинг — когда оригинальные геолокационные данные подменяют на другие. Проще говоря, телефон водителя физически находился в одной точке города, а его GPS-координаты передавались совершенно из другого места.

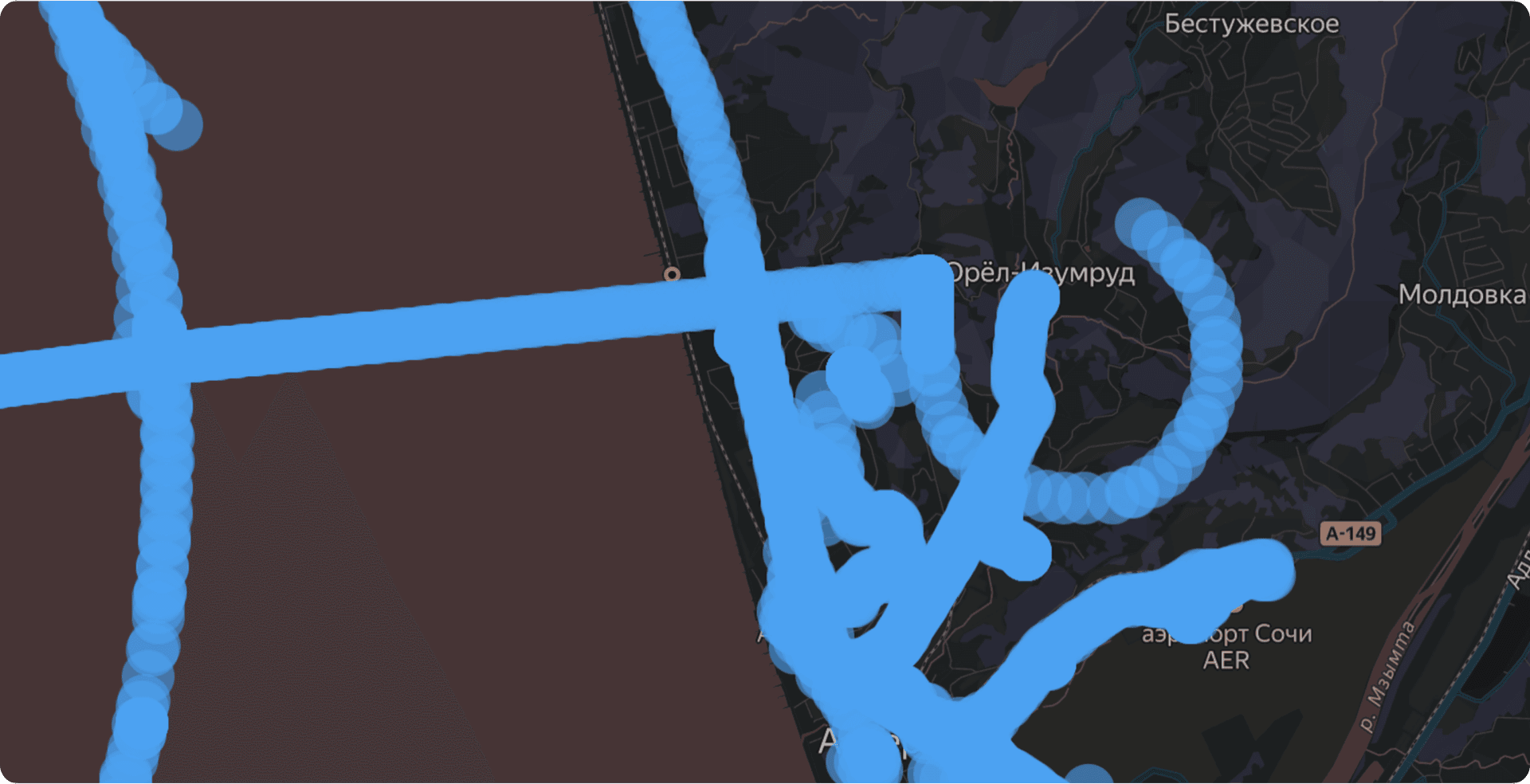
То, что мы видели на своих картах, напоминало кадры из фильма «Знаки» с Мэлом Гибсоном. Вместо логичных маршрутов по улицам — огромные, почти идеальные круги, хаотичные линии и зигзаги, часто расположенные прямо в море или посреди поля. С точки зрения нашего алгоритма, который оперирует расстоянием и временем, это выглядело как телепортация. Машина за доли секунды перемещалась на десятки километров, и система логично фиксировала чудовищное превышение скорости.
Об архитектуре систем, работающих с физическими маршрутами, читайте в статье «Что под капотом логистики Маркета: взгляд на архитектуру оркестрации»
Конечно же, мы столкнулись с огромным количеством ложных срабатываний. Система начала без разбора наказывать порядочных водителей, которые просто оказались не в том месте и не в то время, попав в зону действия глушилок. Естественно, это вызвало шквал обращений в службу поддержки, которой тоже пришлось нелегко.
Сначала мы пытались действовать точечно. В 2022 году последовательно отключали алгоритм в крупных городах: сначала в Москве, потом в Санкт-Петербурге и так далее. Но это практически не помогало. К началу 2024 года мы оказались в ситуации, когда система детекции нарушений не работала уже в 50 с лишним городах.
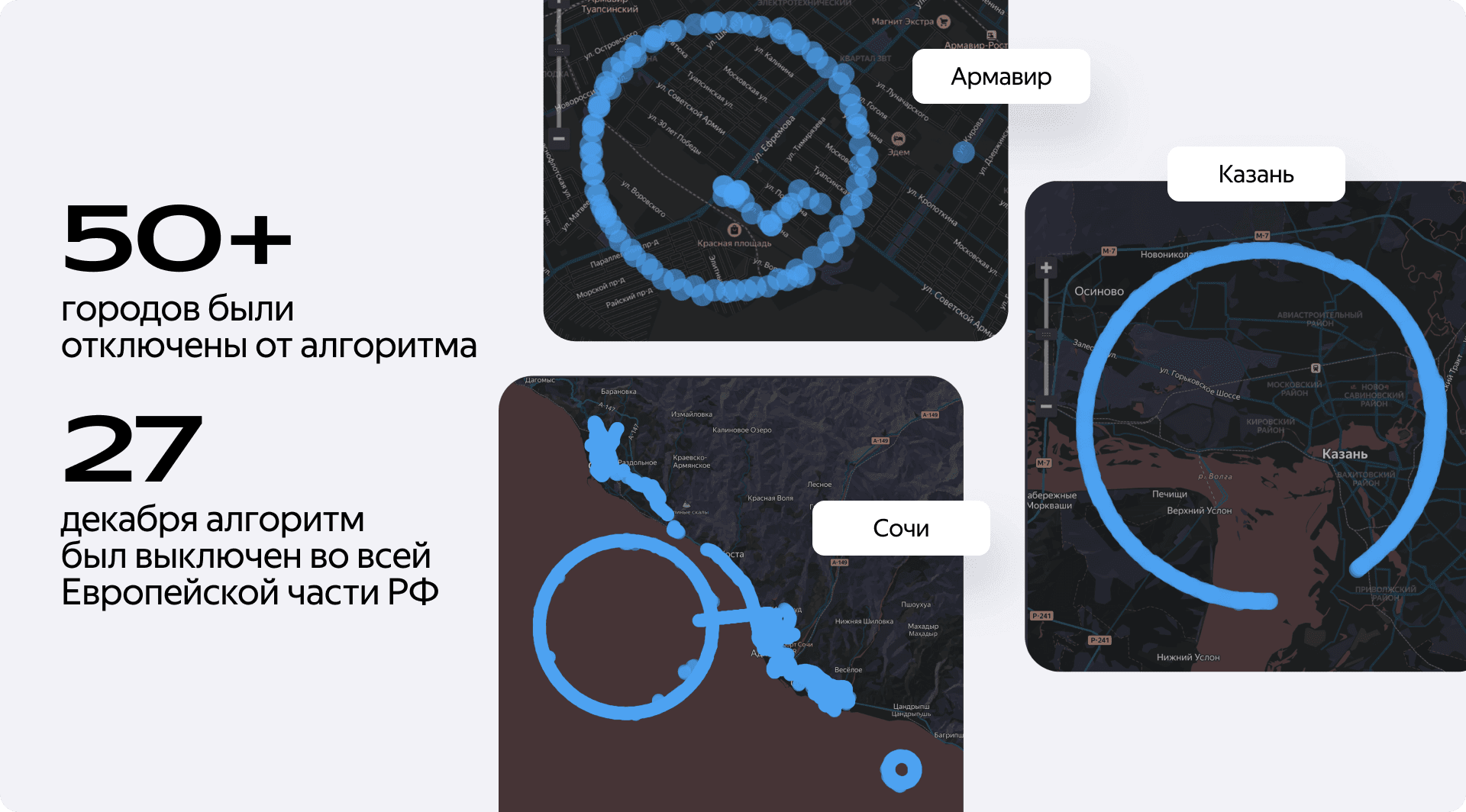
Финальной точкой для нас стало 27 декабря, когда мы были вынуждены полностью отключить алгоритм во всей европейской части России. Стало понятно, что этот инструмент в новых условиях попросту оказался бесполезен. И хотя жалобы от несправедливо наказанных водителей прекратились, сама проблема превышения скорости, конечно, никуда не делась. Нужно было срочно искать решение.
Путь проб и ошибок в мире зашумлённых данных
Итак, перед нами стояла задача — воскресить алгоритм, научив его работать в новых условиях и отличать реальные данные от шума, который создавал спуфинг. Мы начали с анализа проблемы, чтобы понять, где именно система даёт сбой.
Шаг 1. Ищем источник жалоб
Напомню, что наш алгоритм состоял из двух частей: первая работала со средними скоростями на интервалах, вторая — восстанавливала маршрут в разрывах трека. Мы решили посмотреть, какая из этих частей генерирует больше всего ложных срабатываний. Статистика показала, что около 46% всех жалоб от водителей приходилось на нарушения, найденные с помощью восстановления маршрута. При этом сам этот метод детектировал всего 4% от общего числа нарушений.
Почему так происходило? Дело в том, что данные, которые мы получали, уже проходили через первичную верификацию в других командах. Эти команды успешно отфильтровывали часть спуфинга, в результате чего, в треках появлялись уже упомянутые «дыры». А наш алгоритм, пытаясь их восстановить, опирался на крайние точки — последнюю хорошую до «дыры» и первую после. В условиях спуфинга эти крайние точки часто сами оказывались ложными. В итоге мы строили некорректный маршрут по заспуфленным координатам и несправедливо наказывали водителя.
Очевидно, что в текущих реалиях на эту часть алгоритма полагаться нельзя. От неё мы отказались.
Шаг 2. Привлекаем данные пользователей
Отключение проблемного модуля помогло, но не решило проблему — у нас всё ещё оставалось больше половины жалоб. Мы стали думать, какие ещё данные внутри сервиса могут помочь нам фильтровать координаты. И обратили внимание на пользователей.
Идея была такой: если в какой-то части города GPS работает некорректно, то это должно отражаться не только на водителях, но и на пассажирах. Например, пользователь вызывает такси, находясь в одной точке, а его геолокация определяется совершенно в другой. Мы решили посчитать такие случаи.
Для этого мы разбили карту на небольшие квадраты — квадкеи — площадью примерно 1 км². Для каждого такого квадрата мы посчитали долю заспуфленных заказов, где местоположение пользователя в момент вызова значительно отличалось от реальной точки подачи такси. Если эта доля превышала 30%, мы считали такой квадрат плохим и переставали доверять любым геолокационным данным из него.

И такой подход дал вполне заметный результат. На примере Казани можно было видеть, как четыре пятых огромного круга спуфинга просто исчезли после такой фильтрации. В итоге, объединив отключение восстановления маршрута и фильтрацию по квадкеям, мы смогли уменьшить количество жалоб от водителей в 14 раз. Однако, фильтрации были настолько сильными, что мы детектировали лишь треть нарушений от тех, что обнаруживали до 2022 года. Это было слишком мало.
Шаг 3. Исследуем готовые технологии
Когда стало понятно, что полумерами тут не обойтись, мы пошли искать глобальные решения — как в интернете, так и внутри Яндекса.
Первой на очереди была технология LBS (Location-Based Service). Её суть — определять местоположение не по спутникам, а по видимым точкам Wi-Fi и вышкам сотовой связи. Если телефон видит одну точку Wi-Fi, значит, он находится в её зоне покрытия. Если несколько — то в области их пересечения. Точность, конечно, ниже, чем у GPS, но зато нет спуфинга.
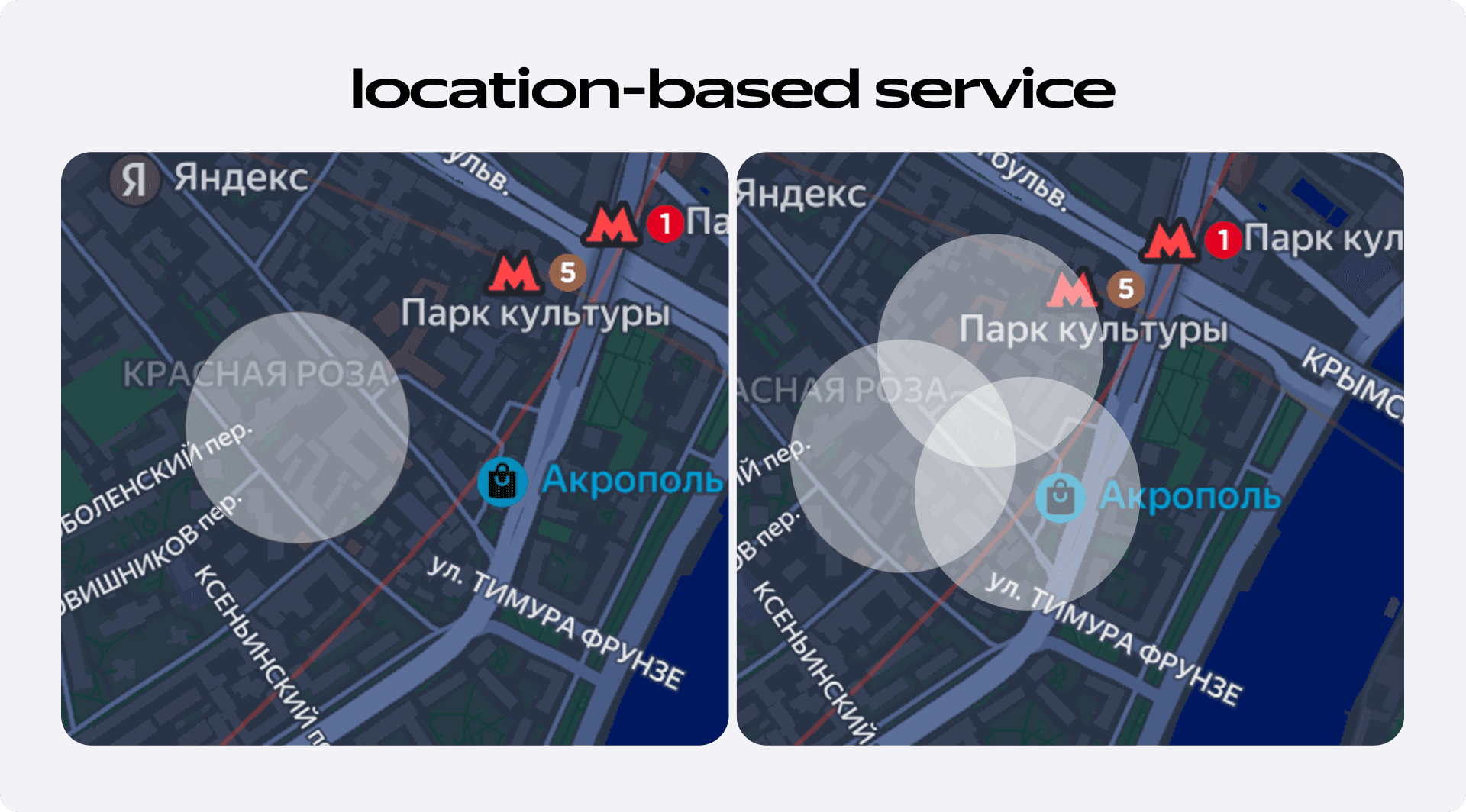
Данные, полученные чисто из LBS очень зашумлённые, поэтому с ними мы всегда использовали фильтр Калмана. Это математический алгоритм для работы с динамическими системами, который отлично справляется с расшумлением данных. Он предсказывает следующее положение объекта, получает реальное измерение, оценивает погрешность обоих и вычисляет итоговое, скорректированное значение. В центре Москвы этот метод работает прекрасно. Но есть одна проблема: чаще всего нарушают скоростной режим не в центре города, где полно перекрёстков, светофоров и лежачих полицейских, а на МКАД или загородных шоссе. А в таких местах, как правило, точек Wi-Fi либо очень мало, либо нет совсем. Это делало использование LBS и фильтра Калмана в нашем случае практически бесполезным.
Следующая идея была уже гораздо интереснее. Раз спуфинг чаще всего выглядит как круги, почему бы просто не находить точки, лежащие на окружности, и не отбрасывать их? Но и тут всё оказалось сложнее. Во-первых, аномальные треки — это не только круги. Часто они выглядят как чупа-чупс — круг с палочкой, — а также бывают в форме отрезков, линий и зигзагов. Кто-то даже утверждал, что видел ленты Мёбиуса и бутылки Клейна, но в это я уже верю с трудом. Во-вторых, вырезая все круги без разбора, мы рисковали случайно отфильтровать поездки по Садовому кольцу или ТТК.
Мы также проанализировали и другие доступные нам данные. Например, у каждой координаты есть параметр точности (accuracy). Но оказалось, что распределение точности для обычных и заспуфленных координат абсолютно одинаковое. Спуфинг подменяет широту и долготу, но сохраняет мета-информацию. Ещё была гипотеза, что поддельные координаты могут иметь неестественную высоту. Но и тут особого успеха не было. Большинство водителей работают с телефонами не самого высокого ценового сегмента, которые не очень точно определяют высоту. К тому же у нас недостаточно данных о рельефе местности, чтобы понять, находится ли точка в воздухе.
А почему не ML?
Уверена, у многих к этому моменту уже возник этот закономерный вопрос. Ответ состоит из нескольких частей. Во-первых, для обучения модели потребовалось бы разметить гигантский объём данных. Мы получаем от каждого автомобиля на линии примерно одну координату в секунду, а таких автомобилей в европейском регионе — больше миллиона. Во-вторых, что самое главное, спуфинг-трек на небольшом участке может быть очень похож на обычное движение автомобиля. Несколько команд в Яндексе занимаются обучением ML для определения спуфинга, и точность их моделей постоянно увеличивается. Но на тот момент, когда нам нужно было принимать решения, этой точности было ещё недостаточно.
И тогда мы придумали кое-что получше.
Простая идея которая всё исправила
Иногда самое эффективное решение лежит прямо перед тобой, просто нужно посмотреть на проблему под другим углом. На идею, которая в итоге всё исправила, меня навела одна из карт со спуфинг-треками: водители ездили где-то в море, очень далеко от дорог. И в голову пришла очень интересная мысль.
Давайте вернёмся на шаг назад. Как наш алгоритм вообще узнаёт скоростное ограничение для конкретного участка? Он использует дорожный граф. Это граф, в котором каждое ребро представляет собой участок дороги. Для каждого ребра у нас хранится масса полезной информации: длина, количество полос, скоростной лимит и, что самое важное, — тип дороги.
Теперь зададимся вопросом: а где чаще всего происходят длительные нарушения скорости, которые мы ищем? Точно не внутри жилого квартала, где полно светофоров, лежачих полицейских и пешеходных переходов. Длительно превышают скорость обычно на крупных дорогах — шоссе, проспектах, магистралях.
А где проходят треки спуфинга? Где угодно, но только не по реальным дорогам.
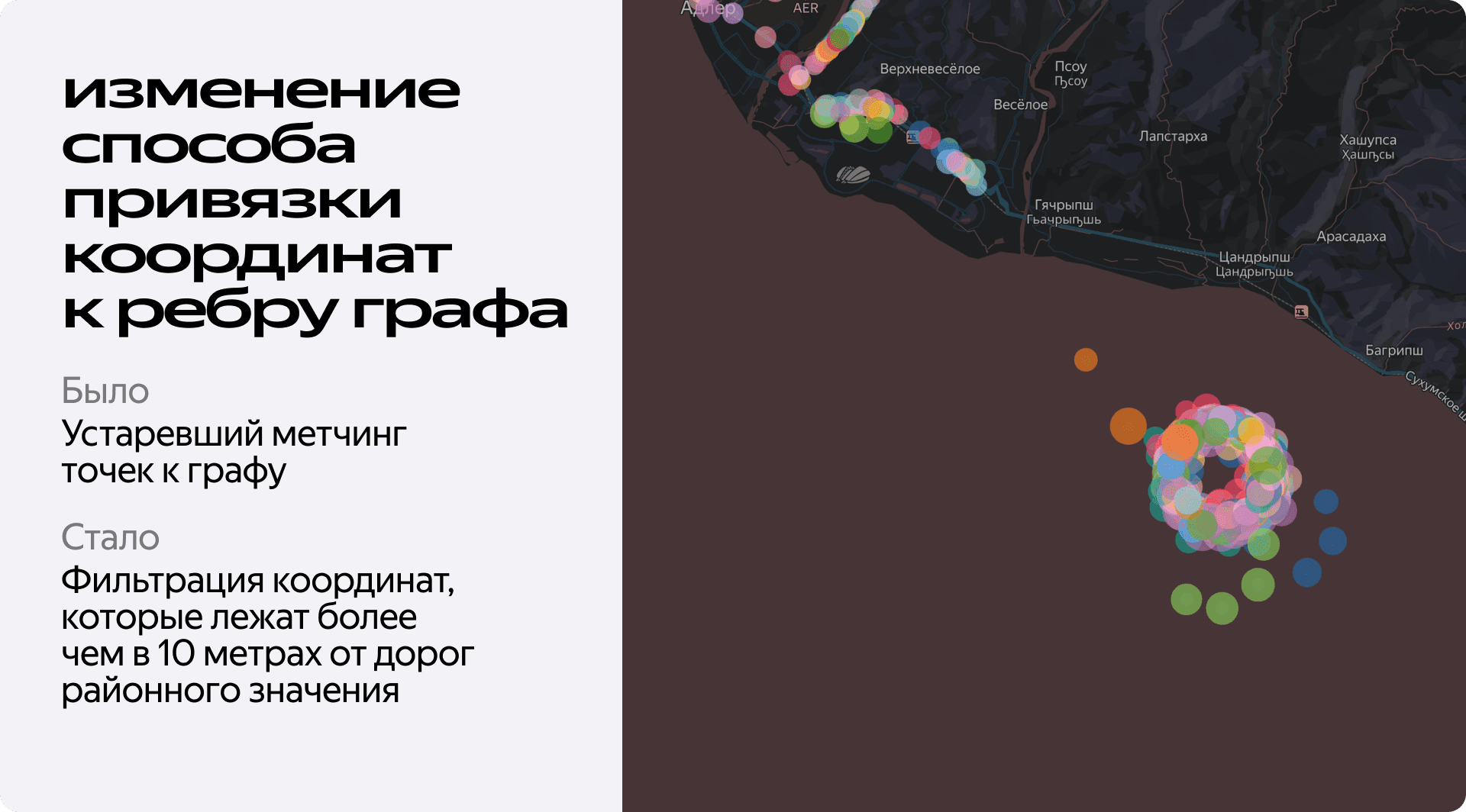
Именно в этом простом наблюдении и заключалось решение. Вместо того чтобы пытаться отличить плохую точку от хорошей по её внутренним характеристикам (точности, высоте), мы решили проверять, а может ли вообще автомобиль физически находиться в этой точке.
Новый подход — это предельно простая фильтрация. Мы решили доверять только тем координатам, которые находятся не более чем в десяти метрах от дорог районного значения и больше, таких как шоссе, автострады и так далее. Всё, что дальше, — отбрасывается.
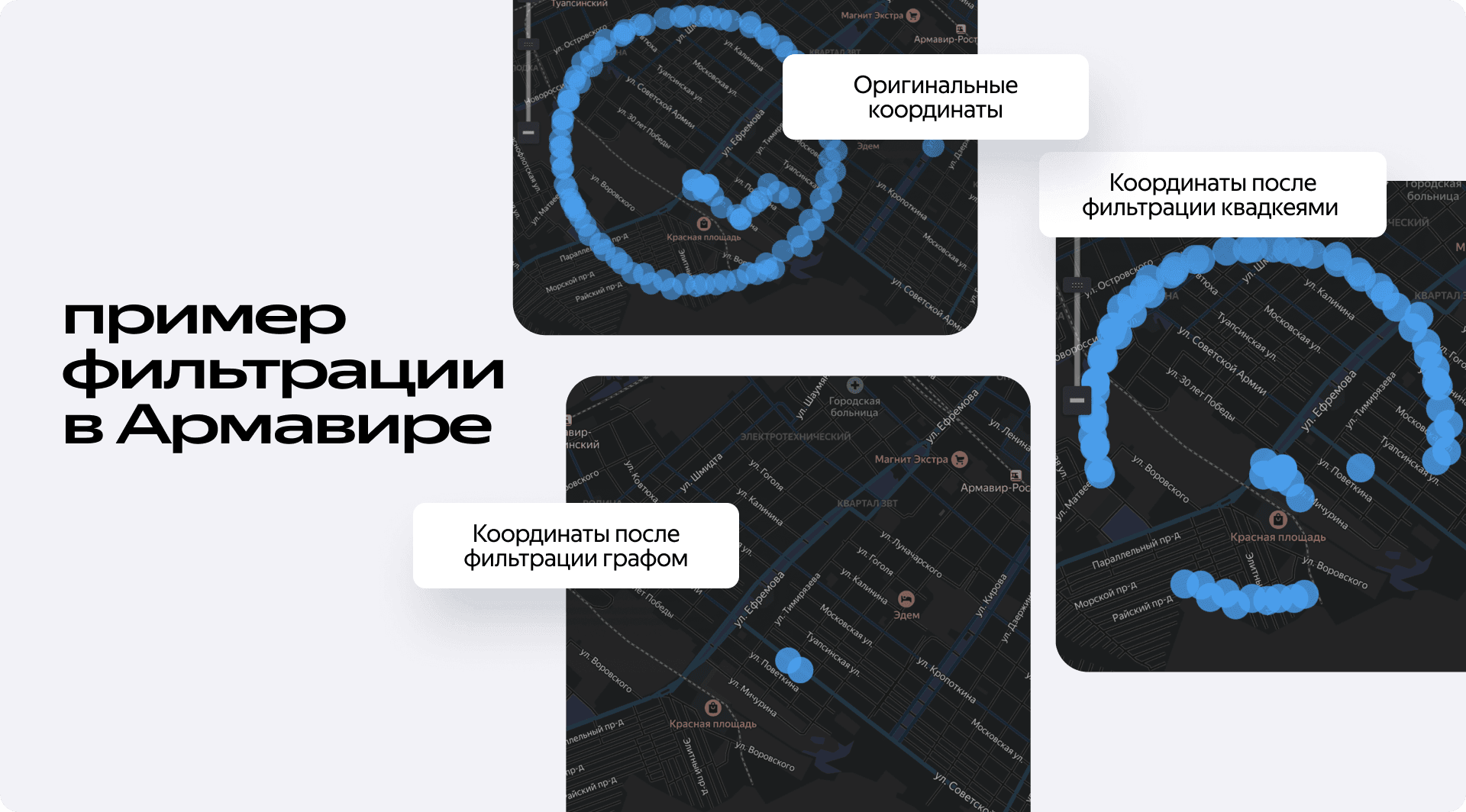
Эффект превзошёл все ожидания. На примере Армавира это было видно особенно наглядно. Вот трек случайного водителя: огромный круг (спуфинг) и несколько точек в центре (скорее всего, его реальное местоположение). Наш новый фильтр полностью убрал всю окружность, оставив только те несколько точек, которые действительно находились на дорогах.
В Казани, где круг спуфинга был гораздо плотнее, произошло то же самое. После фильтрации графом от него осталось меньше десяти разрозненных точек. Для нашего основного алгоритма это просто шум — он не найдёт между ними четыре последовательных интервала с нарушением и просто их проигнорирует.
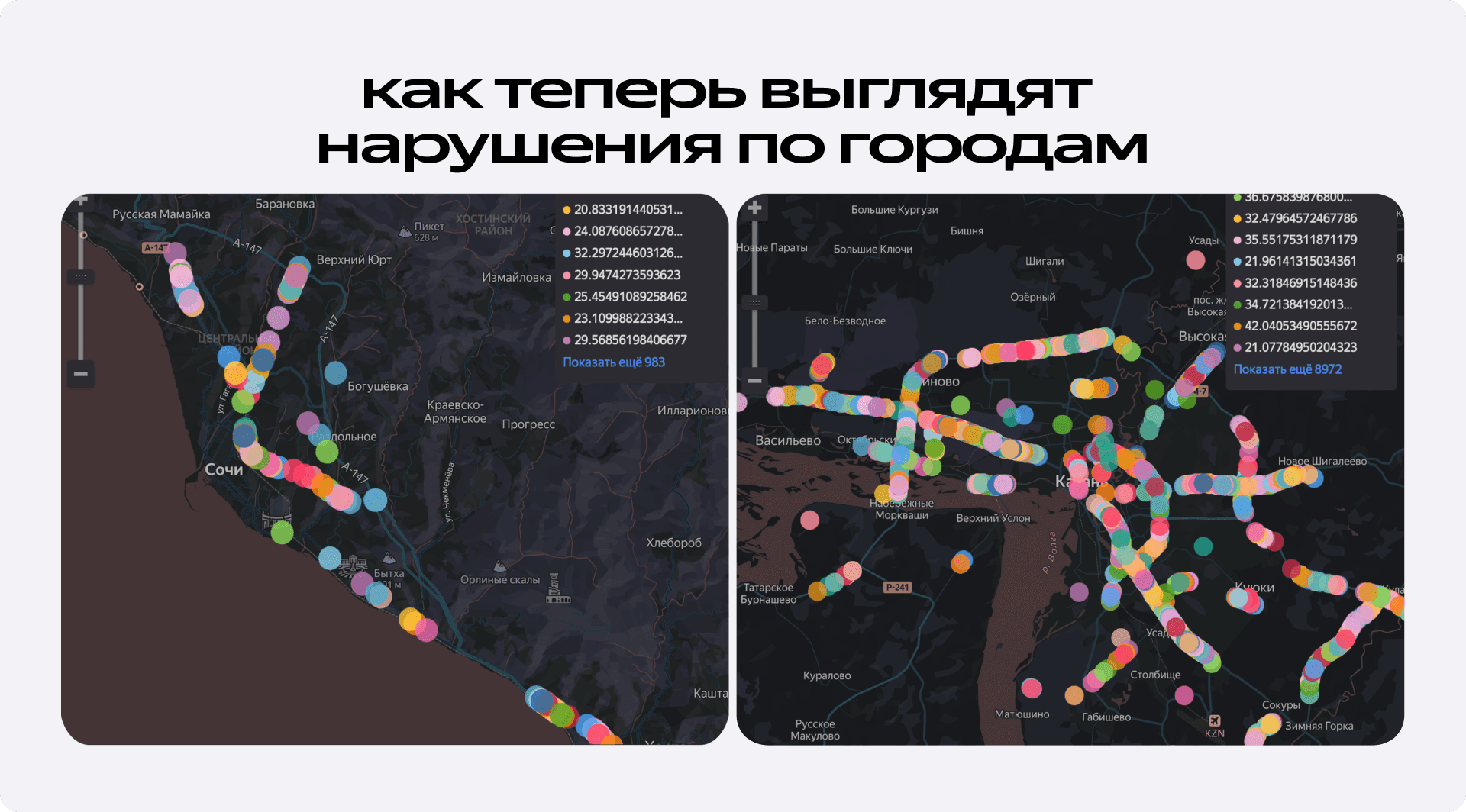
В результате мы перестали видеть на картах те самые огромные круги. Все зафиксированные нарушения оказались приземлены на крупные шоссе и большие городские артерии — именно туда, где они и должны быть. Мы научили систему игнорировать подменные треки и снова видеть реальность.
Чему нас научила эта история
Так чего же мы добились с помощью этого фильтра? Цифры говорят сами за себя: мы смогли восстановить наш алгоритм на 87%. То есть сейчас мы находим почти девять из десяти нарушений по сравнению с тем, что было до 2022 года. Это позволяет нам воздействовать примерно на 0,4% активных водителей в месяц — небольшой процент, но он напрямую влияет на безопасность тысяч поездок.
Конечно, оставшиеся 13% — это в основном нарушения на небольших улицах внутри районов или нарушения, на которых точность приходящих координат была слишком низкая. Такие ситуации наш новый фильтр, к сожалению, пока игнорирует. Чтобы научиться детектировать абсолютно всё, нужно придумать и реализовать метод, который сможет со стопроцентной уверенностью сказать: вот эта точка — спуфинг, а эта — нет. Такая технология у нас уже есть, и совсем скоро мы займёмся её тестированием в нашем алгоритме.
Вся эта история в целом научила нас нескольким важным вещам. Во-первых, не все задачи требуют сложных нейросетей. Иногда красивое и изящное решение лежит в глубоком понимании специфики самих данных и предметной области. Во-вторых, стало очевидно, что универсального метода борьбы со спуфингом, похоже, не существует. Решение всегда будет сильно зависеть от специфики задач и целей.
И наконец, главный вывод. В самом начале я сказала, что моя команда влияет на мир с помощью технологий. Но здесь мы столкнулись с обратной ситуацией — мир повлиял на наши технологии, заставив нас полностью их переосмыслить и переделать.
Спасибо, что дочитали до конца. Пожалуйста, всегда пристёгивайтесь и соблюдайте скоростной режим. А мы со своей стороны уже делаем всё возможное, чтобы ваша поездка в такси была максимально безопасной и комфортной.



