
Привет! Меня зовут Ярослав Смирнов, я старший разработчик в iOS-SDK Яндекс Доставки. Я начинал писать ещё под первые iPhone и помню, что такое ручное управление памятью и отсутствие многозадачности. В нашей команде мы прошли тот же путь со всеми стадиями принятия Swift Concurrency, что и многие разработчики из комментариев на Stack Overflow и Reddit. Но в один момент мы собрались с силами и всё-таки адаптировали всю нашу кодовую базу для работы с новой технологией.
Сегодня я хочу поделиться самыми сложными и неочевидными моментами этой миграции. Мы поговорим о неизолированном deinit, вызовах из неадаптированного кода и работе с отложенными операциями — всё это на реальных примерах из нашего SDK. Цель этой статьи — не просто показать, какие классные решения мы придумали, а объяснить их логику, чтобы сэкономить вам время и сберечь нервы.
Почему мы решились на эти обновления?

Прежде чем переходить к описанию самого процесса, давайте коротко отвечу на вопрос, зачем мы вообще всё это начинали и стоило ли оно того в итоге? Несмотря на первоначальные трудности, мы в Яндекс Доставке верим, что structured concurrency — это будущее многопоточной разработки на платформах Apple. Для себя мы выделили четыре весомых аргумента, которые убедили нас, что игра стоит свеч.
- Контроль над data-races на этапе компиляции. Это фундаментальное изменение. Вместо того чтобы ловить трудновоспроизводимые крэши в рантайме, мы получаем союзника в лице компилятора. Он заранее подсвечивает места, где происходит небезопасное обращение к мутабельному состоянию, тем самым ловко превращая потенциальную ошибку в продакшене в поправимую ошибку сборки. А это, согласитесь, уже немало.
- Прозрачность контекста выполнения. С async/await и акторами в большинстве случаев вы можете с уверенностью сказать, где именно будет исполняться ваш код — на главном потоке или в бэкграунде. Эта предсказуемость избавляет от целого класса ошибок, связанных с неявным переключением очередей, и делает логику приложения более прямолинейной.
- Единая система отмены задач. Нам больше не нужно изобретать кастомные токены или пробрасывать флаги отмены через всё приложение. Встроенный API Task предоставляет унифицированный и надёжный механизм, который работает из коробки для всех асинхронных операций.
- Синхронная семантика асинхронного кода. Возможность писать асинхронный код так, будто он выполняется последовательно, — это огромный шаг вперёд. Вместо монструозных лестниц из вложенных колбэков или сложных конструкций с Promise и flatMap мы можем просто написать цикл for с await внутри. Код становится чище, понятнее и его гораздо проще поддерживать.
Шпаргалка по разметке типов
Чтобы миграция не превратилась в бесконечные споры на код-ревью, мы выработали простой алгоритм. Это наша внутренняя шпаргалка, которая помогает быстро принимать решения о разметке любого типа. Она состоит всего из двух ключевых вопросов.
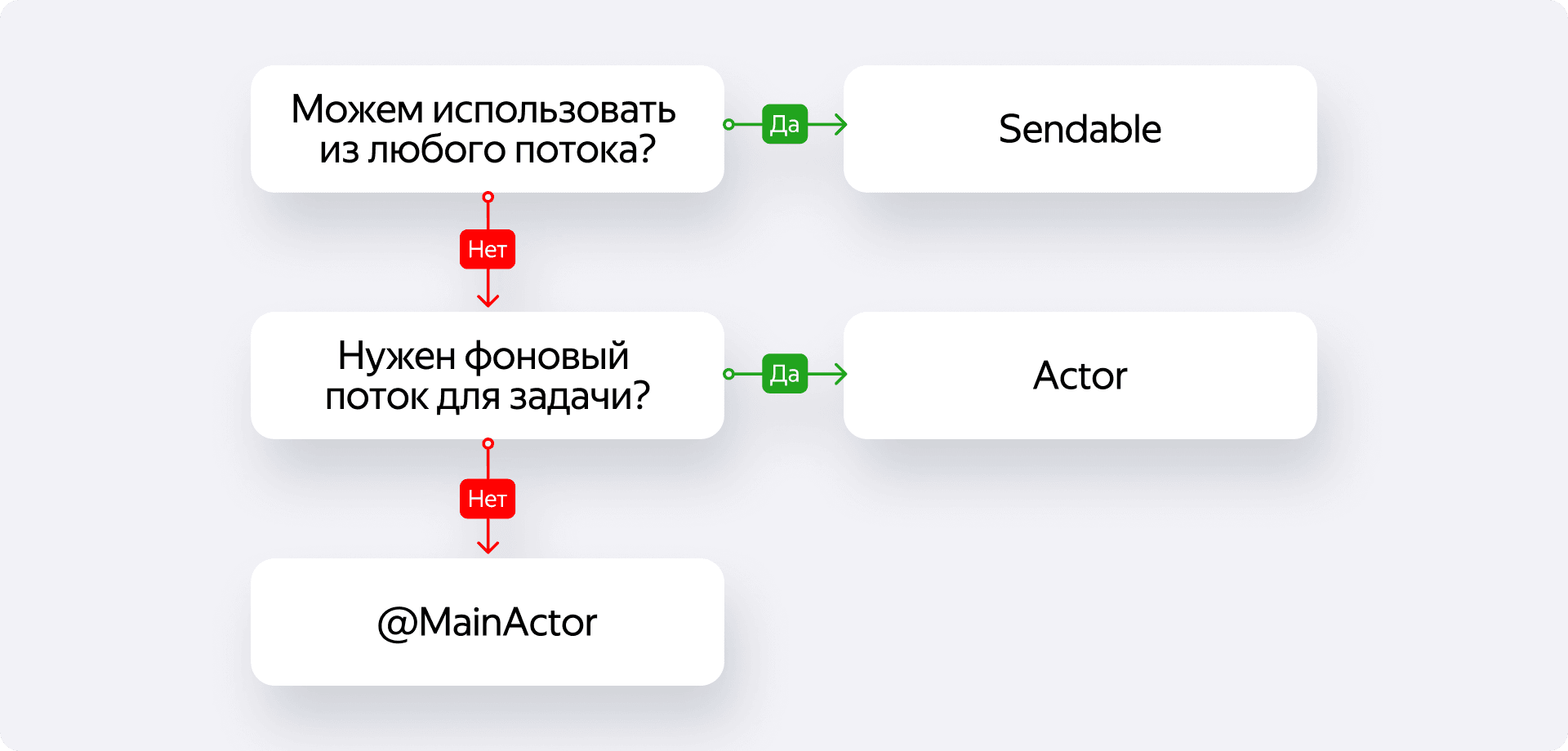
Шаг 1: можно ли использовать тип из любого потока?
Это первый и главный вопрос, который мы себе задаём. Нужно ли нам работать с этим типом одновременно из разных concurrency-домейнов?
Если ответ «да» — используем Sendable.
Sendable — это протокол-маркер. У него нет никаких требований, он просто говорит компилятору: «Этот тип можно безопасно передавать между потоками». В первую очередь мы используем его для:
- Простых моделей данных. Немутабельные структуры, которые описывают сущности.
- DTO-структур. Объекты для маппинга JSON-ответов от сервера.
- Фабрик и билдеров без внутреннего состояния. Типы, которые создают другие объекты, но сами не хранят изменяемых данных.
Если тип соответствует этим критериям, помечаем его Sendable и двигаемся дальше.
Шаг 2: если тип не Sendable, нужен ли ему фоновый поток?
Здесь важно озвучить главный принцип нашей миграции: мы не добавляем многопоточность и асинхронность там, где её не было раньше. Наша цель — использовать Swift Concurrency для более удобной и безопасной реализации уже существующих потребностей, а не создавать новые просто потому, что технология это позволяет.
Итак, если наш тип имеет внутреннее состояние и не предназначен для свободного перемещения между потоками, мы задаём следующий вопрос: достаточно ли для его задач главного потока или работа должна выполняться в бэкграунде?
- Если фоновый поток не нужен — используем @MainActor.
@MainActor — это глобальный актор, который гарантирует, что весь код внутри типа будет выполняться на главном потоке. Поскольку мобильное приложение в первую очередь работает с UI, реагирует на действия пользователя и отображает данные, около 80% нашего кода так или иначе связано с main thread. Поэтому @MainActor идеально подходит для большинства объектов бизнес-логики, не говоря уже о компонентах View-слоя.
- Если фоновый поток необходим — используем кастомный actor.
Если основная задача объекта — выполнение работы в бэкграунде, мы создаём для него кастомный actor. Актор — это специальный тип, который изолирует свой мутабельный state и выполняет свои методы в собственном приватном контексте. Любое обращение к нему извне по умолчанию будет асинхронным.
Мы используем кастомные акторы в двух случаях:
- Когда объект по своей природе предназначен для фоновой работы. Например, PostcardThumbnailProvider, который генерирует превью для открыток.
- Когда к коду объекта всегда обращаются из бэкграундного потока. Отличный пример — RetryPolicy для сетевых запросов, который вызывается из контекста URLSession.
actor PostcardThumbnailProvider {
func getThumbnail(for postcard: Postcard) -> UIImage {
...
}
}
actor RetryPolicy {
func nextRetryAttempt(httpResponse: HTTPURLResponse) -> Bool {
...
}
func nextRetryAttempt(error: Error) -> Bool {
...
}
}
Такой алгоритм покрывает подавляющее большинство наших сценариев. Он и есть та самая основа, от которой мы отталкивались при адаптации всей своей кодовой базы.
Три самые коварные проблемы миграции
Вооружившись нашей шпаргалкой, мы начали адаптацию. И почти сразу столкнулись с ситуациями, где простые и понятные на первый взгляд правила просто не работали. В этой части статьи я расскажу о трёх самых частых и коварных проблемах, с которыми нам пришлось разобраться.
Проблема №1: нелогичный неизолированный deinit
Это, пожалуй, самая назойливая проблема, с которой мы столкнулись. Давайте разберём её на конкретном примере, который связан с загрузкой заказов в приложении Яндекс Go.
Представим упрощённую архитектуру. У нас есть ViewStore, который готовит данные для UI, и Provider, который эти данные загружает с сервера.
@MainActor
class ViewStore {
let provider: Providing
// ...
deinit {
provider.stopPolling()
provider.removeObserver(self)
}
}
@MainActor
protocol Providing {
// ...
}
Согласно нашему алгоритму, оба типа помечены @MainActor, так как они непосредственно связаны с UI. Но как только мы это делаем, компилятор начинает ругаться на код в deinit:
Call to main actor-isolated instance method 'stopPolling()' in a synchronous nonisolated context
Проблема в том, что метод deinit в акторах не изолирован. Он может быть вызван на любом потоке. Казалось бы, странное решение, почему разработчики языка сделали всё именно так?

Всё дело в механизме деинициализации. Когда счётчик ссылок на объект обнуляется, рантайм вызывает swift_release, затем синхронно выполняется deinit, и сразу после этого освобождается память. Ключевое слово здесь — синхронно. Последняя ссылка на ваш объект может исчезнуть на любом потоке. Если бы deinit нужно было принудительно выполнять в контексте своего актора, этот вызов пришлось бы делать асинхронно. А это нарушило бы базовый контракт деинициализации, принятый как в Swift, так и в Objective-C.
Итак, deinit может прийти с любого потока. Что с этим делать? Мы нашли три разных подхода в зависимости от ситуации.
Решение А: простое, для отложенных действий — Task
Рассмотрим первый вызов — provider.stopPolling(). Если нам не критично, чтобы остановка поллинга произошла строго синхронно с деинициализацией, мы можем просто обернуть вызов в асинхронную задачу и перевести его в нужный контекст.
deinit {
Task { @MainActor [provider] in
provider.stopPolling()
}
provider.removeObserver(self)
}
Просто, эффективно, и в большинстве случаев этого достаточно. Но этот трюк не сработает со второй строкой.
Решение Б: когда нужно передать self — «нет вызова, нет проблем»
В вызове provider.removeObserver(self) мы передаём ссылку на сам объект. Если обернуть его в Task, мы попытаемся использовать self уже после того, как deinit завершится. Так делать категорически нельзя.
Когда deinit запускается, у счётчика ссылок уже выставлен флаг isDeiniting. Рантайм перестаёт учитывать новые сильные ссылки, и попытка воскресить объект ни к чему не приведёт — сразу за deinit последует освобождение памяти, и мы получим доступ к мусору.
Как же быть? Иногда лучший способ решить проблему — это её избежать. Давайте посмотрим, как устроен ObserversSet — класс-коллекция, который наш Provider использует для хранения обзёрверов.
class ObserversSet<T> {
var observers = NSHashTable<AnyObject>.weakObjects()
// ...
}
Хранилищем для обзёрверов служит NSHashTable, инициализированный для хранения слабых ссылок. И это ключ к решению. После deinit память не освобождается мгновенно, если на объект есть слабые ссылки. Swift позаботится о том, чтобы эти ссылки не указывали на мусор. Это происходит с помощью очистки SideTable — места хранения слабых ссылок на объект. Важно то, что операции чтения слабой ссылки и уничтожения объекта взаимно потокобезопасны. Это значит, что если мы попытаемся прочитать слабую ссылку в момент деинициализации, мы либо получим nil, либо валидный объект, но никогда не получим крэш.

Поэтому в данном конкретном случае вызов removeObserver(self) можно просто удалить. NSHashTable сам позаботится об очистке мёртвой ссылки.
Решение В: сложное, но универсальное — выводим метод из изоляции
Хорошо, а что, если вызов в deinit всё-таки необходим? Представим, что наш Provider устроен так, что он запускает поллинг сети при появлении первого подписчика и останавливает его, когда уходит последний. Если мы не отпишемся, приложение продолжит генерировать ненужные сетевые запросы.
Удалить вызов нельзя. Перенести в Task тоже. Что остаётся?
Раз deinit может вызываться с разных потоков, давайте поступим с компилятором честно и признаем, что метод removeObserver тоже должен быть доступен с любого потока. Для этого помечаем его в протоколе как nonisolated.
@MainActor
protocol Providing {
nonisolated func addObserver(_ observer: ProviderObserver)
nonisolated func removeObserver(_ observer: ProviderObserver)
}
Теперь ошибка в deinit ушла, но появилась в реализации Provider. Компилятор справедливо ругается, что nonisolated-метод пытается изменить observers — свойство, изолированное на @MainActor.

Чтобы это исправить, нам придётся вернуться к истокам и вспомнить про старую добрую многопоточность. Мы превратим наш ObserversSet в потокобезопасный класс, используя NSLock.
- Делаем коллекцию @unchecked Sendable. Мы говорим компилятору, что берём потокобезопасность на себя.
- Добавляем NSLock. Создаём обычный мьютекс.
- Оборачиваем мутирующие операции в
lock.withLock { ... }. Это защитит хранилище от одновременного доступа.
class ObserversSet<Observer>: @unchecked Sendable {
var observers: NSHashTable<AnyObject> = .weakObjects()
let lock = NSLock()
func add(_ observer: Observer) {
lock.withLock {
observers.add(observer as AnyObject)
}
}
func remove(_ observer: Observer) {
lock.withLock {
observers.remove(observer as AnyObject)
}
}
}
Теперь наш Provider может безопасно работать с ObserversSet из nonisolated-метода.
Казалось бы, всё? Почти. Компилятор выдаёт последнюю ошибку: Cannot access property 'provider' with a non-sendable type 'any Providing' from nonisolated deinit. Проблема в том, что пометив протокол @MainActor, мы гарантировали изоляцию только для его методов. Компилятор не знает, как реализован сам тип, который подчиняется протоколу, и не считает его потокобезопасным.
Чтобы это исправить, мы должны добавить констрейнт Sendable к самому протоколу. Так мы сообщим компилятору, что любой тип, реализующий Providing, будет потокобезопасным для передачи между домейнами. После этого все ошибки наконец уходят.
Проблема №2: обращение к актору из неадаптированного кода
Наше SDK — не отдельное приложение, оно встраивается в другие, и главный потребитель — Яндекс Go. Это огромный проект, и миграция на Swift Concurrency в нём идёт постепенно. И неизбежно возникают ситуации, когда наш новый, полностью адаптированный код должен взаимодействовать со старым, неадаптированным.
Классический пример — аналитика. Мы собираем метрики по действиям пользователей, и для этого используем AppMetrica. В каждое событие добавляется стандартный набор параметров, один из которых — статус текущего заказа. Эти данные, конечно же, берёт наше SDK.
Проблема в том, что события в метрику могут отправляться откуда угодно:
- С главного потока — например, при тапе на кнопку или скролле экрана.
- С фонового потока — например, при обработке сетевой ошибки.
А наш объект Order, хранящий статус, изолирован на главном акторе.
@MainActor
class Order {
var status: String
}
struct Reporter {
let order: DeliveryOrder
func report() -> String {
order.status
}
}
Компилятор тут же выдаёт ошибку: Main actor-isolated property 'status' can not be referenced from a nonisolated context. И он прав. Как нам безопасно и синхронно получить доступ к свойству из кода, который ничего не знает про async/await?
Первое, что приходит в голову, — асинхронный рефакторинг. Можно переделать метод report() так, чтобы он возвращал значение через completion-блок.
func report(completion: @escaping @Sendable (String) -> Void) {
Task { @MainActor in
completion(order.status)
}
}
Это хороший и правильный подход. Мы сами им часто пользуемся. Но есть нюанс: если ваш метод используется в десятках, а то и сотнях мест по всему приложению, такой рефакторинг превращается в каскадное изменение огромного количества кода. Это не всегда приемлемо.
Ловушка №1: MainActor.assumeIsolated
В API Swift Concurrency есть функция MainActor.assumeIsolated. Она говорит компилятору: «Поверь мне на слово, этот код уже выполняется на главном потоке».
func report() -> String {
MainActor.assumeIsolated {
order.status
}
}
Этот код скомпилируется, но упадёт в рантайме, как только событие метрики будет отправлено из фонового потока. assumeIsolated — это не механизм переключения потока, а лишь способ обмануть компилятор, когда вы на 100% уверены в контексте выполнения. Здесь это не так.
Ловушка №2: DispatchQueue.main.sync и потенциальный дедлок
Хорошо, а что, если проверять поток вручную? Если мы на главном — используем assumeIsolated, если нет — синхронно переключаемся на main через DispatchQueue.
func report() -> String {
if Thread.isMainThread {
MainActor.assumeIsolated {
order.status
}
} else {
DispatchQueue.main.sync {
order.status
}
}
}
На первый взгляд, это выглядит надёжным решением. Но оно скрывает в себе бомбу замедленного действия — дедлок. Представьте себе такой сценарий:
- Некий код на главном потоке вызывает синхронную операцию на своей приватной очереди (queue.sync). Это один из часто применяемых способов синхронизации. Главный поток блокируется и ждёт.
- Код на этой приватной очереди выполняет какую-то логику и в какой-то момент отправляет событие в метрику, вызывая наш метод report().
- Наш код видит, что текущий поток — не главный, и пытается синхронно выполнить блок на main очереди (DispatchQueue.main.sync).
- Всё. Приватная очередь заблокирована в ожидании главного потока, а главный поток заблокирован в ожидании приватной очереди. Мы получили классический дедлок.

Я не говорю, что этот паттерн — абсолютное зло. Но использовать его можно только в очень локальных участках кода, где вы полностью контролируете всю цепочку вызовов и гарантируете, что такая ситуация никогда не возникнет. В общем случае это слишком рискованно.
Надёжное решение: снова nonisolated и NSLock
Если мы не можем гарантировать поток выполнения, то честнее всего — как и в случае с deinit — признать этот факт. Мы можем вывести свойство status из-под изоляции актора, разрешив доступ к нему с любого потока.
@MainActor
class Order {
nonisolated(unsafe) var status: String
}
Теперь компилятор не ругается, но мы открыли ящик Пандоры — потенциальный data race. Решение, как вы уже догадались, кроется в старой доброй plain old cocoa style concurrency. Мы создаём приватное хранилище для нашего свойства и защищаем доступ к нему с помощью NSLock.
@MainActor
class Order {
nonisolated(unsafe) var status: String {
set { statusLock.withLock { self.unsafeStatus = newValue } }
get { statusLock.withLock { self.unsafeStatus } }
}
nonisolated(unsafe) private var unsafeStatus: String
let statusLock = NSLock()
}
Здесь мы превратили status в вычисляемое nonisolated-свойство. Оно служит потокобезопасной точкой доступа к приватному хранилищу unsafeStatus, а все операции чтения и записи защищены мьютексом statusLock. Теперь доступ к свойству безопасен как извне, из неадаптированного кода, так и изнутри самого актора. Это надёжное и предсказуемое решение, которое не боится дедлоков и работает в любой ситуации.
Проблема №3: опасный Timer
Последний кейс, который мы разберём, связан с задачей, знакомой каждому iOS-разработчику, — отложенными операциями. Чтобы своевременно обновлять статус заказа, мы используем поллинг: раз в некий промежуток времени, для примера возьмём 15 секунд, мы опрашиваем сервер. Классический инструмент для этого — Timer.
Давайте посмотрим на среднестатистический код для такой задачи, но уже в контексте нашего @MainActor-провайдера.
@MainActor
class Provider {
var timer: Timer?
deinit {
timer?.invalidate()
}
func scheduleFetch() {
timer = Timer.scheduledTimer(
withTimeInterval: 15,
repeats: false
) { [weak self] _ in
self?.fetchDeliveries()
}
}
func fetchDeliveries() { ... }
}
Что здесь может пойти не так? На самом деле почти всё.
Колбэк таймера
Первая ошибка, с которой мы сталкиваемся, — в замыкании таймера: Call to main actor-isolated instance method 'fetchDeliveries()' in a synchronous nonisolated context.
Мы-то с вами знаем, что Timer, добавленный в RunLoop главного потока, будет вызывать свой колбэк на том же главном потоке. Но проблема в том, что текущее API Timer никак не сообщает об этом системе типов Swift Concurrency. Для компилятора это замыкание — неизолированный контекст.
Apple предлагает решение: использовать MainActor.assumeIsolated, чтобы заверить компилятор, что мы знаем, что делаем.
// ...
) { [weak self] _ in
MainActor.assumeIsolated {
self?.fetchDeliveries()
}
}
Это сработает. Но это не решение, а скорее временная заплатка. Мы полагаемся на неявный контракт, а не на гарантии, встроенные в язык. Но это не единственная и даже не главная проблема.
Инвалидация в deinit
Как мы уже выяснили, deinit может быть вызван с любого потока. А документация Apple прямо говорит: инвалидировать Timer критически важно на том же потоке, на котором он был создан. В противном случае Input Source, связанный с таймером, может не удалиться из RunLoop, что приведёт к утечке ресурсов. Наша реализация в deinit напрямую нарушает это правило.
Можно ли сделать лучше? Да. С приходом Swift Concurrency от Timer для таких задач можно — и нужно — отказаться. Вместо Timer мы можем использовать асинхронную Task со статическим методом sleep. Вот как преображается наш код:
@MainActor
class Provider {
var task: Task<Void, Error>?
deinit {
task?.cancel()
}
func scheduleFetch() {
task = Task { [weak self] in
try await Task.sleep(for: .seconds(15))
if !Task.isCancelled {
self?.fetchDeliveries()
}
}
}
func fetchDeliveries() { ... }
}
Этот подход решает обе проблемы Timer весьма элегантно и на уровне системы типов.
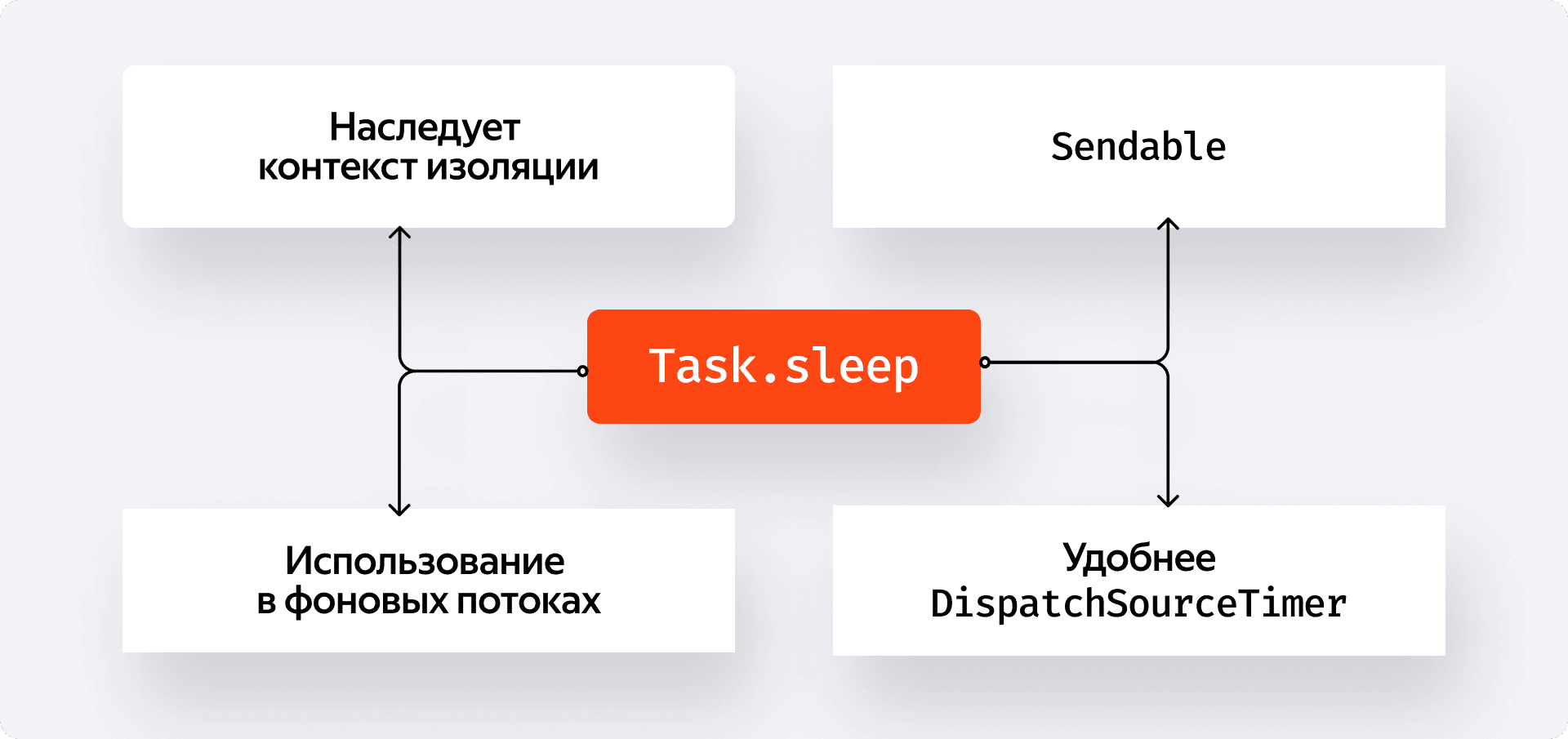
- Наследование контекста изоляции. Task по умолчанию наследует контекст, в котором была создана. Так как scheduleFetch помечен @MainActor, код внутри Task тоже будет выполняться на главном акторе. Нам больше не нужны никакие assumeIsolated.
- Потокобезопасная отмена. Task — это Sendable-тип. Мы можем безопасно вызывать метод 'cancel()' из любого потока, включая неизолированный deinit. Никаких рисков утечки ресурсов или крэшей.
Более того, Task.sleep не привязан к RunLoop, поэтому его можно без проблем использовать для отложенных операций на фоновых потоках. По сравнению с громоздким API DispatchSourceTimer из GCD, Task.sleep — это простой, удобный и всепрощающий инструмент, который идеально вписывается в новую парадигму многопоточности.
Заключение: когда же станет легко?
В процессе адаптации языка разработчики Swift выпустили документ, в котором признали: Swift Concurrency задумывалась как технология, лёгкая для внедрения, но что-то пошло не так. И это правда. Миграция может фрустрировать. Но в Apple работают умные люди, и в Swift 6.2 нас ждёт isolated deinit — одна из многих попыток сгладить самые острые углы. Это облегчит переход, но, как мы выяснили, асинхронный deinit — это свой набор компромиссов, о которых нужно будет помнить.
Так какие выводы мы сделали для себя, пройдя этот путь?
Во-первых, Swift Concurrency надо уметь пользоваться. Легко вызвать async-функцию, но это всё ещё технология многопоточного программирования со своими нюансами, которые требуют глубокого понимания.
Во-вторых, классическая многопоточность никуда не делась. NSLock, мьютексы, понимание принципов синхронизации — всё это остаётся в арсенале. Можно писать код и без них, но недолго. Какие бы красивые обёртки нам ни давали, многопоточность не бывает по-настоящему лёгкой.
И в-третьих, при всём при этом Swift Concurrency — это реально мощный инструмент. Он даёт нам новые, более элегантные способы решения старых задач, как мы увидели на примере с Task.sleep.
Когда мы только начинали адаптацию, это было не просто сложно, это было… очень сложно. Попытка что-то исправить в одном месте порождала ошибки в десяти других. Но по мере того, как мы преодолели рубеж в 60–70% адаптированного кода, мы заметили, что просто создаём акторы, изолируем объекты на @MainActor и больше не испытываем почти никаких трудностей.
Сложность применения Swift Concurrency нелинейна. В начале пути она кажется запредельной, но с каждым адаптированным модулем она экспоненциально падает. И в тот момент, когда кривая идёт вниз, приходит понимание, насколько это крутая и продуманная технология. Надеюсь, наш опыт вам поможет.



