Современное развитие в области встроенной разработки и электроники с учётом бизнес-процессов ускоряется, часто следуя принципам Agile и Scrum. Применение этих методик требует осторожности из-за длительного производственного цикла встроенной разработки, который затрудняет быстрые изменения.
Меня зовут Арсентий Гусев, я руководитель группы embedded-разработки в отделе робототехники Яндекс Маркета. И мне бы хотелось рассказать об опыте, который приобрела наша команда в рамках работы над проектом складского робота. В этой статье определим критерии, предпосылки и предложим инструменты для ускорения разработки и снижения её стоимости.
Постановка проблемы
Проектирование и планирование — очень непростые темы, не поддающиеся математическому анализу. Тем не менее у нас имеется множество инструментов, которые позволяют взглянуть на правильность нашего планирования в ретроспективе и сделать выводы. Это даёт возможность руководителю сформировать внутри себя и, что более важно, принять полученный опыт.
Давайте примем за факт: мы не идеальны и делаем ошибки. Если вы так не считаете, вам ещё многому предстоит научиться. 9 из 10 наших гипотез ошибочны. Мы хотим быстрее получать обратную связь от реальности и поэтому доводим нашу функциональность до практики. В embedded время отклика тем длиннее, чем более низкоуровневый модуль и процесс разработки мы затрагиваем.
Давайте воспользуемся двумя инструментами. Первый — оценочная оптимизационная функция, к которой мы стремимся. Она по какой-то сложной и неочевидной формуле включает в себя затраты на разработку, эффективность полученного результата, его стабильность и поддерживаемость и цену этой поддержки.
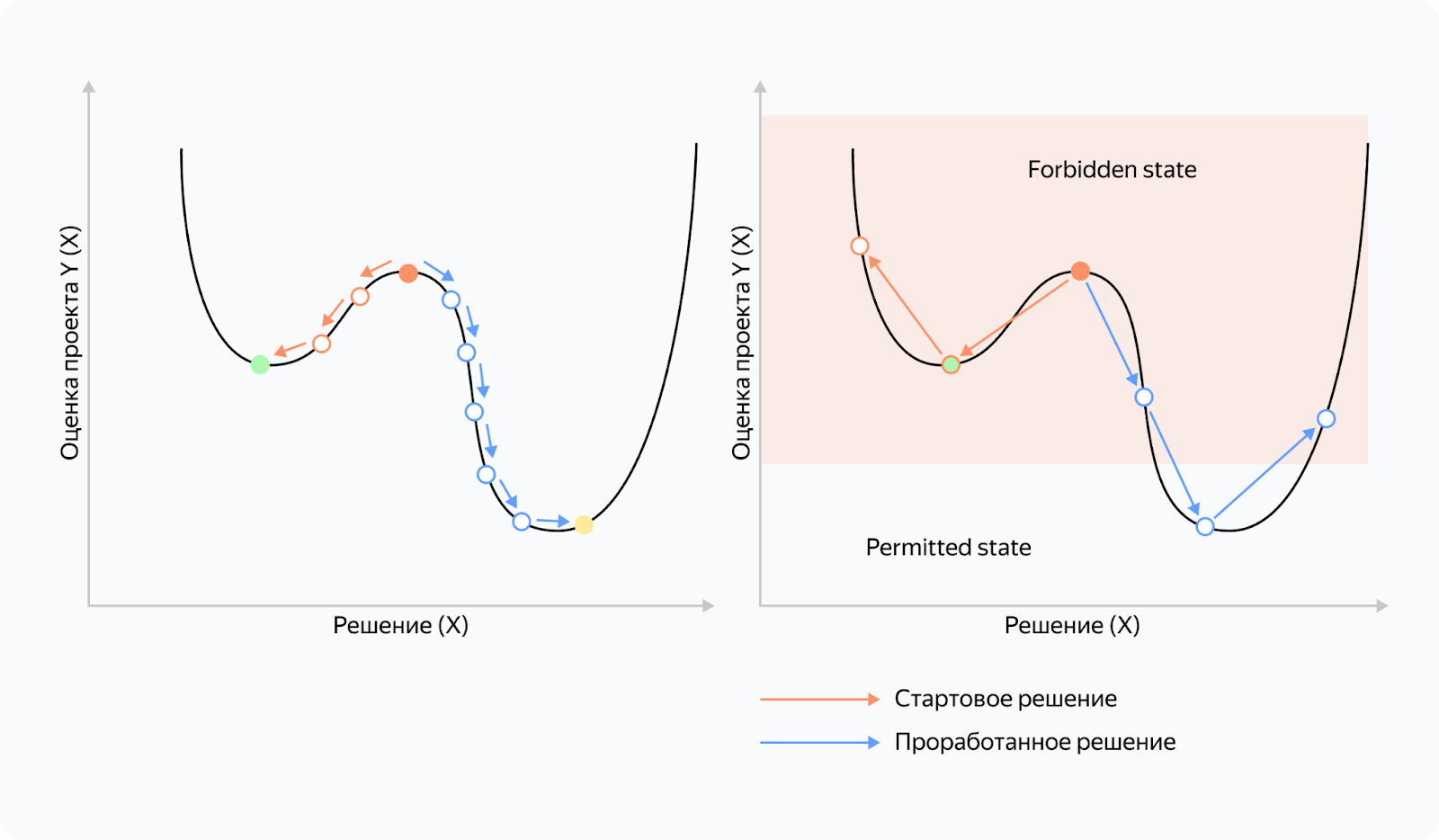
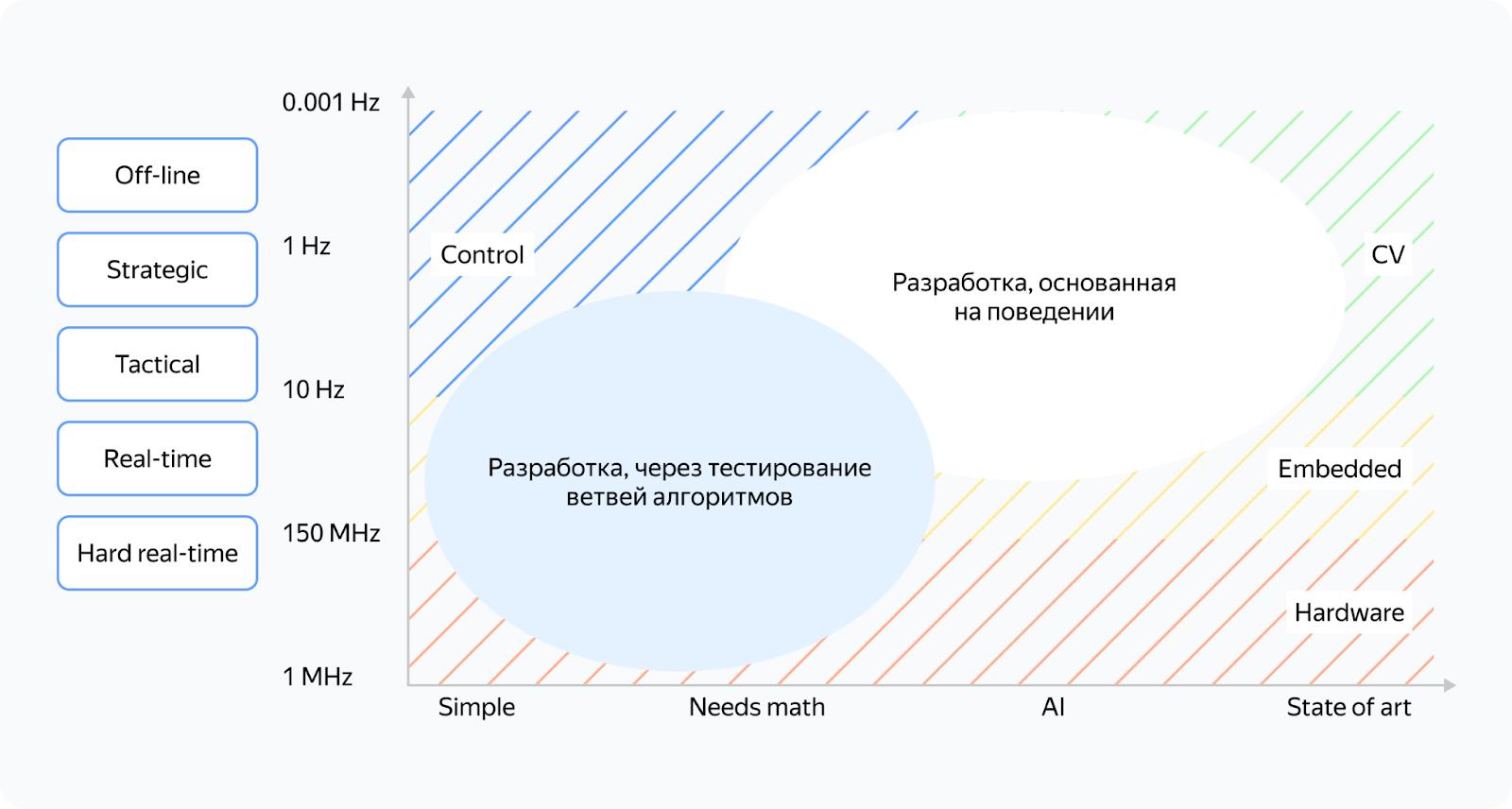
На левом рисунке у нас процесс разработки с коротким циклом релиза, чаще всего это софт или бизнес-логика embedded. На правом — процессы разработки драйверов embedded и новых функциональных плат.
Также на правом рисунке можно выделить размеченную область forbidden state — это область, где мы плохо контролируем результат разработки и у нас есть некоторые проблемы.
Второй инструмент — диаграмма сгорания задач и багов. Она покажет нам технический долг на разных этапах проекта. Давайте сразу оговоримся, что мы будем рассматривать некий идеальный случай.
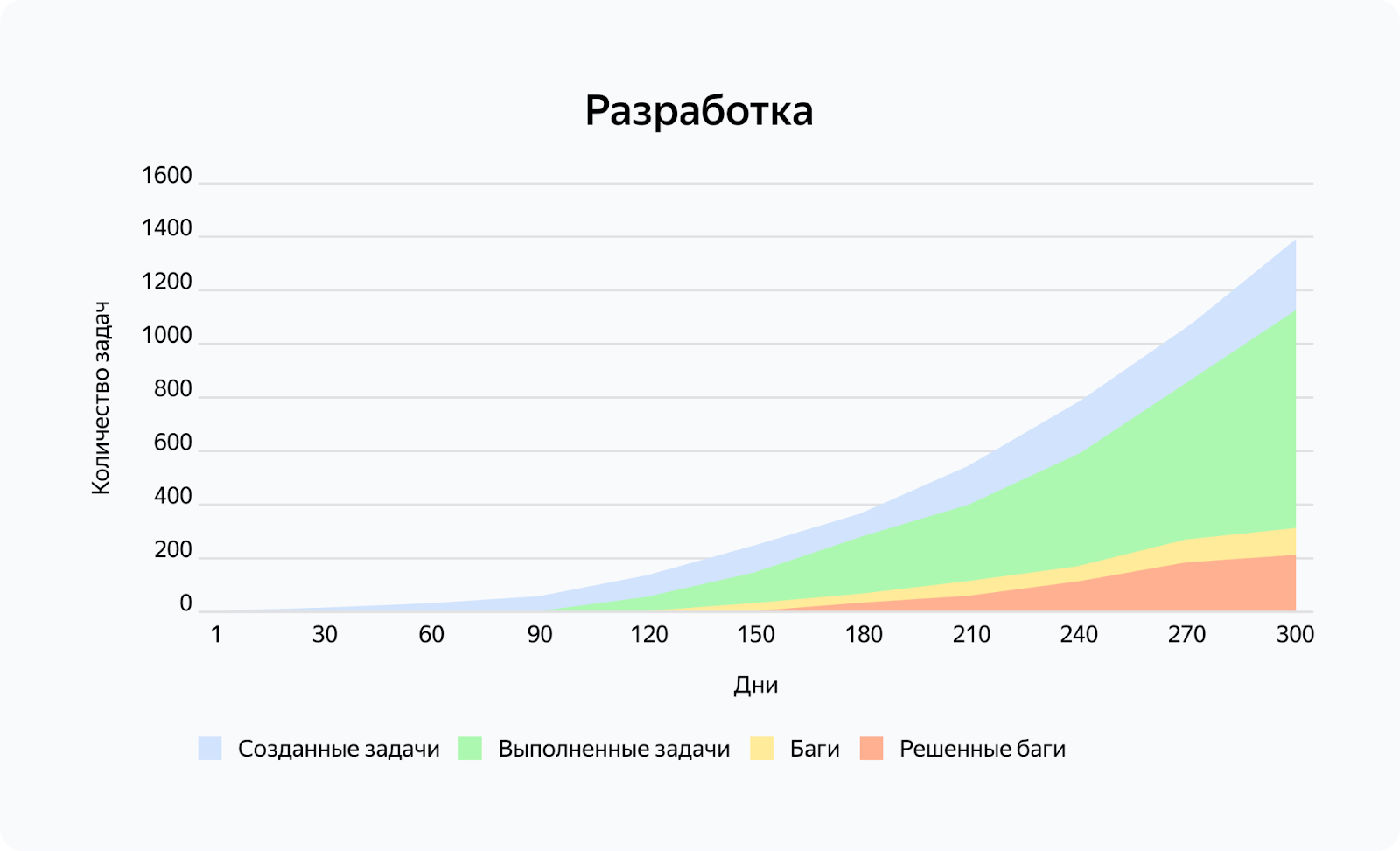
Диаграмма показывает, что производительность команды растёт, как и количество багов и количество выполненных задач. Для стартапа это обычная ситуация. Растёт и количество людей в команде. Для понимания нам нужно очистить показатели от роста команды.
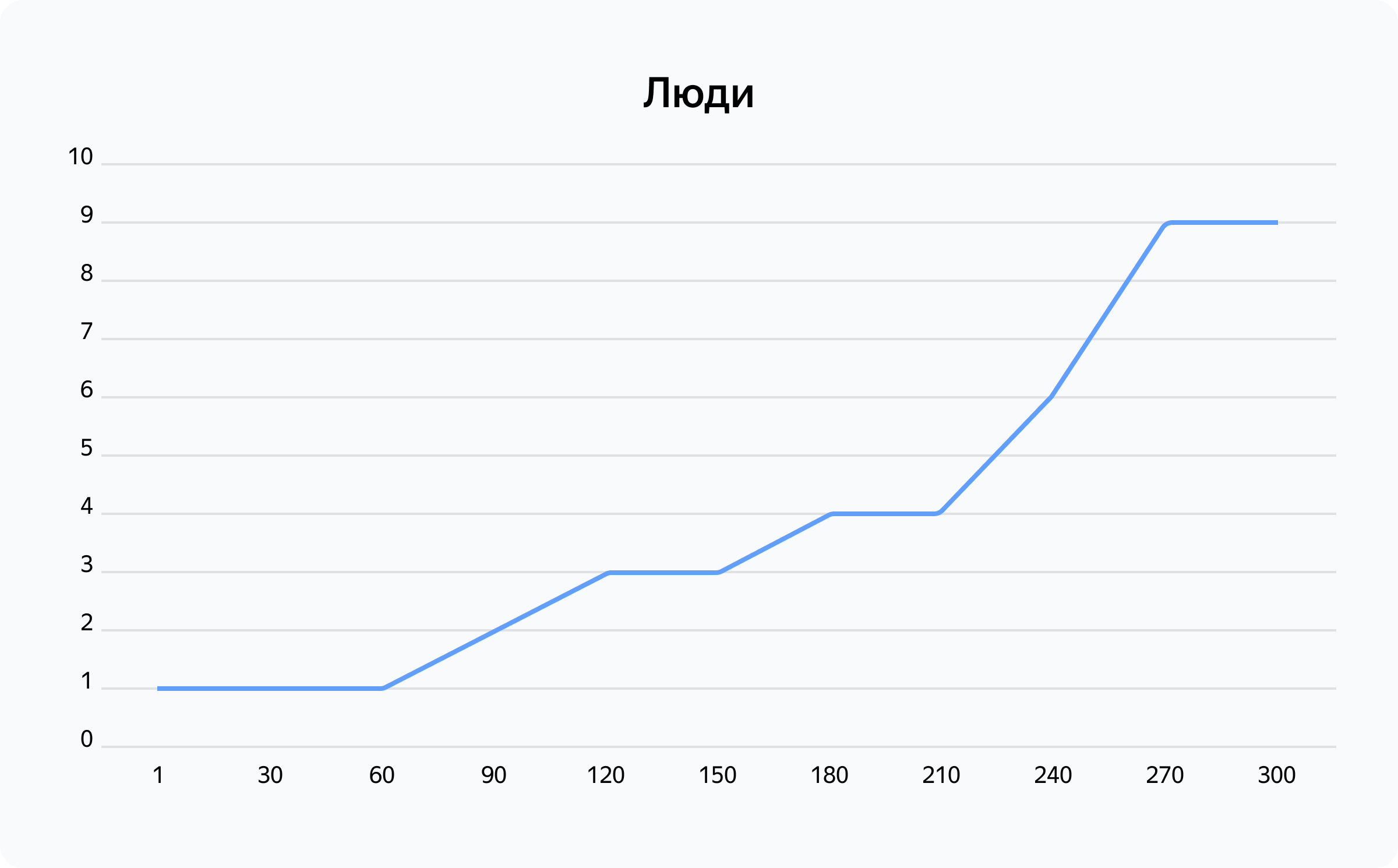
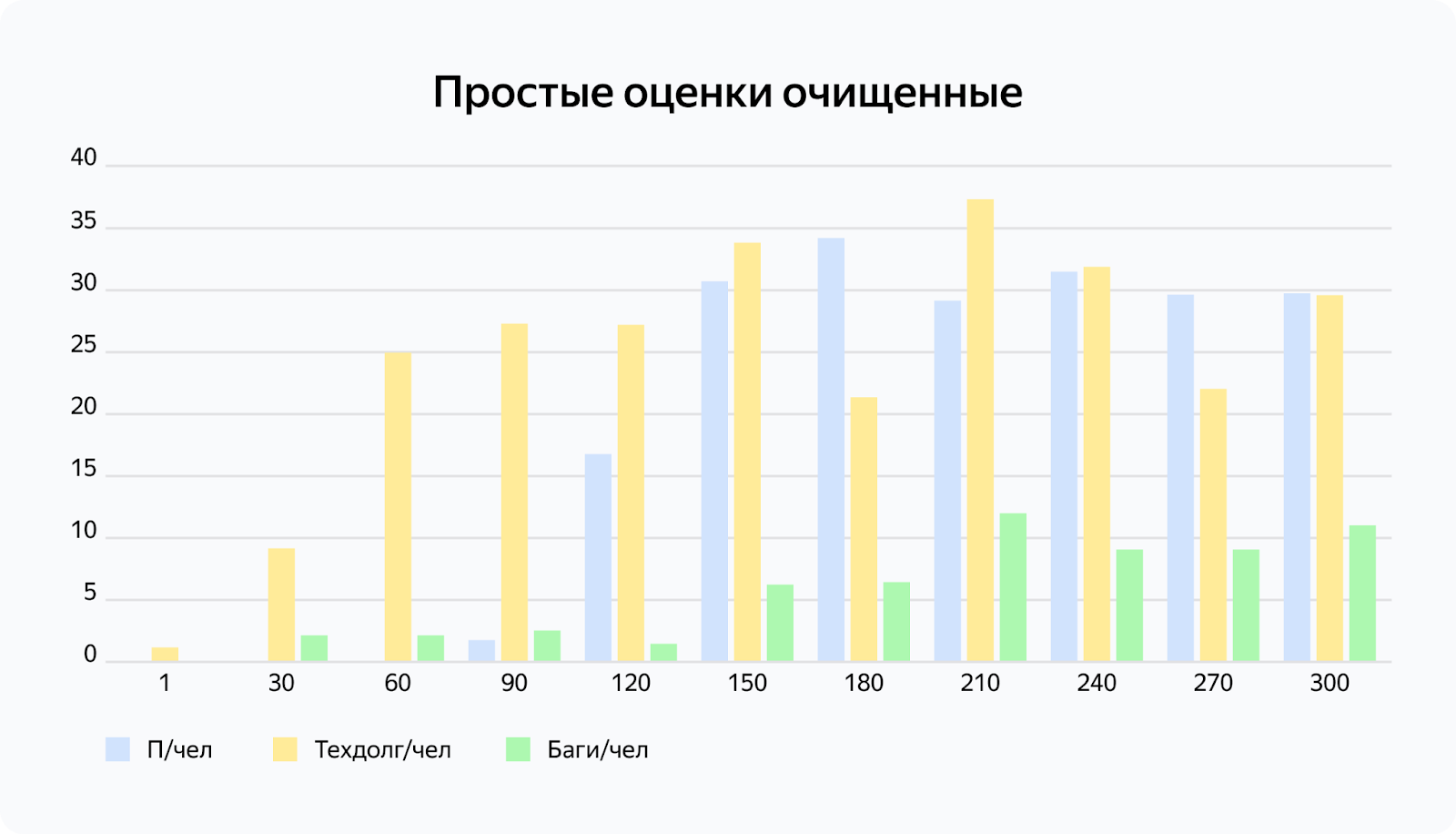
Наложим график прироста позиций в команде и получим очищенные оценки производительности, технического долга и багов на человека. Из этих показателей наиболее явный тренд мы увидим в приросте багов на человека по месяцам.
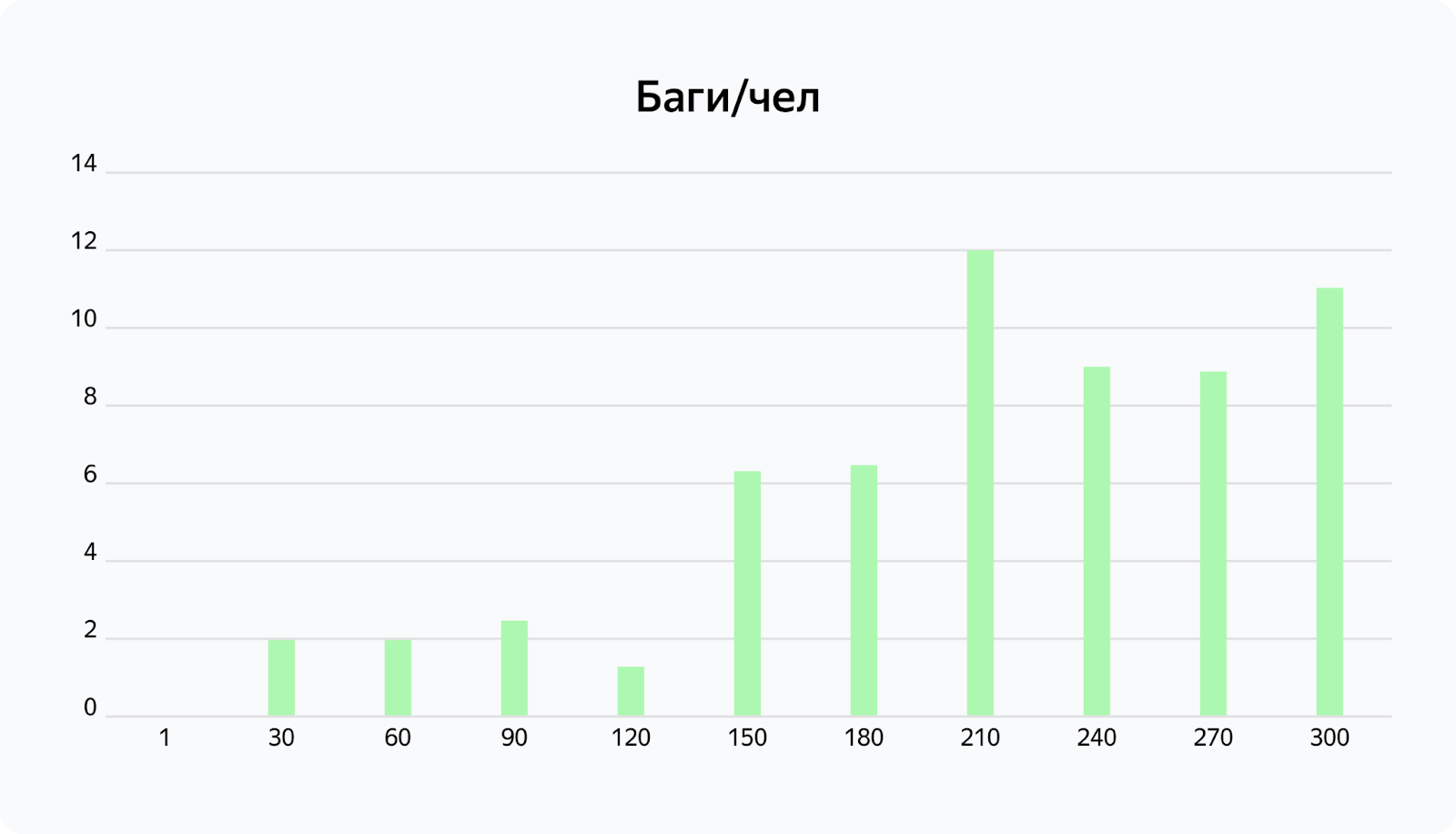
Это может стать проблемой для эффективности нашей команды.
Мы понимаем значение этой проблемы, но важно также определить, когда именно мы находимся в проекте, чтобы оценить её значимость. Я выделяю четыре этапа разработки программно-аппаратного комплекса в стартапах:

- Концепция. Можем ли мы решить техническую или операционную задачу?
- Прототип. Можем ли мы спроектировать и создать функцию, чтобы удовлетворить потребности пользователей?
- Минимально жизнеспособный продукт (MVP). Можем ли мы создать набор функций, чтобы удовлетворить потребности пользователей и доказать это?
- Минимально рыночный продукт (MMP). Будут ли пользователи инвестировать деньги в наш продукт?
На основе моего опыта наибольшая потребность в предсказуемости, стабильности и повторяемости возникает на этапе MVP. К этапу MMP количество багов в системе с текущей функциональностью должно падать.
Принятие неизбежного
Однако помимо технических показателей и цифр давайте попробуем проверить и другие звоночки с проблемами в проекте.
Первая стадия: отрицание. Нестабильность итогового результата
Как правило, команды используют много инструментов при работе с разными уровнями в архитектуре проекта. Инструменты в основном ранжируются по уровню абстракции и соответствующей функциональности. Непонимание разницы между инструментами приводит к ошибкам в проектировании, которые не проверяются должным образом, поскольку разработчик чаще всего сосредоточен на так называемом success flow.
Ошибки накапливаются, и разработчики, столкнувшись с неполадками в модуле, начинают адаптироваться к его поведению, вводя в систему неопределённости. Такой системе требуется значительно больше времени, чтобы достичь баланса (см. многомерная оптимизация против одномерной). Применительно к бизнес-задачам лучше обратиться к курсу Business Math II (part 1): Multivariable Optimization (by Evan Dummit, 2019)).
В результате появляется множество тикетов с ошибками и ещё больше задач в списке ToDo. Задачи, переданные на тестирование, возвращаются в 80% случаев. Процесс нарушается, и качество кода снижается из-за большого количества быстрых исправлений и временных решений.
Вторая стадия: гнев. Неповторяемость результата производства
Устройство начинает вести себя странно, проявляются необъяснимые симптомы, а ошибки становятся нестабильными и возникают редко, но в самых неожиданных частях системы.
Когда вас спрашивают о работе устройства, вы сообщаете о наличии багов, которые, по вашему мнению, не влияют на текущую задачу вопрошающего.
Просто представьте ситуацию: из производства снова вернули робота, который не был полностью собран, и половина функциональности так и не заработала. Причём проблемы возникли в совершенно других местах, чем в прошлый раз. Такое качество сборки очень раздражает. Ведь невозможно так плохо следить за схемой соединений?
Третья стадия: торг. Непредсказуемость времени разработки
Второй раз подряд сроки проекта сдвигаются на месяц из-за того, что постоянно возникают более важные баги, которые вытесняют текущие задачи спринта. Это может показаться обескураживающим, но на самом деле такое положение вещей — норма в мире разработки программного обеспечения. Главное — полностью протестировать систему и найти все возможные ошибки. Важно также не забывать о том, что все процессы необходимо тщательно мониторить.
С каждым новым проектом мы получаем новые уроки. Один из них — приходится временно забывать о паттернах проектирования и связности системы. Наша основная цель — сделать работу быстро, но при этом обеспечить полноценную функциональность нашего продукта. Мы признаём, что это сложная задача, но мы уверены, что сможем справиться с ней.
Четвёртая стадия: депрессия. Невозможность модификации системы
Мы добавили новую функциональность, что, казалось бы, должно было улучшить наш продукт. Но вместо этого все ошибки, которые мы тщательно исправляли, вспыхнули вновь, словно огни на новогодней ёлке. Как будто этого было мало, на свет повылезали ещё и те ошибки, которые мы с большим трудом устраняли два спринта назад.
Пятая стадия: принятие. Полный рефакторинг
Следствие же этого исхода заключается в крайней сложности отладки такой системы. Когда у нас есть множество узлов и вероятность их отказа, то в цепочке вероятностей становится очень сложно локализовать проблему (см. Байесова модель при поиске ошибок).
Так чего же мы хотим добиться на этапе MVP нашего проекта?
- Стабильности итогового результата. Завершённый проект может выполнить полный рабочий цикл 100 раз без остановки.
- Повторяемости результата производства. Пять собранных устройств, и каждое не отличается друг от друга.
- Предсказуемости времени разработки. Финальный проект требует двух итераций производства, чтобы получить рабочую версию.
- Возможности модификации системы. Все программные модули независимы и используются в разных продуктах самостоятельно.
Постановка решения
Не существует никаких краткосрочных мер, которые позволили бы быстро повысить производительность работы.
Повышение производительности — результат долгосрочных усилий.
Любые средства для повышения производительности, которые обещают немедленный результат, — обман.
Том ДеМарко. Deadline. Роман об управлении проектами
Такая ситуация возникает, когда мы торопимся с проектированием, особенно на низком уровне. И используем инструменты, которые на этом уровне не приносят результата. Мой опыт подсказывает, что картина такова:
Здесь мы познакомимся с двумя наиболее полезными, на мой взгляд, методологиями разработки. Рассмотрим их в параллели.
| Разработка через тестирование (TDD) | Разработка, основанная на поведении (BDD) |
|---|---|
| Обеспечивает правильность кода с помощью автоматических тестов | Способствует общему пониманию, общению и подтверждению системного поведения |
| Тесты написаны перед реализацией соответствующего кода | Сценарии определяются перед реализацией кода |
| Узкая область, обычно сосредоточена на отдельных блоках кода | Широкая область, охватывающая работу нескольких блоков кода вместе |
| Технический и ориентированный на реализацию | Ориентирован на пользователя и поведение |
| Мелкозернистый, тестирует отдельные блоки кода изолированно | Крупнозернистый, тестирует системное поведение в целом |
| Итеративно уточняет код через тестовые неудачи и последующие модификации кода | Уточняет сценарии и поведение через сотрудничество и обратную связь |
Применение такой методологии, как разработка через тестирование, меняет наше восприятие процесса создания программного обеспечения и перестраивает традиционный порядок разработки.
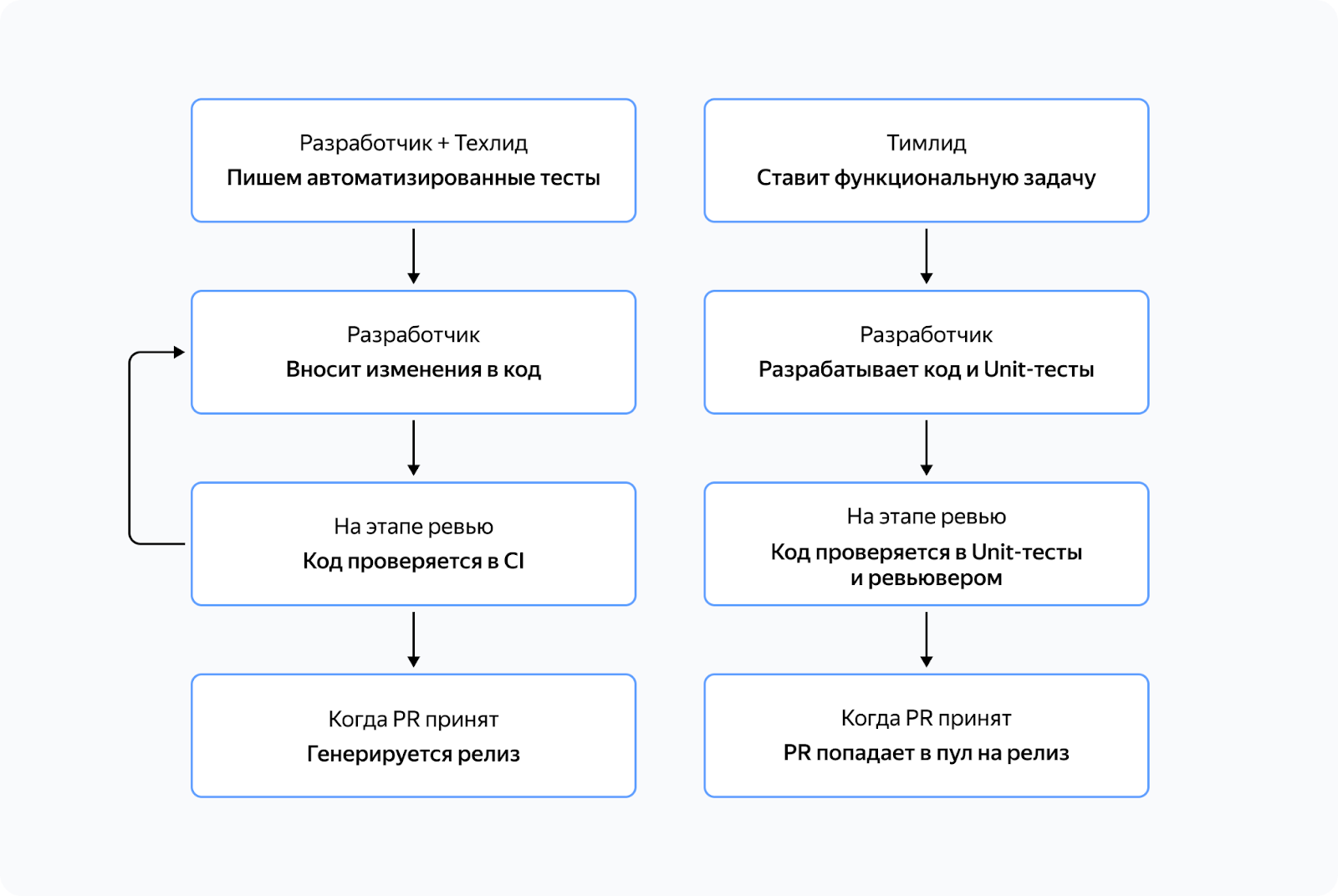
Традиционная методика разработки обычно предполагает постановку функциональной задачи разработчику, после чего следует написание кода и проведение стандартного процесса ревью. На этапе разработки мы, как правило, создаём достаточное количество unit-тестов для проверки качества нашего кода. После проведения ревью код утверждается и попадает в основную ветку репозитория, где ожидает запуска релиза.
В отличие от этого подход, ориентированный на разработку через тестирование, предлагает другую последовательность действий. Прежде всего мы совместно с экспертом составляем достаточное количество тестов, которые покрывают все ветви и состояния нашей системы. Затем мы автоматизируем эти проверки и добавляем их в цикл непрерывной интеграции (CI). Разработчик в свою очередь подготавливает код и архитектуру системы в соответствии с проверками, чтобы успешно их пройти. После успешного прохождения проверки в цикле CI мы генерируем срез кода, который затем отправляется в релиз.
Зачем нужен TDD
Конечно, не секрет, что нужно разрабатывать тесты для своего кода. Но здесь мы делаем акцент на первоочередной разработке тестов. Есть ряд преимуществ использования TDD вместо другого стиля разработки.
- Сокращение времени на доработку. Разработка через тестирование не позволяет писать новый код, пока существующий не пройдёт успешное тестирование без сбоев. Пока сбои полностью не устранены, процесс написания кода останавливается. Поэтому время, затрачиваемое на доработку нерабочего кода, сводится к минимуму.
- Быстрая обратная связь. Поскольку тесты сосредоточены на конкретных участках кода за раз, разработчики могут получать более непосредственную обратную связь, что позволяет им вносить изменения быстрее.
- Повышение производительности разработки. С TDD акцент делается на производстве функционального кода, а не на проектировании тестового случая. Таким образом, производительность увеличивается, и разработка продолжается гладко.
- Более гибкий, поддерживаемый код. Поскольку каждая часть кода тестируется, прежде чем переходить к следующей части процесса разработки программного обеспечения, код сохраняет функциональность и может адаптироваться в будущем.
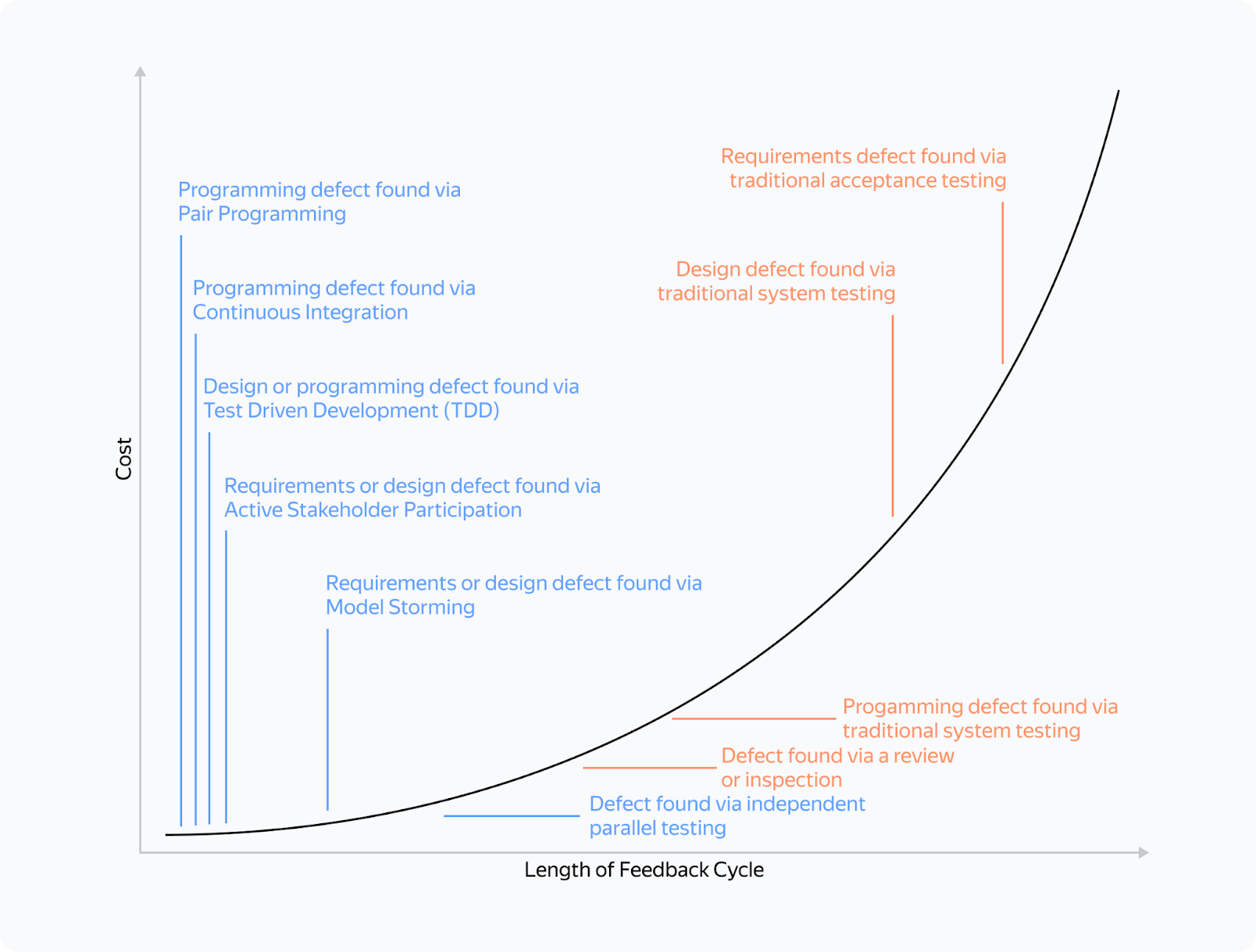
Когда не стоит его использовать
Напомню про четыре стадии разработки:

На начальных стадиях разработки (на первых двух этапах) ключевым фактором является не стабильность и повторяемость, а скорость подтверждения или опровержения теоретических предположений. Работа в таком режиме подразумевает, что подготовка тестов, проверка гипотез и их корректировка могут потребовать значительных ресурсов. Но эти ресурсы можно было бы с большей эффективностью использовать для разработки и тестирования альтернативных идей и подходов, что, в свою очередь, может существенно ускорить процесс поиска оптимального решения.
Программирование vs hardware-разработка
Проблема, с которой сталкиваются многие разработчики в области hardware, заключается в том, что иногда возникают значительные сложности в реализации тестов. Это связано с тем, что инструменты для проведения тестов hardware in the loop, которые играют критическую роль в этом процессе, часто остаются недостаточно проработанными командой инфраструктуры. Это, в свою очередь, создаёт препятствия для эффективного и своевременного тестирования, что может отрицательно сказаться на качестве конечного продукта в большинстве компаний.
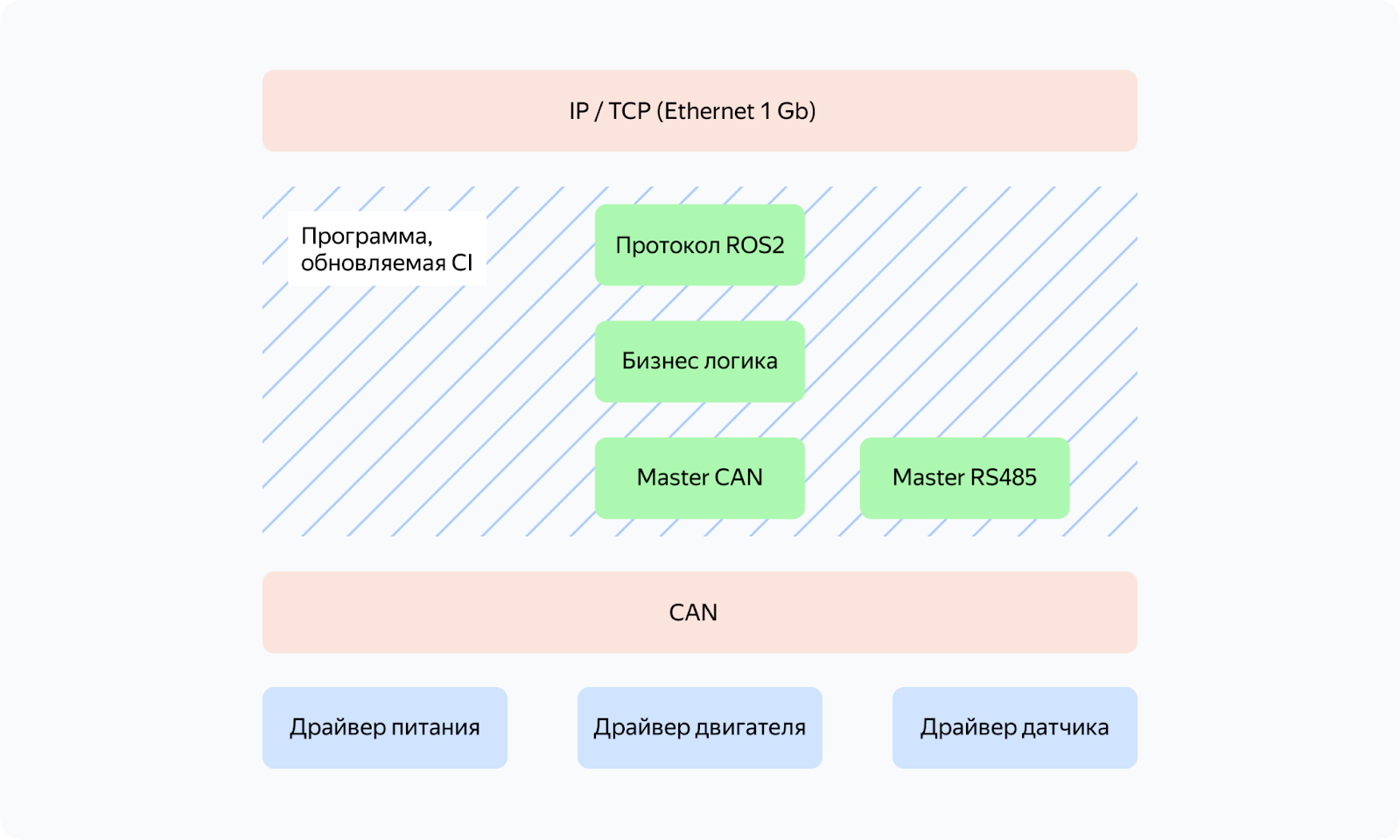
Чтобы достигнуть поставленных нами требований по стабильности итогового результата, повторяемости результата производства, предсказуемости времени разработки и возможности модификации системы, мы должны разделить систему на три составляющих наших тестов.
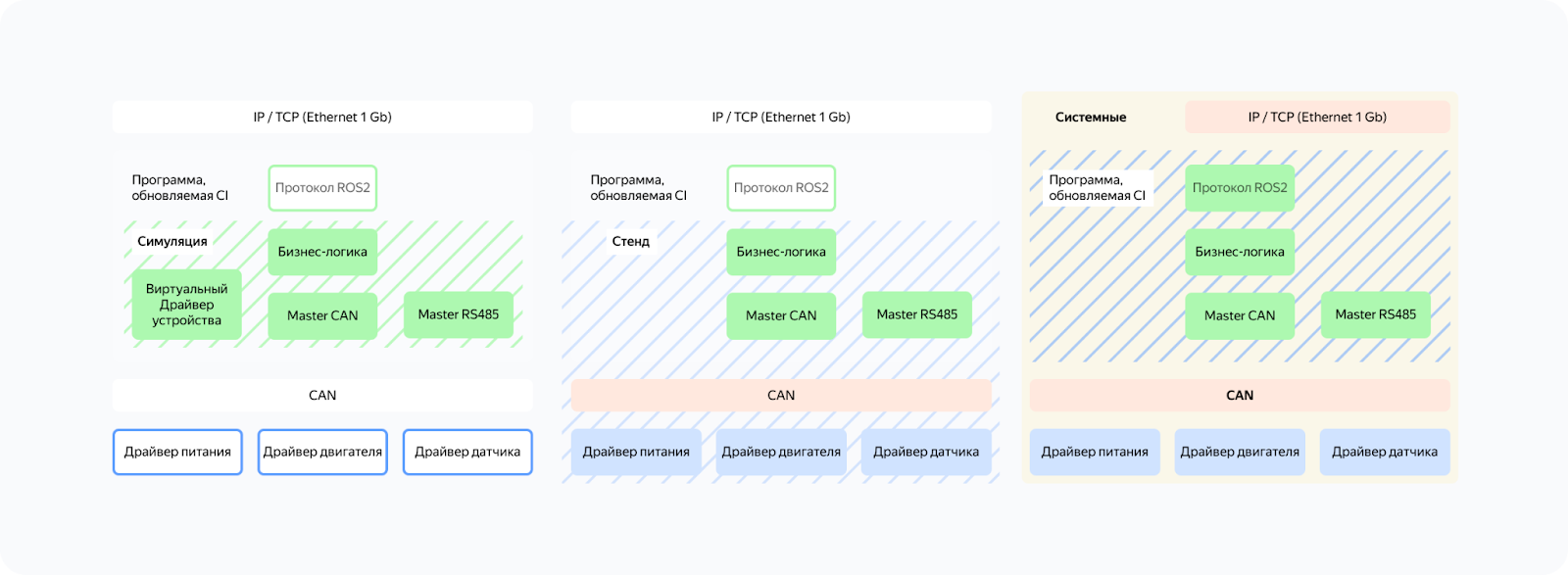
- Блок симуляции — это инструмент, который позволяет тестировать API модулей программного кода и работы драйверов. Это значительно упрощает процесс отладки, уменьшает время на поиск ошибок и позволяет повысить качество нашего кода.
- Блок стенда — это ещё одна важная часть нашего процесса. Он выполняет задачи эмуляции и даёт нам возможность глубоко понять, как работает наш код в реальных условиях. Он позволяет увидеть, какие проблемы могут возникнуть на реальном железе с физически подключённой коммутационной линией, помехами на ней и драйверами устройств, имеющими свои проблемы (задержки ответа, нагрузка на шину коммуникации или плохо проработанный код драйверов).
- Блок системных тестов — это обширная область, которая включает в себя тестирование всей системы в целом. Сюда входят тесты, которые демонстрируют взаимодействие всех компонентов и их необходимой инфраструктуры. Это позволяет нам убедиться, что все части нашей системы работают вместе должным образом и что нет скрытых проблем, которые могут возникнуть в процессе работы.
Выводы
Представленная модель разработки имеет и ряд ограничений, которые стоит учесть при её использовании и внедрении:
- она предполагает очень простую модель расчёта;
- игнорирует стоимость обучения TDD;
- не учитывает, сколько времени пройдёт с момента внедрения TDD до результата;
- предполагает стабильность производительности.
Тем не менее грамотно внедрённый результат окупится довольно быстро.
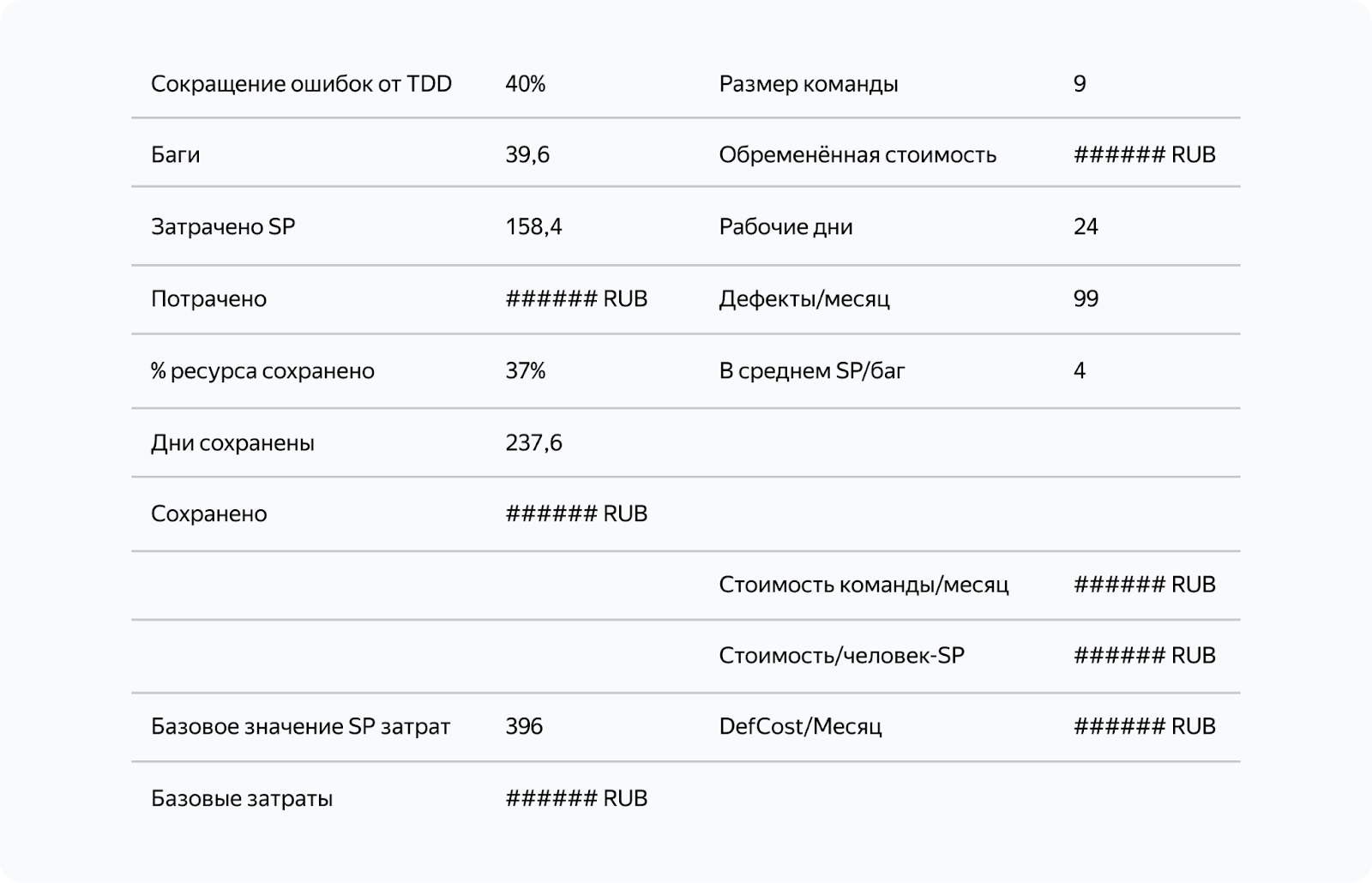
Многие исследования TDD показывают, что его внедрение позволяет сократить количество ошибок на 40–60%. Если учесть производительность команды и минимальную эффективность в 40%, то мы сэкономим более двух реальных рабочих недель в месяц для всей команды, которые они могут потратить на разработку. Это приводит к увеличению производительности на 37%.
Этот результат улучшается, если время на исправление одного бага увеличивается и превышает два дня.