
Привет! Меня зовут Вова Верстов, я руководитель платформы управления данными в Яндекс Go. С 2017 года мы строим и постоянно адаптируем нашу платформу к меняющимся требованиям и внешним факторам. Для нас это инфраструктура, которая живёт и используется внутри разных сервисов: Такси, Еды, Лавки и Доставки.
В статье сначала обсудим скоуп того, что мы считаем платформой и чем занимаемся. Дальше расскажу про архитектуру YTsaurus (YT), предназначенную для обработки и хранения данных, и как она развивалась на стороне Яндекс Go. Про YT я буду рассказывать с точки зрения того, какие возможности он даёт разработчикам хранилища и платформы, аналитикам и другим пользователям, которые активно работают с данными.
DAMA DMBOK и жизненный цикл данных
В своей работе мы опираемся не только на свой опыт или опыт коллег, но и на различные best practices. Вот, например, DAMA‑DMBOK — книга, в которой хорошо сформулированы правильные принципы управления данными.

Из принципов DAMA‑BOOK можно выделить, что специалистам, которые занимаются управлением данными, стоит ориентироваться на весь жизненный цикл продукта, то есть на всё, что происходит с данными.
Ещё из DMBOK мы предлагаем взять цели того, чем мы занимаемся:
- ориентироваться на разные потребности своих пользователей
- предоставлять инструменты для обработки данных
- обеспечивать качество данных
- заботиться о безопасности.
Важный аспект жизненного цикла данных — всё, что с ними происходит, укладывается в классический цикл. Планирование → проектирование → создание → хранение, поддержка, улучшение опыта использования и обработки данных → и опять планирование.
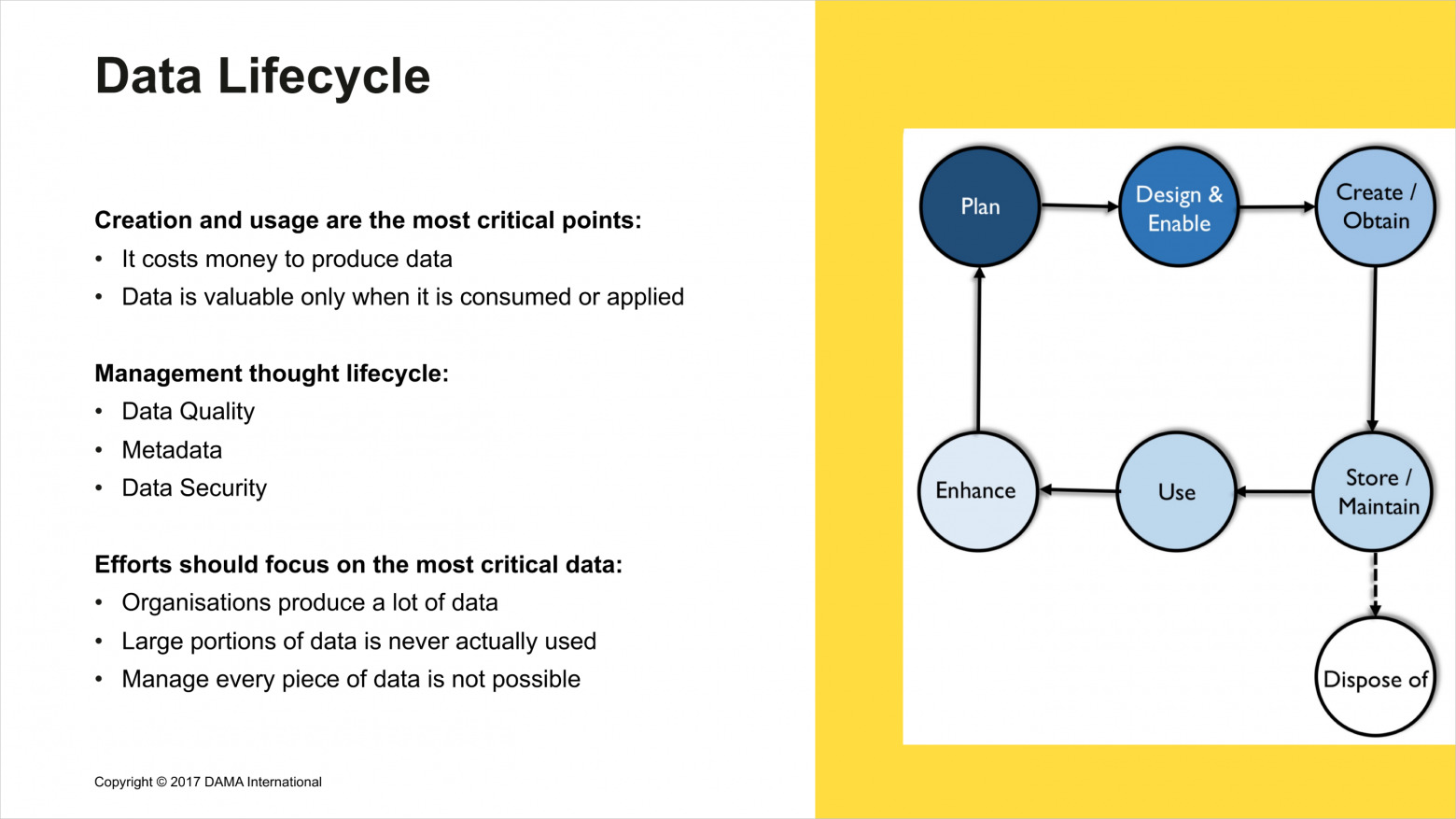
Мы сконцентрируемся не на всех этапах жизненного цикла данных, а на особенно дорогих: обработке, хранении и использовании.
Как развивалась система хранения данных Яндекс Go
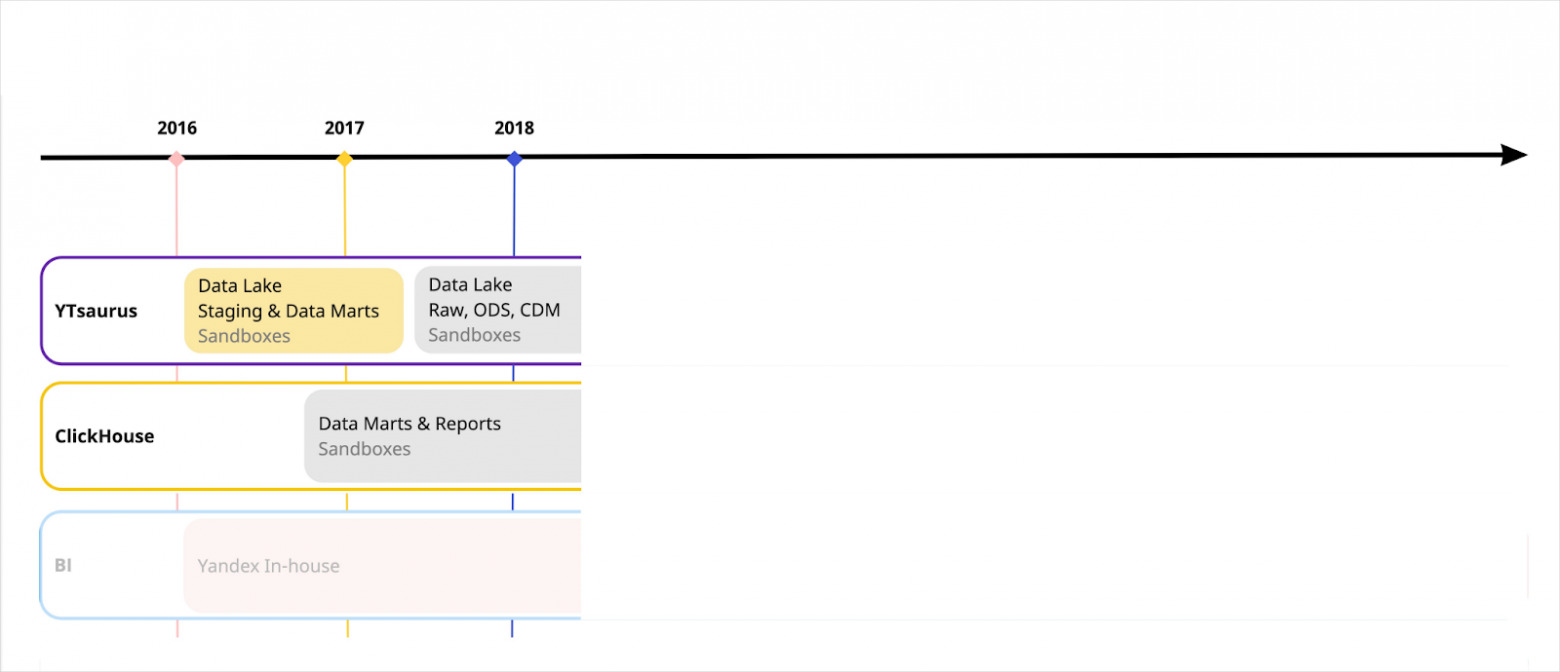
В 2017 году вместо Яндекс Go было просто Яндекс Такси. Я был шестым человеком в команде аналитиков и разработчиков хранилища. У нас уже тогда были десятки источников и терабайты данных. И объёмы росли по экспоненте. Нашей целью стало сделать реплики без бэкенда и витрины по основным сущностям, а также наладить базовую отчётность и дашборды.
В Яндексе уже тогда был YT, и мы сделали максимально простую архитектуру на его основе. То есть мы загружали данные из источников в стейджинг, делали какие‑то основные витрины. Аналитики могли решать свои задачи в так называемых сэндбоксах изолированно от production‑процесса. Для отчётов было in‑house‑решение, интегрированное с YT.

Инструментов стало очень быстро не хватать. Такси росло, увеличивалось количество сервисов в бэкенде, развивалась предметная область, и нужно было быстро закрывать потребности растущей команды аналитики.
Следующий челлендж был в том, чтобы предоставить быстрый доступ к уже существующим витринам, научиться делать более сложные агрегаты, снижать задержку данных от источника. А поскольку сервис активно рос, мы не могли сразу хорошо и точно угадать требования.
И тогда появился ClickHouse®. Он решал задачу быстрого ad‑hoc‑доступа, и в нём можно было считать сложные агрегаты для отчётности.
Ещё мы понимали, что не можем ходить каждый раз за историей в источник, поэтому у нас появился слой оперативных данных, или ODS. Витрина начала строиться как раз поверх ODS. Потребность в постоянных пересчётах истории стала решаться за счёт наличия слоя с «сырыми» данными.
Стали думать, как масштабировать наши решения на большой продукт и большую команду, которая продолжала расти. Нам было важно обеспечить сокращение TTM‑разработки, дать возможность решить часть задач за счёт Self Service.
Первым решением был Greenplum® — MPP СУБД, где ETL‑разработчик или аналитик может просто написать SQL‑запрос вместо MapReduce job и тем самым ускорить разработку. Также Greenplum® решает задачу производительности на определённых сценариях, потому что не всегда и не везде нужна масштабируемость MapReduce‑системы. Помимо этого, Greenplum® позволил нам начать работать со стандартными, известными на рынке BI‑инструментами: например, с Tableau и MS SSAS. В какой‑то момент у нас пропала необходимость в ClickHouse®, потому что связка Greenplum® и Tableau полностью заменила все сценарии, которые раньше решались в ClickHouse‑кластере.
Потом, помимо Яндекс Такси, у нас появились Еда, Лавка, Доставка. И снова важно было не уронить Time to Market, нужно придумывать, как адаптировать архитектуру к новым вызовам. В этот момент у нас возникает детальный слой. Он построен по парадигме, которая сочетает в себе свойства якорного моделирования и Data Vault. Подробнее о hNhM можно прочитать в статье Жени Ермакова.
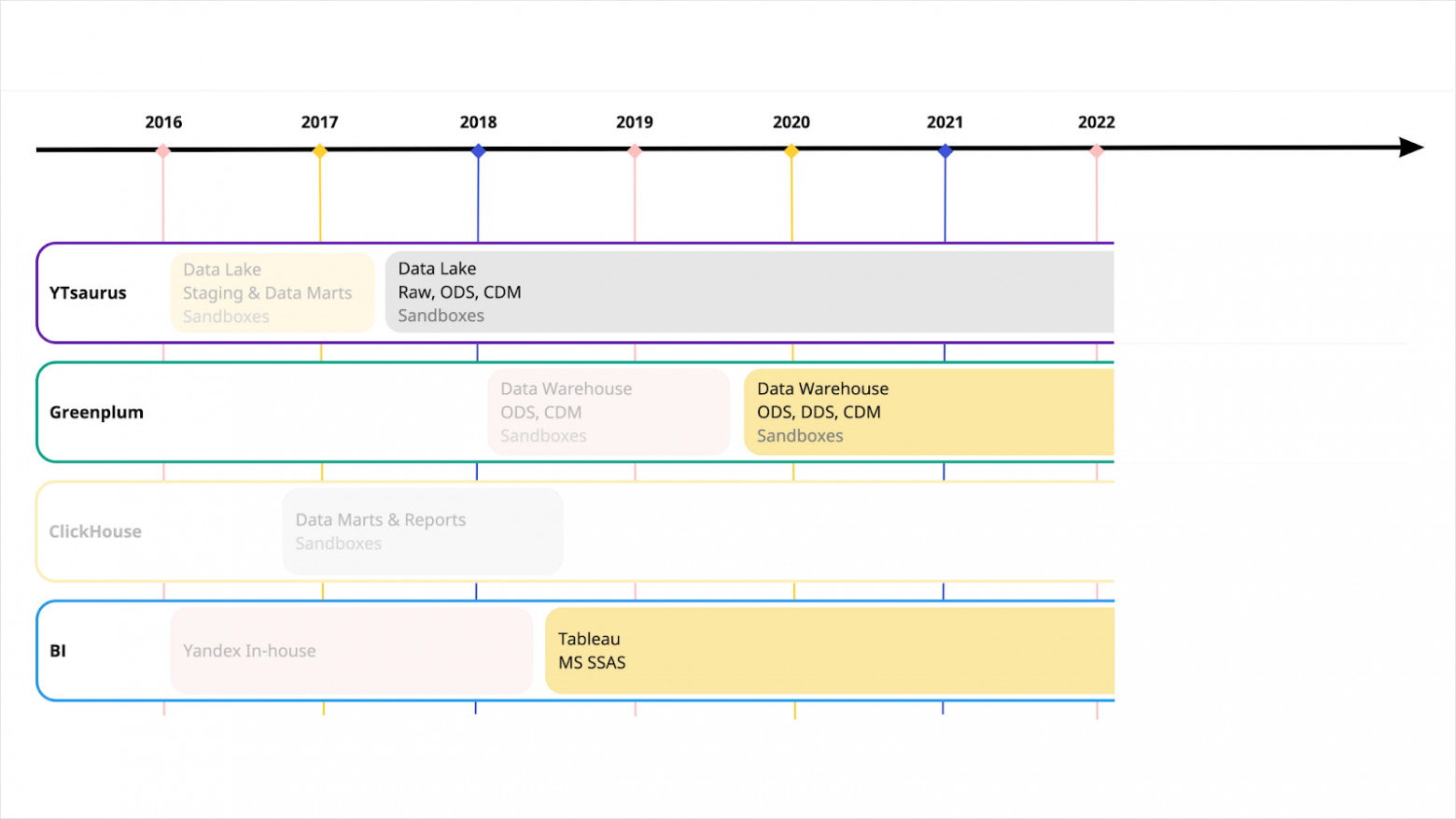
На рубеже 2019 и 2020 годов у нас получилось адаптировать Apache Spark™ для работы с YTsaurus. На тот момент в YT для батч‑вычислений был доступен только MapReduce и YQL (SQL‑диалект) поверх MapReduce, а у нас был запрос на более шустрый вычислительный движок.
К 2022 году огромное центральное DWH у нас разделилось на несколько хранилищ для отдельных бизнес‑юнитов. Каждый из них стал фокусироваться на прикладных задачах своего сервиса. И, соответственно, выделилась команда платформы, развитием которой я занимаюсь.
В 2022 году нам пришлось быстро отказаться от Tableau. Мы переезжали в DataLens, и, чтобы он заработал, нужно было обеспечить возможность построения live‑отчётов. Поверх Greenplum® такая схема работает плохо, особенно когда Greenplum‑кластер загружен очень сильно, как у нас. Поэтому в наш стек вернулся ClickHouse®.
Итак, на данный момент у нас есть Data Lake на YTsaurus, есть хранилище данных Greenplum®. Есть ClickHouse®, DataLens и OLAP‑кубы (MS SSAS), которые продолжают помогать компании решать свои задачи.
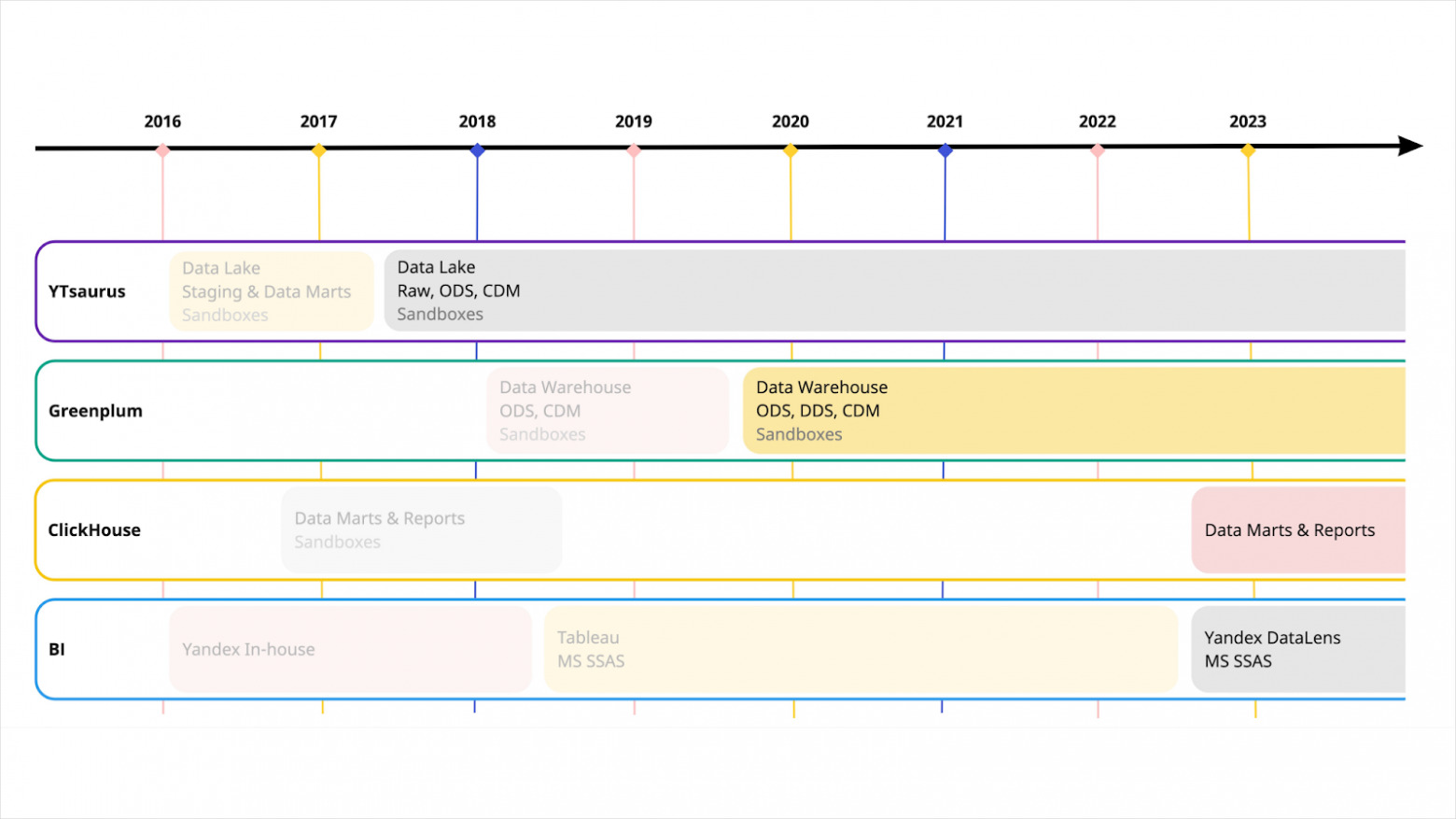
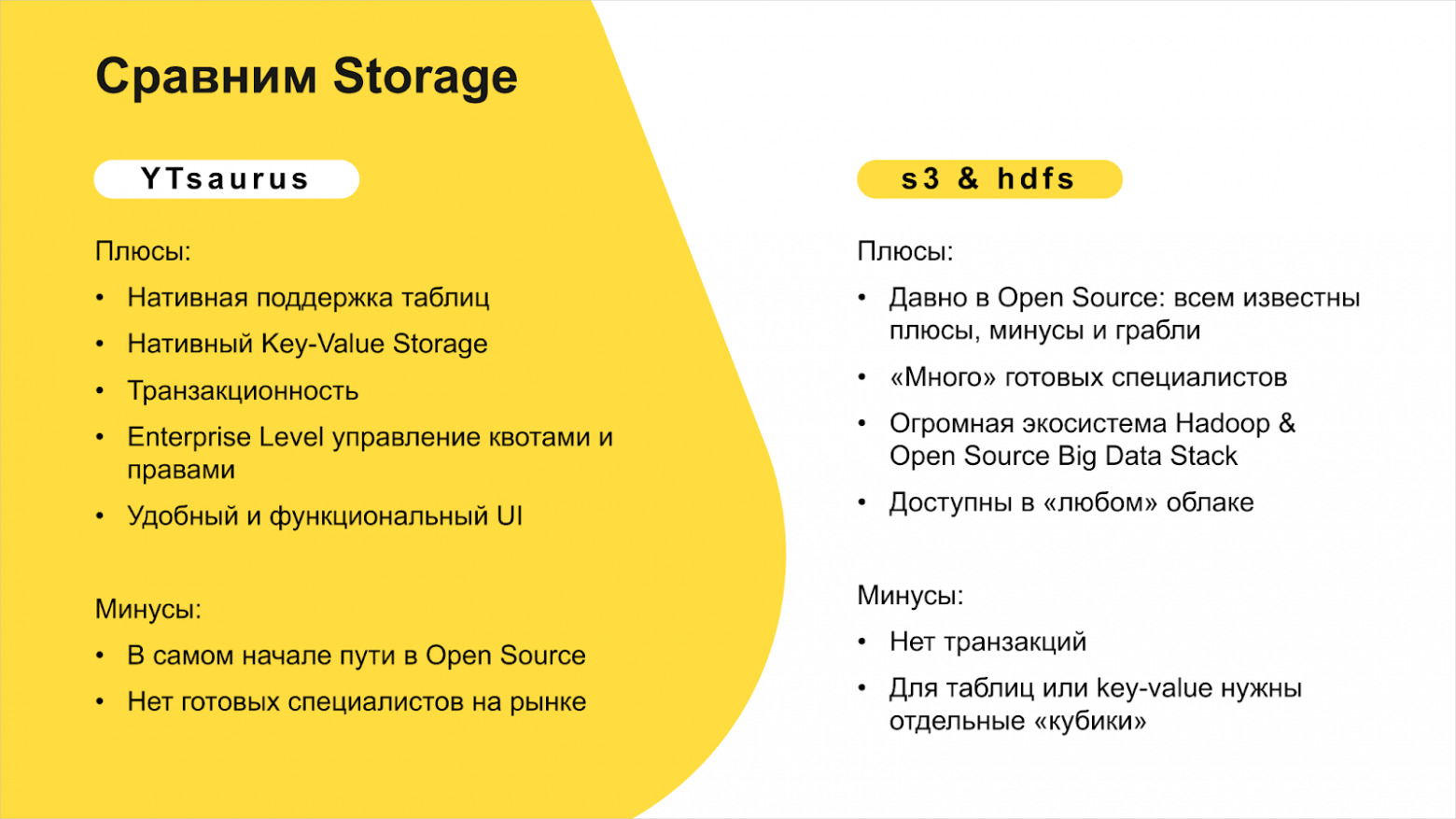
В нашей истории можно заметить, что наиболее стабильная часть всей инфраструктуры — YTsaurus. Мы работаем с ним с самого начала проекта, и в сценариях его использования было минимум изменений. Поэтому я и хочу рассказать про него отдельно.
Решение для хранения данных в Яндекс Go: YTsaurus
Основные составляющие YTsaurus:
- Cypress («Кипарис») — распределённая файловая система и хранилище метаинформации.
- Планировщик ресурсов для MapReduce и других типов вычислений.
- Различные вычислительные движки.
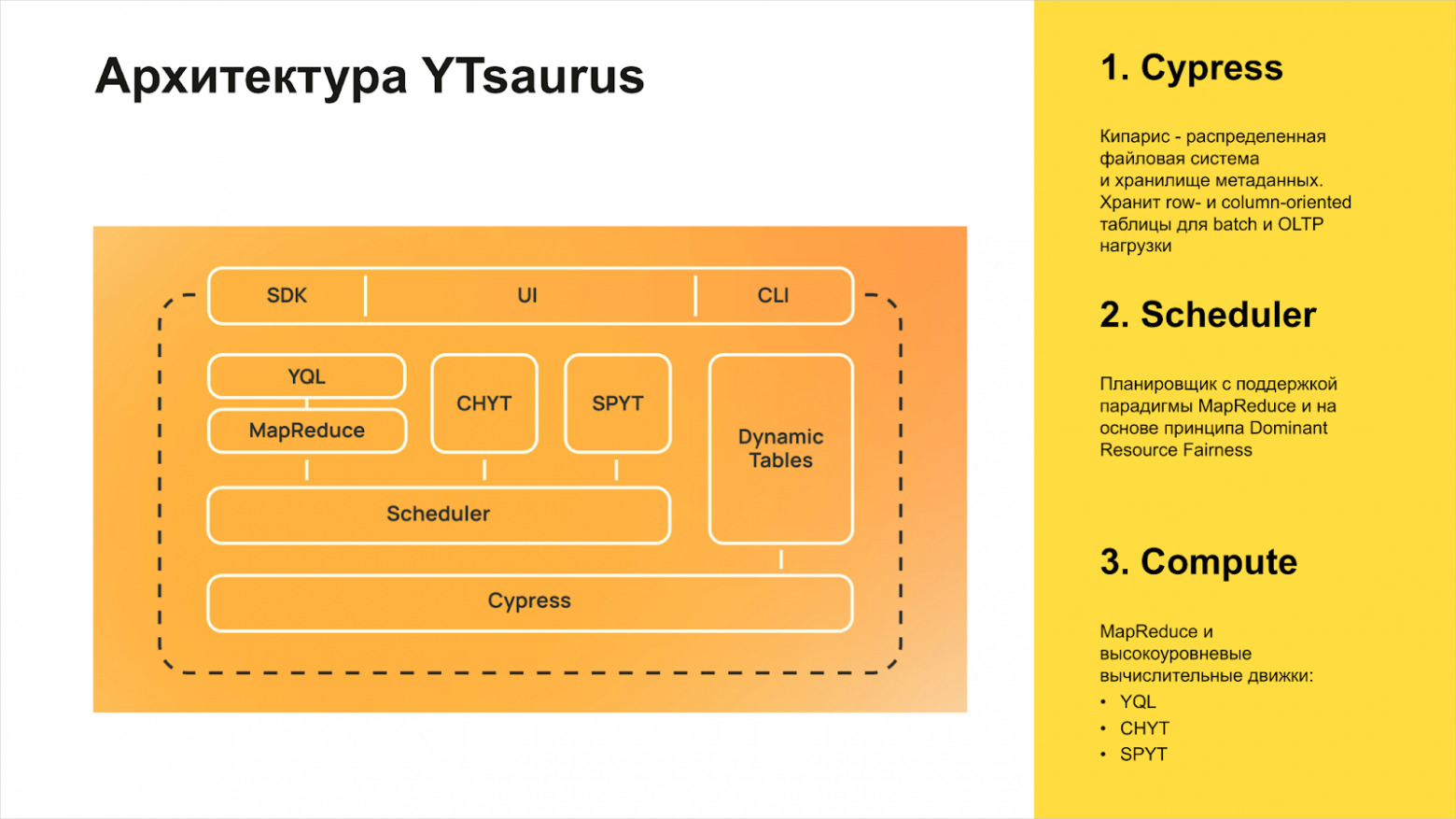
Хочется подчеркнуть, что у YT есть удобный интерфейс, из которого можно узнать всё про процессы, данные, где что падает и не падает, сколько ресурсов затрачивается и так далее. Он решает как задачи пользователя кластера, так и задачи админа.
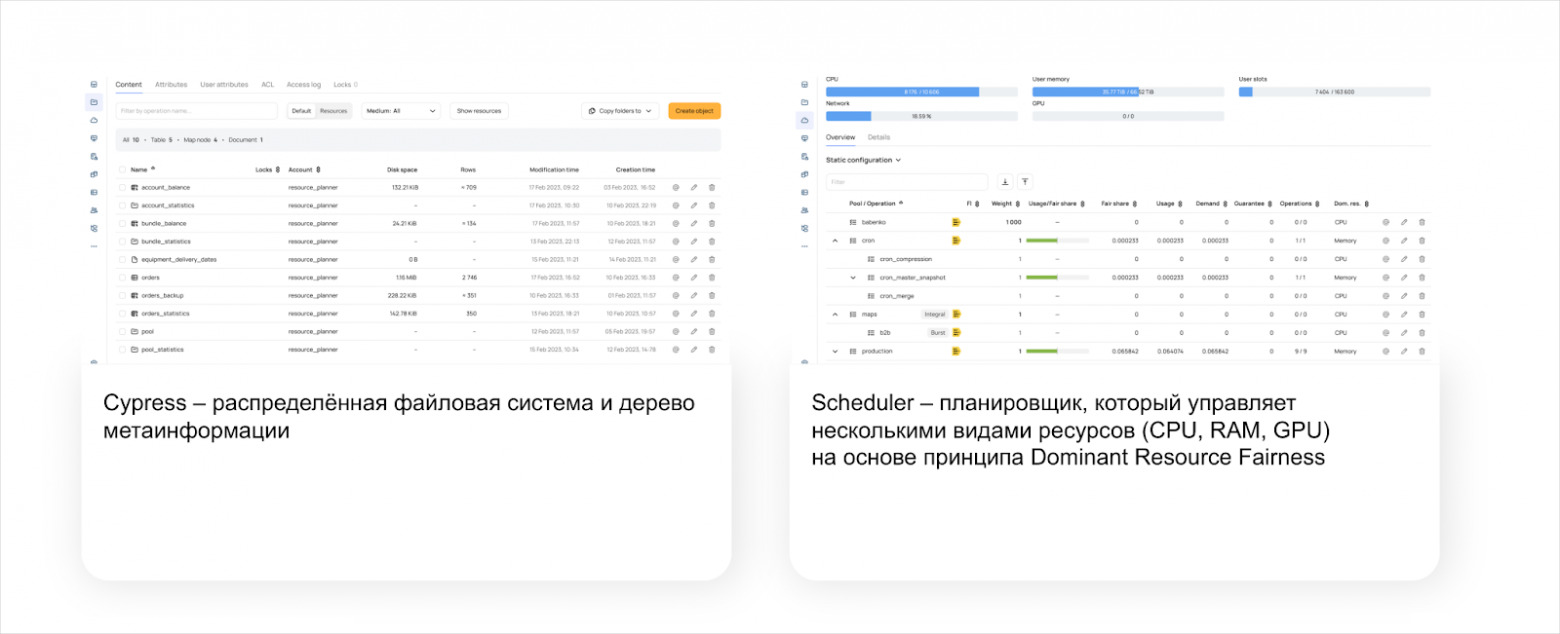
Хранение данных: Cypress
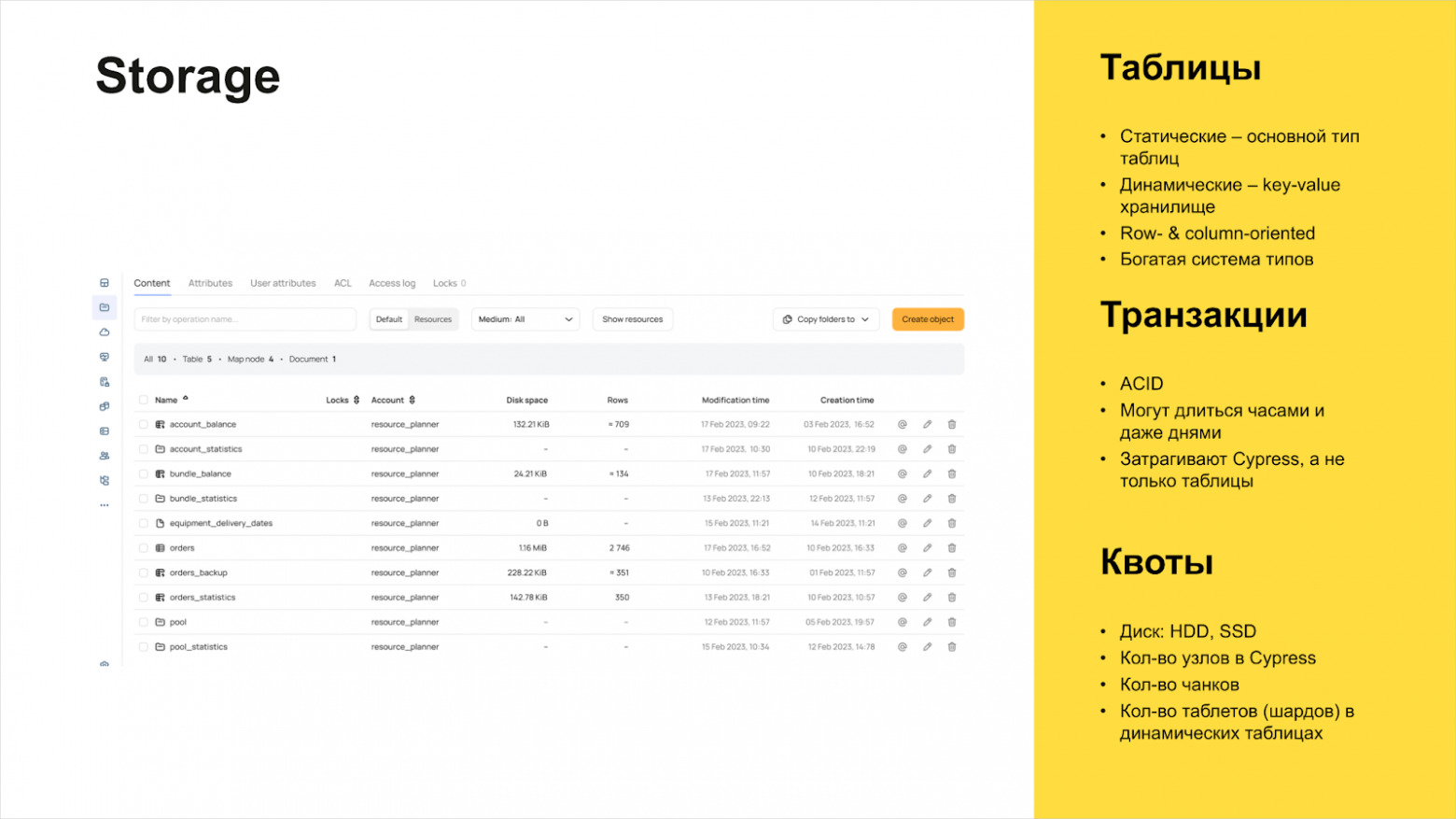
В YT есть статические и динамические таблицы. Статические можно упрощённо считать файликами, которые лежат где‑то в распределённой файловой системе и используются для «больших» батчевых расчётов. Но при этом есть возможность указать схему таблицы, в том числе со «сложными» типами (массивами, словарями и т. п.). Можно управлять сортировкой данных и гарантировать уникальность данных по ключу сортировки. Статические таблицы у нас используются для хранения логов или бизнес‑данных, которые меняются не слишком часто.
Динамические таблицы — это key‑value‑хранилища. Мы используем динамические таблицы в ETL‑процессах для построения ODS (Operational Data Store) с минимальной задержкой от источника.
У обоих видов таблиц может быть построчное или колоночное хранение.
Есть множество возможностей для управления размером таблиц:

Данные могут быть сжаты, есть большой выбор кодеков, и можно спокойно выбирать, что важнее: сэкономить диск или потратить больше CPU. Можно управлять TTL (Time To Live), то есть можно указывать, что данные в системе необходимо в какой‑то момент почистить. И есть разные настройки избыточности хранения: репликация и erasure‑кодирование. Можно эмулировать партиционирование через использование папок и таблиц внутри них.
Мы активно применяем различные кодеки для сжатия данных и erasure‑кодирование для экономии диска при хранении редко используемых исторических бизнес‑данных и логов.
В YT в рамках одной транзакции мы можем, например, взять, посчитать на протяжении недели или даже большего промежутка времени какую‑нибудь тяжёлую большую табличку или даже несколько таблиц, а потом незаметно для пользователя её подменить. Это круто, потому что никто не видит этого момента. Все прекрасно продолжают работать с данными, запросы на чтение не падают, ничего не падает, все счастливы. Это достигается за счёт хорошо развитой системы блокировок. Например, есть snapshot‑блокировка, которая гарантирует, что в рамках своей операции вы будете видеть тот слепок данных, который был на момент её начала, и не будете страдать от того, что он как‑то изменился или пропал.
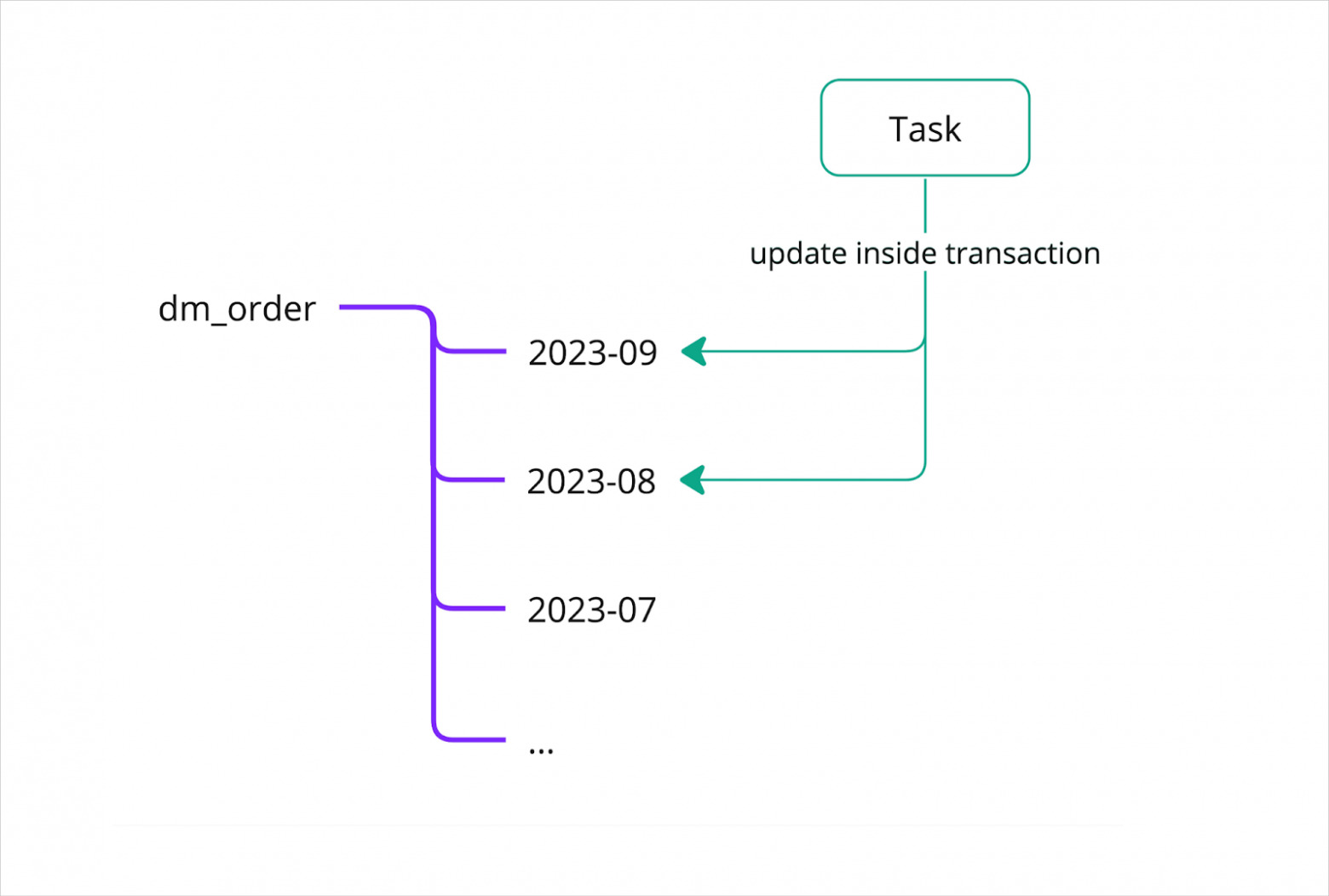
Мы активно пользуемся такой фичей при масштабных пересчётах истории. Благодаря такому подходу пересчёты истории не вызывают боли у пользователей данных.
В большой компании важно уметь в рамках одной системы управлять всем возможным, чтобы люди не могли повредить продпроцессы. У YT есть иерархические аккаунты, при помощи которых можно управлять дисковым хранением, регулировать количество объектов. Это удобно и полезно при большом количестве пользователей и критично, когда их тысячи. Квоты видны и управляются через интерфейс. За счёт квотирования решается задача изоляции пользователей друг от друга, продпроцессов от ad‑hoc и т. п.
Внутри наших бизнесов используются разные аккаунты для продпроцессов разных владельцев. В некоторых случаях мы допускаем overcommit по квотам, чтобы лучше их утилизировать.
В YT — развитая система управления доступами. На каждый объект можно повесить свой access control list, или ACL, в котором указывается список или группы пользователей, которые могут иметь доступ к этим данным.
Далее рассмотрим различным вычислительные движки.
Compute
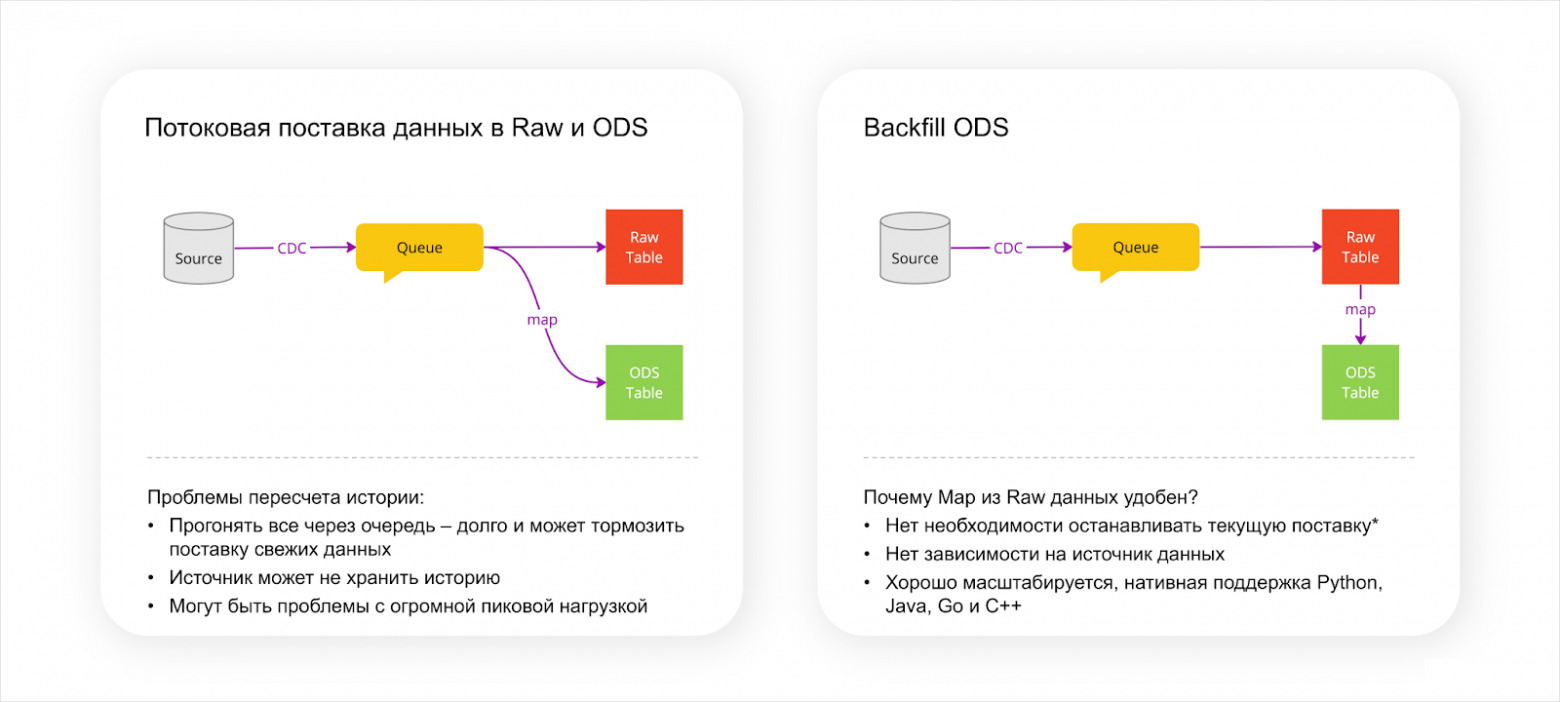
И начнём с MapReduce. Представим наш сценарий поставки данных в операционный слой — это некоторое преобразование на лету. Допустим, нам нужно его пересчитать целиком, а ходить для этого в источник весьма энергозатратно. Тогда мы строго регламентируем то, что может быть в этом преобразовании, и запускаем для пересчёта истории это преобразование в виде map‑операции на YT поверх сырых данных. Это удобно и дёшево, потому что не требуется какая‑то супервысокая скорость обработки данных, а нужна эффективность и надёжность. Так мы получаем систему, в которой в принципе даже не всегда нужно отключать текущую поставку для пересчёта истории.
В YT есть SQL‑подобный язык YQL. Он может работать поверх MapReduce и при помощи движка, который выполняет вычисления в памяти при определённых условиях. Его можно дополнять своими UDF, например написанными на C++ или Python. Для YQL есть очень удобный интерфейс с историей всех запросов и возможностью их «шарить» между пользователями.
Мы пользуемся YQL для обработки наиболее «жирных» логов и расчёта витрин, которые не требуют особой оперативности.
SPYT powered by Apache Spark
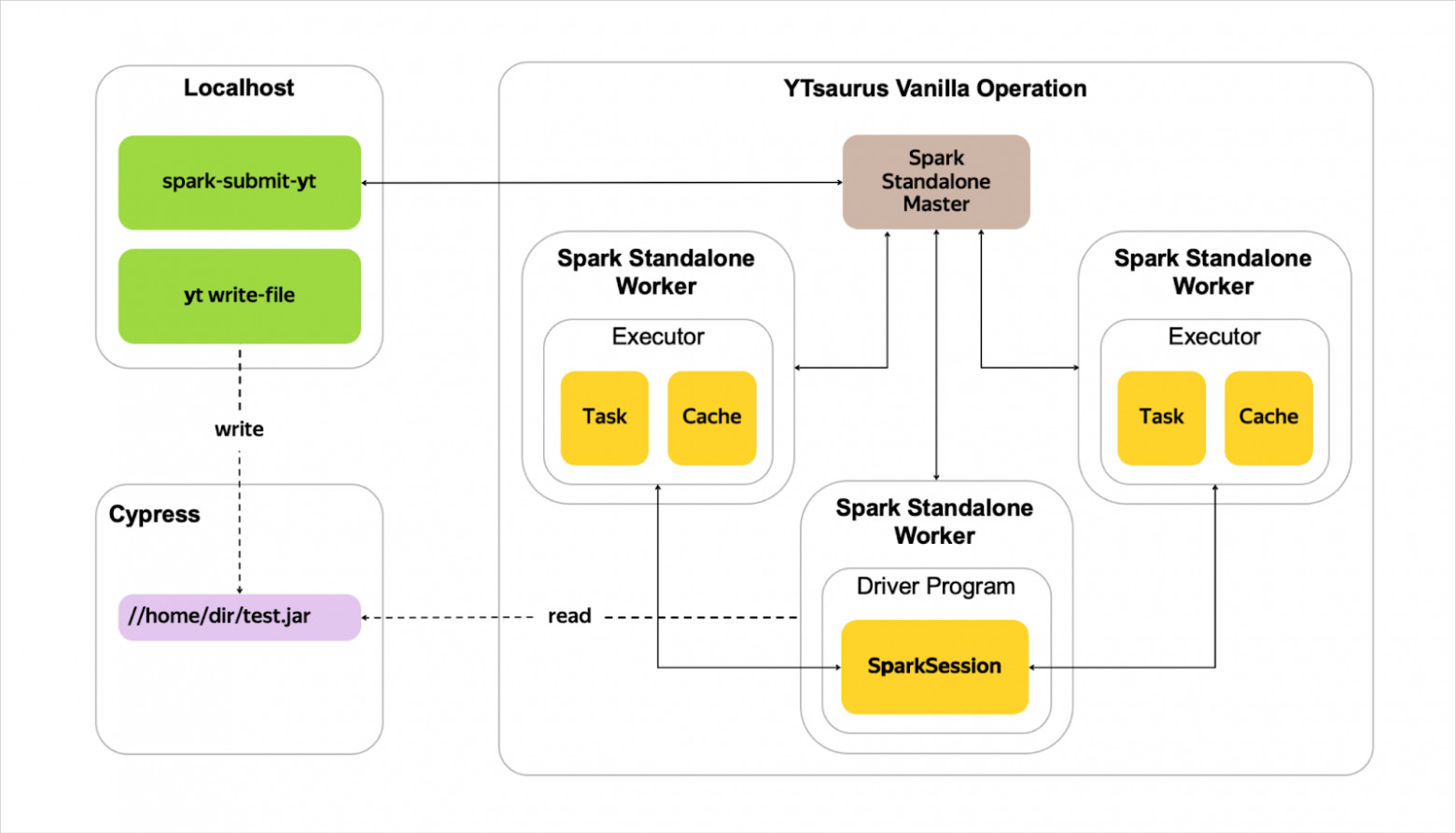
Spark в Яндексе появился на рубеже 2019–2020 годов по инициативе нашей команды. В YT он может работать как Spark Standalone Cluster, когда Spark сам управляет своими ресурсами и живёт полностью внутри YT. В Standalone Cluster поддержаны Client Mode (клиентский режим) и Cluster Mode. Помимо этого, начиная со SPYT 1.76.0, поддержан запуск Spark‑приложений непосредственно через планировщик YTsaurus без необходимости запуска Standalone‑кластера.
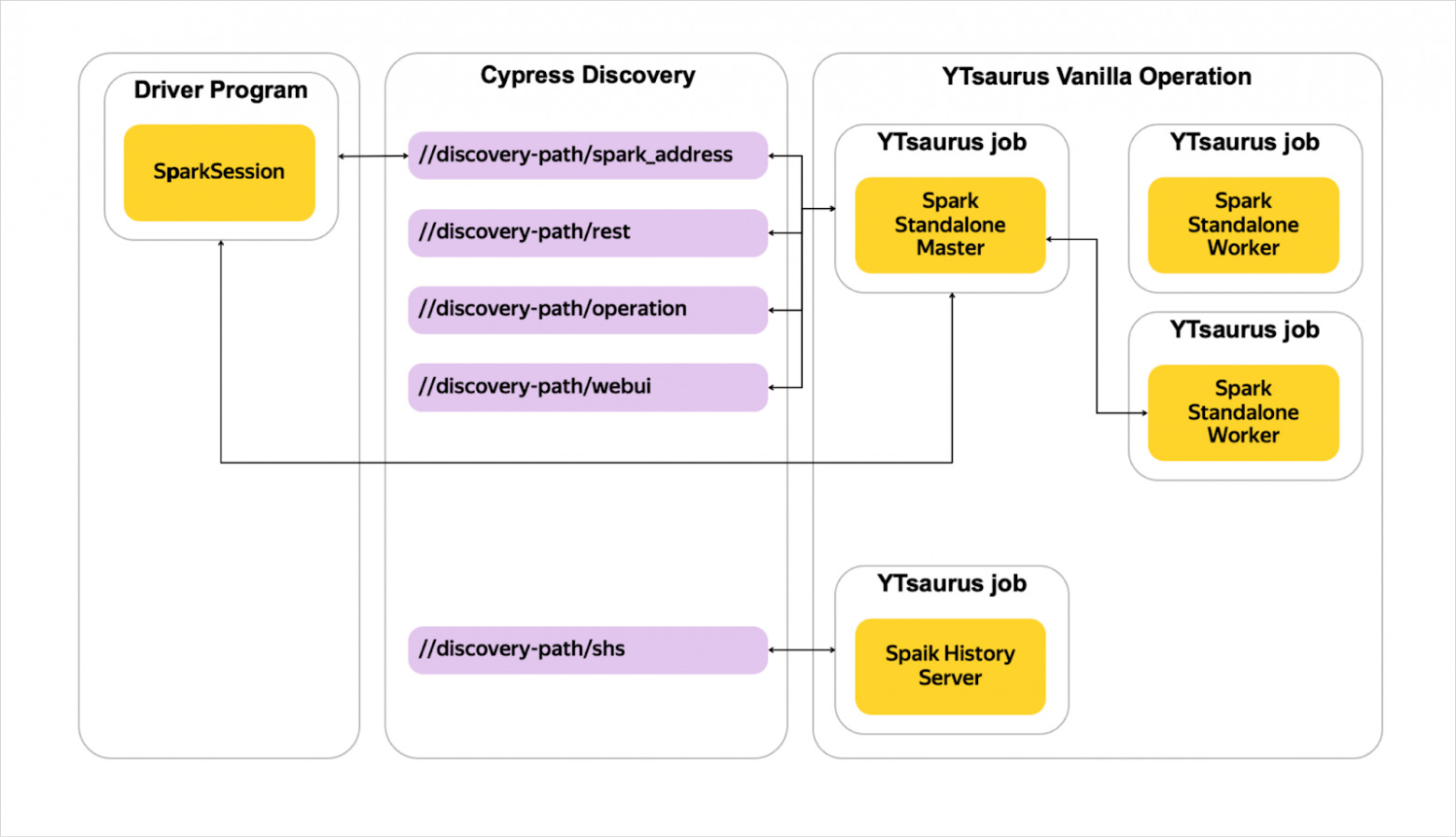
Мы активно используем Spark для обработки инкремента, расчёта витрин со сложной бизнес‑логикой и других сценариев, где требуется скорость работы и данные помещаются в памяти, которая нам доступна.
Bl-сценарии
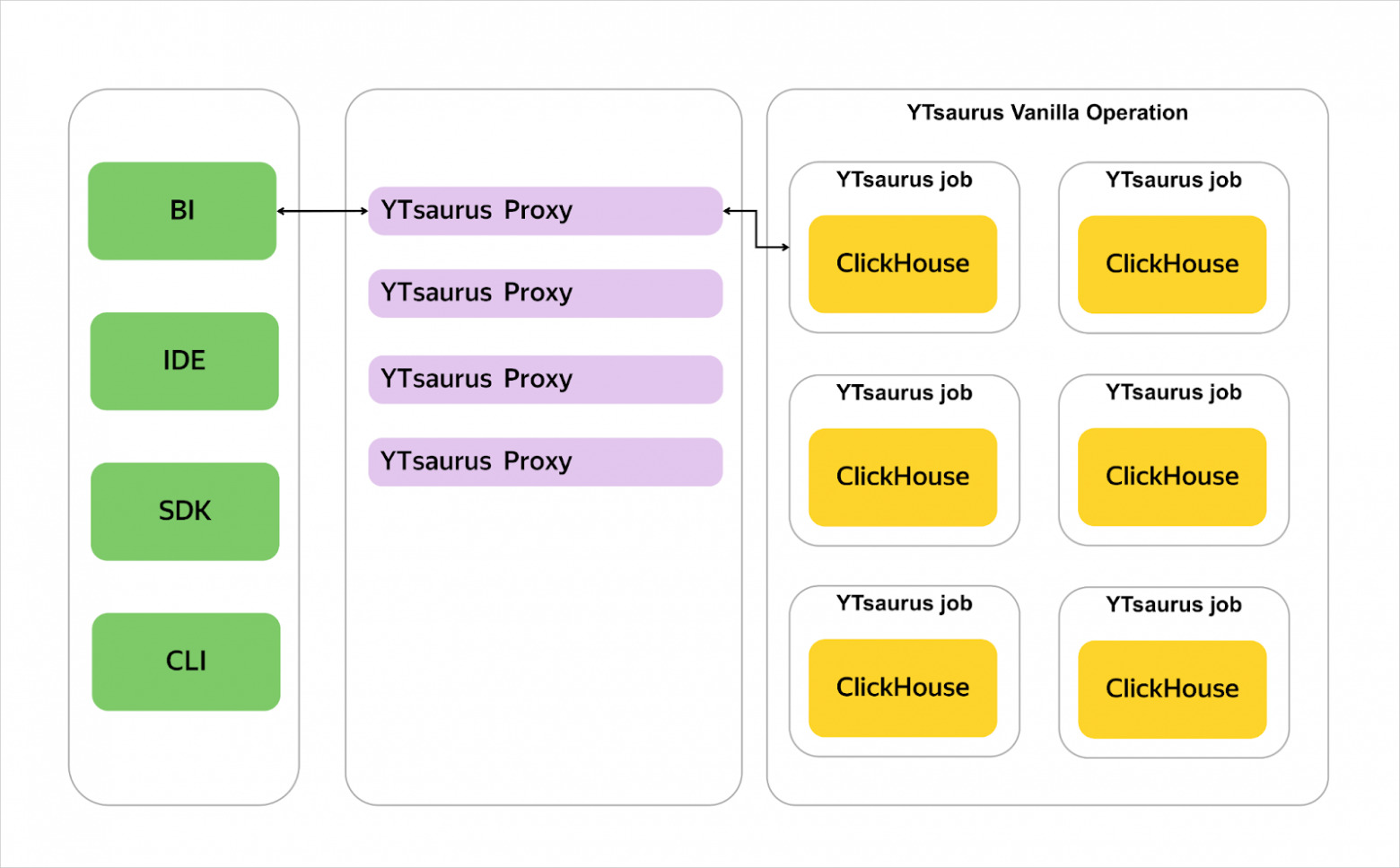
CHYT powered by ClickHouse® работает несколько медленнее, чем обычный локальный ClickHouse®, но для многих отчётов его производительности более чем достаточно. Также важно заметить, что скорость работы CHYT правильнее сравнивать с ClickHouse® Cloud или ClickHouse® over S3, и CHYT сопоставим с ними. В результате можно решать BI‑сценарии и делать ad‑hoc‑аналитику, не копируя данные в более быстрые хранилища.
CHYT активно используется для построения отчётности в Такси, Еде, Лавке и Доставке. В локальный ClickHouse® реплицируются данные только для наиболее критичной и популярной отчётности.
Планировщик и пулы
Всё вышеперечисленное работает за счёт хорошо развитого планировщика и системы вычислительных пулов.

Планировщик управляет ресурсами, пулы могут быть выстроены в иерархию, которая гарантирует изоляцию и переиспользование ресурсов в рамках дерева, и это удобно, потому что можно какие‑нибудь пулы приоритизировать за счёт их веса.
На картинке выше видно, что мы в рамках одного бизнеса делаем один большой корневой вычислительный пул, который далее распределяется по разным пользователям с разными паттернами нагрузки. Каждый большой пользователь внутри своего пула может создавать дополнительные вычислительные пулы со своими гарантиями для более тонкой настройки своих процессов.
Можно подвести итог, что YTsaurus — это платформа, внутри которой тесно интегрировано множество полезных инструментов для различных сценариев. Мы планируем и дальше активно использовать YT. Надеюсь, что скоро мы будем готовы рассказать про использование YTsaurus в сценариях потоковой обработки данных и про его интеграцию с Apache Flink®.
Если говорить о платформе, то есть о сложном продукте, важно опираться на опыт, который есть у вас и ваших коллег, и не забывать о best practice.
Важно идти от требований: нет смысла сразу делать какую‑то мегасложную архитектуру, её можно развивать постепенно. Наш пример показывает, что это работает, и не нужно бояться экспериментировать. Эксперименты — это точно путь к успеху:)



