
Порой простое и очевидное решение может потянуть за собой хвост проблем в будущем. Например, добавление ретраев.
Меня зовут Денис Исаев, и я работаю в Яндекс Go. Сегодня я поделюсь опытом решения проблем с отказоустойчивостью из-за ретраев. Основано на реальных инцидентах в системе из 800 микросервисов.
Этот пост — продолжение вымышленных историй о разработчике Васе, который несколько лет назад разбирался с идемпотентностью в распределённых системах. Теперь перед ним новые задачи — получится ли справиться с ними в этот раз? Давайте узнаем.

Терминология
Прежде чем перейти к новой истории про Васю, сделаю пару замечаний, чтобы у читателя не возникло недопониманий:
- Клиент — в контексте этой статьи это бэкенд-микросервис, который отправляет запрос в другой бэкенд-микросервис. Там, где этот термин обозначает мобильное приложение или фронтенд, об этом написано явно.
- Сервер или сервис — взаимозаменяемые термины для обозначения бэкенд-микросервиса, в который клиент делает запросы.
Зарождение ретраев
Бэкенд-разработчик Вася работал в команде платформы заказов одного из приложений Такси. В один из дней он изучал жалобу пользователя об ошибках в приложении. В логах сервиса заказов были пятисотки из-за тайм-аута к сервису цен. «Опять флапнуло», — подумал Вася и решил добавить три перезапроса при ошибках от сервиса цен. Вася решил, что это было безопасно, ведь все API были идемпотентны. Такие перезапросы часто называют ретраями (от англ. retry).
Перезапросы, которые добавил Вася, были реализованы как простой цикл. На код-ревью тимлид продуктовой команды Олег рассказал Васе о проблеме retry storm: когда сервису цен станет плохо, ретраи добьют его и замедлят восстановление. Олег подсказал, что у этой проблемы есть решение в виде exponential backoff.
Exponential backoff в виде псевдокода:
MAX_RETRY_COUNT = 3
MAX_DELAY_MS = 1000
DELAY_BASE_MS = 50
attempt_count = 0
max_attempt_count = MAX_RETRY_COUNT + 1
while True:
result = do_network_request(...)
attempt_count += 1
if result.code == OK:
return result.data
if attempt_count == max_attempt_count:
raise Error(result.error)
delay = min(DELAY_BASE_MS * pow(2, attempt_count), MAX_DELAY_MS)
sleep(delay)
Прошлый руководитель Васи научил его, что алгоритмы в распределённых системах сложно тестировать и валидировать в корнер-кейсах. Поэтому удобно использовать симуляции — моделирование работы алгоритмов с преднамеренным упрощением системы. Пускай это менее реалистично, чем воспроизводить корнер-кейсы и проводить нагрузочное тестирование, зато делается быстрее.
Вот Вася и решил проверить с помощью симуляции, правда ли exponential backoff так сильно помогает.
Симуляция показала: есть польза от exponential backoff
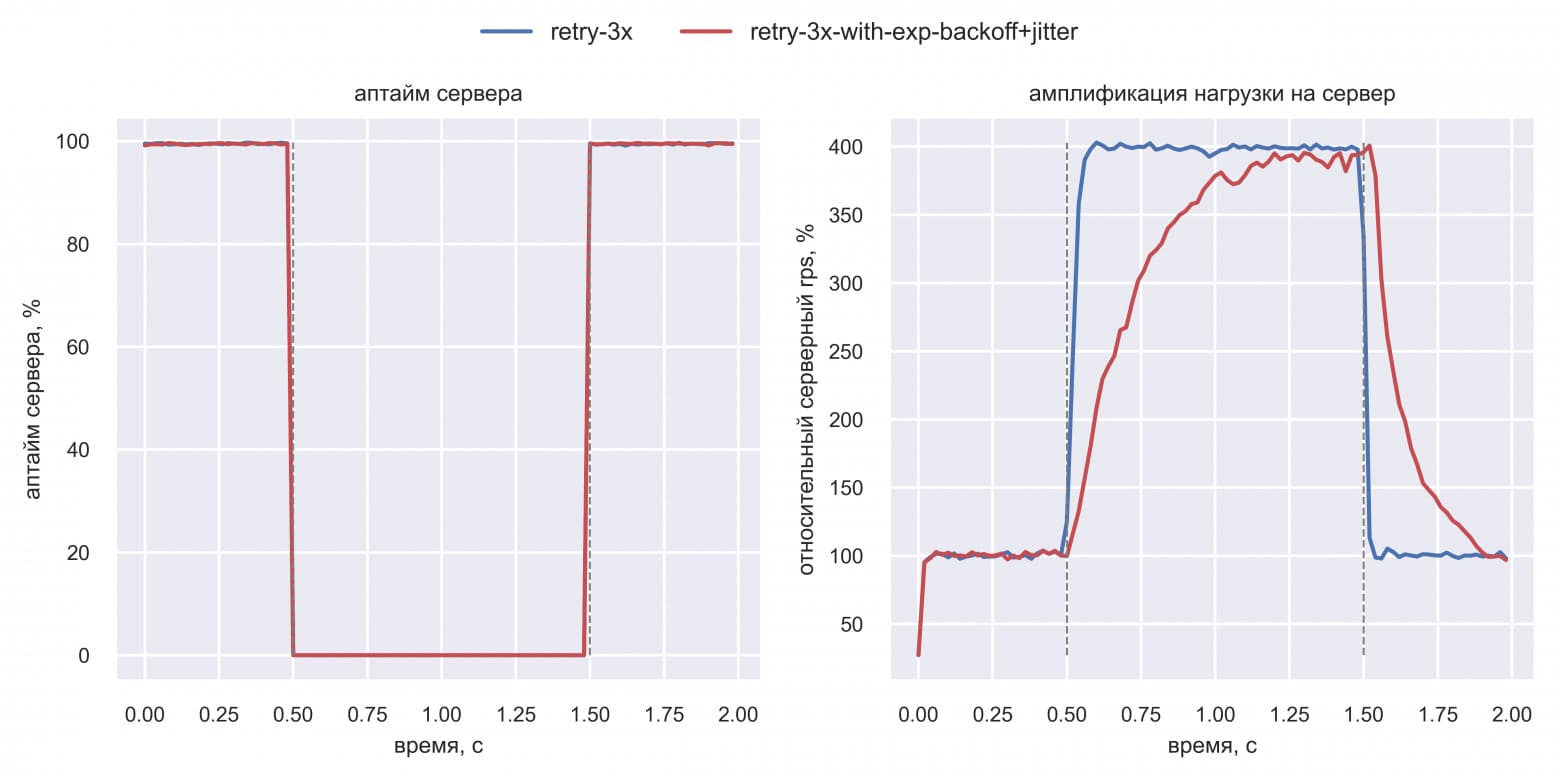
В симуляции задействованы клиенты и сервер. Каждый клиент делает один запрос и ждёт ответа с тайм-аутом 100 мс. В интервале [0.5 с; 1 с] эмулируется даунтайм сервера: он специально отдаёт ошибку на 100% запросов (график «Аптайм сервера») с обычным latency ответа (10 мс + 5 мс на сетевой round-trip). Клиент ретраит ошибку или тайм-аут три раза, совершая в общей сложности до четырёх запросов. Сначала Вася запустил симуляцию простых ретраев:
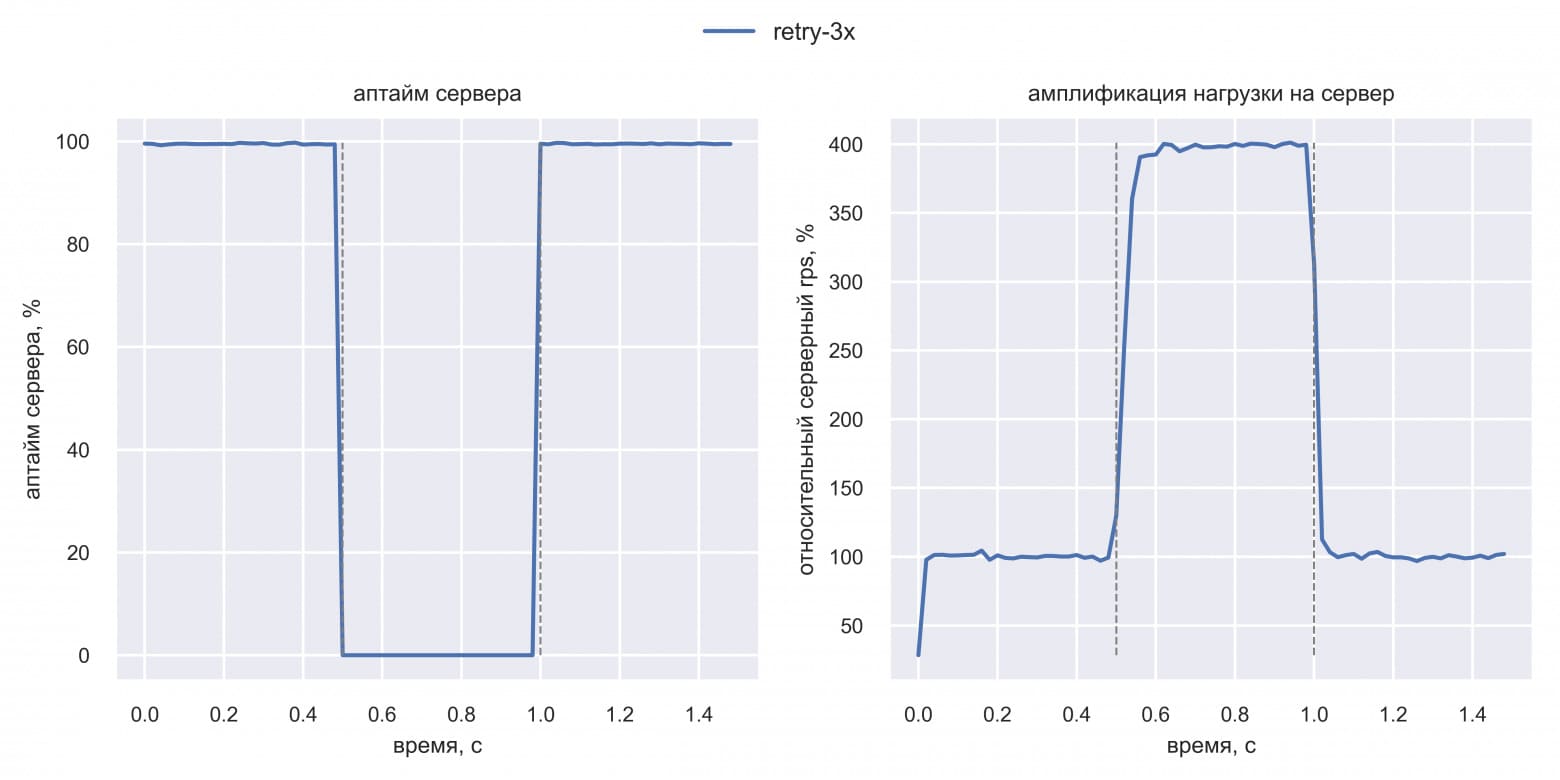
График «Амплификация нагрузки на сервер» показал, что серверный RPS вырос в четыре раза после начала ретраев. Такой рост числа запросов без роста естественной нагрузки назовём амплификацией нагрузки. Затем Вася попробовал применить exponential backoff в симуляции:
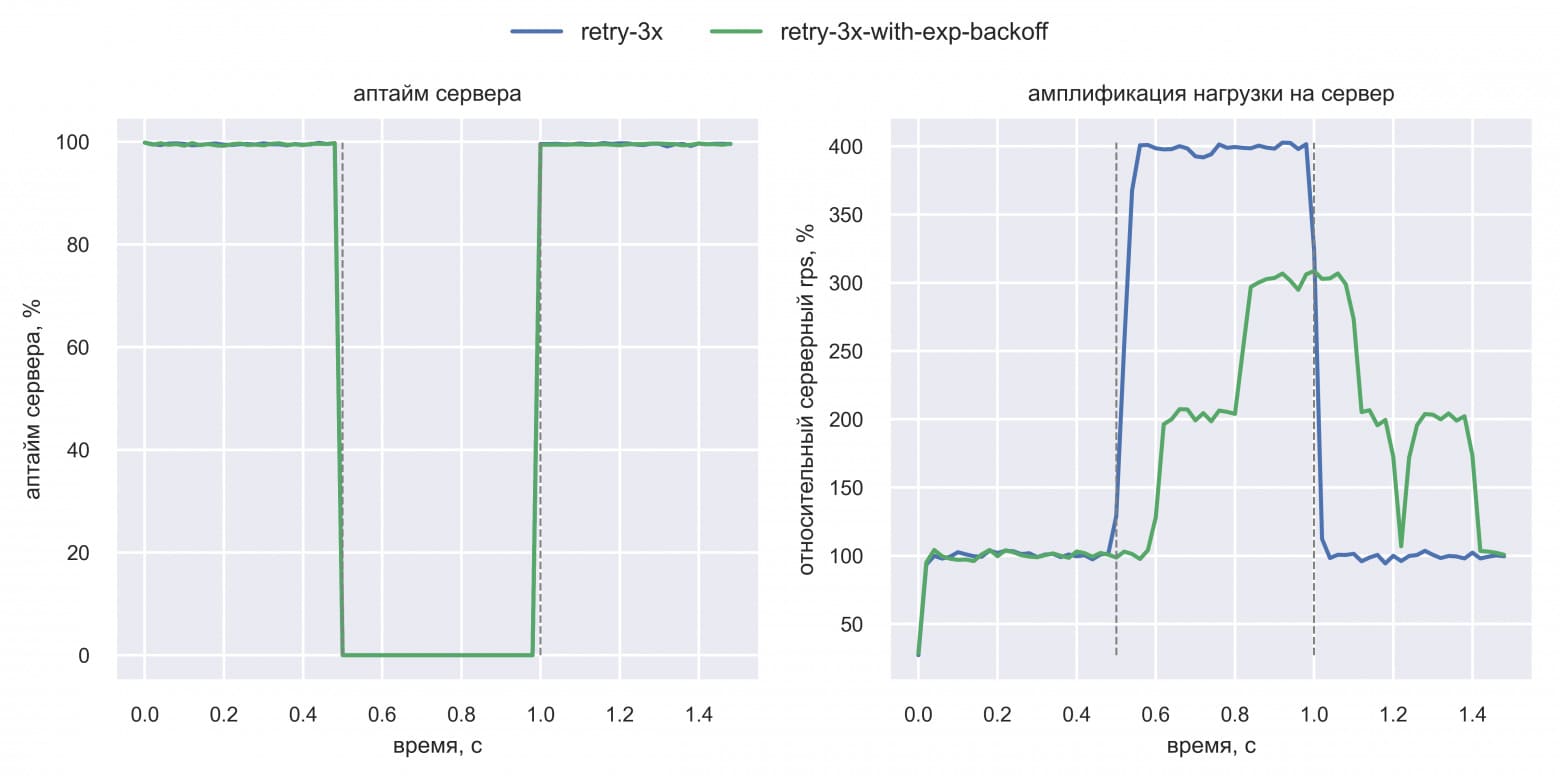
Польза от exponential backoff (зелёная линия) подтвердилась: амплификация нагрузки сильно уменьшилась. Однако Васе показалось странным, что нагрузка на сервер растёт скачкообразно при использовании exponential backoff, но он не знал, как это объяснить.
Олег удивился, что в симуляции эффект от exponential backoff такой слабый. Изучив код симуляции, он увидел, что новые клиенты создаются независимо от здоровья сервера. То есть связка «клиенты + сервер» моделируется как система без отрицательной обратной связи (open loop). Это как кондиционер без датчика текущей температуры: он просто всегда охлаждает. В то время как хороший кондиционер адаптирует мощность охлаждения в зависимости от близости текущей температуры помещения к целевой температуре. Такие системы с отрицательной обратной связью называются closed loop системами.
Олег знал, что exponential backoff особенно хорошо работает как раз в таких closed loop системах. И Вася спросил: «Насколько это вообще реалистично? Точно ли наш production — это closed loop?»
«Наш production не closed loop, но обладает некоторыми его элементами. Например, многие сервисы работают по модели «1 запрос – 1 поток» с ограничением на число потоков. Если latency запросов к другому сервису сильно растёт, все потоки становятся заняты ожиданием ответа от другого сервиса. Поэтому новый запрос в другой сервис не сформируется, пока не завершится хотя бы один старый запрос. Получается цикл обратной связи», — подытожил Олег.
В closed loop симуляции эффект от exponential backoff намного больше
Вася добавил в симуляцию лимит на количество активных клиентов: ожидающих ответа сервера или спящих между ретраями.
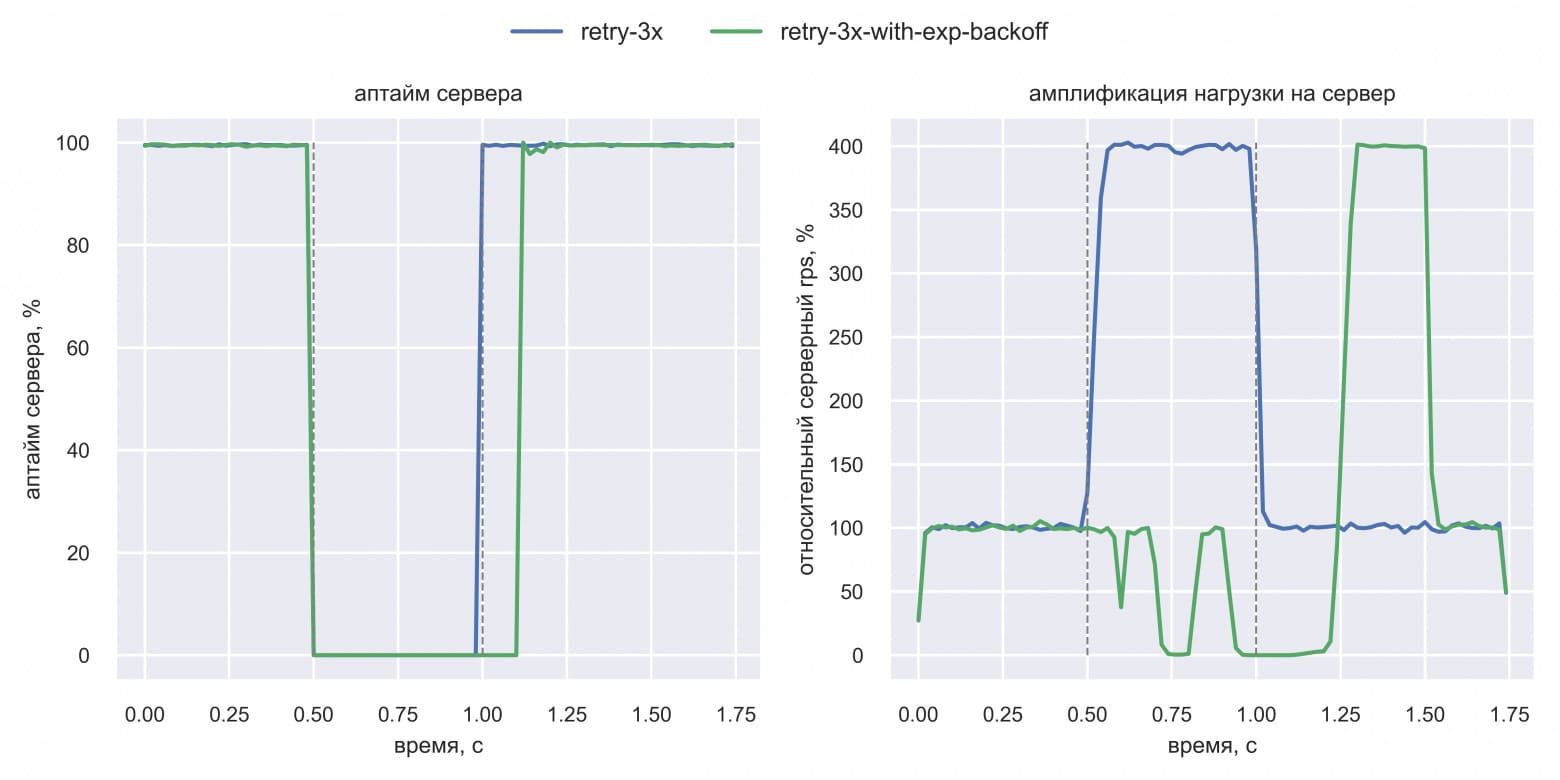
В closed loop системе амплификация нагрузки стала заметно меньше в период даунтайма сервера. Отрыв exponential backoff от простых ретраев стал значительно больше. Вася стал разбираться, почему же так произошло. Он быстро понял, что в момент даунтайма:
- Растёт latency запросов из-за экспоненциальных пауз между ретраями.
- Из-за этого растёт количество активных клиентов (закон Литтла: при росте latency в 5 раз число активных клиентов тоже вырастает в 5 раз).
- Следовательно, система быстро упирается в лимит на количество активных клиентов.
- После этого новые запросы на сервер не формируются, пока не завершится хотя бы один активный запрос.
- Поэтому нагрузка на сервер уменьшается. И снова Вася заметил странные артефакты на графике амплификации нагрузки: синусоиды RPS. Оказалось, что все клиенты, получившие первую ошибку в t=0.5 с, ждут одинаковую задержку 0.1 с. Вскоре после этого, как только достигнут лимит на число активных клиентов, новые запросы перестают отправляться на сервер. Но и старые не отправляются, потому что они ждут 0.1 с. Этим объясняется первый провал в t=0.6 с. Затем всё те же клиенты ждут 0.2 с, а новые клиенты не могут сформировать новые запросы, потому что ни один активный клиент ещё не завершил все три ретрая. Это объясняет провал в t=0.8 с. Клиенты волнами шлют запросы, синхронизировавшись друг с другом. При этом нагрузка на сервер пониженная, что неэффективно утилизирует его ресурсы. Резкий рост RPS после восстановления в t=1.25 с — это следствие такой неэффективности. Дело в том, что все ожидающие клиенты перестают упираться в лимит и массово шлют запросы.
Вася убедился, что exponential backoff точно стоит применить. Осталось решить проблему синхронизации между клиентами, найденную в симуляции.
Синхронизация между клиентами
Во всех симуляциях Вася обнаружил проблему: при даунтайме клиенты могут синхронизироваться между собой и начать слать запросы в одни и те же моменты времени.
Вася нашёл в интернете решение: добавить случайную задержку (jitter) в паузу между ретраями. Такой jitter можно добавить разными способами. Вася решил использовать метод Full Jitter.
jitter в виде псевдокода:
… # Такой же код, как выше в exponential backoff
while True:
… # Такой же код, как выше в exponential backoff
delay = min(DELAY_BASE_MS * pow(2, attempt_count), MAX_DELAY_MS)
delay = random_between(0, delay)
sleep(delay)
И снова Вася решил провалидировать идею jitter с помощью симуляции.
Симуляция подтвердила, что jitter уменьшает синхронизацию клиентов
Вася добавил в симуляцию jitter методом Full Jitter и получил такие графики:
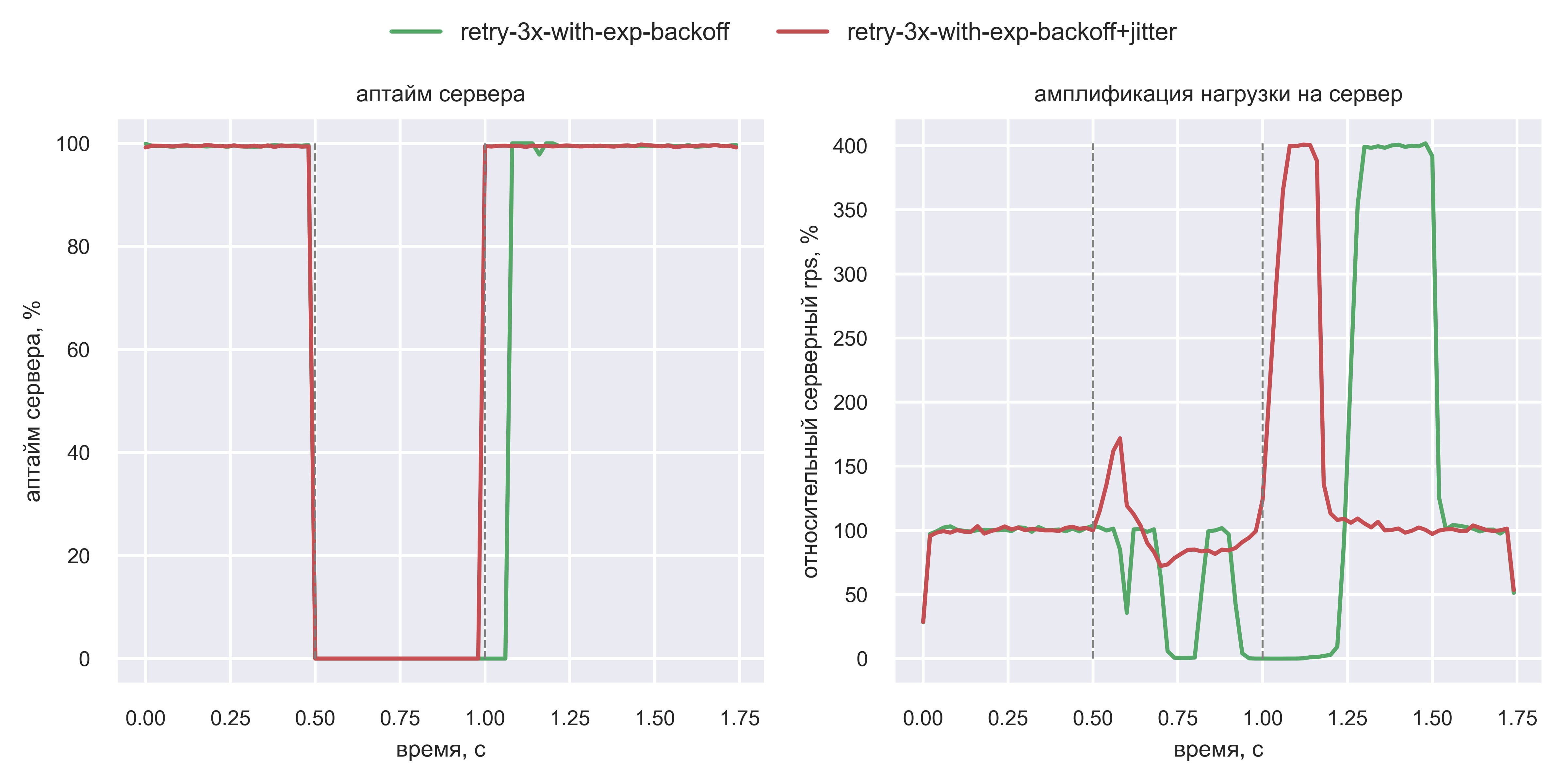
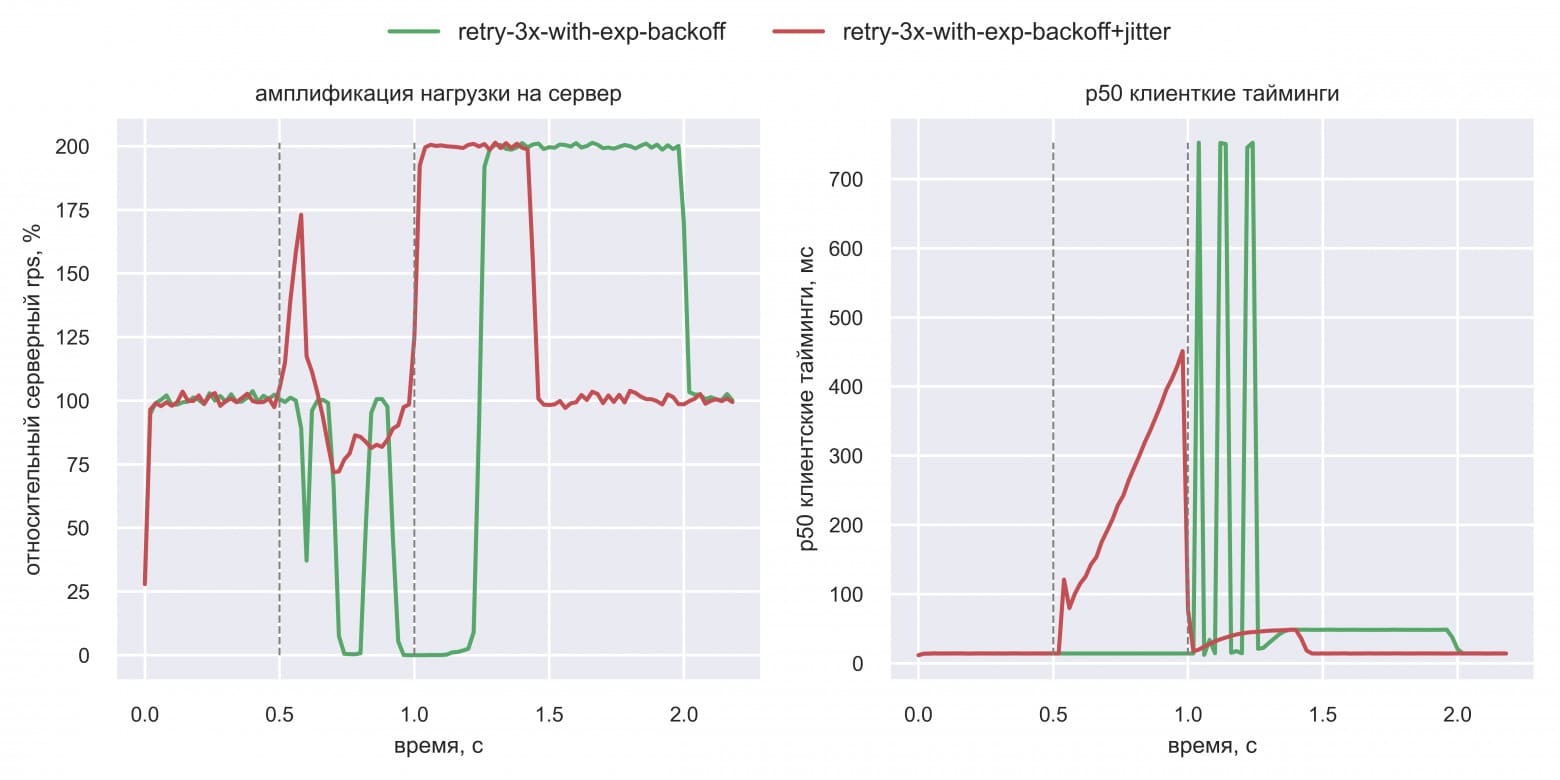
При использовании jitter (красная линия) нагрузка на сервер более равномерная во время даунтайма. Это значит, CPU сервера простаивает меньше, а пик амплификации нагрузки после даунтайма приходится раньше (t=1.1 с против t=1.25 с) и будет меньшей длины. В итоге система быстрее восстанавливается. Вася поигрался с параметрами симуляции и обнаружил интересный момент: эффект от добавления jitter ещё более заметен при уменьшении запаса по CPU (вместо 4x — 2x) и наблюдении за клиентскими таймингами. Вот что получилось:
Итак, Вася успешно провалидировал, что jitter помогает уменьшить синхронизацию между клиентами и ускоряет восстановление.
По итогам Вася убедился, что предложение Олега на код-ревью о внедрении exponential backoff всё же очень верное. Вася внедрил exponential backoff и jitter. Также он вынес логику ретраев из сервиса в общую библиотеку http-клиентов во фреймворке userver. Благодаря добавленным ретраям, исходная проблема решилась: флапы ошибок из-за тайм-аутов к сервису цен полностью исчезли. При этом ретраи были безопасными, то есть без риска привести к retry storm.
Часовое падение
Спустя три года в системе было 500 микросервисов. Каждый второй поход между сервисами был обложен ретраями. Они были правильными: с exponential backoff, jitter, на уровне общей библиотеки.
Но однажды весь бэкенд прилёг на целый час: в новом релизе сервиса заказов начались массовые ошибки. Релиз откатили за 10 мин, но после этого бэкенд не ожил. Ещё через 20 минут команда поняла, что поможет только полное снятие нагрузки с бэкенда. Рейт-лимитером оставили трафик только от 1% пользователей. Система ожила. Начали плавно пускать по 5% пользователей в течение получаса.
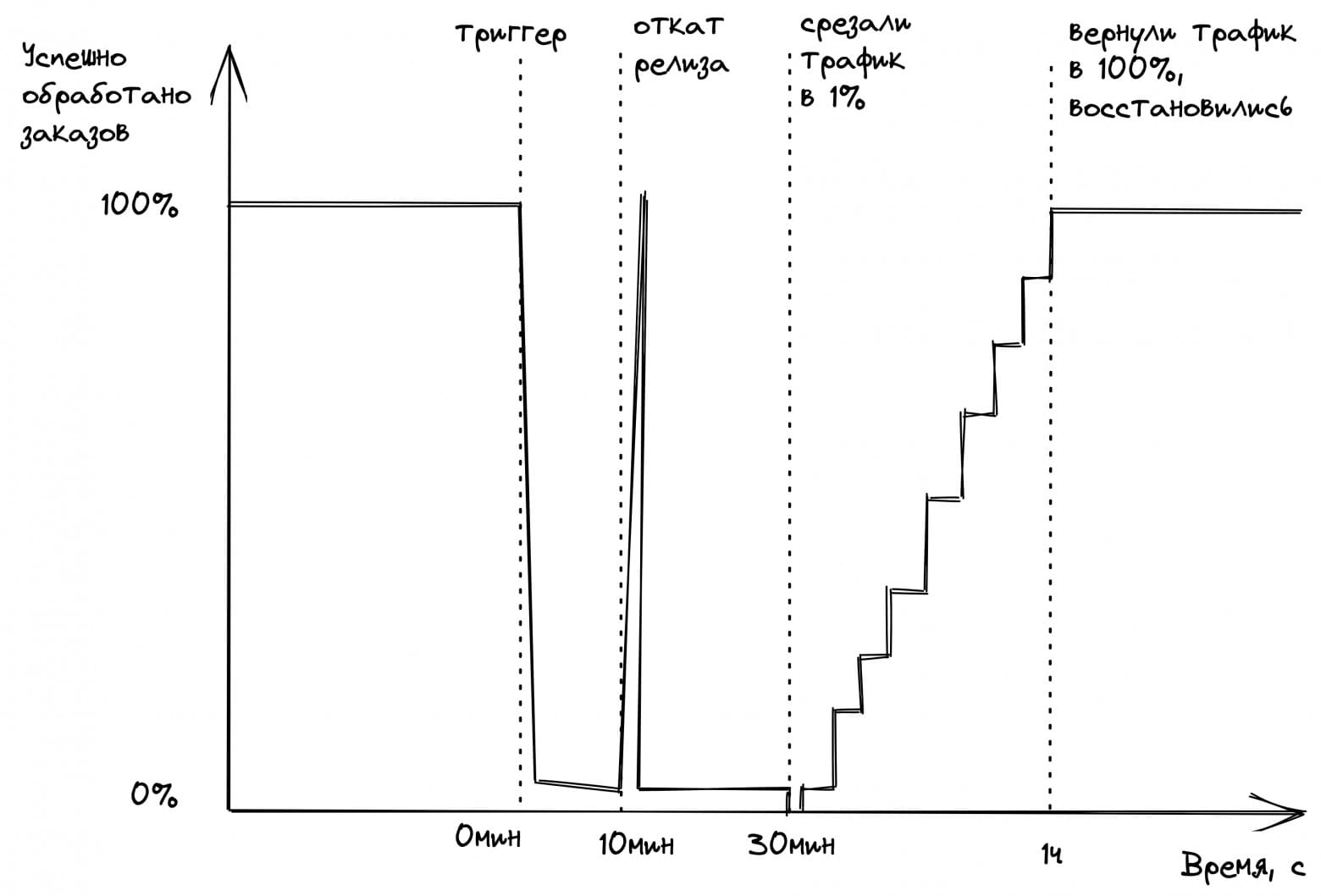
Неудачный релиз сделал Вася, поэтому он и подготовил пост-мортем с выводами. Причиной инцидента был баг в новой фиче, приводящий к segfault сервиса при тайм-аутах Redis. В пост-мортеме были только следующие выводы:
- подтюнить алерты, чтобы реагировать быстрее;
- зафиксить баг с segfault;
- написать тесты на случай тайм-аута Redis и других СУБД.
Стас, руководитель Васи, на инцидентном ретро поднял вопрос: ни в анализе, ни в выводах не адресовано долгое восстановление. Вася предложил сделать автоскейлинг подов для ускорения восстановления. Стасу такой вывод не понравился: надёжно реализовать автоскейлинг дорого. Кроме того, непонятно, точно ли это помогло бы в этой ситуации.
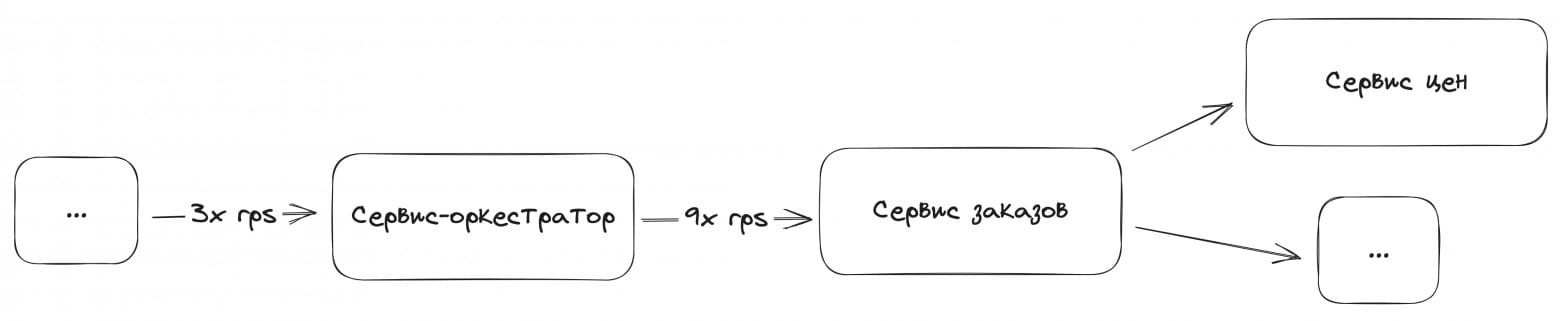
Стас быстро посмотрел на дашборд сервиса заказов и заметил, что в период восстановления сервис принимал нагрузку 9x от обычной. Он спросил, чем вызвана такая амплификация нагрузки? «Пользователи хотели уехать и постоянно пытались заказать Такси. За 10 минут откатки релиза мы накопили много ожидающих пользователей», — объяснил Вася.
Разработчик из платформы заказов Лёша проверил график RPS у сервиса-оркестратора (только он и ходит в сервис заказов). На нём нагрузка была не 9x, а 3x от обычной. То есть либо оркестратор всегда делает три запроса, либо это амплификация ретраями. Это ставило под сомнение теорию Васи об ожидающих пользователях.
Лёша поделился, что симптомы долгого восстановления напоминают ему проблему metastable failure state (MFS). Обычно система восстанавливается сама после устранения триггера (неудачного релиза). Но если этого не происходит, то такое состояние системы называют MFS. В этом инциденте так и случилось. Лёша предположил, что к такому могли привести ретраи.
MFS показался Васе магией, но он понял, что такие проблемы и правда могут быть вызваны ретраями. Вася ушёл разбираться, почему оркестратор превратил 3x в 9x RPS.
Достаточно ли exponential backoff
Вася убедился, что оркестратор ходит в сервис заказов ровно один раз. Но там есть два ретрая. Они используют exponential backoff и jitter. А значит, тут всё безопасно, и утроение нагрузки не может быть вызвано ретраями. Вася не смог найти причину амплификации нагрузки и попросил помощи у разработчика Ивана, который работает в команде водительской платформы.
Иван объяснил, что exponential backoff при ретраях не избавляет от амплификации нагрузки, а лишь откладывает её на время. Начиная с определённого момента даунтайма, exponential backoff никак не помогает уменьшению нагрузки на сервер.
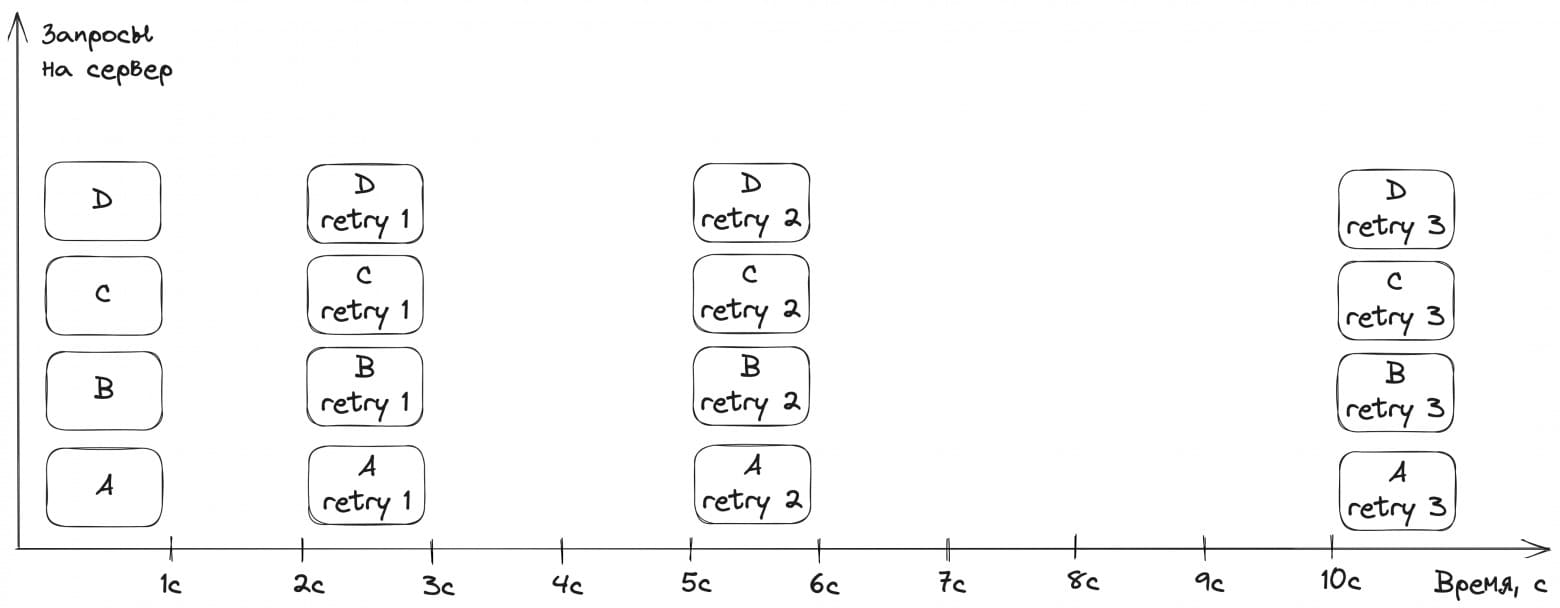
Иван нарисовал, что происходит с сервером при ретраях. Каждый запрос выполняется ровно одну секунду, и каждую секунду на сервер приходит новый запрос (буквы A–Z). Начиная с первой секунды все запросы начинают отдавать ошибку. Если клиент делает три ретрая без exponential backoff, то амплификация 4x происходит уже на четвёртой секунде:
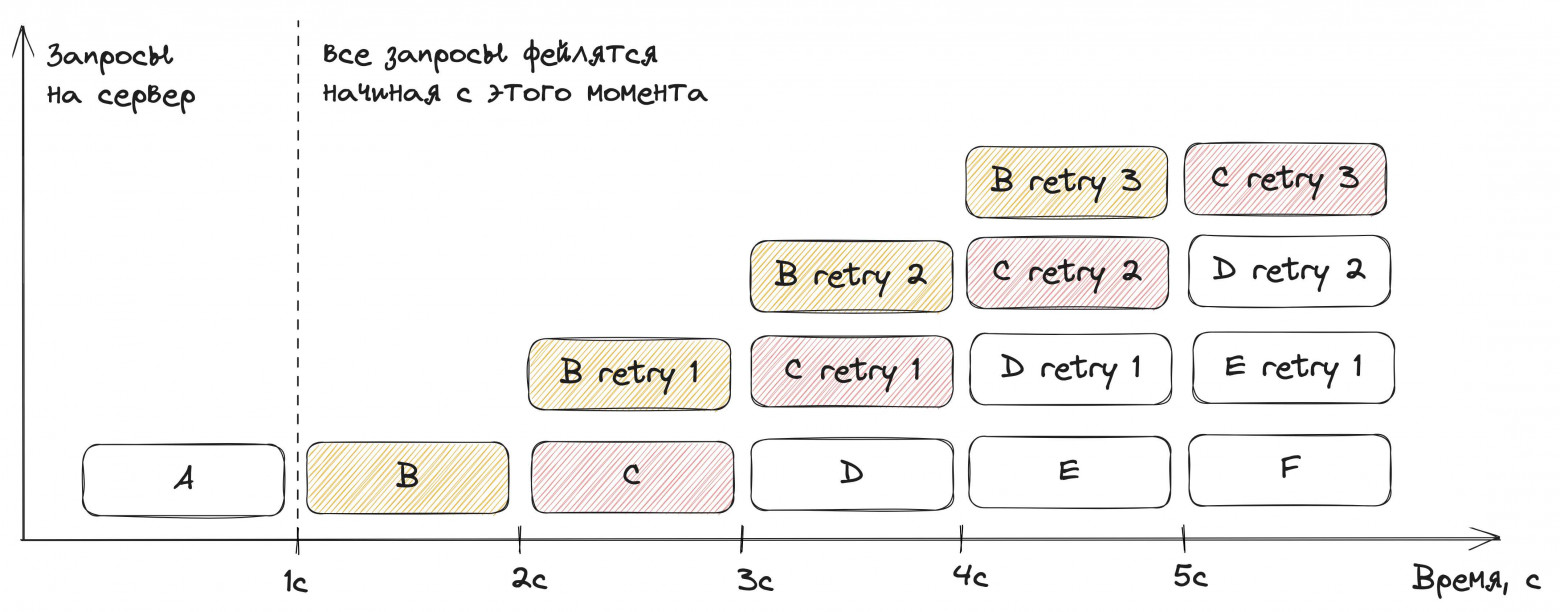
Если применить экспоненциальные задержки 1 с → 2 с → 4 с, то та же амплификация 4x всё равно случится, но позже — на 11-й секунде:
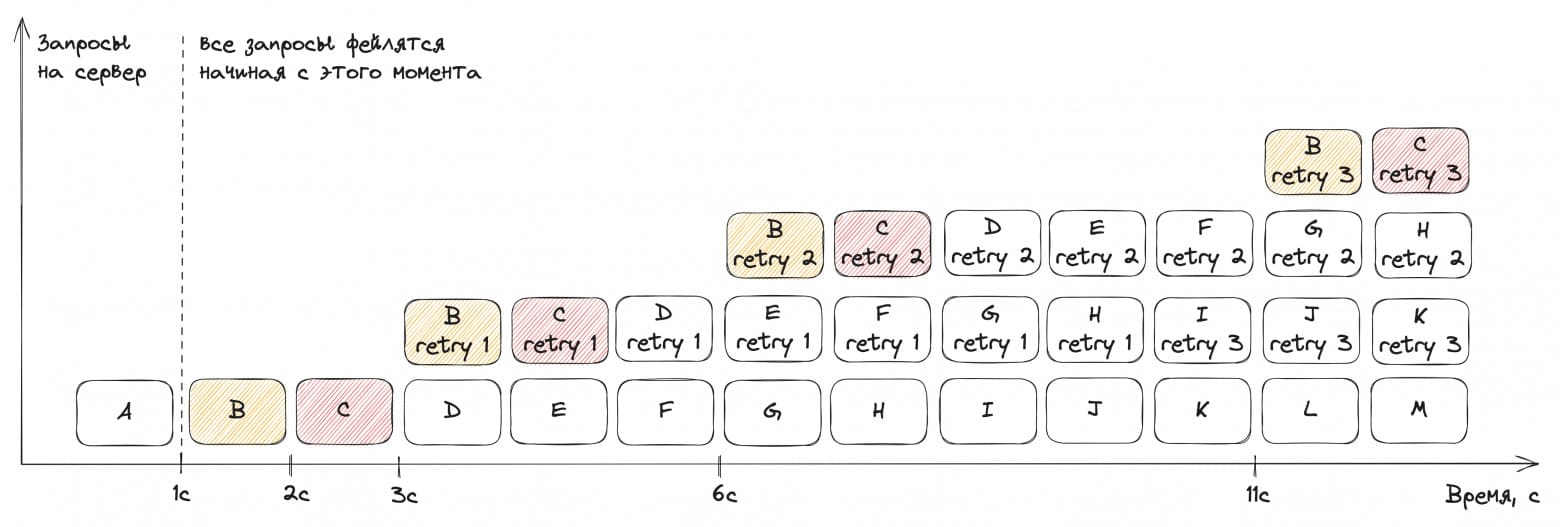
Иван резюмировал: exponential backoff — это способ отложить ретраи в будущее. Если мы уверены, что сможем их успешно обработать (например, у нас короткий даунтайм или быстрый автоскейлинг) — это отличный вариант. В противном случае сервер привалит ретраями.
Мир Васи немного пошатнулся. Три года назад он узнал о технике exponential backoff, прочитал десяток статей о ней, подтвердил её пользу симуляциями и даже выступил на митапе с результатами своих исследований! Вася не поверил сразу и решил провалидировать сказанное Иваном любимым методом — в симуляции.
Симуляция подтвердила, что exponential backoff лишь откладывает амплификацию
Чтобы провалидировать эффект откладывания, Вася удлинил период даунтайма сервера с [0.5 с; 1.0 с] до [0.5 с; 1.5 с]. Для начала Вася сэмулировал open loop систему и сравнил простые ретраи с рандомизированными экспоненциальными:
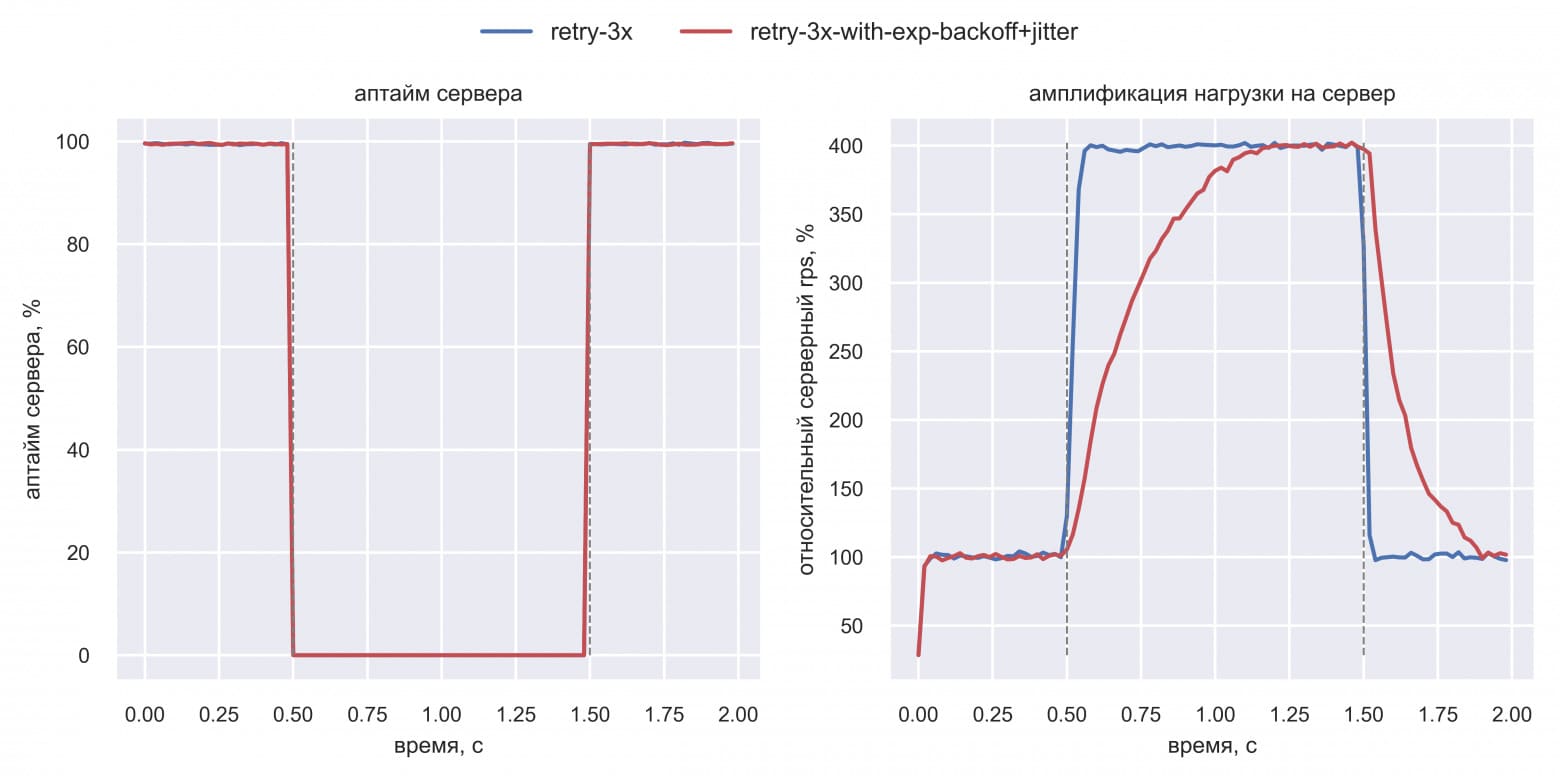
Вася увидел, что амплификация 4x у exponential backoff происходит, но чуть позже. Поэтому он и не видел данный эффект в предыдущих симуляциях: даунтаймы были слишком короткие. Но Вася помнил, что у production есть элементы closed loop системы, поэтому он добавил лимит на число активных клиентов:
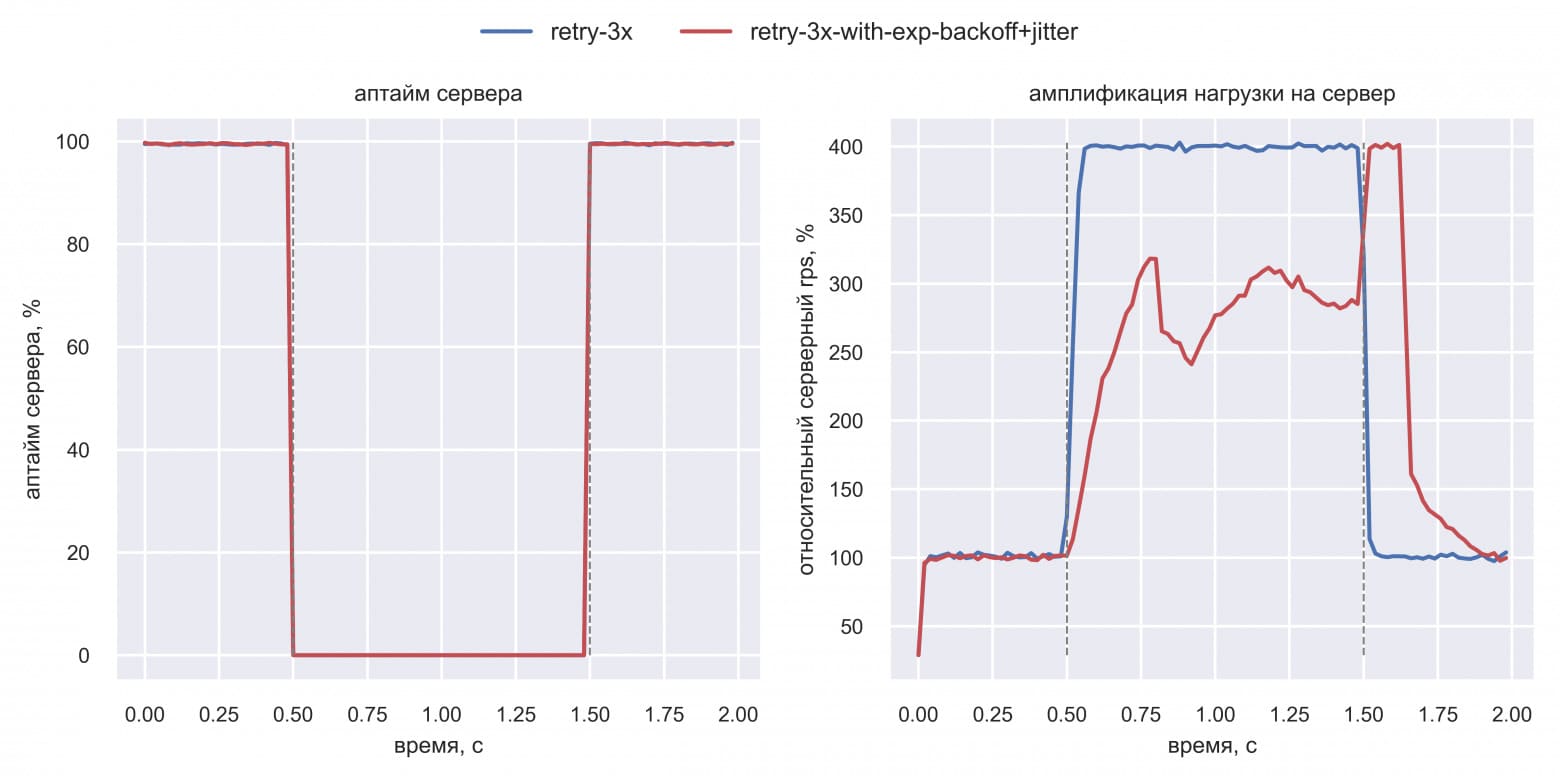
«Супер! Отложенной амплификации нагрузки во время даунтайма нет!» — подумал Вася. Но решил перепроверить и поиграться с лимитом на число активных клиентов. Оказалось, если поднять этот лимит с 30% от нормального RPS до 40%, то ситуация меняется:
Вася понял, что недостаточно просто наличия лимита — он должен быть ещё и корректным, а это трудно гарантировать. На практике отрицательная обратная связь в production-системе может быть слишком слабая. Итак, Вася подтвердил, что амплификация при exponential backoff точно такая же, как и с простыми ретраями, только наступает попозже.
Фундаментальная проблема ретраев
Вася осознал, что exponential backoff не серебряная пуля. Но он не понимал одну вещь: почему ретраи и амплификация ими нагрузки это вообще проблема? Раз есть ретраи, значит, есть ошибки, следовательно, система нездорова — именно в этом и проблема, а не в ретраях! Вася сходил за советом к Паше — руководителю водительской платформы.
Паша подсказал, что можно смотреть на систему с ретраями в двух разрезах: до устранения триггера и после. Триггер — это причина даунтайма, например, неудачный релиз или конфигурация. Пока триггер активен, рассуждения выше верны: даже без ретраев система нездорова. Но когда триггер устранён (например, релиз откатили) — система вновь здорова и способна обработать как минимум обычный поток запросов.
Паша показал на примере: допустим, у системы запас по CPU x2, а клиенты не поддерживают ретраи:
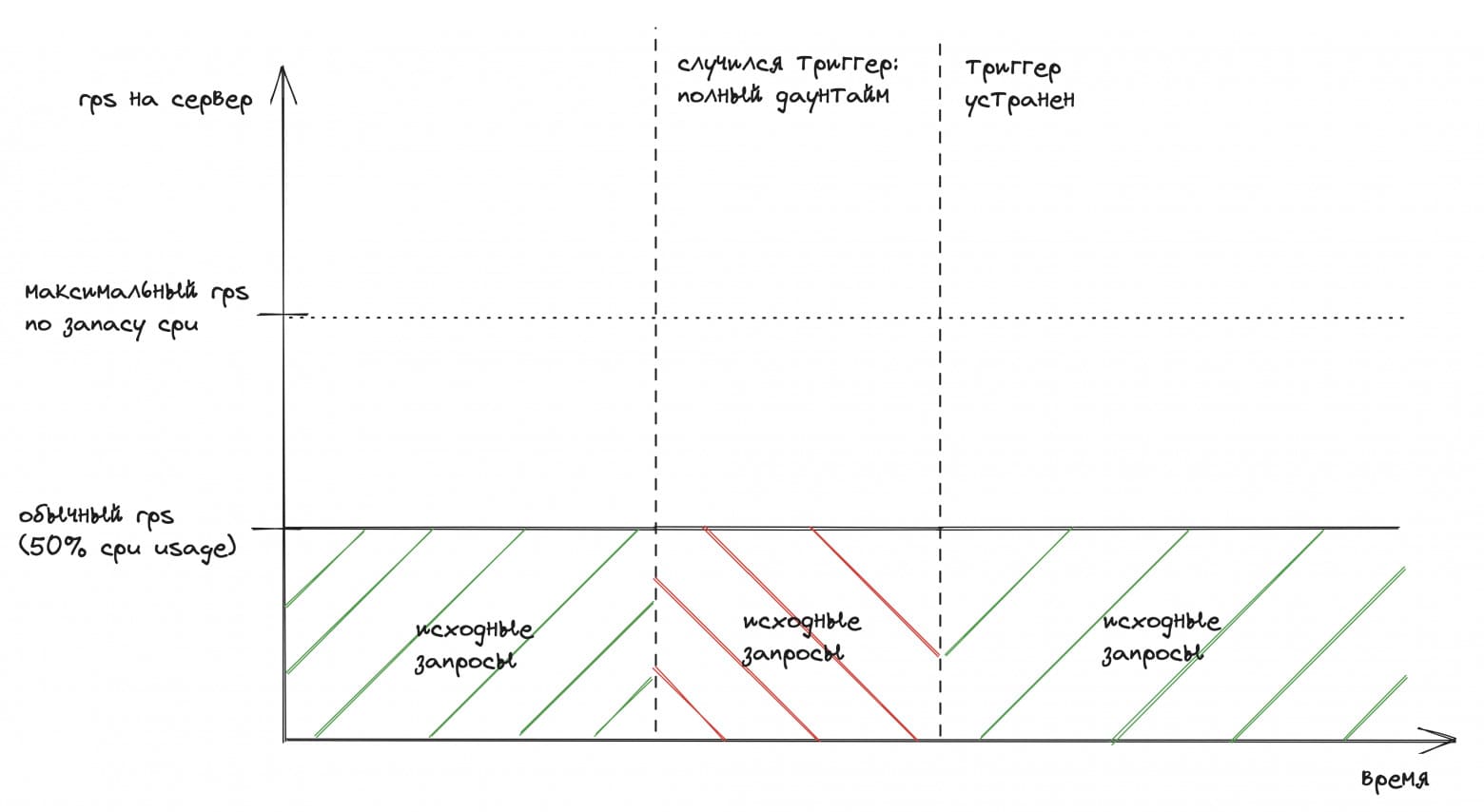
Для упрощения здесь намеренно игнорируется, что часть пользователей при ошибках не уходит, а ожидает, пока система оживёт. Они делают ретраи «руками», поэтому исходные запросы должны плавно расти при даунтайме.
Если клиенты делают два ретрая (всего три запроса на сервер), то можно предположить, что ситуация будет выглядеть так:
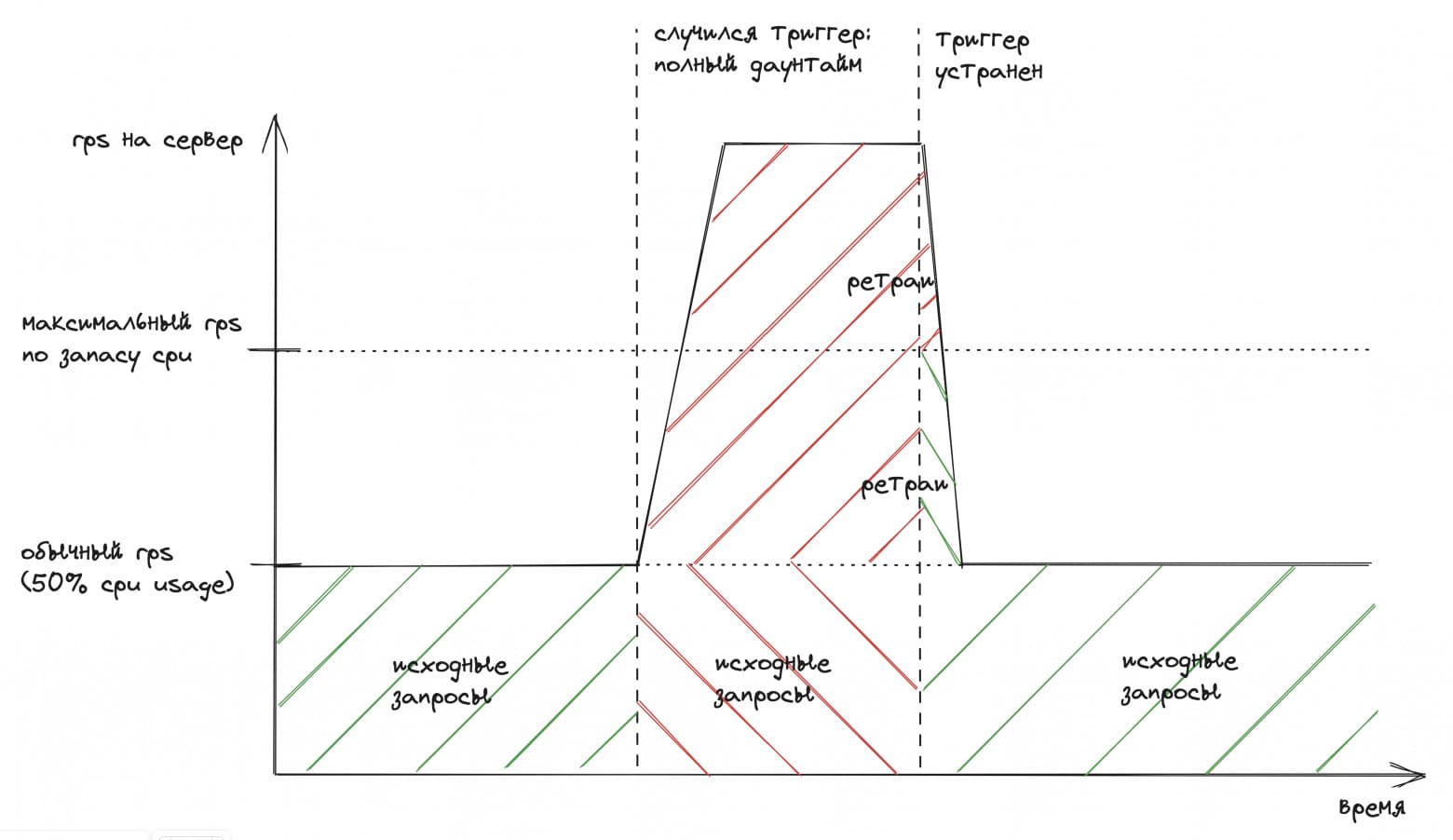
Красным отмечены запросы, завершившиеся ошибкой или тайм-аутом. Зелёным — успешные запросы.
Но в реальности будет по-другому:
При нехватке capacity система начнёт медленно работать. Вырастут очереди запросов на сервере. Начнутся тайм-ауты на клиентах, что вызовет новые ретраи.
Тайм-ауты и ошибки будут равномерно возникать как в обычных, так и ретрайных запросах. Поэтому область после восстановления выделена жёлтым цветом. Часть этих запросов завершится успешно, а часть оттаймаутит или вернёт ошибку.
В реальности ситуация будет выглядеть скорее так:
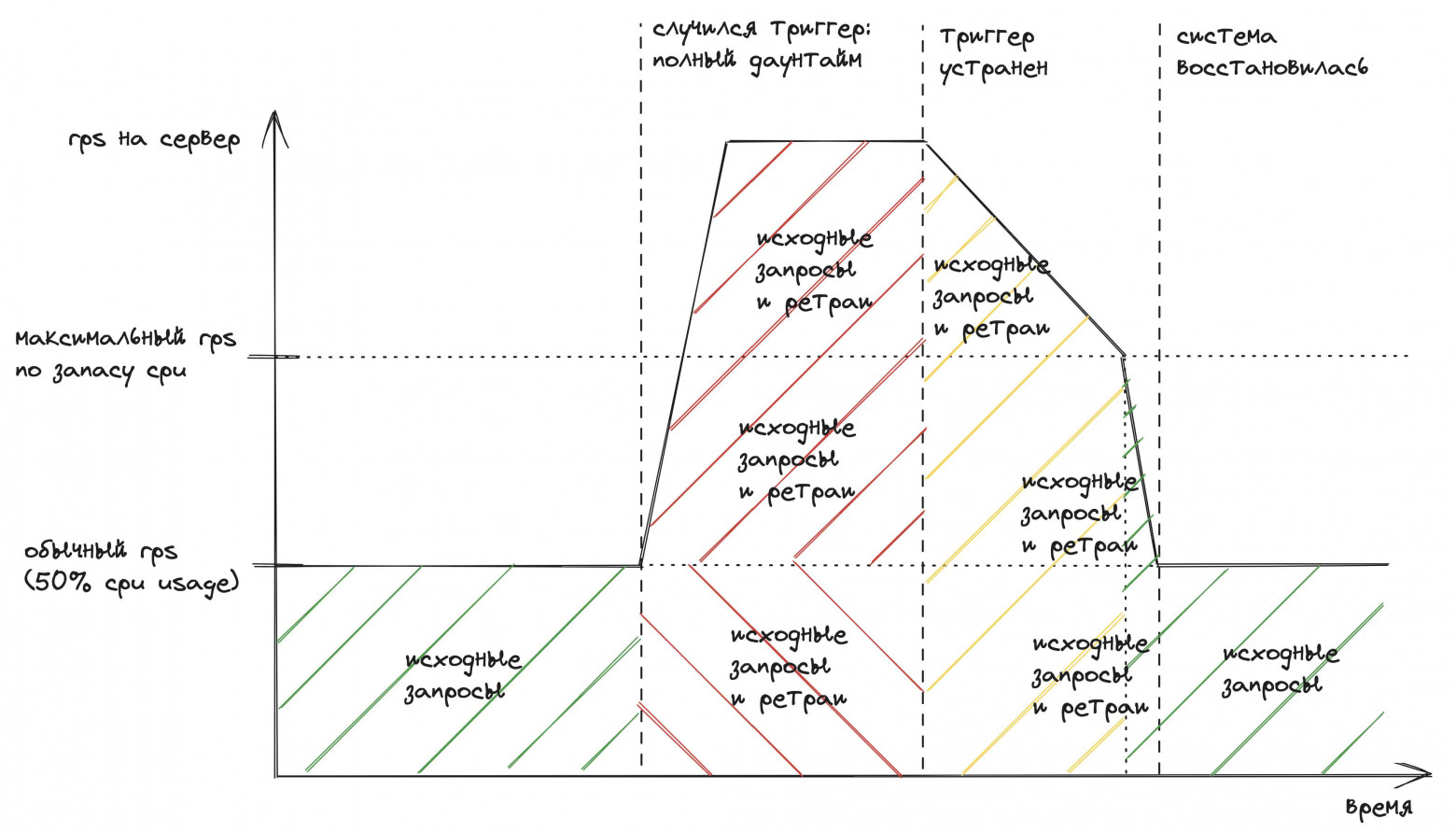
Главная проблема: из-за ретраев система не восстанавливается сразу после устранения триггера. В варианте без ретраев восстановление случается почти сразу.
Паша подвёл итог: время восстановления после устранения триггера зависит от объёма запросов, обрушившихся на сервер. Поэтому важно уменьшать нагрузку на сервер для ускорения восстановления. А ретраи, наоборот, только увеличивают нагрузку.
При этом время восстановления растёт более чем линейно при росте нагрузки. Цепочка такая: больше запросов на сервер → больше тайм-аутов или ошибок получено клиентами → больше ретраев → ещё больше запросов на сервер.
Вася провалидировал тезисы Паши с помощью симуляции
В отличии от прошлых симуляций Вася сделал так, что у клиентов не одинаковый тайм-аут (время ожидания ответа) 100 мс, а случайный из списка — 100 мс, 200 мс, 300 мс. Это ближе к реальными системам. Также Вася сделал у клиентов два ретрая вместо трёх. Симуляция показала следующее:
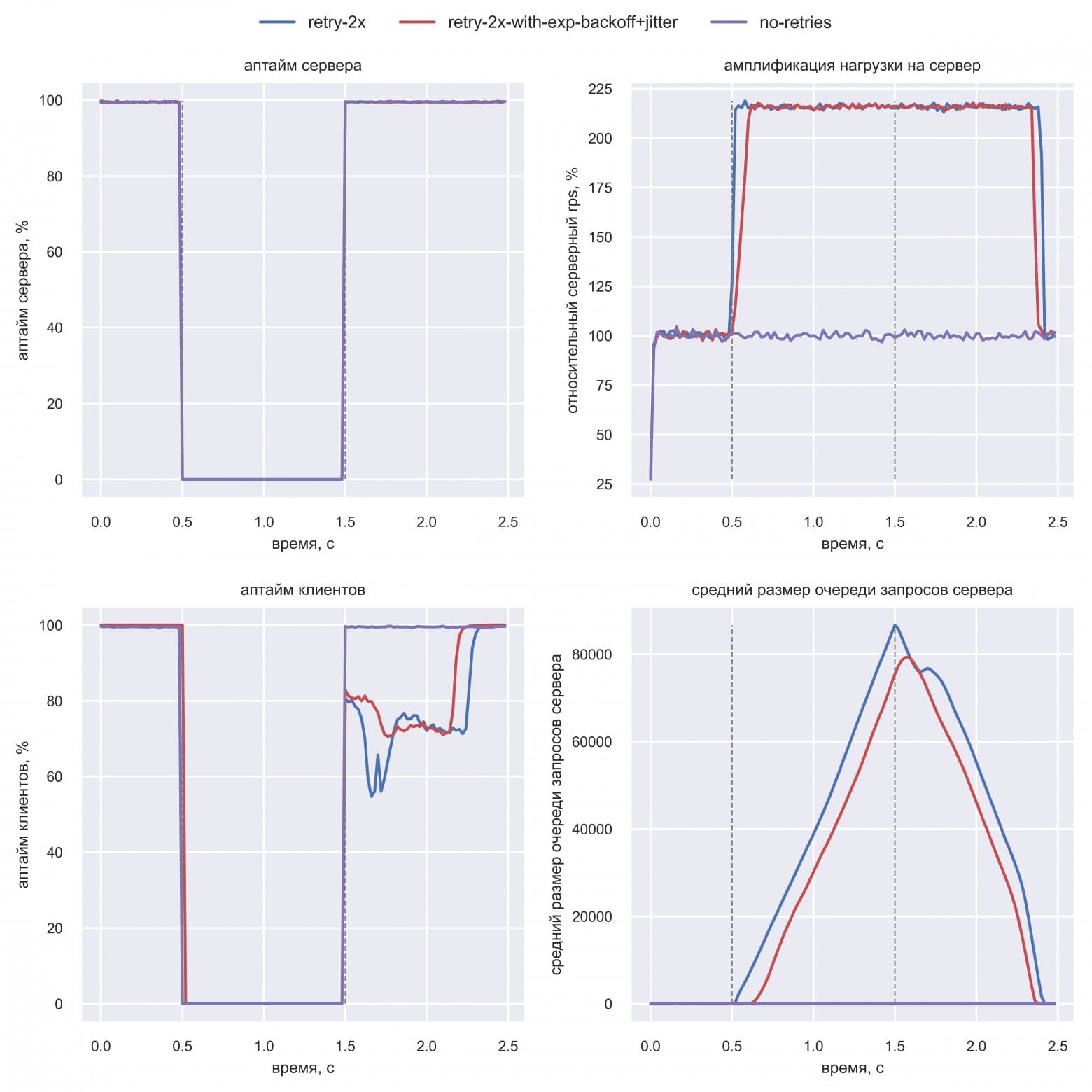
Даунтайм завершился в t=1.5 с, но полностью ошибки ушли только в t=2.3 с для схемы с ретраями. Клиенты без ретраев восстановились моментально в t=1.5 c. Таким образом, Вася провалидировал, что любые ретраи удлиняют восстановление (даже ретраи с экспоненциальной задержкой).
Вася поблагодарил Пашу и ушёл размышлять над всем этим.
Жизнь без ретраев
«Хорошо, без ретраев система восстанавливается быстрее. Давайте тогда избавимся от них», — думал Вася. Но что делать с разовыми ошибками сервера в нормальном состоянии системы, если ретраев вообще нет?
Вася обсудил это с разработчиком Женей из своей команды. Женя объяснил, что нужно разделять сценарий, когда сервис здоров и когда ему плохо. Если сервис здоров, то его можно ретраить, потому что ошибки могут быть разовыми флапами. Если сервису плохо, то ретраи нужно остановить или минимизировать.
«Как понять, что сервису плохо? Считать процент ошибок от сервиса на клиенте?» — спросил Вася. Женя рекомендовал рассмотреть две техники:
- Retry circuit breaker (retry cb). Клиент сервиса полностью отключает ретраи, если процент ошибок сервиса превышает порог, например, 10%. Как только процент ошибок за условную минуту становится ниже порога, то ретраи возвращаются. При проблемах сервиса на него вообще не идёт дополнительная нагрузка от ретраев.
- Retry budget (или adaptive retry). Ретраи допускаются всегда, но в пределах бюджета, например, не более 10% от количества успешных запросов. При проблемах сервиса на него может идти не более 10% дополнительного трафика.
Оба варианта гарантируют, что в случае проблем у сервиса, клиенты накинут ему не более n% дополнительной нагрузки.
Retry circuit breaker или retry budget?
После изучения этих двух техник у Васи возник ряд вопросов:
- Какую из этих техник выбрать на практике?
- Зачем он вообще делал exponential backoff с jitter, если ретраи надо просто минимизировать или отключать? Стоит ли совмещать exponential backoff с данными техниками?
- Нужно ли считать процент ошибок глобально между всеми клиентами? Насколько плохо считать только локальную статистику?
По первому вопросу Женя скинул Васе ссылку на сравнение этих двух техник. По другим вопросам Женя рекомендовал Васе провести исследование самостоятельно.
Вася провалидировал и сравнил обе техники с помощью симуляции
Вася добавил в симуляцию техники retry budget и retry circuit breaker поверх простых ретраев. И решил сравнить их, exponential backoff в сочетании с jitter, простые ретраи и отсутствие ретраев:
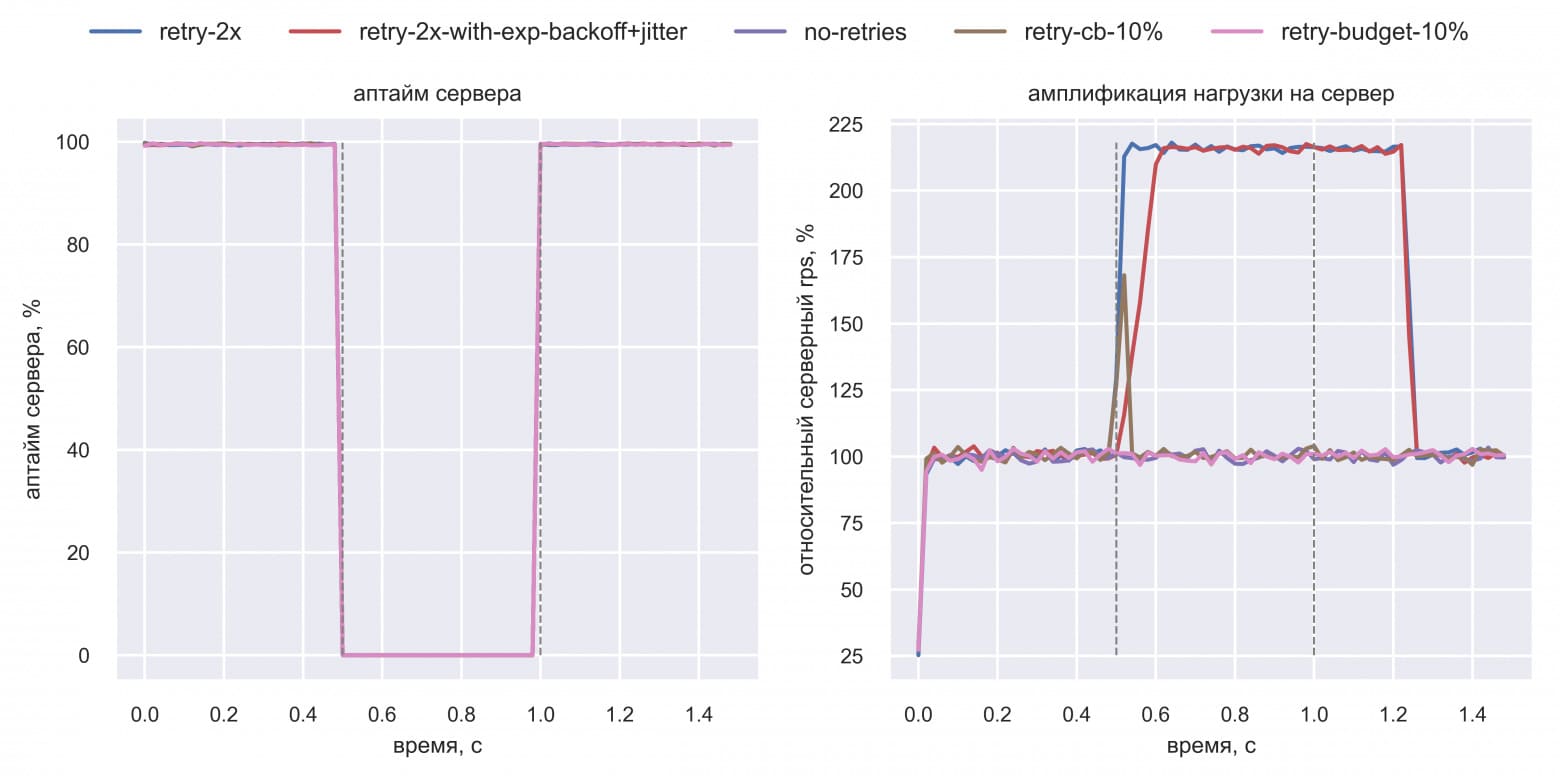
Всё как и говорил Женя: retry budget (розовая линия) и retry cb (коричневая линия) создают меньше избыточной нагрузки на сервер, что позволяет быстрее восстановиться: в t=1.0 с, а не в t=1.25 с. Васе стало интересно: а как себя поведут эти техники, если сервер будет отдавать не 100% ошибок, а меньше? Он решил воспроизвести сценарий частичного отказа: в интервале [0.5 с; 1.0 с] на сервере будет 30% ошибок. Также Вася решил посмотреть на график аптайма со стороны клиентов. Вот результаты симуляции:
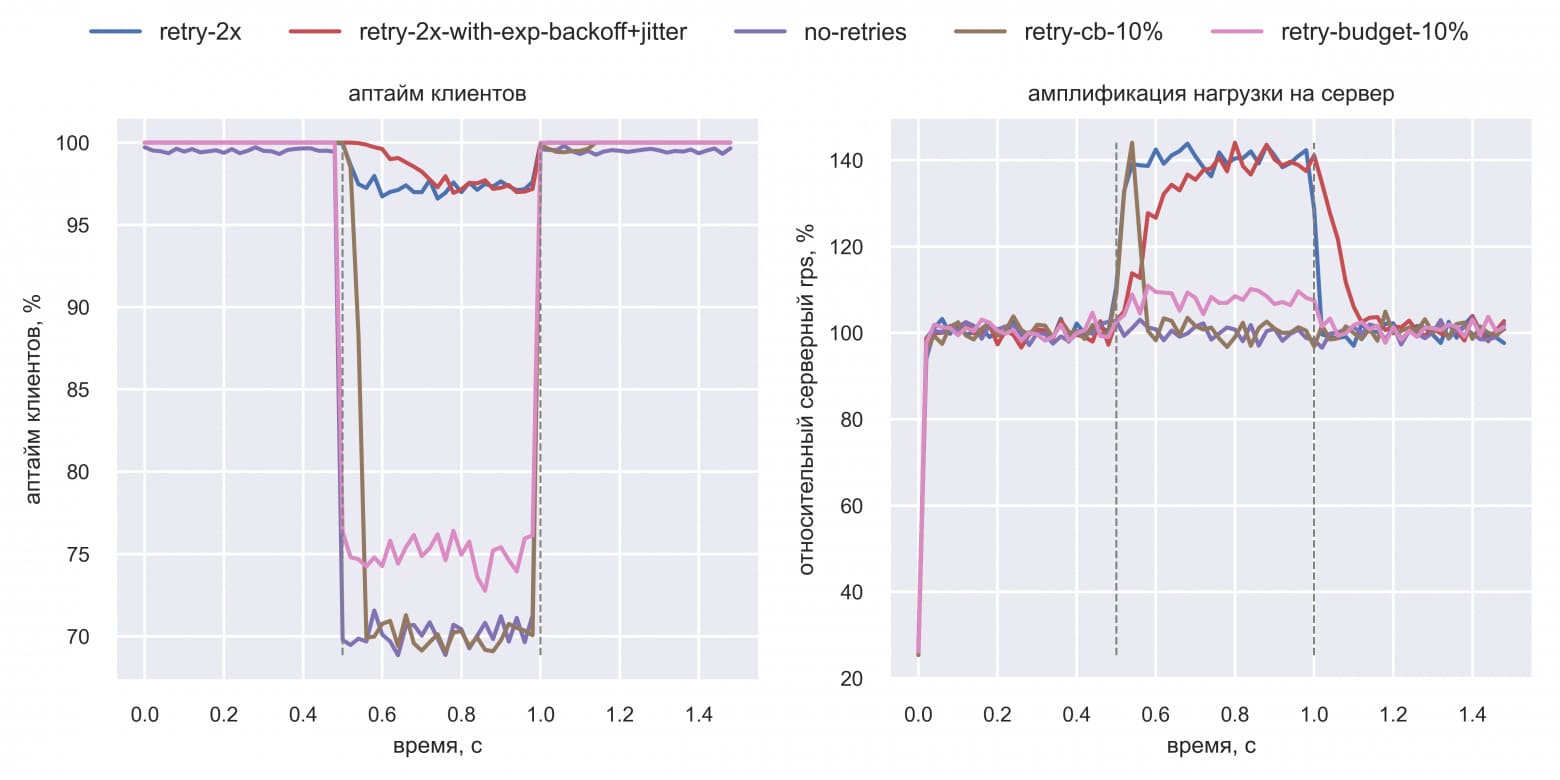
Это уже интереснее! Выходит, retry cb и retry budget не перегружают ретраями сервер, но ценой этому может быть более низкий аптайм клиентов при частичных отказах. На графиках было слишком много линий, и Вася оставил только самые нужные для сравнения двух техник:
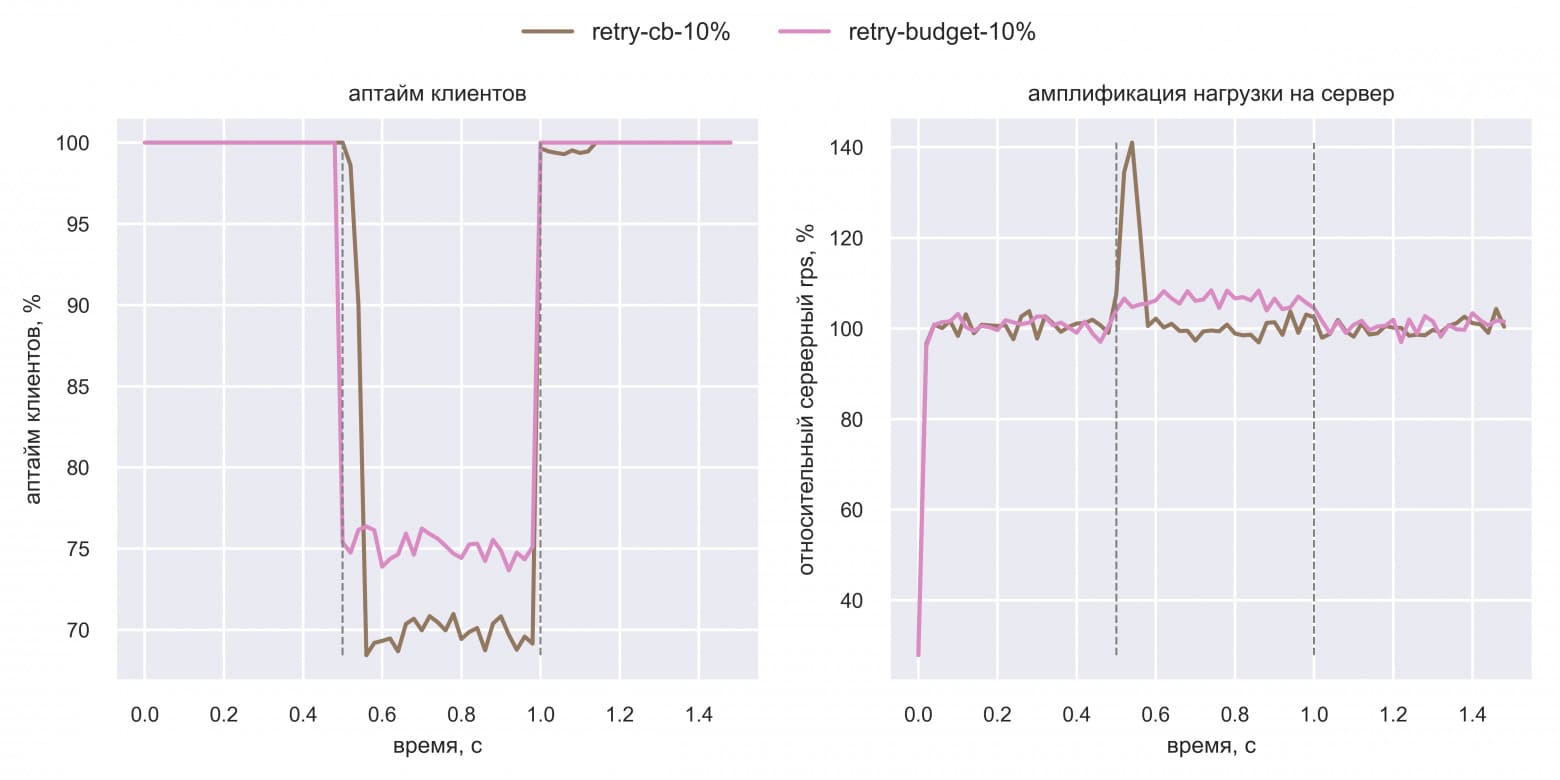
Вася чётко увидел, что retry budget генерирует дополнительные 10% нагрузки на сервер ретраями, но повышает клиентский аптайм.
По итогам симуляции Вася провалидировал, что обе техники действительно решают проблему амплификации нагрузки. Но у каждой из них свои плюсы и минусы, и Вася не знал, как выбрать. Поэтому он решил посмотреть, как реализованы крупные опенсорс-клиенты:
- AWS SDK используют retry budget (HasRetryQuota);
- gRPC-клиент для Go тоже использует retry budget (RFC и код).
«Раз они используют retry budget, то и я буду», — решил Вася.
Реализация опенсорс клиентов также подсказала Васе ответы на два оставшихся вопроса:
- exponential backoff и jitter тоже нужны, они дополняют retry budget;
- статистику с процентом ретраев можно считать локально, не усложняя схему глобальной синхронизацией статистики.
Вася провёл симуляцию: для долгоживущих клиентов локальная статистика ведёт себя идентично глобальной, а exponential backoff не сильно влияет на амплификацию.
В итоге Вася запланировал принести на ретро такой action item: дополнить текущий exponential backoff техникой retry budget с бюджетом 10%. Глобально статистику не синхронизировать, а реализовать через простой token bucket. В симуляции — пример реализации этой техники.
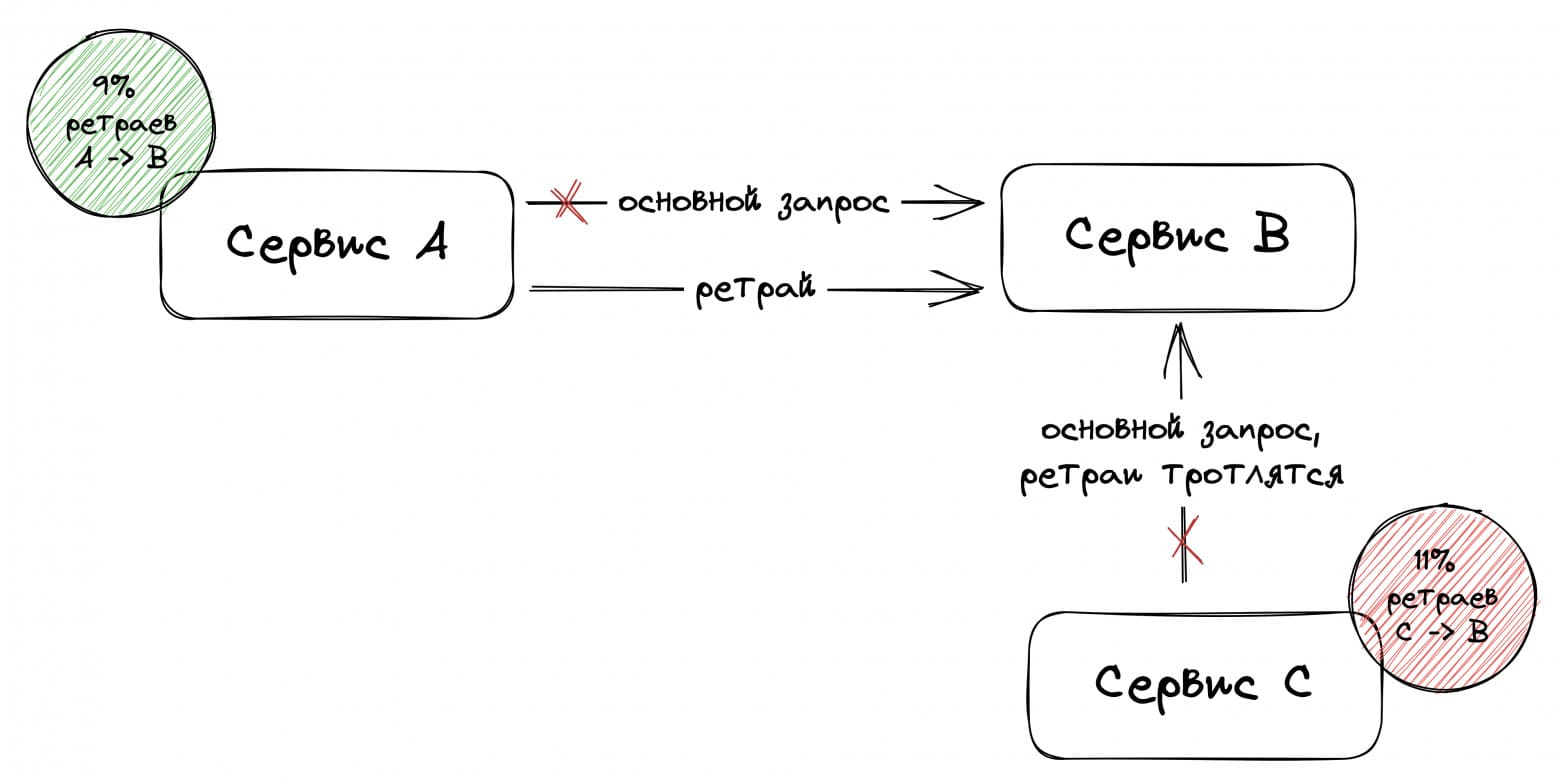
Разные решения одной проблемы
На ретро Вася получил ряд возражений по идее внедрить retry budget. Двое коллег спросили, зачем это делать, раз есть exponential backoff.
Руководитель SRE Кирилл отметил: «Retry budget — это сложная логика на клиентах, что противоречит принципу тонкого клиента. Да, здесь клиенты это не фронтенд, а другие бэкенд-сервисы, но принцип всё равно применим. Пусть каждый сервис сам защищает себя от ретраев».
Вася парировал, что если сервер упадёт, кончится по памяти или CPU, то он не сможет себя защитить. Затем Кирилл с Васей обсудили, поможет ли load shedding на сервере, но в итоге решили, что толстый клиент в данном случае это нормально.
Руководитель b2b разработки Илья предложил вместо ограничения ретраев применить паттерн circuit breaker (cb). Идея паттерна в том, что клиент вообще перестаёт ходить в сервис, если процент ошибок сервиса выше порога. Не будет походов в сервис — не будет и ретраев. Вася готов был согласиться с идеей, но решил сначала провалидировать её в симуляции.
Вася сравнил circuit breaker с retry budget в симуляции
Руководитель Васи посоветовал ему в данной симуляции не просто инжектить ошибку в 100% запросов, а эмулировать отказ одного из шардов базы данных. При таких отказах ошибки будут только у части пользователей. Вася запрограммировал симуляцию для circuit breaker с порогом 10% и эмуляции отказа одного из пяти шардов (ошибки 20% пользователей):
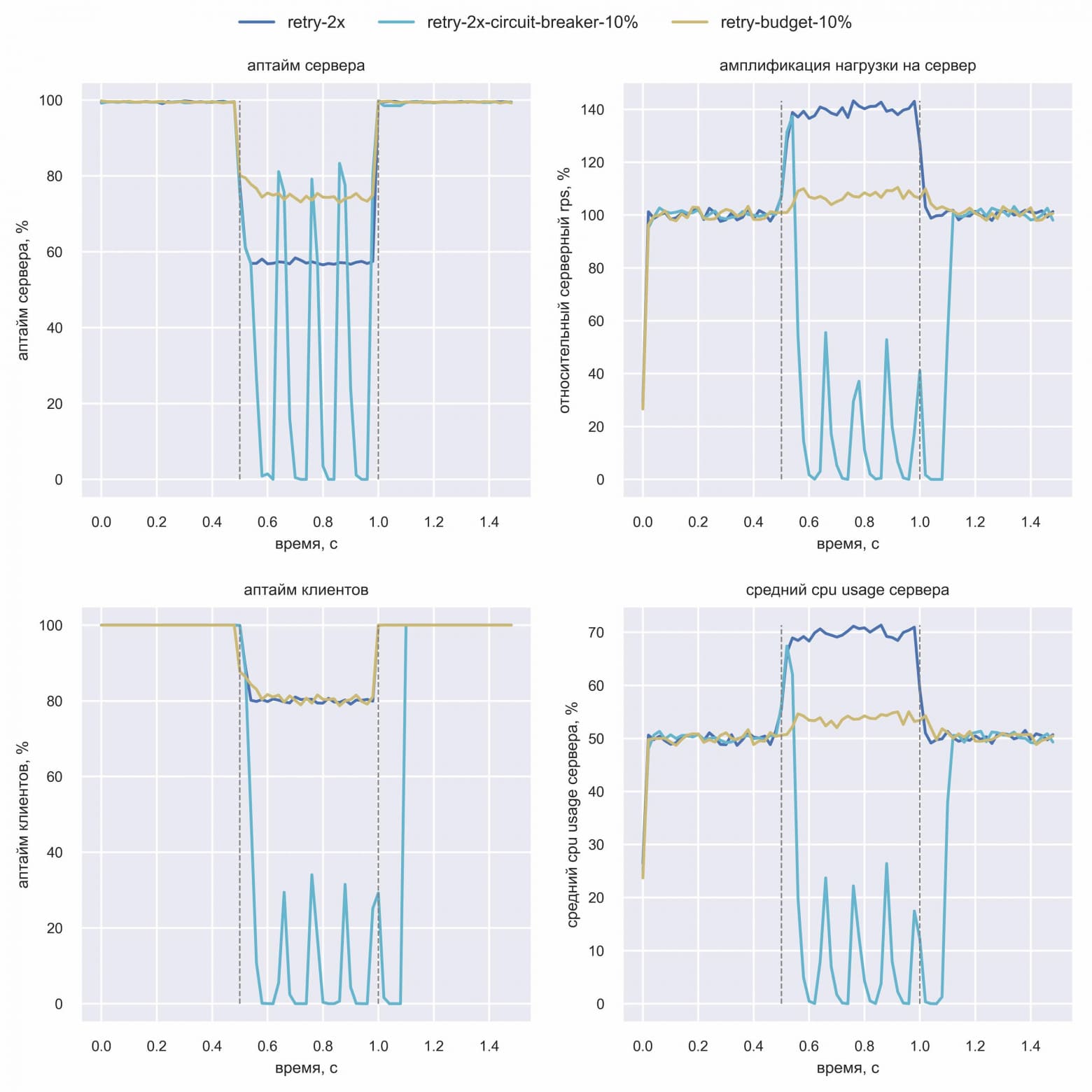
«Что за кардиограмма?!» — подумал Вася. Но тут же понял, в чём дело: ошибки 20% пользователей вызывают срабатывание circuit breaker по порогу 10%. После этого circuit breaker отключает походы клиента в сервис на какое-то время, поэтому аптайм, амплификация и CPU падают до 0. Затем небольшая часть трафика на короткое время пропускается для сбора статистики — это пики «кардиограммы». Статистика показывает, что процент ошибок выше порога, и походы в сервис опять отключаются. Проблема в том, что плохо только одному шарду, а отключаются походы во все. В такой конфигурации circuit breaker скорее вреден — retry budget явно лучше. Поэтому Вася решил проверить circuit breaker с порогом в 50% при тех же 20% пользователей с ошибками:
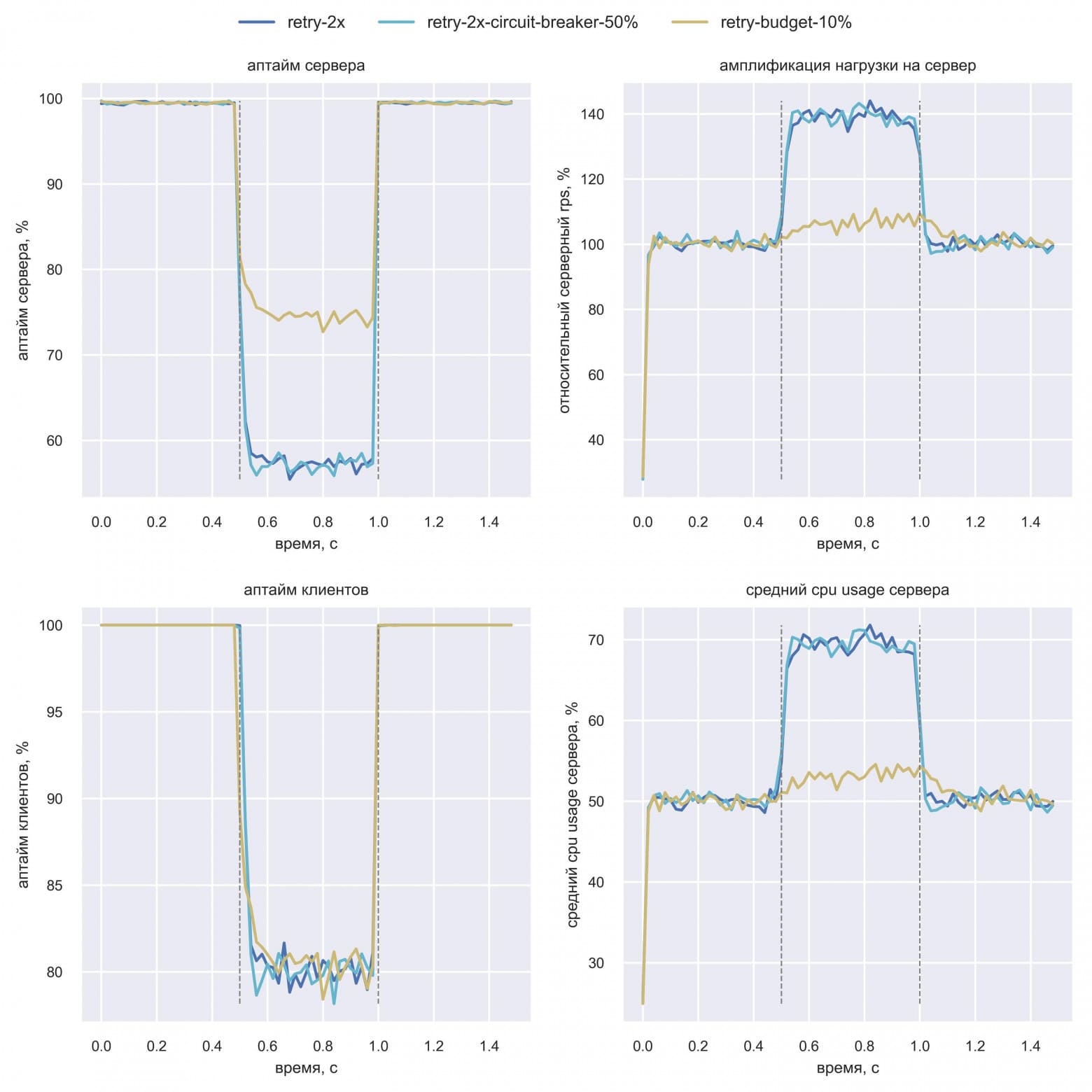
Вася сделал вывод, что circuit breaker с порогом 50% не делает хуже при отказе одного из пяти шардов, но и проблему амплификации нагрузки он не лечит.
По итогам симуляции Вася обнаружил, что circuit breaker (cb) — это более опасный паттерн, чем retry budget. В случае отказа одного шарда сервиса circuit breaker может отключить поход во все шарды. Поэтому у cb должен быть намного более высокий порог срабатывания, чем у retry cb или budget, например, 50%. А значит, и допустимая амплификация нагрузки будет выше. По итогам обсуждений Вася и его коллеги пришли к тому, что circuit breaker нужен, но скорее как дополнение к retry budget.
Между ретро к Васе подошёл Андрей из платформы надёжности: «А ты не думал применить паттерн deadline propagation вместо retry budget? Идея паттерна в том, что клиент в запросе к серверу передаёт значение тайм-аута. Сервер в процессе обработки запроса регулярно проверяет: не истёк ли тайм-аут на клиенте. Если истёк, то можно завершать обработку запроса ошибкой».
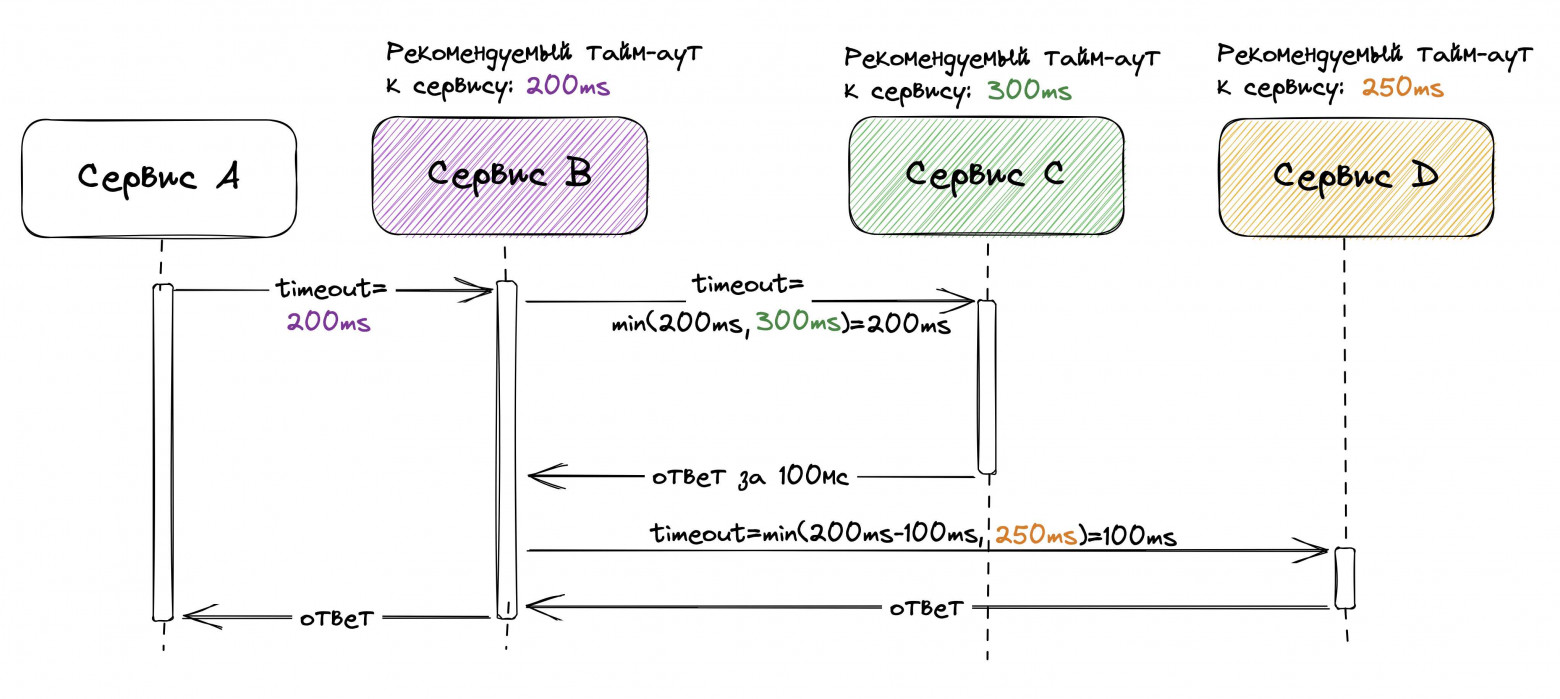
Вася не понял, как deadline propagation может быть заменой отключению ретраев: это же вообще разные идеи. Андрей объяснил: «Если серверу плохо, то клиент шлёт ретрай по тайм-ауту. В момент отправки ретрая сервер либо ещё не начал выполнять исходный запрос, либо находится в процессе выполнения. В обоих случаях благодаря deadline propagation сервер может сразу прервать выполнение запроса. Таким образом, deadline propagation может компенсировать эффект от амплификации ретраями».
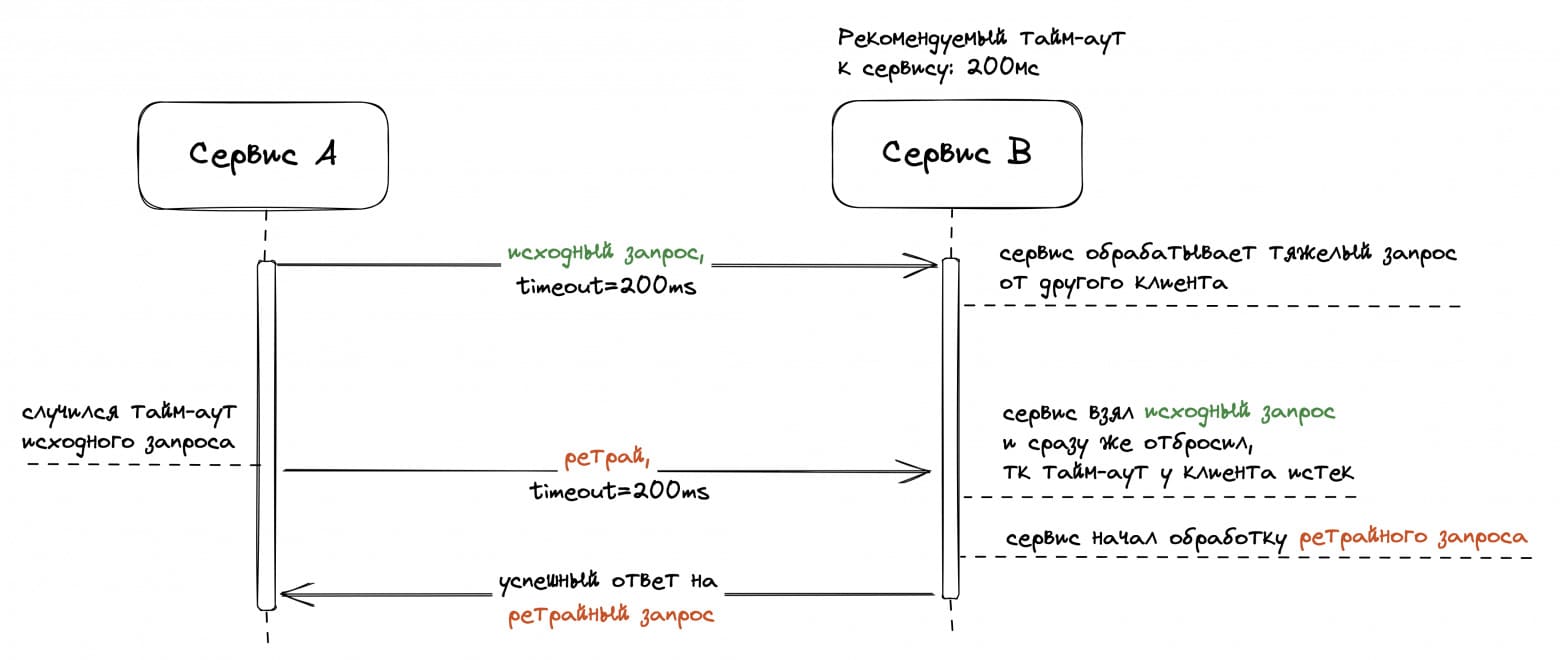
«Звучит правдоподобно, но сложно оценить эффективность техники», — подумал Вася. Поэтому он опять обратился к симуляции.
Симуляция показала, что deadline propagation эффективен, но недостаточно
Вася запрограммировал deadline propagation в симуляции и запустил в сравнении с простыми ретраями и retry budget:
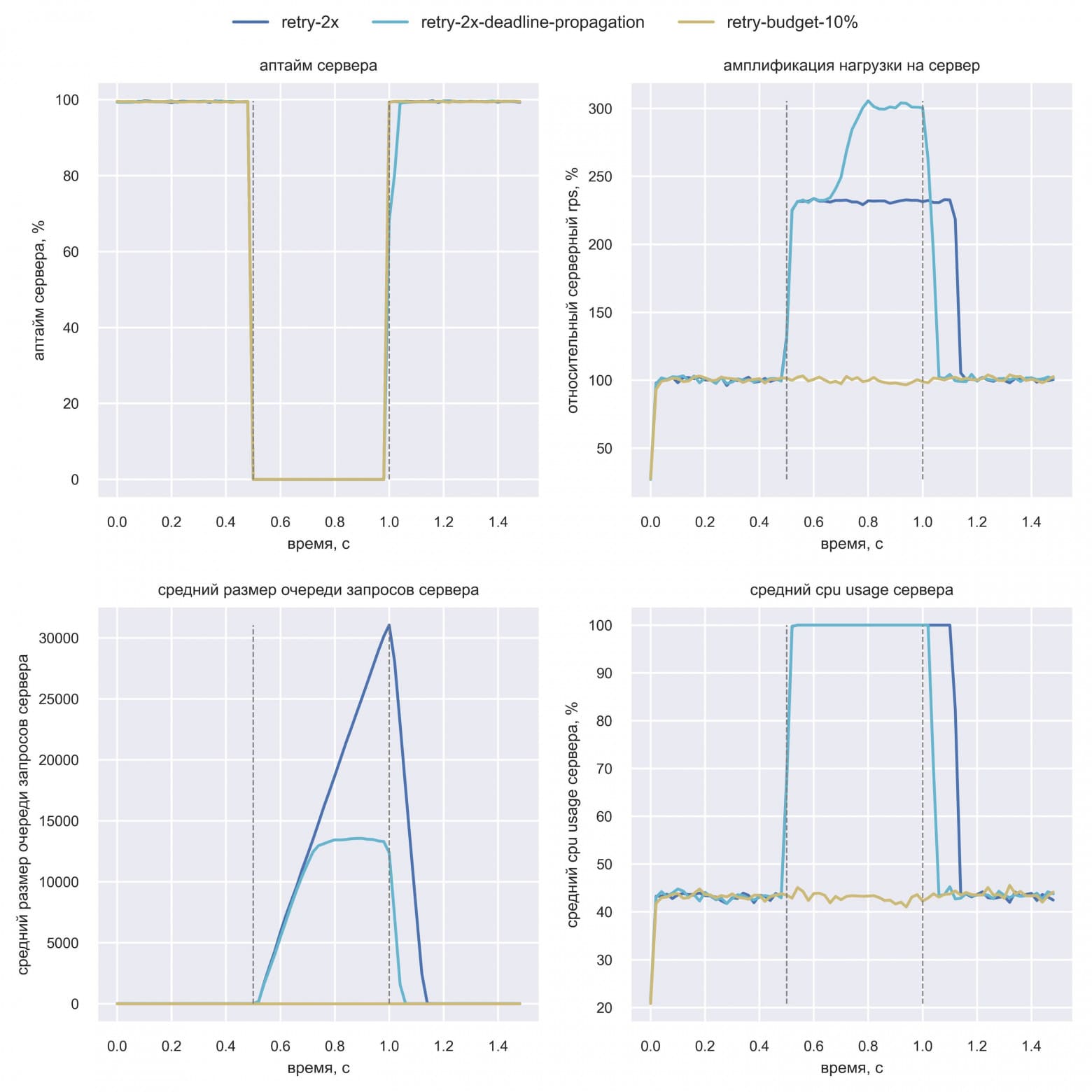
Вася удивился результатам: почему-то выросла амплификация нагрузки, а время восстановления и очередь на сервере при этом сократились. После изучения он смог объяснить этот эффект:
- Амплификация нагрузки у простых ретраев (retry-2x) должна быть 300%, но запас по CPU даёт достичь только ~200% амплификации. Deadline propagation быстро завершает запросы на сервере, что позволяет делать больше запросов в единицу времени. Поэтому амплификация растёт.
- Сервер быстрее восстанавливается, потому что очередь запросов короче. А короче она, потому что сервер быстрее возвращает ошибки на запросы, которые уже не ждёт клиент. При этом Вася заметил, что deadline propagation работает хуже, чем retry budget. Васе было интересно понять, почему так происходит — вдруг симуляция некорректна? Он докопался до сути: deadline propagation обрывает многие запросы посередине их выполнения. Но к этому моменту они уже потратили CPU сервера. В случае с retry budget многие из этих запросов не дошли бы до сервера, потому что часть из них ретрайные. Поэтому deadline propagation — это скорее дополнение к retry budget.
Вася был приятно удивлён, что техника deadline propagation частично решает проблемы ретраев. Эта техника менее эффективна, чем retry budget, но она служит хорошим дополнением.
Финальное ретро по инциденту
Вася собрал финальное ретро по часовому инциденту. Он подготовил сводную таблицу со всеми action items, которые обсуждались по нему:
| Action item | Обобщаемость на другие инциденты | Эффективность для данного инцидента | Вердикт |
|---|---|---|---|
| Подтюнить алерты | низкая | высокая | делаем, дёшево |
| Зафиксить баг с segfault | низкая | высокая | делаем, root cause |
| Автотесты на тайм-аут СУБД | низко-средняя | высокая | делаем, гигиена |
| Retry circuit breaker или retry budget | высокая | высокая | делаем retry budget, ключевой action item |
| Circuit breaker | высокая | средняя | не берём как action item, но делаем в будущем |
| Deadline propagation | высокая | средне-высокая | стартуем как долгосрочный проект |
Вася подытожил: 3x амплификация нагрузки была вызвана ретраями, поэтому важно взять retry budget как самый критичный action item. Вася верил, если бы эта техника была реализована, система восстановилась не за 50 минут после отката релиза, а за 10. Также Вася предложил запланировать разработку deadline propagation как долгосрочный проект.
Все участники ретро согласились с предложениями Васи. На этом разбор инцидента был завершён.
Заключение
Через пару месяцев после завершения разбора инцидента команда платформы поддержала технику retry budget с порогом в 10%. В ближайший год после этого инциденты случались, но на них не была замечена амплификация от ретраев.
Благодаря разбору инцидента, Вася прошёл путь от «флапает — добавим ретраи» до хорошего понимания рисков даже от exponential backoff. Он познакомился с техниками exponential backoff и jitter, с законом Литтла и closed-loop системами, с концепцией metastable failure state, с проблемой амплификации ретраями и техниками retry circuit breaker и retry budget, а ещё с техниками circuit breaker и deadline propagation.
Впереди у Васи был не менее интересный путь познания глубин ретраев, но об этом мы поговорим в следующей части.
P.S. А ещё мы проводим митапы про отказоустойчивость, чтобы помогать Васе и другим разработчикам работать с высоконагруженными системами. Вот видеозаписи с последнего митапа.



