
Привет! Меня зовут Лёша Золотухин, и давным-давно, задолго до того, как я пришёл в Яндекс, моей первой системой observability был обычный телефон. Это когда пользователь звонит и говорит: «Знаете, а у вас всё лежит», — и ты идёшь чинить. Позже я впервые увидел Grafana. Смотрел на графики с условными ста RPS и думал: «Как круто, теперь я могу написать в резюме, что работал с хайлоадом».
Затем были компании покрупнее, знакомство с микросервисной архитектурой, системами мониторинга и SRE-культурой. Сейчас я достаточно долго работаю в Яндексе, и одно из основных направлений моей деятельности — создание дашбордов для огромного количества сервисов.
Под управлением нашей Техплатформы находится около 2600 микросервисов. Они написаны на четырёх основных языках: C++, Python, Go и Java, и для каждого есть свой фреймворк. Конечно, в результате интеграции новых решений и накопления опыта, у нас иногда встречаются сервисы с нефреймворковым кодом, да и легаси, как в любой большой компании, хватает. Но есть важный объединяющий фактор: подавляющее большинство сервисов живёт в контейнерах, перед которыми стоит nginx. Это даёт нам возможность единообразно собирать метрики и отображать их на дашбордах.
О том, как мы унифицировали диагностику на таком масштабе, я и хочу рассказать в этой статье.
Всё приходит с опытом
Дашборд сервиса — не статичная картинка, он эволюционирует вместе с продуктом. Более того, в самом начале его может и не быть вовсе. Некоторые умудряются запускаться в продакшен вслепую, но, как правило, достаточно быстро понимают, что так работать нельзя. Появляется первый дашборд в Grafana — обычно это набор вручную накликанных панелей. И для состояния MVP это вполне нормально.
По мере роста вы задумываетесь о полноте покрытия, о SLO и SLA. Случаются первые инциденты, и типичный action item после разбора полётов — добавить ещё одну панельку на мониторинг. Сервис развивается, обрастает соседями, возможно, делится на части. Вы начинаете думать о генерации дашбордов или развёртывании их из шаблона. На этом этапе дашборд часто превращается в бесконечную портянку, в которой уже невозможно ориентироваться.
Именно такой хаос и заставляет остановиться и наконец задуматься о главном — о сценариях использования. Так вы переходите на последний, самый зрелый этап — цикл бесконечных улучшений. И тут важно понимать: прежде чем что-то добавить, хорошо бы понять, что можно убрать или перенести в другое место.
Проблема масштаба
Когда у вас тысячи сервисов и сотни команд, подход «каждый делает сам» перестаёт работать. У всех разное понимание хорошего дашборда. Согласовать единый подход между командами и инструментами крайне сложно, особенно когда начинаются разговоры о компромиссах и выделении времени.
У продуктовых команд зачастую нет возможности глубоко погрузиться в построение комплексных решений в диагностике. Работа над инструментами observability постоянно требует ресурсов, конфликтуя со временем на фичи. В итоге развитие систем мониторинга отходит на второй план. А если вы в своём сервисе запилили интересное решение, распространить его на соседей в таких условиях — задача нетривиальная.
Наш ответ — централизованный генератор
Чтобы решить эти проблемы, мы создали отдельный сервис — генератор дашбордов. Есть специальные люди, которые его поддерживают. Для визуализации мы используем Grafana, а главная задача инструмента — генерация одинаковых дашбордов для всех сервисов под управлением Техплатформы.
Вот как это устроено:
- Infrastructure as Code (IaC). Мы подходим к конфигурации дашбордов как к коду. Вся структура, связи и логика панелей описываются декларативно и хранятся в системе контроля версий, что позволяет нам управлять ими централизованно.
- Отслеживание зависимостей. Наш сервис не просто генерирует шаблон, он анализирует связи. Если ваш сервис подключил базу данных или очередь сообщений, генератор это увидит и автоматически дополнит дашборд соответствующими графиками.
- Связи с инструментами. Мы рассматриваем дашборд как единую точку входа. Поэтому сервис автоматически создаёт связи с логами, трассировками, админками и другими инструментами диагностики.
- Кастомизация. Поскольку сервисов много, а команд ещё больше, мы предусмотрели возможность кастомизации через IaC. Можно добавить строчку в конфиг, закоммитить, и на дашборде появится ваша любимая панелька с бизнес-метриками. Или просто изменится порядок панелей.
Что интересно, раскатка новой интересной фичи на все 2600 сервисов при таком подходе занимает всего пару часов.
Кто пользуется дашбордами
При создании продукта полезно сразу представлять портрет пользователя, для которого этот продукт и делается. Мы выделили четыре основных категории:

- Разработчик сервиса. Отличается глубоким знанием того, что происходит внутри. Часто пользуется дашбордом во время выкаток, чтобы убедиться, что новый релиз не сломал старую функциональность.
- Дежурный по сервису. Это не обязательно разработчик конкретно этого компонента. Он может знать, что коллега по команде что-то делает в сервисе, но глубоких знаний у него может и не быть.
- Координатор инцидентов. Специальные люди, которые во время сбоя обеспечивают порядок, собирают команду спасения и принимают централизованные решения.
- Все остальные. Те, кто по той или иной причине оказался рядом: коллеги, чьи сервисы зависят от вашего, или опытные инженеры из других команд, пришедшие помочь.
Если проанализировать эти роли, становится очевидно: самое дорогое время использования дашборда — у дежурных и координаторов. Когда они открывают дашборды, это значит, что уже что-то сломалось. Каждая секунда их внимания в этот момент критически важна.
Узнать больше о расследовании инцидентов можно в материале «Инженерия надёжности в Маркете: принципы, процессы и реальные кейсы»
Для них генерация единых дашбордов решает главную боль — навигацию. Структура везде одинаковая, поэтому понятно, куда смотреть и где искать проблему, даже если ты видишь этот сервис впервые.
Обычно расследование инцидента идёт по воронке вопросов:
- Что сломалось? (Тут помогает алертинг и звонки среди ночи от дежурного).
- В каком сервисе сломалось? (Бизнес-дашборды или текст алерта).
- В каком компоненте сервиса проблема? (Сервисные дашборды).
- Что именно пошло не так? (Логи, трейсы, детальные графики).
Этот процесс последовательного погружения от общей картины к деталям и есть drill-down подход. Именно на нём и построена вся философия наших дашбордов. Чтобы он работал, мы пришли к многоуровневой системе: на основной, верхнеуровневый дашборд мы выводим только ключевые, агрегированные панели. А всю детализацию убираем на второй уровень.
Подробнее о применении таких подходов читайте в статье «Найти баг за 60 секунд: Real-Time мониторинг Яндекс Маркета»
Такая структура позволяет мгновенно локализовать проблему на уровне компонента и сразу же дать инженеру всё для детального расследования — готовые ссылки на логи, трейсы и более глубокие дашборды.
Анатомия нашего дашборда
Дашборд сервиса немного видоизменяется в зависимости от начинки микросервиса, но единый образ сохраняется всегда. Мы пришли к многоуровневой системе: на основной экран (Top Level) выводим агрегационные панели, а разложение трафика, фреймворкозависимые графики и кастомизации убираем ниже.
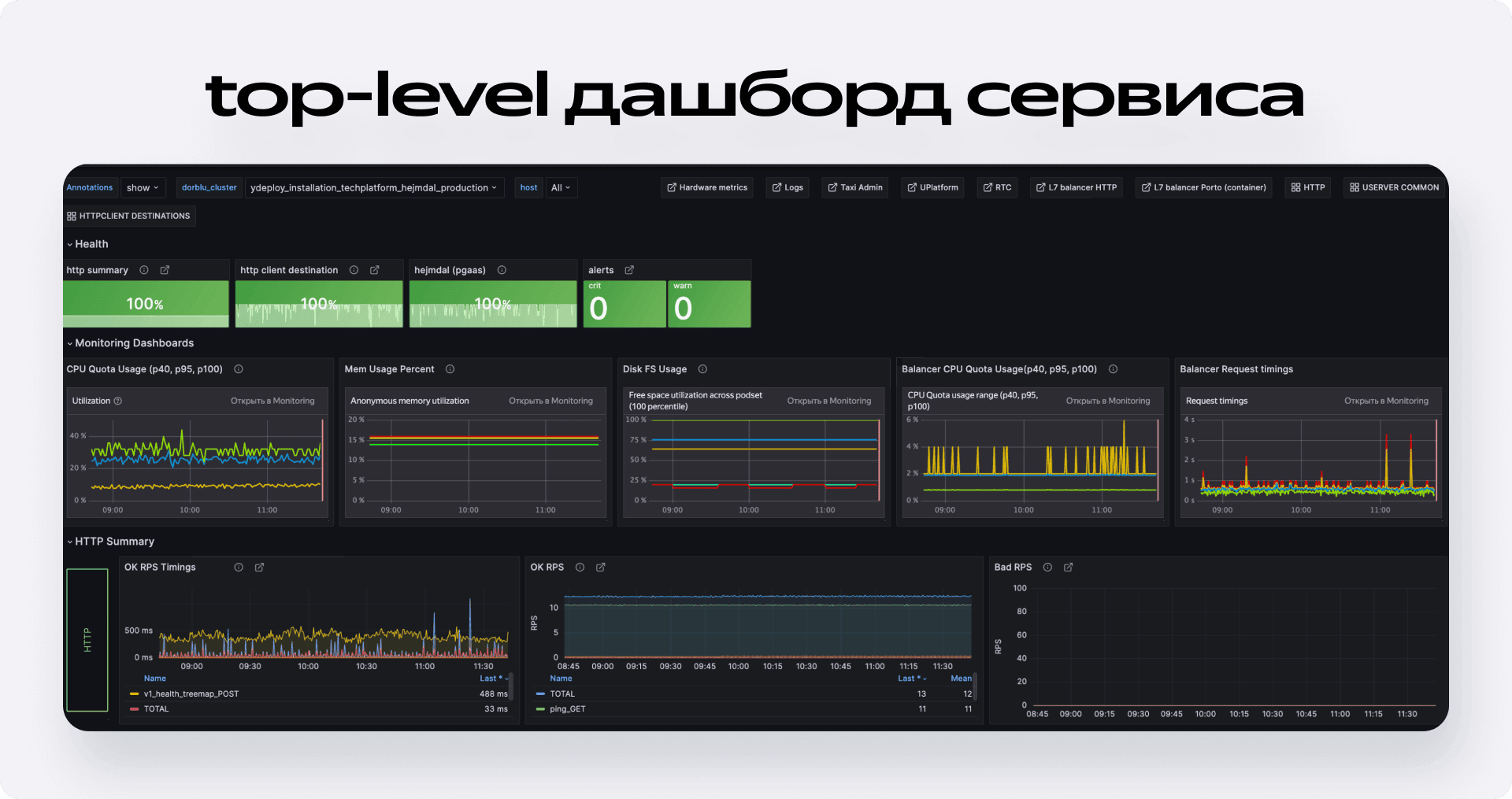
Пройдёмся по основным элементам сверху вниз.
Быстрые ссылки
Они решают две задачи: навигация между уровнями дашбордов и связь с инструментами починки. Всё спроектировано так, чтобы здесь можно было не просто посмотреть, но и быстро сделать что-либо. Например, перейти в админку для отката релиза.
Светофор здоровья
Это самая заметная часть дашборда — зелёная (в идеале) панель, которая сразу привлекает внимание. В базовом варианте она показывает:
- Входящий трафик (отношение ошибок ко всему трафику).
- Исходящий трафик.
- Алерты (количество в статусе warn и crit).

По мере того как сервис обрастает зависимостями, количество этих кубиков увеличивается. Добавляются индикаторы состояния очередей, баз данных. Эта панель может сразу ответить на вопрос: «В каком компоненте проблема?». Все блоки кликабельны и ведут на детальные дашборды или админки соответствующих сущностей.
Hardware-ресурсы
Ниже идут метрики по железу для контейнеров и балансера. Важно понимать, что что причиной инцидентов нередко становится резкий рост нагрузки на сервис. Митигация таких проблем проста — налить железа, а уже потом разбираться.
- Для контейнеров мы выводим CPU, память и диск.
- Для балансера — CPU и тайминги.
Мы сознательно не выводим здесь всё подряд, чтобы не усложнять без лишней необходимости. Например, нет графиков утилизации сети, потому что с ней редко бывают проблемы, и она обычно не лимитируется. Или ещё нет памяти диска для балансеров, потому что для них это не релевантная информация. Зато тайминги на балансере важны — они позволяют увидеть проблемы на стыке контейнеров и балансировщика.
Обзор трафика
Далее идёт блок входящего и исходящего трафика. Он описывается тремя стандартными панелями:
- Тайминги (98-й перцентиль успешных запросов).
- RPS (успешные запросы целиком и в разбивке по ручкам).
- Ошибки (в разбивке по ручкам и кодам ответа).
Но общих цифр часто недостаточно. Поэтому сразу под этим блоком у нас идёт детализация по клиентам. Здесь всё по тому же шаблону — три аналогичные панели: тайминги, трафик, ошибки, но уже в разрезе каждого сервиса, который к нам обращается. Это даёт возможность быстро идентифицировать, с каким конкретно потребителем что-то идёт не так, и пойти к мейнтейнерам соседнего сервиса.
Точно такой же подход мы применяем и для исходящего трафика: сначала общая картина, а ниже — детализация по каждому сервису, к которому мы обращаемся.
Второй уровень и полезные фичи
Чтобы основной дашборд не превращался в ту самую портянку, все детальные метрики мы выносим на второй уровень. Структура этих детальных дашбордов тоже едина: сверху — та же панель быстрых ссылок для навигации и та же агрегационная панель-светофор. А ниже уже идут подробные разбивки: по хостам, отдельным ручкам, in-memory кэшам и так далее.
Но самое интересное здесь даже не сами графики, а связи между ними.
Контекстные ссылки у нас есть практически на каждой панели. Например, ссылка на логи уже содержит предзаполненные фильтры по сервису, проекту и ручке. Такие ссылки можно вставлять не только в шапку панели, но и привязывать к конкретной линии на графике. Видишь всплеск 404-х ошибок? Кликаешь на линию графика — и сразу проваливаешься в логи именно с этим кодом ответа.
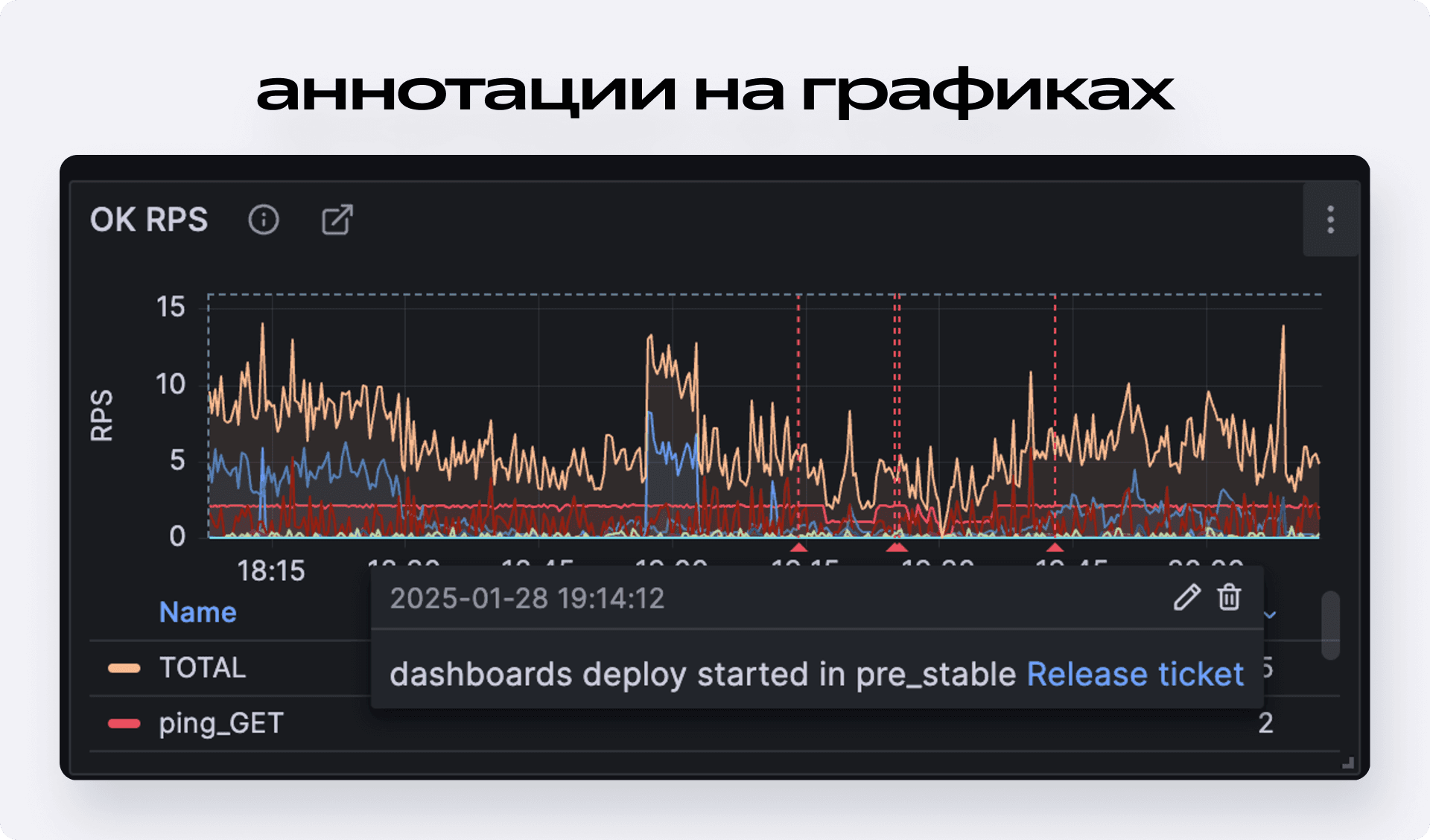
Ещё одна важная фича — аннотации. Это вертикальные пунктирные линии на графиках, которые отмечают события: старт и стоп релизов, изменение конфигов и прочее. В описании аннотации мы всегда даём ссылку на источник этого события — например, на тикет релиза или на страницу в админке, где виден дифф правок. Чтобы инженер мог не только мгновенно понять, что именно произошло в этот момент, но и при необходимости быстро откатить изменение.
Выводы
Хорошие дашборды сокращают время починки инцидентов. Не стоит относиться к observability как к задаче второго сорта — это фундамент стабильности.
Если вы, как и мы, решите идти в сторону генерации единых дашбордов, помните: с большой силой приходит большая ответственность. Вы можете легко раскатить крутую фичу на 2000 сервисов за час, но и цена ошибки при таких объёмах возрастает многократно. Поэтому обязательно нужно тестировать изменения шаблонов и продумывать механизмы отката.
И, конечно, уважайте своих коллег. Инструменты, которые вы делаете, вы делаете для них. Когда у дежурного в три часа ночи валится прод, он, может быть, и не скажет вам спасибо в тот самый момент, но потом точно будет благодарен за предсказуемый, понятный и работающий дашборд.



