
Любая система высокой нагрузки рано или поздно упирается в свой потолок. Для нас такой момент настал, когда наш сервис Сурж, в пике обрабатывающий тысячи запросов в секунду, начал подавать тревожные сигналы.
Давайте я коротко расскажу, о чём речь. Сурж — это наша система, которая отвечает за расчёты баланса спроса и предложения в реальном времени. Мы постоянно анализируем, где в данный момент есть высокий спрос, а где — свободные исполнители. И такой расчёт необходимо делать для 600 тысяч точек, обновляя данные каждые 3–5 минут. В среднем это около 6000 запросов в секунду.
Архитектурно система состоит из трёх звеньев:
- Калькулятор, который умеет считать.
- Планировщик, который знает, когда и что считать.
- Резолвер — кэширующий прокси сервер, который отдаёт данные по запросу.
Данные считает планировщик вместе с калькулятором и складывает в базу данных. Резолвер вычитывает данные и отдаёт нашим клиентам, имея на борту in-memory кеш.
Да, я понимаю, что у опытного инженера сейчас наверняка возник вопрос: зачем здесь вообще база данных в роли связующего звена? Ну, что я могу сказать, это — вынужденный архитектурный компромисс. Нам нужно было запуститься быстро, и использование БД как простого хранилища для обмена данными между компонентами было самым простым путём к цели.
И, нужно отдать должное, эта схема довольно долго и вполне неплохо справлялась со своей задачей. Но по мере роста нагрузки этот компромисс попросту себя исчерпал. Серия небольших инцидентов окончательно нас убедила в том, что архитектура требует пересмотра, а её самое слабое звено — единая база данных — больше не справляется. Так начался наш путь по поиску и устранению самых узких мест, который оказался куда интереснее, чем мы предполагали в самом начале.
Первый звонок от базы данных
Первый серьёзный сигнал мы получили во время, казалось бы, рутинной задачи. Мы решили немного оптимизировать структуру БД, чтобы поправить индексы и освободить часть вычислительных ресурсов. В теории всё выглядело логично, но на практике, как это иногда бывает, получилось только хуже.
Запись в базу данных практически встала, мастер перестал справляться с входящим потоком данных, чтение тоже начало захлёбываться. Эта попытка быстрого улучшения обнажила тот факт, что мы имеем дело не с локальной проблемой, а с фундаментальным узким местом в архитектуре.
Узнать больше о нестандартных подходах к работе с базами данных можно в материале «Миллионы товаров и тысячи аптек: переворачиваем архитектуру Яндекс Еды»
Пришлось копать глубже, чтобы проанализировать весь путь данных. Схема была такой: аналитики выполняют расчёты, их результат упаковывается в JSON-объект, который проверяется на корректность и отправляется в базу. А уже оттуда его забирает наш резолвер, чтобы отдать потребителям. И корень проблемы оказался именно в этих JSON-объектах — их было много, они были большими, и их постоянная запись и чтение создавали колоссальную нагрузку на БД.
Решение напрашивалось само собой: если проблема в объёме данных, нужно его сократить. Мы решили отказаться от громоздких текстовых JSON-объектов в пользу компактных бинарных Protobuf-сообщений.
Эффект был заметен практически сразу. Нагрузка на базу данных резко снизилась, что мы тут же увидели на всех ключевых графиках:
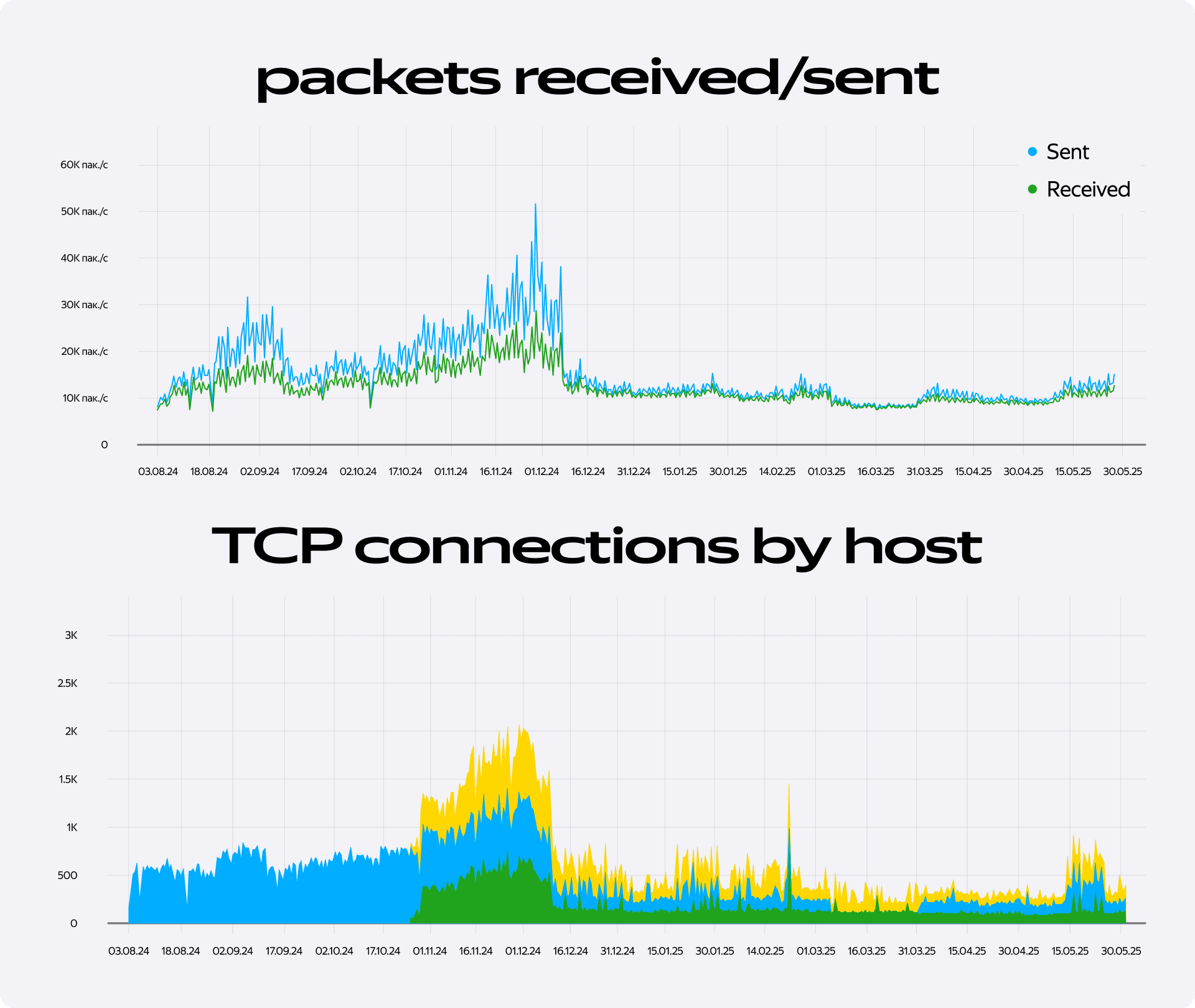
- упал сетевой трафик (Packets received/sent);
- сократилось количество активных подключений к БД;
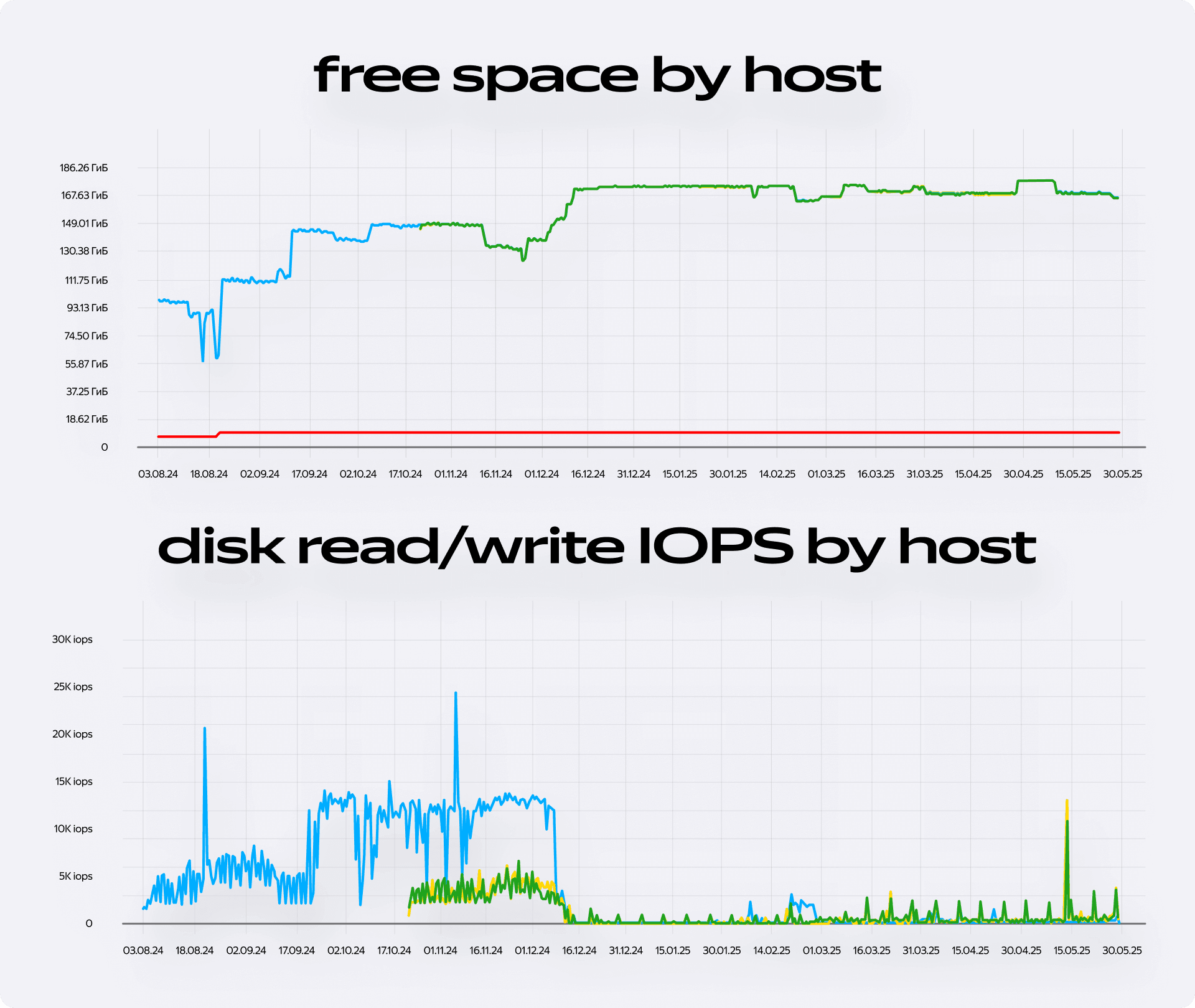
- сократилось количество дисковых операций (Disk read/write IOPS);
- база перестала находиться на грани переполнения — на графике Free space by host появился уверенный запас свободного места.
Тайминги стабилизировались, а команда аналитиков наконец-то смогла вздохнуть спокойно. Первая, самая острая проблема была решена. Но, как оказалось, это было только начало.
Зачем превращать Protobuf в JSON и обратно
Разобравшись с базой данных, мы переключили внимание на следующего кандидата на оптимизацию — систему резолвера. И здесь нас ждало новое открытие: практически вся вычислительная мощность системы уходила не на полезную работу, а на сериализацию данных перед отправкой.
Наши метрики показывали, что одна машина резолвера с трудом держала около 300 RPS. При этом мы понимали, что при нагрузке в 500–800 RPS она бы, скорее всего, просто захлебнулась. Это был явный сигнал, что мы теряем производительность на ровном месте.
Подробнее о работе с высокими нагрузками читайте в статье «Опыт создания коннектора к YTsaurus для Apache Flink под высокие нагрузки Яндекс Go»
Чтобы понять, почему так происходило, достаточно взглянуть на крайне неэффективный процесс обработки запроса:
- Резолвер получает данные из БД и поднимает их в виде C++ структуры.
- Затем эта структура преобразовывается в объектную модель JSON.
- И только потом она сериализуется в текстовую строку для отправки клиенту.
Добавьте к этому постоянную работу с динамической памятью и объектами — и вы получите идеальный рецепт для сжигания процессорного времени.
Мы не могли просто залезть в недра фреймворка userver и что-то там подправить, поэтому пошли другим путём. Раз уж мы храним данные в БД в формате Protobuf, почему бы не отдавать их напрямую, минуя затратный этап преобразования в JSON? Так и сделали.
Результаты нагрузочных тестов превзошли все наши самые смелые ожидания. Новые ручки, отдающие Protobuf, показали производительность более 2000 RPS на один под — это почти семикратный прирост. Как видно на графике CPU Quota usage, потребление процессорного времени резко пошло вниз. Это позволило нам не только справиться с возросшей нагрузкой, но и сэкономить ресурсы, убрав из инсталляции несколько лишних подов.
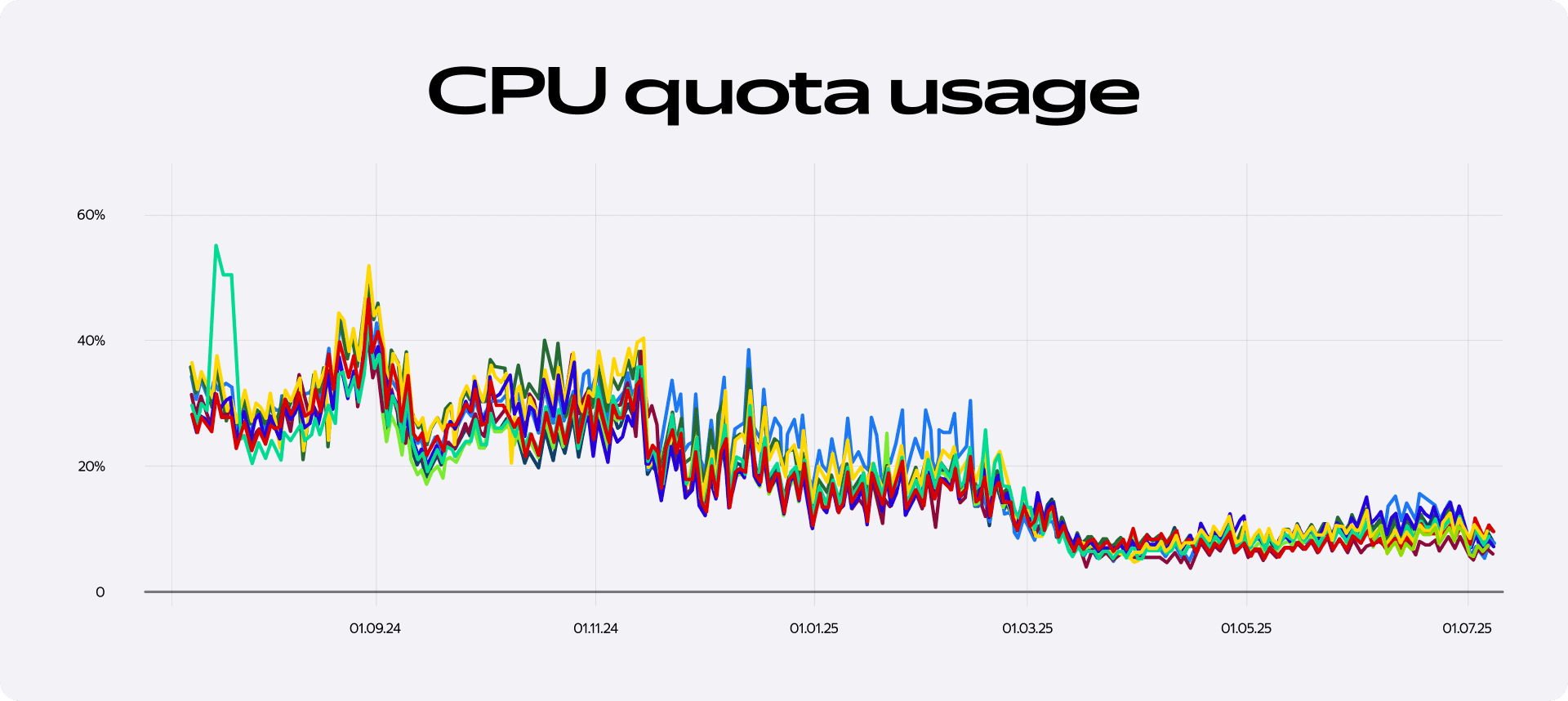
Мы устранили второе бутылочное горлышко. Но цепочка оптимизаций на этом не закончилась — впереди нас ждали не менее интересные открытия.
Неправильное масштабирование и один полезный сайд-эффект
Решив две ключевые проблемы производительности, мы обратили внимание на конфигурацию самой инфраструктуры. Оказалось, что наши предыдущие подходы к масштабированию были не самыми оптимальными, а ретроспективный анализ выявил несколько интересных закономерностей.
Наш резолвер — это, по сути, кэширующий прокси с LRU-кэшем в памяти. Новые данные, или ревизии, появляются в системе каждые 3–5 минут. Это значит, что каждый под должен в среднем раз в четыре минуты обновить свой кэш, подгрузив данные из базы. И здесь мы обнаружили ошибку в нашей логике.
Когда нам требовалось больше производительности, мы по привычке увеличивали количество подов. Но в нашей архитектуре каждый новый под — это ещё один потребитель, который будет регулярно ходить в БД за свежими данными.
Увеличивая число подов, мы пропорционально наращивали пиковую нагрузку на базу в моменты обновления ревизий. Более правильным подходом было бы сначала увеличивать ресурсы, выделенные каждому поду — в первую очередь ЦПУ, — и только потом, если этого недостаточно, наращивать их количество. Осознав это, мы пересмотрели подход к распределению ресурсов в кластере: сократили общее число подов, но выделили каждому из них больше ЦПУ. В результате база данных получила ещё одно долгожданное облегчение, а система в целом стала более предсказуемой.
Изучение работы кэша привело нас к ещё одному любопытному открытию. В какой-то момент наши клиенты, пытаясь снизить нагрузку на нашу систему, решили проредить свои походы к нам. Их логика была понятна: данные у нас обновляются раз в четыре минуты, а они ходят каждую минуту — можно и пореже. Однако, как только они это сделали, наши тайминги резко подскочили.
Оказалось, что своими частыми запросами клиенты, сами того не зная, оказывали нам услугу — они постоянно «прогревали» наш LRU-кэш. Их регулярные походы заставляли поды держать самые востребованные данные в памяти. Как только запросы стали реже, кэш начал «остывать», и мы стали чаще залипать на медленных запросах к базе данных. Это был отличный урок о том, как тесно связаны компоненты распределённой системы. В итоге мы попросили клиентов вернуть всё как было, и тайминги вернулись в норму.
Сглаживаем пики нагрузки на БД
После всех оптимизаций система работала стабильно, но на графиках нагрузки всё ещё оставался один артефакт, который нам не нравился. Каждые четыре минуты, в момент выхода новой ревизии данных, мы наблюдали резкий, пикообразный всплеск обращений к базе данных. Этот паттерн, похожий на зубья пилы, был прямым следствием нашей архитектуры.
Проблема заключалась в том, что все поды начинали подгружать свежие данные одновременно — ровно в тот момент, когда завершался обсчёт и происходил коммит новой ревизии. Все наши резолверы разом устремлялись в базу, создавая короткий, но очень интенсивный пик нагрузки.
Мы не любим всё угловатое, мы любим всё гладкое — и этот график явно требовал сглаживания.
Решение лежало на поверхности: нужно было изменить сам паттерн загрузки данных. Вместо того чтобы ждать официального коммита ревизии и только потом начинать обновление кэша, мы решили действовать на опережение. Новая логика была довольно простой: мы начинаем прогружать данные в поды ещё до того, как ревизия будет полностью посчитана и готова к использованию. Это позволяет растянуть процесс обновления кэша во времени. Когда новая ревизия наконец коммитится, большая часть необходимых данных уже находится в памяти у резолверов.
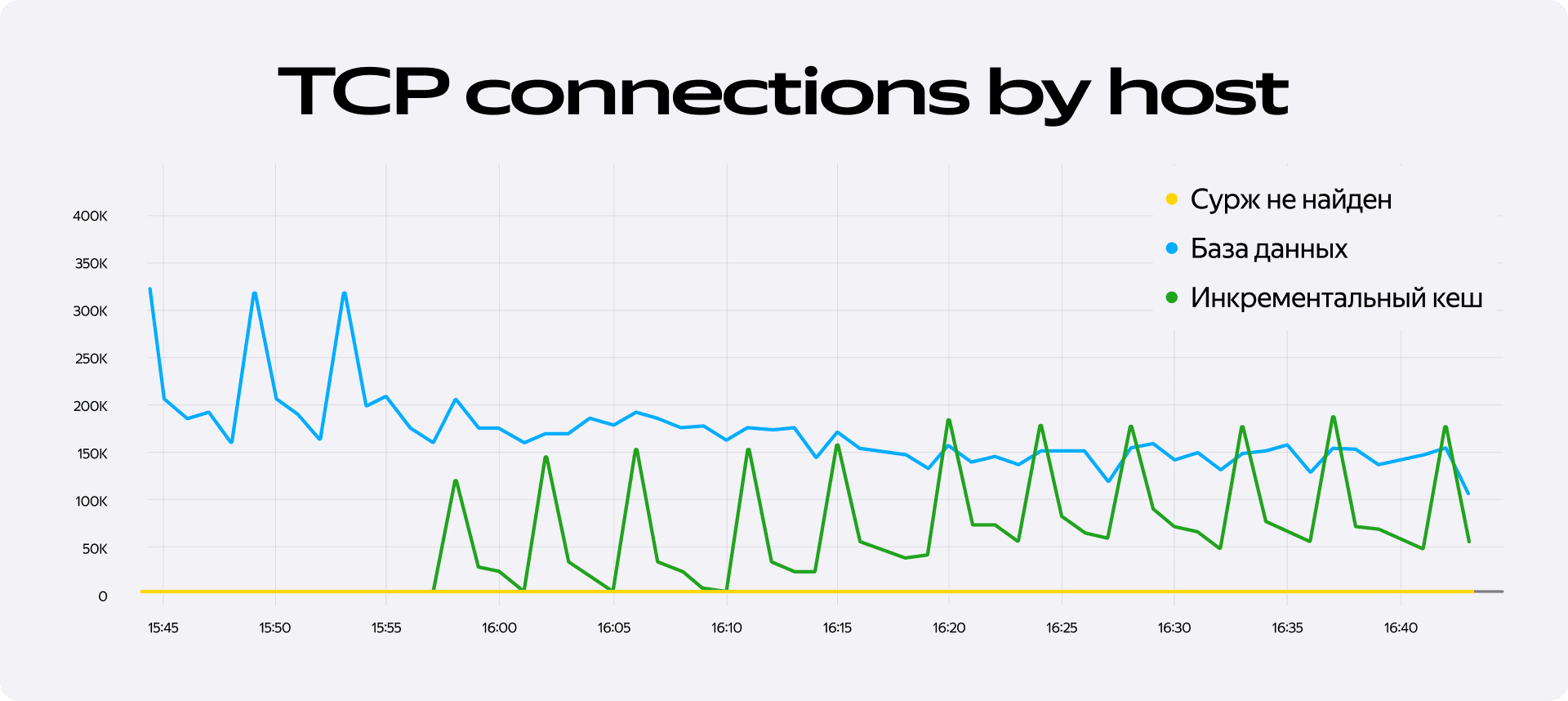
На графике можно видеть процесс включения и прогрева нового кеша. До его включения нагрузка на БД была в виде пилы с пиками каждые 4 минуты. После — ровная линия, в среднем меньше предыдущей. Прыгающую нагрузку забрал на себя новый кеш.
Заключение
Наш путь от горящей базы данных до стабильной, предсказуемой системы по сути является классической историей об устранении узких мест — одного за другим. Мы начали с очевидного — объёма данных и нагрузки на диски. Решив эту проблему, мы упёрлись в потолок по ЦПУ из-за сериализации. Оптимизировав её, мы поняли, что неправильно масштабируемся. И даже после этого нашли способ сделать нагрузку более плавной, перейдя от реакции на события к их опережению.
Главный вывод, который мы для себя сделали после всего этого: оптимизация — это не разовый проект, а непрерывный процесс. Решение одной проблемы часто лишь подсвечивает следующую, скрытую глубже. И это нормально. В таких случаях важно не просто латать дыры, а смотреть на систему целиком, анализировать данные и не бояться пересматривать подходы, которые ещё вчера казались правильными и незыблемыми.
В итоге мы получили систему, которая не просто справляется с пиковыми 11 000 RPS, но и стала гораздо более предсказуемой и управляемой. И теперь мы уверены, что готовы к новым пикам нагрузки, когда бы они ни случились.



